"
- ]
- },
- "metadata": {},
- "output_type": "display_data"
- }
- ],
- "source": [
- "### Function minimization with autograd and gradient descent ###\n",
- "\n",
- "# Initialize a random value for our intial x\n",
- "x = torch.randn(1)\n",
- "print(f\"Initializing x={x.item()}\")\n",
- "\n",
- "learning_rate = 1e-2 # Learning rate\n",
- "history = []\n",
- "x_f = 4 # Target value\n",
- "\n",
- "\n",
- "# We will run gradient descent for a number of iterations. At each iteration, we compute the loss,\n",
- "# compute the derivative of the loss with respect to x, and perform the update.\n",
- "for i in range(500):\n",
- " x = torch.tensor([x], requires_grad=True)\n",
- "\n",
- " # Compute the loss as the square of the difference between x and x_f\n",
- " loss = (x - x_f) ** 2 # TODO\n",
- " # loss = # TODO\n",
- "\n",
- " # Backpropagate through the loss to compute gradients\n",
- " loss.backward()\n",
- "\n",
- " # Update x with gradient descent\n",
- " x = x.item() - learning_rate * x.grad\n",
- "\n",
- " history.append(x.item())\n",
- "\n",
- "# Plot the evolution of x as we optimize toward x_f!\n",
- "plt.plot(history)\n",
- "plt.plot([0, 500], [x_f, x_f])\n",
- "plt.legend(('Predicted', 'True'))\n",
- "plt.xlabel('Iteration')\n",
- "plt.ylabel('x value')\n",
- "plt.show()\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "pC7czCwk3ceH"
- },
- "source": [
- "Now, we have covered the fundamental concepts of PyTorch -- tensors, operations, neural networks, and automatic differentiation. Fire!!\n"
- ]
- }
- ],
- "metadata": {
- "accelerator": "GPU",
- "colab": {
- "collapsed_sections": [
- "WBk0ZDWY-ff8"
- ],
- "name": "PT_Part1_Intro_Solution.ipynb",
- "provenance": []
- },
- "kernelspec": {
- "display_name": "Python 3",
- "language": "python",
- "name": "python3"
- },
- "language_info": {
- "codemirror_mode": {
- "name": "ipython",
- "version": 3
- },
- "file_extension": ".py",
- "mimetype": "text/x-python",
- "name": "python",
- "nbconvert_exporter": "python",
- "pygments_lexer": "ipython3",
- "version": "3.10.6"
- },
- "vscode": {
- "interpreter": {
- "hash": "31f2aee4e71d21fbe5cf8b01ff0e069b9275f58929596ceb00d14d90e3e16cd6"
- }
- }
- },
- "nbformat": 4,
- "nbformat_minor": 0
-}
diff --git a/lab1/solutions/PT_Part2_Music_Generation_Solution.ipynb b/lab1/solutions/PT_Part2_Music_Generation_Solution.ipynb
deleted file mode 100644
index ac0335d9..00000000
--- a/lab1/solutions/PT_Part2_Music_Generation_Solution.ipynb
+++ /dev/null
@@ -1,1073 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "uoJsVjtCMunI"
- },
- "source": [
- "\n",
- "\n",
- "# Copyright Information"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "bUik05YqMyCH"
- },
- "outputs": [],
- "source": [
- "# Copyright 2025 MIT Introduction to Deep Learning. All Rights Reserved.\n",
- "#\n",
- "# Licensed under the MIT License. You may not use this file except in compliance\n",
- "# with the License. Use and/or modification of this code outside of MIT Introduction\n",
- "# to Deep Learning must reference:\n",
- "#\n",
- "# © MIT Introduction to Deep Learning\n",
- "# http://introtodeeplearning.com\n",
- "#"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "O-97SDET3JG-"
- },
- "source": [
- "# Lab 1: Intro to PyTorch and Music Generation with RNNs\n",
- "\n",
- "# Part 2: Music Generation with RNNs\n",
- "\n",
- "In this portion of the lab, we will explore building a Recurrent Neural Network (RNN) for music generation using PyTorch. We will train a model to learn the patterns in raw sheet music in [ABC notation](https://en.wikipedia.org/wiki/ABC_notation) and then use this model to generate new music."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "rsvlBQYCrE4I"
- },
- "source": [
- "## 2.1 Dependencies\n",
- "First, let's download the course repository, install dependencies, and import the relevant packages we'll need for this lab.\n",
- "\n",
- "We will be using [Comet ML](https://www.comet.com/docs/v2/) to track our model development and training runs. First, sign up for a Comet account [at this link](https://www.comet.com/signup?utm_source=mit_dl&utm_medium=partner&utm_content=github\n",
- ") (you can use your Google or Github account). This will generate a personal API Key, which you can find either in the first 'Get Started with Comet' page, under your account settings, or by pressing the '?' in the top right corner and then 'Quickstart Guide'. Enter this API key as the global variable `COMET_API_KEY`."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "riVZCVK65QTH"
- },
- "outputs": [],
- "source": [
- "!pip install comet_ml > /dev/null 2>&1\n",
- "import comet_ml\n",
- "# TODO: ENTER YOUR API KEY HERE!! instructions above\n",
- "COMET_API_KEY = \"\"\n",
- "\n",
- "# Import PyTorch and other relevant libraries\n",
- "import torch\n",
- "import torch.nn as nn\n",
- "import torch.optim as optim\n",
- "\n",
- "# Download and import the MIT Introduction to Deep Learning package\n",
- "!pip install mitdeeplearning --quiet\n",
- "import mitdeeplearning as mdl\n",
- "\n",
- "# Import all remaining packages\n",
- "import numpy as np\n",
- "import os\n",
- "import time\n",
- "import functools\n",
- "from IPython import display as ipythondisplay\n",
- "from tqdm import tqdm\n",
- "from scipy.io.wavfile import write\n",
- "!apt-get install abcmidi timidity > /dev/null 2>&1\n",
- "\n",
- "\n",
- "# Check that we are using a GPU, if not switch runtimes\n",
- "# using Runtime > Change Runtime Type > GPU\n",
- "assert torch.cuda.is_available(), \"Please enable GPU from runtime settings\"\n",
- "assert COMET_API_KEY != \"\", \"Please insert your Comet API Key\"\n",
- "\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "_ajvp0No4qDm"
- },
- "source": [
- "## 2.2 Dataset\n",
- "\n",
- "\n",
- "\n",
- "We've gathered a dataset of thousands of Irish folk songs, represented in the ABC notation. Let's download the dataset and inspect it:\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "P7dFnP5q3Jve"
- },
- "outputs": [],
- "source": [
- "# Download the dataset\n",
- "songs = mdl.lab1.load_training_data()\n",
- "\n",
- "# Print one of the songs to inspect it in greater detail!\n",
- "example_song = songs[0]\n",
- "print(\"\\nExample song: \")\n",
- "print(example_song)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "hKF3EHJlCAj2"
- },
- "source": [
- "We can easily convert a song in ABC notation to an audio waveform and play it back. Be patient for this conversion to run, it can take some time."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "11toYzhEEKDz"
- },
- "outputs": [],
- "source": [
- "# Convert the ABC notation to audio file and listen to it\n",
- "mdl.lab1.play_song(example_song)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "7vH24yyquwKQ"
- },
- "source": [
- "One important thing to think about is that this notation of music does not simply contain information on the notes being played, but additionally there is meta information such as the song title, key, and tempo. How does the number of different characters that are present in the text file impact the complexity of the learning problem? This will become important soon, when we generate a numerical representation for the text data."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "IlCgQBRVymwR"
- },
- "outputs": [],
- "source": [
- "# Join our list of song strings into a single string containing all songs\n",
- "songs_joined = \"\\n\\n\".join(songs)\n",
- "\n",
- "# Find all unique characters in the joined string\n",
- "vocab = sorted(set(songs_joined))\n",
- "print(\"There are\", len(vocab), \"unique characters in the dataset\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "rNnrKn_lL-IJ"
- },
- "source": [
- "## 2.3 Process the dataset for the learning task\n",
- "\n",
- "Let's take a step back and consider our prediction task. We're trying to train an RNN model to learn patterns in ABC music, and then use this model to generate (i.e., predict) a new piece of music based on this learned information.\n",
- "\n",
- "Breaking this down, what we're really asking the model is: given a character, or a sequence of characters, what is the most probable next character? We'll train the model to perform this task.\n",
- "\n",
- "To achieve this, we will input a sequence of characters to the model, and train the model to predict the output, that is, the following character at each time step. RNNs maintain an internal state that depends on previously seen elements, so information about all characters seen up until a given moment will be taken into account in generating the prediction."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "LFjSVAlWzf-N"
- },
- "source": [
- "### Vectorize the text\n",
- "\n",
- "Before we begin training our RNN model, we'll need to create a numerical representation of our text-based dataset. To do this, we'll generate two lookup tables: one that maps characters to numbers, and a second that maps numbers back to characters. Recall that we just identified the unique characters present in the text.\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "IalZLbvOzf-F"
- },
- "outputs": [],
- "source": [
- "### Define numerical representation of text ###\n",
- "\n",
- "# Create a mapping from character to unique index.\n",
- "# For example, to get the index of the character \"d\",\n",
- "# we can evaluate `char2idx[\"d\"]`.\n",
- "char2idx = {u: i for i, u in enumerate(vocab)}\n",
- "\n",
- "# Create a mapping from indices to characters. This is\n",
- "# the inverse of char2idx and allows us to convert back\n",
- "# from unique index to the character in our vocabulary.\n",
- "idx2char = np.array(vocab)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "tZfqhkYCymwX"
- },
- "source": [
- "This gives us an integer representation for each character. Observe that the unique characters (i.e., our vocabulary) in the text are mapped as indices from 0 to `len(unique)`. Let's take a peek at this numerical representation of our dataset:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "FYyNlCNXymwY"
- },
- "outputs": [],
- "source": [
- "print('{')\n",
- "for char, _ in zip(char2idx, range(20)):\n",
- " print(' {:4s}: {:3d},'.format(repr(char), char2idx[char]))\n",
- "print(' ...\\n}')"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "g-LnKyu4dczc"
- },
- "outputs": [],
- "source": [
- "### Vectorize the songs string ###\n",
- "\n",
- "'''TODO: Write a function to convert the all songs string to a vectorized\n",
- " (i.e., numeric) representation. Use the appropriate mapping\n",
- " above to convert from vocab characters to the corresponding indices.\n",
- "\n",
- " NOTE: the output of the `vectorize_string` function\n",
- " should be a np.array with `N` elements, where `N` is\n",
- " the number of characters in the input string\n",
- "'''\n",
- "def vectorize_string(string):\n",
- " vectorized_output = np.array([char2idx[char] for char in string])\n",
- " return vectorized_output\n",
- "\n",
- "# def vectorize_string(string):\n",
- " # TODO\n",
- "\n",
- "vectorized_songs = vectorize_string(songs_joined)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "IqxpSuZ1w-ub"
- },
- "source": [
- "We can also look at how the first part of the text is mapped to an integer representation:\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "l1VKcQHcymwb"
- },
- "outputs": [],
- "source": [
- "print ('{} ---- characters mapped to int ----> {}'.format(repr(songs_joined[:10]), vectorized_songs[:10]))\n",
- "# check that vectorized_songs is a numpy array\n",
- "assert isinstance(vectorized_songs, np.ndarray), \"returned result should be a numpy array\""
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "hgsVvVxnymwf"
- },
- "source": [
- "### Create training examples and targets\n",
- "\n",
- "Our next step is to actually divide the text into example sequences that we'll use during training. Each input sequence that we feed into our RNN will contain `seq_length` characters from the text. We'll also need to define a target sequence for each input sequence, which will be used in training the RNN to predict the next character. For each input, the corresponding target will contain the same length of text, except shifted one character to the right.\n",
- "\n",
- "To do this, we'll break the text into chunks of `seq_length+1`. Suppose `seq_length` is 4 and our text is \"Hello\". Then, our input sequence is \"Hell\" and the target sequence is \"ello\".\n",
- "\n",
- "The batch method will then let us convert this stream of character indices to sequences of the desired size.\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "LF-N8F7BoDRi"
- },
- "outputs": [],
- "source": [
- "### Batch definition to create training examples ###\n",
- "\n",
- "def get_batch(vectorized_songs, seq_length, batch_size):\n",
- " # the length of the vectorized songs string\n",
- " n = vectorized_songs.shape[0] - 1\n",
- " # randomly choose the starting indices for the examples in the training batch\n",
- " idx = np.random.choice(n - seq_length, batch_size)\n",
- "\n",
- " '''TODO: construct a list of input sequences for the training batch'''\n",
- " input_batch = [vectorized_songs[i: i + seq_length] for i in idx]\n",
- "\n",
- " '''TODO: construct a list of output sequences for the training batch'''\n",
- " output_batch = [vectorized_songs[i + 1: i + seq_length + 1] for i in idx]\n",
- "\n",
- " # Convert the input and output batches to tensors\n",
- " x_batch = torch.tensor(input_batch, dtype=torch.long)\n",
- " y_batch = torch.tensor(output_batch, dtype=torch.long)\n",
- "\n",
- " return x_batch, y_batch\n",
- "\n",
- "# Perform some simple tests to make sure your batch function is working properly!\n",
- "test_args = (vectorized_songs, 10, 2)\n",
- "x_batch, y_batch = get_batch(*test_args)\n",
- "assert x_batch.shape == (2, 10), \"x_batch shape is incorrect\"\n",
- "assert y_batch.shape == (2, 10), \"y_batch shape is incorrect\"\n",
- "print(\"Batch function works correctly!\")\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "_33OHL3b84i0"
- },
- "source": [
- "For each of these vectors, each index is processed at a single time step. So, for the input at time step 0, the model receives the index for the first character in the sequence, and tries to predict the index of the next character. At the next timestep, it does the same thing, but the RNN considers the information from the previous step, i.e., its updated state, in addition to the current input.\n",
- "\n",
- "We can make this concrete by taking a look at how this works over the first several characters in our text:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "0eBu9WZG84i0"
- },
- "outputs": [],
- "source": [
- "x_batch, y_batch = get_batch(vectorized_songs, seq_length=5, batch_size=1)\n",
- "\n",
- "for i, (input_idx, target_idx) in enumerate(zip(x_batch[0], y_batch[0])):\n",
- " print(\"Step {:3d}\".format(i))\n",
- " print(\" input: {} ({:s})\".format(input_idx, repr(idx2char[input_idx.item()])))\n",
- " print(\" expected output: {} ({:s})\".format(target_idx, repr(idx2char[target_idx.item()])))\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "r6oUuElIMgVx"
- },
- "source": [
- "## 2.4 The Recurrent Neural Network (RNN) model"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "m8gPwEjRzf-Z"
- },
- "source": [
- "Now we're ready to define and train an RNN model on our ABC music dataset, and then use that trained model to generate a new song. We'll train our RNN using batches of song snippets from our dataset, which we generated in the previous section.\n",
- "\n",
- "The model is based off the LSTM architecture, where we use a state vector to maintain information about the temporal relationships between consecutive characters. The final output of the LSTM is then fed into a fully connected linear [`nn.Linear`](https://pytorch.org/docs/stable/generated/torch.nn.Linear.html) layer where we'll output a softmax over each character in the vocabulary, and then sample from this distribution to predict the next character.\n",
- "\n",
- "As we introduced in the first portion of this lab, we'll be using PyTorch's [`nn.Module`](https://pytorch.org/docs/stable/generated/torch.nn.Module.html) to define the model. Three components are used to define the model:\n",
- "\n",
- "* [`nn.Embedding`](https://pytorch.org/docs/stable/generated/torch.nn.Embedding.html): This is the input layer, consisting of a trainable lookup table that maps the numbers of each character to a vector with `embedding_dim` dimensions.\n",
- "* [`nn.LSTM`](https://pytorch.org/docs/stable/generated/torch.nn.LSTM.html): Our LSTM network, with size `hidden_size`.\n",
- "* [`nn.Linear`](https://pytorch.org/docs/stable/generated/torch.nn.Linear.html): The output layer, with `vocab_size` outputs.\n",
- "\n",
- " \n",
- "\n",
- "\n",
- "\n",
- ""
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "rlaOqndqBmJo"
- },
- "source": [
- "### Define the RNN model\n",
- "\n",
- "Let's define our model as an `nn.Module`. Fill in the `TODOs` to define the RNN model.\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "8DsWzojvkbc7"
- },
- "outputs": [],
- "source": [
- "### Defining the RNN Model ###\n",
- "\n",
- "'''TODO: Add LSTM and Linear layers to define the RNN model using nn.Module'''\n",
- "class LSTMModel(nn.Module):\n",
- " def __init__(self, vocab_size, embedding_dim, hidden_size):\n",
- " super(LSTMModel, self).__init__()\n",
- " self.hidden_size = hidden_size\n",
- "\n",
- " # Define each of the network layers\n",
- " # Layer 1: Embedding layer to transform indices into dense vectors\n",
- " # of a fixed embedding size\n",
- " self.embedding = nn.Embedding(vocab_size, embedding_dim)\n",
- "\n",
- " # Layer 2: LSTM with hidden_size `hidden_size`. note: number of layers defaults to 1.\n",
- " # TODO: Use the nn.LSTM() module from pytorch.\n",
- " self.lstm = nn.LSTM(embedding_dim, hidden_size, batch_first=True)\n",
- " # self.lstm = nn.LSTM('''TODO''')\n",
- "\n",
- " # Layer 3: Linear (fully-connected) layer that transforms the LSTM output\n",
- " # into the vocabulary size.\n",
- " # TODO: Add the Linear layer.\n",
- " self.fc = nn.Linear(hidden_size, vocab_size)\n",
- " # self.fc = nn.Linear('''TODO''')\n",
- "\n",
- " def init_hidden(self, batch_size, device):\n",
- " # Initialize hidden state and cell state with zeros\n",
- " return (torch.zeros(1, batch_size, self.hidden_size).to(device),\n",
- " torch.zeros(1, batch_size, self.hidden_size).to(device))\n",
- "\n",
- " def forward(self, x, state=None, return_state=False):\n",
- " x = self.embedding(x)\n",
- "\n",
- " if state is None:\n",
- " state = self.init_hidden(x.size(0), x.device)\n",
- " out, state = self.lstm(x, state)\n",
- "\n",
- " out = self.fc(out)\n",
- " return out if not return_state else (out, state)\n",
- "\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "IbWU4dMJmMvq"
- },
- "source": [
- "The time has come! Let's instantiate the model!"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "MtCrdfzEI2N0"
- },
- "outputs": [],
- "source": [
- "# Instantiate the model! Build a simple model with default hyperparameters. You\n",
- "# will get the chance to change these later.\n",
- "vocab_size = len(vocab)\n",
- "embedding_dim = 256\n",
- "hidden_size = 1024\n",
- "batch_size = 8\n",
- "\n",
- "device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n",
- "\n",
- "model = LSTMModel(vocab_size, embedding_dim, hidden_size).to(device)\n",
- "\n",
- "# print out a summary of the model\n",
- "print(model)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "-ubPo0_9Prjb"
- },
- "source": [
- "### Test out the RNN model\n",
- "\n",
- "It's always a good idea to run a few simple checks on our model to see that it behaves as expected. \n",
- "\n",
- "We can quickly check the layers in the model, the shape of the output of each of the layers, the batch size, and the dimensionality of the output. Note that the model can be run on inputs of any length."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "C-_70kKAPrPU"
- },
- "outputs": [],
- "source": [
- "# Test the model with some sample data\n",
- "x, y = get_batch(vectorized_songs, seq_length=100, batch_size=32)\n",
- "x = x.to(device)\n",
- "y = y.to(device)\n",
- "\n",
- "pred = model(x)\n",
- "print(\"Input shape: \", x.shape, \" # (batch_size, sequence_length)\")\n",
- "print(\"Prediction shape: \", pred.shape, \"# (batch_size, sequence_length, vocab_size)\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "mT1HvFVUGpoE"
- },
- "source": [
- "### Predictions from the untrained model\n",
- "\n",
- "Let's take a look at what our untrained model is predicting.\n",
- "\n",
- "To get actual predictions from the model, we sample from the output distribution, which is defined by a torch.softmax over our character vocabulary. This will give us actual character indices. This means we are using a [categorical distribution](https://en.wikipedia.org/wiki/Categorical_distribution) to sample over the example prediction. This gives a prediction of the next character (specifically its index) at each timestep. [`torch.multinomial`](https://pytorch.org/docs/stable/generated/torch.multinomial.html#torch.multinomial) samples over a categorical distribution to generate predictions.\n",
- "\n",
- "Note here that we sample from this probability distribution, as opposed to simply taking the `argmax`, which can cause the model to get stuck in a repetitive loop.\n",
- "\n",
- "Let's try this sampling out for the first example in the batch."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "4V4MfFg0RQJg"
- },
- "outputs": [],
- "source": [
- "sampled_indices = torch.multinomial(torch.softmax(pred[0], dim=-1), num_samples=1)\n",
- "sampled_indices = sampled_indices.squeeze(-1).cpu().numpy()\n",
- "sampled_indices"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "LfLtsP3mUhCG"
- },
- "source": [
- "We can now decode these to see the text predicted by the untrained model:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "xWcFwPwLSo05"
- },
- "outputs": [],
- "source": [
- "print(\"Input: \\n\", repr(\"\".join(idx2char[x[0].cpu()])))\n",
- "print()\n",
- "print(\"Next Char Predictions: \\n\", repr(\"\".join(idx2char[sampled_indices])))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "HEHHcRasIDm9"
- },
- "source": [
- "As you can see, the text predicted by the untrained model is pretty nonsensical! How can we do better? Well, we can train the network!"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "LJL0Q0YPY6Ee"
- },
- "source": [
- "## 2.5 Training the model: loss and training operations\n",
- "\n",
- "Now it's time to train the model!\n",
- "\n",
- "At this point, we can think of our next character prediction problem as a standard classification problem. Given the previous state of the RNN, as well as the input at a given time step, we want to predict the class of the next character -- that is, to actually predict the next character.\n",
- "\n",
- "To train our model on this classification task, we can use a form of the `crossentropy` loss (i.e., negative log likelihood loss). Specifically, we will use PyTorch's [`CrossEntropyLoss`](https://pytorch.org/docs/stable/generated/torch.nn.CrossEntropyLoss.html), as it combines the application of a log-softmax ([`LogSoftmax`](https://pytorch.org/docs/stable/generated/torch.nn.LogSoftmax.html#torch.nn.LogSoftmax)) and negative log-likelihood ([`NLLLoss`](https://pytorch.org/docs/stable/generated/torch.nn.NLLLoss.html#torch.nn.NLLLoss) in a single class and accepts integer targets for categorical classification tasks. We will want to compute the loss using the true targets -- the `labels` -- and the predicted targets -- the `logits`.\n",
- "\n",
- "Let's define a function to compute the loss, and then use that function to compute the loss using our example predictions from the untrained model."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "4HrXTACTdzY-"
- },
- "outputs": [],
- "source": [
- "### Defining the loss function ###\n",
- "\n",
- "# '''TODO: define the compute_loss function to compute and return the loss between\n",
- "# the true labels and predictions (logits). '''\n",
- "cross_entropy = nn.CrossEntropyLoss() # instantiates the function\n",
- "def compute_loss(labels, logits):\n",
- " \"\"\"\n",
- " Inputs:\n",
- " labels: (batch_size, sequence_length)\n",
- " logits: (batch_size, sequence_length, vocab_size)\n",
- "\n",
- " Output:\n",
- " loss: scalar cross entropy loss over the batch and sequence length\n",
- " \"\"\"\n",
- "\n",
- " # Batch the labels so that the shape of the labels should be (B * L,)\n",
- " batched_labels = labels.view(-1)\n",
- "\n",
- " ''' TODO: Batch the logits so that the shape of the logits should be (B * L, V) '''\n",
- " batched_logits = logits.view(-1, logits.size(-1))\n",
- " # batched_logits = \"\"\" TODO \"\"\" # TODO\n",
- "\n",
- " '''TODO: Compute the cross-entropy loss using the batched next characters and predictions'''\n",
- " loss = cross_entropy(batched_logits, batched_labels)\n",
- " # loss = \"\"\" TODO \"\"\" # TODO\n",
- " return loss"
- ]
- },
- {
- "cell_type": "code",
- "source": [
- "### compute the loss on the predictions from the untrained model from earlier. ###\n",
- "y.shape # (batch_size, sequence_length)\n",
- "pred.shape # (batch_size, sequence_length, vocab_size)\n",
- "\n",
- "'''TODO: compute the loss using the true next characters from the example batch\n",
- " and the predictions from the untrained model several cells above'''\n",
- "example_batch_loss = compute_loss(y, pred)\n",
- "# example_batch_loss = compute_loss('''TODO''', '''TODO''') # TODO\n",
- "\n",
- "print(f\"Prediction shape: {pred.shape} # (batch_size, sequence_length, vocab_size)\")\n",
- "print(f\"scalar_loss: {example_batch_loss.mean().item()}\")"
- ],
- "metadata": {
- "id": "GuGUJB0ZT_Uo"
- },
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "0Seh7e6eRqd7"
- },
- "source": [
- "Let's start by defining some hyperparameters for training the model. To start, we have provided some reasonable values for some of the parameters. It is up to you to use what we've learned in class to help optimize the parameter selection here!"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "JQWUUhKotkAY"
- },
- "outputs": [],
- "source": [
- "### Hyperparameter setting and optimization ###\n",
- "\n",
- "vocab_size = len(vocab)\n",
- "\n",
- "# Model parameters:\n",
- "params = dict(\n",
- " num_training_iterations = 3000, # Increase this to train longer\n",
- " batch_size = 8, # Experiment between 1 and 64\n",
- " seq_length = 100, # Experiment between 50 and 500\n",
- " learning_rate = 5e-3, # Experiment between 1e-5 and 1e-1\n",
- " embedding_dim = 256,\n",
- " hidden_size = 1024, # Experiment between 1 and 2048\n",
- ")\n",
- "\n",
- "# Checkpoint location:\n",
- "checkpoint_dir = './training_checkpoints'\n",
- "checkpoint_prefix = os.path.join(checkpoint_dir, \"my_ckpt\")\n",
- "os.makedirs(checkpoint_dir, exist_ok=True)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "AyLzIPeAIqfg"
- },
- "source": [
- "Having defined our hyperparameters we can set up for experiment tracking with Comet. [`Experiment`](https://www.comet.com/docs/v2/api-and-sdk/python-sdk/reference/Experiment/) are the core objects in Comet and will allow us to track training and model development. Here we have written a short function to create a new Comet experiment. Note that in this setup, when hyperparameters change, you can run the `create_experiment()` function to initiate a new experiment. All experiments defined with the same `project_name` will live under that project in your Comet interface.\n",
- "\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "MBsN1vvxInmN"
- },
- "outputs": [],
- "source": [
- "### Create a Comet experiment to track our training run ###\n",
- "\n",
- "def create_experiment():\n",
- " # end any prior experiments\n",
- " if 'experiment' in locals():\n",
- " experiment.end()\n",
- "\n",
- " # initiate the comet experiment for tracking\n",
- " experiment = comet_ml.Experiment(\n",
- " api_key=COMET_API_KEY,\n",
- " project_name=\"6S191_Lab1_Part2\")\n",
- " # log our hyperparameters, defined above, to the experiment\n",
- " for param, value in params.items():\n",
- " experiment.log_parameter(param, value)\n",
- " experiment.flush()\n",
- "\n",
- " return experiment"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "5cu11p1MKYZd"
- },
- "source": [
- "Now, we are ready to define our training operation -- the optimizer and duration of training -- and use this function to train the model. You will experiment with the choice of optimizer and the duration for which you train your models, and see how these changes affect the network's output. Some optimizers you may like to try are [`Adam`](https://pytorch.org/docs/stable/generated/torch.optim.Adam.html) and [`Adagrad`](https://pytorch.org/docs/stable/generated/torch.optim.Adagrad.html).\n",
- "\n",
- "First, we will instantiate a new model and an optimizer, and ready them for training. Then, we will use [`loss.backward()`](https://pytorch.org/docs/stable/generated/torch.Tensor.backward.html), enabled by PyTorch's [autograd](https://pytorch.org/docs/stable/generated/torch.autograd.grad.html) method, to perform the backpropagation. Finally, to update the model's parameters based on the computed gradients, we will utake a step with the optimizer, using [`optimizer.step()`](https://pytorch.org/docs/stable/generated/torch.optim.Optimizer.step.html).\n",
- "\n",
- "We will also generate a print-out of the model's progress through training, which will help us easily visualize whether or not we are minimizing the loss."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "F31vzJ_u66cb"
- },
- "outputs": [],
- "source": [
- "### Define optimizer and training operation ###\n",
- "\n",
- "'''TODO: instantiate a new LSTMModel model for training using the hyperparameters\n",
- " created above.'''\n",
- "model = LSTMModel(vocab_size, params[\"embedding_dim\"], params[\"hidden_size\"])\n",
- "# model = LSTMModel('''TODO: arguments''')\n",
- "\n",
- "# Move the model to the GPU\n",
- "model.to(device)\n",
- "\n",
- "'''TODO: instantiate an optimizer with its learning rate.\n",
- " Checkout the PyTorch website for a list of supported optimizers.\n",
- " https://pytorch.org/docs/stable/optim.html\n",
- " Try using the Adam optimizer to start.'''\n",
- "optimizer = torch.optim.Adam(model.parameters(), lr=params[\"learning_rate\"])\n",
- "# optimizer = # TODO\n",
- "\n",
- "def train_step(x, y):\n",
- " # Set the model's mode to train\n",
- " model.train()\n",
- "\n",
- " # Zero gradients for every step\n",
- " optimizer.zero_grad()\n",
- "\n",
- " # Forward pass\n",
- " '''TODO: feed the current input into the model and generate predictions'''\n",
- " y_hat = model(x) # TODO\n",
- " # y_hat = model('''TODO''')\n",
- "\n",
- " # Compute the loss\n",
- " '''TODO: compute the loss!'''\n",
- " loss = compute_loss(y, y_hat) # TODO\n",
- " # loss = compute_loss('''TODO''', '''TODO''')\n",
- "\n",
- " # Backward pass\n",
- " '''TODO: complete the gradient computation and update step.\n",
- " Remember that in PyTorch there are two steps to the training loop:\n",
- " 1. Backpropagate the loss\n",
- " 2. Update the model parameters using the optimizer\n",
- " '''\n",
- " loss.backward() # TODO\n",
- " optimizer.step() # TODO\n",
- "\n",
- " return loss\n",
- "\n",
- "##################\n",
- "# Begin training!#\n",
- "##################\n",
- "\n",
- "history = []\n",
- "plotter = mdl.util.PeriodicPlotter(sec=2, xlabel='Iterations', ylabel='Loss')\n",
- "experiment = create_experiment()\n",
- "\n",
- "if hasattr(tqdm, '_instances'): tqdm._instances.clear() # clear if it exists\n",
- "for iter in tqdm(range(params[\"num_training_iterations\"])):\n",
- "\n",
- " # Grab a batch and propagate it through the network\n",
- " x_batch, y_batch = get_batch(vectorized_songs, params[\"seq_length\"], params[\"batch_size\"])\n",
- "\n",
- " # Convert numpy arrays to PyTorch tensors\n",
- " x_batch = torch.tensor(x_batch, dtype=torch.long).to(device)\n",
- " y_batch = torch.tensor(y_batch, dtype=torch.long).to(device)\n",
- "\n",
- " # Take a train step\n",
- " loss = train_step(x_batch, y_batch)\n",
- "\n",
- " # Log the loss to the Comet interface\n",
- " experiment.log_metric(\"loss\", loss.item(), step=iter)\n",
- "\n",
- " # Update the progress bar and visualize within notebook\n",
- " history.append(loss.item())\n",
- " plotter.plot(history)\n",
- "\n",
- " # Save model checkpoint\n",
- " if iter % 100 == 0:\n",
- " torch.save(model.state_dict(), checkpoint_prefix)\n",
- "\n",
- "# Save the final trained model\n",
- "torch.save(model.state_dict(), checkpoint_prefix)\n",
- "experiment.flush()\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "kKkD5M6eoSiN"
- },
- "source": [
- "## 2.6 Generate music using the RNN model\n",
- "\n",
- "Now, we can use our trained RNN model to generate some music! When generating music, we'll have to feed the model some sort of seed to get it started (because it can't predict anything without something to start with!).\n",
- "\n",
- "Once we have a generated seed, we can then iteratively predict each successive character (remember, we are using the ABC representation for our music) using our trained RNN. More specifically, recall that our RNN outputs a `softmax` over possible successive characters. For inference, we iteratively sample from these distributions, and then use our samples to encode a generated song in the ABC format.\n",
- "\n",
- "Then, all we have to do is write it to a file and listen!"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "DjGz1tDkzf-u"
- },
- "source": [
- "### The prediction procedure\n",
- "\n",
- "Now, we're ready to write the code to generate text in the ABC music format:\n",
- "\n",
- "* Initialize a \"seed\" start string and the RNN state, and set the number of characters we want to generate.\n",
- "\n",
- "* Use the start string and the RNN state to obtain the probability distribution over the next predicted character.\n",
- "\n",
- "* Sample from multinomial distribution to calculate the index of the predicted character. This predicted character is then used as the next input to the model.\n",
- "\n",
- "* At each time step, the updated RNN state is fed back into the model, so that it now has more context in making the next prediction. After predicting the next character, the updated RNN states are again fed back into the model, which is how it learns sequence dependencies in the data, as it gets more information from the previous predictions.\n",
- "\n",
- "\n",
- "\n",
- "Complete and experiment with this code block (as well as some of the aspects of network definition and training!), and see how the model performs. How do songs generated after training with a small number of epochs compare to those generated after a longer duration of training?"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "WvuwZBX5Ogfd"
- },
- "outputs": [],
- "source": [
- "### Prediction of a generated song ###\n",
- "\n",
- "def generate_text(model, start_string, generation_length=1000):\n",
- " # Evaluation step (generating ABC text using the learned RNN model)\n",
- "\n",
- " '''TODO: convert the start string to numbers (vectorize)'''\n",
- " input_idx = [char2idx[s] for s in start_string] # TODO\n",
- " # input_idx = ['''TODO''']\n",
- " input_idx = torch.tensor([input_idx], dtype=torch.long).to(device)\n",
- "\n",
- " # Initialize the hidden state\n",
- " state = model.init_hidden(input_idx.size(0), device)\n",
- "\n",
- " # Empty string to store our results\n",
- " text_generated = []\n",
- " tqdm._instances.clear()\n",
- "\n",
- " for i in tqdm(range(generation_length)):\n",
- " '''TODO: evaluate the inputs and generate the next character predictions'''\n",
- " predictions, state = model(input_idx, state, return_state=True)\n",
- " # predictions, hidden_state = model('''TODO''', '''TODO''', return_state=True)\n",
- "\n",
- " # Remove the batch dimension\n",
- " predictions = predictions.squeeze(0)\n",
- "\n",
- " '''TODO: use a multinomial distribution to sample over the probabilities'''\n",
- " input_idx = torch.multinomial(torch.softmax(predictions, dim=-1), num_samples=1)\n",
- " # input_idx = torch.multinomial('''TODO''', dim=-1), num_samples=1)\n",
- "\n",
- " '''TODO: add the predicted character to the generated text!'''\n",
- " # Hint: consider what format the prediction is in vs. the output\n",
- " text_generated.append(idx2char[input_idx].item()) # TODO\n",
- " # text_generated.append('''TODO''')\n",
- "\n",
- "\n",
- " return (start_string + ''.join(text_generated))"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "ktovv0RFhrkn"
- },
- "outputs": [],
- "source": [
- "'''TODO: Use the model and the function defined above to generate ABC format text of length 1000!\n",
- " As you may notice, ABC files start with \"X\" - this may be a good start string.'''\n",
- "generated_text = generate_text(model, start_string=\"X\", generation_length=1000) # TODO\n",
- "# generated_text = generate_text('''TODO''', '''TODO''', '''TODO''')"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "AM2Uma_-yVIq"
- },
- "source": [
- "### Play back the generated music!\n",
- "\n",
- "We can now call a function to convert the ABC format text to an audio file, and then play that back to check out our generated music! Try training longer if the resulting song is not long enough, or re-generating the song!\n",
- "\n",
- "We will save the song to Comet -- you will be able to find your songs under the `Audio` and `Assets & Artifacts` pages in your Comet interface for the project. Note the [`log_asset()`](https://www.comet.com/docs/v2/api-and-sdk/python-sdk/reference/Experiment/#experimentlog_asset) documentation, where you will see how to specify file names and other parameters for saving your assets."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "LrOtG64bfLto"
- },
- "outputs": [],
- "source": [
- "### Play back generated songs ###\n",
- "\n",
- "generated_songs = mdl.lab1.extract_song_snippet(generated_text)\n",
- "\n",
- "for i, song in enumerate(generated_songs):\n",
- " # Synthesize the waveform from a song\n",
- " waveform = mdl.lab1.play_song(song)\n",
- "\n",
- " # If its a valid song (correct syntax), lets play it!\n",
- " if waveform:\n",
- " print(\"Generated song\", i)\n",
- " ipythondisplay.display(waveform)\n",
- "\n",
- " numeric_data = np.frombuffer(waveform.data, dtype=np.int16)\n",
- " wav_file_path = f\"output_{i}.wav\"\n",
- " write(wav_file_path, 88200, numeric_data)\n",
- "\n",
- " # save your song to the Comet interface -- you can access it there\n",
- " experiment.log_asset(wav_file_path)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "4353qSV76gnJ"
- },
- "outputs": [],
- "source": [
- "# when done, end the comet experiment\n",
- "experiment.end()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "HgVvcrYmSKGG"
- },
- "source": [
- "## 2.7 Experiment and **get awarded for the best songs**!\n",
- "\n",
- "Congrats on making your first sequence model in TensorFlow! It's a pretty big accomplishment, and hopefully you have some sweet tunes to show for it.\n",
- "\n",
- "Consider how you may improve your model and what seems to be most important in terms of performance. Here are some ideas to get you started:\n",
- "\n",
- "* How does the number of training epochs affect the performance?\n",
- "* What if you alter or augment the dataset?\n",
- "* Does the choice of start string significantly affect the result?\n",
- "\n",
- "Try to optimize your model and submit your best song! **Participants will be eligible for prizes during the January 2025 offering. To enter the competition, you must upload the following to [this submission link](https://www.dropbox.com/request/U8nND6enGjirujVZKX1n):**\n",
- "\n",
- "* a recording of your song;\n",
- "* iPython notebook with the code you used to generate the song;\n",
- "* a description and/or diagram of the architecture and hyperparameters you used -- if there are any additional or interesting modifications you made to the template code, please include these in your description.\n",
- "\n",
- "**Name your file in the following format: ``[FirstName]_[LastName]_RNNMusic``, followed by the file format (.zip, .mp4, .ipynb, .pdf, etc). ZIP files of all three components are preferred over individual files. If you submit individual files, you must name the individual files according to the above nomenclature.**\n",
- "\n",
- "You can also tweet us at [@MITDeepLearning](https://twitter.com/MITDeepLearning) a copy of the song (but this will not enter you into the competition)! See this example song generated by a previous student (credit Ana Heart): song from May 20, 2020.\n",
- "\n",
- "\n",
- "Have fun and happy listening!\n",
- "\n",
- "\n"
- ]
- }
- ],
- "metadata": {
- "accelerator": "GPU",
- "colab": {
- "collapsed_sections": [
- "uoJsVjtCMunI"
- ],
- "name": "PT_Part2_Music_Generation_Solution.ipynb",
- "provenance": []
- },
- "kernelspec": {
- "display_name": "Python 3",
- "name": "python3"
- },
- "language_info": {
- "codemirror_mode": {
- "name": "ipython",
- "version": 3
- },
- "file_extension": ".py",
- "mimetype": "text/x-python",
- "name": "python",
- "nbconvert_exporter": "python",
- "pygments_lexer": "ipython3",
- "version": "3.11.11"
- }
- },
- "nbformat": 4,
- "nbformat_minor": 0
-}
\ No newline at end of file
diff --git a/lab1/solutions/TF_Part1_Intro_Solution.ipynb b/lab1/solutions/TF_Part1_Intro_Solution.ipynb
deleted file mode 100644
index 61f502cd..00000000
--- a/lab1/solutions/TF_Part1_Intro_Solution.ipynb
+++ /dev/null
@@ -1,714 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "WBk0ZDWY-ff8"
- },
- "source": [
- "\n",
- "\n",
- "# Copyright Information\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "3eI6DUic-6jo"
- },
- "outputs": [],
- "source": [
- "# Copyright 2025 MIT Introduction to Deep Learning. All Rights Reserved.\n",
- "#\n",
- "# Licensed under the MIT License. You may not use this file except in compliance\n",
- "# with the License. Use and/or modification of this code outside of MIT Introduction\n",
- "# to Deep Learning must reference:\n",
- "#\n",
- "# © MIT Introduction to Deep Learning\n",
- "# http://introtodeeplearning.com\n",
- "#"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "57knM8jrYZ2t"
- },
- "source": [
- "# Lab 1: Intro to TensorFlow and Music Generation with RNNs\n",
- "\n",
- "In this lab, you'll get exposure to using TensorFlow and learn how it can be used for solving deep learning tasks. Go through the code and run each cell. Along the way, you'll encounter several ***TODO*** blocks -- follow the instructions to fill them out before running those cells and continuing.\n",
- "\n",
- "\n",
- "# Part 1: Intro to TensorFlow\n",
- "\n",
- "## 0.1 Install TensorFlow\n",
- "\n",
- "TensorFlow is a software library extensively used in machine learning. Here we'll learn how computations are represented and how to define a simple neural network in TensorFlow. For all the TensorFlow labs in Introduction to Deep Learning 2025, we'll be using TensorFlow 2, which affords great flexibility and the ability to imperatively execute operations, just like in Python. You'll notice that TensorFlow 2 is quite similar to Python in its syntax and imperative execution. Let's install TensorFlow and a couple of dependencies.\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "LkaimNJfYZ2w"
- },
- "outputs": [],
- "source": [
- "import tensorflow as tf\n",
- "\n",
- "# Download and import the MIT Introduction to Deep Learning package\n",
- "!pip install mitdeeplearning --quiet\n",
- "import mitdeeplearning as mdl\n",
- "\n",
- "import numpy as np\n",
- "import matplotlib.pyplot as plt"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "2QNMcdP4m3Vs"
- },
- "source": [
- "## 1.1 Why is TensorFlow called TensorFlow?\n",
- "\n",
- "TensorFlow is called 'TensorFlow' because it handles the flow (node/mathematical operation) of Tensors, which are data structures that you can think of as multi-dimensional arrays. Tensors are represented as n-dimensional arrays of base dataypes such as a string or integer -- they provide a way to generalize vectors and matrices to higher dimensions.\n",
- "\n",
- "The ```shape``` of a Tensor defines its number of dimensions and the size of each dimension. The ```rank``` of a Tensor provides the number of dimensions (n-dimensions) -- you can also think of this as the Tensor's order or degree.\n",
- "\n",
- "Let's first look at 0-d Tensors, of which a scalar is an example:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "tFxztZQInlAB"
- },
- "outputs": [],
- "source": [
- "sport = tf.constant(\"Tennis\", tf.string)\n",
- "number = tf.constant(1.41421356237, tf.float64)\n",
- "\n",
- "print(\"`sport` is a {}-d Tensor\".format(tf.rank(sport).numpy()))\n",
- "print(\"`number` is a {}-d Tensor\".format(tf.rank(number).numpy()))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "-dljcPUcoJZ6"
- },
- "source": [
- "Vectors and lists can be used to create 1-d Tensors:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "oaHXABe8oPcO"
- },
- "outputs": [],
- "source": [
- "sports = tf.constant([\"Tennis\", \"Basketball\"], tf.string)\n",
- "numbers = tf.constant([3.141592, 1.414213, 2.71821], tf.float64)\n",
- "\n",
- "print(\"`sports` is a {}-d Tensor with shape: {}\".format(tf.rank(sports).numpy(), tf.shape(sports)))\n",
- "print(\"`numbers` is a {}-d Tensor with shape: {}\".format(tf.rank(numbers).numpy(), tf.shape(numbers)))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "gvffwkvtodLP"
- },
- "source": [
- "Next we consider creating 2-d (i.e., matrices) and higher-rank Tensors. For examples, in future labs involving image processing and computer vision, we will use 4-d Tensors. Here the dimensions correspond to the number of example images in our batch, image height, image width, and the number of color channels."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "tFeBBe1IouS3"
- },
- "outputs": [],
- "source": [
- "### Defining higher-order Tensors ###\n",
- "\n",
- "'''TODO: Define a 2-d Tensor'''\n",
- "matrix = tf.constant([[1.0, 2.0, 3.0, 4.0], [5.0, 6.0, 7.0, 8.0]]) # TODO\n",
- "# matrix = # TODO\n",
- "\n",
- "assert isinstance(matrix, tf.Tensor), \"matrix must be a tf Tensor object\"\n",
- "assert tf.rank(matrix).numpy() == 2"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "Zv1fTn_Ya_cz"
- },
- "outputs": [],
- "source": [
- "'''TODO: Define a 4-d Tensor.'''\n",
- "# Use tf.zeros to initialize a 4-d Tensor of zeros with size 10 x 256 x 256 x 3.\n",
- "# You can think of this as 10 images where each image is RGB 256 x 256.\n",
- "images = tf.zeros([10, 256, 256, 3]) # TODO\n",
- "# images = # TODO\n",
- "\n",
- "assert isinstance(images, tf.Tensor), \"matrix must be a tf Tensor object\"\n",
- "assert tf.rank(images).numpy() == 4, \"matrix must be of rank 4\"\n",
- "assert tf.shape(images).numpy().tolist() == [10, 256, 256, 3], \"matrix is incorrect shape\""
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "wkaCDOGapMyl"
- },
- "source": [
- "As you have seen, the ```shape``` of a Tensor provides the number of elements in each Tensor dimension. The ```shape``` is quite useful, and we'll use it often. You can also use slicing to access subtensors within a higher-rank Tensor:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "FhaufyObuLEG"
- },
- "outputs": [],
- "source": [
- "row_vector = matrix[1]\n",
- "column_vector = matrix[:,1]\n",
- "scalar = matrix[0, 1]\n",
- "\n",
- "print(\"`row_vector`: {}\".format(row_vector.numpy()))\n",
- "print(\"`column_vector`: {}\".format(column_vector.numpy()))\n",
- "print(\"`scalar`: {}\".format(scalar.numpy()))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "iD3VO-LZYZ2z"
- },
- "source": [
- "## 1.2 Computations on Tensors\n",
- "\n",
- "A convenient way to think about and visualize computations in TensorFlow is in terms of graphs. We can define this graph in terms of Tensors, which hold data, and the mathematical operations that act on these Tensors in some order. Let's look at a simple example, and define this computation using TensorFlow:\n",
- "\n",
- "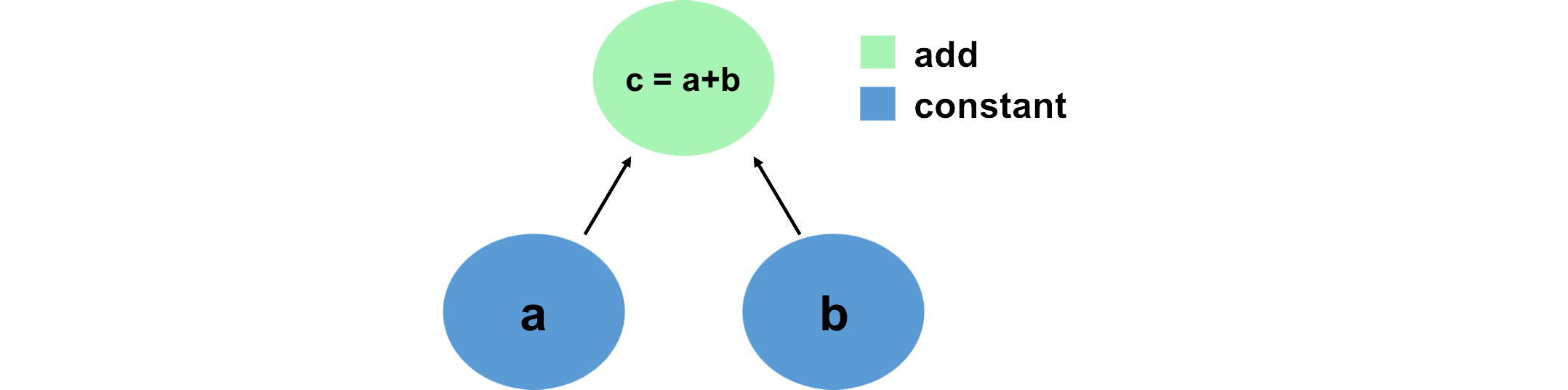"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "X_YJrZsxYZ2z"
- },
- "outputs": [],
- "source": [
- "# Create the nodes in the graph, and initialize values\n",
- "a = tf.constant(15)\n",
- "b = tf.constant(61)\n",
- "\n",
- "# Add them!\n",
- "c1 = tf.add(a,b)\n",
- "c2 = a + b # TensorFlow overrides the \"+\" operation so that it is able to act on Tensors\n",
- "print(c1)\n",
- "print(c2)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Mbfv_QOiYZ23"
- },
- "source": [
- "Notice how we've created a computation graph consisting of TensorFlow operations, and how the output is a Tensor with value 76 -- we've just created a computation graph consisting of operations, and it's executed them and given us back the result.\n",
- "\n",
- "Now let's consider a slightly more complicated example:\n",
- "\n",
- "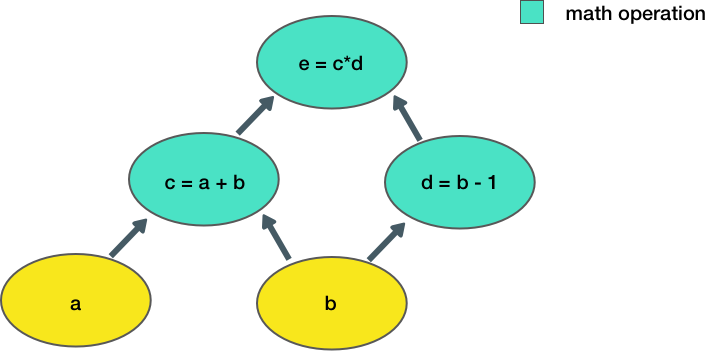\n",
- "\n",
- "Here, we take two inputs, `a, b`, and compute an output `e`. Each node in the graph represents an operation that takes some input, does some computation, and passes its output to another node.\n",
- "\n",
- "Let's define a simple function in TensorFlow to construct this computation function:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "PJnfzpWyYZ23",
- "scrolled": true
- },
- "outputs": [],
- "source": [
- "### Defining Tensor computations ###\n",
- "\n",
- "# Construct a simple computation function\n",
- "def func(a,b):\n",
- " '''TODO: Define the operation for c, d, e (use tf.add, tf.subtract, tf.multiply).'''\n",
- " c = tf.add(a, b)\n",
- " # c = # TODO\n",
- " d = tf.subtract(b, 1)\n",
- " # d = # TODO\n",
- " e = tf.multiply(c, d)\n",
- " # e = # TODO\n",
- " return e"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "AwrRfDMS2-oy"
- },
- "source": [
- "Now, we can call this function to execute the computation graph given some inputs `a,b`:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "pnwsf8w2uF7p"
- },
- "outputs": [],
- "source": [
- "# Consider example values for a,b\n",
- "a, b = 1.5, 2.5\n",
- "# Execute the computation\n",
- "e_out = func(a,b)\n",
- "print(e_out)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "6HqgUIUhYZ29"
- },
- "source": [
- "Notice how our output is a Tensor with value defined by the output of the computation, and that the output has no shape as it is a single scalar value."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "1h4o9Bb0YZ29"
- },
- "source": [
- "## 1.3 Neural networks in TensorFlow\n",
- "We can also define neural networks in TensorFlow. TensorFlow uses a high-level API called [Keras](https://www.tensorflow.org/guide/keras) that provides a powerful, intuitive framework for building and training deep learning models.\n",
- "\n",
- "Let's first consider the example of a simple perceptron defined by just one dense layer: $ y = \\sigma(Wx + b)$, where $W$ represents a matrix of weights, $b$ is a bias, $x$ is the input, $\\sigma$ is the sigmoid activation function, and $y$ is the output. We can also visualize this operation using a graph:\n",
- "\n",
- "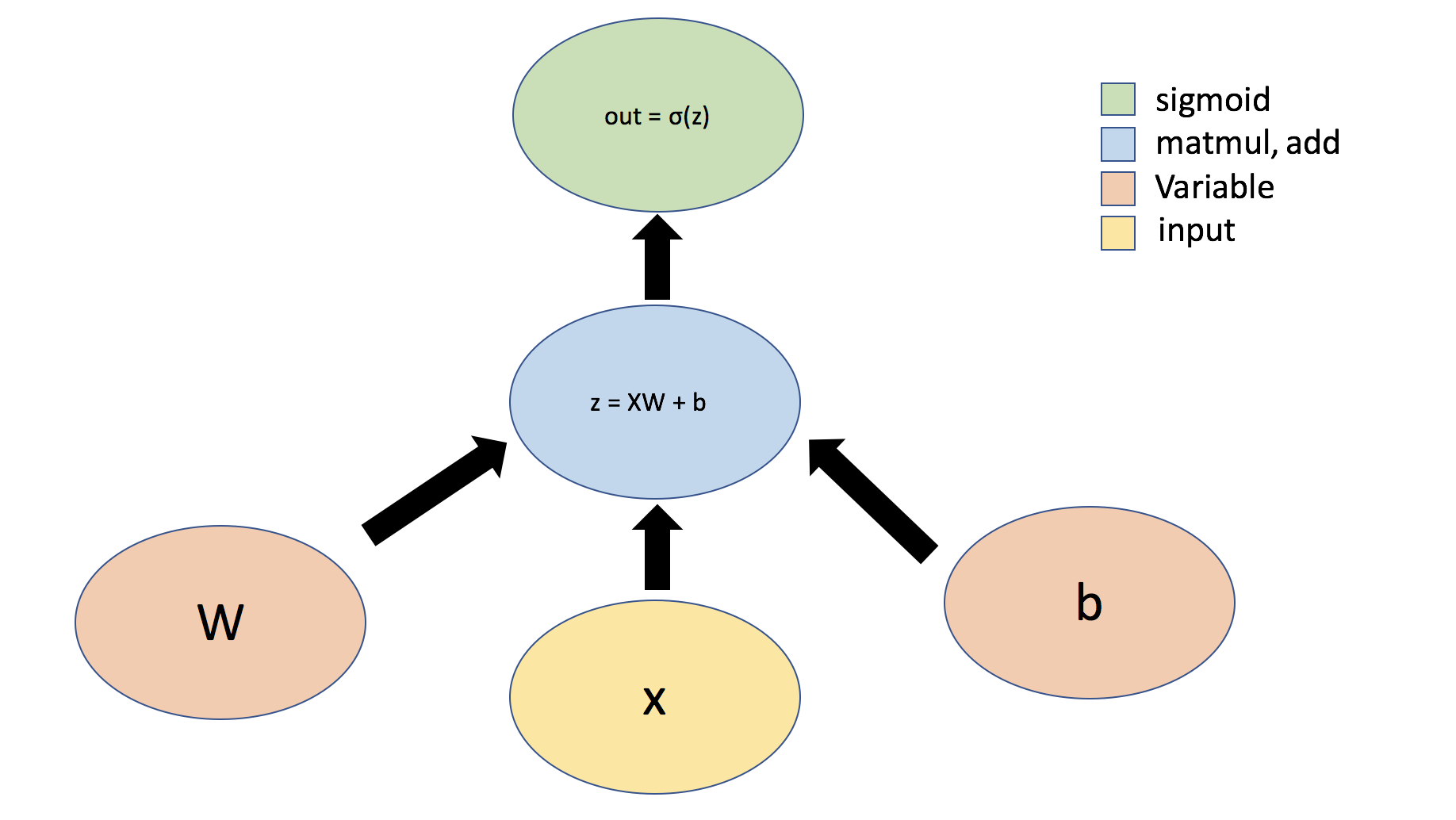\n",
- "\n",
- "Tensors can flow through abstract types called [```Layers```](https://www.tensorflow.org/api_docs/python/tf/keras/layers/Layer) -- the building blocks of neural networks. ```Layers``` implement common neural networks operations, and are used to update weights, compute losses, and define inter-layer connectivity. We will first define a ```Layer``` to implement the simple perceptron defined above."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "HutbJk-1kHPh"
- },
- "outputs": [],
- "source": [
- "### Defining a network Layer ###\n",
- "\n",
- "# n_output_nodes: number of output nodes\n",
- "# input_shape: shape of the input\n",
- "# x: input to the layer\n",
- "\n",
- "class OurDenseLayer(tf.keras.layers.Layer):\n",
- " def __init__(self, n_output_nodes):\n",
- " super(OurDenseLayer, self).__init__()\n",
- " self.n_output_nodes = n_output_nodes\n",
- "\n",
- " def build(self, input_shape):\n",
- " d = int(input_shape[-1])\n",
- " # Define and initialize parameters: a weight matrix W and bias b\n",
- " # Note that parameter initialization is random!\n",
- " self.W = self.add_weight(\"weight\", shape=[d, self.n_output_nodes]) # note the dimensionality\n",
- " self.b = self.add_weight(\"bias\", shape=[1, self.n_output_nodes]) # note the dimensionality\n",
- "\n",
- " def call(self, x):\n",
- " '''TODO: define the operation for z (hint: use tf.matmul)'''\n",
- " z = tf.matmul(x, self.W) + self.b # TODO\n",
- " # z = # TODO\n",
- "\n",
- " '''TODO: define the operation for out (hint: use tf.sigmoid)'''\n",
- " y = tf.sigmoid(z) # TODO\n",
- " # y = # TODO\n",
- " return y\n",
- "\n",
- "# Since layer parameters are initialized randomly, we will set a random seed for reproducibility\n",
- "tf.keras.utils.set_random_seed(1)\n",
- "layer = OurDenseLayer(3)\n",
- "layer.build((1,2))\n",
- "x_input = tf.constant([[1,2.]], shape=(1,2))\n",
- "y = layer.call(x_input)\n",
- "\n",
- "# test the output!\n",
- "print(y.numpy())\n",
- "mdl.lab1.test_custom_dense_layer_output(y)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Jt1FgM7qYZ3D"
- },
- "source": [
- "Conveniently, TensorFlow has defined a number of ```Layers``` that are commonly used in neural networks, for example a [```Dense```](https://www.tensorflow.org/api_docs/python/tf/keras/layers/Dense?version=stable). Now, instead of using a single ```Layer``` to define our simple neural network, we'll use the [`Sequential`](https://www.tensorflow.org/versions/r2.0/api_docs/python/tf/keras/Sequential) model from Keras and a single [`Dense` ](https://www.tensorflow.org/versions/r2.0/api_docs/python/tf/keras/layers/Dense) layer to define our network. With the `Sequential` API, you can readily create neural networks by stacking together layers like building blocks."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "7WXTpmoL6TDz"
- },
- "outputs": [],
- "source": [
- "### Defining a neural network using the Sequential API ###\n",
- "\n",
- "# Import relevant packages\n",
- "from tensorflow.keras import Sequential\n",
- "from tensorflow.keras.layers import Dense\n",
- "\n",
- "# Define the number of outputs\n",
- "n_output_nodes = 3\n",
- "\n",
- "# First define the model\n",
- "model = Sequential()\n",
- "\n",
- "'''TODO: Define a dense (fully connected) layer to compute z'''\n",
- "# Remember: dense layers are defined by the parameters W and b!\n",
- "# You can read more about the initialization of W and b in the TF documentation :)\n",
- "# https://www.tensorflow.org/api_docs/python/tf/keras/layers/Dense?version=stable\n",
- "dense_layer = Dense(n_output_nodes, activation='sigmoid') # TODO\n",
- "# dense_layer = # TODO\n",
- "\n",
- "# Add the dense layer to the model\n",
- "model.add(dense_layer)\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "HDGcwYfUyR-U"
- },
- "source": [
- "That's it! We've defined our model using the Sequential API. Now, we can test it out using an example input:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "sg23OczByRDb"
- },
- "outputs": [],
- "source": [
- "# Test model with example input\n",
- "x_input = tf.constant([[1,2.]], shape=(1,2))\n",
- "\n",
- "'''TODO: feed input into the model and predict the output!'''\n",
- "model_output = model(x_input).numpy()\n",
- "# model_output = # TODO\n",
- "print(model_output)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "596NvsOOtr9F"
- },
- "source": [
- "In addition to defining models using the `Sequential` API, we can also define neural networks by directly subclassing the [`Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model?version=stable) class, which groups layers together to enable model training and inference. The `Model` class captures what we refer to as a \"model\" or as a \"network\". Using Subclassing, we can create a class for our model, and then define the forward pass through the network using the `call` function. Subclassing affords the flexibility to define custom layers, custom training loops, custom activation functions, and custom models. Let's define the same neural network as above now using Subclassing rather than the `Sequential` model."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "K4aCflPVyViD"
- },
- "outputs": [],
- "source": [
- "### Defining a model using subclassing ###\n",
- "\n",
- "from tensorflow.keras import Model\n",
- "from tensorflow.keras.layers import Dense\n",
- "\n",
- "class SubclassModel(tf.keras.Model):\n",
- "\n",
- " # In __init__, we define the Model's layers\n",
- " def __init__(self, n_output_nodes):\n",
- " super(SubclassModel, self).__init__()\n",
- " '''TODO: Our model consists of a single Dense layer. Define this layer.'''\n",
- " self.dense_layer = Dense(n_output_nodes, activation='sigmoid') # TODO\n",
- " # self.dense_layer = '''TODO: Dense Layer'''\n",
- "\n",
- " # In the call function, we define the Model's forward pass.\n",
- " def call(self, inputs):\n",
- " return self.dense_layer(inputs)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "U0-lwHDk4irB"
- },
- "source": [
- "Just like the model we built using the `Sequential` API, let's test out our `SubclassModel` using an example input.\n",
- "\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "LhB34RA-4gXb"
- },
- "outputs": [],
- "source": [
- "n_output_nodes = 3\n",
- "model = SubclassModel(n_output_nodes)\n",
- "\n",
- "x_input = tf.constant([[1,2.]], shape=(1,2))\n",
- "\n",
- "print(model.call(x_input))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "HTIFMJLAzsyE"
- },
- "source": [
- "Importantly, Subclassing affords us a lot of flexibility to define custom models. For example, we can use boolean arguments in the `call` function to specify different network behaviors, for example different behaviors during training and inference. Let's suppose under some instances we want our network to simply output the input, without any perturbation. We define a boolean argument `isidentity` to control this behavior:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "P7jzGX5D1xT5"
- },
- "outputs": [],
- "source": [
- "### Defining a model using subclassing and specifying custom behavior ###\n",
- "\n",
- "from tensorflow.keras import Model\n",
- "from tensorflow.keras.layers import Dense\n",
- "\n",
- "class IdentityModel(tf.keras.Model):\n",
- "\n",
- " # As before, in __init__ we define the Model's layers\n",
- " # Since our desired behavior involves the forward pass, this part is unchanged\n",
- " def __init__(self, n_output_nodes):\n",
- " super(IdentityModel, self).__init__()\n",
- " self.dense_layer = tf.keras.layers.Dense(n_output_nodes, activation='sigmoid')\n",
- "\n",
- " '''TODO: Implement the behavior where the network outputs the input, unchanged, under control of the isidentity argument.'''\n",
- " def call(self, inputs, isidentity=False):\n",
- " x = self.dense_layer(inputs)\n",
- " if isidentity: # TODO\n",
- " return inputs # TODO\n",
- " return x\n",
- "\n",
- " # def call(self, inputs, isidentity=False):\n",
- " # TODO"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Ku4rcCGx5T3y"
- },
- "source": [
- "Let's test this behavior:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "NzC0mgbk5dp2"
- },
- "outputs": [],
- "source": [
- "n_output_nodes = 3\n",
- "model = IdentityModel(n_output_nodes)\n",
- "\n",
- "x_input = tf.constant([[1,2.]], shape=(1,2))\n",
- "'''TODO: pass the input into the model and call with and without the input identity option.'''\n",
- "out_activate = model.call(x_input) # TODO\n",
- "# out_activate = # TODO\n",
- "out_identity = model.call(x_input, isidentity=True) # TODO\n",
- "# out_identity = # TODO\n",
- "\n",
- "print(\"Network output with activation: {}; network identity output: {}\".format(out_activate.numpy(), out_identity.numpy()))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "7V1dEqdk6VI5"
- },
- "source": [
- "Now that we have learned how to define `Layers` as well as neural networks in TensorFlow using both the `Sequential` and Subclassing APIs, we're ready to turn our attention to how to actually implement network training with backpropagation."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "dQwDhKn8kbO2"
- },
- "source": [
- "## 1.4 Automatic differentiation in TensorFlow\n",
- "\n",
- "[Automatic differentiation](https://en.wikipedia.org/wiki/Automatic_differentiation)\n",
- "is one of the most important parts of TensorFlow and is the backbone of training with\n",
- "[backpropagation](https://en.wikipedia.org/wiki/Backpropagation). We will use the TensorFlow GradientTape [`tf.GradientTape`](https://www.tensorflow.org/api_docs/python/tf/GradientTape?version=stable) to trace operations for computing gradients later.\n",
- "\n",
- "When a forward pass is made through the network, all forward-pass operations get recorded to a \"tape\"; then, to compute the gradient, the tape is played backwards. By default, the tape is discarded after it is played backwards; this means that a particular `tf.GradientTape` can only\n",
- "compute one gradient, and subsequent calls throw a runtime error. However, we can compute multiple gradients over the same computation by creating a ```persistent``` gradient tape.\n",
- "\n",
- "First, we will look at how we can compute gradients using GradientTape and access them for computation. We define the simple function $ y = x^2$ and compute the gradient:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "tdkqk8pw5yJM"
- },
- "outputs": [],
- "source": [
- "### Gradient computation with GradientTape ###\n",
- "\n",
- "# y = x^2\n",
- "# Example: x = 3.0\n",
- "x = tf.Variable(3.0)\n",
- "\n",
- "# Initiate the gradient tape\n",
- "with tf.GradientTape() as tape:\n",
- " # Define the function\n",
- " y = x * x\n",
- "# Access the gradient -- derivative of y with respect to x\n",
- "dy_dx = tape.gradient(y, x)\n",
- "\n",
- "assert dy_dx.numpy() == 6.0"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "JhU5metS5xF3"
- },
- "source": [
- "In training neural networks, we use differentiation and stochastic gradient descent (SGD) to optimize a loss function. Now that we have a sense of how `GradientTape` can be used to compute and access derivatives, we will look at an example where we use automatic differentiation and SGD to find the minimum of $L=(x-x_f)^2$. Here $x_f$ is a variable for a desired value we are trying to optimize for; $L$ represents a loss that we are trying to minimize. While we can clearly solve this problem analytically ($x_{min}=x_f$), considering how we can compute this using `GradientTape` sets us up nicely for future labs where we use gradient descent to optimize entire neural network losses."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "attributes": {
- "classes": [
- "py"
- ],
- "id": ""
- },
- "id": "7g1yWiSXqEf-"
- },
- "outputs": [],
- "source": [
- "### Function minimization with automatic differentiation and SGD ###\n",
- "\n",
- "# Initialize a random value for our initial x\n",
- "x = tf.Variable([tf.random.normal([1])])\n",
- "print(\"Initializing x={}\".format(x.numpy()))\n",
- "\n",
- "learning_rate = 1e-2 # learning rate for SGD\n",
- "history = []\n",
- "# Define the target value\n",
- "x_f = 4\n",
- "\n",
- "# We will run SGD for a number of iterations. At each iteration, we compute the loss,\n",
- "# compute the derivative of the loss with respect to x, and perform the SGD update.\n",
- "for i in range(500):\n",
- " with tf.GradientTape() as tape:\n",
- " '''TODO: define the loss as described above'''\n",
- " loss = (x - x_f)**2 # \"forward pass\": record the current loss on the tape\n",
- " # loss = # TODO\n",
- "\n",
- " # loss minimization using gradient tape\n",
- " grad = tape.gradient(loss, x) # compute the derivative of the loss with respect to x\n",
- " new_x = x - learning_rate*grad # sgd update\n",
- " x.assign(new_x) # update the value of x\n",
- " history.append(x.numpy()[0])\n",
- "\n",
- "# Plot the evolution of x as we optimize towards x_f!\n",
- "plt.plot(history)\n",
- "plt.plot([0, 500],[x_f,x_f])\n",
- "plt.legend(('Predicted', 'True'))\n",
- "plt.xlabel('Iteration')\n",
