|
| 1 | +--- |
| 2 | +layout: post |
| 3 | +title: "【论文速读】| 注意力是实现基于大语言模型的代码漏洞定位的关键" |
| 4 | +date: 2024-12-20 10:30:00 |
| 5 | +author: "安全极客" |
| 6 | +header-img: "img/post-bg-unix-linux.jpg" |
| 7 | +tags: |
| 8 | + - Security |
| 9 | + - AIGC |
| 10 | + - 论文速读 |
| 11 | +--- |
| 12 | + |
| 13 | + |
| 14 | + |
| 15 | + |
| 16 | +## 基本信息 |
| 17 | + |
| 18 | +**原文标题**:Attention Is All You Need for LLM-based Code Vulnerability Localization |
| 19 | + |
| 20 | +**原文作者**:Yue Li, Xiao Li, Hao Wu, Yue Zhang, Xiuzhen Cheng, Sheng Zhong, Fengyuan Xu |
| 21 | + |
| 22 | +**作者单位**:National Key Laboratory for Novel Software Technology, Nanjing University, Nanjing, China; Department of Computer Science, Drexel University, Philadelphia, USA; School of Computer Science and Technology, Shandong University, Qingdao, China |
| 23 | + |
| 24 | +**关键词**:代码漏洞定位、LLM、自注意力机制、安全性 |
| 25 | + |
| 26 | +**原文链接**:https://arxiv.org/pdf/2410.15288 |
| 27 | + |
| 28 | +**开源代码**:暂无 |
| 29 | + |
| 30 | +## 论文要点 |
| 31 | + |
| 32 | +**论文简介**:随着软件系统的快速扩展和漏洞数量的增加,准确识别易受攻击的代码段变得尤为重要。传统的漏洞定位方法,如人工审计或基于规则的工具,往往耗时且受限于特定编程语言。近年来,大语言模型(LLM)的引入为自动化漏洞检测提供了新的可能性,但仍需有效利用其能力以提高定位准确性。 |
| 33 | + |
| 34 | +**研究目的**:软件漏洞是系统中的弱点,攻击者可以利用这些弱点危害系统的安全性和数据完整性。截至2024年9月,公共报告的漏洞数量超过240,000个,准确定位漏洞已成为重点研究领域,使开发人员能够针对性修复特定代码段。 |
| 35 | + |
| 36 | +**研究贡献**: |
| 37 | + |
| 38 | +1. 率先发现自注意力机制在漏洞定位中的有效性,通过跟踪注意力权重变化,识别可能包含漏洞的代码行。 |
| 39 | + |
| 40 | +2. 设计并实现了LOVA框架,结合行索引的提示设计、降维简化注意力输出,采用语言感知模型实现跨语言的推广。 |
| 41 | + |
| 42 | +3. 实验表明,LOVA在多种编程语言中提升了精度、召回率和可扩展性,适应不同代码长度和架构,确保稳健性。 |
| 43 | + |
| 44 | +## 引言 |
| 45 | + |
| 46 | +在当前的网络安全环境中,软件漏洞的存在不仅影响用户体验,还可能导致严重的安全事件。随着软件应用的增多,攻击者利用漏洞进行攻击的案例层出不穷。传统的漏洞定位方法依赖人工审核,效率低、准确性差。因此,研究者开始探索自动化工具,利用机器学习等新技术提升漏洞检测效率和准确性。已有的工具往往对特定编程语言或漏洞类型有较强依赖,这限制了其应用范围。因此,提出一种通用且高效的漏洞定位方法显得尤为重要。 |