- "plt.ylabel('x value')"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "pC7czCwk3ceH"
- },
- "source": [
- "`GradientTape` provides an extremely flexible framework for automatic differentiation. In order to back propagate errors through a neural network, we track forward passes on the Tape, use this information to determine the gradients, and then use these gradients for optimization using SGD.\n"
- ]
- }
- ],
- "metadata": {
- "accelerator": "GPU",
- "colab": {
- "collapsed_sections": [
- "WBk0ZDWY-ff8"
- ],
- "name": "TF_Part1_Intro_Solution.ipynb",
- "provenance": []
- },
- "kernelspec": {
- "display_name": "Python 3",
- "language": "python",
- "name": "python3"
- },
- "language_info": {
- "name": "python",
- "version": "3.9.6"
- },
- "vscode": {
- "interpreter": {
- "hash": "31f2aee4e71d21fbe5cf8b01ff0e069b9275f58929596ceb00d14d90e3e16cd6"
- }
- }
- },
- "nbformat": 4,
- "nbformat_minor": 0
-}
diff --git a/lab1/solutions/TF_Part2_Music_Generation_Solution.ipynb b/lab1/solutions/TF_Part2_Music_Generation_Solution.ipynb
deleted file mode 100644
index df0ded1c..00000000
--- a/lab1/solutions/TF_Part2_Music_Generation_Solution.ipynb
+++ /dev/null
@@ -1,1059 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "uoJsVjtCMunI"
- },
- "source": [
- "\n",
- "\n",
- "# Copyright Information"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "bUik05YqMyCH"
- },
- "outputs": [],
- "source": [
- "# Copyright 2025 MIT Introduction to Deep Learning. All Rights Reserved.\n",
- "#\n",
- "# Licensed under the MIT License. You may not use this file except in compliance\n",
- "# with the License. Use and/or modification of this code outside of MIT Introduction\n",
- "# to Deep Learning must reference:\n",
- "#\n",
- "# © MIT Introduction to Deep Learning\n",
- "# http://introtodeeplearning.com\n",
- "#"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "O-97SDET3JG-"
- },
- "source": [
- "# Lab 1: Intro to TensorFlow and Music Generation with RNNs\n",
- "\n",
- "# Part 2: Music Generation with RNNs\n",
- "\n",
- "In this portion of the lab, we will explore building a Recurrent Neural Network (RNN) for music generation. We will train a model to learn the patterns in raw sheet music in [ABC notation](https://en.wikipedia.org/wiki/ABC_notation) and then use this model to generate new music."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "rsvlBQYCrE4I"
- },
- "source": [
- "## 2.1 Dependencies\n",
- "First, let's download the course repository, install dependencies, and import the relevant packages we'll need for this lab.\n",
- "\n",
- "We will be using [Comet ML](https://www.comet.com/docs/v2/) to track our model development and training runs. First, sign up for a Comet account [at this link](https://www.comet.com/signup?utm_source=mit_dl&utm_medium=partner&utm_content=github\n",
- ") (you can use your Google or Github account). This will generate a personal API Key, which you can find either in the first 'Get Started with Comet' page, under your account settings, or by pressing the '?' in the top right corner and then 'Quickstart Guide'. Enter this API key as the global variable `COMET_API_KEY`."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "riVZCVK65QTH"
- },
- "outputs": [],
- "source": [
- "!pip install comet_ml > /dev/null 2>&1\n",
- "import comet_ml\n",
- "# TODO: ENTER YOUR API KEY HERE!! instructions above\n",
- "COMET_API_KEY = \"\"\n",
- "\n",
- "# Import Tensorflow 2.0\n",
- "import tensorflow as tf\n",
- "\n",
- "# Download and import the MIT Introduction to Deep Learning package\n",
- "!pip install mitdeeplearning --quiet\n",
- "import mitdeeplearning as mdl\n",
- "\n",
- "# Import all remaining packages\n",
- "import numpy as np\n",
- "import os\n",
- "import time\n",
- "import functools\n",
- "from IPython import display as ipythondisplay\n",
- "from tqdm import tqdm\n",
- "from scipy.io.wavfile import write\n",
- "!apt-get install abcmidi timidity > /dev/null 2>&1\n",
- "\n",
- "\n",
- "# Check that we are using a GPU, if not switch runtimes\n",
- "# using Runtime > Change Runtime Type > GPU\n",
- "# assert len(tf.config.list_physical_devices('GPU')) > 0\n",
- "# assert COMET_API_KEY != \"\", \"Please insert your Comet API Key\""
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "_ajvp0No4qDm"
- },
- "source": [
- "## 2.2 Dataset\n",
- "\n",
- "\n",
- "\n",
- "We've gathered a dataset of thousands of Irish folk songs, represented in the ABC notation. Let's download the dataset and inspect it:\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "P7dFnP5q3Jve"
- },
- "outputs": [],
- "source": [
- "# Download the dataset\n",
- "songs = mdl.lab1.load_training_data()\n",
- "\n",
- "# Print one of the songs to inspect it in greater detail!\n",
- "example_song = songs[0]\n",
- "print(\"\\nExample song: \")\n",
- "print(example_song)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "hKF3EHJlCAj2"
- },
- "source": [
- "We can easily convert a song in ABC notation to an audio waveform and play it back. Be patient for this conversion to run, it can take some time."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "11toYzhEEKDz"
- },
- "outputs": [],
- "source": [
- "# Convert the ABC notation to audio file and listen to it\n",
- "mdl.lab1.play_song(example_song)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "7vH24yyquwKQ"
- },
- "source": [
- "One important thing to think about is that this notation of music does not simply contain information on the notes being played, but additionally there is meta information such as the song title, key, and tempo. How does the number of different characters that are present in the text file impact the complexity of the learning problem? This will become important soon, when we generate a numerical representation for the text data."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "IlCgQBRVymwR"
- },
- "outputs": [],
- "source": [
- "# Join our list of song strings into a single string containing all songs\n",
- "songs_joined = \"\\n\\n\".join(songs)\n",
- "\n",
- "# Find all unique characters in the joined string\n",
- "vocab = sorted(set(songs_joined))\n",
- "print(\"There are\", len(vocab), \"unique characters in the dataset\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "rNnrKn_lL-IJ"
- },
- "source": [
- "## 2.3 Process the dataset for the learning task\n",
- "\n",
- "Let's take a step back and consider our prediction task. We're trying to train a RNN model to learn patterns in ABC music, and then use this model to generate (i.e., predict) a new piece of music based on this learned information.\n",
- "\n",
- "Breaking this down, what we're really asking the model is: given a character, or a sequence of characters, what is the most probable next character? We'll train the model to perform this task.\n",
- "\n",
- "To achieve this, we will input a sequence of characters to the model, and train the model to predict the output, that is, the following character at each time step. RNNs maintain an internal state that depends on previously seen elements, so information about all characters seen up until a given moment will be taken into account in generating the prediction."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "LFjSVAlWzf-N"
- },
- "source": [
- "### Vectorize the text\n",
- "\n",
- "Before we begin training our RNN model, we'll need to create a numerical representation of our text-based dataset. To do this, we'll generate two lookup tables: one that maps characters to numbers, and a second that maps numbers back to characters. Recall that we just identified the unique characters present in the text."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "IalZLbvOzf-F"
- },
- "outputs": [],
- "source": [
- "### Define numerical representation of text ###\n",
- "\n",
- "# Create a mapping from character to unique index.\n",
- "# For example, to get the index of the character \"d\",\n",
- "# we can evaluate `char2idx[\"d\"]`.\n",
- "char2idx = {u:i for i, u in enumerate(vocab)}\n",
- "\n",
- "# Create a mapping from indices to characters. This is\n",
- "# the inverse of char2idx and allows us to convert back\n",
- "# from unique index to the character in our vocabulary.\n",
- "idx2char = np.array(vocab)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "tZfqhkYCymwX"
- },
- "source": [
- "This gives us an integer representation for each character. Observe that the unique characters (i.e., our vocabulary) in the text are mapped as indices from 0 to `len(unique)`. Let's take a peek at this numerical representation of our dataset:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "FYyNlCNXymwY"
- },
- "outputs": [],
- "source": [
- "print('{')\n",
- "for char,_ in zip(char2idx, range(20)):\n",
- " print(' {:4s}: {:3d},'.format(repr(char), char2idx[char]))\n",
- "print(' ...\\n}')"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "g-LnKyu4dczc"
- },
- "outputs": [],
- "source": [
- "### Vectorize the songs string ###\n",
- "\n",
- "'''TODO: Write a function to convert the all songs string to a vectorized\n",
- " (i.e., numeric) representation. Use the appropriate mapping\n",
- " above to convert from vocab characters to the corresponding indices.\n",
- "\n",
- " NOTE: the output of the `vectorize_string` function\n",
- " should be a np.array with `N` elements, where `N` is\n",
- " the number of characters in the input string\n",
- "'''\n",
- "def vectorize_string(string):\n",
- " vectorized_output = np.array([char2idx[char] for char in string])\n",
- " return vectorized_output\n",
- "\n",
- "# def vectorize_string(string):\n",
- " # TODO\n",
- "\n",
- "vectorized_songs = vectorize_string(songs_joined)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "IqxpSuZ1w-ub"
- },
- "source": [
- "We can also look at how the first part of the text is mapped to an integer representation:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "l1VKcQHcymwb"
- },
- "outputs": [],
- "source": [
- "print ('{} ---- characters mapped to int ----> {}'.format(repr(songs_joined[:10]), vectorized_songs[:10]))\n",
- "# check that vectorized_songs is a numpy array\n",
- "assert isinstance(vectorized_songs, np.ndarray), \"returned result should be a numpy array\""
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "hgsVvVxnymwf"
- },
- "source": [
- "### Create training examples and targets\n",
- "\n",
- "Our next step is to actually divide the text into example sequences that we'll use during training. Each input sequence that we feed into our RNN will contain `seq_length` characters from the text. We'll also need to define a target sequence for each input sequence, which will be used in training the RNN to predict the next character. For each input, the corresponding target will contain the same length of text, except shifted one character to the right.\n",
- "\n",
- "To do this, we'll break the text into chunks of `seq_length+1`. Suppose `seq_length` is 4 and our text is \"Hello\". Then, our input sequence is \"Hell\" and the target sequence is \"ello\".\n",
- "\n",
- "The batch method will then let us convert this stream of character indices to sequences of the desired size."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "LF-N8F7BoDRi"
- },
- "outputs": [],
- "source": [
- "### Batch definition to create training examples ###\n",
- "\n",
- "def get_batch(vectorized_songs, seq_length, batch_size):\n",
- " # the length of the vectorized songs string\n",
- " n = vectorized_songs.shape[0] - 1\n",
- " # randomly choose the starting indices for the examples in the training batch\n",
- " idx = np.random.choice(n-seq_length, batch_size)\n",
- "\n",
- " '''TODO: construct a list of input sequences for the training batch'''\n",
- " input_batch = [vectorized_songs[i : i+seq_length] for i in idx]\n",
- " # input_batch = # TODO\n",
- " '''TODO: construct a list of output sequences for the training batch'''\n",
- " output_batch = [vectorized_songs[i+1 : i+seq_length+1] for i in idx]\n",
- " # output_batch = # TODO\n",
- "\n",
- " # x_batch, y_batch provide the true inputs and targets for network training\n",
- " x_batch = np.reshape(input_batch, [batch_size, seq_length])\n",
- " y_batch = np.reshape(output_batch, [batch_size, seq_length])\n",
- " return x_batch, y_batch\n",
- "\n",
- "\n",
- "# Perform some simple tests to make sure your batch function is working properly!\n",
- "test_args = (vectorized_songs, 10, 2)\n",
- "if not mdl.lab1.test_batch_func_types(get_batch, test_args) or \\\n",
- " not mdl.lab1.test_batch_func_shapes(get_batch, test_args) or \\\n",
- " not mdl.lab1.test_batch_func_next_step(get_batch, test_args):\n",
- " print(\"======\\n[FAIL] could not pass tests\")\n",
- "else:\n",
- " print(\"======\\n[PASS] passed all tests!\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "_33OHL3b84i0"
- },
- "source": [
- "For each of these vectors, each index is processed at a single time step. So, for the input at time step 0, the model receives the index for the first character in the sequence, and tries to predict the index of the next character. At the next timestep, it does the same thing, but the RNN considers the information from the previous step, i.e., its updated state, in addition to the current input.\n",
- "\n",
- "We can make this concrete by taking a look at how this works over the first several characters in our text:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "0eBu9WZG84i0"
- },
- "outputs": [],
- "source": [
- "x_batch, y_batch = get_batch(vectorized_songs, seq_length=5, batch_size=1)\n",
- "\n",
- "for i, (input_idx, target_idx) in enumerate(zip(np.squeeze(x_batch), np.squeeze(y_batch))):\n",
- " print(\"Step {:3d}\".format(i))\n",
- " print(\" input: {} ({:s})\".format(input_idx, repr(idx2char[input_idx])))\n",
- " print(\" expected output: {} ({:s})\".format(target_idx, repr(idx2char[target_idx])))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "r6oUuElIMgVx"
- },
- "source": [
- "## 2.4 The Recurrent Neural Network (RNN) model"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "m8gPwEjRzf-Z"
- },
- "source": [
- "Now we're ready to define and train a RNN model on our ABC music dataset, and then use that trained model to generate a new song. We'll train our RNN using batches of song snippets from our dataset, which we generated in the previous section.\n",
- "\n",
- "The model is based off the LSTM architecture, where we use a state vector to maintain information about the temporal relationships between consecutive characters. The final output of the LSTM is then fed into a fully connected [`Dense`](https://www.tensorflow.org/api_docs/python/tf/keras/layers/Dense) layer where we'll output a softmax over each character in the vocabulary, and then sample from this distribution to predict the next character.\n",
- "\n",
- "As we introduced in the first portion of this lab, we'll be using the Keras API, specifically, [`tf.keras.Sequential`](https://www.tensorflow.org/api_docs/python/tf/keras/models/Sequential), to define the model. Three layers are used to define the model:\n",
- "\n",
- "* [`tf.keras.layers.Embedding`](https://www.tensorflow.org/api_docs/python/tf/keras/layers/Embedding): This is the input layer, consisting of a trainable lookup table that maps the numbers of each character to a vector with `embedding_dim` dimensions.\n",
- "* [`tf.keras.layers.LSTM`](https://www.tensorflow.org/api_docs/python/tf/keras/layers/LSTM): Our LSTM network, with size `units=rnn_units`.\n",
- "* [`tf.keras.layers.Dense`](https://www.tensorflow.org/api_docs/python/tf/keras/layers/Dense): The output layer, with `vocab_size` outputs.\n",
- "\n",
- "\n",
- ""
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "rlaOqndqBmJo"
- },
- "source": [
- "### Define the RNN model\n",
- "\n",
- "Now, we will define a function that we will use to actually build the model."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "8DsWzojvkbc7"
- },
- "outputs": [],
- "source": [
- "def LSTM(rnn_units):\n",
- " return tf.keras.layers.LSTM(\n",
- " rnn_units,\n",
- " return_sequences=True,\n",
- " recurrent_initializer='glorot_uniform',\n",
- " recurrent_activation='sigmoid',\n",
- " stateful=True,\n",
- " )"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "IbWU4dMJmMvq"
- },
- "source": [
- "The time has come! Fill in the `TODOs` to define the RNN model within the `build_model` function, and then call the function you just defined to instantiate the model!"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "MtCrdfzEI2N0"
- },
- "outputs": [],
- "source": [
- "### Defining the RNN Model ###\n",
- "\n",
- "'''TODO: Add LSTM and Dense layers to define the RNN model using the Sequential API.'''\n",
- "def build_model(vocab_size, embedding_dim, rnn_units, batch_size):\n",
- " model = tf.keras.Sequential([\n",
- " # Layer 1: Embedding layer to transform indices into dense vectors\n",
- " # of a fixed embedding size\n",
- " tf.keras.layers.Embedding(vocab_size, embedding_dim),\n",
- "\n",
- " # Layer 2: LSTM with `rnn_units` number of units.\n",
- " # TODO: Call the LSTM function defined above to add this layer.\n",
- " LSTM(rnn_units),\n",
- " # LSTM('''TODO'''),\n",
- "\n",
- " # Layer 3: Dense (fully-connected) layer that transforms the LSTM output\n",
- " # into the vocabulary size.\n",
- " # TODO: Add the Dense layer.\n",
- " tf.keras.layers.Dense(vocab_size)\n",
- " # '''TODO: DENSE LAYER HERE'''\n",
- " ])\n",
- "\n",
- " return model\n",
- "\n",
- "# Build a simple model with default hyperparameters. You will get the\n",
- "# chance to change these later.\n",
- "model = build_model(len(vocab), embedding_dim=256, rnn_units=1024, batch_size=32)\n",
- "model.build(tf.TensorShape([32, 100])) # [batch_size, sequence_length]"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "-ubPo0_9Prjb"
- },
- "source": [
- "### Test out the RNN model\n",
- "\n",
- "It's always a good idea to run a few simple checks on our model to see that it behaves as expected. \n",
- "\n",
- "First, we can use the `Model.summary` function to print out a summary of our model's internal workings. Here we can check the layers in the model, the shape of the output of each of the layers, the batch size, etc."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "RwG1DD6rDrRM"
- },
- "outputs": [],
- "source": [
- "model.summary()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "8xeDn5nZD0LX"
- },
- "source": [
- "We can also quickly check the dimensionality of our output, using a sequence length of 100. Note that the model can be run on inputs of any length."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "C-_70kKAPrPU"
- },
- "outputs": [],
- "source": [
- "x, y = get_batch(vectorized_songs, seq_length=100, batch_size=32)\n",
- "pred = model(x)\n",
- "print(\"Input shape: \", x.shape, \" # (batch_size, sequence_length)\")\n",
- "print(\"Prediction shape: \", pred.shape, \"# (batch_size, sequence_length, vocab_size)\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "mT1HvFVUGpoE"
- },
- "source": [
- "### Predictions from the untrained model\n",
- "\n",
- "Let's take a look at what our untrained model is predicting.\n",
- "\n",
- "To get actual predictions from the model, we sample from the output distribution, which is defined by a `softmax` over our character vocabulary. This will give us actual character indices. This means we are using a [categorical distribution](https://en.wikipedia.org/wiki/Categorical_distribution) to sample over the example prediction. This gives a prediction of the next character (specifically its index) at each timestep.\n",
- "\n",
- "Note here that we sample from this probability distribution, as opposed to simply taking the `argmax`, which can cause the model to get stuck in a loop.\n",
- "\n",
- "Let's try this sampling out for the first example in the batch."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "4V4MfFg0RQJg"
- },
- "outputs": [],
- "source": [
- "sampled_indices = tf.random.categorical(pred[0], num_samples=1)\n",
- "sampled_indices = tf.squeeze(sampled_indices,axis=-1).numpy()\n",
- "sampled_indices"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "LfLtsP3mUhCG"
- },
- "source": [
- "We can now decode these to see the text predicted by the untrained model:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "xWcFwPwLSo05"
- },
- "outputs": [],
- "source": [
- "print(\"Input: \\n\", repr(\"\".join(idx2char[x[0]])))\n",
- "print()\n",
- "print(\"Next Char Predictions: \\n\", repr(\"\".join(idx2char[sampled_indices])))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "HEHHcRasIDm9"
- },
- "source": [
- "As you can see, the text predicted by the untrained model is pretty nonsensical! How can we do better? We can train the network!"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "LJL0Q0YPY6Ee"
- },
- "source": [
- "## 2.5 Training the model: loss and training operations\n",
- "\n",
- "Now it's time to train the model!\n",
- "\n",
- "At this point, we can think of our next character prediction problem as a standard classification problem. Given the previous state of the RNN, as well as the input at a given time step, we want to predict the class of the next character -- that is, to actually predict the next character.\n",
- "\n",
- "To train our model on this classification task, we can use a form of the `crossentropy` loss (negative log likelihood loss). Specifically, we will use the [`sparse_categorical_crossentropy`](https://www.tensorflow.org/api_docs/python/tf/keras/losses/sparse_categorical_crossentropy) loss, as it utilizes integer targets for categorical classification tasks. We will want to compute the loss using the true targets -- the `labels` -- and the predicted targets -- the `logits`.\n",
- "\n",
- "Let's first compute the loss using our example predictions from the untrained model:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "4HrXTACTdzY-"
- },
- "outputs": [],
- "source": [
- "### Defining the loss function ###\n",
- "\n",
- "'''TODO: define the loss function to compute and return the loss between\n",
- " the true labels and predictions (logits). Set the argument from_logits=True.'''\n",
- "def compute_loss(labels, logits):\n",
- " loss = tf.keras.losses.sparse_categorical_crossentropy(labels, logits, from_logits=True)\n",
- " # loss = tf.keras.losses.sparse_categorical_crossentropy('''TODO''', '''TODO''', from_logits=True) # TODO\n",
- " return loss\n",
- "\n",
- "'''TODO: compute the loss using the true next characters from the example batch\n",
- " and the predictions from the untrained model several cells above'''\n",
- "example_batch_loss = compute_loss(y, pred)\n",
- "# example_batch_loss = compute_loss('''TODO''', '''TODO''') # TODO\n",
- "\n",
- "print(\"Prediction shape: \", pred.shape, \" # (batch_size, sequence_length, vocab_size)\")\n",
- "print(\"scalar_loss: \", example_batch_loss.numpy().mean())"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "0Seh7e6eRqd7"
- },
- "source": [
- "Let's start by defining some hyperparameters for training the model. To start, we have provided some reasonable values for some of the parameters. It is up to you to use what we've learned in class to help optimize the parameter selection here!"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "JQWUUhKotkAY"
- },
- "outputs": [],
- "source": [
- "### Hyperparameter setting and optimization ###\n",
- "\n",
- "vocab_size = len(vocab)\n",
- "\n",
- "# Model parameters:\n",
- "params = dict(\n",
- " num_training_iterations = 3000, # Increase this to train longer\n",
- " batch_size = 8, # Experiment between 1 and 64\n",
- " seq_length = 100, # Experiment between 50 and 500\n",
- " learning_rate = 5e-3, # Experiment between 1e-5 and 1e-1\n",
- " embedding_dim = 256,\n",
- " rnn_units = 1024, # Experiment between 1 and 2048\n",
- ")\n",
- "\n",
- "# Checkpoint location:\n",
- "checkpoint_dir = './training_checkpoints'\n",
- "checkpoint_prefix = os.path.join(checkpoint_dir, \"my_ckpt.weights.h5\")\n",
- "os.makedirs(checkpoint_dir, exist_ok=True)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "AyLzIPeAIqfg"
- },
- "source": [
- "Having defined our hyperparameters we can set up for experiment tracking with Comet. [`Experiment`](https://www.comet.com/docs/v2/api-and-sdk/python-sdk/reference/Experiment/) are the core objects in Comet and will allow us to track training and model development. Here we have written a short function to create a new comet experiment. Note that in this setup, when hyperparameters change, you can run the `create_experiment()` function to initiate a new experiment. All experiments defined with the same `project_name` will live under that project in your Comet interface.\n",
- "\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "MBsN1vvxInmN"
- },
- "outputs": [],
- "source": [
- "### Create a Comet experiment to track our training run ###\n",
- "\n",
- "def create_experiment():\n",
- " # end any prior experiments\n",
- " if 'experiment' in locals():\n",
- " experiment.end()\n",
- "\n",
- " # initiate the comet experiment for tracking\n",
- " experiment = comet_ml.Experiment(\n",
- " api_key=COMET_API_KEY,\n",
- " project_name=\"6S191_Lab1_Part2\")\n",
- " # log our hyperparameters, defined above, to the experiment\n",
- " for param, value in params.items():\n",
- " experiment.log_parameter(param, value)\n",
- " experiment.flush()\n",
- "\n",
- " return experiment"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "5cu11p1MKYZd"
- },
- "source": [
- "Now, we are ready to define our training operation -- the optimizer and duration of training -- and use this function to train the model. You will experiment with the choice of optimizer and the duration for which you train your models, and see how these changes affect the network's output. Some optimizers you may like to try are [`Adam`](https://www.tensorflow.org/api_docs/python/tf/keras/optimizers/Adam?version=stable) and [`Adagrad`](https://www.tensorflow.org/api_docs/python/tf/keras/optimizers/Adagrad?version=stable).\n",
- "\n",
- "First, we will instantiate a new model and an optimizer. Then, we will use the [`tf.GradientTape`](https://www.tensorflow.org/api_docs/python/tf/GradientTape) method to perform the backpropagation operations.\n",
- "\n",
- "We will also generate a print-out of the model's progress through training, which will help us easily visualize whether or not we are minimizing the loss."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "F31vzJ_u66cb"
- },
- "outputs": [],
- "source": [
- "### Define optimizer and training operation ###\n",
- "\n",
- "'''TODO: instantiate a new model for training using the `build_model`\n",
- " function and the hyperparameters created above.'''\n",
- "model = build_model(vocab_size, params[\"embedding_dim\"], params[\"rnn_units\"], params[\"batch_size\"])\n",
- "# model = build_model('''TODO: arguments''')\n",
- "\n",
- "'''TODO: instantiate an optimizer with its learning rate.\n",
- " Checkout the tensorflow website for a list of supported optimizers.\n",
- " https://www.tensorflow.org/api_docs/python/tf/keras/optimizers/\n",
- " Try using the Adam optimizer to start.'''\n",
- "optimizer = tf.keras.optimizers.Adam(params[\"learning_rate\"])\n",
- "# optimizer = # TODO\n",
- "\n",
- "@tf.function\n",
- "def train_step(x, y):\n",
- " # Use tf.GradientTape()\n",
- " with tf.GradientTape() as tape:\n",
- "\n",
- " '''TODO: feed the current input into the model and generate predictions'''\n",
- " y_hat = model(x) # TODO\n",
- " # y_hat = model('''TODO''')\n",
- "\n",
- " '''TODO: compute the loss!'''\n",
- " loss = compute_loss(y, y_hat) # TODO\n",
- " # loss = compute_loss('''TODO''', '''TODO''')\n",
- "\n",
- " # Now, compute the gradients\n",
- " '''TODO: complete the function call for gradient computation.\n",
- " Remember that we want the gradient of the loss with respect all\n",
- " of the model parameters.\n",
- " HINT: use `model.trainable_variables` to get a list of all model\n",
- " parameters.'''\n",
- " grads = tape.gradient(loss, model.trainable_variables) # TODO\n",
- " # grads = tape.gradient('''TODO''', '''TODO''')\n",
- "\n",
- " # Apply the gradients to the optimizer so it can update the model accordingly\n",
- " optimizer.apply_gradients(zip(grads, model.trainable_variables))\n",
- " return loss\n",
- "\n",
- "##################\n",
- "# Begin training!#\n",
- "##################\n",
- "\n",
- "history = []\n",
- "plotter = mdl.util.PeriodicPlotter(sec=2, xlabel='Iterations', ylabel='Loss')\n",
- "experiment = create_experiment()\n",
- "\n",
- "if hasattr(tqdm, '_instances'): tqdm._instances.clear() # clear if it exists\n",
- "for iter in tqdm(range(params[\"num_training_iterations\"])):\n",
- "\n",
- " # Grab a batch and propagate it through the network\n",
- " x_batch, y_batch = get_batch(vectorized_songs, params[\"seq_length\"], params[\"batch_size\"])\n",
- " loss = train_step(x_batch, y_batch)\n",
- "\n",
- " # log the loss to the Comet interface! we will be able to track it there.\n",
- " experiment.log_metric(\"loss\", loss.numpy().mean(), step=iter)\n",
- " # Update the progress bar and also visualize within notebook\n",
- " history.append(loss.numpy().mean())\n",
- " plotter.plot(history)\n",
- "\n",
- " # Update the model with the changed weights!\n",
- " if iter % 100 == 0:\n",
- " model.save_weights(checkpoint_prefix)\n",
- "\n",
- "# Save the trained model and the weights\n",
- "model.save_weights(checkpoint_prefix)\n",
- "experiment.flush()\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "kKkD5M6eoSiN"
- },
- "source": [
- "## 2.6 Generate music using the RNN model\n",
- "\n",
- "Now, we can use our trained RNN model to generate some music! When generating music, we'll have to feed the model some sort of seed to get it started (because it can't predict anything without something to start with!).\n",
- "\n",
- "Once we have a generated seed, we can then iteratively predict each successive character (remember, we are using the ABC representation for our music) using our trained RNN. More specifically, recall that our RNN outputs a `softmax` over possible successive characters. For inference, we iteratively sample from these distributions, and then use our samples to encode a generated song in the ABC format.\n",
- "\n",
- "Then, all we have to do is write it to a file and listen!"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "JIPcXllKjkdr"
- },
- "source": [
- "\n",
- "### Restore the latest checkpoint\n",
- "\n",
- "To keep this inference step simple, we will use a batch size of 1. Because of how the RNN state is passed from timestep to timestep, the model will only be able to accept a fixed batch size once it is built.\n",
- "\n",
- "To run the model with a different `batch_size`, we'll need to rebuild the model and restore the weights from the latest checkpoint, i.e., the weights after the last checkpoint during training:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "LycQ-ot_jjyu"
- },
- "outputs": [],
- "source": [
- "'''TODO: Rebuild the model using a batch_size=1'''\n",
- "model = build_model(vocab_size, params[\"embedding_dim\"], params[\"rnn_units\"], batch_size=1) # TODO\n",
- "# model = build_model('''TODO''', '''TODO''', '''TODO''', batch_size=1)\n",
- "\n",
- "# Restore the model weights for the last checkpoint after training\n",
- "model.build(tf.TensorShape([1, None]))\n",
- "model.load_weights(checkpoint_prefix)\n",
- "\n",
- "model.summary()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "I9b4V2C8N62l"
- },
- "source": [
- "Notice that we have fed in a fixed `batch_size` of 1 for inference."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "DjGz1tDkzf-u"
- },
- "source": [
- "### The prediction procedure\n",
- "\n",
- "Now, we're ready to write the code to generate text in the ABC music format:\n",
- "\n",
- "* Initialize a \"seed\" start string and the RNN state, and set the number of characters we want to generate.\n",
- "\n",
- "* Use the start string and the RNN state to obtain the probability distribution over the next predicted character.\n",
- "\n",
- "* Sample from multinomial distribution to calculate the index of the predicted character. This predicted character is then used as the next input to the model.\n",
- "\n",
- "* At each time step, the updated RNN state is fed back into the model, so that it now has more context in making the next prediction. After predicting the next character, the updated RNN states are again fed back into the model, which is how it learns sequence dependencies in the data, as it gets more information from the previous predictions.\n",
- "\n",
- "\n",
- "\n",
- "Complete and experiment with this code block (as well as some of the aspects of network definition and training!), and see how the model performs. How do songs generated after training with a small number of epochs compare to those generated after a longer duration of training?"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "WvuwZBX5Ogfd"
- },
- "outputs": [],
- "source": [
- "### Prediction of a generated song ###\n",
- "\n",
- "def generate_text(model, start_string, generation_length=1000):\n",
- " # Evaluation step (generating ABC text using the learned RNN model)\n",
- "\n",
- " '''TODO: convert the start string to numbers (vectorize)'''\n",
- " input_eval = [char2idx[s] for s in start_string] # TODO\n",
- " # input_eval = ['''TODO''']\n",
- " input_eval = tf.expand_dims(input_eval, 0)\n",
- "\n",
- " # Empty string to store our results\n",
- " text_generated = []\n",
- "\n",
- " # Here batch size == 1\n",
- " model.reset_states()\n",
- " tqdm._instances.clear()\n",
- "\n",
- " for i in tqdm(range(generation_length)):\n",
- " '''TODO: evaluate the inputs and generate the next character predictions'''\n",
- " predictions = model(input_eval)\n",
- " # predictions = model('''TODO''')\n",
- "\n",
- " # Remove the batch dimension\n",
- " predictions = tf.squeeze(predictions, 0)\n",
- "\n",
- " '''TODO: use a multinomial distribution to sample'''\n",
- " predicted_id = tf.random.categorical(predictions, num_samples=1)[-1,0].numpy()\n",
- " # predicted_id = tf.random.categorical('''TODO''', num_samples=1)[-1,0].numpy()\n",
- "\n",
- " # Pass the prediction along with the previous hidden state\n",
- " # as the next inputs to the model\n",
- " input_eval = tf.expand_dims([predicted_id], 0)\n",
- "\n",
- " '''TODO: add the predicted character to the generated text!'''\n",
- " # Hint: consider what format the prediction is in vs. the output\n",
- " text_generated.append(idx2char[predicted_id]) # TODO\n",
- " # text_generated.append('''TODO''')\n",
- "\n",
- " return (start_string + ''.join(text_generated))"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "ktovv0RFhrkn"
- },
- "outputs": [],
- "source": [
- "'''TODO: Use the model and the function defined above to generate ABC format text of length 1000!\n",
- " As you may notice, ABC files start with \"X\" - this may be a good start string.'''\n",
- "generated_text = generate_text(model, start_string=\"X\", generation_length=1000) # TODO\n",
- "# generated_text = generate_text('''TODO''', start_string=\"X\", generation_length=1000)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "AM2Uma_-yVIq"
- },
- "source": [
- "### Play back the generated music!\n",
- "\n",
- "We can now call a function to convert the ABC format text to an audio file, and then play that back to check out our generated music! Try training longer if the resulting song is not long enough, or re-generating the song!\n",
- "\n",
- "We will save the song to Comet -- you will be able to find your songs under the `Audio` and `Assets & Artificats` pages in your Comet interface for the project. Note the [`log_asset()`](https://www.comet.com/docs/v2/api-and-sdk/python-sdk/reference/Experiment/#experimentlog_asset) documentation, where you will see how to specify file names and other parameters for saving your assets."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "LrOtG64bfLto"
- },
- "outputs": [],
- "source": [
- "### Play back generated songs ###\n",
- "\n",
- "generated_songs = mdl.lab1.extract_song_snippet(generated_text)\n",
- "\n",
- "for i, song in enumerate(generated_songs):\n",
- " # Synthesize the waveform from a song\n",
- " waveform = mdl.lab1.play_song(song)\n",
- "\n",
- " # If its a valid song (correct syntax), lets play it!\n",
- " if waveform:\n",
- " print(\"Generated song\", i)\n",
- " ipythondisplay.display(waveform)\n",
- "\n",
- " numeric_data = np.frombuffer(waveform.data, dtype=np.int16)\n",
- " wav_file_path = f\"output_{i}.wav\"\n",
- " write(wav_file_path, 88200, numeric_data)\n",
- "\n",
- " # save your song to the Comet interface -- you can access it there\n",
- " experiment.log_asset(wav_file_path)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "4353qSV76gnJ"
- },
- "outputs": [],
- "source": [
- "# when done, end the comet experiment\n",
- "experiment.end()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "HgVvcrYmSKGG"
- },
- "source": [
- "## 2.7 Experiment and **get awarded for the best songs**!\n",
- "\n",
- "Congrats on making your first sequence model in TensorFlow! It's a pretty big accomplishment, and hopefully you have some sweet tunes to show for it.\n",
- "\n",
- "Consider how you may improve your model and what seems to be most important in terms of performance. Here are some ideas to get you started:\n",
- "\n",
- "* How does the number of training epochs affect the performance?\n",
- "* What if you alter or augment the dataset?\n",
- "* Does the choice of start string significantly affect the result?\n",
- "\n",
- "Try to optimize your model and submit your best song! **Participants will be eligible for prizes during the January 2025 offering. To enter the competition, you must upload the following to [this submission link](https://www.dropbox.com/request/U8nND6enGjirujVZKX1n):**\n",
- "\n",
- "* a recording of your song;\n",
- "* iPython notebook with the code you used to generate the song;\n",
- "* a description and/or diagram of the architecture and hyperparameters you used -- if there are any additional or interesting modifications you made to the template code, please include these in your description.\n",
- "\n",
- "**Name your file in the following format: ``[FirstName]_[LastName]_RNNMusic``, followed by the file format (.zip, .mp4, .ipynb, .pdf, etc). ZIP files of all three components are preferred over individual files. If you submit individual files, you must name the individual files according to the above nomenclature.**\n",
- "\n",
- "You can also tweet us at [@MITDeepLearning](https://twitter.com/MITDeepLearning) a copy of the song (but this will not enter you into the competition)! See this example song generated by a previous student (credit Ana Heart): song from May 20, 2020.\n",
- "\n",
- "\n",
- "Have fun and happy listening!\n",
- "\n",
- "\n"
- ]
- }
- ],
- "metadata": {
- "accelerator": "GPU",
- "colab": {
- "collapsed_sections": [
- "uoJsVjtCMunI"
- ],
- "name": "TF_Part2_Music_Generation_Solution.ipynb",
- "provenance": []
- },
- "kernelspec": {
- "display_name": "Python 3",
- "name": "python3"
- },
- "language_info": {
- "codemirror_mode": {
- "name": "ipython",
- "version": 3
- },
- "file_extension": ".py",
- "mimetype": "text/x-python",
- "name": "python",
- "nbconvert_exporter": "python",
- "pygments_lexer": "ipython3",
- "version": "3.11.11"
- }
- },
- "nbformat": 4,
- "nbformat_minor": 0
-}
\ No newline at end of file
diff --git a/lab2/TF_Part1_MNIST.ipynb b/lab2/TF_Part1_MNIST.ipynb
deleted file mode 100644
index 81549151..00000000
--- a/lab2/TF_Part1_MNIST.ipynb
+++ /dev/null
@@ -1,772 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Xmf_JRJa_N8C"
- },
- "source": [
- "\n",
- "\n",
- "# Copyright Information"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "gKA_J7bdP33T"
- },
- "outputs": [],
- "source": [
- "# Copyright 2025 MIT Introduction to Deep Learning. All Rights Reserved.\n",
- "#\n",
- "# Licensed under the MIT License. You may not use this file except in compliance\n",
- "# with the License. Use and/or modification of this code outside of MIT Introduction\n",
- "# to Deep Learning must reference:\n",
- "#\n",
- "# © MIT Introduction to Deep Learning\n",
- "# http://introtodeeplearning.com\n",
- "#"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Cm1XpLftPi4A"
- },
- "source": [
- "# Laboratory 2: Computer Vision\n",
- "\n",
- "# Part 1: MNIST Digit Classification\n",
- "\n",
- "In the first portion of this lab, we will build and train a convolutional neural network (CNN) for classification of handwritten digits from the famous [MNIST](http://yann.lecun.com/exdb/mnist/) dataset. The MNIST dataset consists of 60,000 training images and 10,000 test images. Our classes are the digits 0-9.\n",
- "\n",
- "First, let's download the course repository, install dependencies, and import the relevant packages we'll need for this lab."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "RsGqx_ai_N8F"
- },
- "outputs": [],
- "source": [
- "# Import Tensorflow 2.0\n",
- "# !pip install tensorflow\n",
- "import tensorflow as tf\n",
- "\n",
- "# MIT introduction to deep learning package\n",
- "!pip install mitdeeplearning --quiet\n",
- "import mitdeeplearning as mdl\n",
- "\n",
- "# other packages\n",
- "import matplotlib.pyplot as plt\n",
- "import numpy as np\n",
- "import random\n",
- "from tqdm import tqdm"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "nCpHDxX1bzyZ"
- },
- "source": [
- "We'll also install Comet. If you followed the instructions from Lab 1, you should have your Comet account set up. Enter your API key below."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "GSR_PAqjbzyZ"
- },
- "outputs": [],
- "source": [
- "!pip install comet_ml > /dev/null 2>&1\n",
- "import comet_ml\n",
- "# TODO: ENTER YOUR API KEY HERE!!\n",
- "COMET_API_KEY = \"\"\n",
- "\n",
- "# Check that we are using a GPU, if not switch runtimes\n",
- "# using Runtime > Change Runtime Type > GPU\n",
- "assert len(tf.config.list_physical_devices('GPU')) > 0\n",
- "assert COMET_API_KEY != \"\", \"Please insert your Comet API Key\""
- ]
- },
- {
- "cell_type": "code",
- "source": [
- "# start a first comet experiment for the first part of the lab\n",
- "comet_ml.init(project_name=\"6S191_lab2_part1_NN\")\n",
- "comet_model_1 = comet_ml.Experiment()"
- ],
- "metadata": {
- "id": "wGPDtVxvTtPk"
- },
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "HKjrdUtX_N8J"
- },
- "source": [
- "## 1.1 MNIST dataset\n",
- "\n",
- "Let's download and load the dataset and display a few random samples from it:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "p2dQsHI3_N8K"
- },
- "outputs": [],
- "source": [
- "mnist = tf.keras.datasets.mnist\n",
- "(train_images, train_labels), (test_images, test_labels) = mnist.load_data()\n",
- "train_images = (np.expand_dims(train_images, axis=-1)/255.).astype(np.float32)\n",
- "train_labels = (train_labels).astype(np.int64)\n",
- "test_images = (np.expand_dims(test_images, axis=-1)/255.).astype(np.float32)\n",
- "test_labels = (test_labels).astype(np.int64)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "5ZtUqOqePsRD"
- },
- "source": [
- "Our training set is made up of 28x28 grayscale images of handwritten digits.\n",
- "\n",
- "Let's visualize what some of these images and their corresponding training labels look like."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "bDBsR2lP_N8O",
- "scrolled": true
- },
- "outputs": [],
- "source": [
- "plt.figure(figsize=(10,10))\n",
- "random_inds = np.random.choice(60000,36)\n",
- "for i in range(36):\n",
- " plt.subplot(6,6,i+1)\n",
- " plt.xticks([])\n",
- " plt.yticks([])\n",
- " plt.grid(False)\n",
- " image_ind = random_inds[i]\n",
- " plt.imshow(np.squeeze(train_images[image_ind]), cmap=plt.cm.binary)\n",
- " plt.xlabel(train_labels[image_ind])\n",
- "comet_model_1.log_figure(figure=plt)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "V6hd3Nt1_N8q"
- },
- "source": [
- "## 1.2 Neural Network for Handwritten Digit Classification\n",
- "\n",
- "We'll first build a simple neural network consisting of two fully connected layers and apply this to the digit classification task. Our network will ultimately output a probability distribution over the 10 digit classes (0-9). This first architecture we will be building is depicted below:\n",
- "\n",
- "\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "rphS2rMIymyZ"
- },
- "source": [
- "### Fully connected neural network architecture\n",
- "To define the architecture of this first fully connected neural network, we'll once again use the Keras API and define the model using the [`Sequential`](https://www.tensorflow.org/api_docs/python/tf/keras/models/Sequential) class. Note how we first use a [`Flatten`](https://www.tensorflow.org/api_docs/python/tf/keras/layers/Flatten) layer, which flattens the input so that it can be fed into the model.\n",
- "\n",
- "In this next block, you'll define the fully connected layers of this simple work."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "MMZsbjAkDKpU"
- },
- "outputs": [],
- "source": [
- "def build_fc_model():\n",
- " fc_model = tf.keras.Sequential([\n",
- " # First define a Flatten layer\n",
- " tf.keras.layers.Flatten(),\n",
- "\n",
- " # '''TODO: Define the activation function for the first fully connected (Dense) layer.'''\n",
- " tf.keras.layers.Dense(128, activation= '''TODO'''),\n",
- "\n",
- " # '''TODO: Define the second Dense layer to output the classification probabilities'''\n",
- " '''[TODO Dense layer to output classification probabilities]'''\n",
- "\n",
- " ])\n",
- " return fc_model\n",
- "\n",
- "model = build_fc_model()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "VtGZpHVKz5Jt"
- },
- "source": [
- "As we progress through this next portion, you may find that you'll want to make changes to the architecture defined above. **Note that in order to update the model later on, you'll need to re-run the above cell to re-initialize the model.**"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "mVN1_AeG_N9N"
- },
- "source": [
- "Let's take a step back and think about the network we've just created. The first layer in this network, `tf.keras.layers.Flatten`, transforms the format of the images from a 2d-array (28 x 28 pixels), to a 1d-array of 28 * 28 = 784 pixels. You can think of this layer as unstacking rows of pixels in the image and lining them up. There are no learned parameters in this layer; it only reformats the data.\n",
- "\n",
- "After the pixels are flattened, the network consists of a sequence of two `tf.keras.layers.Dense` layers. These are fully-connected neural layers. The first `Dense` layer has 128 nodes (or neurons). The second (and last) layer (which you've defined!) should return an array of probability scores that sum to 1. Each node contains a score that indicates the probability that the current image belongs to one of the handwritten digit classes.\n",
- "\n",
- "That defines our fully connected model!"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "gut8A_7rCaW6"
- },
- "source": [
- "\n",
- "\n",
- "### Compile the model\n",
- "\n",
- "Before training the model, we need to define a few more settings. These are added during the model's [`compile`](https://www.tensorflow.org/api_docs/python/tf/keras/models/Sequential#compile) step:\n",
- "\n",
- "* *Loss function* — This defines how we measure how accurate the model is during training. As was covered in lecture, during training we want to minimize this function, which will \"steer\" the model in the right direction.\n",
- "* *Optimizer* — This defines how the model is updated based on the data it sees and its loss function.\n",
- "* *Metrics* — Here we can define metrics used to monitor the training and testing steps. In this example, we'll look at the *accuracy*, the fraction of the images that are correctly classified.\n",
- "\n",
- "We'll start out by using a stochastic gradient descent (SGD) optimizer initialized with a learning rate of 0.1. Since we are performing a categorical classification task, we'll want to use the [cross entropy loss](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/sparse_categorical_crossentropy).\n",
- "\n",
- "You'll want to experiment with both the choice of optimizer and learning rate and evaluate how these affect the accuracy of the trained model."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "Lhan11blCaW7"
- },
- "outputs": [],
- "source": [
- "'''TODO: Experiment with different optimizers and learning rates. How do these affect\n",
- " the accuracy of the trained model? Which optimizers and/or learning rates yield\n",
- " the best performance?'''\n",
- "model.compile(optimizer=tf.keras.optimizers.SGD(learning_rate=1e-1),\n",
- " loss='sparse_categorical_crossentropy',\n",
- " metrics=['accuracy'])"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "qKF6uW-BCaW-"
- },
- "source": [
- "### Train the model\n",
- "\n",
- "We're now ready to train our model, which will involve feeding the training data (`train_images` and `train_labels`) into the model, and then asking it to learn the associations between images and labels. We'll also need to define the batch size and the number of epochs, or iterations over the MNIST dataset, to use during training.\n",
- "\n",
- "In Lab 1, we saw how we can use `GradientTape` to optimize losses and train models with stochastic gradient descent. After defining the model settings in the `compile` step, we can also accomplish training by calling the [`fit`](https://www.tensorflow.org/api_docs/python/tf/keras/models/Sequential#fit) method on an instance of the `Model` class. We will use this to train our fully connected model\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "EFMbIqIvQ2X0"
- },
- "outputs": [],
- "source": [
- "# Define the batch size and the number of epochs to use during training\n",
- "BATCH_SIZE = 64\n",
- "EPOCHS = 5\n",
- "\n",
- "model.fit(train_images, train_labels, batch_size=BATCH_SIZE, epochs=EPOCHS)\n",
- "comet_model_1.end()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "W3ZVOhugCaXA"
- },
- "source": [
- "As the model trains, the loss and accuracy metrics are displayed. With five epochs and a learning rate of 0.01, this fully connected model should achieve an accuracy of approximatley 0.97 (or 97%) on the training data."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "oEw4bZgGCaXB"
- },
- "source": [
- "### Evaluate accuracy on the test dataset\n",
- "\n",
- "Now that we've trained the model, we can ask it to make predictions about a test set that it hasn't seen before. In this example, the `test_images` array comprises our test dataset. To evaluate accuracy, we can check to see if the model's predictions match the labels from the `test_labels` array.\n",
- "\n",
- "Use the [`evaluate`](https://www.tensorflow.org/api_docs/python/tf/keras/models/Sequential#evaluate) method to evaluate the model on the test dataset!"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "VflXLEeECaXC"
- },
- "outputs": [],
- "source": [
- "'''TODO: Use the evaluate method to test the model!'''\n",
- "test_loss, test_acc = # TODO\n",
- "\n",
- "print('Test accuracy:', test_acc)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "yWfgsmVXCaXG"
- },
- "source": [
- "You may observe that the accuracy on the test dataset is a little lower than the accuracy on the training dataset. This gap between training accuracy and test accuracy is an example of *overfitting*, when a machine learning model performs worse on new data than on its training data.\n",
- "\n",
- "What is the highest accuracy you can achieve with this first fully connected model? Since the handwritten digit classification task is pretty straightforward, you may be wondering how we can do better...\n",
- "\n",
- ""
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "baIw9bDf8v6Z"
- },
- "source": [
- "## 1.3 Convolutional Neural Network (CNN) for handwritten digit classification"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "_J72Yt1o_fY7"
- },
- "source": [
- "As we saw in lecture, convolutional neural networks (CNNs) are particularly well-suited for a variety of tasks in computer vision, and have achieved near-perfect accuracies on the MNIST dataset. We will now build a CNN composed of two convolutional layers and pooling layers, followed by two fully connected layers, and ultimately output a probability distribution over the 10 digit classes (0-9). The CNN we will be building is depicted below:\n",
- "\n",
- ""
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "EEHqzbJJAEoR"
- },
- "source": [
- "### Define the CNN model\n",
- "\n",
- "We'll use the same training and test datasets as before, and proceed similarly as our fully connected network to define and train our new CNN model. To do this we will explore two layers we have not encountered before: you can use [`keras.layers.Conv2D` ](https://www.tensorflow.org/api_docs/python/tf/keras/layers/Conv2D) to define convolutional layers and [`keras.layers.MaxPool2D`](https://www.tensorflow.org/api_docs/python/tf/keras/layers/MaxPool2D) to define the pooling layers. Use the parameters shown in the network architecture above to define these layers and build the CNN model."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "vec9qcJs-9W5"
- },
- "outputs": [],
- "source": [
- "def build_cnn_model():\n",
- " cnn_model = tf.keras.Sequential([\n",
- "\n",
- " # TODO: Define the first convolutional layer\n",
- " tf.keras.layers.Conv2D('''TODO''')\n",
- "\n",
- " # TODO: Define the first max pooling layer\n",
- " tf.keras.layers.MaxPool2D('''TODO''')\n",
- "\n",
- " # TODO: Define the second convolutional layer\n",
- " tf.keras.layers.Conv2D('''TODO''')\n",
- "\n",
- " # TODO: Define the second max pooling layer\n",
- " tf.keras.layers.MaxPool2D('''TODO''')\n",
- "\n",
- " tf.keras.layers.Flatten(),\n",
- " tf.keras.layers.Dense(128, activation=tf.nn.relu),\n",
- "\n",
- " # TODO: Define the last Dense layer to output the classification\n",
- " # probabilities. Pay attention to the activation needed a probability\n",
- " # output\n",
- " '''[TODO Dense layer to output classification probabilities]'''\n",
- " ])\n",
- "\n",
- " return cnn_model\n",
- "\n",
- "cnn_model = build_cnn_model()\n",
- "# Initialize the model by passing some data through\n",
- "cnn_model.predict(train_images[[0]])\n",
- "# Print the summary of the layers in the model.\n",
- "print(cnn_model.summary())"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "kUAXIBynCih2"
- },
- "source": [
- "### Train and test the CNN model\n",
- "\n",
- "Now, as before, we can define the loss function, optimizer, and metrics through the `compile` method. Compile the CNN model with an optimizer and learning rate of choice:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "vheyanDkCg6a"
- },
- "outputs": [],
- "source": [
- "comet_ml.init(project_name=\"6.s191lab2_part1_CNN\")\n",
- "comet_model_2 = comet_ml.Experiment()\n",
- "\n",
- "'''TODO: Define the compile operation with your optimizer and learning rate of choice'''\n",
- "cnn_model.compile(optimizer='''TODO''', loss='''TODO''', metrics=['accuracy']) # TODO"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "U19bpRddC7H_"
- },
- "source": [
- "As was the case with the fully connected model, we can train our CNN using the `fit` method via the Keras API."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "YdrGZVmWDK4p"
- },
- "outputs": [],
- "source": [
- "'''TODO: Use model.fit to train the CNN model, with the same batch_size and number of epochs previously used.'''\n",
- "cnn_model.fit('''TODO''')\n",
- "# comet_model_2.end()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "pEszYWzgDeIc"
- },
- "source": [
- "Great! Now that we've trained the model, let's evaluate it on the test dataset using the [`evaluate`](https://www.tensorflow.org/api_docs/python/tf/keras/models/Sequential#evaluate) method:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "JDm4znZcDtNl"
- },
- "outputs": [],
- "source": [
- "'''TODO: Use the evaluate method to test the model!'''\n",
- "test_loss, test_acc = # TODO\n",
- "\n",
- "print('Test accuracy:', test_acc)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "2rvEgK82Glv9"
- },
- "source": [
- "What is the highest accuracy you're able to achieve using the CNN model, and how does the accuracy of the CNN model compare to the accuracy of the simple fully connected network? What optimizers and learning rates seem to be optimal for training the CNN model?\n",
- "\n",
- "Feel free to click the Comet links to investigate the training/accuracy curves for your model."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "xsoS7CPDCaXH"
- },
- "source": [
- "### Make predictions with the CNN model\n",
- "\n",
- "With the model trained, we can use it to make predictions about some images. The [`predict`](https://www.tensorflow.org/api_docs/python/tf/keras/models/Sequential#predict) function call generates the output predictions given a set of input samples.\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "Gl91RPhdCaXI"
- },
- "outputs": [],
- "source": [
- "predictions = cnn_model.predict(test_images)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "x9Kk1voUCaXJ"
- },
- "source": [
- "With this function call, the model has predicted the label for each image in the testing set. Let's take a look at the prediction for the first image in the test dataset:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "3DmJEUinCaXK"
- },
- "outputs": [],
- "source": [
- "predictions[0]"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "-hw1hgeSCaXN"
- },
- "source": [
- "As you can see, a prediction is an array of 10 numbers. Recall that the output of our model is a probability distribution over the 10 digit classes. Thus, these numbers describe the model's \"confidence\" that the image corresponds to each of the 10 different digits.\n",
- "\n",
- "Let's look at the digit that has the highest confidence for the first image in the test dataset:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "qsqenuPnCaXO"
- },
- "outputs": [],
- "source": [
- "'''TODO: identify the digit with the highest confidence prediction for the first\n",
- " image in the test dataset. '''\n",
- "prediction = # TODO\n",
- "\n",
- "print(prediction)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "E51yS7iCCaXO"
- },
- "source": [
- "So, the model is most confident that this image is a \"???\". We can check the test label (remember, this is the true identity of the digit) to see if this prediction is correct:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "Sd7Pgsu6CaXP"
- },
- "outputs": [],
- "source": [
- "print(\"Label of this digit is:\", test_labels[0])\n",
- "plt.imshow(test_images[0,:,:,0], cmap=plt.cm.binary)\n",
- "comet_model_2.log_figure(figure=plt)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "ygh2yYC972ne"
- },
- "source": [
- "It is! Let's visualize the classification results on the MNIST dataset. We will plot images from the test dataset along with their predicted label, as well as a histogram that provides the prediction probabilities for each of the digits:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "HV5jw-5HwSmO"
- },
- "outputs": [],
- "source": [
- "#@title Change the slider to look at the model's predictions! { run: \"auto\" }\n",
- "\n",
- "image_index = 79 #@param {type:\"slider\", min:0, max:100, step:1}\n",
- "plt.subplot(1,2,1)\n",
- "mdl.lab2.plot_image_prediction(image_index, predictions, test_labels, test_images)\n",
- "plt.subplot(1,2,2)\n",
- "mdl.lab2.plot_value_prediction(image_index, predictions, test_labels)\n",
- "comet_model_2.log_figure(figure=plt)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "kgdvGD52CaXR"
- },
- "source": [
- "We can also plot several images along with their predictions, where correct prediction labels are blue and incorrect prediction labels are grey. The number gives the percent confidence (out of 100) for the predicted label. Note the model can be very confident in an incorrect prediction!"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "hQlnbqaw2Qu_"
- },
- "outputs": [],
- "source": [
- "# Plots the first X test images, their predicted label, and the true label\n",
- "# Color correct predictions in blue, incorrect predictions in red\n",
- "num_rows = 5\n",
- "num_cols = 4\n",
- "num_images = num_rows*num_cols\n",
- "plt.figure(figsize=(2*2*num_cols, 2*num_rows))\n",
- "for i in range(num_images):\n",
- " plt.subplot(num_rows, 2*num_cols, 2*i+1)\n",
- " mdl.lab2.plot_image_prediction(i, predictions, test_labels, test_images)\n",
- " plt.subplot(num_rows, 2*num_cols, 2*i+2)\n",
- " mdl.lab2.plot_value_prediction(i, predictions, test_labels)\n",
- "comet_model_2.log_figure(figure=plt)\n",
- "comet_model_2.end()\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "k-2glsRiMdqa"
- },
- "source": [
- "## 1.4 Training the model 2.0\n",
- "\n",
- "Earlier in the lab, we used the [`fit`](https://www.tensorflow.org/api_docs/python/tf/keras/models/Sequential#fit) function call to train the model. This function is quite high-level and intuitive, which is really useful for simpler models. As you may be able to tell, this function abstracts away many details in the training call, and we have less control over training model, which could be useful in other contexts.\n",
- "\n",
- "As an alternative to this, we can use the [`tf.GradientTape`](https://www.tensorflow.org/api_docs/python/tf/GradientTape) class to record differentiation operations during training, and then call the [`tf.GradientTape.gradient`](https://www.tensorflow.org/api_docs/python/tf/GradientTape#gradient) function to actually compute the gradients. You may recall seeing this in Lab 1 Part 1, but let's take another look at this here.\n",
- "\n",
- "We'll use this framework to train our `cnn_model` using stochastic gradient descent."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "Wq34id-iN1Ml"
- },
- "outputs": [],
- "source": [
- "# Rebuild the CNN model\n",
- "cnn_model = build_cnn_model()\n",
- "\n",
- "batch_size = 12\n",
- "loss_history = mdl.util.LossHistory(smoothing_factor=0.95) # to record the evolution of the loss\n",
- "plotter = mdl.util.PeriodicPlotter(sec=2, xlabel='Iterations', ylabel='Loss', scale='semilogy')\n",
- "optimizer = tf.keras.optimizers.SGD(learning_rate=1e-2) # define our optimizer\n",
- "\n",
- "comet_ml.init(project_name=\"6.s191lab2_part1_CNN2\")\n",
- "comet_model_3 = comet_ml.Experiment()\n",
- "\n",
- "if hasattr(tqdm, '_instances'): tqdm._instances.clear() # clear if it exists\n",
- "\n",
- "for idx in tqdm(range(0, train_images.shape[0], batch_size)):\n",
- " # First grab a batch of training data and convert the input images to tensors\n",
- " (images, labels) = (train_images[idx:idx+batch_size], train_labels[idx:idx+batch_size])\n",
- " images = tf.convert_to_tensor(images, dtype=tf.float32)\n",
- "\n",
- " # GradientTape to record differentiation operations\n",
- " with tf.GradientTape() as tape:\n",
- " #'''TODO: feed the images into the model and obtain the predictions'''\n",
- " logits = # TODO\n",
- "\n",
- " #'''TODO: compute the categorical cross entropy loss\n",
- " loss_value = tf.keras.backend.sparse_categorical_crossentropy('''TODO''', '''TODO''') # TODO\n",
- " comet_model_3.log_metric(\"loss\", loss_value.numpy().mean(), step=idx)\n",
- "\n",
- " loss_history.append(loss_value.numpy().mean()) # append the loss to the loss_history record\n",
- " plotter.plot(loss_history.get())\n",
- "\n",
- " # Backpropagation\n",
- " '''TODO: Use the tape to compute the gradient against all parameters in the CNN model.\n",
- " Use cnn_model.trainable_variables to access these parameters.'''\n",
- " grads = # TODO\n",
- " optimizer.apply_gradients(zip(grads, cnn_model.trainable_variables))\n",
- "\n",
- "comet_model_3.log_figure(figure=plt)\n",
- "comet_model_3.end()\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "3cNtDhVaqEdR"
- },
- "source": [
- "## 1.5 Conclusion\n",
- "In this part of the lab, you had the chance to play with different MNIST classifiers with different architectures (fully-connected layers only, CNN), and experiment with how different hyperparameters affect accuracy (learning rate, etc.). The next part of the lab explores another application of CNNs, facial detection, and some drawbacks of AI systems in real world applications, like issues of bias."
- ]
- }
- ],
- "metadata": {
- "accelerator": "GPU",
- "colab": {
- "collapsed_sections": [
- "Xmf_JRJa_N8C"
- ],
- "name": "TF_Part1_MNIST.ipynb",
- "provenance": []
- },
- "kernelspec": {
- "display_name": "Python 3",
- "name": "python3"
- },
- "language_info": {
- "codemirror_mode": {
- "name": "ipython",
- "version": 3
- },
- "file_extension": ".py",
- "mimetype": "text/x-python",
- "name": "python",
- "nbconvert_exporter": "python",
- "pygments_lexer": "ipython3",
- "version": "3.9.6"
- }
- },
- "nbformat": 4,
- "nbformat_minor": 0
-}
diff --git a/lab2/TF_Part2_Debiasing.ipynb b/lab2/TF_Part2_Debiasing.ipynb
deleted file mode 100644
index 494b74c7..00000000
--- a/lab2/TF_Part2_Debiasing.ipynb
+++ /dev/null
@@ -1,1147 +0,0 @@
-{
- "nbformat": 4,
- "nbformat_minor": 0,
- "metadata": {
- "colab": {
- "name": "TF_Part2_Debiasing.ipynb",
- "provenance": [],
- "collapsed_sections": [
- "Ag_e7xtTzT1W",
- "NDj7KBaW8Asz"
- ]
- },
- "kernelspec": {
- "name": "python3",
- "display_name": "Python 3"
- },
- "accelerator": "GPU"
- },
- "cells": [
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Ag_e7xtTzT1W"
- },
- "source": [
- "\n",
- "\n",
- "# Copyright Information"
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "rNbf1pRlSDby"
- },
- "source": [
- "# Copyright 2025 MIT 6.S191 Introduction to Deep Learning. All Rights Reserved.\n",
- "#\n",
- "# Licensed under the MIT License. You may not use this file except in compliance\n",
- "# with the License. Use and/or modification of this code outside of 6.S191 must\n",
- "# reference:\n",
- "#\n",
- "# © MIT 6.S191: Introduction to Deep Learning\n",
- "# http://introtodeeplearning.com\n",
- "#"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "QOpPUH3FR179"
- },
- "source": [
- "# Laboratory 2: Computer Vision\n",
- "\n",
- "# Part 2: Debiasing Facial Detection Systems\n",
- "\n",
- "In the second portion of the lab, we'll explore two prominent aspects of applied deep learning: facial detection and algorithmic bias.\n",
- "\n",
- "Deploying fair, unbiased AI systems is critical to their long-term acceptance. Consider the task of facial detection: given an image, is it an image of a face? This seemingly simple, but extremely important, task is subject to significant amounts of algorithmic bias among select demographics.\n",
- "\n",
- "In this lab, we'll investigate [one recently published approach](http://introtodeeplearning.com/AAAI_MitigatingAlgorithmicBias.pdf) to addressing algorithmic bias. We'll build a facial detection model that learns the *latent variables* underlying face image datasets and uses this to adaptively re-sample the training data, thus mitigating any biases that may be present in order to train a *debiased* model.\n",
- "\n",
- "\n",
- "Run the next code block for a short video from Google that explores how and why it's important to consider bias when thinking about machine learning:"
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "XQh5HZfbupFF"
- },
- "source": [
- "import IPython\n",
- "IPython.display.YouTubeVideo('59bMh59JQDo')"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "3Ezfc6Yv6IhI"
- },
- "source": [
- "Let's get started by installing the relevant dependencies.\n",
- "\n",
- "We will be using Comet ML to track our model development and training runs.\n",
- "\n",
- "1. Sign up for a Comet account: [HERE](https://www.comet.com/signup?utm_source=mit_dl&utm_medium=partner&utm_content=github)\n",
- "2. This will generate a personal API Key, which you can find either in the first 'Get Started with Comet' page, under your account settings, or by pressing the '?' in the top right corner and then 'Quickstart Guide'. Enter this API key as the global variable `COMET_API_KEY` below.\n",
- "\n"
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "E46sWVKK6LP9"
- },
- "source": [
- "!pip install comet_ml --quiet\n",
- "import comet_ml\n",
- "# TODO: ENTER YOUR API KEY HERE!! instructions above\n",
- "COMET_API_KEY = \"\"\n",
- "\n",
- "# Import Tensorflow 2.0\n",
- "import tensorflow as tf\n",
- "\n",
- "import IPython\n",
- "import functools\n",
- "import matplotlib.pyplot as plt\n",
- "import numpy as np\n",
- "from tqdm import tqdm\n",
- "\n",
- "# Download and import the MIT 6.S191 package\n",
- "!pip install mitdeeplearning --quiet\n",
- "import mitdeeplearning as mdl\n",
- "\n",
- "# Check that we are using a GPU, if not switch runtimes\n",
- "# using Runtime > Change Runtime Type > GPU\n",
- "assert len(tf.config.list_physical_devices('GPU')) > 0\n",
- "assert COMET_API_KEY != \"\", \"Please insert your Comet API Key\""
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "V0e77oOM3udR"
- },
- "source": [
- "## 2.1 Datasets\n",
- "\n",
- "We'll be using three datasets in this lab. In order to train our facial detection models, we'll need a dataset of positive examples (i.e., of faces) and a dataset of negative examples (i.e., of things that are not faces). We'll use these data to train our models to classify images as either faces or not faces. Finally, we'll need a test dataset of face images. Since we're concerned about the potential *bias* of our learned models against certain demographics, it's important that the test dataset we use has equal representation across the demographics or features of interest. In this lab, we'll consider skin tone and gender.\n",
- "\n",
- "1. **Positive training data**: [CelebA Dataset](http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html). A large-scale (over 200K images) of celebrity faces. \n",
- "2. **Negative training data**: [ImageNet](http://www.image-net.org/). Many images across many different categories. We'll take negative examples from a variety of non-human categories.\n",
- "[Fitzpatrick Scale](https://en.wikipedia.org/wiki/Fitzpatrick_scale) skin type classification system, with each image labeled as \"Lighter'' or \"Darker''.\n",
- "\n",
- "Let's begin by importing these datasets. We've written a class that does a bit of data pre-processing to import the training data in a usable format."
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "RWXaaIWy6jVw"
- },
- "source": [
- "# Get the training data: both images from CelebA and ImageNet\n",
- "path_to_training_data = tf.keras.utils.get_file('train_face.h5', 'https://www.dropbox.com/s/hlz8atheyozp1yx/train_face.h5?dl=1')\n",
- "# Instantiate a TrainingDatasetLoader using the downloaded dataset\n",
- "loader = mdl.lab2.TrainingDatasetLoader(path_to_training_data)"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "yIE321rxa_b3"
- },
- "source": [
- "We can look at the size of the training dataset and grab a batch of size 100:"
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "DjPSjZZ_bGqe"
- },
- "source": [
- "number_of_training_examples = loader.get_train_size()\n",
- "(images, labels) = loader.get_batch(100)"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "sxtkJoqF6oH1"
- },
- "source": [
- "Play around with displaying images to get a sense of what the training data actually looks like!"
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "Jg17jzwtbxDA"
- },
- "source": [
- "### Examining the CelebA training dataset ###\n",
- "\n",
- "#@title Change the sliders to look at positive and negative training examples! { run: \"auto\" }\n",
- "\n",
- "face_images = images[np.where(labels==1)[0]]\n",
- "not_face_images = images[np.where(labels==0)[0]]\n",
- "\n",
- "idx_face = 23 #@param {type:\"slider\", min:0, max:50, step:1}\n",
- "idx_not_face = 9 #@param {type:\"slider\", min:0, max:50, step:1}\n",
- "\n",
- "plt.figure(figsize=(5,5))\n",
- "plt.subplot(1, 2, 1)\n",
- "plt.imshow(face_images[idx_face])\n",
- "plt.title(\"Face\"); plt.grid(False)\n",
- "\n",
- "plt.subplot(1, 2, 2)\n",
- "plt.imshow(not_face_images[idx_not_face])\n",
- "plt.title(\"Not Face\"); plt.grid(False)"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "NDj7KBaW8Asz"
- },
- "source": [
- "### Thinking about bias\n",
- "\n",
- "Remember we'll be training our facial detection classifiers on the large, well-curated CelebA dataset (and ImageNet), and then evaluating their accuracy by testing them on an independent test dataset. Our goal is to build a model that trains on CelebA *and* achieves high classification accuracy on the the test dataset across all demographics, and to thus show that this model does not suffer from any hidden bias.\n",
- "\n",
- "What exactly do we mean when we say a classifier is biased? In order to formalize this, we'll need to think about [*latent variables*](https://en.wikipedia.org/wiki/Latent_variable), variables that define a dataset but are not strictly observed. As defined in the generative modeling lecture, we'll use the term *latent space* to refer to the probability distributions of the aforementioned latent variables. Putting these ideas together, we consider a classifier *biased* if its classification decision changes after it sees some additional latent features. This notion of bias may be helpful to keep in mind throughout the rest of the lab."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "AIFDvU4w8OIH"
- },
- "source": [
- "## 2.2 CNN for facial detection\n",
- "\n",
- "First, we'll define and train a CNN on the facial classification task, and evaluate its accuracy. Later, we'll evaluate the performance of our debiased models against this baseline CNN. The CNN model has a relatively standard architecture consisting of a series of convolutional layers with batch normalization followed by two fully connected layers to flatten the convolution output and generate a class prediction.\n",
- "\n",
- "### Define and train the CNN model\n",
- "\n",
- "Like we did in the first part of the lab, we'll define our CNN model, and then train on the CelebA and ImageNet datasets using the `tf.GradientTape` class and the `tf.GradientTape.gradient` method."
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "82EVTAAW7B_X"
- },
- "source": [
- "### Define the CNN model ###\n",
- "\n",
- "n_filters = 12 # base number of convolutional filters\n",
- "\n",
- "'''Function to define a standard CNN model'''\n",
- "def make_standard_classifier(n_outputs=1):\n",
- " Conv2D = functools.partial(tf.keras.layers.Conv2D, padding='same', activation='relu')\n",
- " BatchNormalization = tf.keras.layers.BatchNormalization\n",
- " Flatten = tf.keras.layers.Flatten\n",
- " Dense = functools.partial(tf.keras.layers.Dense, activation='relu')\n",
- "\n",
- " model = tf.keras.Sequential([\n",
- " Conv2D(filters=1*n_filters, kernel_size=5, strides=2),\n",
- " BatchNormalization(),\n",
- "\n",
- " Conv2D(filters=2*n_filters, kernel_size=5, strides=2),\n",
- " BatchNormalization(),\n",
- "\n",
- " Conv2D(filters=4*n_filters, kernel_size=3, strides=2),\n",
- " BatchNormalization(),\n",
- "\n",
- " Conv2D(filters=6*n_filters, kernel_size=3, strides=2),\n",
- " BatchNormalization(),\n",
- "\n",
- " Flatten(),\n",
- " Dense(512),\n",
- " Dense(n_outputs, activation=None),\n",
- " ])\n",
- " return model\n",
- "\n",
- "standard_classifier = make_standard_classifier()"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "c-eWf3l_lCri"
- },
- "source": [
- "Now let's train the standard CNN!"
- ]
- },
- {
- "cell_type": "code",
- "source": [
- "### Create a Comet experiment to track our training run ###\n",
- "def create_experiment(project_name, params):\n",
- " # end any prior experiments\n",
- " if 'experiment' in locals():\n",
- " experiment.end()\n",
- "\n",
- " # initiate the comet experiment for tracking\n",
- " experiment = comet_ml.Experiment(\n",
- " api_key=COMET_API_KEY,\n",
- " project_name=project_name)\n",
- " # log our hyperparameters, defined above, to the experiment\n",
- " for param, value in params.items():\n",
- " experiment.log_parameter(param, value)\n",
- " experiment.flush()\n",
- "\n",
- " return experiment\n"
- ],
- "metadata": {
- "id": "mi-04SAfK6lm"
- },
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "eJlDGh1o31G1"
- },
- "source": [
- "### Train the standard CNN ###\n",
- "\n",
- "# Training hyperparameters\n",
- "params = dict(\n",
- " batch_size = 32,\n",
- " num_epochs = 2, # keep small to run faster\n",
- " learning_rate = 5e-4,\n",
- ")\n",
- "\n",
- "experiment = create_experiment(\"6S191_Lab2_Part2_CNN\", params)\n",
- "\n",
- "optimizer = tf.keras.optimizers.Adam(params[\"learning_rate\"]) # define our optimizer\n",
- "loss_history = mdl.util.LossHistory(smoothing_factor=0.99) # to record loss evolution\n",
- "plotter = mdl.util.PeriodicPlotter(sec=2, scale='semilogy')\n",
- "if hasattr(tqdm, '_instances'): tqdm._instances.clear() # clear if it exists\n",
- "\n",
- "@tf.function\n",
- "def standard_train_step(x, y):\n",
- " with tf.GradientTape() as tape:\n",
- " # feed the images into the model\n",
- " logits = standard_classifier(x)\n",
- " # Compute the loss\n",
- " loss = tf.nn.sigmoid_cross_entropy_with_logits(labels=y, logits=logits)\n",
- "\n",
- " # Backpropagation\n",
- " grads = tape.gradient(loss, standard_classifier.trainable_variables)\n",
- " optimizer.apply_gradients(zip(grads, standard_classifier.trainable_variables))\n",
- " return loss\n",
- "\n",
- "# The training loop!\n",
- "step = 0\n",
- "for epoch in range(params[\"num_epochs\"]):\n",
- " for idx in tqdm(range(loader.get_train_size()//params[\"batch_size\"])):\n",
- " # Grab a batch of training data and propagate through the network\n",
- " x, y = loader.get_batch(params[\"batch_size\"])\n",
- " loss = standard_train_step(x, y)\n",
- "\n",
- " # Record the loss and plot the evolution of the loss as a function of training\n",
- " loss_history.append(loss.numpy().mean())\n",
- " plotter.plot(loss_history.get())\n",
- "\n",
- " experiment.log_metric(\"loss\", loss.numpy().mean(), step=step)\n",
- " step += 1"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "AKMdWVHeCxj8"
- },
- "source": [
- "### Evaluate performance of the standard CNN\n",
- "\n",
- "Next, let's evaluate the classification performance of our CelebA-trained standard CNN on the training dataset.\n"
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "35-PDgjdWk6_"
- },
- "source": [
- "### Evaluation of standard CNN ###\n",
- "\n",
- "# TRAINING DATA\n",
- "# Evaluate on a subset of CelebA+Imagenet\n",
- "(batch_x, batch_y) = loader.get_batch(5000)\n",
- "y_pred_standard = tf.round(tf.nn.sigmoid(standard_classifier.predict(batch_x)))\n",
- "acc_standard = tf.reduce_mean(tf.cast(tf.equal(batch_y, y_pred_standard), tf.float32))\n",
- "\n",
- "print(\"Standard CNN accuracy on (potentially biased) training set: {:.4f}\".format(acc_standard.numpy()))"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Qu7R14KaEEvU"
- },
- "source": [
- "We will also evaluate our networks on an independent test dataset containing faces that were not seen during training. For the test data, we'll look at the classification accuracy across four different demographics, based on the Fitzpatrick skin scale and sex-based labels: dark-skinned male, dark-skinned female, light-skinned male, and light-skinned female.\n",
- "\n",
- "Let's take a look at some sample faces in the test set."
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "vfDD8ztGWk6x"
- },
- "source": [
- "### Load test dataset and plot examples ###\n",
- "\n",
- "test_faces = mdl.lab2.get_test_faces()\n",
- "keys = [\"Light Female\", \"Light Male\", \"Dark Female\", \"Dark Male\"]\n",
- "for group, key in zip(test_faces,keys):\n",
- " plt.figure(figsize=(5,5))\n",
- " plt.imshow(np.hstack(group))\n",
- " plt.title(key, fontsize=15)"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "uo1z3cdbEUMM"
- },
- "source": [
- "Now, let's evaluate the probability of each of these face demographics being classified as a face using the standard CNN classifier we've just trained."
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "GI4O0Y1GAot9"
- },
- "source": [
- "### Evaluate the standard CNN on the test data ###\n",
- "\n",
- "standard_classifier_logits = [standard_classifier(np.array(x, dtype=np.float32)) for x in test_faces]\n",
- "standard_classifier_probs = tf.squeeze(tf.sigmoid(standard_classifier_logits))\n",
- "\n",
- "# Plot the prediction accuracies per demographic\n",
- "xx = range(len(keys))\n",
- "yy = standard_classifier_probs.numpy().mean(1)\n",
- "plt.bar(xx, yy)\n",
- "plt.xticks(xx, keys)\n",
- "plt.ylim(max(0,yy.min()-yy.ptp()/2.), yy.max()+yy.ptp()/2.)\n",
- "plt.title(\"Standard classifier predictions\");"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "j0Cvvt90DoAm"
- },
- "source": [
- "Take a look at the accuracies for this first model across these four groups. What do you observe? Would you consider this model biased or unbiased? What are some reasons why a trained model may have biased accuracies?"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "0AKcHnXVtgqJ"
- },
- "source": [
- "## 2.3 Mitigating algorithmic bias\n",
- "\n",
- "Imbalances in the training data can result in unwanted algorithmic bias. For example, the majority of faces in CelebA (our training set) are those of light-skinned females. As a result, a classifier trained on CelebA will be better suited at recognizing and classifying faces with features similar to these, and will thus be biased.\n",
- "\n",
- "How could we overcome this? A naive solution -- and one that is being adopted by many companies and organizations -- would be to annotate different subclasses (i.e., light-skinned females, males with hats, etc.) within the training data, and then manually even out the data with respect to these groups.\n",
- "\n",
- "But this approach has two major disadvantages. First, it requires annotating massive amounts of data, which is not scalable. Second, it requires that we know what potential biases (e.g., race, gender, pose, occlusion, hats, glasses, etc.) to look for in the data. As a result, manual annotation may not capture all the different features that are imbalanced within the training data.\n",
- "\n",
- "Instead, let's actually **learn** these features in an unbiased, unsupervised manner, without the need for any annotation, and then train a classifier fairly with respect to these features. In the rest of this lab, we'll do exactly that."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "nLemS7dqECsI"
- },
- "source": [
- "## 2.4 Variational autoencoder (VAE) for learning latent structure\n",
- "\n",
- "As you saw, the accuracy of the CNN varies across the four demographics we looked at. To think about why this may be, consider the dataset the model was trained on, CelebA. If certain features, such as dark skin or hats, are *rare* in CelebA, the model may end up biased against these as a result of training with a biased dataset. That is to say, its classification accuracy will be worse on faces that have under-represented features, such as dark-skinned faces or faces with hats, relevative to faces with features well-represented in the training data! This is a problem.\n",
- "\n",
- "Our goal is to train a *debiased* version of this classifier -- one that accounts for potential disparities in feature representation within the training data. Specifically, to build a debiased facial classifier, we'll train a model that **learns a representation of the underlying latent space** to the face training data. The model then uses this information to mitigate unwanted biases by sampling faces with rare features, like dark skin or hats, *more frequently* during training. The key design requirement for our model is that it can learn an *encoding* of the latent features in the face data in an entirely *unsupervised* way. To achieve this, we'll turn to variational autoencoders (VAEs).\n",
- "\n",
- "\n",
- "\n",
- "As shown in the schematic above and in Lecture 4, VAEs rely on an encoder-decoder structure to learn a latent representation of the input data. In the context of computer vision, the encoder network takes in input images, encodes them into a series of variables defined by a mean and standard deviation, and then draws from the distributions defined by these parameters to generate a set of sampled latent variables. The decoder network then \"decodes\" these variables to generate a reconstruction of the original image, which is used during training to help the model identify which latent variables are important to learn.\n",
- "\n",
- "Let's formalize two key aspects of the VAE model and define relevant functions for each.\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "KmbXKtcPkTXA"
- },
- "source": [
- "### Understanding VAEs: loss function\n",
- "\n",
- "In practice, how can we train a VAE? In learning the latent space, we constrain the means and standard deviations to approximately follow a unit Gaussian. Recall that these are learned parameters, and therefore must factor into the loss computation, and that the decoder portion of the VAE is using these parameters to output a reconstruction that should closely match the input image, which also must factor into the loss. What this means is that we'll have two terms in our VAE loss function:\n",
- "\n",
- "1. **Latent loss ($L_{KL}$)**: measures how closely the learned latent variables match a unit Gaussian and is defined by the Kullback-Leibler (KL) divergence.\n",
- "2. **Reconstruction loss ($L_{x}{(x,\\hat{x})}$)**: measures how accurately the reconstructed outputs match the input and is given by the $L^1$ norm of the input image and its reconstructed output."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Ux3jK2wc153s"
- },
- "source": [
- "The equation for the latent loss is provided by:\n",
- "\n",
- "$$L_{KL}(\\mu, \\sigma) = \\frac{1}{2}\\sum_{j=0}^{k-1} (\\sigma_j + \\mu_j^2 - 1 - \\log{\\sigma_j})$$\n",
- "\n",
- "The equation for the reconstruction loss is provided by:\n",
- "\n",
- "$$L_{x}{(x,\\hat{x})} = ||x-\\hat{x}||_1$$\n",
- "\n",
- "Thus for the VAE loss we have:\n",
- "\n",
- "$$L_{VAE} = c\\cdot L_{KL} + L_{x}{(x,\\hat{x})}$$\n",
- "\n",
- "where $c$ is a weighting coefficient used for regularization. Now we're ready to define our VAE loss function:"
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "S00ASo1ImSuh"
- },
- "source": [
- "### Defining the VAE loss function ###\n",
- "\n",
- "''' Function to calculate VAE loss given:\n",
- " an input x,\n",
- " reconstructed output x_recon,\n",
- " encoded means mu,\n",
- " encoded log of standard deviation logsigma,\n",
- " weight parameter for the latent loss kl_weight\n",
- "'''\n",
- "def vae_loss_function(x, x_recon, mu, logsigma, kl_weight=0.0005):\n",
- " # TODO: Define the latent loss. Note this is given in the equation for L_{KL}\n",
- " # in the text block directly above\n",
- " latent_loss = # TODO\n",
- "\n",
- " # TODO: Define the reconstruction loss as the mean absolute pixel-wise\n",
- " # difference between the input and reconstruction. Hint: you'll need to\n",
- " # use tf.reduce_mean, and supply an axis argument which specifies which\n",
- " # dimensions to reduce over. For example, reconstruction loss needs to average\n",
- " # over the height, width, and channel image dimensions.\n",
- " # https://www.tensorflow.org/api_docs/python/tf/math/reduce_mean\n",
- " reconstruction_loss = # TODO\n",
- "\n",
- " # TODO: Define the VAE loss. Note this is given in the equation for L_{VAE}\n",
- " # in the text block directly above\n",
- " vae_loss = # TODO\n",
- "\n",
- " return vae_loss"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "E8mpb3pJorpu"
- },
- "source": [
- "Great! Now that we have a more concrete sense of how VAEs work, let's explore how we can leverage this network structure to train a *debiased* facial classifier."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "DqtQH4S5fO8F"
- },
- "source": [
- "### Understanding VAEs: reparameterization\n",
- "\n",
- "As you may recall from lecture, VAEs use a \"reparameterization trick\" for sampling learned latent variables. Instead of the VAE encoder generating a single vector of real numbers for each latent variable, it generates a vector of means and a vector of standard deviations that are constrained to roughly follow Gaussian distributions. We then sample from the standard deviations and add back the mean to output this as our sampled latent vector. Formalizing this for a latent variable $z$ where we sample $\\epsilon \\sim N(0,(I))$ we have:\n",
- "\n",
- "$$z = \\mu + e^{\\left(\\frac{1}{2} \\cdot \\log{\\Sigma}\\right)}\\circ \\epsilon$$\n",
- "\n",
- "where $\\mu$ is the mean and $\\Sigma$ is the covariance matrix. This is useful because it will let us neatly define the loss function for the VAE, generate randomly sampled latent variables, achieve improved network generalization, **and** make our complete VAE network differentiable so that it can be trained via backpropagation. Quite powerful!\n",
- "\n",
- "Let's define a function to implement the VAE sampling operation:"
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "cT6PGdNajl3K"
- },
- "source": [
- "### VAE Reparameterization ###\n",
- "\n",
- "\"\"\"Reparameterization trick by sampling from an isotropic unit Gaussian.\n",
- "# Arguments\n",
- " z_mean, z_logsigma (tensor): mean and log of standard deviation of latent distribution (Q(z|X))\n",
- "# Returns\n",
- " z (tensor): sampled latent vector\n",
- "\"\"\"\n",
- "def sampling(z_mean, z_logsigma):\n",
- " # By default, random.normal is \"standard\" (ie. mean=0 and std=1.0)\n",
- " batch, latent_dim = z_mean.shape\n",
- " epsilon = tf.random.normal(shape=(batch, latent_dim))\n",
- "\n",
- " # TODO: Define the reparameterization computation!\n",
- " # Note the equation is given in the text block immediately above.\n",
- " z = # TODO\n",
- "\n",
- " return z"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "qtHEYI9KNn0A"
- },
- "source": [
- "## 2.5 Debiasing variational autoencoder (DB-VAE)\n",
- "\n",
- "Now, we'll use the general idea behind the VAE architecture to build a model, termed a [*debiasing variational autoencoder*](https://lmrt.mit.edu/sites/default/files/AIES-19_paper_220.pdf) or DB-VAE, to mitigate (potentially) unknown biases present within the training idea. We'll train our DB-VAE model on the facial detection task, run the debiasing operation during training, evaluate on the PPB dataset, and compare its accuracy to our original, biased CNN model. \n",
- "\n",
- "### The DB-VAE model\n",
- "\n",
- "The key idea behind this debiasing approach is to use the latent variables learned via a VAE to adaptively re-sample the CelebA data during training. Specifically, we will alter the probability that a given image is used during training based on how often its latent features appear in the dataset. So, faces with rarer features (like dark skin, sunglasses, or hats) should become more likely to be sampled during training, while the sampling probability for faces with features that are over-represented in the training dataset should decrease (relative to uniform random sampling across the training data).\n",
- "\n",
- "A general schematic of the DB-VAE approach is shown here:\n",
- "\n",
- ""
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "ziA75SN-UxxO"
- },
- "source": [
- "Recall that we want to apply our DB-VAE to a *supervised classification* problem -- the facial detection task. Importantly, note how the encoder portion in the DB-VAE architecture also outputs a single supervised variable, $z_o$, corresponding to the class prediction -- face or not face. Usually, VAEs are not trained to output any supervised variables (such as a class prediction)! This is another key distinction between the DB-VAE and a traditional VAE.\n",
- "\n",
- "Keep in mind that we only want to learn the latent representation of *faces*, as that's what we're ultimately debiasing against, even though we are training a model on a binary classification problem. We'll need to ensure that, **for faces**, our DB-VAE model both learns a representation of the unsupervised latent variables, captured by the distribution $q_\\phi(z|x)$, **and** outputs a supervised class prediction $z_o$, but that, **for negative examples**, it only outputs a class prediction $z_o$."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "XggIKYPRtOZR"
- },
- "source": [
- "### Defining the DB-VAE loss function\n",
- "\n",
- "This means we'll need to be a bit clever about the loss function for the DB-VAE. The form of the loss will depend on whether it's a face image or a non-face image that's being considered.\n",
- "\n",
- "For **face images**, our loss function will have two components:\n",
- "\n",
- "\n",
- "1. **VAE loss ($L_{VAE}$)**: consists of the latent loss and the reconstruction loss.\n",
- "2. **Classification loss ($L_y(y,\\hat{y})$)**: standard cross-entropy loss for a binary classification problem.\n",
- "\n",
- "In contrast, for images of **non-faces**, our loss function is solely the classification loss.\n",
- "\n",
- "We can write a single expression for the loss by defining an indicator variable ${I}_f$which reflects which training data are images of faces (${I}_f(y) = 1$ ) and which are images of non-faces (${I}_f(y) = 0$). Using this, we obtain:\n",
- "\n",
- "$$L_{total} = L_y(y,\\hat{y}) + {I}_f(y)\\Big[L_{VAE}\\Big]$$\n",
- "\n",
- "Let's write a function to define the DB-VAE loss function:\n"
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "VjieDs8Ovcqs"
- },
- "source": [
- "### Loss function for DB-VAE ###\n",
- "\n",
- "\"\"\"Loss function for DB-VAE.\n",
- "# Arguments\n",
- " x: true input x\n",
- " x_pred: reconstructed x\n",
- " y: true label (face or not face)\n",
- " y_logit: predicted labels\n",
- " mu: mean of latent distribution (Q(z|X))\n",
- " logsigma: log of standard deviation of latent distribution (Q(z|X))\n",
- "# Returns\n",
- " total_loss: DB-VAE total loss\n",
- " classification_loss = DB-VAE classification loss\n",
- "\"\"\"\n",
- "def debiasing_loss_function(x, x_pred, y, y_logit, mu, logsigma):\n",
- "\n",
- " # TODO: call the relevant function to obtain VAE loss\n",
- " vae_loss = vae_loss_function('''TODO''') # TODO\n",
- "\n",
- " # TODO: define the classification loss using sigmoid_cross_entropy\n",
- " # https://www.tensorflow.org/api_docs/python/tf/nn/sigmoid_cross_entropy_with_logits\n",
- " classification_loss = # TODO\n",
- "\n",
- " # Use the training data labels to create variable face_indicator:\n",
- " # indicator that reflects which training data are images of faces\n",
- " face_indicator = tf.cast(tf.equal(y, 1), tf.float32)\n",
- "\n",
- " # TODO: define the DB-VAE total loss! Use tf.reduce_mean to average over all\n",
- " # samples\n",
- " total_loss = # TODO\n",
- "\n",
- " return total_loss, classification_loss"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "YIu_2LzNWwWY"
- },
- "source": [
- "### DB-VAE architecture\n",
- "\n",
- "Now we're ready to define the DB-VAE architecture. To build the DB-VAE, we will use the standard CNN classifier from above as our encoder, and then define a decoder network. We will create and initialize the two models, and then construct the end-to-end VAE. We will use a latent space with 100 latent variables.\n",
- "\n",
- "The decoder network will take as input the sampled latent variables, run them through a series of deconvolutional layers, and output a reconstruction of the original input image."
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "JfWPHGrmyE7R"
- },
- "source": [
- "### Define the decoder portion of the DB-VAE ###\n",
- "\n",
- "n_filters = 12 # base number of convolutional filters, same as standard CNN\n",
- "latent_dim = 100 # number of latent variables\n",
- "\n",
- "def make_face_decoder_network():\n",
- " # Functionally define the different layer types we will use\n",
- " Conv2DTranspose = functools.partial(tf.keras.layers.Conv2DTranspose, padding='same', activation='relu')\n",
- " BatchNormalization = tf.keras.layers.BatchNormalization\n",
- " Flatten = tf.keras.layers.Flatten\n",
- " Dense = functools.partial(tf.keras.layers.Dense, activation='relu')\n",
- " Reshape = tf.keras.layers.Reshape\n",
- "\n",
- " # Build the decoder network using the Sequential API\n",
- " decoder = tf.keras.Sequential([\n",
- " # Transform to pre-convolutional generation\n",
- " Dense(units=4*4*6*n_filters), # 4x4 feature maps (with 6N occurances)\n",
- " Reshape(target_shape=(4, 4, 6*n_filters)),\n",
- "\n",
- " # Upscaling convolutions (inverse of encoder)\n",
- " Conv2DTranspose(filters=4*n_filters, kernel_size=3, strides=2),\n",
- " Conv2DTranspose(filters=2*n_filters, kernel_size=3, strides=2),\n",
- " Conv2DTranspose(filters=1*n_filters, kernel_size=5, strides=2),\n",
- " Conv2DTranspose(filters=3, kernel_size=5, strides=2),\n",
- " ])\n",
- "\n",
- " return decoder"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "yWCMu12w1BuD"
- },
- "source": [
- "Now, we will put this decoder together with the standard CNN classifier as our encoder to define the DB-VAE. Note that at this point, there is nothing special about how we put the model together that makes it a \"debiasing\" model -- that will come when we define the training operation. Here, we will define the core VAE architecture by sublassing the `Model` class; defining encoding, reparameterization, and decoding operations; and calling the network end-to-end."
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "dSFDcFBL13c3"
- },
- "source": [
- "### Defining and creating the DB-VAE ###\n",
- "\n",
- "class DB_VAE(tf.keras.Model):\n",
- " def __init__(self, latent_dim):\n",
- " super(DB_VAE, self).__init__()\n",
- " self.latent_dim = latent_dim\n",
- "\n",
- " # Define the number of outputs for the encoder. Recall that we have\n",
- " # `latent_dim` latent variables, as well as a supervised output for the\n",
- " # classification.\n",
- " num_encoder_dims = 2*self.latent_dim + 1\n",
- "\n",
- " self.encoder = make_standard_classifier(num_encoder_dims)\n",
- " self.decoder = make_face_decoder_network()\n",
- "\n",
- " # function to feed images into encoder, encode the latent space, and output\n",
- " # classification probability\n",
- " def encode(self, x):\n",
- " # encoder output\n",
- " encoder_output = self.encoder(x)\n",
- "\n",
- " # classification prediction\n",
- " y_logit = tf.expand_dims(encoder_output[:, 0], -1)\n",
- "\n",
- " # latent variable distribution parameters\n",
- " z_mean = encoder_output[:, 1:self.latent_dim+1]\n",
- " z_logsigma = encoder_output[:, self.latent_dim+1:]\n",
- "\n",
- " return y_logit, z_mean, z_logsigma\n",
- "\n",
- " # VAE reparameterization: given a mean and logsigma, sample latent variables\n",
- " def reparameterize(self, z_mean, z_logsigma):\n",
- " # TODO: call the sampling function defined above\n",
- " z = # TODO\n",
- " return z\n",
- "\n",
- " # Decode the latent space and output reconstruction\n",
- " def decode(self, z):\n",
- " # TODO: use the decoder to output the reconstruction\n",
- " reconstruction = # TODO\n",
- " return reconstruction\n",
- "\n",
- " # The call function will be used to pass inputs x through the core VAE\n",
- " def call(self, x):\n",
- " # Encode input to a prediction and latent space\n",
- " y_logit, z_mean, z_logsigma = self.encode(x)\n",
- "\n",
- " # TODO: reparameterization\n",
- " z = # TODO\n",
- "\n",
- " # TODO: reconstruction\n",
- " recon = # TODO\n",
- " return y_logit, z_mean, z_logsigma, recon\n",
- "\n",
- " # Predict face or not face logit for given input x\n",
- " def predict(self, x):\n",
- " y_logit, z_mean, z_logsigma = self.encode(x)\n",
- " return y_logit\n",
- "\n",
- "dbvae = DB_VAE(latent_dim)"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "M-clbYAj2waY"
- },
- "source": [
- "As stated, the encoder architecture is identical to the CNN from earlier in this lab. Note the outputs of our constructed DB_VAE model in the `call` function: `y_logit, z_mean, z_logsigma, z`. Think carefully about why each of these are outputted and their significance to the problem at hand.\n",
- "\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "nbDNlslgQc5A"
- },
- "source": [
- "### Adaptive resampling for automated debiasing with DB-VAE\n",
- "\n",
- "So, how can we actually use DB-VAE to train a debiased facial detection classifier?\n",
- "\n",
- "Recall the DB-VAE architecture: as input images are fed through the network, the encoder learns an estimate ${Q}(z|X)$ of the latent space. We want to increase the relative frequency of rare data by increased sampling of under-represented regions of the latent space. We can approximate ${Q}(z|X)$ using the frequency distributions of each of the learned latent variables, and then define the probability distribution of selecting a given datapoint $x$ based on this approximation. These probability distributions will be used during training to re-sample the data.\n",
- "\n",
- "You'll write a function to execute this update of the sampling probabilities, and then call this function within the DB-VAE training loop to actually debias the model."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Fej5FDu37cf7"
- },
- "source": [
- "First, we've defined a short helper function `get_latent_mu` that returns the latent variable means returned by the encoder after a batch of images is inputted to the network:"
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "ewWbf7TE7wVc"
- },
- "source": [
- "# Function to return the means for an input image batch\n",
- "def get_latent_mu(images, dbvae, batch_size=1024):\n",
- " N = images.shape[0]\n",
- " mu = np.zeros((N, latent_dim))\n",
- " for start_ind in range(0, N, batch_size):\n",
- " end_ind = min(start_ind+batch_size, N+1)\n",
- " batch = (images[start_ind:end_ind]).astype(np.float32)/255.\n",
- " _, batch_mu, _ = dbvae.encode(batch)\n",
- " mu[start_ind:end_ind] = batch_mu\n",
- " return mu"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "wn4yK3SC72bo"
- },
- "source": [
- "Now, let's define the actual resampling algorithm `get_training_sample_probabilities`. Importantly note the argument `smoothing_fac`. This parameter tunes the degree of debiasing: for `smoothing_fac=0`, the re-sampled training set will tend towards falling uniformly over the latent space, i.e., the most extreme debiasing."
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "HiX9pmmC7_wn"
- },
- "source": [
- "### Resampling algorithm for DB-VAE ###\n",
- "\n",
- "'''Function that recomputes the sampling probabilities for images within a batch\n",
- " based on how they distribute across the training data'''\n",
- "def get_training_sample_probabilities(images, dbvae, bins=10, smoothing_fac=0.001):\n",
- " print(\"Recomputing the sampling probabilities\")\n",
- "\n",
- " # TODO: run the input batch and get the latent variable means\n",
- " mu = get_latent_mu('''TODO''') # TODO\n",
- "\n",
- " # sampling probabilities for the images\n",
- " training_sample_p = np.zeros(mu.shape[0])\n",
- "\n",
- " # consider the distribution for each latent variable\n",
- " for i in range(latent_dim):\n",
- "\n",
- " latent_distribution = mu[:,i]\n",
- " # generate a histogram of the latent distribution\n",
- " hist_density, bin_edges = np.histogram(latent_distribution, density=True, bins=bins)\n",
- "\n",
- " # find which latent bin every data sample falls in\n",
- " bin_edges[0] = -float('inf')\n",
- " bin_edges[-1] = float('inf')\n",
- "\n",
- " # TODO: call the digitize function to find which bins in the latent distribution\n",
- " # every data sample falls in to\n",
- " # https://docs.scipy.org/doc/numpy-1.13.0/reference/generated/numpy.digitize.html\n",
- " bin_idx = np.digitize('''TODO''', '''TODO''') # TODO\n",
- "\n",
- " # smooth the density function\n",
- " hist_smoothed_density = hist_density + smoothing_fac\n",
- " hist_smoothed_density = hist_smoothed_density / np.sum(hist_smoothed_density)\n",
- "\n",
- " # invert the density function\n",
- " p = 1.0/(hist_smoothed_density[bin_idx-1])\n",
- "\n",
- " # TODO: normalize all probabilities\n",
- " p = # TODO\n",
- "\n",
- " # TODO: update sampling probabilities by considering whether the newly\n",
- " # computed p is greater than the existing sampling probabilities.\n",
- " training_sample_p = # TODO\n",
- "\n",
- " # final normalization\n",
- " training_sample_p /= np.sum(training_sample_p)\n",
- "\n",
- " return training_sample_p"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "pF14fQkVUs-a"
- },
- "source": [
- "Now that we've defined the resampling update, we can train our DB-VAE model on the CelebA/ImageNet training data, and run the above operation to re-weight the importance of particular data points as we train the model. Remember again that we only want to debias for features relevant to *faces*, not the set of negative examples. Complete the code block below to execute the training loop!"
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "xwQs-Gu5bKEK"
- },
- "source": [
- "### Training the DB-VAE ###\n",
- "\n",
- "# Hyperparameters\n",
- "params = dict(\n",
- " batch_size = 32,\n",
- " learning_rate = 5e-4,\n",
- " latent_dim = 100,\n",
- " num_epochs = 1, #DB-VAE needs slightly more epochs to train\n",
- ")\n",
- "\n",
- "experiment = create_experiment(\"6S191_Lab2_Part2_DBVAE\", params)\n",
- "\n",
- "# instantiate a new DB-VAE model and optimizer\n",
- "dbvae = DB_VAE(params[\"latent_dim\"])\n",
- "optimizer = tf.keras.optimizers.Adam(params[\"learning_rate\"])\n",
- "\n",
- "# To define the training operation, we will use tf.function which is a powerful tool\n",
- "# that lets us turn a Python function into a TensorFlow computation graph.\n",
- "@tf.function\n",
- "def debiasing_train_step(x, y):\n",
- "\n",
- " with tf.GradientTape() as tape:\n",
- " # Feed input x into dbvae. Note that this is using the DB_VAE call function!\n",
- " y_logit, z_mean, z_logsigma, x_recon = dbvae(x)\n",
- "\n",
- " '''TODO: call the DB_VAE loss function to compute the loss'''\n",
- " loss, class_loss = debiasing_loss_function('''TODO arguments''') # TODO\n",
- "\n",
- " '''TODO: use the GradientTape.gradient method to compute the gradients.\n",
- " Hint: this is with respect to the trainable_variables of the dbvae.'''\n",
- " grads = tape.gradient('''TODO''', '''TODO''') # TODO\n",
- "\n",
- " # apply gradients to variables\n",
- " optimizer.apply_gradients(zip(grads, dbvae.trainable_variables))\n",
- " return loss\n",
- "\n",
- "# get training faces from data loader\n",
- "all_faces = loader.get_all_train_faces()\n",
- "\n",
- "if hasattr(tqdm, '_instances'): tqdm._instances.clear() # clear if it exists\n",
- "\n",
- "# The training loop -- outer loop iterates over the number of epochs\n",
- "step = 0\n",
- "for i in range(params[\"num_epochs\"]):\n",
- "\n",
- " IPython.display.clear_output(wait=True)\n",
- " print(\"Starting epoch {}/{}\".format(i+1, params[\"num_epochs\"]))\n",
- "\n",
- " # Recompute data sampling proabilities\n",
- " '''TODO: recompute the sampling probabilities for debiasing'''\n",
- " p_faces = get_training_sample_probabilities('''TODO''', '''TODO''') # TODO\n",
- "\n",
- " # get a batch of training data and compute the training step\n",
- " for j in tqdm(range(loader.get_train_size() // params[\"batch_size\"])):\n",
- " # load a batch of data\n",
- " (x, y) = loader.get_batch(params[\"batch_size\"], p_pos=p_faces)\n",
- "\n",
- " # loss optimization\n",
- " loss = debiasing_train_step(x, y)\n",
- " experiment.log_metric(\"loss\", loss.numpy().mean(), step=step)\n",
- "\n",
- " # plot the progress every 200 steps\n",
- " if j % 500 == 0:\n",
- " mdl.util.plot_sample(x, y, dbvae)\n",
- "\n",
- " step += 1\n",
- "\n",
- "experiment.end()"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "uZBlWDPOVcHg"
- },
- "source": [
- "Wonderful! Now we should have a trained and (hopefully!) debiased facial classification model, ready for evaluation!"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Eo34xC7MbaiQ"
- },
- "source": [
- "## 2.6 Evaluation of DB-VAE on Test Dataset\n",
- "\n",
- "Finally let's test our DB-VAE model on the test dataset, looking specifically at its accuracy on each the \"Dark Male\", \"Dark Female\", \"Light Male\", and \"Light Female\" demographics. We will compare the performance of this debiased model against the (potentially biased) standard CNN from earlier in the lab."