| 47 | + |
| 48 | +## 研究背景 |
| 49 | + |
| 50 | +准确识别和定位漏洞是软件安全的关键环节。随着系统日益复杂,漏洞数量不断增加,给开发人员带来巨大挑战。漏洞可能导致数据泄露和功能失效,损害用户信任和企业声誉。因此,开发高效可靠的漏洞检测工具显得尤为重要。传统手动审核和基于规则的工具效率低,容易遗漏漏洞。大语言模型(LLM)的兴起为漏洞检测提供了新思路,能够快速识别潜在漏洞,提高修复效率,提升软件整体质量。 |
| 51 | + |
| 52 | +## 研究动机 |
| 53 | + |
| 54 | +本研究的动机源于对有效漏洞定位方法的迫切需求。随着网络攻击频繁,传统技术面临诸多挑战,包括低效率和局限性。传统方法不仅耗时,还容易遗漏潜在漏洞,特别是在复杂代码库中。近年来,LLM的发展为自动化漏洞检测提供了机会,利用其自注意力机制,我们希望能更好地理解代码上下文,识别安全漏洞。这种新方法能提高检测准确性,并减少开发和维护所需的时间和资源,为软件开发者提供高效工具,增强整体安全性。 |
| 55 | + |
| 56 | +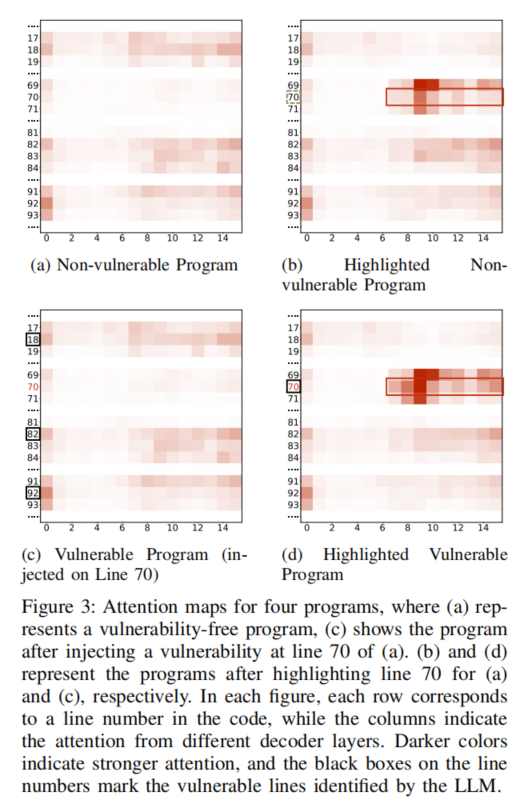 |
| 57 | + |
| 58 | +## LOVA设计 |
| 59 | + |
| 60 | +LOVA(基于自注意力的漏洞定位系统)的核心在于利用LLM的自注意力机制,自动评估和定位代码中的漏洞。系统首先分析输入代码,提取语法和语义特征,以识别可能的漏洞。自注意力机制允许模型关注代码不同部分之间的关系,帮助理解结构和逻辑。LOVA结合多种编程语言特征,具备更强的适应性和灵活性。系统设计包括有效的预处理步骤,确保输入数据质量和一致性,最终目标是提供高效、准确的漏洞定位工具,帮助开发人员在复杂环境中快速发现并修复安全隐患。 |
| 61 | + |
| 62 | +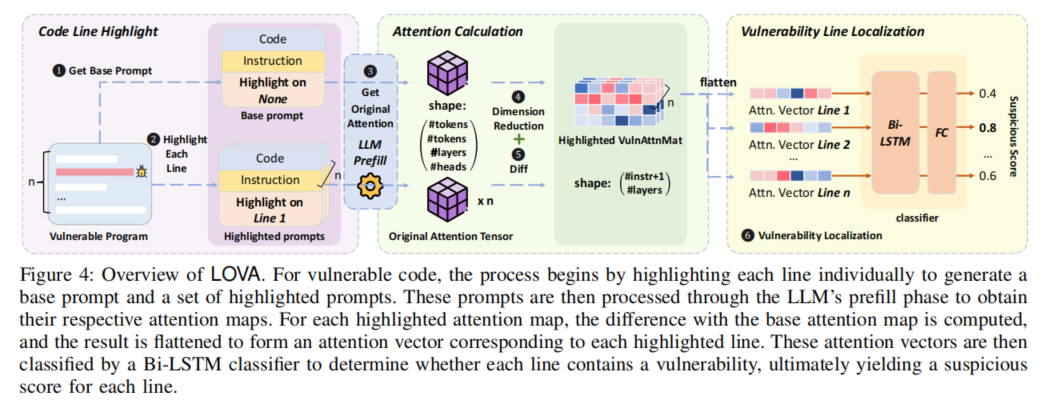 |
| 63 | + |
| 64 | +## 研究评估 |
| 65 | + |
| 66 | +**实验设置**:采用多种数据集训练和评估漏洞定位模型,涵盖多个编程语言和不同类型的漏洞,确保模型的泛化能力。使用公共开源项目及其相关漏洞报告,训练过程中采用交叉验证策略以避免过拟合。进行大量预处理,包括代码标准化和特征提取,实验环境设置在多个配置下以评估模型稳定性和性能。 |
| 67 | + |
| 68 | +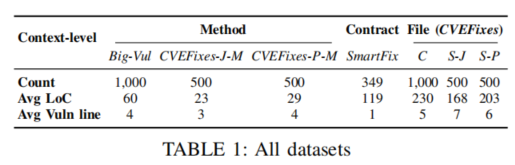 |
| 69 | + |
| 70 | +**实验结果**:实验结果显示,LOVA模型在漏洞定位的准确性上显著优于传统方法。在测试阶段,LOVA在真实数据集上的F1-score达到85%,而其他工具最高仅为72%。在复杂代码库中,LOVA成功识别90%的已知漏洞,且误报率显著降低,证明基于自注意力机制的模型在漏洞定位方面的有效性,为未来的自动化检测提供新思路。 |
| 71 | + |
| 72 | + |
| 73 | + |
| 74 | +## 论文结论 |
| 75 | + |
| 76 | +本论文的贡献在于提出了一种新的基于自注意力机制的漏洞定位方法,LOVA。通过系统性跟踪和分析代码的注意力权重,LOVA能有效识别复杂代码库中的潜在漏洞。研究结果表明,LOVA显著提高漏洞定位的准确性,展示其在软件安全领域的广泛应用潜力。期待未来研究进一步优化此方法,为自动化漏洞检测开辟新途径。 |
| 77 | + |
| 78 | + |
| 79 | + |
| 80 | + |
| 81 | + |
| 82 | + |
| 83 | + |
| 84 | + |
| 85 | + |
| 86 | + |
0 commit comments