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "bgK77aB9oDtX"
- },
- "source": [
- "dbvae_logits = [dbvae.predict(np.array(x, dtype=np.float32)) for x in test_faces]\n",
- "dbvae_probs = tf.squeeze(tf.sigmoid(dbvae_logits))\n",
- "\n",
- "xx = np.arange(len(keys))\n",
- "plt.bar(xx, standard_classifier_probs.numpy().mean(1), width=0.2, label=\"Standard CNN\")\n",
- "plt.bar(xx+0.2, dbvae_probs.numpy().mean(1), width=0.2, label=\"DB-VAE\")\n",
- "plt.xticks(xx, keys);\n",
- "plt.title(\"Network predictions on test dataset\")\n",
- "plt.ylabel(\"Probability\"); plt.legend(bbox_to_anchor=(1.04,1), loc=\"upper left\");\n"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "rESoXRPQo_mq"
- },
- "source": [
- "## 2.7 Conclusion and submission information\n",
- "\n",
- "We encourage you to think about and maybe even address some questions raised by the approach and results outlined here:\n",
- "\n",
- "* How does the accuracy of the DB-VAE across the four demographics compare to that of the standard CNN? Do you find this result surprising in any way?\n",
- "* How can the performance of the DB-VAE classifier be improved even further? We purposely did not optimize hyperparameters to leave this up to you!\n",
- "* In which applications (either related to facial detection or not!) would debiasing in this way be desired? Are there applications where you may not want to debias your model?\n",
- "* Do you think it should be necessary for companies to demonstrate that their models, particularly in the context of tasks like facial detection, are not biased? If so, do you have thoughts on how this could be standardized and implemented?\n",
- "* Do you have ideas for other ways to address issues of bias, particularly in terms of the training data?\n",
- "\n",
- "**Try to optimize your model to achieve improved performance. To enter the competition, please upload the following to the lab submission site for the Debiasing Faces Lab ([submission upload link](https://www.dropbox.com/request/dJZUEoqGLB43JEKzzqIc)).**\n",
- "\n",
- "* Jupyter notebook with the code you used to generate your results;\n",
- "* copy of the bar plot from section 2.6 showing the performance of your model;\n",
- "* a written description and/or diagram of the architecture and hyperparameters you used -- if there are any additional or interesting modifications you made to the template code, please include these in your description;\n",
- "* a written discussion of why these modifications helped improve performance.\n",
- "\n",
- "**Name your file in the following format: `[FirstName]_[LastName]_Face`, followed by the file format (.zip, .ipynb, .pdf, etc).** ZIP files are preferred over individual files. If you submit individual files, you must name the individual files according to the above nomenclature (e.g., `[FirstName]_[LastName]_Face_TODO.pdf`, `[FirstName]_[LastName]_Face_Report.pdf`, etc.).\n",
- "\n",
- "Hopefully this lab has shed some light on a few concepts, from vision based tasks, to VAEs, to algorithmic bias. We like to think it has, but we're biased ;).\n",
- "\n",
- "
\n",
- "\n",
- "\n",
- "\n",
- ""
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "rlaOqndqBmJo"
- },
- "source": [
- "### Define the RNN model\n",
- "\n",
- "Let's define our model as an `nn.Module`. Fill in the `TODOs` to define the RNN model.\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "8DsWzojvkbc7"
- },
- "outputs": [],
- "source": [
- "### Defining the RNN Model ###\n",
- "\n",
- "'''TODO: Add LSTM and Linear layers to define the RNN model using nn.Module'''\n",
- "class LSTMModel(nn.Module):\n",
- " def __init__(self, vocab_size, embedding_dim, hidden_size):\n",
- " super(LSTMModel, self).__init__()\n",
- " self.hidden_size = hidden_size\n",
- "\n",
- " # Define each of the network layers\n",
- " # Layer 1: Embedding layer to transform indices into dense vectors\n",
- " # of a fixed embedding size\n",
- " self.embedding = nn.Embedding(vocab_size, embedding_dim)\n",
- "\n",
- " # Layer 2: LSTM with hidden_size `hidden_size`. note: number of layers defaults to 1.\n",
- " # TODO: Use the nn.LSTM() module from pytorch.\n",
- " self.lstm = nn.LSTM(embedding_dim, hidden_size, batch_first=True)\n",
- " # self.lstm = nn.LSTM('''TODO''')\n",
- "\n",
- " # Layer 3: Linear (fully-connected) layer that transforms the LSTM output\n",
- " # into the vocabulary size.\n",
- " # TODO: Add the Linear layer.\n",
- " self.fc = nn.Linear(hidden_size, vocab_size)\n",
- " # self.fc = nn.Linear('''TODO''')\n",
- "\n",
- " def init_hidden(self, batch_size, device):\n",
- " # Initialize hidden state and cell state with zeros\n",
- " return (torch.zeros(1, batch_size, self.hidden_size).to(device),\n",
- " torch.zeros(1, batch_size, self.hidden_size).to(device))\n",
- "\n",
- " def forward(self, x, state=None, return_state=False):\n",
- " x = self.embedding(x)\n",
- "\n",
- " if state is None:\n",
- " state = self.init_hidden(x.size(0), x.device)\n",
- " out, state = self.lstm(x, state)\n",
- "\n",
- " out = self.fc(out)\n",
- " return out if not return_state else (out, state)\n",
- "\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "IbWU4dMJmMvq"
- },
- "source": [
- "The time has come! Let's instantiate the model!"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "MtCrdfzEI2N0"
- },
- "outputs": [],
- "source": [
- "# Instantiate the model! Build a simple model with default hyperparameters. You\n",
- "# will get the chance to change these later.\n",
- "vocab_size = len(vocab)\n",
- "embedding_dim = 256\n",
- "hidden_size = 1024\n",
- "batch_size = 8\n",
- "\n",
- "device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n",
- "\n",
- "model = LSTMModel(vocab_size, embedding_dim, hidden_size).to(device)\n",
- "\n",
- "# print out a summary of the model\n",
- "print(model)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "-ubPo0_9Prjb"
- },
- "source": [
- "### Test out the RNN model\n",
- "\n",
- "It's always a good idea to run a few simple checks on our model to see that it behaves as expected. \n",
- "\n",
- "We can quickly check the layers in the model, the shape of the output of each of the layers, the batch size, and the dimensionality of the output. Note that the model can be run on inputs of any length."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "C-_70kKAPrPU"
- },
- "outputs": [],
- "source": [
- "# Test the model with some sample data\n",
- "x, y = get_batch(vectorized_songs, seq_length=100, batch_size=32)\n",
- "x = x.to(device)\n",
- "y = y.to(device)\n",
- "\n",
- "pred = model(x)\n",
- "print(\"Input shape: \", x.shape, \" # (batch_size, sequence_length)\")\n",
- "print(\"Prediction shape: \", pred.shape, \"# (batch_size, sequence_length, vocab_size)\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "mT1HvFVUGpoE"
- },
- "source": [
- "### Predictions from the untrained model\n",
- "\n",
- "Let's take a look at what our untrained model is predicting.\n",
- "\n",
- "To get actual predictions from the model, we sample from the output distribution, which is defined by a torch.softmax over our character vocabulary. This will give us actual character indices. This means we are using a [categorical distribution](https://en.wikipedia.org/wiki/Categorical_distribution) to sample over the example prediction. This gives a prediction of the next character (specifically its index) at each timestep. [`torch.multinomial`](https://pytorch.org/docs/stable/generated/torch.multinomial.html#torch.multinomial) samples over a categorical distribution to generate predictions.\n",
- "\n",
- "Note here that we sample from this probability distribution, as opposed to simply taking the `argmax`, which can cause the model to get stuck in a repetitive loop.\n",
- "\n",
- "Let's try this sampling out for the first example in the batch."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "4V4MfFg0RQJg"
- },
- "outputs": [],
- "source": [
- "sampled_indices = torch.multinomial(torch.softmax(pred[0], dim=-1), num_samples=1)\n",
- "sampled_indices = sampled_indices.squeeze(-1).cpu().numpy()\n",
- "sampled_indices"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "LfLtsP3mUhCG"
- },
- "source": [
- "We can now decode these to see the text predicted by the untrained model:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "xWcFwPwLSo05"
- },
- "outputs": [],
- "source": [
- "print(\"Input: \\n\", repr(\"\".join(idx2char[x[0].cpu()])))\n",
- "print()\n",
- "print(\"Next Char Predictions: \\n\", repr(\"\".join(idx2char[sampled_indices])))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "HEHHcRasIDm9"
- },
- "source": [
- "As you can see, the text predicted by the untrained model is pretty nonsensical! How can we do better? Well, we can train the network!"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "LJL0Q0YPY6Ee"
- },
- "source": [
- "## 2.5 Training the model: loss and training operations\n",
- "\n",
- "Now it's time to train the model!\n",
- "\n",
- "At this point, we can think of our next character prediction problem as a standard classification problem. Given the previous state of the RNN, as well as the input at a given time step, we want to predict the class of the next character -- that is, to actually predict the next character.\n",
- "\n",
- "To train our model on this classification task, we can use a form of the `crossentropy` loss (i.e., negative log likelihood loss). Specifically, we will use PyTorch's [`CrossEntropyLoss`](https://pytorch.org/docs/stable/generated/torch.nn.CrossEntropyLoss.html), as it combines the application of a log-softmax ([`LogSoftmax`](https://pytorch.org/docs/stable/generated/torch.nn.LogSoftmax.html#torch.nn.LogSoftmax)) and negative log-likelihood ([`NLLLoss`](https://pytorch.org/docs/stable/generated/torch.nn.NLLLoss.html#torch.nn.NLLLoss) in a single class and accepts integer targets for categorical classification tasks. We will want to compute the loss using the true targets -- the `labels` -- and the predicted targets -- the `logits`.\n",
- "\n",
- "Let's define a function to compute the loss, and then use that function to compute the loss using our example predictions from the untrained model."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "4HrXTACTdzY-"
- },
- "outputs": [],
- "source": [
- "### Defining the loss function ###\n",
- "\n",
- "# '''TODO: define the compute_loss function to compute and return the loss between\n",
- "# the true labels and predictions (logits). '''\n",
- "cross_entropy = nn.CrossEntropyLoss() # instantiates the function\n",
- "def compute_loss(labels, logits):\n",
- " \"\"\"\n",
- " Inputs:\n",
- " labels: (batch_size, sequence_length)\n",
- " logits: (batch_size, sequence_length, vocab_size)\n",
- "\n",
- " Output:\n",
- " loss: scalar cross entropy loss over the batch and sequence length\n",
- " \"\"\"\n",
- "\n",
- " # Batch the labels so that the shape of the labels should be (B * L,)\n",
- " batched_labels = labels.view(-1)\n",
- "\n",
- " ''' TODO: Batch the logits so that the shape of the logits should be (B * L, V) '''\n",
- " batched_logits = logits.view(-1, logits.size(-1))\n",
- " # batched_logits = \"\"\" TODO \"\"\" # TODO\n",
- "\n",
- " '''TODO: Compute the cross-entropy loss using the batched next characters and predictions'''\n",
- " loss = cross_entropy(batched_logits, batched_labels)\n",
- " # loss = \"\"\" TODO \"\"\" # TODO\n",
- " return loss"
- ]
- },
- {
- "cell_type": "code",
- "source": [
- "### compute the loss on the predictions from the untrained model from earlier. ###\n",
- "y.shape # (batch_size, sequence_length)\n",
- "pred.shape # (batch_size, sequence_length, vocab_size)\n",
- "\n",
- "'''TODO: compute the loss using the true next characters from the example batch\n",
- " and the predictions from the untrained model several cells above'''\n",
- "example_batch_loss = compute_loss(y, pred)\n",
- "# example_batch_loss = compute_loss('''TODO''', '''TODO''') # TODO\n",
- "\n",
- "print(f\"Prediction shape: {pred.shape} # (batch_size, sequence_length, vocab_size)\")\n",
- "print(f\"scalar_loss: {example_batch_loss.mean().item()}\")"
- ],
- "metadata": {
- "id": "GuGUJB0ZT_Uo"
- },
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "0Seh7e6eRqd7"
- },
- "source": [
- "Let's start by defining some hyperparameters for training the model. To start, we have provided some reasonable values for some of the parameters. It is up to you to use what we've learned in class to help optimize the parameter selection here!"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "JQWUUhKotkAY"
- },
- "outputs": [],
- "source": [
- "### Hyperparameter setting and optimization ###\n",
- "\n",
- "vocab_size = len(vocab)\n",
- "\n",
- "# Model parameters:\n",
- "params = dict(\n",
- " num_training_iterations = 3000, # Increase this to train longer\n",
- " batch_size = 8, # Experiment between 1 and 64\n",
- " seq_length = 100, # Experiment between 50 and 500\n",
- " learning_rate = 5e-3, # Experiment between 1e-5 and 1e-1\n",
- " embedding_dim = 256,\n",
- " hidden_size = 1024, # Experiment between 1 and 2048\n",
- ")\n",
- "\n",
- "# Checkpoint location:\n",
- "checkpoint_dir = './training_checkpoints'\n",
- "checkpoint_prefix = os.path.join(checkpoint_dir, \"my_ckpt\")\n",
- "os.makedirs(checkpoint_dir, exist_ok=True)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "AyLzIPeAIqfg"
- },
- "source": [
- "Having defined our hyperparameters we can set up for experiment tracking with Comet. [`Experiment`](https://www.comet.com/docs/v2/api-and-sdk/python-sdk/reference/Experiment/) are the core objects in Comet and will allow us to track training and model development. Here we have written a short function to create a new Comet experiment. Note that in this setup, when hyperparameters change, you can run the `create_experiment()` function to initiate a new experiment. All experiments defined with the same `project_name` will live under that project in your Comet interface.\n",
- "\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "MBsN1vvxInmN"
- },
- "outputs": [],
- "source": [
- "### Create a Comet experiment to track our training run ###\n",
- "\n",
- "def create_experiment():\n",
- " # end any prior experiments\n",
- " if 'experiment' in locals():\n",
- " experiment.end()\n",
- "\n",
- " # initiate the comet experiment for tracking\n",
- " experiment = comet_ml.Experiment(\n",
- " api_key=COMET_API_KEY,\n",
- " project_name=\"6S191_Lab1_Part2\")\n",
- " # log our hyperparameters, defined above, to the experiment\n",
- " for param, value in params.items():\n",
- " experiment.log_parameter(param, value)\n",
- " experiment.flush()\n",
- "\n",
- " return experiment"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "5cu11p1MKYZd"
- },
- "source": [
- "Now, we are ready to define our training operation -- the optimizer and duration of training -- and use this function to train the model. You will experiment with the choice of optimizer and the duration for which you train your models, and see how these changes affect the network's output. Some optimizers you may like to try are [`Adam`](https://pytorch.org/docs/stable/generated/torch.optim.Adam.html) and [`Adagrad`](https://pytorch.org/docs/stable/generated/torch.optim.Adagrad.html).\n",
- "\n",
- "First, we will instantiate a new model and an optimizer, and ready them for training. Then, we will use [`loss.backward()`](https://pytorch.org/docs/stable/generated/torch.Tensor.backward.html), enabled by PyTorch's [autograd](https://pytorch.org/docs/stable/generated/torch.autograd.grad.html) method, to perform the backpropagation. Finally, to update the model's parameters based on the computed gradients, we will utake a step with the optimizer, using [`optimizer.step()`](https://pytorch.org/docs/stable/generated/torch.optim.Optimizer.step.html).\n",
- "\n",
- "We will also generate a print-out of the model's progress through training, which will help us easily visualize whether or not we are minimizing the loss."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "F31vzJ_u66cb"
- },
- "outputs": [],
- "source": [
- "### Define optimizer and training operation ###\n",
- "\n",
- "'''TODO: instantiate a new LSTMModel model for training using the hyperparameters\n",
- " created above.'''\n",
- "model = LSTMModel(vocab_size, params[\"embedding_dim\"], params[\"hidden_size\"])\n",
- "# model = LSTMModel('''TODO: arguments''')\n",
- "\n",
- "# Move the model to the GPU\n",
- "model.to(device)\n",
- "\n",
- "'''TODO: instantiate an optimizer with its learning rate.\n",
- " Checkout the PyTorch website for a list of supported optimizers.\n",
- " https://pytorch.org/docs/stable/optim.html\n",
- " Try using the Adam optimizer to start.'''\n",
- "optimizer = torch.optim.Adam(model.parameters(), lr=params[\"learning_rate\"])\n",
- "# optimizer = # TODO\n",
- "\n",
- "def train_step(x, y):\n",
- " # Set the model's mode to train\n",
- " model.train()\n",
- "\n",
- " # Zero gradients for every step\n",
- " optimizer.zero_grad()\n",
- "\n",
- " # Forward pass\n",
- " '''TODO: feed the current input into the model and generate predictions'''\n",
- " y_hat = model(x) # TODO\n",
- " # y_hat = model('''TODO''')\n",
- "\n",
- " # Compute the loss\n",
- " '''TODO: compute the loss!'''\n",
- " loss = compute_loss(y, y_hat) # TODO\n",
- " # loss = compute_loss('''TODO''', '''TODO''')\n",
- "\n",
- " # Backward pass\n",
- " '''TODO: complete the gradient computation and update step.\n",
- " Remember that in PyTorch there are two steps to the training loop:\n",
- " 1. Backpropagate the loss\n",
- " 2. Update the model parameters using the optimizer\n",
- " '''\n",
- " loss.backward() # TODO\n",
- " optimizer.step() # TODO\n",
- "\n",
- " return loss\n",
- "\n",
- "##################\n",
- "# Begin training!#\n",
- "##################\n",
- "\n",
- "history = []\n",
- "plotter = mdl.util.PeriodicPlotter(sec=2, xlabel='Iterations', ylabel='Loss')\n",
- "experiment = create_experiment()\n",
- "\n",
- "if hasattr(tqdm, '_instances'): tqdm._instances.clear() # clear if it exists\n",
- "for iter in tqdm(range(params[\"num_training_iterations\"])):\n",
- "\n",
- " # Grab a batch and propagate it through the network\n",
- " x_batch, y_batch = get_batch(vectorized_songs, params[\"seq_length\"], params[\"batch_size\"])\n",
- "\n",
- " # Convert numpy arrays to PyTorch tensors\n",
- " x_batch = torch.tensor(x_batch, dtype=torch.long).to(device)\n",
- " y_batch = torch.tensor(y_batch, dtype=torch.long).to(device)\n",
- "\n",
- " # Take a train step\n",
- " loss = train_step(x_batch, y_batch)\n",
- "\n",
- " # Log the loss to the Comet interface\n",
- " experiment.log_metric(\"loss\", loss.item(), step=iter)\n",
- "\n",
- " # Update the progress bar and visualize within notebook\n",
- " history.append(loss.item())\n",
- " plotter.plot(history)\n",
- "\n",
- " # Save model checkpoint\n",
- " if iter % 100 == 0:\n",
- " torch.save(model.state_dict(), checkpoint_prefix)\n",
- "\n",
- "# Save the final trained model\n",
- "torch.save(model.state_dict(), checkpoint_prefix)\n",
- "experiment.flush()\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "kKkD5M6eoSiN"
- },
- "source": [
- "## 2.6 Generate music using the RNN model\n",
- "\n",
- "Now, we can use our trained RNN model to generate some music! When generating music, we'll have to feed the model some sort of seed to get it started (because it can't predict anything without something to start with!).\n",
- "\n",
- "Once we have a generated seed, we can then iteratively predict each successive character (remember, we are using the ABC representation for our music) using our trained RNN. More specifically, recall that our RNN outputs a `softmax` over possible successive characters. For inference, we iteratively sample from these distributions, and then use our samples to encode a generated song in the ABC format.\n",
- "\n",
- "Then, all we have to do is write it to a file and listen!"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "DjGz1tDkzf-u"
- },
- "source": [
- "### The prediction procedure\n",
- "\n",
- "Now, we're ready to write the code to generate text in the ABC music format:\n",
- "\n",
- "* Initialize a \"seed\" start string and the RNN state, and set the number of characters we want to generate.\n",
- "\n",
- "* Use the start string and the RNN state to obtain the probability distribution over the next predicted character.\n",
- "\n",
- "* Sample from multinomial distribution to calculate the index of the predicted character. This predicted character is then used as the next input to the model.\n",
- "\n",
- "* At each time step, the updated RNN state is fed back into the model, so that it now has more context in making the next prediction. After predicting the next character, the updated RNN states are again fed back into the model, which is how it learns sequence dependencies in the data, as it gets more information from the previous predictions.\n",
- "\n",
- "\n",
- "\n",
- "Complete and experiment with this code block (as well as some of the aspects of network definition and training!), and see how the model performs. How do songs generated after training with a small number of epochs compare to those generated after a longer duration of training?"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "WvuwZBX5Ogfd"
- },
- "outputs": [],
- "source": [
- "### Prediction of a generated song ###\n",
- "\n",
- "def generate_text(model, start_string, generation_length=1000):\n",
- " # Evaluation step (generating ABC text using the learned RNN model)\n",
- "\n",
- " '''TODO: convert the start string to numbers (vectorize)'''\n",
- " input_idx = [char2idx[s] for s in start_string] # TODO\n",
- " # input_idx = ['''TODO''']\n",
- " input_idx = torch.tensor([input_idx], dtype=torch.long).to(device)\n",
- "\n",
- " # Initialize the hidden state\n",
- " state = model.init_hidden(input_idx.size(0), device)\n",
- "\n",
- " # Empty string to store our results\n",
- " text_generated = []\n",
- " tqdm._instances.clear()\n",
- "\n",
- " for i in tqdm(range(generation_length)):\n",
- " '''TODO: evaluate the inputs and generate the next character predictions'''\n",
- " predictions, state = model(input_idx, state, return_state=True)\n",
- " # predictions, hidden_state = model('''TODO''', '''TODO''', return_state=True)\n",
- "\n",
- " # Remove the batch dimension\n",
- " predictions = predictions.squeeze(0)\n",
- "\n",
- " '''TODO: use a multinomial distribution to sample over the probabilities'''\n",
- " input_idx = torch.multinomial(torch.softmax(predictions, dim=-1), num_samples=1)\n",
- " # input_idx = torch.multinomial('''TODO''', dim=-1), num_samples=1)\n",
- "\n",
- " '''TODO: add the predicted character to the generated text!'''\n",
- " # Hint: consider what format the prediction is in vs. the output\n",
- " text_generated.append(idx2char[input_idx].item()) # TODO\n",
- " # text_generated.append('''TODO''')\n",
- "\n",
- "\n",
- " return (start_string + ''.join(text_generated))"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "ktovv0RFhrkn"
- },
- "outputs": [],
- "source": [
- "'''TODO: Use the model and the function defined above to generate ABC format text of length 1000!\n",
- " As you may notice, ABC files start with \"X\" - this may be a good start string.'''\n",
- "generated_text = generate_text(model, start_string=\"X\", generation_length=1000) # TODO\n",
- "# generated_text = generate_text('''TODO''', '''TODO''', '''TODO''')"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "AM2Uma_-yVIq"
- },
- "source": [
- "### Play back the generated music!\n",
- "\n",
- "We can now call a function to convert the ABC format text to an audio file, and then play that back to check out our generated music! Try training longer if the resulting song is not long enough, or re-generating the song!\n",
- "\n",
- "We will save the song to Comet -- you will be able to find your songs under the `Audio` and `Assets & Artifacts` pages in your Comet interface for the project. Note the [`log_asset()`](https://www.comet.com/docs/v2/api-and-sdk/python-sdk/reference/Experiment/#experimentlog_asset) documentation, where you will see how to specify file names and other parameters for saving your assets."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "LrOtG64bfLto"
- },
- "outputs": [],
- "source": [
- "### Play back generated songs ###\n",
- "\n",
- "generated_songs = mdl.lab1.extract_song_snippet(generated_text)\n",
- "\n",
- "for i, song in enumerate(generated_songs):\n",
- " # Synthesize the waveform from a song\n",
- " waveform = mdl.lab1.play_song(song)\n",
- "\n",
- " # If its a valid song (correct syntax), lets play it!\n",
- " if waveform:\n",
- " print(\"Generated song\", i)\n",
- " ipythondisplay.display(waveform)\n",
- "\n",
- " numeric_data = np.frombuffer(waveform.data, dtype=np.int16)\n",
- " wav_file_path = f\"output_{i}.wav\"\n",
- " write(wav_file_path, 88200, numeric_data)\n",
- "\n",
- " # save your song to the Comet interface -- you can access it there\n",
- " experiment.log_asset(wav_file_path)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "4353qSV76gnJ"
- },
- "outputs": [],
- "source": [
- "# when done, end the comet experiment\n",
- "experiment.end()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "HgVvcrYmSKGG"
- },
- "source": [
- "## 2.7 Experiment and **get awarded for the best songs**!\n",
- "\n",
- "Congrats on making your first sequence model in TensorFlow! It's a pretty big accomplishment, and hopefully you have some sweet tunes to show for it.\n",
- "\n",
- "Consider how you may improve your model and what seems to be most important in terms of performance. Here are some ideas to get you started:\n",
- "\n",
- "* How does the number of training epochs affect the performance?\n",
- "* What if you alter or augment the dataset?\n",
- "* Does the choice of start string significantly affect the result?\n",
- "\n",
- "Try to optimize your model and submit your best song! **Participants will be eligible for prizes during the January 2025 offering. To enter the competition, you must upload the following to [this submission link](https://www.dropbox.com/request/U8nND6enGjirujVZKX1n):**\n",
- "\n",
- "* a recording of your song;\n",
- "* iPython notebook with the code you used to generate the song;\n",
- "* a description and/or diagram of the architecture and hyperparameters you used -- if there are any additional or interesting modifications you made to the template code, please include these in your description.\n",
- "\n",
- "**Name your file in the following format: ``[FirstName]_[LastName]_RNNMusic``, followed by the file format (.zip, .mp4, .ipynb, .pdf, etc). ZIP files of all three components are preferred over individual files. If you submit individual files, you must name the individual files according to the above nomenclature.**\n",
- "\n",
- "You can also tweet us at [@MITDeepLearning](https://twitter.com/MITDeepLearning) a copy of the song (but this will not enter you into the competition)! See this example song generated by a previous student (credit Ana Heart): song from May 20, 2020.\n",
- "\n",
- "\n",
- "Have fun and happy listening!\n",
- "\n",
- "\n"
- ]
- }
- ],
- "metadata": {
- "accelerator": "GPU",
- "colab": {
- "collapsed_sections": [
- "uoJsVjtCMunI"
- ],
- "name": "PT_Part2_Music_Generation_Solution.ipynb",
- "provenance": []
- },
- "kernelspec": {
- "display_name": "Python 3",
- "name": "python3"
- },
- "language_info": {
- "codemirror_mode": {
- "name": "ipython",
- "version": 3
- },
- "file_extension": ".py",
- "mimetype": "text/x-python",
- "name": "python",
- "nbconvert_exporter": "python",
- "pygments_lexer": "ipython3",
- "version": "3.11.11"
- }
- },
- "nbformat": 4,
- "nbformat_minor": 0
-}
\ No newline at end of file
diff --git a/lab1/solutions/TF_Part1_Intro_Solution.ipynb b/lab1/solutions/TF_Part1_Intro_Solution.ipynb
deleted file mode 100644
index 61f502cd..00000000
--- a/lab1/solutions/TF_Part1_Intro_Solution.ipynb
+++ /dev/null
@@ -1,714 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "WBk0ZDWY-ff8"
- },
- "source": [
- "\n",
- "\n",
- "# Copyright Information\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "3eI6DUic-6jo"
- },
- "outputs": [],
- "source": [
- "# Copyright 2025 MIT Introduction to Deep Learning. All Rights Reserved.\n",
- "#\n",
- "# Licensed under the MIT License. You may not use this file except in compliance\n",
- "# with the License. Use and/or modification of this code outside of MIT Introduction\n",
- "# to Deep Learning must reference:\n",
- "#\n",
- "# © MIT Introduction to Deep Learning\n",
- "# http://introtodeeplearning.com\n",
- "#"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "57knM8jrYZ2t"
- },
- "source": [
- "# Lab 1: Intro to TensorFlow and Music Generation with RNNs\n",
- "\n",
- "In this lab, you'll get exposure to using TensorFlow and learn how it can be used for solving deep learning tasks. Go through the code and run each cell. Along the way, you'll encounter several ***TODO*** blocks -- follow the instructions to fill them out before running those cells and continuing.\n",
- "\n",
- "\n",
- "# Part 1: Intro to TensorFlow\n",
- "\n",
- "## 0.1 Install TensorFlow\n",
- "\n",
- "TensorFlow is a software library extensively used in machine learning. Here we'll learn how computations are represented and how to define a simple neural network in TensorFlow. For all the TensorFlow labs in Introduction to Deep Learning 2025, we'll be using TensorFlow 2, which affords great flexibility and the ability to imperatively execute operations, just like in Python. You'll notice that TensorFlow 2 is quite similar to Python in its syntax and imperative execution. Let's install TensorFlow and a couple of dependencies.\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "LkaimNJfYZ2w"
- },
- "outputs": [],
- "source": [
- "import tensorflow as tf\n",
- "\n",
- "# Download and import the MIT Introduction to Deep Learning package\n",
- "!pip install mitdeeplearning --quiet\n",
- "import mitdeeplearning as mdl\n",
- "\n",
- "import numpy as np\n",
- "import matplotlib.pyplot as plt"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "2QNMcdP4m3Vs"
- },
- "source": [
- "## 1.1 Why is TensorFlow called TensorFlow?\n",
- "\n",
- "TensorFlow is called 'TensorFlow' because it handles the flow (node/mathematical operation) of Tensors, which are data structures that you can think of as multi-dimensional arrays. Tensors are represented as n-dimensional arrays of base dataypes such as a string or integer -- they provide a way to generalize vectors and matrices to higher dimensions.\n",
- "\n",
- "The ```shape``` of a Tensor defines its number of dimensions and the size of each dimension. The ```rank``` of a Tensor provides the number of dimensions (n-dimensions) -- you can also think of this as the Tensor's order or degree.\n",
- "\n",
- "Let's first look at 0-d Tensors, of which a scalar is an example:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "tFxztZQInlAB"
- },
- "outputs": [],
- "source": [
- "sport = tf.constant(\"Tennis\", tf.string)\n",
- "number = tf.constant(1.41421356237, tf.float64)\n",
- "\n",
- "print(\"`sport` is a {}-d Tensor\".format(tf.rank(sport).numpy()))\n",
- "print(\"`number` is a {}-d Tensor\".format(tf.rank(number).numpy()))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "-dljcPUcoJZ6"
- },
- "source": [
- "Vectors and lists can be used to create 1-d Tensors:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "oaHXABe8oPcO"
- },
- "outputs": [],
- "source": [
- "sports = tf.constant([\"Tennis\", \"Basketball\"], tf.string)\n",
- "numbers = tf.constant([3.141592, 1.414213, 2.71821], tf.float64)\n",
- "\n",
- "print(\"`sports` is a {}-d Tensor with shape: {}\".format(tf.rank(sports).numpy(), tf.shape(sports)))\n",
- "print(\"`numbers` is a {}-d Tensor with shape: {}\".format(tf.rank(numbers).numpy(), tf.shape(numbers)))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "gvffwkvtodLP"
- },
- "source": [
- "Next we consider creating 2-d (i.e., matrices) and higher-rank Tensors. For examples, in future labs involving image processing and computer vision, we will use 4-d Tensors. Here the dimensions correspond to the number of example images in our batch, image height, image width, and the number of color channels."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "tFeBBe1IouS3"
- },
- "outputs": [],
- "source": [
- "### Defining higher-order Tensors ###\n",
- "\n",
- "'''TODO: Define a 2-d Tensor'''\n",
- "matrix = tf.constant([[1.0, 2.0, 3.0, 4.0], [5.0, 6.0, 7.0, 8.0]]) # TODO\n",
- "# matrix = # TODO\n",
- "\n",
- "assert isinstance(matrix, tf.Tensor), \"matrix must be a tf Tensor object\"\n",
- "assert tf.rank(matrix).numpy() == 2"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "Zv1fTn_Ya_cz"
- },
- "outputs": [],
- "source": [
- "'''TODO: Define a 4-d Tensor.'''\n",
- "# Use tf.zeros to initialize a 4-d Tensor of zeros with size 10 x 256 x 256 x 3.\n",
- "# You can think of this as 10 images where each image is RGB 256 x 256.\n",
- "images = tf.zeros([10, 256, 256, 3]) # TODO\n",
- "# images = # TODO\n",
- "\n",
- "assert isinstance(images, tf.Tensor), \"matrix must be a tf Tensor object\"\n",
- "assert tf.rank(images).numpy() == 4, \"matrix must be of rank 4\"\n",
- "assert tf.shape(images).numpy().tolist() == [10, 256, 256, 3], \"matrix is incorrect shape\""
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "wkaCDOGapMyl"
- },
- "source": [
- "As you have seen, the ```shape``` of a Tensor provides the number of elements in each Tensor dimension. The ```shape``` is quite useful, and we'll use it often. You can also use slicing to access subtensors within a higher-rank Tensor:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "FhaufyObuLEG"
- },
- "outputs": [],
- "source": [
- "row_vector = matrix[1]\n",
- "column_vector = matrix[:,1]\n",
- "scalar = matrix[0, 1]\n",
- "\n",
- "print(\"`row_vector`: {}\".format(row_vector.numpy()))\n",
- "print(\"`column_vector`: {}\".format(column_vector.numpy()))\n",
- "print(\"`scalar`: {}\".format(scalar.numpy()))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "iD3VO-LZYZ2z"
- },
- "source": [
- "## 1.2 Computations on Tensors\n",
- "\n",
- "A convenient way to think about and visualize computations in TensorFlow is in terms of graphs. We can define this graph in terms of Tensors, which hold data, and the mathematical operations that act on these Tensors in some order. Let's look at a simple example, and define this computation using TensorFlow:\n",
- "\n",
- ""
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "X_YJrZsxYZ2z"
- },
- "outputs": [],
- "source": [
- "# Create the nodes in the graph, and initialize values\n",
- "a = tf.constant(15)\n",
- "b = tf.constant(61)\n",
- "\n",
- "# Add them!\n",
- "c1 = tf.add(a,b)\n",
- "c2 = a + b # TensorFlow overrides the \"+\" operation so that it is able to act on Tensors\n",
- "print(c1)\n",
- "print(c2)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Mbfv_QOiYZ23"
- },
- "source": [
- "Notice how we've created a computation graph consisting of TensorFlow operations, and how the output is a Tensor with value 76 -- we've just created a computation graph consisting of operations, and it's executed them and given us back the result.\n",
- "\n",
- "Now let's consider a slightly more complicated example:\n",
- "\n",
- "\n",
- "\n",
- "Here, we take two inputs, `a, b`, and compute an output `e`. Each node in the graph represents an operation that takes some input, does some computation, and passes its output to another node.\n",
- "\n",
- "Let's define a simple function in TensorFlow to construct this computation function:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "PJnfzpWyYZ23",
- "scrolled": true
- },
- "outputs": [],
- "source": [
- "### Defining Tensor computations ###\n",
- "\n",
- "# Construct a simple computation function\n",
- "def func(a,b):\n",
- " '''TODO: Define the operation for c, d, e (use tf.add, tf.subtract, tf.multiply).'''\n",
- " c = tf.add(a, b)\n",
- " # c = # TODO\n",
- " d = tf.subtract(b, 1)\n",
- " # d = # TODO\n",
- " e = tf.multiply(c, d)\n",
- " # e = # TODO\n",
- " return e"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "AwrRfDMS2-oy"
- },
- "source": [
- "Now, we can call this function to execute the computation graph given some inputs `a,b`:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "pnwsf8w2uF7p"
- },
- "outputs": [],
- "source": [
- "# Consider example values for a,b\n",
- "a, b = 1.5, 2.5\n",
- "# Execute the computation\n",
- "e_out = func(a,b)\n",
- "print(e_out)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "6HqgUIUhYZ29"
- },
- "source": [
- "Notice how our output is a Tensor with value defined by the output of the computation, and that the output has no shape as it is a single scalar value."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "1h4o9Bb0YZ29"
- },
- "source": [
- "## 1.3 Neural networks in TensorFlow\n",
- "We can also define neural networks in TensorFlow. TensorFlow uses a high-level API called [Keras](https://www.tensorflow.org/guide/keras) that provides a powerful, intuitive framework for building and training deep learning models.\n",
- "\n",
- "Let's first consider the example of a simple perceptron defined by just one dense layer: $ y = \\sigma(Wx + b)$, where $W$ represents a matrix of weights, $b$ is a bias, $x$ is the input, $\\sigma$ is the sigmoid activation function, and $y$ is the output. We can also visualize this operation using a graph:\n",
- "\n",
- "\n",
- "\n",
- "Tensors can flow through abstract types called [```Layers```](https://www.tensorflow.org/api_docs/python/tf/keras/layers/Layer) -- the building blocks of neural networks. ```Layers``` implement common neural networks operations, and are used to update weights, compute losses, and define inter-layer connectivity. We will first define a ```Layer``` to implement the simple perceptron defined above."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "HutbJk-1kHPh"
- },
- "outputs": [],
- "source": [
- "### Defining a network Layer ###\n",
- "\n",
- "# n_output_nodes: number of output nodes\n",
- "# input_shape: shape of the input\n",
- "# x: input to the layer\n",
- "\n",
- "class OurDenseLayer(tf.keras.layers.Layer):\n",
- " def __init__(self, n_output_nodes):\n",
- " super(OurDenseLayer, self).__init__()\n",
- " self.n_output_nodes = n_output_nodes\n",
- "\n",
- " def build(self, input_shape):\n",
- " d = int(input_shape[-1])\n",
- " # Define and initialize parameters: a weight matrix W and bias b\n",
- " # Note that parameter initialization is random!\n",
- " self.W = self.add_weight(\"weight\", shape=[d, self.n_output_nodes]) # note the dimensionality\n",
- " self.b = self.add_weight(\"bias\", shape=[1, self.n_output_nodes]) # note the dimensionality\n",
- "\n",
- " def call(self, x):\n",
- " '''TODO: define the operation for z (hint: use tf.matmul)'''\n",
- " z = tf.matmul(x, self.W) + self.b # TODO\n",
- " # z = # TODO\n",
- "\n",
- " '''TODO: define the operation for out (hint: use tf.sigmoid)'''\n",
- " y = tf.sigmoid(z) # TODO\n",
- " # y = # TODO\n",
- " return y\n",
- "\n",
- "# Since layer parameters are initialized randomly, we will set a random seed for reproducibility\n",
- "tf.keras.utils.set_random_seed(1)\n",
- "layer = OurDenseLayer(3)\n",
- "layer.build((1,2))\n",
- "x_input = tf.constant([[1,2.]], shape=(1,2))\n",
- "y = layer.call(x_input)\n",
- "\n",
- "# test the output!\n",
- "print(y.numpy())\n",
- "mdl.lab1.test_custom_dense_layer_output(y)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Jt1FgM7qYZ3D"
- },
- "source": [
- "Conveniently, TensorFlow has defined a number of ```Layers``` that are commonly used in neural networks, for example a [```Dense```](https://www.tensorflow.org/api_docs/python/tf/keras/layers/Dense?version=stable). Now, instead of using a single ```Layer``` to define our simple neural network, we'll use the [`Sequential`](https://www.tensorflow.org/versions/r2.0/api_docs/python/tf/keras/Sequential) model from Keras and a single [`Dense` ](https://www.tensorflow.org/versions/r2.0/api_docs/python/tf/keras/layers/Dense) layer to define our network. With the `Sequential` API, you can readily create neural networks by stacking together layers like building blocks."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "7WXTpmoL6TDz"
- },
- "outputs": [],
- "source": [
- "### Defining a neural network using the Sequential API ###\n",
- "\n",
- "# Import relevant packages\n",
- "from tensorflow.keras import Sequential\n",
- "from tensorflow.keras.layers import Dense\n",
- "\n",
- "# Define the number of outputs\n",
- "n_output_nodes = 3\n",
- "\n",
- "# First define the model\n",
- "model = Sequential()\n",
- "\n",
- "'''TODO: Define a dense (fully connected) layer to compute z'''\n",
- "# Remember: dense layers are defined by the parameters W and b!\n",
- "# You can read more about the initialization of W and b in the TF documentation :)\n",
- "# https://www.tensorflow.org/api_docs/python/tf/keras/layers/Dense?version=stable\n",
- "dense_layer = Dense(n_output_nodes, activation='sigmoid') # TODO\n",
- "# dense_layer = # TODO\n",
- "\n",
- "# Add the dense layer to the model\n",
- "model.add(dense_layer)\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "HDGcwYfUyR-U"
- },
- "source": [
- "That's it! We've defined our model using the Sequential API. Now, we can test it out using an example input:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "sg23OczByRDb"
- },
- "outputs": [],
- "source": [
- "# Test model with example input\n",
- "x_input = tf.constant([[1,2.]], shape=(1,2))\n",
- "\n",
- "'''TODO: feed input into the model and predict the output!'''\n",
- "model_output = model(x_input).numpy()\n",
- "# model_output = # TODO\n",
- "print(model_output)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "596NvsOOtr9F"
- },
- "source": [
- "In addition to defining models using the `Sequential` API, we can also define neural networks by directly subclassing the [`Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model?version=stable) class, which groups layers together to enable model training and inference. The `Model` class captures what we refer to as a \"model\" or as a \"network\". Using Subclassing, we can create a class for our model, and then define the forward pass through the network using the `call` function. Subclassing affords the flexibility to define custom layers, custom training loops, custom activation functions, and custom models. Let's define the same neural network as above now using Subclassing rather than the `Sequential` model."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "K4aCflPVyViD"
- },
- "outputs": [],
- "source": [
- "### Defining a model using subclassing ###\n",
- "\n",
- "from tensorflow.keras import Model\n",
- "from tensorflow.keras.layers import Dense\n",
- "\n",
- "class SubclassModel(tf.keras.Model):\n",
- "\n",
- " # In __init__, we define the Model's layers\n",
- " def __init__(self, n_output_nodes):\n",
- " super(SubclassModel, self).__init__()\n",
- " '''TODO: Our model consists of a single Dense layer. Define this layer.'''\n",
- " self.dense_layer = Dense(n_output_nodes, activation='sigmoid') # TODO\n",
- " # self.dense_layer = '''TODO: Dense Layer'''\n",
- "\n",
- " # In the call function, we define the Model's forward pass.\n",
- " def call(self, inputs):\n",
- " return self.dense_layer(inputs)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "U0-lwHDk4irB"
- },
- "source": [
- "Just like the model we built using the `Sequential` API, let's test out our `SubclassModel` using an example input.\n",
- "\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "LhB34RA-4gXb"
- },
- "outputs": [],
- "source": [
- "n_output_nodes = 3\n",
- "model = SubclassModel(n_output_nodes)\n",
- "\n",
- "x_input = tf.constant([[1,2.]], shape=(1,2))\n",
- "\n",
- "print(model.call(x_input))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "HTIFMJLAzsyE"
- },
- "source": [
- "Importantly, Subclassing affords us a lot of flexibility to define custom models. For example, we can use boolean arguments in the `call` function to specify different network behaviors, for example different behaviors during training and inference. Let's suppose under some instances we want our network to simply output the input, without any perturbation. We define a boolean argument `isidentity` to control this behavior:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "P7jzGX5D1xT5"
- },
- "outputs": [],
- "source": [
- "### Defining a model using subclassing and specifying custom behavior ###\n",
- "\n",
- "from tensorflow.keras import Model\n",
- "from tensorflow.keras.layers import Dense\n",
- "\n",
- "class IdentityModel(tf.keras.Model):\n",
- "\n",
- " # As before, in __init__ we define the Model's layers\n",
- " # Since our desired behavior involves the forward pass, this part is unchanged\n",
- " def __init__(self, n_output_nodes):\n",
- " super(IdentityModel, self).__init__()\n",
- " self.dense_layer = tf.keras.layers.Dense(n_output_nodes, activation='sigmoid')\n",
- "\n",
- " '''TODO: Implement the behavior where the network outputs the input, unchanged, under control of the isidentity argument.'''\n",
- " def call(self, inputs, isidentity=False):\n",
- " x = self.dense_layer(inputs)\n",
- " if isidentity: # TODO\n",
- " return inputs # TODO\n",
- " return x\n",
- "\n",
- " # def call(self, inputs, isidentity=False):\n",
- " # TODO"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Ku4rcCGx5T3y"
- },
- "source": [
- "Let's test this behavior:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "NzC0mgbk5dp2"
- },
- "outputs": [],
- "source": [
- "n_output_nodes = 3\n",
- "model = IdentityModel(n_output_nodes)\n",
- "\n",
- "x_input = tf.constant([[1,2.]], shape=(1,2))\n",
- "'''TODO: pass the input into the model and call with and without the input identity option.'''\n",
- "out_activate = model.call(x_input) # TODO\n",
- "# out_activate = # TODO\n",
- "out_identity = model.call(x_input, isidentity=True) # TODO\n",
- "# out_identity = # TODO\n",
- "\n",
- "print(\"Network output with activation: {}; network identity output: {}\".format(out_activate.numpy(), out_identity.numpy()))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "7V1dEqdk6VI5"
- },
- "source": [
- "Now that we have learned how to define `Layers` as well as neural networks in TensorFlow using both the `Sequential` and Subclassing APIs, we're ready to turn our attention to how to actually implement network training with backpropagation."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "dQwDhKn8kbO2"
- },
- "source": [
- "## 1.4 Automatic differentiation in TensorFlow\n",
- "\n",
- "[Automatic differentiation](https://en.wikipedia.org/wiki/Automatic_differentiation)\n",
- "is one of the most important parts of TensorFlow and is the backbone of training with\n",
- "[backpropagation](https://en.wikipedia.org/wiki/Backpropagation). We will use the TensorFlow GradientTape [`tf.GradientTape`](https://www.tensorflow.org/api_docs/python/tf/GradientTape?version=stable) to trace operations for computing gradients later.\n",
- "\n",
- "When a forward pass is made through the network, all forward-pass operations get recorded to a \"tape\"; then, to compute the gradient, the tape is played backwards. By default, the tape is discarded after it is played backwards; this means that a particular `tf.GradientTape` can only\n",
- "compute one gradient, and subsequent calls throw a runtime error. However, we can compute multiple gradients over the same computation by creating a ```persistent``` gradient tape.\n",
- "\n",
- "First, we will look at how we can compute gradients using GradientTape and access them for computation. We define the simple function $ y = x^2$ and compute the gradient:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "tdkqk8pw5yJM"
- },
- "outputs": [],
- "source": [
- "### Gradient computation with GradientTape ###\n",
- "\n",
- "# y = x^2\n",
- "# Example: x = 3.0\n",
- "x = tf.Variable(3.0)\n",
- "\n",
- "# Initiate the gradient tape\n",
- "with tf.GradientTape() as tape:\n",
- " # Define the function\n",
- " y = x * x\n",
- "# Access the gradient -- derivative of y with respect to x\n",
- "dy_dx = tape.gradient(y, x)\n",
- "\n",
- "assert dy_dx.numpy() == 6.0"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "JhU5metS5xF3"
- },
- "source": [
- "In training neural networks, we use differentiation and stochastic gradient descent (SGD) to optimize a loss function. Now that we have a sense of how `GradientTape` can be used to compute and access derivatives, we will look at an example where we use automatic differentiation and SGD to find the minimum of $L=(x-x_f)^2$. Here $x_f$ is a variable for a desired value we are trying to optimize for; $L$ represents a loss that we are trying to minimize. While we can clearly solve this problem analytically ($x_{min}=x_f$), considering how we can compute this using `GradientTape` sets us up nicely for future labs where we use gradient descent to optimize entire neural network losses."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "attributes": {
- "classes": [
- "py"
- ],
- "id": ""
- },
- "id": "7g1yWiSXqEf-"
- },
- "outputs": [],
- "source": [
- "### Function minimization with automatic differentiation and SGD ###\n",
- "\n",
- "# Initialize a random value for our initial x\n",
- "x = tf.Variable([tf.random.normal([1])])\n",
- "print(\"Initializing x={}\".format(x.numpy()))\n",
- "\n",
- "learning_rate = 1e-2 # learning rate for SGD\n",
- "history = []\n",
- "# Define the target value\n",
- "x_f = 4\n",
- "\n",
- "# We will run SGD for a number of iterations. At each iteration, we compute the loss,\n",
- "# compute the derivative of the loss with respect to x, and perform the SGD update.\n",
- "for i in range(500):\n",
- " with tf.GradientTape() as tape:\n",
- " '''TODO: define the loss as described above'''\n",
- " loss = (x - x_f)**2 # \"forward pass\": record the current loss on the tape\n",
- " # loss = # TODO\n",
- "\n",
- " # loss minimization using gradient tape\n",
- " grad = tape.gradient(loss, x) # compute the derivative of the loss with respect to x\n",
- " new_x = x - learning_rate*grad # sgd update\n",
- " x.assign(new_x) # update the value of x\n",
- " history.append(x.numpy()[0])\n",
- "\n",
- "# Plot the evolution of x as we optimize towards x_f!\n",
- "plt.plot(history)\n",
- "plt.plot([0, 500],[x_f,x_f])\n",
- "plt.legend(('Predicted', 'True'))\n",
- "plt.xlabel('Iteration')\n",
- "plt.ylabel('x value')"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "pC7czCwk3ceH"
- },
- "source": [
- "`GradientTape` provides an extremely flexible framework for automatic differentiation. In order to back propagate errors through a neural network, we track forward passes on the Tape, use this information to determine the gradients, and then use these gradients for optimization using SGD.\n"
- ]
- }
- ],
- "metadata": {
- "accelerator": "GPU",
- "colab": {
- "collapsed_sections": [
- "WBk0ZDWY-ff8"
- ],
- "name": "TF_Part1_Intro_Solution.ipynb",
- "provenance": []
- },
- "kernelspec": {
- "display_name": "Python 3",
- "language": "python",
- "name": "python3"
- },
- "language_info": {
- "name": "python",
- "version": "3.9.6"
- },
- "vscode": {
- "interpreter": {
- "hash": "31f2aee4e71d21fbe5cf8b01ff0e069b9275f58929596ceb00d14d90e3e16cd6"
- }
- }
- },
- "nbformat": 4,
- "nbformat_minor": 0
-}
diff --git a/lab1/solutions/TF_Part2_Music_Generation_Solution.ipynb b/lab1/solutions/TF_Part2_Music_Generation_Solution.ipynb
deleted file mode 100644
index df0ded1c..00000000
--- a/lab1/solutions/TF_Part2_Music_Generation_Solution.ipynb
+++ /dev/null
@@ -1,1059 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "uoJsVjtCMunI"
- },
- "source": [
- "\n",
- "\n",
- "# Copyright Information"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "bUik05YqMyCH"
- },
- "outputs": [],
- "source": [
- "# Copyright 2025 MIT Introduction to Deep Learning. All Rights Reserved.\n",
- "#\n",
- "# Licensed under the MIT License. You may not use this file except in compliance\n",
- "# with the License. Use and/or modification of this code outside of MIT Introduction\n",
- "# to Deep Learning must reference:\n",
- "#\n",
- "# © MIT Introduction to Deep Learning\n",
- "# http://introtodeeplearning.com\n",
- "#"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "O-97SDET3JG-"
- },
- "source": [
- "# Lab 1: Intro to TensorFlow and Music Generation with RNNs\n",
- "\n",
- "# Part 2: Music Generation with RNNs\n",
- "\n",
- "In this portion of the lab, we will explore building a Recurrent Neural Network (RNN) for music generation. We will train a model to learn the patterns in raw sheet music in [ABC notation](https://en.wikipedia.org/wiki/ABC_notation) and then use this model to generate new music."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "rsvlBQYCrE4I"
- },
- "source": [
- "## 2.1 Dependencies\n",
- "First, let's download the course repository, install dependencies, and import the relevant packages we'll need for this lab.\n",
- "\n",
- "We will be using [Comet ML](https://www.comet.com/docs/v2/) to track our model development and training runs. First, sign up for a Comet account [at this link](https://www.comet.com/signup?utm_source=mit_dl&utm_medium=partner&utm_content=github\n",
- ") (you can use your Google or Github account). This will generate a personal API Key, which you can find either in the first 'Get Started with Comet' page, under your account settings, or by pressing the '?' in the top right corner and then 'Quickstart Guide'. Enter this API key as the global variable `COMET_API_KEY`."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "riVZCVK65QTH"
- },
- "outputs": [],
- "source": [
- "!pip install comet_ml > /dev/null 2>&1\n",
- "import comet_ml\n",
- "# TODO: ENTER YOUR API KEY HERE!! instructions above\n",
- "COMET_API_KEY = \"\"\n",
- "\n",
- "# Import Tensorflow 2.0\n",
- "import tensorflow as tf\n",
- "\n",
- "# Download and import the MIT Introduction to Deep Learning package\n",
- "!pip install mitdeeplearning --quiet\n",
- "import mitdeeplearning as mdl\n",
- "\n",
- "# Import all remaining packages\n",
- "import numpy as np\n",
- "import os\n",
- "import time\n",
- "import functools\n",
- "from IPython import display as ipythondisplay\n",
- "from tqdm import tqdm\n",
- "from scipy.io.wavfile import write\n",
- "!apt-get install abcmidi timidity > /dev/null 2>&1\n",
- "\n",
- "\n",
- "# Check that we are using a GPU, if not switch runtimes\n",
- "# using Runtime > Change Runtime Type > GPU\n",
- "# assert len(tf.config.list_physical_devices('GPU')) > 0\n",
- "# assert COMET_API_KEY != \"\", \"Please insert your Comet API Key\""
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "_ajvp0No4qDm"
- },
- "source": [
- "## 2.2 Dataset\n",
- "\n",
- "\n",
- "\n",
- "We've gathered a dataset of thousands of Irish folk songs, represented in the ABC notation. Let's download the dataset and inspect it:\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "P7dFnP5q3Jve"
- },
- "outputs": [],
- "source": [
- "# Download the dataset\n",
- "songs = mdl.lab1.load_training_data()\n",
- "\n",
- "# Print one of the songs to inspect it in greater detail!\n",
- "example_song = songs[0]\n",
- "print(\"\\nExample song: \")\n",
- "print(example_song)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "hKF3EHJlCAj2"
- },
- "source": [
- "We can easily convert a song in ABC notation to an audio waveform and play it back. Be patient for this conversion to run, it can take some time."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "11toYzhEEKDz"
- },
- "outputs": [],
- "source": [
- "# Convert the ABC notation to audio file and listen to it\n",
- "mdl.lab1.play_song(example_song)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "7vH24yyquwKQ"
- },
- "source": [
- "One important thing to think about is that this notation of music does not simply contain information on the notes being played, but additionally there is meta information such as the song title, key, and tempo. How does the number of different characters that are present in the text file impact the complexity of the learning problem? This will become important soon, when we generate a numerical representation for the text data."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "IlCgQBRVymwR"
- },
- "outputs": [],
- "source": [
- "# Join our list of song strings into a single string containing all songs\n",
- "songs_joined = \"\\n\\n\".join(songs)\n",
- "\n",
- "# Find all unique characters in the joined string\n",
- "vocab = sorted(set(songs_joined))\n",
- "print(\"There are\", len(vocab), \"unique characters in the dataset\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "rNnrKn_lL-IJ"
- },
- "source": [
- "## 2.3 Process the dataset for the learning task\n",
- "\n",
- "Let's take a step back and consider our prediction task. We're trying to train a RNN model to learn patterns in ABC music, and then use this model to generate (i.e., predict) a new piece of music based on this learned information.\n",
- "\n",
- "Breaking this down, what we're really asking the model is: given a character, or a sequence of characters, what is the most probable next character? We'll train the model to perform this task.\n",
- "\n",
- "To achieve this, we will input a sequence of characters to the model, and train the model to predict the output, that is, the following character at each time step. RNNs maintain an internal state that depends on previously seen elements, so information about all characters seen up until a given moment will be taken into account in generating the prediction."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "LFjSVAlWzf-N"
- },
- "source": [
- "### Vectorize the text\n",
- "\n",
- "Before we begin training our RNN model, we'll need to create a numerical representation of our text-based dataset. To do this, we'll generate two lookup tables: one that maps characters to numbers, and a second that maps numbers back to characters. Recall that we just identified the unique characters present in the text."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "IalZLbvOzf-F"
- },
- "outputs": [],
- "source": [
- "### Define numerical representation of text ###\n",
- "\n",
- "# Create a mapping from character to unique index.\n",
- "# For example, to get the index of the character \"d\",\n",
- "# we can evaluate `char2idx[\"d\"]`.\n",
- "char2idx = {u:i for i, u in enumerate(vocab)}\n",
- "\n",
- "# Create a mapping from indices to characters. This is\n",
- "# the inverse of char2idx and allows us to convert back\n",
- "# from unique index to the character in our vocabulary.\n",
- "idx2char = np.array(vocab)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "tZfqhkYCymwX"
- },
- "source": [
- "This gives us an integer representation for each character. Observe that the unique characters (i.e., our vocabulary) in the text are mapped as indices from 0 to `len(unique)`. Let's take a peek at this numerical representation of our dataset:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "FYyNlCNXymwY"
- },
- "outputs": [],
- "source": [
- "print('{')\n",
- "for char,_ in zip(char2idx, range(20)):\n",
- " print(' {:4s}: {:3d},'.format(repr(char), char2idx[char]))\n",
- "print(' ...\\n}')"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "g-LnKyu4dczc"
- },
- "outputs": [],
- "source": [
- "### Vectorize the songs string ###\n",
- "\n",
- "'''TODO: Write a function to convert the all songs string to a vectorized\n",
- " (i.e., numeric) representation. Use the appropriate mapping\n",
- " above to convert from vocab characters to the corresponding indices.\n",
- "\n",
- " NOTE: the output of the `vectorize_string` function\n",
- " should be a np.array with `N` elements, where `N` is\n",
- " the number of characters in the input string\n",
- "'''\n",
- "def vectorize_string(string):\n",
- " vectorized_output = np.array([char2idx[char] for char in string])\n",
- " return vectorized_output\n",
- "\n",
- "# def vectorize_string(string):\n",
- " # TODO\n",
- "\n",
- "vectorized_songs = vectorize_string(songs_joined)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "IqxpSuZ1w-ub"
- },
- "source": [
- "We can also look at how the first part of the text is mapped to an integer representation:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "l1VKcQHcymwb"
- },
- "outputs": [],
- "source": [
- "print ('{} ---- characters mapped to int ----> {}'.format(repr(songs_joined[:10]), vectorized_songs[:10]))\n",
- "# check that vectorized_songs is a numpy array\n",
- "assert isinstance(vectorized_songs, np.ndarray), \"returned result should be a numpy array\""
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "hgsVvVxnymwf"
- },
- "source": [
- "### Create training examples and targets\n",
- "\n",
- "Our next step is to actually divide the text into example sequences that we'll use during training. Each input sequence that we feed into our RNN will contain `seq_length` characters from the text. We'll also need to define a target sequence for each input sequence, which will be used in training the RNN to predict the next character. For each input, the corresponding target will contain the same length of text, except shifted one character to the right.\n",
- "\n",
- "To do this, we'll break the text into chunks of `seq_length+1`. Suppose `seq_length` is 4 and our text is \"Hello\". Then, our input sequence is \"Hell\" and the target sequence is \"ello\".\n",
- "\n",
- "The batch method will then let us convert this stream of character indices to sequences of the desired size."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "LF-N8F7BoDRi"
- },
- "outputs": [],
- "source": [
- "### Batch definition to create training examples ###\n",
- "\n",
- "def get_batch(vectorized_songs, seq_length, batch_size):\n",
- " # the length of the vectorized songs string\n",
- " n = vectorized_songs.shape[0] - 1\n",
- " # randomly choose the starting indices for the examples in the training batch\n",
- " idx = np.random.choice(n-seq_length, batch_size)\n",
- "\n",
- " '''TODO: construct a list of input sequences for the training batch'''\n",
- " input_batch = [vectorized_songs[i : i+seq_length] for i in idx]\n",
- " # input_batch = # TODO\n",
- " '''TODO: construct a list of output sequences for the training batch'''\n",
- " output_batch = [vectorized_songs[i+1 : i+seq_length+1] for i in idx]\n",
- " # output_batch = # TODO\n",
- "\n",
- " # x_batch, y_batch provide the true inputs and targets for network training\n",
- " x_batch = np.reshape(input_batch, [batch_size, seq_length])\n",
- " y_batch = np.reshape(output_batch, [batch_size, seq_length])\n",
- " return x_batch, y_batch\n",
- "\n",
- "\n",
- "# Perform some simple tests to make sure your batch function is working properly!\n",
- "test_args = (vectorized_songs, 10, 2)\n",
- "if not mdl.lab1.test_batch_func_types(get_batch, test_args) or \\\n",
- " not mdl.lab1.test_batch_func_shapes(get_batch, test_args) or \\\n",
- " not mdl.lab1.test_batch_func_next_step(get_batch, test_args):\n",
- " print(\"======\\n[FAIL] could not pass tests\")\n",
- "else:\n",
- " print(\"======\\n[PASS] passed all tests!\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "_33OHL3b84i0"
- },
- "source": [
- "For each of these vectors, each index is processed at a single time step. So, for the input at time step 0, the model receives the index for the first character in the sequence, and tries to predict the index of the next character. At the next timestep, it does the same thing, but the RNN considers the information from the previous step, i.e., its updated state, in addition to the current input.\n",
- "\n",
- "We can make this concrete by taking a look at how this works over the first several characters in our text:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "0eBu9WZG84i0"
- },
- "outputs": [],
- "source": [
- "x_batch, y_batch = get_batch(vectorized_songs, seq_length=5, batch_size=1)\n",
- "\n",
- "for i, (input_idx, target_idx) in enumerate(zip(np.squeeze(x_batch), np.squeeze(y_batch))):\n",
- " print(\"Step {:3d}\".format(i))\n",
- " print(\" input: {} ({:s})\".format(input_idx, repr(idx2char[input_idx])))\n",
- " print(\" expected output: {} ({:s})\".format(target_idx, repr(idx2char[target_idx])))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "r6oUuElIMgVx"
- },
- "source": [
- "## 2.4 The Recurrent Neural Network (RNN) model"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "m8gPwEjRzf-Z"
- },
- "source": [
- "Now we're ready to define and train a RNN model on our ABC music dataset, and then use that trained model to generate a new song. We'll train our RNN using batches of song snippets from our dataset, which we generated in the previous section.\n",
- "\n",
- "The model is based off the LSTM architecture, where we use a state vector to maintain information about the temporal relationships between consecutive characters. The final output of the LSTM is then fed into a fully connected [`Dense`](https://www.tensorflow.org/api_docs/python/tf/keras/layers/Dense) layer where we'll output a softmax over each character in the vocabulary, and then sample from this distribution to predict the next character.\n",
- "\n",
- "As we introduced in the first portion of this lab, we'll be using the Keras API, specifically, [`tf.keras.Sequential`](https://www.tensorflow.org/api_docs/python/tf/keras/models/Sequential), to define the model. Three layers are used to define the model:\n",
- "\n",
- "* [`tf.keras.layers.Embedding`](https://www.tensorflow.org/api_docs/python/tf/keras/layers/Embedding): This is the input layer, consisting of a trainable lookup table that maps the numbers of each character to a vector with `embedding_dim` dimensions.\n",
- "* [`tf.keras.layers.LSTM`](https://www.tensorflow.org/api_docs/python/tf/keras/layers/LSTM): Our LSTM network, with size `units=rnn_units`.\n",
- "* [`tf.keras.layers.Dense`](https://www.tensorflow.org/api_docs/python/tf/keras/layers/Dense): The output layer, with `vocab_size` outputs.\n",
- "\n",
- "\n",
- ""
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "rlaOqndqBmJo"
- },
- "source": [
- "### Define the RNN model\n",
- "\n",
- "Now, we will define a function that we will use to actually build the model."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "8DsWzojvkbc7"
- },
- "outputs": [],
- "source": [
- "def LSTM(rnn_units):\n",
- " return tf.keras.layers.LSTM(\n",
- " rnn_units,\n",
- " return_sequences=True,\n",
- " recurrent_initializer='glorot_uniform',\n",
- " recurrent_activation='sigmoid',\n",
- " stateful=True,\n",
- " )"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "IbWU4dMJmMvq"
- },
- "source": [
- "The time has come! Fill in the `TODOs` to define the RNN model within the `build_model` function, and then call the function you just defined to instantiate the model!"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "MtCrdfzEI2N0"
- },
- "outputs": [],
- "source": [
- "### Defining the RNN Model ###\n",
- "\n",
- "'''TODO: Add LSTM and Dense layers to define the RNN model using the Sequential API.'''\n",
- "def build_model(vocab_size, embedding_dim, rnn_units, batch_size):\n",
- " model = tf.keras.Sequential([\n",
- " # Layer 1: Embedding layer to transform indices into dense vectors\n",
- " # of a fixed embedding size\n",
- " tf.keras.layers.Embedding(vocab_size, embedding_dim),\n",
- "\n",
- " # Layer 2: LSTM with `rnn_units` number of units.\n",
- " # TODO: Call the LSTM function defined above to add this layer.\n",
- " LSTM(rnn_units),\n",
- " # LSTM('''TODO'''),\n",
- "\n",
- " # Layer 3: Dense (fully-connected) layer that transforms the LSTM output\n",
- " # into the vocabulary size.\n",
- " # TODO: Add the Dense layer.\n",
- " tf.keras.layers.Dense(vocab_size)\n",
- " # '''TODO: DENSE LAYER HERE'''\n",
- " ])\n",
- "\n",
- " return model\n",
- "\n",
- "# Build a simple model with default hyperparameters. You will get the\n",
- "# chance to change these later.\n",
- "model = build_model(len(vocab), embedding_dim=256, rnn_units=1024, batch_size=32)\n",
- "model.build(tf.TensorShape([32, 100])) # [batch_size, sequence_length]"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "-ubPo0_9Prjb"
- },
- "source": [
- "### Test out the RNN model\n",
- "\n",
- "It's always a good idea to run a few simple checks on our model to see that it behaves as expected. \n",
- "\n",
- "First, we can use the `Model.summary` function to print out a summary of our model's internal workings. Here we can check the layers in the model, the shape of the output of each of the layers, the batch size, etc."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "RwG1DD6rDrRM"
- },
- "outputs": [],
- "source": [
- "model.summary()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "8xeDn5nZD0LX"
- },
- "source": [
- "We can also quickly check the dimensionality of our output, using a sequence length of 100. Note that the model can be run on inputs of any length."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "C-_70kKAPrPU"
- },
- "outputs": [],
- "source": [
- "x, y = get_batch(vectorized_songs, seq_length=100, batch_size=32)\n",
- "pred = model(x)\n",
- "print(\"Input shape: \", x.shape, \" # (batch_size, sequence_length)\")\n",
- "print(\"Prediction shape: \", pred.shape, \"# (batch_size, sequence_length, vocab_size)\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "mT1HvFVUGpoE"
- },
- "source": [
- "### Predictions from the untrained model\n",
- "\n",
- "Let's take a look at what our untrained model is predicting.\n",
- "\n",
- "To get actual predictions from the model, we sample from the output distribution, which is defined by a `softmax` over our character vocabulary. This will give us actual character indices. This means we are using a [categorical distribution](https://en.wikipedia.org/wiki/Categorical_distribution) to sample over the example prediction. This gives a prediction of the next character (specifically its index) at each timestep.\n",
- "\n",
- "Note here that we sample from this probability distribution, as opposed to simply taking the `argmax`, which can cause the model to get stuck in a loop.\n",
- "\n",
- "Let's try this sampling out for the first example in the batch."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "4V4MfFg0RQJg"
- },
- "outputs": [],
- "source": [
- "sampled_indices = tf.random.categorical(pred[0], num_samples=1)\n",
- "sampled_indices = tf.squeeze(sampled_indices,axis=-1).numpy()\n",
- "sampled_indices"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "LfLtsP3mUhCG"
- },
- "source": [
- "We can now decode these to see the text predicted by the untrained model:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "xWcFwPwLSo05"
- },
- "outputs": [],
- "source": [
- "print(\"Input: \\n\", repr(\"\".join(idx2char[x[0]])))\n",
- "print()\n",
- "print(\"Next Char Predictions: \\n\", repr(\"\".join(idx2char[sampled_indices])))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "HEHHcRasIDm9"
- },
- "source": [
- "As you can see, the text predicted by the untrained model is pretty nonsensical! How can we do better? We can train the network!"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "LJL0Q0YPY6Ee"
- },
- "source": [
- "## 2.5 Training the model: loss and training operations\n",
- "\n",
- "Now it's time to train the model!\n",
- "\n",
- "At this point, we can think of our next character prediction problem as a standard classification problem. Given the previous state of the RNN, as well as the input at a given time step, we want to predict the class of the next character -- that is, to actually predict the next character.\n",
- "\n",
- "To train our model on this classification task, we can use a form of the `crossentropy` loss (negative log likelihood loss). Specifically, we will use the [`sparse_categorical_crossentropy`](https://www.tensorflow.org/api_docs/python/tf/keras/losses/sparse_categorical_crossentropy) loss, as it utilizes integer targets for categorical classification tasks. We will want to compute the loss using the true targets -- the `labels` -- and the predicted targets -- the `logits`.\n",
- "\n",
- "Let's first compute the loss using our example predictions from the untrained model:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "4HrXTACTdzY-"
- },
- "outputs": [],
- "source": [
- "### Defining the loss function ###\n",
- "\n",
- "'''TODO: define the loss function to compute and return the loss between\n",
- " the true labels and predictions (logits). Set the argument from_logits=True.'''\n",
- "def compute_loss(labels, logits):\n",
- " loss = tf.keras.losses.sparse_categorical_crossentropy(labels, logits, from_logits=True)\n",
- " # loss = tf.keras.losses.sparse_categorical_crossentropy('''TODO''', '''TODO''', from_logits=True) # TODO\n",
- " return loss\n",
- "\n",
- "'''TODO: compute the loss using the true next characters from the example batch\n",
- " and the predictions from the untrained model several cells above'''\n",
- "example_batch_loss = compute_loss(y, pred)\n",
- "# example_batch_loss = compute_loss('''TODO''', '''TODO''') # TODO\n",
- "\n",
- "print(\"Prediction shape: \", pred.shape, \" # (batch_size, sequence_length, vocab_size)\")\n",
- "print(\"scalar_loss: \", example_batch_loss.numpy().mean())"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "0Seh7e6eRqd7"
- },
- "source": [
- "Let's start by defining some hyperparameters for training the model. To start, we have provided some reasonable values for some of the parameters. It is up to you to use what we've learned in class to help optimize the parameter selection here!"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "JQWUUhKotkAY"
- },
- "outputs": [],
- "source": [
- "### Hyperparameter setting and optimization ###\n",
- "\n",
- "vocab_size = len(vocab)\n",
- "\n",
- "# Model parameters:\n",
- "params = dict(\n",
- " num_training_iterations = 3000, # Increase this to train longer\n",
- " batch_size = 8, # Experiment between 1 and 64\n",
- " seq_length = 100, # Experiment between 50 and 500\n",
- " learning_rate = 5e-3, # Experiment between 1e-5 and 1e-1\n",
- " embedding_dim = 256,\n",
- " rnn_units = 1024, # Experiment between 1 and 2048\n",
- ")\n",
- "\n",
- "# Checkpoint location:\n",
- "checkpoint_dir = './training_checkpoints'\n",
- "checkpoint_prefix = os.path.join(checkpoint_dir, \"my_ckpt.weights.h5\")\n",
- "os.makedirs(checkpoint_dir, exist_ok=True)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "AyLzIPeAIqfg"
- },
- "source": [
- "Having defined our hyperparameters we can set up for experiment tracking with Comet. [`Experiment`](https://www.comet.com/docs/v2/api-and-sdk/python-sdk/reference/Experiment/) are the core objects in Comet and will allow us to track training and model development. Here we have written a short function to create a new comet experiment. Note that in this setup, when hyperparameters change, you can run the `create_experiment()` function to initiate a new experiment. All experiments defined with the same `project_name` will live under that project in your Comet interface.\n",
- "\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "MBsN1vvxInmN"
- },
- "outputs": [],
- "source": [
- "### Create a Comet experiment to track our training run ###\n",
- "\n",
- "def create_experiment():\n",
- " # end any prior experiments\n",
- " if 'experiment' in locals():\n",
- " experiment.end()\n",
- "\n",
- " # initiate the comet experiment for tracking\n",
- " experiment = comet_ml.Experiment(\n",
- " api_key=COMET_API_KEY,\n",
- " project_name=\"6S191_Lab1_Part2\")\n",
- " # log our hyperparameters, defined above, to the experiment\n",
- " for param, value in params.items():\n",
- " experiment.log_parameter(param, value)\n",
- " experiment.flush()\n",
- "\n",
- " return experiment"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "5cu11p1MKYZd"
- },
- "source": [
- "Now, we are ready to define our training operation -- the optimizer and duration of training -- and use this function to train the model. You will experiment with the choice of optimizer and the duration for which you train your models, and see how these changes affect the network's output. Some optimizers you may like to try are [`Adam`](https://www.tensorflow.org/api_docs/python/tf/keras/optimizers/Adam?version=stable) and [`Adagrad`](https://www.tensorflow.org/api_docs/python/tf/keras/optimizers/Adagrad?version=stable).\n",
- "\n",
- "First, we will instantiate a new model and an optimizer. Then, we will use the [`tf.GradientTape`](https://www.tensorflow.org/api_docs/python/tf/GradientTape) method to perform the backpropagation operations.\n",
- "\n",
- "We will also generate a print-out of the model's progress through training, which will help us easily visualize whether or not we are minimizing the loss."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "F31vzJ_u66cb"
- },
- "outputs": [],
- "source": [
- "### Define optimizer and training operation ###\n",
- "\n",
- "'''TODO: instantiate a new model for training using the `build_model`\n",
- " function and the hyperparameters created above.'''\n",
- "model = build_model(vocab_size, params[\"embedding_dim\"], params[\"rnn_units\"], params[\"batch_size\"])\n",
- "# model = build_model('''TODO: arguments''')\n",
- "\n",
- "'''TODO: instantiate an optimizer with its learning rate.\n",
- " Checkout the tensorflow website for a list of supported optimizers.\n",
- " https://www.tensorflow.org/api_docs/python/tf/keras/optimizers/\n",
- " Try using the Adam optimizer to start.'''\n",
- "optimizer = tf.keras.optimizers.Adam(params[\"learning_rate\"])\n",
- "# optimizer = # TODO\n",
- "\n",
- "@tf.function\n",
- "def train_step(x, y):\n",
- " # Use tf.GradientTape()\n",
- " with tf.GradientTape() as tape:\n",
- "\n",
- " '''TODO: feed the current input into the model and generate predictions'''\n",
- " y_hat = model(x) # TODO\n",
- " # y_hat = model('''TODO''')\n",
- "\n",
- " '''TODO: compute the loss!'''\n",
- " loss = compute_loss(y, y_hat) # TODO\n",
- " # loss = compute_loss('''TODO''', '''TODO''')\n",
- "\n",
- " # Now, compute the gradients\n",
- " '''TODO: complete the function call for gradient computation.\n",
- " Remember that we want the gradient of the loss with respect all\n",
- " of the model parameters.\n",
- " HINT: use `model.trainable_variables` to get a list of all model\n",
- " parameters.'''\n",
- " grads = tape.gradient(loss, model.trainable_variables) # TODO\n",
- " # grads = tape.gradient('''TODO''', '''TODO''')\n",
- "\n",
- " # Apply the gradients to the optimizer so it can update the model accordingly\n",
- " optimizer.apply_gradients(zip(grads, model.trainable_variables))\n",
- " return loss\n",
- "\n",
- "##################\n",
- "# Begin training!#\n",
- "##################\n",
- "\n",
- "history = []\n",
- "plotter = mdl.util.PeriodicPlotter(sec=2, xlabel='Iterations', ylabel='Loss')\n",
- "experiment = create_experiment()\n",
- "\n",
- "if hasattr(tqdm, '_instances'): tqdm._instances.clear() # clear if it exists\n",
- "for iter in tqdm(range(params[\"num_training_iterations\"])):\n",
- "\n",
- " # Grab a batch and propagate it through the network\n",
- " x_batch, y_batch = get_batch(vectorized_songs, params[\"seq_length\"], params[\"batch_size\"])\n",
- " loss = train_step(x_batch, y_batch)\n",
- "\n",
- " # log the loss to the Comet interface! we will be able to track it there.\n",
- " experiment.log_metric(\"loss\", loss.numpy().mean(), step=iter)\n",
- " # Update the progress bar and also visualize within notebook\n",
- " history.append(loss.numpy().mean())\n",
- " plotter.plot(history)\n",
- "\n",
- " # Update the model with the changed weights!\n",
- " if iter % 100 == 0:\n",
- " model.save_weights(checkpoint_prefix)\n",
- "\n",
- "# Save the trained model and the weights\n",
- "model.save_weights(checkpoint_prefix)\n",
- "experiment.flush()\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "kKkD5M6eoSiN"
- },
- "source": [
- "## 2.6 Generate music using the RNN model\n",
- "\n",
- "Now, we can use our trained RNN model to generate some music! When generating music, we'll have to feed the model some sort of seed to get it started (because it can't predict anything without something to start with!).\n",
- "\n",
- "Once we have a generated seed, we can then iteratively predict each successive character (remember, we are using the ABC representation for our music) using our trained RNN. More specifically, recall that our RNN outputs a `softmax` over possible successive characters. For inference, we iteratively sample from these distributions, and then use our samples to encode a generated song in the ABC format.\n",
- "\n",
- "Then, all we have to do is write it to a file and listen!"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "JIPcXllKjkdr"
- },
- "source": [
- "\n",
- "### Restore the latest checkpoint\n",
- "\n",
- "To keep this inference step simple, we will use a batch size of 1. Because of how the RNN state is passed from timestep to timestep, the model will only be able to accept a fixed batch size once it is built.\n",
- "\n",
- "To run the model with a different `batch_size`, we'll need to rebuild the model and restore the weights from the latest checkpoint, i.e., the weights after the last checkpoint during training:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "LycQ-ot_jjyu"
- },
- "outputs": [],
- "source": [
- "'''TODO: Rebuild the model using a batch_size=1'''\n",
- "model = build_model(vocab_size, params[\"embedding_dim\"], params[\"rnn_units\"], batch_size=1) # TODO\n",
- "# model = build_model('''TODO''', '''TODO''', '''TODO''', batch_size=1)\n",
- "\n",
- "# Restore the model weights for the last checkpoint after training\n",
- "model.build(tf.TensorShape([1, None]))\n",
- "model.load_weights(checkpoint_prefix)\n",
- "\n",
- "model.summary()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "I9b4V2C8N62l"
- },
- "source": [
- "Notice that we have fed in a fixed `batch_size` of 1 for inference."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "DjGz1tDkzf-u"
- },
- "source": [
- "### The prediction procedure\n",
- "\n",
- "Now, we're ready to write the code to generate text in the ABC music format:\n",
- "\n",
- "* Initialize a \"seed\" start string and the RNN state, and set the number of characters we want to generate.\n",
- "\n",
- "* Use the start string and the RNN state to obtain the probability distribution over the next predicted character.\n",
- "\n",
- "* Sample from multinomial distribution to calculate the index of the predicted character. This predicted character is then used as the next input to the model.\n",
- "\n",
- "* At each time step, the updated RNN state is fed back into the model, so that it now has more context in making the next prediction. After predicting the next character, the updated RNN states are again fed back into the model, which is how it learns sequence dependencies in the data, as it gets more information from the previous predictions.\n",
- "\n",
- "\n",
- "\n",
- "Complete and experiment with this code block (as well as some of the aspects of network definition and training!), and see how the model performs. How do songs generated after training with a small number of epochs compare to those generated after a longer duration of training?"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "WvuwZBX5Ogfd"
- },
- "outputs": [],
- "source": [
- "### Prediction of a generated song ###\n",
- "\n",
- "def generate_text(model, start_string, generation_length=1000):\n",
- " # Evaluation step (generating ABC text using the learned RNN model)\n",
- "\n",
- " '''TODO: convert the start string to numbers (vectorize)'''\n",
- " input_eval = [char2idx[s] for s in start_string] # TODO\n",
- " # input_eval = ['''TODO''']\n",
- " input_eval = tf.expand_dims(input_eval, 0)\n",
- "\n",
- " # Empty string to store our results\n",
- " text_generated = []\n",
- "\n",
- " # Here batch size == 1\n",
- " model.reset_states()\n",
- " tqdm._instances.clear()\n",
- "\n",
- " for i in tqdm(range(generation_length)):\n",
- " '''TODO: evaluate the inputs and generate the next character predictions'''\n",
- " predictions = model(input_eval)\n",
- " # predictions = model('''TODO''')\n",
- "\n",
- " # Remove the batch dimension\n",
- " predictions = tf.squeeze(predictions, 0)\n",
- "\n",
- " '''TODO: use a multinomial distribution to sample'''\n",
- " predicted_id = tf.random.categorical(predictions, num_samples=1)[-1,0].numpy()\n",
- " # predicted_id = tf.random.categorical('''TODO''', num_samples=1)[-1,0].numpy()\n",
- "\n",
- " # Pass the prediction along with the previous hidden state\n",
- " # as the next inputs to the model\n",
- " input_eval = tf.expand_dims([predicted_id], 0)\n",
- "\n",
- " '''TODO: add the predicted character to the generated text!'''\n",
- " # Hint: consider what format the prediction is in vs. the output\n",
- " text_generated.append(idx2char[predicted_id]) # TODO\n",
- " # text_generated.append('''TODO''')\n",
- "\n",
- " return (start_string + ''.join(text_generated))"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "ktovv0RFhrkn"
- },
- "outputs": [],
- "source": [
- "'''TODO: Use the model and the function defined above to generate ABC format text of length 1000!\n",
- " As you may notice, ABC files start with \"X\" - this may be a good start string.'''\n",
- "generated_text = generate_text(model, start_string=\"X\", generation_length=1000) # TODO\n",
- "# generated_text = generate_text('''TODO''', start_string=\"X\", generation_length=1000)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "AM2Uma_-yVIq"
- },
- "source": [
- "### Play back the generated music!\n",
- "\n",
- "We can now call a function to convert the ABC format text to an audio file, and then play that back to check out our generated music! Try training longer if the resulting song is not long enough, or re-generating the song!\n",
- "\n",
- "We will save the song to Comet -- you will be able to find your songs under the `Audio` and `Assets & Artificats` pages in your Comet interface for the project. Note the [`log_asset()`](https://www.comet.com/docs/v2/api-and-sdk/python-sdk/reference/Experiment/#experimentlog_asset) documentation, where you will see how to specify file names and other parameters for saving your assets."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "LrOtG64bfLto"
- },
- "outputs": [],
- "source": [
- "### Play back generated songs ###\n",
- "\n",
- "generated_songs = mdl.lab1.extract_song_snippet(generated_text)\n",
- "\n",
- "for i, song in enumerate(generated_songs):\n",
- " # Synthesize the waveform from a song\n",
- " waveform = mdl.lab1.play_song(song)\n",
- "\n",
- " # If its a valid song (correct syntax), lets play it!\n",
- " if waveform:\n",
- " print(\"Generated song\", i)\n",
- " ipythondisplay.display(waveform)\n",
- "\n",
- " numeric_data = np.frombuffer(waveform.data, dtype=np.int16)\n",
- " wav_file_path = f\"output_{i}.wav\"\n",
- " write(wav_file_path, 88200, numeric_data)\n",
- "\n",
- " # save your song to the Comet interface -- you can access it there\n",
- " experiment.log_asset(wav_file_path)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "4353qSV76gnJ"
- },
- "outputs": [],
- "source": [
- "# when done, end the comet experiment\n",
- "experiment.end()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "HgVvcrYmSKGG"
- },
- "source": [
- "## 2.7 Experiment and **get awarded for the best songs**!\n",
- "\n",
- "Congrats on making your first sequence model in TensorFlow! It's a pretty big accomplishment, and hopefully you have some sweet tunes to show for it.\n",
- "\n",
- "Consider how you may improve your model and what seems to be most important in terms of performance. Here are some ideas to get you started:\n",
- "\n",
- "* How does the number of training epochs affect the performance?\n",
- "* What if you alter or augment the dataset?\n",
- "* Does the choice of start string significantly affect the result?\n",
- "\n",
- "Try to optimize your model and submit your best song! **Participants will be eligible for prizes during the January 2025 offering. To enter the competition, you must upload the following to [this submission link](https://www.dropbox.com/request/U8nND6enGjirujVZKX1n):**\n",
- "\n",
- "* a recording of your song;\n",
- "* iPython notebook with the code you used to generate the song;\n",
- "* a description and/or diagram of the architecture and hyperparameters you used -- if there are any additional or interesting modifications you made to the template code, please include these in your description.\n",
- "\n",
- "**Name your file in the following format: ``[FirstName]_[LastName]_RNNMusic``, followed by the file format (.zip, .mp4, .ipynb, .pdf, etc). ZIP files of all three components are preferred over individual files. If you submit individual files, you must name the individual files according to the above nomenclature.**\n",
- "\n",
- "You can also tweet us at [@MITDeepLearning](https://twitter.com/MITDeepLearning) a copy of the song (but this will not enter you into the competition)! See this example song generated by a previous student (credit Ana Heart): song from May 20, 2020.\n",
- "\n",
- "\n",
- "Have fun and happy listening!\n",
- "\n",
- "\n"
- ]
- }
- ],
- "metadata": {
- "accelerator": "GPU",
- "colab": {
- "collapsed_sections": [
- "uoJsVjtCMunI"
- ],
- "name": "TF_Part2_Music_Generation_Solution.ipynb",
- "provenance": []
- },
- "kernelspec": {
- "display_name": "Python 3",
- "name": "python3"
- },
- "language_info": {
- "codemirror_mode": {
- "name": "ipython",
- "version": 3
- },
- "file_extension": ".py",
- "mimetype": "text/x-python",
- "name": "python",
- "nbconvert_exporter": "python",
- "pygments_lexer": "ipython3",
- "version": "3.11.11"
- }
- },
- "nbformat": 4,
- "nbformat_minor": 0
-}
\ No newline at end of file
diff --git a/lab2/TF_Part1_MNIST.ipynb b/lab2/TF_Part1_MNIST.ipynb
deleted file mode 100644
index 81549151..00000000
--- a/lab2/TF_Part1_MNIST.ipynb
+++ /dev/null
@@ -1,772 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Xmf_JRJa_N8C"
- },
- "source": [
- "\n",
- "\n",
- "# Copyright Information"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "gKA_J7bdP33T"
- },
- "outputs": [],
- "source": [
- "# Copyright 2025 MIT Introduction to Deep Learning. All Rights Reserved.\n",
- "#\n",
- "# Licensed under the MIT License. You may not use this file except in compliance\n",
- "# with the License. Use and/or modification of this code outside of MIT Introduction\n",
- "# to Deep Learning must reference:\n",
- "#\n",
- "# © MIT Introduction to Deep Learning\n",
- "# http://introtodeeplearning.com\n",
- "#"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Cm1XpLftPi4A"
- },
- "source": [
- "# Laboratory 2: Computer Vision\n",
- "\n",
- "# Part 1: MNIST Digit Classification\n",
- "\n",
- "In the first portion of this lab, we will build and train a convolutional neural network (CNN) for classification of handwritten digits from the famous [MNIST](http://yann.lecun.com/exdb/mnist/) dataset. The MNIST dataset consists of 60,000 training images and 10,000 test images. Our classes are the digits 0-9.\n",
- "\n",
- "First, let's download the course repository, install dependencies, and import the relevant packages we'll need for this lab."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "RsGqx_ai_N8F"
- },
- "outputs": [],
- "source": [
- "# Import Tensorflow 2.0\n",
- "# !pip install tensorflow\n",
- "import tensorflow as tf\n",
- "\n",
- "# MIT introduction to deep learning package\n",
- "!pip install mitdeeplearning --quiet\n",
- "import mitdeeplearning as mdl\n",
- "\n",
- "# other packages\n",
- "import matplotlib.pyplot as plt\n",
- "import numpy as np\n",
- "import random\n",
- "from tqdm import tqdm"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "nCpHDxX1bzyZ"
- },
- "source": [
- "We'll also install Comet. If you followed the instructions from Lab 1, you should have your Comet account set up. Enter your API key below."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "GSR_PAqjbzyZ"
- },
- "outputs": [],
- "source": [
- "!pip install comet_ml > /dev/null 2>&1\n",
- "import comet_ml\n",
- "# TODO: ENTER YOUR API KEY HERE!!\n",
- "COMET_API_KEY = \"\"\n",
- "\n",
- "# Check that we are using a GPU, if not switch runtimes\n",
- "# using Runtime > Change Runtime Type > GPU\n",
- "assert len(tf.config.list_physical_devices('GPU')) > 0\n",
- "assert COMET_API_KEY != \"\", \"Please insert your Comet API Key\""
- ]
- },
- {
- "cell_type": "code",
- "source": [
- "# start a first comet experiment for the first part of the lab\n",
- "comet_ml.init(project_name=\"6S191_lab2_part1_NN\")\n",
- "comet_model_1 = comet_ml.Experiment()"
- ],
- "metadata": {
- "id": "wGPDtVxvTtPk"
- },
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "HKjrdUtX_N8J"
- },
- "source": [
- "## 1.1 MNIST dataset\n",
- "\n",
- "Let's download and load the dataset and display a few random samples from it:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "p2dQsHI3_N8K"
- },
- "outputs": [],
- "source": [
- "mnist = tf.keras.datasets.mnist\n",
- "(train_images, train_labels), (test_images, test_labels) = mnist.load_data()\n",
- "train_images = (np.expand_dims(train_images, axis=-1)/255.).astype(np.float32)\n",
- "train_labels = (train_labels).astype(np.int64)\n",
- "test_images = (np.expand_dims(test_images, axis=-1)/255.).astype(np.float32)\n",
- "test_labels = (test_labels).astype(np.int64)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "5ZtUqOqePsRD"
- },
- "source": [
- "Our training set is made up of 28x28 grayscale images of handwritten digits.\n",
- "\n",
- "Let's visualize what some of these images and their corresponding training labels look like."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "bDBsR2lP_N8O",
- "scrolled": true
- },
- "outputs": [],
- "source": [
- "plt.figure(figsize=(10,10))\n",
- "random_inds = np.random.choice(60000,36)\n",
- "for i in range(36):\n",
- " plt.subplot(6,6,i+1)\n",
- " plt.xticks([])\n",
- " plt.yticks([])\n",
- " plt.grid(False)\n",
- " image_ind = random_inds[i]\n",
- " plt.imshow(np.squeeze(train_images[image_ind]), cmap=plt.cm.binary)\n",
- " plt.xlabel(train_labels[image_ind])\n",
- "comet_model_1.log_figure(figure=plt)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "V6hd3Nt1_N8q"
- },
- "source": [
- "## 1.2 Neural Network for Handwritten Digit Classification\n",
- "\n",
- "We'll first build a simple neural network consisting of two fully connected layers and apply this to the digit classification task. Our network will ultimately output a probability distribution over the 10 digit classes (0-9). This first architecture we will be building is depicted below:\n",
- "\n",
- "\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "rphS2rMIymyZ"
- },
- "source": [
- "### Fully connected neural network architecture\n",
- "To define the architecture of this first fully connected neural network, we'll once again use the Keras API and define the model using the [`Sequential`](https://www.tensorflow.org/api_docs/python/tf/keras/models/Sequential) class. Note how we first use a [`Flatten`](https://www.tensorflow.org/api_docs/python/tf/keras/layers/Flatten) layer, which flattens the input so that it can be fed into the model.\n",
- "\n",
- "In this next block, you'll define the fully connected layers of this simple work."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "MMZsbjAkDKpU"
- },
- "outputs": [],
- "source": [
- "def build_fc_model():\n",
- " fc_model = tf.keras.Sequential([\n",
- " # First define a Flatten layer\n",
- " tf.keras.layers.Flatten(),\n",
- "\n",
- " # '''TODO: Define the activation function for the first fully connected (Dense) layer.'''\n",
- " tf.keras.layers.Dense(128, activation= '''TODO'''),\n",
- "\n",
- " # '''TODO: Define the second Dense layer to output the classification probabilities'''\n",
- " '''[TODO Dense layer to output classification probabilities]'''\n",
- "\n",
- " ])\n",
- " return fc_model\n",
- "\n",
- "model = build_fc_model()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "VtGZpHVKz5Jt"
- },
- "source": [
- "As we progress through this next portion, you may find that you'll want to make changes to the architecture defined above. **Note that in order to update the model later on, you'll need to re-run the above cell to re-initialize the model.**"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "mVN1_AeG_N9N"
- },
- "source": [
- "Let's take a step back and think about the network we've just created. The first layer in this network, `tf.keras.layers.Flatten`, transforms the format of the images from a 2d-array (28 x 28 pixels), to a 1d-array of 28 * 28 = 784 pixels. You can think of this layer as unstacking rows of pixels in the image and lining them up. There are no learned parameters in this layer; it only reformats the data.\n",
- "\n",
- "After the pixels are flattened, the network consists of a sequence of two `tf.keras.layers.Dense` layers. These are fully-connected neural layers. The first `Dense` layer has 128 nodes (or neurons). The second (and last) layer (which you've defined!) should return an array of probability scores that sum to 1. Each node contains a score that indicates the probability that the current image belongs to one of the handwritten digit classes.\n",
- "\n",
- "That defines our fully connected model!"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "gut8A_7rCaW6"
- },
- "source": [
- "\n",
- "\n",
- "### Compile the model\n",
- "\n",
- "Before training the model, we need to define a few more settings. These are added during the model's [`compile`](https://www.tensorflow.org/api_docs/python/tf/keras/models/Sequential#compile) step:\n",
- "\n",
- "* *Loss function* — This defines how we measure how accurate the model is during training. As was covered in lecture, during training we want to minimize this function, which will \"steer\" the model in the right direction.\n",
- "* *Optimizer* — This defines how the model is updated based on the data it sees and its loss function.\n",
- "* *Metrics* — Here we can define metrics used to monitor the training and testing steps. In this example, we'll look at the *accuracy*, the fraction of the images that are correctly classified.\n",
- "\n",
- "We'll start out by using a stochastic gradient descent (SGD) optimizer initialized with a learning rate of 0.1. Since we are performing a categorical classification task, we'll want to use the [cross entropy loss](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/sparse_categorical_crossentropy).\n",
- "\n",
- "You'll want to experiment with both the choice of optimizer and learning rate and evaluate how these affect the accuracy of the trained model."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "Lhan11blCaW7"
- },
- "outputs": [],
- "source": [
- "'''TODO: Experiment with different optimizers and learning rates. How do these affect\n",
- " the accuracy of the trained model? Which optimizers and/or learning rates yield\n",
- " the best performance?'''\n",
- "model.compile(optimizer=tf.keras.optimizers.SGD(learning_rate=1e-1),\n",
- " loss='sparse_categorical_crossentropy',\n",
- " metrics=['accuracy'])"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "qKF6uW-BCaW-"
- },
- "source": [
- "### Train the model\n",
- "\n",
- "We're now ready to train our model, which will involve feeding the training data (`train_images` and `train_labels`) into the model, and then asking it to learn the associations between images and labels. We'll also need to define the batch size and the number of epochs, or iterations over the MNIST dataset, to use during training.\n",
- "\n",
- "In Lab 1, we saw how we can use `GradientTape` to optimize losses and train models with stochastic gradient descent. After defining the model settings in the `compile` step, we can also accomplish training by calling the [`fit`](https://www.tensorflow.org/api_docs/python/tf/keras/models/Sequential#fit) method on an instance of the `Model` class. We will use this to train our fully connected model\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "EFMbIqIvQ2X0"
- },
- "outputs": [],
- "source": [
- "# Define the batch size and the number of epochs to use during training\n",
- "BATCH_SIZE = 64\n",
- "EPOCHS = 5\n",
- "\n",
- "model.fit(train_images, train_labels, batch_size=BATCH_SIZE, epochs=EPOCHS)\n",
- "comet_model_1.end()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "W3ZVOhugCaXA"
- },
- "source": [
- "As the model trains, the loss and accuracy metrics are displayed. With five epochs and a learning rate of 0.01, this fully connected model should achieve an accuracy of approximatley 0.97 (or 97%) on the training data."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "oEw4bZgGCaXB"
- },
- "source": [
- "### Evaluate accuracy on the test dataset\n",
- "\n",
- "Now that we've trained the model, we can ask it to make predictions about a test set that it hasn't seen before. In this example, the `test_images` array comprises our test dataset. To evaluate accuracy, we can check to see if the model's predictions match the labels from the `test_labels` array.\n",
- "\n",
- "Use the [`evaluate`](https://www.tensorflow.org/api_docs/python/tf/keras/models/Sequential#evaluate) method to evaluate the model on the test dataset!"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "VflXLEeECaXC"
- },
- "outputs": [],
- "source": [
- "'''TODO: Use the evaluate method to test the model!'''\n",
- "test_loss, test_acc = # TODO\n",
- "\n",
- "print('Test accuracy:', test_acc)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "yWfgsmVXCaXG"
- },
- "source": [
- "You may observe that the accuracy on the test dataset is a little lower than the accuracy on the training dataset. This gap between training accuracy and test accuracy is an example of *overfitting*, when a machine learning model performs worse on new data than on its training data.\n",
- "\n",
- "What is the highest accuracy you can achieve with this first fully connected model? Since the handwritten digit classification task is pretty straightforward, you may be wondering how we can do better...\n",
- "\n",
- ""
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "baIw9bDf8v6Z"
- },
- "source": [
- "## 1.3 Convolutional Neural Network (CNN) for handwritten digit classification"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "_J72Yt1o_fY7"
- },
- "source": [
- "As we saw in lecture, convolutional neural networks (CNNs) are particularly well-suited for a variety of tasks in computer vision, and have achieved near-perfect accuracies on the MNIST dataset. We will now build a CNN composed of two convolutional layers and pooling layers, followed by two fully connected layers, and ultimately output a probability distribution over the 10 digit classes (0-9). The CNN we will be building is depicted below:\n",
- "\n",
- ""
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "EEHqzbJJAEoR"
- },
- "source": [
- "### Define the CNN model\n",
- "\n",
- "We'll use the same training and test datasets as before, and proceed similarly as our fully connected network to define and train our new CNN model. To do this we will explore two layers we have not encountered before: you can use [`keras.layers.Conv2D` ](https://www.tensorflow.org/api_docs/python/tf/keras/layers/Conv2D) to define convolutional layers and [`keras.layers.MaxPool2D`](https://www.tensorflow.org/api_docs/python/tf/keras/layers/MaxPool2D) to define the pooling layers. Use the parameters shown in the network architecture above to define these layers and build the CNN model."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "vec9qcJs-9W5"
- },
- "outputs": [],
- "source": [
- "def build_cnn_model():\n",
- " cnn_model = tf.keras.Sequential([\n",
- "\n",
- " # TODO: Define the first convolutional layer\n",
- " tf.keras.layers.Conv2D('''TODO''')\n",
- "\n",
- " # TODO: Define the first max pooling layer\n",
- " tf.keras.layers.MaxPool2D('''TODO''')\n",
- "\n",
- " # TODO: Define the second convolutional layer\n",
- " tf.keras.layers.Conv2D('''TODO''')\n",
- "\n",
- " # TODO: Define the second max pooling layer\n",
- " tf.keras.layers.MaxPool2D('''TODO''')\n",
- "\n",
- " tf.keras.layers.Flatten(),\n",
- " tf.keras.layers.Dense(128, activation=tf.nn.relu),\n",
- "\n",
- " # TODO: Define the last Dense layer to output the classification\n",
- " # probabilities. Pay attention to the activation needed a probability\n",
- " # output\n",
- " '''[TODO Dense layer to output classification probabilities]'''\n",
- " ])\n",
- "\n",
- " return cnn_model\n",
- "\n",
- "cnn_model = build_cnn_model()\n",
- "# Initialize the model by passing some data through\n",
- "cnn_model.predict(train_images[[0]])\n",
- "# Print the summary of the layers in the model.\n",
- "print(cnn_model.summary())"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "kUAXIBynCih2"
- },
- "source": [
- "### Train and test the CNN model\n",
- "\n",
- "Now, as before, we can define the loss function, optimizer, and metrics through the `compile` method. Compile the CNN model with an optimizer and learning rate of choice:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "vheyanDkCg6a"
- },
- "outputs": [],
- "source": [
- "comet_ml.init(project_name=\"6.s191lab2_part1_CNN\")\n",
- "comet_model_2 = comet_ml.Experiment()\n",
- "\n",
- "'''TODO: Define the compile operation with your optimizer and learning rate of choice'''\n",
- "cnn_model.compile(optimizer='''TODO''', loss='''TODO''', metrics=['accuracy']) # TODO"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "U19bpRddC7H_"
- },
- "source": [
- "As was the case with the fully connected model, we can train our CNN using the `fit` method via the Keras API."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "YdrGZVmWDK4p"
- },
- "outputs": [],
- "source": [
- "'''TODO: Use model.fit to train the CNN model, with the same batch_size and number of epochs previously used.'''\n",
- "cnn_model.fit('''TODO''')\n",
- "# comet_model_2.end()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "pEszYWzgDeIc"
- },
- "source": [
- "Great! Now that we've trained the model, let's evaluate it on the test dataset using the [`evaluate`](https://www.tensorflow.org/api_docs/python/tf/keras/models/Sequential#evaluate) method:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "JDm4znZcDtNl"
- },
- "outputs": [],
- "source": [
- "'''TODO: Use the evaluate method to test the model!'''\n",
- "test_loss, test_acc = # TODO\n",
- "\n",
- "print('Test accuracy:', test_acc)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "2rvEgK82Glv9"
- },
- "source": [
- "What is the highest accuracy you're able to achieve using the CNN model, and how does the accuracy of the CNN model compare to the accuracy of the simple fully connected network? What optimizers and learning rates seem to be optimal for training the CNN model?\n",
- "\n",
- "Feel free to click the Comet links to investigate the training/accuracy curves for your model."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "xsoS7CPDCaXH"
- },
- "source": [
- "### Make predictions with the CNN model\n",
- "\n",
- "With the model trained, we can use it to make predictions about some images. The [`predict`](https://www.tensorflow.org/api_docs/python/tf/keras/models/Sequential#predict) function call generates the output predictions given a set of input samples.\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "Gl91RPhdCaXI"
- },
- "outputs": [],
- "source": [
- "predictions = cnn_model.predict(test_images)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "x9Kk1voUCaXJ"
- },
- "source": [
- "With this function call, the model has predicted the label for each image in the testing set. Let's take a look at the prediction for the first image in the test dataset:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "3DmJEUinCaXK"
- },
- "outputs": [],
- "source": [
- "predictions[0]"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "-hw1hgeSCaXN"
- },
- "source": [
- "As you can see, a prediction is an array of 10 numbers. Recall that the output of our model is a probability distribution over the 10 digit classes. Thus, these numbers describe the model's \"confidence\" that the image corresponds to each of the 10 different digits.\n",
- "\n",
- "Let's look at the digit that has the highest confidence for the first image in the test dataset:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "qsqenuPnCaXO"
- },
- "outputs": [],
- "source": [
- "'''TODO: identify the digit with the highest confidence prediction for the first\n",
- " image in the test dataset. '''\n",
- "prediction = # TODO\n",
- "\n",
- "print(prediction)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "E51yS7iCCaXO"
- },
- "source": [
- "So, the model is most confident that this image is a \"???\". We can check the test label (remember, this is the true identity of the digit) to see if this prediction is correct:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "Sd7Pgsu6CaXP"
- },
- "outputs": [],
- "source": [
- "print(\"Label of this digit is:\", test_labels[0])\n",
- "plt.imshow(test_images[0,:,:,0], cmap=plt.cm.binary)\n",
- "comet_model_2.log_figure(figure=plt)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "ygh2yYC972ne"
- },
- "source": [
- "It is! Let's visualize the classification results on the MNIST dataset. We will plot images from the test dataset along with their predicted label, as well as a histogram that provides the prediction probabilities for each of the digits:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "HV5jw-5HwSmO"
- },
- "outputs": [],
- "source": [
- "#@title Change the slider to look at the model's predictions! { run: \"auto\" }\n",
- "\n",
- "image_index = 79 #@param {type:\"slider\", min:0, max:100, step:1}\n",
- "plt.subplot(1,2,1)\n",
- "mdl.lab2.plot_image_prediction(image_index, predictions, test_labels, test_images)\n",
- "plt.subplot(1,2,2)\n",
- "mdl.lab2.plot_value_prediction(image_index, predictions, test_labels)\n",
- "comet_model_2.log_figure(figure=plt)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "kgdvGD52CaXR"
- },
- "source": [
- "We can also plot several images along with their predictions, where correct prediction labels are blue and incorrect prediction labels are grey. The number gives the percent confidence (out of 100) for the predicted label. Note the model can be very confident in an incorrect prediction!"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "hQlnbqaw2Qu_"
- },
- "outputs": [],
- "source": [
- "# Plots the first X test images, their predicted label, and the true label\n",
- "# Color correct predictions in blue, incorrect predictions in red\n",
- "num_rows = 5\n",
- "num_cols = 4\n",
- "num_images = num_rows*num_cols\n",
- "plt.figure(figsize=(2*2*num_cols, 2*num_rows))\n",
- "for i in range(num_images):\n",
- " plt.subplot(num_rows, 2*num_cols, 2*i+1)\n",
- " mdl.lab2.plot_image_prediction(i, predictions, test_labels, test_images)\n",
- " plt.subplot(num_rows, 2*num_cols, 2*i+2)\n",
- " mdl.lab2.plot_value_prediction(i, predictions, test_labels)\n",
- "comet_model_2.log_figure(figure=plt)\n",
- "comet_model_2.end()\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "k-2glsRiMdqa"
- },
- "source": [
- "## 1.4 Training the model 2.0\n",
- "\n",
- "Earlier in the lab, we used the [`fit`](https://www.tensorflow.org/api_docs/python/tf/keras/models/Sequential#fit) function call to train the model. This function is quite high-level and intuitive, which is really useful for simpler models. As you may be able to tell, this function abstracts away many details in the training call, and we have less control over training model, which could be useful in other contexts.\n",
- "\n",
- "As an alternative to this, we can use the [`tf.GradientTape`](https://www.tensorflow.org/api_docs/python/tf/GradientTape) class to record differentiation operations during training, and then call the [`tf.GradientTape.gradient`](https://www.tensorflow.org/api_docs/python/tf/GradientTape#gradient) function to actually compute the gradients. You may recall seeing this in Lab 1 Part 1, but let's take another look at this here.\n",
- "\n",
- "We'll use this framework to train our `cnn_model` using stochastic gradient descent."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "Wq34id-iN1Ml"
- },
- "outputs": [],
- "source": [
- "# Rebuild the CNN model\n",
- "cnn_model = build_cnn_model()\n",
- "\n",
- "batch_size = 12\n",
- "loss_history = mdl.util.LossHistory(smoothing_factor=0.95) # to record the evolution of the loss\n",
- "plotter = mdl.util.PeriodicPlotter(sec=2, xlabel='Iterations', ylabel='Loss', scale='semilogy')\n",
- "optimizer = tf.keras.optimizers.SGD(learning_rate=1e-2) # define our optimizer\n",
- "\n",
- "comet_ml.init(project_name=\"6.s191lab2_part1_CNN2\")\n",
- "comet_model_3 = comet_ml.Experiment()\n",
- "\n",
- "if hasattr(tqdm, '_instances'): tqdm._instances.clear() # clear if it exists\n",
- "\n",
- "for idx in tqdm(range(0, train_images.shape[0], batch_size)):\n",
- " # First grab a batch of training data and convert the input images to tensors\n",
- " (images, labels) = (train_images[idx:idx+batch_size], train_labels[idx:idx+batch_size])\n",
- " images = tf.convert_to_tensor(images, dtype=tf.float32)\n",
- "\n",
- " # GradientTape to record differentiation operations\n",
- " with tf.GradientTape() as tape:\n",
- " #'''TODO: feed the images into the model and obtain the predictions'''\n",
- " logits = # TODO\n",
- "\n",
- " #'''TODO: compute the categorical cross entropy loss\n",
- " loss_value = tf.keras.backend.sparse_categorical_crossentropy('''TODO''', '''TODO''') # TODO\n",
- " comet_model_3.log_metric(\"loss\", loss_value.numpy().mean(), step=idx)\n",
- "\n",
- " loss_history.append(loss_value.numpy().mean()) # append the loss to the loss_history record\n",
- " plotter.plot(loss_history.get())\n",
- "\n",
- " # Backpropagation\n",
- " '''TODO: Use the tape to compute the gradient against all parameters in the CNN model.\n",
- " Use cnn_model.trainable_variables to access these parameters.'''\n",
- " grads = # TODO\n",
- " optimizer.apply_gradients(zip(grads, cnn_model.trainable_variables))\n",
- "\n",
- "comet_model_3.log_figure(figure=plt)\n",
- "comet_model_3.end()\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "3cNtDhVaqEdR"
- },
- "source": [
- "## 1.5 Conclusion\n",
- "In this part of the lab, you had the chance to play with different MNIST classifiers with different architectures (fully-connected layers only, CNN), and experiment with how different hyperparameters affect accuracy (learning rate, etc.). The next part of the lab explores another application of CNNs, facial detection, and some drawbacks of AI systems in real world applications, like issues of bias."
- ]
- }
- ],
- "metadata": {
- "accelerator": "GPU",
- "colab": {
- "collapsed_sections": [
- "Xmf_JRJa_N8C"
- ],
- "name": "TF_Part1_MNIST.ipynb",
- "provenance": []
- },
- "kernelspec": {
- "display_name": "Python 3",
- "name": "python3"
- },
- "language_info": {
- "codemirror_mode": {
- "name": "ipython",
- "version": 3
- },
- "file_extension": ".py",
- "mimetype": "text/x-python",
- "name": "python",
- "nbconvert_exporter": "python",
- "pygments_lexer": "ipython3",
- "version": "3.9.6"
- }
- },
- "nbformat": 4,
- "nbformat_minor": 0
-}
diff --git a/lab2/TF_Part2_Debiasing.ipynb b/lab2/TF_Part2_Debiasing.ipynb
deleted file mode 100644
index 494b74c7..00000000
--- a/lab2/TF_Part2_Debiasing.ipynb
+++ /dev/null
@@ -1,1147 +0,0 @@
-{
- "nbformat": 4,
- "nbformat_minor": 0,
- "metadata": {
- "colab": {
- "name": "TF_Part2_Debiasing.ipynb",
- "provenance": [],
- "collapsed_sections": [
- "Ag_e7xtTzT1W",
- "NDj7KBaW8Asz"
- ]
- },
- "kernelspec": {
- "name": "python3",
- "display_name": "Python 3"
- },
- "accelerator": "GPU"
- },
- "cells": [
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Ag_e7xtTzT1W"
- },
- "source": [
- "\n",
- "\n",
- "# Copyright Information"
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "rNbf1pRlSDby"
- },
- "source": [
- "# Copyright 2025 MIT 6.S191 Introduction to Deep Learning. All Rights Reserved.\n",
- "#\n",
- "# Licensed under the MIT License. You may not use this file except in compliance\n",
- "# with the License. Use and/or modification of this code outside of 6.S191 must\n",
- "# reference:\n",
- "#\n",
- "# © MIT 6.S191: Introduction to Deep Learning\n",
- "# http://introtodeeplearning.com\n",
- "#"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "QOpPUH3FR179"
- },
- "source": [
- "# Laboratory 2: Computer Vision\n",
- "\n",
- "# Part 2: Debiasing Facial Detection Systems\n",
- "\n",
- "In the second portion of the lab, we'll explore two prominent aspects of applied deep learning: facial detection and algorithmic bias.\n",
- "\n",
- "Deploying fair, unbiased AI systems is critical to their long-term acceptance. Consider the task of facial detection: given an image, is it an image of a face? This seemingly simple, but extremely important, task is subject to significant amounts of algorithmic bias among select demographics.\n",
- "\n",
- "In this lab, we'll investigate [one recently published approach](http://introtodeeplearning.com/AAAI_MitigatingAlgorithmicBias.pdf) to addressing algorithmic bias. We'll build a facial detection model that learns the *latent variables* underlying face image datasets and uses this to adaptively re-sample the training data, thus mitigating any biases that may be present in order to train a *debiased* model.\n",
- "\n",
- "\n",
- "Run the next code block for a short video from Google that explores how and why it's important to consider bias when thinking about machine learning:"
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "XQh5HZfbupFF"
- },
- "source": [
- "import IPython\n",
- "IPython.display.YouTubeVideo('59bMh59JQDo')"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "3Ezfc6Yv6IhI"
- },
- "source": [
- "Let's get started by installing the relevant dependencies.\n",
- "\n",
- "We will be using Comet ML to track our model development and training runs.\n",
- "\n",
- "1. Sign up for a Comet account: [HERE](https://www.comet.com/signup?utm_source=mit_dl&utm_medium=partner&utm_content=github)\n",
- "2. This will generate a personal API Key, which you can find either in the first 'Get Started with Comet' page, under your account settings, or by pressing the '?' in the top right corner and then 'Quickstart Guide'. Enter this API key as the global variable `COMET_API_KEY` below.\n",
- "\n"
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "E46sWVKK6LP9"
- },
- "source": [
- "!pip install comet_ml --quiet\n",
- "import comet_ml\n",
- "# TODO: ENTER YOUR API KEY HERE!! instructions above\n",
- "COMET_API_KEY = \"\"\n",
- "\n",
- "# Import Tensorflow 2.0\n",
- "import tensorflow as tf\n",
- "\n",
- "import IPython\n",
- "import functools\n",
- "import matplotlib.pyplot as plt\n",
- "import numpy as np\n",
- "from tqdm import tqdm\n",
- "\n",
- "# Download and import the MIT 6.S191 package\n",
- "!pip install mitdeeplearning --quiet\n",
- "import mitdeeplearning as mdl\n",
- "\n",
- "# Check that we are using a GPU, if not switch runtimes\n",
- "# using Runtime > Change Runtime Type > GPU\n",
- "assert len(tf.config.list_physical_devices('GPU')) > 0\n",
- "assert COMET_API_KEY != \"\", \"Please insert your Comet API Key\""
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "V0e77oOM3udR"
- },
- "source": [
- "## 2.1 Datasets\n",
- "\n",
- "We'll be using three datasets in this lab. In order to train our facial detection models, we'll need a dataset of positive examples (i.e., of faces) and a dataset of negative examples (i.e., of things that are not faces). We'll use these data to train our models to classify images as either faces or not faces. Finally, we'll need a test dataset of face images. Since we're concerned about the potential *bias* of our learned models against certain demographics, it's important that the test dataset we use has equal representation across the demographics or features of interest. In this lab, we'll consider skin tone and gender.\n",
- "\n",
- "1. **Positive training data**: [CelebA Dataset](http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html). A large-scale (over 200K images) of celebrity faces. \n",
- "2. **Negative training data**: [ImageNet](http://www.image-net.org/). Many images across many different categories. We'll take negative examples from a variety of non-human categories.\n",
- "[Fitzpatrick Scale](https://en.wikipedia.org/wiki/Fitzpatrick_scale) skin type classification system, with each image labeled as \"Lighter'' or \"Darker''.\n",
- "\n",
- "Let's begin by importing these datasets. We've written a class that does a bit of data pre-processing to import the training data in a usable format."
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "RWXaaIWy6jVw"
- },
- "source": [
- "# Get the training data: both images from CelebA and ImageNet\n",
- "path_to_training_data = tf.keras.utils.get_file('train_face.h5', 'https://www.dropbox.com/s/hlz8atheyozp1yx/train_face.h5?dl=1')\n",
- "# Instantiate a TrainingDatasetLoader using the downloaded dataset\n",
- "loader = mdl.lab2.TrainingDatasetLoader(path_to_training_data)"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "yIE321rxa_b3"
- },
- "source": [
- "We can look at the size of the training dataset and grab a batch of size 100:"
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "DjPSjZZ_bGqe"
- },
- "source": [
- "number_of_training_examples = loader.get_train_size()\n",
- "(images, labels) = loader.get_batch(100)"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "sxtkJoqF6oH1"
- },
- "source": [
- "Play around with displaying images to get a sense of what the training data actually looks like!"
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "Jg17jzwtbxDA"
- },
- "source": [
- "### Examining the CelebA training dataset ###\n",
- "\n",
- "#@title Change the sliders to look at positive and negative training examples! { run: \"auto\" }\n",
- "\n",
- "face_images = images[np.where(labels==1)[0]]\n",
- "not_face_images = images[np.where(labels==0)[0]]\n",
- "\n",
- "idx_face = 23 #@param {type:\"slider\", min:0, max:50, step:1}\n",
- "idx_not_face = 9 #@param {type:\"slider\", min:0, max:50, step:1}\n",
- "\n",
- "plt.figure(figsize=(5,5))\n",
- "plt.subplot(1, 2, 1)\n",
- "plt.imshow(face_images[idx_face])\n",
- "plt.title(\"Face\"); plt.grid(False)\n",
- "\n",
- "plt.subplot(1, 2, 2)\n",
- "plt.imshow(not_face_images[idx_not_face])\n",
- "plt.title(\"Not Face\"); plt.grid(False)"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "NDj7KBaW8Asz"
- },
- "source": [
- "### Thinking about bias\n",
- "\n",
- "Remember we'll be training our facial detection classifiers on the large, well-curated CelebA dataset (and ImageNet), and then evaluating their accuracy by testing them on an independent test dataset. Our goal is to build a model that trains on CelebA *and* achieves high classification accuracy on the the test dataset across all demographics, and to thus show that this model does not suffer from any hidden bias.\n",
- "\n",
- "What exactly do we mean when we say a classifier is biased? In order to formalize this, we'll need to think about [*latent variables*](https://en.wikipedia.org/wiki/Latent_variable), variables that define a dataset but are not strictly observed. As defined in the generative modeling lecture, we'll use the term *latent space* to refer to the probability distributions of the aforementioned latent variables. Putting these ideas together, we consider a classifier *biased* if its classification decision changes after it sees some additional latent features. This notion of bias may be helpful to keep in mind throughout the rest of the lab."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "AIFDvU4w8OIH"
- },
- "source": [
- "## 2.2 CNN for facial detection\n",
- "\n",
- "First, we'll define and train a CNN on the facial classification task, and evaluate its accuracy. Later, we'll evaluate the performance of our debiased models against this baseline CNN. The CNN model has a relatively standard architecture consisting of a series of convolutional layers with batch normalization followed by two fully connected layers to flatten the convolution output and generate a class prediction.\n",
- "\n",
- "### Define and train the CNN model\n",
- "\n",
- "Like we did in the first part of the lab, we'll define our CNN model, and then train on the CelebA and ImageNet datasets using the `tf.GradientTape` class and the `tf.GradientTape.gradient` method."
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "82EVTAAW7B_X"
- },
- "source": [
- "### Define the CNN model ###\n",
- "\n",
- "n_filters = 12 # base number of convolutional filters\n",
- "\n",
- "'''Function to define a standard CNN model'''\n",
- "def make_standard_classifier(n_outputs=1):\n",
- " Conv2D = functools.partial(tf.keras.layers.Conv2D, padding='same', activation='relu')\n",
- " BatchNormalization = tf.keras.layers.BatchNormalization\n",
- " Flatten = tf.keras.layers.Flatten\n",
- " Dense = functools.partial(tf.keras.layers.Dense, activation='relu')\n",
- "\n",
- " model = tf.keras.Sequential([\n",
- " Conv2D(filters=1*n_filters, kernel_size=5, strides=2),\n",
- " BatchNormalization(),\n",
- "\n",
- " Conv2D(filters=2*n_filters, kernel_size=5, strides=2),\n",
- " BatchNormalization(),\n",
- "\n",
- " Conv2D(filters=4*n_filters, kernel_size=3, strides=2),\n",
- " BatchNormalization(),\n",
- "\n",
- " Conv2D(filters=6*n_filters, kernel_size=3, strides=2),\n",
- " BatchNormalization(),\n",
- "\n",
- " Flatten(),\n",
- " Dense(512),\n",
- " Dense(n_outputs, activation=None),\n",
- " ])\n",
- " return model\n",
- "\n",
- "standard_classifier = make_standard_classifier()"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "c-eWf3l_lCri"
- },
- "source": [
- "Now let's train the standard CNN!"
- ]
- },
- {
- "cell_type": "code",
- "source": [
- "### Create a Comet experiment to track our training run ###\n",
- "def create_experiment(project_name, params):\n",
- " # end any prior experiments\n",
- " if 'experiment' in locals():\n",
- " experiment.end()\n",
- "\n",
- " # initiate the comet experiment for tracking\n",
- " experiment = comet_ml.Experiment(\n",
- " api_key=COMET_API_KEY,\n",
- " project_name=project_name)\n",
- " # log our hyperparameters, defined above, to the experiment\n",
- " for param, value in params.items():\n",
- " experiment.log_parameter(param, value)\n",
- " experiment.flush()\n",
- "\n",
- " return experiment\n"
- ],
- "metadata": {
- "id": "mi-04SAfK6lm"
- },
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "eJlDGh1o31G1"
- },
- "source": [
- "### Train the standard CNN ###\n",
- "\n",
- "# Training hyperparameters\n",
- "params = dict(\n",
- " batch_size = 32,\n",
- " num_epochs = 2, # keep small to run faster\n",
- " learning_rate = 5e-4,\n",
- ")\n",
- "\n",
- "experiment = create_experiment(\"6S191_Lab2_Part2_CNN\", params)\n",
- "\n",
- "optimizer = tf.keras.optimizers.Adam(params[\"learning_rate\"]) # define our optimizer\n",
- "loss_history = mdl.util.LossHistory(smoothing_factor=0.99) # to record loss evolution\n",
- "plotter = mdl.util.PeriodicPlotter(sec=2, scale='semilogy')\n",
- "if hasattr(tqdm, '_instances'): tqdm._instances.clear() # clear if it exists\n",
- "\n",
- "@tf.function\n",
- "def standard_train_step(x, y):\n",
- " with tf.GradientTape() as tape:\n",
- " # feed the images into the model\n",
- " logits = standard_classifier(x)\n",
- " # Compute the loss\n",
- " loss = tf.nn.sigmoid_cross_entropy_with_logits(labels=y, logits=logits)\n",
- "\n",
- " # Backpropagation\n",
- " grads = tape.gradient(loss, standard_classifier.trainable_variables)\n",
- " optimizer.apply_gradients(zip(grads, standard_classifier.trainable_variables))\n",
- " return loss\n",
- "\n",
- "# The training loop!\n",
- "step = 0\n",
- "for epoch in range(params[\"num_epochs\"]):\n",
- " for idx in tqdm(range(loader.get_train_size()//params[\"batch_size\"])):\n",
- " # Grab a batch of training data and propagate through the network\n",
- " x, y = loader.get_batch(params[\"batch_size\"])\n",
- " loss = standard_train_step(x, y)\n",
- "\n",
- " # Record the loss and plot the evolution of the loss as a function of training\n",
- " loss_history.append(loss.numpy().mean())\n",
- " plotter.plot(loss_history.get())\n",
- "\n",
- " experiment.log_metric(\"loss\", loss.numpy().mean(), step=step)\n",
- " step += 1"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "AKMdWVHeCxj8"
- },
- "source": [
- "### Evaluate performance of the standard CNN\n",
- "\n",
- "Next, let's evaluate the classification performance of our CelebA-trained standard CNN on the training dataset.\n"
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "35-PDgjdWk6_"
- },
- "source": [
- "### Evaluation of standard CNN ###\n",
- "\n",
- "# TRAINING DATA\n",
- "# Evaluate on a subset of CelebA+Imagenet\n",
- "(batch_x, batch_y) = loader.get_batch(5000)\n",
- "y_pred_standard = tf.round(tf.nn.sigmoid(standard_classifier.predict(batch_x)))\n",
- "acc_standard = tf.reduce_mean(tf.cast(tf.equal(batch_y, y_pred_standard), tf.float32))\n",
- "\n",
- "print(\"Standard CNN accuracy on (potentially biased) training set: {:.4f}\".format(acc_standard.numpy()))"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Qu7R14KaEEvU"
- },
- "source": [
- "We will also evaluate our networks on an independent test dataset containing faces that were not seen during training. For the test data, we'll look at the classification accuracy across four different demographics, based on the Fitzpatrick skin scale and sex-based labels: dark-skinned male, dark-skinned female, light-skinned male, and light-skinned female.\n",
- "\n",
- "Let's take a look at some sample faces in the test set."
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "vfDD8ztGWk6x"
- },
- "source": [
- "### Load test dataset and plot examples ###\n",
- "\n",
- "test_faces = mdl.lab2.get_test_faces()\n",
- "keys = [\"Light Female\", \"Light Male\", \"Dark Female\", \"Dark Male\"]\n",
- "for group, key in zip(test_faces,keys):\n",
- " plt.figure(figsize=(5,5))\n",
- " plt.imshow(np.hstack(group))\n",
- " plt.title(key, fontsize=15)"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "uo1z3cdbEUMM"
- },
- "source": [
- "Now, let's evaluate the probability of each of these face demographics being classified as a face using the standard CNN classifier we've just trained."
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "GI4O0Y1GAot9"
- },
- "source": [
- "### Evaluate the standard CNN on the test data ###\n",
- "\n",
- "standard_classifier_logits = [standard_classifier(np.array(x, dtype=np.float32)) for x in test_faces]\n",
- "standard_classifier_probs = tf.squeeze(tf.sigmoid(standard_classifier_logits))\n",
- "\n",
- "# Plot the prediction accuracies per demographic\n",
- "xx = range(len(keys))\n",
- "yy = standard_classifier_probs.numpy().mean(1)\n",
- "plt.bar(xx, yy)\n",
- "plt.xticks(xx, keys)\n",
- "plt.ylim(max(0,yy.min()-yy.ptp()/2.), yy.max()+yy.ptp()/2.)\n",
- "plt.title(\"Standard classifier predictions\");"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "j0Cvvt90DoAm"
- },
- "source": [
- "Take a look at the accuracies for this first model across these four groups. What do you observe? Would you consider this model biased or unbiased? What are some reasons why a trained model may have biased accuracies?"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "0AKcHnXVtgqJ"
- },
- "source": [
- "## 2.3 Mitigating algorithmic bias\n",
- "\n",
- "Imbalances in the training data can result in unwanted algorithmic bias. For example, the majority of faces in CelebA (our training set) are those of light-skinned females. As a result, a classifier trained on CelebA will be better suited at recognizing and classifying faces with features similar to these, and will thus be biased.\n",
- "\n",
- "How could we overcome this? A naive solution -- and one that is being adopted by many companies and organizations -- would be to annotate different subclasses (i.e., light-skinned females, males with hats, etc.) within the training data, and then manually even out the data with respect to these groups.\n",
- "\n",
- "But this approach has two major disadvantages. First, it requires annotating massive amounts of data, which is not scalable. Second, it requires that we know what potential biases (e.g., race, gender, pose, occlusion, hats, glasses, etc.) to look for in the data. As a result, manual annotation may not capture all the different features that are imbalanced within the training data.\n",
- "\n",
- "Instead, let's actually **learn** these features in an unbiased, unsupervised manner, without the need for any annotation, and then train a classifier fairly with respect to these features. In the rest of this lab, we'll do exactly that."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "nLemS7dqECsI"
- },
- "source": [
- "## 2.4 Variational autoencoder (VAE) for learning latent structure\n",
- "\n",
- "As you saw, the accuracy of the CNN varies across the four demographics we looked at. To think about why this may be, consider the dataset the model was trained on, CelebA. If certain features, such as dark skin or hats, are *rare* in CelebA, the model may end up biased against these as a result of training with a biased dataset. That is to say, its classification accuracy will be worse on faces that have under-represented features, such as dark-skinned faces or faces with hats, relevative to faces with features well-represented in the training data! This is a problem.\n",
- "\n",
- "Our goal is to train a *debiased* version of this classifier -- one that accounts for potential disparities in feature representation within the training data. Specifically, to build a debiased facial classifier, we'll train a model that **learns a representation of the underlying latent space** to the face training data. The model then uses this information to mitigate unwanted biases by sampling faces with rare features, like dark skin or hats, *more frequently* during training. The key design requirement for our model is that it can learn an *encoding* of the latent features in the face data in an entirely *unsupervised* way. To achieve this, we'll turn to variational autoencoders (VAEs).\n",
- "\n",
- "\n",
- "\n",
- "As shown in the schematic above and in Lecture 4, VAEs rely on an encoder-decoder structure to learn a latent representation of the input data. In the context of computer vision, the encoder network takes in input images, encodes them into a series of variables defined by a mean and standard deviation, and then draws from the distributions defined by these parameters to generate a set of sampled latent variables. The decoder network then \"decodes\" these variables to generate a reconstruction of the original image, which is used during training to help the model identify which latent variables are important to learn.\n",
- "\n",
- "Let's formalize two key aspects of the VAE model and define relevant functions for each.\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "KmbXKtcPkTXA"
- },
- "source": [
- "### Understanding VAEs: loss function\n",
- "\n",
- "In practice, how can we train a VAE? In learning the latent space, we constrain the means and standard deviations to approximately follow a unit Gaussian. Recall that these are learned parameters, and therefore must factor into the loss computation, and that the decoder portion of the VAE is using these parameters to output a reconstruction that should closely match the input image, which also must factor into the loss. What this means is that we'll have two terms in our VAE loss function:\n",
- "\n",
- "1. **Latent loss ($L_{KL}$)**: measures how closely the learned latent variables match a unit Gaussian and is defined by the Kullback-Leibler (KL) divergence.\n",
- "2. **Reconstruction loss ($L_{x}{(x,\\hat{x})}$)**: measures how accurately the reconstructed outputs match the input and is given by the $L^1$ norm of the input image and its reconstructed output."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Ux3jK2wc153s"
- },
- "source": [
- "The equation for the latent loss is provided by:\n",
- "\n",
- "$$L_{KL}(\\mu, \\sigma) = \\frac{1}{2}\\sum_{j=0}^{k-1} (\\sigma_j + \\mu_j^2 - 1 - \\log{\\sigma_j})$$\n",
- "\n",
- "The equation for the reconstruction loss is provided by:\n",
- "\n",
- "$$L_{x}{(x,\\hat{x})} = ||x-\\hat{x}||_1$$\n",
- "\n",
- "Thus for the VAE loss we have:\n",
- "\n",
- "$$L_{VAE} = c\\cdot L_{KL} + L_{x}{(x,\\hat{x})}$$\n",
- "\n",
- "where $c$ is a weighting coefficient used for regularization. Now we're ready to define our VAE loss function:"
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "S00ASo1ImSuh"
- },
- "source": [
- "### Defining the VAE loss function ###\n",
- "\n",
- "''' Function to calculate VAE loss given:\n",
- " an input x,\n",
- " reconstructed output x_recon,\n",
- " encoded means mu,\n",
- " encoded log of standard deviation logsigma,\n",
- " weight parameter for the latent loss kl_weight\n",
- "'''\n",
- "def vae_loss_function(x, x_recon, mu, logsigma, kl_weight=0.0005):\n",
- " # TODO: Define the latent loss. Note this is given in the equation for L_{KL}\n",
- " # in the text block directly above\n",
- " latent_loss = # TODO\n",
- "\n",
- " # TODO: Define the reconstruction loss as the mean absolute pixel-wise\n",
- " # difference between the input and reconstruction. Hint: you'll need to\n",
- " # use tf.reduce_mean, and supply an axis argument which specifies which\n",
- " # dimensions to reduce over. For example, reconstruction loss needs to average\n",
- " # over the height, width, and channel image dimensions.\n",
- " # https://www.tensorflow.org/api_docs/python/tf/math/reduce_mean\n",
- " reconstruction_loss = # TODO\n",
- "\n",
- " # TODO: Define the VAE loss. Note this is given in the equation for L_{VAE}\n",
- " # in the text block directly above\n",
- " vae_loss = # TODO\n",
- "\n",
- " return vae_loss"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "E8mpb3pJorpu"
- },
- "source": [
- "Great! Now that we have a more concrete sense of how VAEs work, let's explore how we can leverage this network structure to train a *debiased* facial classifier."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "DqtQH4S5fO8F"
- },
- "source": [
- "### Understanding VAEs: reparameterization\n",
- "\n",
- "As you may recall from lecture, VAEs use a \"reparameterization trick\" for sampling learned latent variables. Instead of the VAE encoder generating a single vector of real numbers for each latent variable, it generates a vector of means and a vector of standard deviations that are constrained to roughly follow Gaussian distributions. We then sample from the standard deviations and add back the mean to output this as our sampled latent vector. Formalizing this for a latent variable $z$ where we sample $\\epsilon \\sim N(0,(I))$ we have:\n",
- "\n",
- "$$z = \\mu + e^{\\left(\\frac{1}{2} \\cdot \\log{\\Sigma}\\right)}\\circ \\epsilon$$\n",
- "\n",
- "where $\\mu$ is the mean and $\\Sigma$ is the covariance matrix. This is useful because it will let us neatly define the loss function for the VAE, generate randomly sampled latent variables, achieve improved network generalization, **and** make our complete VAE network differentiable so that it can be trained via backpropagation. Quite powerful!\n",
- "\n",
- "Let's define a function to implement the VAE sampling operation:"
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "cT6PGdNajl3K"
- },
- "source": [
- "### VAE Reparameterization ###\n",
- "\n",
- "\"\"\"Reparameterization trick by sampling from an isotropic unit Gaussian.\n",
- "# Arguments\n",
- " z_mean, z_logsigma (tensor): mean and log of standard deviation of latent distribution (Q(z|X))\n",
- "# Returns\n",
- " z (tensor): sampled latent vector\n",
- "\"\"\"\n",
- "def sampling(z_mean, z_logsigma):\n",
- " # By default, random.normal is \"standard\" (ie. mean=0 and std=1.0)\n",
- " batch, latent_dim = z_mean.shape\n",
- " epsilon = tf.random.normal(shape=(batch, latent_dim))\n",
- "\n",
- " # TODO: Define the reparameterization computation!\n",
- " # Note the equation is given in the text block immediately above.\n",
- " z = # TODO\n",
- "\n",
- " return z"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "qtHEYI9KNn0A"
- },
- "source": [
- "## 2.5 Debiasing variational autoencoder (DB-VAE)\n",
- "\n",
- "Now, we'll use the general idea behind the VAE architecture to build a model, termed a [*debiasing variational autoencoder*](https://lmrt.mit.edu/sites/default/files/AIES-19_paper_220.pdf) or DB-VAE, to mitigate (potentially) unknown biases present within the training idea. We'll train our DB-VAE model on the facial detection task, run the debiasing operation during training, evaluate on the PPB dataset, and compare its accuracy to our original, biased CNN model. \n",
- "\n",
- "### The DB-VAE model\n",
- "\n",
- "The key idea behind this debiasing approach is to use the latent variables learned via a VAE to adaptively re-sample the CelebA data during training. Specifically, we will alter the probability that a given image is used during training based on how often its latent features appear in the dataset. So, faces with rarer features (like dark skin, sunglasses, or hats) should become more likely to be sampled during training, while the sampling probability for faces with features that are over-represented in the training dataset should decrease (relative to uniform random sampling across the training data).\n",
- "\n",
- "A general schematic of the DB-VAE approach is shown here:\n",
- "\n",
- ""
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "ziA75SN-UxxO"
- },
- "source": [
- "Recall that we want to apply our DB-VAE to a *supervised classification* problem -- the facial detection task. Importantly, note how the encoder portion in the DB-VAE architecture also outputs a single supervised variable, $z_o$, corresponding to the class prediction -- face or not face. Usually, VAEs are not trained to output any supervised variables (such as a class prediction)! This is another key distinction between the DB-VAE and a traditional VAE.\n",
- "\n",
- "Keep in mind that we only want to learn the latent representation of *faces*, as that's what we're ultimately debiasing against, even though we are training a model on a binary classification problem. We'll need to ensure that, **for faces**, our DB-VAE model both learns a representation of the unsupervised latent variables, captured by the distribution $q_\\phi(z|x)$, **and** outputs a supervised class prediction $z_o$, but that, **for negative examples**, it only outputs a class prediction $z_o$."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "XggIKYPRtOZR"
- },
- "source": [
- "### Defining the DB-VAE loss function\n",
- "\n",
- "This means we'll need to be a bit clever about the loss function for the DB-VAE. The form of the loss will depend on whether it's a face image or a non-face image that's being considered.\n",
- "\n",
- "For **face images**, our loss function will have two components:\n",
- "\n",
- "\n",
- "1. **VAE loss ($L_{VAE}$)**: consists of the latent loss and the reconstruction loss.\n",
- "2. **Classification loss ($L_y(y,\\hat{y})$)**: standard cross-entropy loss for a binary classification problem.\n",
- "\n",
- "In contrast, for images of **non-faces**, our loss function is solely the classification loss.\n",
- "\n",
- "We can write a single expression for the loss by defining an indicator variable ${I}_f$which reflects which training data are images of faces (${I}_f(y) = 1$ ) and which are images of non-faces (${I}_f(y) = 0$). Using this, we obtain:\n",
- "\n",
- "$$L_{total} = L_y(y,\\hat{y}) + {I}_f(y)\\Big[L_{VAE}\\Big]$$\n",
- "\n",
- "Let's write a function to define the DB-VAE loss function:\n"
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "VjieDs8Ovcqs"
- },
- "source": [
- "### Loss function for DB-VAE ###\n",
- "\n",
- "\"\"\"Loss function for DB-VAE.\n",
- "# Arguments\n",
- " x: true input x\n",
- " x_pred: reconstructed x\n",
- " y: true label (face or not face)\n",
- " y_logit: predicted labels\n",
- " mu: mean of latent distribution (Q(z|X))\n",
- " logsigma: log of standard deviation of latent distribution (Q(z|X))\n",
- "# Returns\n",
- " total_loss: DB-VAE total loss\n",
- " classification_loss = DB-VAE classification loss\n",
- "\"\"\"\n",
- "def debiasing_loss_function(x, x_pred, y, y_logit, mu, logsigma):\n",
- "\n",
- " # TODO: call the relevant function to obtain VAE loss\n",
- " vae_loss = vae_loss_function('''TODO''') # TODO\n",
- "\n",
- " # TODO: define the classification loss using sigmoid_cross_entropy\n",
- " # https://www.tensorflow.org/api_docs/python/tf/nn/sigmoid_cross_entropy_with_logits\n",
- " classification_loss = # TODO\n",
- "\n",
- " # Use the training data labels to create variable face_indicator:\n",
- " # indicator that reflects which training data are images of faces\n",
- " face_indicator = tf.cast(tf.equal(y, 1), tf.float32)\n",
- "\n",
- " # TODO: define the DB-VAE total loss! Use tf.reduce_mean to average over all\n",
- " # samples\n",
- " total_loss = # TODO\n",
- "\n",
- " return total_loss, classification_loss"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "YIu_2LzNWwWY"
- },
- "source": [
- "### DB-VAE architecture\n",
- "\n",
- "Now we're ready to define the DB-VAE architecture. To build the DB-VAE, we will use the standard CNN classifier from above as our encoder, and then define a decoder network. We will create and initialize the two models, and then construct the end-to-end VAE. We will use a latent space with 100 latent variables.\n",
- "\n",
- "The decoder network will take as input the sampled latent variables, run them through a series of deconvolutional layers, and output a reconstruction of the original input image."
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "JfWPHGrmyE7R"
- },
- "source": [
- "### Define the decoder portion of the DB-VAE ###\n",
- "\n",
- "n_filters = 12 # base number of convolutional filters, same as standard CNN\n",
- "latent_dim = 100 # number of latent variables\n",
- "\n",
- "def make_face_decoder_network():\n",
- " # Functionally define the different layer types we will use\n",
- " Conv2DTranspose = functools.partial(tf.keras.layers.Conv2DTranspose, padding='same', activation='relu')\n",
- " BatchNormalization = tf.keras.layers.BatchNormalization\n",
- " Flatten = tf.keras.layers.Flatten\n",
- " Dense = functools.partial(tf.keras.layers.Dense, activation='relu')\n",
- " Reshape = tf.keras.layers.Reshape\n",
- "\n",
- " # Build the decoder network using the Sequential API\n",
- " decoder = tf.keras.Sequential([\n",
- " # Transform to pre-convolutional generation\n",
- " Dense(units=4*4*6*n_filters), # 4x4 feature maps (with 6N occurances)\n",
- " Reshape(target_shape=(4, 4, 6*n_filters)),\n",
- "\n",
- " # Upscaling convolutions (inverse of encoder)\n",
- " Conv2DTranspose(filters=4*n_filters, kernel_size=3, strides=2),\n",
- " Conv2DTranspose(filters=2*n_filters, kernel_size=3, strides=2),\n",
- " Conv2DTranspose(filters=1*n_filters, kernel_size=5, strides=2),\n",
- " Conv2DTranspose(filters=3, kernel_size=5, strides=2),\n",
- " ])\n",
- "\n",
- " return decoder"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "yWCMu12w1BuD"
- },
- "source": [
- "Now, we will put this decoder together with the standard CNN classifier as our encoder to define the DB-VAE. Note that at this point, there is nothing special about how we put the model together that makes it a \"debiasing\" model -- that will come when we define the training operation. Here, we will define the core VAE architecture by sublassing the `Model` class; defining encoding, reparameterization, and decoding operations; and calling the network end-to-end."
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "dSFDcFBL13c3"
- },
- "source": [
- "### Defining and creating the DB-VAE ###\n",
- "\n",
- "class DB_VAE(tf.keras.Model):\n",
- " def __init__(self, latent_dim):\n",
- " super(DB_VAE, self).__init__()\n",
- " self.latent_dim = latent_dim\n",
- "\n",
- " # Define the number of outputs for the encoder. Recall that we have\n",
- " # `latent_dim` latent variables, as well as a supervised output for the\n",
- " # classification.\n",
- " num_encoder_dims = 2*self.latent_dim + 1\n",
- "\n",
- " self.encoder = make_standard_classifier(num_encoder_dims)\n",
- " self.decoder = make_face_decoder_network()\n",
- "\n",
- " # function to feed images into encoder, encode the latent space, and output\n",
- " # classification probability\n",
- " def encode(self, x):\n",
- " # encoder output\n",
- " encoder_output = self.encoder(x)\n",
- "\n",
- " # classification prediction\n",
- " y_logit = tf.expand_dims(encoder_output[:, 0], -1)\n",
- "\n",
- " # latent variable distribution parameters\n",
- " z_mean = encoder_output[:, 1:self.latent_dim+1]\n",
- " z_logsigma = encoder_output[:, self.latent_dim+1:]\n",
- "\n",
- " return y_logit, z_mean, z_logsigma\n",
- "\n",
- " # VAE reparameterization: given a mean and logsigma, sample latent variables\n",
- " def reparameterize(self, z_mean, z_logsigma):\n",
- " # TODO: call the sampling function defined above\n",
- " z = # TODO\n",
- " return z\n",
- "\n",
- " # Decode the latent space and output reconstruction\n",
- " def decode(self, z):\n",
- " # TODO: use the decoder to output the reconstruction\n",
- " reconstruction = # TODO\n",
- " return reconstruction\n",
- "\n",
- " # The call function will be used to pass inputs x through the core VAE\n",
- " def call(self, x):\n",
- " # Encode input to a prediction and latent space\n",
- " y_logit, z_mean, z_logsigma = self.encode(x)\n",
- "\n",
- " # TODO: reparameterization\n",
- " z = # TODO\n",
- "\n",
- " # TODO: reconstruction\n",
- " recon = # TODO\n",
- " return y_logit, z_mean, z_logsigma, recon\n",
- "\n",
- " # Predict face or not face logit for given input x\n",
- " def predict(self, x):\n",
- " y_logit, z_mean, z_logsigma = self.encode(x)\n",
- " return y_logit\n",
- "\n",
- "dbvae = DB_VAE(latent_dim)"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "M-clbYAj2waY"
- },
- "source": [
- "As stated, the encoder architecture is identical to the CNN from earlier in this lab. Note the outputs of our constructed DB_VAE model in the `call` function: `y_logit, z_mean, z_logsigma, z`. Think carefully about why each of these are outputted and their significance to the problem at hand.\n",
- "\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "nbDNlslgQc5A"
- },
- "source": [
- "### Adaptive resampling for automated debiasing with DB-VAE\n",
- "\n",
- "So, how can we actually use DB-VAE to train a debiased facial detection classifier?\n",
- "\n",
- "Recall the DB-VAE architecture: as input images are fed through the network, the encoder learns an estimate ${Q}(z|X)$ of the latent space. We want to increase the relative frequency of rare data by increased sampling of under-represented regions of the latent space. We can approximate ${Q}(z|X)$ using the frequency distributions of each of the learned latent variables, and then define the probability distribution of selecting a given datapoint $x$ based on this approximation. These probability distributions will be used during training to re-sample the data.\n",
- "\n",
- "You'll write a function to execute this update of the sampling probabilities, and then call this function within the DB-VAE training loop to actually debias the model."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Fej5FDu37cf7"
- },
- "source": [
- "First, we've defined a short helper function `get_latent_mu` that returns the latent variable means returned by the encoder after a batch of images is inputted to the network:"
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "ewWbf7TE7wVc"
- },
- "source": [
- "# Function to return the means for an input image batch\n",
- "def get_latent_mu(images, dbvae, batch_size=1024):\n",
- " N = images.shape[0]\n",
- " mu = np.zeros((N, latent_dim))\n",
- " for start_ind in range(0, N, batch_size):\n",
- " end_ind = min(start_ind+batch_size, N+1)\n",
- " batch = (images[start_ind:end_ind]).astype(np.float32)/255.\n",
- " _, batch_mu, _ = dbvae.encode(batch)\n",
- " mu[start_ind:end_ind] = batch_mu\n",
- " return mu"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "wn4yK3SC72bo"
- },
- "source": [
- "Now, let's define the actual resampling algorithm `get_training_sample_probabilities`. Importantly note the argument `smoothing_fac`. This parameter tunes the degree of debiasing: for `smoothing_fac=0`, the re-sampled training set will tend towards falling uniformly over the latent space, i.e., the most extreme debiasing."
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "HiX9pmmC7_wn"
- },
- "source": [
- "### Resampling algorithm for DB-VAE ###\n",
- "\n",
- "'''Function that recomputes the sampling probabilities for images within a batch\n",
- " based on how they distribute across the training data'''\n",
- "def get_training_sample_probabilities(images, dbvae, bins=10, smoothing_fac=0.001):\n",
- " print(\"Recomputing the sampling probabilities\")\n",
- "\n",
- " # TODO: run the input batch and get the latent variable means\n",
- " mu = get_latent_mu('''TODO''') # TODO\n",
- "\n",
- " # sampling probabilities for the images\n",
- " training_sample_p = np.zeros(mu.shape[0])\n",
- "\n",
- " # consider the distribution for each latent variable\n",
- " for i in range(latent_dim):\n",
- "\n",
- " latent_distribution = mu[:,i]\n",
- " # generate a histogram of the latent distribution\n",
- " hist_density, bin_edges = np.histogram(latent_distribution, density=True, bins=bins)\n",
- "\n",
- " # find which latent bin every data sample falls in\n",
- " bin_edges[0] = -float('inf')\n",
- " bin_edges[-1] = float('inf')\n",
- "\n",
- " # TODO: call the digitize function to find which bins in the latent distribution\n",
- " # every data sample falls in to\n",
- " # https://docs.scipy.org/doc/numpy-1.13.0/reference/generated/numpy.digitize.html\n",
- " bin_idx = np.digitize('''TODO''', '''TODO''') # TODO\n",
- "\n",
- " # smooth the density function\n",
- " hist_smoothed_density = hist_density + smoothing_fac\n",
- " hist_smoothed_density = hist_smoothed_density / np.sum(hist_smoothed_density)\n",
- "\n",
- " # invert the density function\n",
- " p = 1.0/(hist_smoothed_density[bin_idx-1])\n",
- "\n",
- " # TODO: normalize all probabilities\n",
- " p = # TODO\n",
- "\n",
- " # TODO: update sampling probabilities by considering whether the newly\n",
- " # computed p is greater than the existing sampling probabilities.\n",
- " training_sample_p = # TODO\n",
- "\n",
- " # final normalization\n",
- " training_sample_p /= np.sum(training_sample_p)\n",
- "\n",
- " return training_sample_p"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "pF14fQkVUs-a"
- },
- "source": [
- "Now that we've defined the resampling update, we can train our DB-VAE model on the CelebA/ImageNet training data, and run the above operation to re-weight the importance of particular data points as we train the model. Remember again that we only want to debias for features relevant to *faces*, not the set of negative examples. Complete the code block below to execute the training loop!"
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "xwQs-Gu5bKEK"
- },
- "source": [
- "### Training the DB-VAE ###\n",
- "\n",
- "# Hyperparameters\n",
- "params = dict(\n",
- " batch_size = 32,\n",
- " learning_rate = 5e-4,\n",
- " latent_dim = 100,\n",
- " num_epochs = 1, #DB-VAE needs slightly more epochs to train\n",
- ")\n",
- "\n",
- "experiment = create_experiment(\"6S191_Lab2_Part2_DBVAE\", params)\n",
- "\n",
- "# instantiate a new DB-VAE model and optimizer\n",
- "dbvae = DB_VAE(params[\"latent_dim\"])\n",
- "optimizer = tf.keras.optimizers.Adam(params[\"learning_rate\"])\n",
- "\n",
- "# To define the training operation, we will use tf.function which is a powerful tool\n",
- "# that lets us turn a Python function into a TensorFlow computation graph.\n",
- "@tf.function\n",
- "def debiasing_train_step(x, y):\n",
- "\n",
- " with tf.GradientTape() as tape:\n",
- " # Feed input x into dbvae. Note that this is using the DB_VAE call function!\n",
- " y_logit, z_mean, z_logsigma, x_recon = dbvae(x)\n",
- "\n",
- " '''TODO: call the DB_VAE loss function to compute the loss'''\n",
- " loss, class_loss = debiasing_loss_function('''TODO arguments''') # TODO\n",
- "\n",
- " '''TODO: use the GradientTape.gradient method to compute the gradients.\n",
- " Hint: this is with respect to the trainable_variables of the dbvae.'''\n",
- " grads = tape.gradient('''TODO''', '''TODO''') # TODO\n",
- "\n",
- " # apply gradients to variables\n",
- " optimizer.apply_gradients(zip(grads, dbvae.trainable_variables))\n",
- " return loss\n",
- "\n",
- "# get training faces from data loader\n",
- "all_faces = loader.get_all_train_faces()\n",
- "\n",
- "if hasattr(tqdm, '_instances'): tqdm._instances.clear() # clear if it exists\n",
- "\n",
- "# The training loop -- outer loop iterates over the number of epochs\n",
- "step = 0\n",
- "for i in range(params[\"num_epochs\"]):\n",
- "\n",
- " IPython.display.clear_output(wait=True)\n",
- " print(\"Starting epoch {}/{}\".format(i+1, params[\"num_epochs\"]))\n",
- "\n",
- " # Recompute data sampling proabilities\n",
- " '''TODO: recompute the sampling probabilities for debiasing'''\n",
- " p_faces = get_training_sample_probabilities('''TODO''', '''TODO''') # TODO\n",
- "\n",
- " # get a batch of training data and compute the training step\n",
- " for j in tqdm(range(loader.get_train_size() // params[\"batch_size\"])):\n",
- " # load a batch of data\n",
- " (x, y) = loader.get_batch(params[\"batch_size\"], p_pos=p_faces)\n",
- "\n",
- " # loss optimization\n",
- " loss = debiasing_train_step(x, y)\n",
- " experiment.log_metric(\"loss\", loss.numpy().mean(), step=step)\n",
- "\n",
- " # plot the progress every 200 steps\n",
- " if j % 500 == 0:\n",
- " mdl.util.plot_sample(x, y, dbvae)\n",
- "\n",
- " step += 1\n",
- "\n",
- "experiment.end()"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "uZBlWDPOVcHg"
- },
- "source": [
- "Wonderful! Now we should have a trained and (hopefully!) debiased facial classification model, ready for evaluation!"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Eo34xC7MbaiQ"
- },
- "source": [
- "## 2.6 Evaluation of DB-VAE on Test Dataset\n",
- "\n",
- "Finally let's test our DB-VAE model on the test dataset, looking specifically at its accuracy on each the \"Dark Male\", \"Dark Female\", \"Light Male\", and \"Light Female\" demographics. We will compare the performance of this debiased model against the (potentially biased) standard CNN from earlier in the lab."
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "bgK77aB9oDtX"
- },
- "source": [
- "dbvae_logits = [dbvae.predict(np.array(x, dtype=np.float32)) for x in test_faces]\n",
- "dbvae_probs = tf.squeeze(tf.sigmoid(dbvae_logits))\n",
- "\n",
- "xx = np.arange(len(keys))\n",
- "plt.bar(xx, standard_classifier_probs.numpy().mean(1), width=0.2, label=\"Standard CNN\")\n",
- "plt.bar(xx+0.2, dbvae_probs.numpy().mean(1), width=0.2, label=\"DB-VAE\")\n",
- "plt.xticks(xx, keys);\n",
- "plt.title(\"Network predictions on test dataset\")\n",
- "plt.ylabel(\"Probability\"); plt.legend(bbox_to_anchor=(1.04,1), loc=\"upper left\");\n"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "rESoXRPQo_mq"
- },
- "source": [
- "## 2.7 Conclusion and submission information\n",
- "\n",
- "We encourage you to think about and maybe even address some questions raised by the approach and results outlined here:\n",
- "\n",
- "* How does the accuracy of the DB-VAE across the four demographics compare to that of the standard CNN? Do you find this result surprising in any way?\n",
- "* How can the performance of the DB-VAE classifier be improved even further? We purposely did not optimize hyperparameters to leave this up to you!\n",
- "* In which applications (either related to facial detection or not!) would debiasing in this way be desired? Are there applications where you may not want to debias your model?\n",
- "* Do you think it should be necessary for companies to demonstrate that their models, particularly in the context of tasks like facial detection, are not biased? If so, do you have thoughts on how this could be standardized and implemented?\n",
- "* Do you have ideas for other ways to address issues of bias, particularly in terms of the training data?\n",
- "\n",
- "**Try to optimize your model to achieve improved performance. To enter the competition, please upload the following to the lab submission site for the Debiasing Faces Lab ([submission upload link](https://www.dropbox.com/request/dJZUEoqGLB43JEKzzqIc)).**\n",
- "\n",
- "* Jupyter notebook with the code you used to generate your results;\n",
- "* copy of the bar plot from section 2.6 showing the performance of your model;\n",
- "* a written description and/or diagram of the architecture and hyperparameters you used -- if there are any additional or interesting modifications you made to the template code, please include these in your description;\n",
- "* a written discussion of why these modifications helped improve performance.\n",
- "\n",
- "**Name your file in the following format: `[FirstName]_[LastName]_Face`, followed by the file format (.zip, .ipynb, .pdf, etc).** ZIP files are preferred over individual files. If you submit individual files, you must name the individual files according to the above nomenclature (e.g., `[FirstName]_[LastName]_Face_TODO.pdf`, `[FirstName]_[LastName]_Face_Report.pdf`, etc.).\n",
- "\n",
- "Hopefully this lab has shed some light on a few concepts, from vision based tasks, to VAEs, to algorithmic bias. We like to think it has, but we're biased ;).\n",
- "\n",
- " "
- ]
- }
- ]
-}
diff --git a/lab2/solutions/PT_Part1_MNIST_Solution.ipynb b/lab2/solutions/PT_Part1_MNIST_Solution.ipynb
deleted file mode 100644
index 01dc5bfa..00000000
--- a/lab2/solutions/PT_Part1_MNIST_Solution.ipynb
+++ /dev/null
@@ -1,1029 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Xmf_JRJa_N8C"
- },
- "source": [
- "\n",
- "\n",
- "# Copyright Information"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "gKA_J7bdP33T"
- },
- "outputs": [],
- "source": [
- "# Copyright 2025 MIT Introduction to Deep Learning. All Rights Reserved.\n",
- "#\n",
- "# Licensed under the MIT License. You may not use this file except in compliance\n",
- "# with the License. Use and/or modification of this code outside of MIT Introduction\n",
- "# to Deep Learning must reference:\n",
- "#\n",
- "# © MIT Introduction to Deep Learning\n",
- "# http://introtodeeplearning.com\n",
- "#"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Cm1XpLftPi4A"
- },
- "source": [
- "# Laboratory 2: Computer Vision\n",
- "\n",
- "# Part 1: MNIST Digit Classification\n",
- "\n",
- "In the first portion of this lab, we will build and train a convolutional neural network (CNN) for classification of handwritten digits from the famous [MNIST](http://yann.lecun.com/exdb/mnist/) dataset. The MNIST dataset consists of 60,000 training images and 10,000 test images. Our classes are the digits 0-9.\n",
- "\n",
- "First, let's download the course repository, install dependencies, and import the relevant packages we'll need for this lab."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "RsGqx_ai_N8F"
- },
- "outputs": [],
- "source": [
- "# Import PyTorch and other relevant libraries\n",
- "import torch\n",
- "import torch.nn as nn\n",
- "import torch.optim as optim\n",
- "import torchvision\n",
- "import torchvision.datasets as datasets\n",
- "import torchvision.transforms as transforms\n",
- "from torch.utils.data import DataLoader\n",
- "from torchsummary import summary\n",
- "\n",
- "# MIT introduction to deep learning package\n",
- "!pip install mitdeeplearning --quiet\n",
- "import mitdeeplearning as mdl\n",
- "\n",
- "# other packages\n",
- "import matplotlib.pyplot as plt\n",
- "import numpy as np\n",
- "import random\n",
- "from tqdm import tqdm"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "nCpHDxX1bzyZ"
- },
- "source": [
- "We'll also install Comet. If you followed the instructions from Lab 1, you should have your Comet account set up. Enter your API key below."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "GSR_PAqjbzyZ"
- },
- "outputs": [],
- "source": [
- "!pip install comet_ml > /dev/null 2>&1\n",
- "import comet_ml\n",
- "# TODO: ENTER YOUR API KEY HERE!!\n",
- "COMET_API_KEY = \"\"\n",
- "\n",
- "# Check that we are using a GPU, if not switch runtimes\n",
- "# using Runtime > Change Runtime Type > GPU\n",
- "assert torch.cuda.is_available(), \"Please enable GPU from runtime settings\"\n",
- "assert COMET_API_KEY != \"\", \"Please insert your Comet API Key\"\n",
- "\n",
- "# Set GPU for computation\n",
- "device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "wGPDtVxvTtPk"
- },
- "outputs": [],
- "source": [
- "# start a first comet experiment for the first part of the lab\n",
- "comet_ml.init(project_name=\"6S191_lab2_part1_NN\")\n",
- "comet_model_1 = comet_ml.Experiment()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "HKjrdUtX_N8J"
- },
- "source": [
- "## 1.1 MNIST dataset\n",
- "\n",
- "Let's download and load the dataset and display a few random samples from it:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "G1Bryi5ssUNX"
- },
- "outputs": [],
- "source": [
- "# Download and transform the MNIST dataset\n",
- "transform = transforms.Compose([\n",
- " # Convert images to PyTorch tensors which also scales data from [0,255] to [0,1]\n",
- " transforms.ToTensor()\n",
- "])\n",
- "\n",
- "# Download training and test datasets\n",
- "train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)\n",
- "test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "D_AhlQB4sUNX"
- },
- "source": [
- "The MNIST dataset object in PyTorch is not a simple tensor or array. It's an iterable dataset that loads samples (image-label pairs) one at a time or in batches. In a later section of this lab, we will define a handy DataLoader to process the data in batches."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "LpxeLuaysUNX"
- },
- "outputs": [],
- "source": [
- "image, label = train_dataset[0]\n",
- "print(image.size()) # For a tensor: torch.Size([1, 28, 28])\n",
- "print(label) # For a label: integer (e.g., 5)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "5ZtUqOqePsRD"
- },
- "source": [
- "Our training set is made up of 28x28 grayscale images of handwritten digits.\n",
- "\n",
- "Let's visualize what some of these images and their corresponding training labels look like."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "bDBsR2lP_N8O",
- "scrolled": true
- },
- "outputs": [],
- "source": [
- "plt.figure(figsize=(10,10))\n",
- "random_inds = np.random.choice(60000,36)\n",
- "for i in range(36):\n",
- " plt.subplot(6, 6, i + 1)\n",
- " plt.xticks([])\n",
- " plt.yticks([])\n",
- " plt.grid(False)\n",
- " image_ind = random_inds[i]\n",
- " image, label = train_dataset[image_ind]\n",
- " plt.imshow(image.squeeze(), cmap=plt.cm.binary)\n",
- " plt.xlabel(label)\n",
- "comet_model_1.log_figure(figure=plt)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "V6hd3Nt1_N8q"
- },
- "source": [
- "## 1.2 Neural Network for Handwritten Digit Classification\n",
- "\n",
- "We'll first build a simple neural network consisting of two fully connected layers and apply this to the digit classification task. Our network will ultimately output a probability distribution over the 10 digit classes (0-9). This first architecture we will be building is depicted below:\n",
- "\n",
- "\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "rphS2rMIymyZ"
- },
- "source": [
- "### Fully connected neural network architecture\n",
- "To define the architecture of this first fully connected neural network, we'll once again use the the `torch.nn` modules, defining the model using [`nn.Sequential`](https://pytorch.org/docs/stable/generated/torch.nn.Sequential.html). Note how we first use a [`nn.Flatten`](https://www.tensorflow.org/api_docs/python/tf/keras/layers/Flatten) layer, which flattens the input so that it can be fed into the model.\n",
- "\n",
- "In this next block, you'll define the fully connected layers of this simple network."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "MMZsbjAkDKpU"
- },
- "outputs": [],
- "source": [
- "def build_fc_model():\n",
- " fc_model = nn.Sequential(\n",
- " # First define a Flatten layer\n",
- " nn.Flatten(),\n",
- "\n",
- " nn.Linear(28 * 28, 128),\n",
- " # '''TODO: Define the activation function.'''\n",
- " nn.ReLU(),\n",
- "\n",
- " # '''TODO: Define the second Linear layer'''\n",
- " nn.Linear(128, 10),\n",
- " )\n",
- " return fc_model\n",
- "\n",
- "fc_model_sequential = build_fc_model()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "VtGZpHVKz5Jt"
- },
- "source": [
- "As we progress through this next portion, you may find that you'll want to make changes to the architecture defined above. **Note that in order to update the model later on, you'll need to re-run the above cell to re-initialize the model.**"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "mVN1_AeG_N9N"
- },
- "source": [
- "Let's take a step back and think about the network we've just created. The first layer in this network, `nn.Flatten`, transforms the format of the images from a 2d-array (28 x 28 pixels), to a 1d-array of 28 * 28 = 784 pixels. You can think of this layer as unstacking rows of pixels in the image and lining them up. There are no learned parameters in this layer; it only reformats the data.\n",
- "\n",
- "After the pixels are flattened, the network consists of a sequence of two `nn.Linear` layers. These are fully-connected neural layers. The first `nn.Linear` layer has 128 nodes (or neurons). The second (and last) layer (which you've defined!) should return an array of probability scores that sum to 1. Each node contains a score that indicates the probability that the current image belongs to one of the handwritten digit classes.\n",
- "\n",
- "That defines our fully connected model!"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "kquVpHqPsUNX"
- },
- "source": [
- "### Embracing subclassing in PyTorch"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "RyqD3eJgsUNX"
- },
- "source": [
- "Recall that in Lab 1, we explored creating more flexible models by subclassing [`nn.Module`](https://pytorch.org/docs/stable/generated/torch.nn.Module.html). This technique of defining models is more commonly used in PyTorch. We will practice using this approach of subclassing to define our models for the rest of the lab."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "7JhFJXjYsUNX"
- },
- "outputs": [],
- "source": [
- "# Define the fully connected model\n",
- "class FullyConnectedModel(nn.Module):\n",
- " def __init__(self):\n",
- " super(FullyConnectedModel, self).__init__()\n",
- " self.flatten = nn.Flatten()\n",
- " self.fc1 = nn.Linear(28 * 28, 128)\n",
- "\n",
- " # '''TODO: Define the activation function for the first fully connected layer'''\n",
- " self.relu = nn.ReLU()\n",
- "\n",
- " # '''TODO: Define the second Linear layer to output the classification probabilities'''\n",
- " self.fc2 = nn.Linear(128, 10)\n",
- " # self.fc2 = # TODO\n",
- "\n",
- " def forward(self, x):\n",
- " x = self.flatten(x)\n",
- " x = self.fc1(x)\n",
- "\n",
- " # '''TODO: Implement the rest of forward pass of the model using the layers you have defined above'''\n",
- " x = self.relu(x)\n",
- " x = self.fc2(x)\n",
- " # '''TODO'''\n",
- "\n",
- " return x\n",
- "\n",
- "fc_model = FullyConnectedModel().to(device) # send the model to GPU"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "gut8A_7rCaW6"
- },
- "source": [
- "### Model Metrics and Training Parameters\n",
- "\n",
- "Before training the model, we need to define components that govern its performance and guide its learning process. These include the loss function, optimizer, and evaluation metrics:\n",
- "\n",
- "* *Loss function* — This defines how we measure how accurate the model is during training. As was covered in lecture, during training we want to minimize this function, which will \"steer\" the model in the right direction.\n",
- "* *Optimizer* — This defines how the model is updated based on the data it sees and its loss function.\n",
- "* *Metrics* — Here we can define metrics that we want to use to monitor the training and testing steps. In this example, we'll define and take a look at the *accuracy*, the fraction of the images that are correctly classified.\n",
- "\n",
- "We'll start out by using a stochastic gradient descent (SGD) optimizer initialized with a learning rate of 0.1. Since we are performing a categorical classification task, we'll want to use the [cross entropy loss](https://pytorch.org/docs/stable/generated/torch.nn.CrossEntropyLoss.html).\n",
- "\n",
- "You'll want to experiment with both the choice of optimizer and learning rate and evaluate how these affect the accuracy of the trained model."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "Lhan11blCaW7"
- },
- "outputs": [],
- "source": [
- "'''TODO: Experiment with different optimizers and learning rates. How do these affect\n",
- " the accuracy of the trained model? Which optimizers and/or learning rates yield\n",
- " the best performance?'''\n",
- "# Define loss function and optimizer\n",
- "loss_function = nn.CrossEntropyLoss()\n",
- "optimizer = optim.SGD(fc_model.parameters(), lr=0.1)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "qKF6uW-BCaW-"
- },
- "source": [
- "### Train the model\n",
- "\n",
- "We're now ready to train our model, which will involve feeding the training data (`train_dataset`) into the model, and then asking it to learn the associations between images and labels. We'll also need to define the batch size and the number of epochs, or iterations over the MNIST dataset, to use during training. This dataset consists of a (image, label) tuples that we will iteratively access in batches.\n",
- "\n",
- "In Lab 1, we saw how we can use the [`.backward()`](https://pytorch.org/docs/stable/generated/torch.Tensor.backward.html) method to optimize losses and train models with stochastic gradient descent. In this section, we will define a function to train the model using `.backward()` and `optimizer.step()` to automatically update our model parameters (weights and biases) as we saw in Lab 1.\n",
- "\n",
- "Recall, we mentioned in Section 1.1 that the MNIST dataset can be accessed iteratively in batches. Here, we will define a PyTorch [`DataLoader`](https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader) that will enable us to do that."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "EFMbIqIvQ2X0"
- },
- "outputs": [],
- "source": [
- "# Create DataLoaders for batch processing\n",
- "BATCH_SIZE = 64\n",
- "trainset_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)\n",
- "testset_loader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "dfnnoDwEsUNY"
- },
- "outputs": [],
- "source": [
- "def train(model, dataloader, criterion, optimizer, epochs):\n",
- " model.train() # Set the model to training mode\n",
- " for epoch in range(epochs):\n",
- " total_loss = 0\n",
- " correct_pred = 0\n",
- " total_pred = 0\n",
- "\n",
- " for images, labels in trainset_loader:\n",
- " # Move tensors to GPU so compatible with model\n",
- " images, labels = images.to(device), labels.to(device)\n",
- " # Clear gradients before performing backward pass\n",
- " optimizer.zero_grad()\n",
- " # Forward pass\n",
- " outputs = fc_model(images)\n",
- " # Calculate loss based on model predictions\n",
- " loss = loss_function(outputs, labels)\n",
- " # Backpropagate and update model parameters\n",
- " loss.backward()\n",
- " optimizer.step()\n",
- " # multiply loss by total nos. of samples in batch\n",
- " total_loss += loss.item()*images.size(0)\n",
- "\n",
- " # Calculate accuracy\n",
- " predicted = torch.argmax(outputs, dim=1) # Get predicted class\n",
- " correct_pred += (predicted == labels).sum().item() # Count correct predictions\n",
- " total_pred += labels.size(0) # Count total predictions\n",
- "\n",
- " # Compute metrics\n",
- " total_epoch_loss = total_loss / total_pred\n",
- " epoch_accuracy = correct_pred / total_pred\n",
- " print(f\"Epoch {epoch + 1}, Loss: {total_epoch_loss}, Accuracy: {epoch_accuracy:.4f}\")\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "kIpdv-H0sUNY"
- },
- "outputs": [],
- "source": [
- "# TODO: Train the model by calling the function appropriately\n",
- "EPOCHS = 5\n",
- "train(fc_model, trainset_loader, loss_function, optimizer, EPOCHS)\n",
- "# train('''TODO''') # TODO\n",
- "\n",
- "comet_model_1.end()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "W3ZVOhugCaXA"
- },
- "source": [
- "As the model trains, the loss and accuracy metrics are displayed. With five epochs and a learning rate of 0.01, this fully connected model should achieve an accuracy of approximatley 0.97 (or 97%) on the training data."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "oEw4bZgGCaXB"
- },
- "source": [
- "### Evaluate accuracy on the test dataset\n",
- "\n",
- "Now that we've trained the model, we can ask it to make predictions about a test set that it hasn't seen before. In this example, iterating over the `testset_loader` allows us to access our test images and test labels. And to evaluate accuracy, we can check to see if the model's predictions match the labels from this loader.\n",
- "\n",
- "Since we have now trained the mode, we will use the eval state of the model on the test dataset."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "VflXLEeECaXC"
- },
- "outputs": [],
- "source": [
- "'''TODO: Use the model we have defined in its eval state to complete\n",
- "and call the evaluate function, and calculate the accuracy of the model'''\n",
- "\n",
- "def evaluate(model, dataloader, loss_function):\n",
- " # Evaluate model performance on the test dataset\n",
- " model.eval()\n",
- " test_loss = 0\n",
- " correct_pred = 0\n",
- " total_pred = 0\n",
- " # Disable gradient calculations when in inference mode\n",
- " with torch.no_grad():\n",
- " for images, labels in testset_loader:\n",
- " # TODO: ensure evalaution happens on the GPU\n",
- " images, labels = images.to(device), labels.to(device)\n",
- " # images, labels = # TODO\n",
- "\n",
- " # TODO: feed the images into the model and obtain the predictions (forward pass)\n",
- " outputs = model(images)\n",
- " # outputs = # TODO\n",
- "\n",
- " loss = loss_function(outputs, labels)\n",
- "\n",
- " # TODO: Calculate test loss\n",
- " test_loss += loss.item() * images.size(0)\n",
- " # test_loss += # TODO\n",
- "\n",
- " '''TODO: make a prediction and determine whether it is correct!'''\n",
- " # TODO: identify the digit with the highest probability prediction for the images in the test dataset.\n",
- " predicted = torch.argmax(outputs, dim=1)\n",
- " # predicted = # TODO\n",
- "\n",
- " # TODO: tally the number of correct predictions\n",
- " correct_pred += (predicted == labels).sum().item()\n",
- " # correct_pred += TODO\n",
- " # TODO: tally the total number of predictions\n",
- " total_pred += labels.size(0)\n",
- " # total_pred += TODO\n",
- "\n",
- " # Compute average loss and accuracy\n",
- " test_loss /= total_pred\n",
- " test_acc = correct_pred / total_pred\n",
- " return test_loss, test_acc\n",
- "\n",
- "# TODO: call the evaluate function to evaluate the trained model!!\n",
- "test_loss, test_acc = evaluate(fc_model, trainset_loader, loss_function)\n",
- "# test_loss, test_acc = # TODO\n",
- "\n",
- "print('Test accuracy:', test_acc)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "yWfgsmVXCaXG"
- },
- "source": [
- "You may observe that the accuracy on the test dataset is a little lower than the accuracy on the training dataset. This gap between training accuracy and test accuracy is an example of *overfitting*, when a machine learning model performs worse on new data than on its training data.\n",
- "\n",
- "What is the highest accuracy you can achieve with this first fully connected model? Since the handwritten digit classification task is pretty straightforward, you may be wondering how we can do better...\n",
- "\n",
- ""
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "baIw9bDf8v6Z"
- },
- "source": [
- "## 1.3 Convolutional Neural Network (CNN) for handwritten digit classification"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "_J72Yt1o_fY7"
- },
- "source": [
- "As we saw in lecture, convolutional neural networks (CNNs) are particularly well-suited for a variety of tasks in computer vision, and have achieved near-perfect accuracies on the MNIST dataset. We will now build a CNN composed of two convolutional layers and pooling layers, followed by two fully connected layers, and ultimately output a probability distribution over the 10 digit classes (0-9). The CNN we will be building is depicted below:\n",
- "\n",
- ""
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "EEHqzbJJAEoR"
- },
- "source": [
- "### Define the CNN model\n",
- "\n",
- "We'll use the same training and test datasets as before, and proceed similarly as our fully connected network to define and train our new CNN model. To do this we will explore two layers we have not encountered before: you can use [`nn.Conv2d`](https://pytorch.org/docs/stable/generated/torch.nn.Conv2d.html) to define convolutional layers and [`nn.MaxPool2D`](https://pytorch.org/docs/stable/generated/torch.nn.MaxPool2d.html) to define the pooling layers. Use the parameters shown in the network architecture above to define these layers and build the CNN model. You can decide to use `nn.Sequential` or to subclass `nn.Module`based on your preference."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "vec9qcJs-9W5"
- },
- "outputs": [],
- "source": [
- "### Basic CNN in PyTorch ###\n",
- "\n",
- "class CNN(nn.Module):\n",
- " def __init__(self):\n",
- " super(CNN, self).__init__()\n",
- " # TODO: Define the first convolutional layer\n",
- " self.conv1 = nn.Conv2d(1, 24, kernel_size=3)\n",
- " # self.conv1 = # TODO\n",
- "\n",
- " # TODO: Define the first max pooling layer\n",
- " self.pool1 = nn.MaxPool2d(kernel_size=2)\n",
- " # self.pool1 = # TODO\n",
- "\n",
- " # TODO: Define the second convolutional layer\n",
- " self.conv2 = nn.Conv2d(24, 36, kernel_size=3)\n",
- " # self.conv2 = # TODO\n",
- "\n",
- " # TODO: Define the second max pooling layer\n",
- " self.pool2 = nn.MaxPool2d(kernel_size=2)\n",
- " # self.pool2 = # TODO\n",
- "\n",
- " self.flatten = nn.Flatten()\n",
- " self.fc1 = nn.Linear(36 * 5 * 5, 128)\n",
- " self.relu = nn.ReLU()\n",
- "\n",
- " # TODO: Define the Linear layer that outputs the classification\n",
- " # logits over class labels. Remember that CrossEntropyLoss operates over logits.\n",
- " self.fc2 = nn.Linear(128, 10)\n",
- " # self.fc2 = # TODO\n",
- "\n",
- "\n",
- " def forward(self, x):\n",
- " # First convolutional and pooling layers\n",
- " x = self.conv1(x)\n",
- " x = self.relu(x)\n",
- " x = self.pool1(x)\n",
- "\n",
- " # '''TODO: Implement the rest of forward pass of the model using the layers you have defined above'''\n",
- " # '''hint: this will involve another set of convolutional/pooling layers and then the linear layers'''\n",
- " x = self.conv2(x)\n",
- " x = self.relu(x)\n",
- " x = self.pool2(x)\n",
- "\n",
- " x = self.flatten(x)\n",
- " x = self.fc1(x)\n",
- " x = self.relu(x)\n",
- " x = self.fc2(x)\n",
- "\n",
- " return x\n",
- "\n",
- "# Instantiate the model\n",
- "cnn_model = CNN().to(device)\n",
- "# Initialize the model by passing some data through\n",
- "image, label = train_dataset[0]\n",
- "image = image.to(device).unsqueeze(0) # Add batch dimension → Shape: (1, 1, 28, 28)\n",
- "output = cnn_model(image)\n",
- "# Print the model summary\n",
- "print(cnn_model)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "kUAXIBynCih2"
- },
- "source": [
- "### Train and test the CNN model\n",
- "\n",
- "Earlier in the lab, we defined a `train` function. The body of the function is quite useful because it allows us to have control over the training model, and to record differentiation operations during training by computing the gradients using `loss.backward()`. You may recall seeing this in Lab 1 Part 1.\n",
- "\n",
- "We'll use this same framework to train our `cnn_model` using stochastic gradient descent. You are free to implement the following parts with or without the train and evaluate functions we defined above. What is most important is understanding how to manipulate the bodies of those functions to train and test models.\n",
- "\n",
- "As we've done above, we can define the loss function, optimizer, and calculate the accuracy of the model. Define an optimizer and learning rate of choice. Feel free to modify as you see fit to optimize your model's performance."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "vheyanDkCg6a"
- },
- "outputs": [],
- "source": [
- "# Rebuild the CNN model\n",
- "cnn_model = CNN().to(device)\n",
- "\n",
- "# Define hyperparams\n",
- "batch_size = 64\n",
- "epochs = 7\n",
- "optimizer = optim.SGD(cnn_model.parameters(), lr=1e-2)\n",
- "\n",
- "# TODO: instantiate the cross entropy loss function\n",
- "loss_function = nn.CrossEntropyLoss()\n",
- "# loss_function = # TODO\n",
- "\n",
- "# Redefine trainloader with new batch size parameter (tweak as see fit if optimizing)\n",
- "trainset_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)\n",
- "testset_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "bzgOEAXVsUNZ"
- },
- "outputs": [],
- "source": [
- "loss_history = mdl.util.LossHistory(smoothing_factor=0.95) # to record the evolution of the loss\n",
- "plotter = mdl.util.PeriodicPlotter(sec=2, xlabel='Iterations', ylabel='Loss', scale='semilogy')\n",
- "\n",
- "# Initialize new comet experiment\n",
- "comet_ml.init(project_name=\"6.s191lab2_part1_CNN\")\n",
- "comet_model_2 = comet_ml.Experiment()\n",
- "\n",
- "if hasattr(tqdm, '_instances'): tqdm._instances.clear() # clear if it exists\n",
- "\n",
- "# Training loop!\n",
- "cnn_model.train()\n",
- "\n",
- "for epoch in range(epochs):\n",
- " total_loss = 0\n",
- " correct_pred = 0\n",
- " total_pred = 0\n",
- "\n",
- " # First grab a batch of training data which our data loader returns as a tensor\n",
- " for idx, (images, labels) in enumerate(tqdm(trainset_loader)):\n",
- " images, labels = images.to(device), labels.to(device)\n",
- "\n",
- " # Forward pass\n",
- " #'''TODO: feed the images into the model and obtain the predictions'''\n",
- " logits = cnn_model(images)\n",
- " # logits = # TODO\n",
- "\n",
- " #'''TODO: compute the categorical cross entropy loss\n",
- " loss = loss_function(logits, labels)\n",
- " # loss = # TODO\n",
- " # Get the loss and log it to comet and the loss_history record\n",
- " loss_value = loss.item()\n",
- " comet_model_2.log_metric(\"loss\", loss_value, step=idx)\n",
- " loss_history.append(loss_value) # append the loss to the loss_history record\n",
- " plotter.plot(loss_history.get())\n",
- "\n",
- " # Backpropagation/backward pass\n",
- " '''TODO: Compute gradients for all model parameters and propagate backwads\n",
- " to update model parameters. remember to reset your optimizer!'''\n",
- " optimizer.zero_grad()\n",
- " loss.backward()\n",
- " optimizer.step()\n",
- "\n",
- " # Get the prediction and tally metrics\n",
- " predicted = torch.argmax(logits, dim=1)\n",
- " correct_pred += (predicted == labels).sum().item()\n",
- " total_pred += labels.size(0)\n",
- "\n",
- " # Compute metrics\n",
- " total_epoch_loss = total_loss / total_pred\n",
- " epoch_accuracy = correct_pred / total_pred\n",
- " print(f\"Epoch {epoch + 1}, Loss: {total_epoch_loss}, Accuracy: {epoch_accuracy:.4f}\")\n",
- "\n",
- "comet_model_2.log_figure(figure=plt)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "UG3ZXwYOsUNZ"
- },
- "source": [
- "### Evaluate the CNN Model\n",
- "\n",
- "Now that we've trained the model, let's evaluate it on the test dataset."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "JDm4znZcDtNl"
- },
- "outputs": [],
- "source": [
- "'''TODO: Evaluate the CNN model!'''\n",
- "\n",
- "test_loss, test_acc = evaluate(cnn_model, trainset_loader, loss_function)\n",
- "# test_loss, test_acc = # TODO\n",
- "\n",
- "print('Test accuracy:', test_acc)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "2rvEgK82Glv9"
- },
- "source": [
- "What is the highest accuracy you're able to achieve using the CNN model, and how does the accuracy of the CNN model compare to the accuracy of the simple fully connected network? What optimizers and learning rates seem to be optimal for training the CNN model?\n",
- "\n",
- "Feel free to click the Comet links to investigate the training/accuracy curves for your model."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "xsoS7CPDCaXH"
- },
- "source": [
- "### Make predictions with the CNN model\n",
- "\n",
- "With the model trained, we can use it to make predictions about some images."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "Gl91RPhdCaXI"
- },
- "outputs": [],
- "source": [
- "test_image, test_label = test_dataset[0]\n",
- "test_image = test_image.to(device).unsqueeze(0)\n",
- "\n",
- "# put the model in evaluation (inference) mode\n",
- "cnn_model.eval()\n",
- "predictions_test_image = cnn_model(test_image)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "x9Kk1voUCaXJ"
- },
- "source": [
- "With this function call, the model has predicted the label of the first image in the testing set. Let's take a look at the prediction:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "3DmJEUinCaXK"
- },
- "outputs": [],
- "source": [
- "predictions_test_image"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "-hw1hgeSCaXN"
- },
- "source": [
- "As you can see, a prediction is an array of 10 numbers. Recall that the output of our model is a distribution over the 10 digit classes. Thus, these numbers describe the model's predicted likelihood that the image corresponds to each of the 10 different digits.\n",
- "\n",
- "Let's look at the digit that has the highest likelihood for the first image in the test dataset:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "qsqenuPnCaXO"
- },
- "outputs": [],
- "source": [
- "'''TODO: identify the digit with the highest likelihood prediction for the first\n",
- " image in the test dataset. '''\n",
- "predictions_value = predictions_test_image.cpu().detach().numpy() #.cpu() to copy tensor to memory first\n",
- "prediction = np.argmax(predictions_value)\n",
- "# prediction = # TODO\n",
- "print(prediction)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "E51yS7iCCaXO"
- },
- "source": [
- "So, the model is most confident that this image is a \"???\". We can check the test label (remember, this is the true identity of the digit) to see if this prediction is correct:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "Sd7Pgsu6CaXP"
- },
- "outputs": [],
- "source": [
- "print(\"Label of this digit is:\", test_label)\n",
- "plt.imshow(test_image[0,0,:,:].cpu(), cmap=plt.cm.binary)\n",
- "comet_model_2.log_figure(figure=plt)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "ygh2yYC972ne"
- },
- "source": [
- "It is! Let's visualize the classification results on the MNIST dataset. We will plot images from the test dataset along with their predicted label, as well as a histogram that provides the prediction probabilities for each of the digits.\n",
- "\n",
- "Recall that in PyTorch the MNIST dataset is typically accessed using a DataLoader to iterate through the test set in smaller, manageable batches. By appending the predictions, test labels, and test images from each batch, we will first gradually accumulate all the data needed for visualization into singular variables to observe our model's predictions."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "v6OqZSiAsUNf"
- },
- "outputs": [],
- "source": [
- "# Initialize variables to store all data\n",
- "all_predictions = []\n",
- "all_labels = []\n",
- "all_images = []\n",
- "\n",
- "# Process test set in batches\n",
- "with torch.no_grad():\n",
- " for images, labels in testset_loader:\n",
- " outputs = cnn_model(images)\n",
- "\n",
- " # Apply softmax to get probabilities from the predicted logits\n",
- " probabilities = torch.nn.functional.softmax(outputs, dim=1)\n",
- "\n",
- " # Get predicted classes\n",
- " predicted = torch.argmax(probabilities, dim=1)\n",
- "\n",
- " all_predictions.append(probabilities)\n",
- " all_labels.append(labels)\n",
- " all_images.append(images)\n",
- "\n",
- "all_predictions = torch.cat(all_predictions) # Shape: (total_samples, num_classes)\n",
- "all_labels = torch.cat(all_labels) # Shape: (total_samples,)\n",
- "all_images = torch.cat(all_images) # Shape: (total_samples, 1, 28, 28)\n",
- "\n",
- "# Convert tensors to NumPy for compatibility with plotting functions\n",
- "predictions = all_predictions.cpu().numpy() # Shape: (total_samples, num_classes)\n",
- "test_labels = all_labels.cpu().numpy() # Shape: (total_samples,)\n",
- "test_images = all_images.cpu().numpy() # Shape: (total_samples, 1, 28, 28)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "HV5jw-5HwSmO"
- },
- "outputs": [],
- "source": [
- "#@title Change the slider to look at the model's predictions! { run: \"auto\" }\n",
- "\n",
- "image_index = 79 #@param {type:\"slider\", min:0, max:100, step:1}\n",
- "plt.subplot(1,2,1)\n",
- "mdl.lab2.plot_image_prediction(image_index, predictions, test_labels, test_images)\n",
- "plt.subplot(1,2,2)\n",
- "mdl.lab2.plot_value_prediction(image_index, predictions, test_labels)\n",
- "comet_model_2.log_figure(figure=plt)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "kgdvGD52CaXR"
- },
- "source": [
- "We can also plot several images along with their predictions, where correct prediction labels are blue and incorrect prediction labels are grey. The number gives the percent confidence (out of 100) for the predicted label. Note the model can be very confident in an incorrect prediction!"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "hQlnbqaw2Qu_"
- },
- "outputs": [],
- "source": [
- "# Plots the first X test images, their predicted label, and the true label\n",
- "# Color correct predictions in blue, incorrect predictions in red\n",
- "num_rows = 5\n",
- "num_cols = 4\n",
- "num_images = num_rows*num_cols\n",
- "plt.figure(figsize=(2*2*num_cols, 2*num_rows))\n",
- "for i in range(num_images):\n",
- " plt.subplot(num_rows, 2*num_cols, 2*i+1)\n",
- " mdl.lab2.plot_image_prediction(i, predictions, test_labels, test_images)\n",
- " plt.subplot(num_rows, 2*num_cols, 2*i+2)\n",
- " mdl.lab2.plot_value_prediction(i, predictions, test_labels)\n",
- "comet_model_2.log_figure(figure=plt)\n",
- "comet_model_2.end()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "3cNtDhVaqEdR"
- },
- "source": [
- "## 1.5 Conclusion\n",
- "In this part of the lab, you had the chance to play with different MNIST classifiers with different architectures (fully-connected layers only, CNN), and experiment with how different hyperparameters affect accuracy (learning rate, etc.). The next part of the lab explores another application of CNNs, facial detection, and some drawbacks of AI systems in real world applications, like issues of bias."
- ]
- }
- ],
- "metadata": {
- "accelerator": "GPU",
- "colab": {
- "collapsed_sections": [
- "Xmf_JRJa_N8C"
- ],
- "name": "PT_Part1_MNIST_Solution.ipynb",
- "provenance": []
- },
- "kernelspec": {
- "display_name": "Python 3",
- "name": "python3"
- },
- "language_info": {
- "codemirror_mode": {
- "name": "ipython",
- "version": 3
- },
- "file_extension": ".py",
- "mimetype": "text/x-python",
- "name": "python",
- "nbconvert_exporter": "python",
- "pygments_lexer": "ipython3",
- "version": "3.10.7"
- }
- },
- "nbformat": 4,
- "nbformat_minor": 0
-}
\ No newline at end of file
diff --git a/lab2/solutions/PT_Part2_Debiasing_Solution.ipynb b/lab2/solutions/PT_Part2_Debiasing_Solution.ipynb
deleted file mode 100644
index b258530b..00000000
--- a/lab2/solutions/PT_Part2_Debiasing_Solution.ipynb
+++ /dev/null
@@ -1,1367 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Ag_e7xtTzT1W"
- },
- "source": [
- "\n",
- "\n",
- "# Copyright Information"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "rNbf1pRlSDby"
- },
- "outputs": [],
- "source": [
- "# Copyright 2025 MIT 6.S191 Introduction to Deep Learning. All Rights Reserved.\n",
- "#\n",
- "# Licensed under the MIT License. You may not use this file except in compliance\n",
- "# with the License. Use and/or modification of this code outside of 6.S191 must\n",
- "# reference:\n",
- "#\n",
- "# © MIT 6.S191: Introduction to Deep Learning\n",
- "# http://introtodeeplearning.com\n",
- "#"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "QOpPUH3FR179"
- },
- "source": [
- "# Laboratory 2: Computer Vision\n",
- "\n",
- "# Part 2: Debiasing Facial Detection Systems\n",
- "\n",
- "In the second portion of the lab, we'll explore two prominent aspects of applied deep learning: facial detection and algorithmic bias.\n",
- "\n",
- "Deploying fair, unbiased AI systems is critical to their long-term acceptance. Consider the task of facial detection: given an image, is it an image of a face? This seemingly simple, but extremely important, task is subject to significant amounts of algorithmic bias among select demographics.\n",
- "\n",
- "In this lab, we'll investigate [one recently published approach](http://introtodeeplearning.com/AAAI_MitigatingAlgorithmicBias.pdf) to addressing algorithmic bias. We'll build a facial detection model that learns the *latent variables* underlying face image datasets and uses this to adaptively re-sample the training data, thus mitigating any biases that may be present in order to train a *debiased* model.\n",
- "\n",
- "\n",
- "Run the next code block for a short video from Google that explores how and why it's important to consider bias when thinking about machine learning:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "XQh5HZfbupFF"
- },
- "outputs": [],
- "source": [
- "import IPython\n",
- "\n",
- "IPython.display.YouTubeVideo(\"59bMh59JQDo\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "3Ezfc6Yv6IhI"
- },
- "source": [
- "Let's get started by installing the relevant dependencies.\n",
- "\n",
- "We will be using Comet ML to track our model development and training runs.\n",
- "\n",
- "1. Sign up for a Comet account: [HERE](https://www.comet.com/signup?utm_source=mit_dl&utm_medium=partner&utm_content=github)\n",
- "2. This will generate a personal API Key, which you can find either in the first 'Get Started with Comet' page, under your account settings, or by pressing the '?' in the top right corner and then 'Quickstart Guide'. Enter this API key as the global variable `COMET_API_KEY` below.\n",
- "\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "9MLH3vHqy741"
- },
- "outputs": [],
- "source": [
- "## Comet ML\n",
- "!pip install comet_ml --quiet\n",
- "import comet_ml\n",
- "\n",
- "# TODO: ENTER YOUR API KEY HERE!! instructions above\n",
- "COMET_API_KEY = \"\"\n",
- "assert COMET_API_KEY != \"\", \"Please insert your Comet API Key\"\n",
- "\n",
- "# MIT introduction to deep learning package\n",
- "!pip install mitdeeplearning --quiet\n",
- "import mitdeeplearning as mdl"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "E46sWVKK6LP9"
- },
- "outputs": [],
- "source": [
- "import os\n",
- "import random\n",
- "import IPython\n",
- "import functools\n",
- "import matplotlib.pyplot as plt\n",
- "import numpy as np\n",
- "from tqdm import tqdm\n",
- "from pathlib import Path\n",
- "\n",
- "# Import torch\n",
- "import torch\n",
- "import torch.nn as nn\n",
- "import torch.optim as optim\n",
- "import torch.nn.functional as F\n",
- "import torch.backends.cudnn as cudnn\n",
- "\n",
- "\n",
- "# Check that we are using a GPU, if not switch runtimes\n",
- "# using Runtime > Change Runtime Type > GPU\n",
- "if torch.cuda.is_available():\n",
- " device = torch.device(\"cuda\")\n",
- " cudnn.benchmark = True\n",
- "else:\n",
- " raise ValueError(\"GPU is not available. Change Colab runtime.\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "V0e77oOM3udR"
- },
- "source": [
- "## 2.1 Datasets\n",
- "\n",
- "We'll be using three datasets in this lab. In order to train our facial detection models, we'll need a dataset of positive examples (i.e., of faces) and a dataset of negative examples (i.e., of things that are not faces). We'll use these data to train our models to classify images as either faces or not faces. Finally, we'll need a test dataset of face images. Since we're concerned about the potential *bias* of our learned models against certain demographics, it's important that the test dataset we use has equal representation across the demographics or features of interest. In this lab, we'll consider skin tone and gender.\n",
- "\n",
- "1. **Positive training data**: [CelebA Dataset](http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html). A large-scale (over 200K images) of celebrity faces. \n",
- "2. **Negative training data**: [ImageNet](http://www.image-net.org/). Many images across many different categories. We'll take negative examples from a variety of non-human categories.\n",
- "[Fitzpatrick Scale](https://en.wikipedia.org/wiki/Fitzpatrick_scale) skin type classification system, with each image labeled as \"Lighter'' or \"Darker''.\n",
- "\n",
- "Let's begin by importing these datasets. We've written a class that does a bit of data pre-processing to import the training data in a usable format."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "RWXaaIWy6jVw"
- },
- "outputs": [],
- "source": [
- "CACHE_DIR = Path.home() / \".cache\" / \"mitdeeplearning\"\n",
- "CACHE_DIR.mkdir(parents=True, exist_ok=True)\n",
- "\n",
- "# Get the training data: both images from CelebA and ImageNet\n",
- "path_to_training_data = CACHE_DIR.joinpath(\"train_face.h5\")\n",
- "\n",
- "# Create a simple check to avoid re-downloading\n",
- "if path_to_training_data.is_file():\n",
- " print(f\"Using cached training data from {path_to_training_data}\")\n",
- "else:\n",
- " print(f\"Downloading training data to {path_to_training_data}\")\n",
- " url = \"https://www.dropbox.com/s/hlz8atheyozp1yx/train_face.h5?dl=1\"\n",
- " torch.hub.download_url_to_file(url, path_to_training_data)\n",
- "\n",
- "# Instantiate a TrainingDatasetLoader using the downloaded dataset\n",
- "channels_last = False\n",
- "loader = mdl.lab2.TrainingDatasetLoader(\n",
- " path_to_training_data, channels_last=channels_last\n",
- ")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "yIE321rxa_b3"
- },
- "source": [
- "We can look at the size of the training dataset and grab a batch of size 100:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "DjPSjZZ_bGqe"
- },
- "outputs": [],
- "source": [
- "number_of_training_examples = loader.get_train_size()\n",
- "(images, labels) = loader.get_batch(100)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "tpa3a2z0y742"
- },
- "outputs": [],
- "source": [
- "B, C, H, W = images.shape"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "sxtkJoqF6oH1"
- },
- "source": [
- "Play around with displaying images to get a sense of what the training data actually looks like!"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "Jg17jzwtbxDA"
- },
- "outputs": [],
- "source": [
- "### Examining the CelebA training dataset ###\n",
- "\n",
- "# @title Change the sliders to look at positive and negative training examples! { run: \"auto\" }\n",
- "\n",
- "face_images = images[np.where(labels == 1)[0]].transpose(0, 2, 3, 1)\n",
- "not_face_images = images[np.where(labels == 0)[0]].transpose(0, 2, 3, 1)\n",
- "\n",
- "idx_face = 23 # @param {type:\"slider\", min:0, max:50, step:1}\n",
- "idx_not_face = 9 # @param {type:\"slider\", min:0, max:50, step:1}\n",
- "\n",
- "plt.figure(figsize=(5, 5))\n",
- "plt.subplot(1, 2, 1)\n",
- "plt.imshow(face_images[idx_face])\n",
- "plt.title(\"Face\")\n",
- "plt.grid(False)\n",
- "\n",
- "plt.subplot(1, 2, 2)\n",
- "plt.imshow(not_face_images[idx_not_face])\n",
- "plt.title(\"Not Face\")\n",
- "plt.grid(False)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "NDj7KBaW8Asz"
- },
- "source": [
- "### Thinking about bias\n",
- "\n",
- "Remember we'll be training our facial detection classifiers on the large, well-curated CelebA dataset (and ImageNet), and then evaluating their accuracy by testing them on an independent test dataset. Our goal is to build a model that trains on CelebA *and* achieves high classification accuracy on the the test dataset across all demographics, and to thus show that this model does not suffer from any hidden bias.\n",
- "\n",
- "What exactly do we mean when we say a classifier is biased? In order to formalize this, we'll need to think about [*latent variables*](https://en.wikipedia.org/wiki/Latent_variable), variables that define a dataset but are not strictly observed. As defined in the generative modeling lecture, we'll use the term *latent space* to refer to the probability distributions of the aforementioned latent variables. Putting these ideas together, we consider a classifier *biased* if its classification decision changes after it sees some additional latent features. This notion of bias may be helpful to keep in mind throughout the rest of the lab."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "AIFDvU4w8OIH"
- },
- "source": [
- "## 2.2 CNN for facial detection\n",
- "\n",
- "First, we'll define and train a CNN on the facial classification task, and evaluate its accuracy. Later, we'll evaluate the performance of our debiased models against this baseline CNN. The CNN model has a relatively standard architecture consisting of a series of convolutional layers with batch normalization followed by two fully connected layers to flatten the convolution output and generate a class prediction.\n",
- "\n",
- "### Define and train the CNN model\n",
- "\n",
- "Like we did in the first part of the lab, we'll define our CNN model, and then train on the CelebA and ImageNet datasets by leveraging PyTorch's automatic differentiation (`torch.autograd`) by using the `loss.backward()` and `optimizer.step()` functions."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "82EVTAAW7B_X"
- },
- "outputs": [],
- "source": [
- "### Define the CNN model ###\n",
- "\n",
- "n_filters = 12 # base number of convolutional filters\n",
- "in_channels = images.shape[1]\n",
- "\n",
- "def make_standard_classifier(n_outputs):\n",
- " \"\"\"Create a standard CNN classifier.\"\"\"\n",
- "\n",
- " # Start by first defining a convolutional block\n",
- " class ConvBlock(nn.Module):\n",
- " def __init__(self, in_channels, out_channels, kernel_size, stride, padding=0):\n",
- " super().__init__()\n",
- " self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)\n",
- " self.relu = nn.ReLU(inplace=True)\n",
- " self.bn = nn.BatchNorm2d(out_channels)\n",
- "\n",
- " def forward(self, x):\n",
- " x = self.conv(x)\n",
- " x = self.relu(x)\n",
- " x = self.bn(x)\n",
- " return x\n",
- "\n",
- " # now use the block to define the classifier\n",
- " model = nn.Sequential(\n",
- " ConvBlock(in_channels, n_filters, kernel_size=5, stride=2, padding=2),\n",
- " ConvBlock(n_filters, 2*n_filters, kernel_size=5, stride=2, padding=2),\n",
- " ConvBlock(2*n_filters, 4*n_filters, kernel_size=3, stride=2, padding=1),\n",
- " ConvBlock(4*n_filters, 6*n_filters, kernel_size=3, stride=2, padding=1),\n",
- " nn.Flatten(),\n",
- " nn.Linear(H // 16 * W // 16 * 6 * n_filters, 512),\n",
- " nn.ReLU(inplace=True),\n",
- " nn.Linear(512, n_outputs),\n",
- " )\n",
- "\n",
- " return model.to(device)\n",
- "\n",
- "# call the function to instantiate a classifier model\n",
- "standard_classifier = make_standard_classifier(n_outputs=1)\n",
- "print(standard_classifier)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "c-eWf3l_lCri"
- },
- "source": [
- "Now let's train the standard CNN!"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "mi-04SAfK6lm"
- },
- "outputs": [],
- "source": [
- "### Create a Comet experiment to track our training run ###\n",
- "def create_experiment(project_name, params):\n",
- " # end any prior experiments\n",
- " if \"experiment\" in locals():\n",
- " experiment.end()\n",
- "\n",
- " # initiate the comet experiment for tracking\n",
- " experiment = comet_ml.Experiment(api_key=COMET_API_KEY, project_name=project_name)\n",
- " # log our hyperparameters, defined above, to the experiment\n",
- " for param, value in params.items():\n",
- " experiment.log_parameter(param, value)\n",
- " experiment.flush()\n",
- "\n",
- " return experiment\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "eJlDGh1o31G1"
- },
- "outputs": [],
- "source": [
- "### Train the standard CNN ###\n",
- "loss_fn = nn.BCEWithLogitsLoss()\n",
- "# Training hyperparameters\n",
- "params = dict(\n",
- " batch_size=32,\n",
- " num_epochs=2, # keep small to run faster\n",
- " learning_rate=5e-4,\n",
- ")\n",
- "\n",
- "experiment = create_experiment(\"6S191_Lab2_Part2_CNN\", params)\n",
- "\n",
- "optimizer = optim.Adam(\n",
- " standard_classifier.parameters(), lr=params[\"learning_rate\"]\n",
- ") # define our optimizer\n",
- "loss_history = mdl.util.LossHistory(smoothing_factor=0.99) # to record loss evolution\n",
- "plotter = mdl.util.PeriodicPlotter(sec=2, scale=\"semilogy\")\n",
- "if hasattr(tqdm, \"_instances\"):\n",
- " tqdm._instances.clear() # clear if it exists\n",
- "\n",
- "# set the model to train mode\n",
- "standard_classifier.train()\n",
- "\n",
- "\n",
- "def standard_train_step(x, y):\n",
- " x = torch.from_numpy(x).float().to(device)\n",
- " y = torch.from_numpy(y).float().to(device)\n",
- "\n",
- " # clear the gradients\n",
- " optimizer.zero_grad()\n",
- "\n",
- " # feed the images into the model\n",
- " logits = standard_classifier(x)\n",
- " # Compute the loss\n",
- " loss = loss_fn(logits, y)\n",
- "\n",
- " # Backpropagation\n",
- " loss.backward()\n",
- " optimizer.step()\n",
- "\n",
- " return loss\n",
- "\n",
- "\n",
- "# The training loop!\n",
- "step = 0\n",
- "for epoch in range(params[\"num_epochs\"]):\n",
- " for idx in tqdm(range(loader.get_train_size() // params[\"batch_size\"])):\n",
- " # Grab a batch of training data and propagate through the network\n",
- " x, y = loader.get_batch(params[\"batch_size\"])\n",
- " loss = standard_train_step(x, y)\n",
- " loss_value = loss.detach().cpu().numpy()\n",
- "\n",
- " # Record the loss and plot the evolution of the loss as a function of training\n",
- " loss_history.append(loss_value)\n",
- " plotter.plot(loss_history.get())\n",
- "\n",
- " experiment.log_metric(\"loss\", loss_value, step=step)\n",
- " step += 1\n",
- "\n",
- "experiment.end()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "AKMdWVHeCxj8"
- },
- "source": [
- "### Evaluate performance of the standard CNN\n",
- "\n",
- "Next, let's evaluate the classification performance of our CelebA-trained standard CNN on the training dataset.\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "35-PDgjdWk6_"
- },
- "outputs": [],
- "source": [
- "### Evaluation of standard CNN ###\n",
- "\n",
- "# set the model to eval mode\n",
- "standard_classifier.eval()\n",
- "\n",
- "# TRAINING DATA\n",
- "# Evaluate on a subset of CelebA+Imagenet\n",
- "(batch_x, batch_y) = loader.get_batch(5000)\n",
- "batch_x = torch.from_numpy(batch_x).float().to(device)\n",
- "batch_y = torch.from_numpy(batch_y).float().to(device)\n",
- "\n",
- "with torch.inference_mode():\n",
- " y_pred_logits = standard_classifier(batch_x)\n",
- " y_pred_standard = torch.round(torch.sigmoid(y_pred_logits))\n",
- " acc_standard = torch.mean((batch_y == y_pred_standard).float())\n",
- "\n",
- "print(\n",
- " \"Standard CNN accuracy on (potentially biased) training set: {:.4f}\".format(\n",
- " acc_standard.item()\n",
- " )\n",
- ")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Qu7R14KaEEvU"
- },
- "source": [
- "We will also evaluate our networks on an independent test dataset containing faces that were not seen during training. For the test data, we'll look at the classification accuracy across four different demographics, based on the Fitzpatrick skin scale and sex-based labels: dark-skinned male, dark-skinned female, light-skinned male, and light-skinned female.\n",
- "\n",
- "Let's take a look at some sample faces in the test set."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "vfDD8ztGWk6x"
- },
- "outputs": [],
- "source": [
- "### Load test dataset and plot examples ###\n",
- "\n",
- "test_faces = mdl.lab2.get_test_faces(channels_last=channels_last)\n",
- "keys = [\"Light Female\", \"Light Male\", \"Dark Female\", \"Dark Male\"]\n",
- "\n",
- "fig, axs = plt.subplots(1, len(keys), figsize=(7.5, 7.5))\n",
- "for i, (group, key) in enumerate(zip(test_faces, keys)):\n",
- " axs[i].imshow(np.hstack(group).transpose(1, 2, 0))\n",
- " axs[i].set_title(key, fontsize=15)\n",
- " axs[i].axis(\"off\")\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "uo1z3cdbEUMM"
- },
- "source": [
- "Now, let's evaluate the probability of each of these face demographics being classified as a face using the standard CNN classifier we've just trained."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "GI4O0Y1GAot9"
- },
- "outputs": [],
- "source": [
- "### Evaluate the standard CNN on the test data ###\n",
- "\n",
- "standard_classifier_probs_list = [] # store each demographic's probabilities\n",
- "\n",
- "with torch.inference_mode():\n",
- " for x in test_faces:\n",
- " x = torch.from_numpy(np.array(x, dtype=np.float32)).to(device)\n",
- " logits = standard_classifier(x) # [B, 1]\n",
- " probs = torch.sigmoid(logits) # [B, 1]\n",
- " probs = torch.squeeze(probs, dim=-1) # shape [B]\n",
- " standard_classifier_probs_list.append(probs.cpu().numpy())\n",
- "\n",
- "standard_classifier_probs = np.stack(standard_classifier_probs_list, axis=0)\n",
- "\n",
- "\n",
- "# Plot the prediction accuracies per demographic\n",
- "xx = range(len(keys))\n",
- "yy = standard_classifier_probs.mean(axis=1) # shape [D]\n",
- "plt.bar(xx, yy)\n",
- "plt.xticks(xx, keys)\n",
- "plt.ylim(max(0, yy.min() - np.ptp(yy) / 2.0), yy.max() + np.ptp(yy) / 2.0)\n",
- "plt.title(\"Standard classifier predictions\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "j0Cvvt90DoAm"
- },
- "source": [
- "Take a look at the accuracies for this first model across these four groups. What do you observe? Would you consider this model biased or unbiased? What are some reasons why a trained model may have biased accuracies?"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "0AKcHnXVtgqJ"
- },
- "source": [
- "## 2.3 Mitigating algorithmic bias\n",
- "\n",
- "Imbalances in the training data can result in unwanted algorithmic bias. For example, the majority of faces in CelebA (our training set) are those of light-skinned females. As a result, a classifier trained on CelebA will be better suited at recognizing and classifying faces with features similar to these, and will thus be biased.\n",
- "\n",
- "How could we overcome this? A naive solution -- and one that is being adopted by many companies and organizations -- would be to annotate different subclasses (i.e., light-skinned females, males with hats, etc.) within the training data, and then manually even out the data with respect to these groups.\n",
- "\n",
- "But this approach has two major disadvantages. First, it requires annotating massive amounts of data, which is not scalable. Second, it requires that we know what potential biases (e.g., race, gender, pose, occlusion, hats, glasses, etc.) to look for in the data. As a result, manual annotation may not capture all the different features that are imbalanced within the training data.\n",
- "\n",
- "Instead, let's actually **learn** these features in an unbiased, unsupervised manner, without the need for any annotation, and then train a classifier fairly with respect to these features. In the rest of this lab, we'll do exactly that."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "nLemS7dqECsI"
- },
- "source": [
- "## 2.4 Variational autoencoder (VAE) for learning latent structure\n",
- "\n",
- "As you saw, the accuracy of the CNN varies across the four demographics we looked at. To think about why this may be, consider the dataset the model was trained on, CelebA. If certain features, such as dark skin or hats, are *rare* in CelebA, the model may end up biased against these as a result of training with a biased dataset. That is to say, its classification accuracy will be worse on faces that have under-represented features, such as dark-skinned faces or faces with hats, relevative to faces with features well-represented in the training data! This is a problem.\n",
- "\n",
- "Our goal is to train a *debiased* version of this classifier -- one that accounts for potential disparities in feature representation within the training data. Specifically, to build a debiased facial classifier, we'll train a model that **learns a representation of the underlying latent space** to the face training data. The model then uses this information to mitigate unwanted biases by sampling faces with rare features, like dark skin or hats, *more frequently* during training. The key design requirement for our model is that it can learn an *encoding* of the latent features in the face data in an entirely *unsupervised* way. To achieve this, we'll turn to variational autoencoders (VAEs).\n",
- "\n",
- "\n",
- "\n",
- "As shown in the schematic above and in Lecture 4, VAEs rely on an encoder-decoder structure to learn a latent representation of the input data. In the context of computer vision, the encoder network takes in input images, encodes them into a series of variables defined by a mean and standard deviation, and then draws from the distributions defined by these parameters to generate a set of sampled latent variables. The decoder network then \"decodes\" these variables to generate a reconstruction of the original image, which is used during training to help the model identify which latent variables are important to learn.\n",
- "\n",
- "Let's formalize two key aspects of the VAE model and define relevant functions for each.\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "KmbXKtcPkTXA"
- },
- "source": [
- "### Understanding VAEs: loss function\n",
- "\n",
- "In practice, how can we train a VAE? In learning the latent space, we constrain the means and standard deviations to approximately follow a unit Gaussian. Recall that these are learned parameters, and therefore must factor into the loss computation, and that the decoder portion of the VAE is using these parameters to output a reconstruction that should closely match the input image, which also must factor into the loss. What this means is that we'll have two terms in our VAE loss function:\n",
- "\n",
- "1. **Latent loss ($L_{KL}$)**: measures how closely the learned latent variables match a unit Gaussian and is defined by the Kullback-Leibler (KL) divergence.\n",
- "2. **Reconstruction loss ($L_{x}{(x,\\hat{x})}$)**: measures how accurately the reconstructed outputs match the input and is given by the $L^1$ norm of the input image and its reconstructed output."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Ux3jK2wc153s"
- },
- "source": [
- "The equation for the latent loss is provided by:\n",
- "\n",
- "$$L_{KL}(\\mu, \\sigma) = \\frac{1}{2}\\sum_{j=0}^{k-1} (\\sigma_j + \\mu_j^2 - 1 - \\log{\\sigma_j})$$\n",
- "\n",
- "The equation for the reconstruction loss is provided by:\n",
- "\n",
- "$$L_{x}{(x,\\hat{x})} = ||x-\\hat{x}||_1$$\n",
- "\n",
- "Thus for the VAE loss we have:\n",
- "\n",
- "$$L_{VAE} = c\\cdot L_{KL} + L_{x}{(x,\\hat{x})}$$\n",
- "\n",
- "where $c$ is a weighting coefficient used for regularization. Now we're ready to define our VAE loss function:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "S00ASo1ImSuh"
- },
- "outputs": [],
- "source": [
- "### Defining the VAE loss function ###\n",
- "\n",
- "\"\"\" Function to calculate VAE loss given:\n",
- " an input x,\n",
- " reconstructed output x_recon,\n",
- " encoded means mu,\n",
- " encoded log of standard deviation logsigma,\n",
- " weight parameter for the latent loss kl_weight\n",
- "\"\"\"\n",
- "def vae_loss_function(x, x_recon, mu, logsigma, kl_weight=0.0005):\n",
- " # TODO: Define the latent loss. Note this is given in the equation for L_{KL}\n",
- " # in the text block directly above\n",
- " latent_loss = 0.5 * torch.sum(torch.exp(logsigma) + mu**2 - 1 - logsigma, dim=1)\n",
- " # latent_loss = # TODO\n",
- "\n",
- " # TODO: Define the reconstruction loss as the mean absolute pixel-wise\n",
- " # difference between the input and reconstruction. Hint: you'll need to\n",
- " # use torch.mean, and specify the dimensions to reduce over.\n",
- " # For example, reconstruction loss needs to average\n",
- " # over the height, width, and channel image dimensions.\n",
- " # https://pytorch.org/docs/stable/generated/torch.mean.html\n",
- " reconstruction_loss = torch.mean(torch.abs(x - x_recon), dim=(1, 2, 3))\n",
- " # reconstruction_loss = # TODO\n",
- "\n",
- " # TODO: Define the VAE loss. Note this is given in the equation for L_{VAE}\n",
- " # in the text block directly above\n",
- " vae_loss = kl_weight * latent_loss + reconstruction_loss\n",
- " # vae_loss = # TODO\n",
- "\n",
- " return vae_loss"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "E8mpb3pJorpu"
- },
- "source": [
- "Great! Now that we have a more concrete sense of how VAEs work, let's explore how we can leverage this network structure to train a *debiased* facial classifier."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "DqtQH4S5fO8F"
- },
- "source": [
- "### Understanding VAEs: reparameterization\n",
- "\n",
- "As you may recall from lecture, VAEs use a \"reparameterization trick\" for sampling learned latent variables. Instead of the VAE encoder generating a single vector of real numbers for each latent variable, it generates a vector of means and a vector of standard deviations that are constrained to roughly follow Gaussian distributions. We then sample from the standard deviations and add back the mean to output this as our sampled latent vector. Formalizing this for a latent variable $z$ where we sample $\\epsilon \\sim N(0,(I))$ we have:\n",
- "\n",
- "$$z = \\mu + e^{\\left(\\frac{1}{2} \\cdot \\log{\\Sigma}\\right)}\\circ \\epsilon$$\n",
- "\n",
- "where $\\mu$ is the mean and $\\Sigma$ is the covariance matrix. This is useful because it will let us neatly define the loss function for the VAE, generate randomly sampled latent variables, achieve improved network generalization, **and** make our complete VAE network differentiable so that it can be trained via backpropagation. Quite powerful!\n",
- "\n",
- "Let's define a function to implement the VAE sampling operation:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "cT6PGdNajl3K"
- },
- "outputs": [],
- "source": [
- "### VAE Reparameterization ###\n",
- "\n",
- "\"\"\"Reparameterization trick by sampling from an isotropic unit Gaussian.\n",
- "# Arguments\n",
- " z_mean, z_logsigma (tensor): mean and log of standard deviation of latent distribution (Q(z|X))\n",
- "# Returns\n",
- " z (tensor): sampled latent vector\n",
- "\"\"\"\n",
- "def sampling(z_mean, z_logsigma):\n",
- " # Generate random noise with the same shape as z_mean, sampled from a standard normal distribution (mean=0, std=1)\n",
- " eps = torch.randn_like(z_mean)\n",
- "\n",
- " # # TODO: Define the reparameterization computation!\n",
- " # # Note the equation is given in the text block immediately above.\n",
- " z = z_mean + torch.exp(z_logsigma) * eps\n",
- " # z = # TODO\n",
- "\n",
- " return z"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "qtHEYI9KNn0A"
- },
- "source": [
- "## 2.5 Debiasing variational autoencoder (DB-VAE)\n",
- "\n",
- "Now, we'll use the general idea behind the VAE architecture to build a model, termed a [*debiasing variational autoencoder*](https://lmrt.mit.edu/sites/default/files/AIES-19_paper_220.pdf) or DB-VAE, to mitigate (potentially) unknown biases present within the training idea. We'll train our DB-VAE model on the facial detection task, run the debiasing operation during training, evaluate on the PPB dataset, and compare its accuracy to our original, biased CNN model. \n",
- "\n",
- "### The DB-VAE model\n",
- "\n",
- "The key idea behind this debiasing approach is to use the latent variables learned via a VAE to adaptively re-sample the CelebA data during training. Specifically, we will alter the probability that a given image is used during training based on how often its latent features appear in the dataset. So, faces with rarer features (like dark skin, sunglasses, or hats) should become more likely to be sampled during training, while the sampling probability for faces with features that are over-represented in the training dataset should decrease (relative to uniform random sampling across the training data).\n",
- "\n",
- "A general schematic of the DB-VAE approach is shown here:\n",
- "\n",
- ""
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "ziA75SN-UxxO"
- },
- "source": [
- "Recall that we want to apply our DB-VAE to a *supervised classification* problem -- the facial detection task. Importantly, note how the encoder portion in the DB-VAE architecture also outputs a single supervised variable, $z_o$, corresponding to the class prediction -- face or not face. Usually, VAEs are not trained to output any supervised variables (such as a class prediction)! This is another key distinction between the DB-VAE and a traditional VAE.\n",
- "\n",
- "Keep in mind that we only want to learn the latent representation of *faces*, as that's what we're ultimately debiasing against, even though we are training a model on a binary classification problem. We'll need to ensure that, **for faces**, our DB-VAE model both learns a representation of the unsupervised latent variables, captured by the distribution $q_\\phi(z|x)$, **and** outputs a supervised class prediction $z_o$, but that, **for negative examples**, it only outputs a class prediction $z_o$."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "XggIKYPRtOZR"
- },
- "source": [
- "### Defining the DB-VAE loss function\n",
- "\n",
- "This means we'll need to be a bit clever about the loss function for the DB-VAE. The form of the loss will depend on whether it's a face image or a non-face image that's being considered.\n",
- "\n",
- "For **face images**, our loss function will have two components:\n",
- "\n",
- "\n",
- "1. **VAE loss ($L_{VAE}$)**: consists of the latent loss and the reconstruction loss.\n",
- "2. **Classification loss ($L_y(y,\\hat{y})$)**: standard cross-entropy loss for a binary classification problem.\n",
- "\n",
- "In contrast, for images of **non-faces**, our loss function is solely the classification loss.\n",
- "\n",
- "We can write a single expression for the loss by defining an indicator variable ${I}_f$which reflects which training data are images of faces (${I}_f(y) = 1$ ) and which are images of non-faces (${I}_f(y) = 0$). Using this, we obtain:\n",
- "\n",
- "$$L_{total} = L_y(y,\\hat{y}) + {I}_f(y)\\Big[L_{VAE}\\Big]$$\n",
- "\n",
- "Let's write a function to define the DB-VAE loss function:\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "VjieDs8Ovcqs"
- },
- "outputs": [],
- "source": [
- "### Loss function for DB-VAE ###\n",
- "\n",
- "\"\"\"Loss function for DB-VAE.\n",
- "# Arguments\n",
- " x: true input x\n",
- " x_pred: reconstructed x\n",
- " y: true label (face or not face)\n",
- " y_logit: predicted labels\n",
- " mu: mean of latent distribution (Q(z|X))\n",
- " logsigma: log of standard deviation of latent distribution (Q(z|X))\n",
- "# Returns\n",
- " total_loss: DB-VAE total loss\n",
- " classification_loss = DB-VAE classification loss\n",
- "\"\"\"\n",
- "def debiasing_loss_function(x, x_pred, y, y_logit, mu, logsigma):\n",
- " # TODO: call the relevant function to obtain VAE loss\n",
- " vae_loss = vae_loss_function(x, x_pred, mu, logsigma)\n",
- " # vae_loss = vae_loss_function('''TODO''') # TODO\n",
- "\n",
- " # TODO: define the classification loss using binary_cross_entropy\n",
- " # https://pytorch.org/docs/stable/generated/torch.nn.functional.binary_cross_entropy_with_logits.html\n",
- " classification_loss = F.binary_cross_entropy_with_logits(\n",
- " y_logit, y, reduction=\"none\"\n",
- " )\n",
- " # classification_loss = # TODO\n",
- "\n",
- " # Use the training data labels to create variable face_indicator:\n",
- " # indicator that reflects which training data are images of faces\n",
- " y = y.float()\n",
- " face_indicator = (y == 1.0).float()\n",
- "\n",
- " # TODO: define the DB-VAE total loss! Use torch.mean to average over all\n",
- " # samples\n",
- " total_loss = torch.mean(classification_loss * face_indicator + vae_loss)\n",
- " # total_loss = # TODO\n",
- "\n",
- " return total_loss, classification_loss"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "YIu_2LzNWwWY"
- },
- "source": [
- "### DB-VAE architecture\n",
- "\n",
- "Now we're ready to define the DB-VAE architecture. To build the DB-VAE, we will use the standard CNN classifier from above as our encoder, and then define a decoder network. We will create and initialize the two models, and then construct the end-to-end VAE. We will use a latent space with 100 latent variables.\n",
- "\n",
- "The decoder network will take as input the sampled latent variables, run them through a series of deconvolutional layers, and output a reconstruction of the original input image."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "JfWPHGrmyE7R"
- },
- "outputs": [],
- "source": [
- "### Define the decoder portion of the DB-VAE ###\n",
- "\n",
- "n_filters = 12 # base number of convolutional filters, same as standard CNN\n",
- "latent_dim = 100 # number of latent variables\n",
- "\n",
- "\n",
- "def make_face_decoder_network(latent_dim=100, n_filters=12):\n",
- " \"\"\"\n",
- " Function builds a face-decoder network.\n",
- "\n",
- " Args:\n",
- " latent_dim (int): the dimension of the latent representation\n",
- " n_filters (int): base number of convolutional filters\n",
- "\n",
- " Returns:\n",
- " decoder_model (nn.Module): the decoder network\n",
- " \"\"\"\n",
- "\n",
- " class FaceDecoder(nn.Module):\n",
- " def __init__(self, latent_dim, n_filters):\n",
- " super(FaceDecoder, self).__init__()\n",
- "\n",
- " self.latent_dim = latent_dim\n",
- " self.n_filters = n_filters\n",
- "\n",
- " # Linear (fully connected) layer to project from latent space\n",
- " # to a 4 x 4 feature map with (6*n_filters) channels\n",
- " self.linear = nn.Sequential(\n",
- " nn.Linear(latent_dim, 4 * 4 * 6 * n_filters), nn.ReLU()\n",
- " )\n",
- "\n",
- " # Convolutional upsampling (inverse of an encoder)\n",
- " self.deconv = nn.Sequential(\n",
- " # [B, 6n_filters, 4, 4] -> [B, 4n_filters, 8, 8]\n",
- " nn.ConvTranspose2d(\n",
- " in_channels=6 * n_filters,\n",
- " out_channels=4 * n_filters,\n",
- " kernel_size=3,\n",
- " stride=2,\n",
- " padding=1,\n",
- " output_padding=1,\n",
- " ),\n",
- " nn.ReLU(),\n",
- " # [B, 4n_filters, 8, 8] -> [B, 2n_filters, 16, 16]\n",
- " nn.ConvTranspose2d(\n",
- " in_channels=4 * n_filters,\n",
- " out_channels=2 * n_filters,\n",
- " kernel_size=3,\n",
- " stride=2,\n",
- " padding=1,\n",
- " output_padding=1,\n",
- " ),\n",
- " nn.ReLU(),\n",
- " # [B, 2n_filters, 16, 16] -> [B, n_filters, 32, 32]\n",
- " nn.ConvTranspose2d(\n",
- " in_channels=2 * n_filters,\n",
- " out_channels=n_filters,\n",
- " kernel_size=5,\n",
- " stride=2,\n",
- " padding=2,\n",
- " output_padding=1,\n",
- " ),\n",
- " nn.ReLU(),\n",
- " # [B, n_filters, 32, 32] -> [B, 3, 64, 64]\n",
- " nn.ConvTranspose2d(\n",
- " in_channels=n_filters,\n",
- " out_channels=3,\n",
- " kernel_size=5,\n",
- " stride=2,\n",
- " padding=2,\n",
- " output_padding=1,\n",
- " ),\n",
- " )\n",
- "\n",
- " def forward(self, z):\n",
- " \"\"\"\n",
- " Forward pass of the decoder.\n",
- "\n",
- " Args:\n",
- " z (Tensor): Latent codes of shape [batch_size, latent_dim].\n",
- "\n",
- " Returns:\n",
- " Tensor of shape [batch_size, 3, 64, 64], representing\n",
- " the reconstructed images.\n",
- " \"\"\"\n",
- " x = self.linear(z) # [B, 4*4*6*n_filters]\n",
- " x = x.view(-1, 6 * self.n_filters, 4, 4) # [B, 6n_filters, 4, 4]\n",
- "\n",
- " # Upsample through transposed convolutions\n",
- " x = self.deconv(x) # [B, 3, 64, 64]\n",
- " return x\n",
- "\n",
- " return FaceDecoder(latent_dim, n_filters)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "yWCMu12w1BuD"
- },
- "source": [
- "Now, we will put this decoder together with the standard CNN classifier as our encoder to define the DB-VAE. Note that at this point, there is nothing special about how we put the model together that makes it a \"debiasing\" model -- that will come when we define the training operation. Here, we will define the core VAE architecture by sublassing `nn.Module` class; defining encoding, reparameterization, and decoding operations; and calling the network end-to-end."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "dSFDcFBL13c3"
- },
- "outputs": [],
- "source": [
- "### Defining and creating the DB-VAE ###\n",
- "\n",
- "\n",
- "class DB_VAE(nn.Module):\n",
- " def __init__(self, latent_dim=100):\n",
- " super(DB_VAE, self).__init__()\n",
- " self.latent_dim = latent_dim\n",
- "\n",
- " # Define the number of outputs for the encoder.\n",
- " self.encoder = make_standard_classifier(n_outputs=2 * latent_dim + 1)\n",
- " self.decoder = make_face_decoder_network()\n",
- "\n",
- " # function to feed images into encoder, encode the latent space, and output\n",
- " def encode(self, x):\n",
- " encoder_output = self.encoder(x)\n",
- "\n",
- " # classification prediction\n",
- " y_logit = encoder_output[:, 0].unsqueeze(-1)\n",
- " # latent variable distribution parameters\n",
- " z_mean = encoder_output[:, 1 : self.latent_dim + 1]\n",
- " z_logsigma = encoder_output[:, self.latent_dim + 1 :]\n",
- "\n",
- " return y_logit, z_mean, z_logsigma\n",
- "\n",
- " # VAE reparameterization: given a mean and logsigma, sample latent variables\n",
- " def reparameterize(self, z_mean, z_logsigma):\n",
- " # TODO: call the sampling function defined above\n",
- " z = sampling(z_mean, z_logsigma)\n",
- " # z = # TODO\n",
- " return z\n",
- "\n",
- " # Decode the latent space and output reconstruction\n",
- " def decode(self, z):\n",
- " # TODO: use the decoder to output the reconstruction\n",
- " reconstruction = self.decoder(z)\n",
- " # reconstruction = # TODO\n",
- " return reconstruction\n",
- "\n",
- " # The forward function will be used to pass inputs x through the core VAE\n",
- " def forward(self, x):\n",
- " # Encode input to a prediction and latent space\n",
- " y_logit, z_mean, z_logsigma = self.encode(x)\n",
- "\n",
- " # TODO: reparameterization\n",
- " z = self.reparameterize(z_mean, z_logsigma)\n",
- " # z = # TODO\n",
- "\n",
- " # TODO: reconstruction\n",
- " recon = self.decode(z)\n",
- " # recon = # TODO\n",
- "\n",
- " return y_logit, z_mean, z_logsigma, recon\n",
- "\n",
- " # Predict face or not face logit for given input x\n",
- " def predict(self, x):\n",
- " y_logit, z_mean, z_logsigma = self.encode(x)\n",
- " return y_logit\n",
- "\n",
- "dbvae = DB_VAE(latent_dim)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "M-clbYAj2waY"
- },
- "source": [
- "As stated, the encoder architecture is identical to the CNN from earlier in this lab. Note the outputs of our constructed DB_VAE model in the `forward` function: `y_logit, z_mean, z_logsigma, z`. Think carefully about why each of these are outputted and their significance to the problem at hand.\n",
- "\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "nbDNlslgQc5A"
- },
- "source": [
- "### Adaptive resampling for automated debiasing with DB-VAE\n",
- "\n",
- "So, how can we actually use DB-VAE to train a debiased facial detection classifier?\n",
- "\n",
- "Recall the DB-VAE architecture: as input images are fed through the network, the encoder learns an estimate ${Q}(z|X)$ of the latent space. We want to increase the relative frequency of rare data by increased sampling of under-represented regions of the latent space. We can approximate ${Q}(z|X)$ using the frequency distributions of each of the learned latent variables, and then define the probability distribution of selecting a given datapoint $x$ based on this approximation. These probability distributions will be used during training to re-sample the data.\n",
- "\n",
- "You'll write a function to execute this update of the sampling probabilities, and then call this function within the DB-VAE training loop to actually debias the model."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Fej5FDu37cf7"
- },
- "source": [
- "First, we've defined a short helper function `get_latent_mu` that returns the latent variable means returned by the encoder after a batch of images is inputted to the network:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "ewWbf7TE7wVc"
- },
- "outputs": [],
- "source": [
- "# Function to return the means for an input image batch\n",
- "\n",
- "def get_latent_mu(images, dbvae, batch_size=64):\n",
- " dbvae.eval()\n",
- " all_z_mean = []\n",
- "\n",
- " # If images is NumPy, convert once outside the loop\n",
- " images_t = torch.from_numpy(images).float()\n",
- "\n",
- " with torch.inference_mode():\n",
- " for start in range(0, len(images_t), batch_size):\n",
- " end = start + batch_size\n",
- " batch = images_t[start:end]\n",
- " batch = batch.to(device).permute(0, 3, 1, 2)\n",
- " # Forward pass on this chunk only\n",
- " _, z_mean, _, _ = dbvae(batch)\n",
- " all_z_mean.append(z_mean.cpu())\n",
- "\n",
- " # Concatenate all partial z_mean\n",
- " z_mean_full = torch.cat(all_z_mean, dim=0) # shape [N, latent_dim]\n",
- " mu = z_mean_full.numpy() # convert to NumPy if needed\n",
- " return mu"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "wn4yK3SC72bo"
- },
- "source": [
- "Now, let's define the actual resampling algorithm `get_training_sample_probabilities`. Importantly note the argument `smoothing_fac`. This parameter tunes the degree of debiasing: for `smoothing_fac=0`, the re-sampled training set will tend towards falling uniformly over the latent space, i.e., the most extreme debiasing."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "HiX9pmmC7_wn"
- },
- "outputs": [],
- "source": [
- "### Resampling algorithm for DB-VAE ###\n",
- "\n",
- "\"\"\"Function that recomputes the sampling probabilities for images within a batch\n",
- " based on how they distribute across the training data\"\"\"\n",
- "def get_training_sample_probabilities(images, dbvae, bins=10, smoothing_fac=0.001):\n",
- " print(\"Recomputing the sampling probabilities\")\n",
- "\n",
- " # TODO: run the input batch and get the latent variable means\n",
- " mu = get_latent_mu(images, dbvae)\n",
- " # mu = get_latent_mu('''TODO''', '''TODO''') # TODO\n",
- "\n",
- " # sampling probabilities for the images\n",
- " training_sample_p = np.zeros(mu.shape[0], dtype=np.float64)\n",
- "\n",
- " # consider the distribution for each latent variable\n",
- " for i in range(latent_dim):\n",
- " latent_distribution = mu[:, i]\n",
- " # generate a histogram of the latent distribution\n",
- " hist_density, bin_edges = np.histogram(\n",
- " latent_distribution, density=True, bins=bins\n",
- " )\n",
- "\n",
- " # find which latent bin every data sample falls in\n",
- " bin_edges[0] = -float(\"inf\")\n",
- " bin_edges[-1] = float(\"inf\")\n",
- "\n",
- " # TODO: call the digitize function to find which bins in the latent distribution\n",
- " # every data sample falls in to\n",
- " # https://docs.scipy.org/doc/numpy-1.13.0/reference/generated/numpy.digitize.html\n",
- " bin_idx = np.digitize(latent_distribution, bin_edges)\n",
- " # bin_idx = np.digitize('''TODO''', '''TODO''') # TODO\n",
- "\n",
- " # smooth the density function\n",
- " hist_smoothed_density = hist_density + smoothing_fac\n",
- " hist_smoothed_density = hist_smoothed_density / np.sum(hist_smoothed_density)\n",
- "\n",
- " # invert the density function\n",
- " p = 1.0 / (hist_smoothed_density[bin_idx - 1])\n",
- "\n",
- " # TODO: normalize all probabilities\n",
- " p = p / np.sum(p)\n",
- " # p = # TODO\n",
- "\n",
- " # TODO: update sampling probabilities by considering whether the newly\n",
- " # computed p is greater than the existing sampling probabilities.\n",
- " training_sample_p = np.maximum(training_sample_p, p)\n",
- " # training_sample_p = # TODO\n",
- "\n",
- " # final normalization\n",
- " training_sample_p /= np.sum(training_sample_p)\n",
- "\n",
- " return training_sample_p"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "pF14fQkVUs-a"
- },
- "source": [
- "Now that we've defined the resampling update, we can train our DB-VAE model on the CelebA/ImageNet training data, and run the above operation to re-weight the importance of particular data points as we train the model. Remember again that we only want to debias for features relevant to *faces*, not the set of negative examples. Complete the code block below to execute the training loop!"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "xwQs-Gu5bKEK"
- },
- "outputs": [],
- "source": [
- "### Training the DB-VAE ###\n",
- "\n",
- "# Hyperparameters\n",
- "params = dict(\n",
- " batch_size=32,\n",
- " learning_rate=5e-4,\n",
- " latent_dim=100,\n",
- " num_epochs=2, # DB-VAE needs slightly more epochs to train\n",
- ")\n",
- "\n",
- "experiment = create_experiment(\"6S191_Lab2_Part2_DBVAE\", params)\n",
- "\n",
- "# instantiate a new DB-VAE model and optimizer\n",
- "dbvae = DB_VAE(params[\"latent_dim\"]).to(device)\n",
- "optimizer = optim.Adam(dbvae.parameters(), lr=params[\"learning_rate\"])\n",
- "\n",
- "\n",
- "def debiasing_train_step(x, y):\n",
- " optimizer.zero_grad()\n",
- "\n",
- " y_logit, z_mean, z_logsigma, x_recon = dbvae(x)\n",
- "\n",
- " '''TODO: call the DB_VAE loss function to compute the loss'''\n",
- " loss, class_loss = debiasing_loss_function(\n",
- " x, x_recon, y, y_logit, z_mean, z_logsigma\n",
- " )\n",
- " # loss, class_loss = debiasing_loss_function('''TODO arguments''') # TODO\n",
- "\n",
- " loss.backward()\n",
- " optimizer.step()\n",
- "\n",
- " return loss\n",
- "\n",
- "\n",
- "# get training faces from data loader\n",
- "all_faces = loader.get_all_train_faces()\n",
- "\n",
- "# The training loop -- outer loop iterates over the number of epochs\n",
- "step = 0\n",
- "for i in range(params[\"num_epochs\"]):\n",
- " IPython.display.clear_output(wait=True)\n",
- " print(\"Starting epoch {}/{}\".format(i + 1, params[\"num_epochs\"]))\n",
- "\n",
- " # Recompute data sampling proabilities\n",
- " \"\"\"TODO: recompute the sampling probabilities for debiasing\"\"\"\n",
- " p_faces = get_training_sample_probabilities(all_faces, dbvae)\n",
- " # p_faces = get_training_sample_probabilities('''TODO''', '''TODO''') # TODO\n",
- "\n",
- " # get a batch of training data and compute the training step\n",
- " for j in tqdm(range(loader.get_train_size() // params[\"batch_size\"])):\n",
- " # load a batch of data\n",
- " (x, y) = loader.get_batch(params[\"batch_size\"], p_pos=p_faces)\n",
- " x = torch.from_numpy(x).float().to(device)\n",
- " y = torch.from_numpy(y).float().to(device)\n",
- "\n",
- " # loss optimization\n",
- " loss = debiasing_train_step(x, y)\n",
- " loss_value = loss.detach().cpu().numpy()\n",
- " experiment.log_metric(\"loss\", loss_value, step=step)\n",
- "\n",
- " # plot the progress every 200 steps\n",
- " if j % 500 == 0:\n",
- " mdl.util.plot_sample(x, y, dbvae, backend=\"pt\")\n",
- "\n",
- " step += 1\n",
- "\n",
- "experiment.end()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "uZBlWDPOVcHg"
- },
- "source": [
- "Wonderful! Now we should have a trained and (hopefully!) debiased facial classification model, ready for evaluation!"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Eo34xC7MbaiQ"
- },
- "source": [
- "## 2.6 Evaluation of DB-VAE on Test Dataset\n",
- "\n",
- "Finally let's test our DB-VAE model on the test dataset, looking specifically at its accuracy on each the \"Dark Male\", \"Dark Female\", \"Light Male\", and \"Light Female\" demographics. We will compare the performance of this debiased model against the (potentially biased) standard CNN from earlier in the lab."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "bgK77aB9oDtX"
- },
- "outputs": [],
- "source": [
- "dbvae.to(device)\n",
- "dbvae_logits_list = []\n",
- "for face in test_faces:\n",
- " face = np.asarray(face, dtype=np.float32)\n",
- " face = torch.from_numpy(face).to(device)\n",
- "\n",
- " # Forward pass to get the classification logit\n",
- " with torch.inference_mode():\n",
- " logit = dbvae.predict(face)\n",
- "\n",
- " dbvae_logits_list.append(logit.detach().cpu().numpy())\n",
- "\n",
- "dbvae_logits_array = np.concatenate(dbvae_logits_list, axis=0)\n",
- "dbvae_logits_tensor = torch.from_numpy(dbvae_logits_array)\n",
- "dbvae_probs_tensor = torch.sigmoid(dbvae_logits_tensor)\n",
- "dbvae_probs_array = dbvae_probs_tensor.squeeze(dim=-1).numpy()\n",
- "\n",
- "xx = np.arange(len(keys))\n",
- "\n",
- "std_probs_mean = standard_classifier_probs.mean(axis=1)\n",
- "dbvae_probs_mean = dbvae_probs_array.reshape(len(keys), -1).mean(axis=1)\n",
- "\n",
- "plt.bar(xx, std_probs_mean, width=0.2, label=\"Standard CNN\")\n",
- "plt.bar(xx + 0.2, dbvae_probs_mean, width=0.2, label=\"DB-VAE\")\n",
- "\n",
- "plt.xticks(xx, keys)\n",
- "plt.title(\"Network predictions on test dataset\")\n",
- "plt.ylabel(\"Probability\")\n",
- "plt.legend(bbox_to_anchor=(1.04, 1), loc=\"upper left\")\n",
- "plt.show()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "rESoXRPQo_mq"
- },
- "source": [
- "## 2.7 Conclusion and submission information\n",
- "\n",
- "We encourage you to think about and maybe even address some questions raised by the approach and results outlined here:\n",
- "\n",
- "* How does the accuracy of the DB-VAE across the four demographics compare to that of the standard CNN? Do you find this result surprising in any way?\n",
- "* Can the performance of the DB-VAE classifier be improved even further?\n",
- "* In which applications (either related to facial detection or not!) would debiasing in this way be desired? Are there applications where you may not want to debias your model?\n",
- "* Do you think it should be necessary for companies to demonstrate that their models, particularly in the context of tasks like facial detection, are not biased? If so, do you have thoughts on how this could be standardized and implemented?\n",
- "* Do you have ideas for other ways to address issues of bias, particularly in terms of the training data?\n",
- "\n",
- "**The debiased model may or may not perform well based on the initial hyperparameters. This lab competition will be focused on your answers to the questions above, experiments you tried, and your interpretation and analysis of the results. To enter the competition, please upload the following to the lab submission site for the Debiasing Faces Lab ([submission upload link](https://www.dropbox.com/request/dJZUEoqGLB43JEKzzqIc)).**\n",
- "\n",
- "* Jupyter notebook with the code you used to generate your results;\n",
- "* copy of the bar plot from section 2.6 showing the performance of your model;\n",
- "* a written description and/or diagram of the architecture and hyperparameters you used -- if there are any additional or interesting modifications you made to the template code, please include these in your description;\n",
- "* a written discussion of why and how these modifications changed performance.\n",
- "\n",
- "**Name your file in the following format: `[FirstName]_[LastName]_Face`, followed by the file format (.zip, .ipynb, .pdf, etc).** ZIP files are preferred over individual files. If you submit individual files, you must name the individual files according to the above nomenclature (e.g., `[FirstName]_[LastName]_Face_TODO.pdf`, `[FirstName]_[LastName]_Face_Report.pdf`, etc.).\n",
- "\n",
- "Hopefully this lab has shed some light on a few concepts, from vision based tasks, to VAEs, to algorithmic bias. We like to think it has, but we're biased ;).\n",
- "\n",
- ""
- ]
- }
- ],
- "metadata": {
- "accelerator": "GPU",
- "colab": {
- "collapsed_sections": [
- "Ag_e7xtTzT1W",
- "NDj7KBaW8Asz"
- ],
- "name": "PT_Part2_Debiasing_Solution.ipynb",
- "provenance": []
- },
- "kernelspec": {
- "display_name": "Python 3",
- "name": "python3"
- },
- "language_info": {
- "codemirror_mode": {
- "name": "ipython",
- "version": 3
- },
- "file_extension": ".py",
- "mimetype": "text/x-python",
- "name": "python",
- "nbconvert_exporter": "python",
- "pygments_lexer": "ipython3",
- "version": "3.10.16"
- }
- },
- "nbformat": 4,
- "nbformat_minor": 0
-}
diff --git a/lab2/solutions/TF_Part1_MNIST_Solution.ipynb b/lab2/solutions/TF_Part1_MNIST_Solution.ipynb
deleted file mode 100644
index c2ae8377..00000000
--- a/lab2/solutions/TF_Part1_MNIST_Solution.ipynb
+++ /dev/null
@@ -1,789 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Xmf_JRJa_N8C"
- },
- "source": [
- "\n",
- "\n",
- "# Copyright Information"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "gKA_J7bdP33T"
- },
- "outputs": [],
- "source": [
- "# Copyright 2025 MIT Introduction to Deep Learning. All Rights Reserved.\n",
- "#\n",
- "# Licensed under the MIT License. You may not use this file except in compliance\n",
- "# with the License. Use and/or modification of this code outside of MIT Introduction\n",
- "# to Deep Learning must reference:\n",
- "#\n",
- "# © MIT Introduction to Deep Learning\n",
- "# http://introtodeeplearning.com\n",
- "#"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Cm1XpLftPi4A"
- },
- "source": [
- "# Laboratory 2: Computer Vision\n",
- "\n",
- "# Part 1: MNIST Digit Classification\n",
- "\n",
- "In the first portion of this lab, we will build and train a convolutional neural network (CNN) for classification of handwritten digits from the famous [MNIST](http://yann.lecun.com/exdb/mnist/) dataset. The MNIST dataset consists of 60,000 training images and 10,000 test images. Our classes are the digits 0-9.\n",
- "\n",
- "First, let's download the course repository, install dependencies, and import the relevant packages we'll need for this lab."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "RsGqx_ai_N8F"
- },
- "outputs": [],
- "source": [
- "# Import Tensorflow 2.0\n",
- "# !pip install tensorflow\n",
- "import tensorflow as tf\n",
- "\n",
- "# MIT introduction to deep learning package\n",
- "!pip install mitdeeplearning --quiet\n",
- "import mitdeeplearning as mdl\n",
- "\n",
- "# other packages\n",
- "import matplotlib.pyplot as plt\n",
- "import numpy as np\n",
- "import random\n",
- "from tqdm import tqdm"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "nCpHDxX1bzyZ"
- },
- "source": [
- "We'll also install Comet. If you followed the instructions from Lab 1, you should have your Comet account set up. Enter your API key below."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "GSR_PAqjbzyZ"
- },
- "outputs": [],
- "source": [
- "!pip install comet_ml > /dev/null 2>&1\n",
- "import comet_ml\n",
- "# TODO: ENTER YOUR API KEY HERE!!\n",
- "COMET_API_KEY = \"\"\n",
- "\n",
- "# Check that we are using a GPU, if not switch runtimes\n",
- "# using Runtime > Change Runtime Type > GPU\n",
- "assert len(tf.config.list_physical_devices('GPU')) > 0\n",
- "assert COMET_API_KEY != \"\", \"Please insert your Comet API Key\""
- ]
- },
- {
- "cell_type": "code",
- "source": [
- "# start a first comet experiment for the first part of the lab\n",
- "comet_ml.init(project_name=\"6S191_lab2_part1_NN\")\n",
- "comet_model_1 = comet_ml.Experiment()"
- ],
- "metadata": {
- "id": "wGPDtVxvTtPk"
- },
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "HKjrdUtX_N8J"
- },
- "source": [
- "## 1.1 MNIST dataset\n",
- "\n",
- "Let's download and load the dataset and display a few random samples from it:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "p2dQsHI3_N8K"
- },
- "outputs": [],
- "source": [
- "mnist = tf.keras.datasets.mnist\n",
- "(train_images, train_labels), (test_images, test_labels) = mnist.load_data()\n",
- "train_images = (np.expand_dims(train_images, axis=-1)/255.).astype(np.float32)\n",
- "train_labels = (train_labels).astype(np.int64)\n",
- "test_images = (np.expand_dims(test_images, axis=-1)/255.).astype(np.float32)\n",
- "test_labels = (test_labels).astype(np.int64)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "5ZtUqOqePsRD"
- },
- "source": [
- "Our training set is made up of 28x28 grayscale images of handwritten digits.\n",
- "\n",
- "Let's visualize what some of these images and their corresponding training labels look like."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "bDBsR2lP_N8O",
- "scrolled": true
- },
- "outputs": [],
- "source": [
- "plt.figure(figsize=(10,10))\n",
- "random_inds = np.random.choice(60000,36)\n",
- "for i in range(36):\n",
- " plt.subplot(6,6,i+1)\n",
- " plt.xticks([])\n",
- " plt.yticks([])\n",
- " plt.grid(False)\n",
- " image_ind = random_inds[i]\n",
- " plt.imshow(np.squeeze(train_images[image_ind]), cmap=plt.cm.binary)\n",
- " plt.xlabel(train_labels[image_ind])\n",
- "comet_model_1.log_figure(figure=plt)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "V6hd3Nt1_N8q"
- },
- "source": [
- "## 1.2 Neural Network for Handwritten Digit Classification\n",
- "\n",
- "We'll first build a simple neural network consisting of two fully connected layers and apply this to the digit classification task. Our network will ultimately output a probability distribution over the 10 digit classes (0-9). This first architecture we will be building is depicted below:\n",
- "\n",
- "\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "rphS2rMIymyZ"
- },
- "source": [
- "### Fully connected neural network architecture\n",
- "To define the architecture of this first fully connected neural network, we'll once again use the Keras API and define the model using the [`Sequential`](https://www.tensorflow.org/api_docs/python/tf/keras/models/Sequential) class. Note how we first use a [`Flatten`](https://www.tensorflow.org/api_docs/python/tf/keras/layers/Flatten) layer, which flattens the input so that it can be fed into the model.\n",
- "\n",
- "In this next block, you'll define the fully connected layers of this simple work."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "MMZsbjAkDKpU"
- },
- "outputs": [],
- "source": [
- "def build_fc_model():\n",
- " fc_model = tf.keras.Sequential([\n",
- " # First define a Flatten layer\n",
- " tf.keras.layers.Flatten(),\n",
- "\n",
- " # '''TODO: Define the activation function for the first fully connected (Dense) layer.'''\n",
- " tf.keras.layers.Dense(128, activation=tf.nn.relu),\n",
- " # tf.keras.layers.Dense(128, activation= '''TODO'''),\n",
- "\n",
- " # '''TODO: Define the second Dense layer to output the classification probabilities'''\n",
- " tf.keras.layers.Dense(10, activation=tf.nn.softmax)\n",
- " # [TODO Dense layer to output classification probabilities]\n",
- "\n",
- " ])\n",
- " return fc_model\n",
- "\n",
- "model = build_fc_model()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "VtGZpHVKz5Jt"
- },
- "source": [
- "As we progress through this next portion, you may find that you'll want to make changes to the architecture defined above. **Note that in order to update the model later on, you'll need to re-run the above cell to re-initialize the model.**"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "mVN1_AeG_N9N"
- },
- "source": [
- "Let's take a step back and think about the network we've just created. The first layer in this network, `tf.keras.layers.Flatten`, transforms the format of the images from a 2d-array (28 x 28 pixels), to a 1d-array of 28 * 28 = 784 pixels. You can think of this layer as unstacking rows of pixels in the image and lining them up. There are no learned parameters in this layer; it only reformats the data.\n",
- "\n",
- "After the pixels are flattened, the network consists of a sequence of two `tf.keras.layers.Dense` layers. These are fully-connected neural layers. The first `Dense` layer has 128 nodes (or neurons). The second (and last) layer (which you've defined!) should return an array of probability scores that sum to 1. Each node contains a score that indicates the probability that the current image belongs to one of the handwritten digit classes.\n",
- "\n",
- "That defines our fully connected model!"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "gut8A_7rCaW6"
- },
- "source": [
- "\n",
- "\n",
- "### Compile the model\n",
- "\n",
- "Before training the model, we need to define a few more settings. These are added during the model's [`compile`](https://www.tensorflow.org/api_docs/python/tf/keras/models/Sequential#compile) step:\n",
- "\n",
- "* *Loss function* — This defines how we measure how accurate the model is during training. As was covered in lecture, during training we want to minimize this function, which will \"steer\" the model in the right direction.\n",
- "* *Optimizer* — This defines how the model is updated based on the data it sees and its loss function.\n",
- "* *Metrics* — Here we can define metrics used to monitor the training and testing steps. In this example, we'll look at the *accuracy*, the fraction of the images that are correctly classified.\n",
- "\n",
- "We'll start out by using a stochastic gradient descent (SGD) optimizer initialized with a learning rate of 0.1. Since we are performing a categorical classification task, we'll want to use the [cross entropy loss](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/sparse_categorical_crossentropy).\n",
- "\n",
- "You'll want to experiment with both the choice of optimizer and learning rate and evaluate how these affect the accuracy of the trained model."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "Lhan11blCaW7"
- },
- "outputs": [],
- "source": [
- "'''TODO: Experiment with different optimizers and learning rates. How do these affect\n",
- " the accuracy of the trained model? Which optimizers and/or learning rates yield\n",
- " the best performance?'''\n",
- "model.compile(optimizer=tf.keras.optimizers.SGD(learning_rate=1e-1),\n",
- " loss='sparse_categorical_crossentropy',\n",
- " metrics=['accuracy'])"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "qKF6uW-BCaW-"
- },
- "source": [
- "### Train the model\n",
- "\n",
- "We're now ready to train our model, which will involve feeding the training data (`train_images` and `train_labels`) into the model, and then asking it to learn the associations between images and labels. We'll also need to define the batch size and the number of epochs, or iterations over the MNIST dataset, to use during training.\n",
- "\n",
- "In Lab 1, we saw how we can use `GradientTape` to optimize losses and train models with stochastic gradient descent. After defining the model settings in the `compile` step, we can also accomplish training by calling the [`fit`](https://www.tensorflow.org/api_docs/python/tf/keras/models/Sequential#fit) method on an instance of the `Model` class. We will use this to train our fully connected model\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "EFMbIqIvQ2X0"
- },
- "outputs": [],
- "source": [
- "# Define the batch size and the number of epochs to use during training\n",
- "BATCH_SIZE = 64\n",
- "EPOCHS = 5\n",
- "\n",
- "model.fit(train_images, train_labels, batch_size=BATCH_SIZE, epochs=EPOCHS)\n",
- "comet_model_1.end()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "W3ZVOhugCaXA"
- },
- "source": [
- "As the model trains, the loss and accuracy metrics are displayed. With five epochs and a learning rate of 0.01, this fully connected model should achieve an accuracy of approximatley 0.97 (or 97%) on the training data."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "oEw4bZgGCaXB"
- },
- "source": [
- "### Evaluate accuracy on the test dataset\n",
- "\n",
- "Now that we've trained the model, we can ask it to make predictions about a test set that it hasn't seen before. In this example, the `test_images` array comprises our test dataset. To evaluate accuracy, we can check to see if the model's predictions match the labels from the `test_labels` array.\n",
- "\n",
- "Use the [`evaluate`](https://www.tensorflow.org/api_docs/python/tf/keras/models/Sequential#evaluate) method to evaluate the model on the test dataset!"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "VflXLEeECaXC"
- },
- "outputs": [],
- "source": [
- "'''TODO: Use the evaluate method to test the model!'''\n",
- "test_loss, test_acc = model.evaluate(test_images, test_labels) # TODO\n",
- "# test_loss, test_acc = # TODO\n",
- "\n",
- "print('Test accuracy:', test_acc)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "yWfgsmVXCaXG"
- },
- "source": [
- "You may observe that the accuracy on the test dataset is a little lower than the accuracy on the training dataset. This gap between training accuracy and test accuracy is an example of *overfitting*, when a machine learning model performs worse on new data than on its training data.\n",
- "\n",
- "What is the highest accuracy you can achieve with this first fully connected model? Since the handwritten digit classification task is pretty straightforward, you may be wondering how we can do better...\n",
- "\n",
- ""
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "baIw9bDf8v6Z"
- },
- "source": [
- "## 1.3 Convolutional Neural Network (CNN) for handwritten digit classification"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "_J72Yt1o_fY7"
- },
- "source": [
- "As we saw in lecture, convolutional neural networks (CNNs) are particularly well-suited for a variety of tasks in computer vision, and have achieved near-perfect accuracies on the MNIST dataset. We will now build a CNN composed of two convolutional layers and pooling layers, followed by two fully connected layers, and ultimately output a probability distribution over the 10 digit classes (0-9). The CNN we will be building is depicted below:\n",
- "\n",
- ""
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "EEHqzbJJAEoR"
- },
- "source": [
- "### Define the CNN model\n",
- "\n",
- "We'll use the same training and test datasets as before, and proceed similarly as our fully connected network to define and train our new CNN model. To do this we will explore two layers we have not encountered before: you can use [`keras.layers.Conv2D` ](https://www.tensorflow.org/api_docs/python/tf/keras/layers/Conv2D) to define convolutional layers and [`keras.layers.MaxPool2D`](https://www.tensorflow.org/api_docs/python/tf/keras/layers/MaxPool2D) to define the pooling layers. Use the parameters shown in the network architecture above to define these layers and build the CNN model."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "vec9qcJs-9W5"
- },
- "outputs": [],
- "source": [
- "def build_cnn_model():\n",
- " cnn_model = tf.keras.Sequential([\n",
- "\n",
- " # TODO: Define the first convolutional layer\n",
- " tf.keras.layers.Conv2D(filters=24, kernel_size=(3,3), activation=tf.nn.relu),\n",
- " # tf.keras.layers.Conv2D('''TODO''')\n",
- "\n",
- " # TODO: Define the first max pooling layer\n",
- " tf.keras.layers.MaxPool2D(pool_size=(2,2)),\n",
- " # tf.keras.layers.MaxPool2D('''TODO''')\n",
- "\n",
- " # TODO: Define the second convolutional layer\n",
- " tf.keras.layers.Conv2D(filters=36, kernel_size=(3,3), activation=tf.nn.relu),\n",
- " # tf.keras.layers.Conv2D('''TODO''')\n",
- "\n",
- " # TODO: Define the second max pooling layer\n",
- " tf.keras.layers.MaxPool2D(pool_size=(2,2)),\n",
- " # tf.keras.layers.MaxPool2D('''TODO''')\n",
- "\n",
- " tf.keras.layers.Flatten(),\n",
- " tf.keras.layers.Dense(128, activation=tf.nn.relu),\n",
- "\n",
- " # TODO: Define the last Dense layer to output the classification\n",
- " # probabilities. Pay attention to the activation needed a probability\n",
- " # output\n",
- " tf.keras.layers.Dense(10, activation=tf.nn.softmax)\n",
- " # [TODO Dense layer to output classification probabilities]\n",
- " ])\n",
- "\n",
- " return cnn_model\n",
- "\n",
- "cnn_model = build_cnn_model()\n",
- "# Initialize the model by passing some data through\n",
- "cnn_model.predict(train_images[[0]])\n",
- "# Print the summary of the layers in the model.\n",
- "print(cnn_model.summary())"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "kUAXIBynCih2"
- },
- "source": [
- "### Train and test the CNN model\n",
- "\n",
- "Now, as before, we can define the loss function, optimizer, and metrics through the `compile` method. Compile the CNN model with an optimizer and learning rate of choice:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "vheyanDkCg6a"
- },
- "outputs": [],
- "source": [
- "comet_ml.init(project_name=\"6.s191lab2_part1_CNN\")\n",
- "comet_model_2 = comet_ml.Experiment()\n",
- "\n",
- "'''TODO: Define the compile operation with your optimizer and learning rate of choice'''\n",
- "cnn_model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=1e-3),\n",
- " loss='sparse_categorical_crossentropy',\n",
- " metrics=['accuracy'])\n",
- "# cnn_model.compile(optimizer='''TODO''', loss='''TODO''', metrics=['accuracy']) # TODO"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "U19bpRddC7H_"
- },
- "source": [
- "As was the case with the fully connected model, we can train our CNN using the `fit` method via the Keras API."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "YdrGZVmWDK4p"
- },
- "outputs": [],
- "source": [
- "'''TODO: Use model.fit to train the CNN model, with the same batch_size and number of epochs previously used.'''\n",
- "cnn_model.fit(train_images, train_labels, batch_size=BATCH_SIZE, epochs=EPOCHS)\n",
- "# cnn_model.fit('''TODO''')\n",
- "# comet_model_2.end()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "pEszYWzgDeIc"
- },
- "source": [
- "Great! Now that we've trained the model, let's evaluate it on the test dataset using the [`evaluate`](https://www.tensorflow.org/api_docs/python/tf/keras/models/Sequential#evaluate) method:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "JDm4znZcDtNl"
- },
- "outputs": [],
- "source": [
- "'''TODO: Use the evaluate method to test the model!'''\n",
- "test_loss, test_acc = cnn_model.evaluate(test_images, test_labels)\n",
- "# test_loss, test_acc = # TODO\n",
- "\n",
- "print('Test accuracy:', test_acc)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "2rvEgK82Glv9"
- },
- "source": [
- "What is the highest accuracy you're able to achieve using the CNN model, and how does the accuracy of the CNN model compare to the accuracy of the simple fully connected network? What optimizers and learning rates seem to be optimal for training the CNN model?\n",
- "\n",
- "Feel free to click the Comet links to investigate the training/accuracy curves for your model."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "xsoS7CPDCaXH"
- },
- "source": [
- "### Make predictions with the CNN model\n",
- "\n",
- "With the model trained, we can use it to make predictions about some images. The [`predict`](https://www.tensorflow.org/api_docs/python/tf/keras/models/Sequential#predict) function call generates the output predictions given a set of input samples.\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "Gl91RPhdCaXI"
- },
- "outputs": [],
- "source": [
- "predictions = cnn_model.predict(test_images)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "x9Kk1voUCaXJ"
- },
- "source": [
- "With this function call, the model has predicted the label for each image in the testing set. Let's take a look at the prediction for the first image in the test dataset:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "3DmJEUinCaXK"
- },
- "outputs": [],
- "source": [
- "predictions[0]"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "-hw1hgeSCaXN"
- },
- "source": [
- "As you can see, a prediction is an array of 10 numbers. Recall that the output of our model is a probability distribution over the 10 digit classes. Thus, these numbers describe the model's \"confidence\" that the image corresponds to each of the 10 different digits.\n",
- "\n",
- "Let's look at the digit that has the highest confidence for the first image in the test dataset:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "qsqenuPnCaXO"
- },
- "outputs": [],
- "source": [
- "'''TODO: identify the digit with the highest confidence prediction for the first\n",
- " image in the test dataset. '''\n",
- "prediction = np.argmax(predictions[0])\n",
- "# prediction = # TODO\n",
- "\n",
- "print(prediction)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "E51yS7iCCaXO"
- },
- "source": [
- "So, the model is most confident that this image is a \"???\". We can check the test label (remember, this is the true identity of the digit) to see if this prediction is correct:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "Sd7Pgsu6CaXP"
- },
- "outputs": [],
- "source": [
- "print(\"Label of this digit is:\", test_labels[0])\n",
- "plt.imshow(test_images[0,:,:,0], cmap=plt.cm.binary)\n",
- "comet_model_2.log_figure(figure=plt)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "ygh2yYC972ne"
- },
- "source": [
- "It is! Let's visualize the classification results on the MNIST dataset. We will plot images from the test dataset along with their predicted label, as well as a histogram that provides the prediction probabilities for each of the digits:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "HV5jw-5HwSmO"
- },
- "outputs": [],
- "source": [
- "#@title Change the slider to look at the model's predictions! { run: \"auto\" }\n",
- "\n",
- "image_index = 79 #@param {type:\"slider\", min:0, max:100, step:1}\n",
- "plt.subplot(1,2,1)\n",
- "mdl.lab2.plot_image_prediction(image_index, predictions, test_labels, test_images)\n",
- "plt.subplot(1,2,2)\n",
- "mdl.lab2.plot_value_prediction(image_index, predictions, test_labels)\n",
- "comet_model_2.log_figure(figure=plt)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "kgdvGD52CaXR"
- },
- "source": [
- "We can also plot several images along with their predictions, where correct prediction labels are blue and incorrect prediction labels are grey. The number gives the percent confidence (out of 100) for the predicted label. Note the model can be very confident in an incorrect prediction!"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "hQlnbqaw2Qu_"
- },
- "outputs": [],
- "source": [
- "# Plots the first X test images, their predicted label, and the true label\n",
- "# Color correct predictions in blue, incorrect predictions in red\n",
- "num_rows = 5\n",
- "num_cols = 4\n",
- "num_images = num_rows*num_cols\n",
- "plt.figure(figsize=(2*2*num_cols, 2*num_rows))\n",
- "for i in range(num_images):\n",
- " plt.subplot(num_rows, 2*num_cols, 2*i+1)\n",
- " mdl.lab2.plot_image_prediction(i, predictions, test_labels, test_images)\n",
- " plt.subplot(num_rows, 2*num_cols, 2*i+2)\n",
- " mdl.lab2.plot_value_prediction(i, predictions, test_labels)\n",
- "comet_model_2.log_figure(figure=plt)\n",
- "comet_model_2.end()\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "k-2glsRiMdqa"
- },
- "source": [
- "## 1.4 Training the model 2.0\n",
- "\n",
- "Earlier in the lab, we used the [`fit`](https://www.tensorflow.org/api_docs/python/tf/keras/models/Sequential#fit) function call to train the model. This function is quite high-level and intuitive, which is really useful for simpler models. As you may be able to tell, this function abstracts away many details in the training call, and we have less control over training model, which could be useful in other contexts.\n",
- "\n",
- "As an alternative to this, we can use the [`tf.GradientTape`](https://www.tensorflow.org/api_docs/python/tf/GradientTape) class to record differentiation operations during training, and then call the [`tf.GradientTape.gradient`](https://www.tensorflow.org/api_docs/python/tf/GradientTape#gradient) function to actually compute the gradients. You may recall seeing this in Lab 1 Part 1, but let's take another look at this here.\n",
- "\n",
- "We'll use this framework to train our `cnn_model` using stochastic gradient descent."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "Wq34id-iN1Ml"
- },
- "outputs": [],
- "source": [
- "# Rebuild the CNN model\n",
- "cnn_model = build_cnn_model()\n",
- "\n",
- "batch_size = 12\n",
- "loss_history = mdl.util.LossHistory(smoothing_factor=0.95) # to record the evolution of the loss\n",
- "plotter = mdl.util.PeriodicPlotter(sec=2, xlabel='Iterations', ylabel='Loss', scale='semilogy')\n",
- "optimizer = tf.keras.optimizers.SGD(learning_rate=1e-2) # define our optimizer\n",
- "\n",
- "comet_ml.init(project_name=\"6.s191lab2_part1_CNN2\")\n",
- "comet_model_3 = comet_ml.Experiment()\n",
- "\n",
- "if hasattr(tqdm, '_instances'): tqdm._instances.clear() # clear if it exists\n",
- "\n",
- "for idx in tqdm(range(0, train_images.shape[0], batch_size)):\n",
- " # First grab a batch of training data and convert the input images to tensors\n",
- " (images, labels) = (train_images[idx:idx+batch_size], train_labels[idx:idx+batch_size])\n",
- " images = tf.convert_to_tensor(images, dtype=tf.float32)\n",
- "\n",
- " # GradientTape to record differentiation operations\n",
- " with tf.GradientTape() as tape:\n",
- " #'''TODO: feed the images into the model and obtain the predictions'''\n",
- " logits = cnn_model(images)\n",
- " # logits = # TODO\n",
- "\n",
- " #'''TODO: compute the categorical cross entropy loss\n",
- " loss_value = tf.keras.backend.sparse_categorical_crossentropy(labels, logits)\n",
- " comet_model_3.log_metric(\"loss\", loss_value.numpy().mean(), step=idx)\n",
- " # loss_value = tf.keras.backend.sparse_categorical_crossentropy('''TODO''', '''TODO''') # TODO\n",
- "\n",
- " loss_history.append(loss_value.numpy().mean()) # append the loss to the loss_history record\n",
- " plotter.plot(loss_history.get())\n",
- "\n",
- " # Backpropagation\n",
- " '''TODO: Use the tape to compute the gradient against all parameters in the CNN model.\n",
- " Use cnn_model.trainable_variables to access these parameters.'''\n",
- " grads = tape.gradient(loss_value, cnn_model.trainable_variables)\n",
- " # grads = # TODO\n",
- " optimizer.apply_gradients(zip(grads, cnn_model.trainable_variables))\n",
- "\n",
- "comet_model_3.log_figure(figure=plt)\n",
- "comet_model_3.end()\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "3cNtDhVaqEdR"
- },
- "source": [
- "## 1.5 Conclusion\n",
- "In this part of the lab, you had the chance to play with different MNIST classifiers with different architectures (fully-connected layers only, CNN), and experiment with how different hyperparameters affect accuracy (learning rate, etc.). The next part of the lab explores another application of CNNs, facial detection, and some drawbacks of AI systems in real world applications, like issues of bias."
- ]
- }
- ],
- "metadata": {
- "accelerator": "GPU",
- "colab": {
- "collapsed_sections": [
- "Xmf_JRJa_N8C"
- ],
- "name": "TF_Part1_MNIST_Solution.ipynb",
- "provenance": []
- },
- "kernelspec": {
- "display_name": "Python 3",
- "name": "python3"
- },
- "language_info": {
- "codemirror_mode": {
- "name": "ipython",
- "version": 3
- },
- "file_extension": ".py",
- "mimetype": "text/x-python",
- "name": "python",
- "nbconvert_exporter": "python",
- "pygments_lexer": "ipython3",
- "version": "3.9.6"
- }
- },
- "nbformat": 4,
- "nbformat_minor": 0
-}
diff --git a/lab2/solutions/TF_Part2_Debiasing_Solution.ipynb b/lab2/solutions/TF_Part2_Debiasing_Solution.ipynb
deleted file mode 100644
index d6ccba60..00000000
--- a/lab2/solutions/TF_Part2_Debiasing_Solution.ipynb
+++ /dev/null
@@ -1,1166 +0,0 @@
-{
- "nbformat": 4,
- "nbformat_minor": 0,
- "metadata": {
- "colab": {
- "name": "TF_Part2_Debiasing_Solution.ipynb",
- "provenance": [],
- "collapsed_sections": [
- "Ag_e7xtTzT1W",
- "NDj7KBaW8Asz"
- ]
- },
- "kernelspec": {
- "name": "python3",
- "display_name": "Python 3"
- },
- "accelerator": "GPU"
- },
- "cells": [
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Ag_e7xtTzT1W"
- },
- "source": [
- "\n",
- "\n",
- "# Copyright Information"
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "rNbf1pRlSDby"
- },
- "source": [
- "# Copyright 2025 MIT 6.S191 Introduction to Deep Learning. All Rights Reserved.\n",
- "#\n",
- "# Licensed under the MIT License. You may not use this file except in compliance\n",
- "# with the License. Use and/or modification of this code outside of 6.S191 must\n",
- "# reference:\n",
- "#\n",
- "# © MIT 6.S191: Introduction to Deep Learning\n",
- "# http://introtodeeplearning.com\n",
- "#"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "QOpPUH3FR179"
- },
- "source": [
- "# Laboratory 2: Computer Vision\n",
- "\n",
- "# Part 2: Debiasing Facial Detection Systems\n",
- "\n",
- "In the second portion of the lab, we'll explore two prominent aspects of applied deep learning: facial detection and algorithmic bias.\n",
- "\n",
- "Deploying fair, unbiased AI systems is critical to their long-term acceptance. Consider the task of facial detection: given an image, is it an image of a face? This seemingly simple, but extremely important, task is subject to significant amounts of algorithmic bias among select demographics.\n",
- "\n",
- "In this lab, we'll investigate [one recently published approach](http://introtodeeplearning.com/AAAI_MitigatingAlgorithmicBias.pdf) to addressing algorithmic bias. We'll build a facial detection model that learns the *latent variables* underlying face image datasets and uses this to adaptively re-sample the training data, thus mitigating any biases that may be present in order to train a *debiased* model.\n",
- "\n",
- "\n",
- "Run the next code block for a short video from Google that explores how and why it's important to consider bias when thinking about machine learning:"
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "XQh5HZfbupFF"
- },
- "source": [
- "import IPython\n",
- "IPython.display.YouTubeVideo('59bMh59JQDo')"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "3Ezfc6Yv6IhI"
- },
- "source": [
- "Let's get started by installing the relevant dependencies.\n",
- "\n",
- "We will be using Comet ML to track our model development and training runs.\n",
- "\n",
- "1. Sign up for a Comet account: [HERE](https://www.comet.com/signup?utm_source=mit_dl&utm_medium=partner&utm_content=github)\n",
- "2. This will generate a personal API Key, which you can find either in the first 'Get Started with Comet' page, under your account settings, or by pressing the '?' in the top right corner and then 'Quickstart Guide'. Enter this API key as the global variable `COMET_API_KEY` below.\n",
- "\n"
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "E46sWVKK6LP9"
- },
- "source": [
- "!pip install comet_ml --quiet\n",
- "import comet_ml\n",
- "# TODO: ENTER YOUR API KEY HERE!! instructions above\n",
- "COMET_API_KEY = \"\"\n",
- "\n",
- "# Import Tensorflow 2.0\n",
- "import tensorflow as tf\n",
- "\n",
- "import IPython\n",
- "import functools\n",
- "import matplotlib.pyplot as plt\n",
- "import numpy as np\n",
- "from tqdm import tqdm\n",
- "\n",
- "# Download and import the MIT 6.S191 package\n",
- "!pip install mitdeeplearning --quiet\n",
- "import mitdeeplearning as mdl\n",
- "\n",
- "# Check that we are using a GPU, if not switch runtimes\n",
- "# using Runtime > Change Runtime Type > GPU\n",
- "assert len(tf.config.list_physical_devices('GPU')) > 0\n",
- "assert COMET_API_KEY != \"\", \"Please insert your Comet API Key\""
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "V0e77oOM3udR"
- },
- "source": [
- "## 2.1 Datasets\n",
- "\n",
- "We'll be using three datasets in this lab. In order to train our facial detection models, we'll need a dataset of positive examples (i.e., of faces) and a dataset of negative examples (i.e., of things that are not faces). We'll use these data to train our models to classify images as either faces or not faces. Finally, we'll need a test dataset of face images. Since we're concerned about the potential *bias* of our learned models against certain demographics, it's important that the test dataset we use has equal representation across the demographics or features of interest. In this lab, we'll consider skin tone and gender.\n",
- "\n",
- "1. **Positive training data**: [CelebA Dataset](http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html). A large-scale (over 200K images) of celebrity faces. \n",
- "2. **Negative training data**: [ImageNet](http://www.image-net.org/). Many images across many different categories. We'll take negative examples from a variety of non-human categories.\n",
- "[Fitzpatrick Scale](https://en.wikipedia.org/wiki/Fitzpatrick_scale) skin type classification system, with each image labeled as \"Lighter'' or \"Darker''.\n",
- "\n",
- "Let's begin by importing these datasets. We've written a class that does a bit of data pre-processing to import the training data in a usable format."
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "RWXaaIWy6jVw"
- },
- "source": [
- "# Get the training data: both images from CelebA and ImageNet\n",
- "path_to_training_data = tf.keras.utils.get_file('train_face.h5', 'https://www.dropbox.com/s/hlz8atheyozp1yx/train_face.h5?dl=1')\n",
- "# Instantiate a TrainingDatasetLoader using the downloaded dataset\n",
- "loader = mdl.lab2.TrainingDatasetLoader(path_to_training_data)"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "yIE321rxa_b3"
- },
- "source": [
- "We can look at the size of the training dataset and grab a batch of size 100:"
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "DjPSjZZ_bGqe"
- },
- "source": [
- "number_of_training_examples = loader.get_train_size()\n",
- "(images, labels) = loader.get_batch(100)"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "sxtkJoqF6oH1"
- },
- "source": [
- "Play around with displaying images to get a sense of what the training data actually looks like!"
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "Jg17jzwtbxDA"
- },
- "source": [
- "### Examining the CelebA training dataset ###\n",
- "\n",
- "#@title Change the sliders to look at positive and negative training examples! { run: \"auto\" }\n",
- "\n",
- "face_images = images[np.where(labels==1)[0]]\n",
- "not_face_images = images[np.where(labels==0)[0]]\n",
- "\n",
- "idx_face = 23 #@param {type:\"slider\", min:0, max:50, step:1}\n",
- "idx_not_face = 9 #@param {type:\"slider\", min:0, max:50, step:1}\n",
- "\n",
- "plt.figure(figsize=(5,5))\n",
- "plt.subplot(1, 2, 1)\n",
- "plt.imshow(face_images[idx_face])\n",
- "plt.title(\"Face\"); plt.grid(False)\n",
- "\n",
- "plt.subplot(1, 2, 2)\n",
- "plt.imshow(not_face_images[idx_not_face])\n",
- "plt.title(\"Not Face\"); plt.grid(False)"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "NDj7KBaW8Asz"
- },
- "source": [
- "### Thinking about bias\n",
- "\n",
- "Remember we'll be training our facial detection classifiers on the large, well-curated CelebA dataset (and ImageNet), and then evaluating their accuracy by testing them on an independent test dataset. Our goal is to build a model that trains on CelebA *and* achieves high classification accuracy on the the test dataset across all demographics, and to thus show that this model does not suffer from any hidden bias.\n",
- "\n",
- "What exactly do we mean when we say a classifier is biased? In order to formalize this, we'll need to think about [*latent variables*](https://en.wikipedia.org/wiki/Latent_variable), variables that define a dataset but are not strictly observed. As defined in the generative modeling lecture, we'll use the term *latent space* to refer to the probability distributions of the aforementioned latent variables. Putting these ideas together, we consider a classifier *biased* if its classification decision changes after it sees some additional latent features. This notion of bias may be helpful to keep in mind throughout the rest of the lab."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "AIFDvU4w8OIH"
- },
- "source": [
- "## 2.2 CNN for facial detection\n",
- "\n",
- "First, we'll define and train a CNN on the facial classification task, and evaluate its accuracy. Later, we'll evaluate the performance of our debiased models against this baseline CNN. The CNN model has a relatively standard architecture consisting of a series of convolutional layers with batch normalization followed by two fully connected layers to flatten the convolution output and generate a class prediction.\n",
- "\n",
- "### Define and train the CNN model\n",
- "\n",
- "Like we did in the first part of the lab, we'll define our CNN model, and then train on the CelebA and ImageNet datasets using the `tf.GradientTape` class and the `tf.GradientTape.gradient` method."
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "82EVTAAW7B_X"
- },
- "source": [
- "### Define the CNN model ###\n",
- "\n",
- "n_filters = 12 # base number of convolutional filters\n",
- "\n",
- "'''Function to define a standard CNN model'''\n",
- "def make_standard_classifier(n_outputs=1):\n",
- " Conv2D = functools.partial(tf.keras.layers.Conv2D, padding='same', activation='relu')\n",
- " BatchNormalization = tf.keras.layers.BatchNormalization\n",
- " Flatten = tf.keras.layers.Flatten\n",
- " Dense = functools.partial(tf.keras.layers.Dense, activation='relu')\n",
- "\n",
- " model = tf.keras.Sequential([\n",
- " Conv2D(filters=1*n_filters, kernel_size=5, strides=2),\n",
- " BatchNormalization(),\n",
- "\n",
- " Conv2D(filters=2*n_filters, kernel_size=5, strides=2),\n",
- " BatchNormalization(),\n",
- "\n",
- " Conv2D(filters=4*n_filters, kernel_size=3, strides=2),\n",
- " BatchNormalization(),\n",
- "\n",
- " Conv2D(filters=6*n_filters, kernel_size=3, strides=2),\n",
- " BatchNormalization(),\n",
- "\n",
- " Flatten(),\n",
- " Dense(512),\n",
- " Dense(n_outputs, activation=None),\n",
- " ])\n",
- " return model\n",
- "\n",
- "standard_classifier = make_standard_classifier()"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "c-eWf3l_lCri"
- },
- "source": [
- "Now let's train the standard CNN!"
- ]
- },
- {
- "cell_type": "code",
- "source": [
- "### Create a Comet experiment to track our training run ###\n",
- "def create_experiment(project_name, params):\n",
- " # end any prior experiments\n",
- " if 'experiment' in locals():\n",
- " experiment.end()\n",
- "\n",
- " # initiate the comet experiment for tracking\n",
- " experiment = comet_ml.Experiment(\n",
- " api_key=COMET_API_KEY,\n",
- " project_name=project_name)\n",
- " # log our hyperparameters, defined above, to the experiment\n",
- " for param, value in params.items():\n",
- " experiment.log_parameter(param, value)\n",
- " experiment.flush()\n",
- "\n",
- " return experiment\n"
- ],
- "metadata": {
- "id": "mi-04SAfK6lm"
- },
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "eJlDGh1o31G1"
- },
- "source": [
- "### Train the standard CNN ###\n",
- "\n",
- "# Training hyperparameters\n",
- "params = dict(\n",
- " batch_size = 32,\n",
- " num_epochs = 2, # keep small to run faster\n",
- " learning_rate = 5e-4,\n",
- ")\n",
- "\n",
- "experiment = create_experiment(\"6S191_Lab2_Part2_CNN\", params)\n",
- "\n",
- "optimizer = tf.keras.optimizers.Adam(params[\"learning_rate\"]) # define our optimizer\n",
- "loss_history = mdl.util.LossHistory(smoothing_factor=0.99) # to record loss evolution\n",
- "plotter = mdl.util.PeriodicPlotter(sec=2, scale='semilogy')\n",
- "if hasattr(tqdm, '_instances'): tqdm._instances.clear() # clear if it exists\n",
- "\n",
- "@tf.function\n",
- "def standard_train_step(x, y):\n",
- " with tf.GradientTape() as tape:\n",
- " # feed the images into the model\n",
- " logits = standard_classifier(x)\n",
- " # Compute the loss\n",
- " loss = tf.nn.sigmoid_cross_entropy_with_logits(labels=y, logits=logits)\n",
- "\n",
- " # Backpropagation\n",
- " grads = tape.gradient(loss, standard_classifier.trainable_variables)\n",
- " optimizer.apply_gradients(zip(grads, standard_classifier.trainable_variables))\n",
- " return loss\n",
- "\n",
- "# The training loop!\n",
- "step = 0\n",
- "for epoch in range(params[\"num_epochs\"]):\n",
- " for idx in tqdm(range(loader.get_train_size()//params[\"batch_size\"])):\n",
- " # Grab a batch of training data and propagate through the network\n",
- " x, y = loader.get_batch(params[\"batch_size\"])\n",
- " loss = standard_train_step(x, y)\n",
- "\n",
- " # Record the loss and plot the evolution of the loss as a function of training\n",
- " loss_history.append(loss.numpy().mean())\n",
- " plotter.plot(loss_history.get())\n",
- "\n",
- " experiment.log_metric(\"loss\", loss.numpy().mean(), step=step)\n",
- " step += 1"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "AKMdWVHeCxj8"
- },
- "source": [
- "### Evaluate performance of the standard CNN\n",
- "\n",
- "Next, let's evaluate the classification performance of our CelebA-trained standard CNN on the training dataset.\n"
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "35-PDgjdWk6_"
- },
- "source": [
- "### Evaluation of standard CNN ###\n",
- "\n",
- "# TRAINING DATA\n",
- "# Evaluate on a subset of CelebA+Imagenet\n",
- "(batch_x, batch_y) = loader.get_batch(5000)\n",
- "y_pred_standard = tf.round(tf.nn.sigmoid(standard_classifier.predict(batch_x)))\n",
- "acc_standard = tf.reduce_mean(tf.cast(tf.equal(batch_y, y_pred_standard), tf.float32))\n",
- "\n",
- "print(\"Standard CNN accuracy on (potentially biased) training set: {:.4f}\".format(acc_standard.numpy()))"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Qu7R14KaEEvU"
- },
- "source": [
- "We will also evaluate our networks on an independent test dataset containing faces that were not seen during training. For the test data, we'll look at the classification accuracy across four different demographics, based on the Fitzpatrick skin scale and sex-based labels: dark-skinned male, dark-skinned female, light-skinned male, and light-skinned female.\n",
- "\n",
- "Let's take a look at some sample faces in the test set."
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "vfDD8ztGWk6x"
- },
- "source": [
- "### Load test dataset and plot examples ###\n",
- "\n",
- "test_faces = mdl.lab2.get_test_faces()\n",
- "keys = [\"Light Female\", \"Light Male\", \"Dark Female\", \"Dark Male\"]\n",
- "for group, key in zip(test_faces,keys):\n",
- " plt.figure(figsize=(5,5))\n",
- " plt.imshow(np.hstack(group))\n",
- " plt.title(key, fontsize=15)"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "uo1z3cdbEUMM"
- },
- "source": [
- "Now, let's evaluate the probability of each of these face demographics being classified as a face using the standard CNN classifier we've just trained."
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "GI4O0Y1GAot9"
- },
- "source": [
- "### Evaluate the standard CNN on the test data ###\n",
- "\n",
- "standard_classifier_logits = [standard_classifier(np.array(x, dtype=np.float32)) for x in test_faces]\n",
- "standard_classifier_probs = tf.squeeze(tf.sigmoid(standard_classifier_logits))\n",
- "\n",
- "# Plot the prediction accuracies per demographic\n",
- "xx = range(len(keys))\n",
- "yy = standard_classifier_probs.numpy().mean(1)\n",
- "plt.bar(xx, yy)\n",
- "plt.xticks(xx, keys)\n",
- "plt.ylim(max(0,yy.min()-yy.ptp()/2.), yy.max()+yy.ptp()/2.)\n",
- "plt.title(\"Standard classifier predictions\");"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "j0Cvvt90DoAm"
- },
- "source": [
- "Take a look at the accuracies for this first model across these four groups. What do you observe? Would you consider this model biased or unbiased? What are some reasons why a trained model may have biased accuracies?"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "0AKcHnXVtgqJ"
- },
- "source": [
- "## 2.3 Mitigating algorithmic bias\n",
- "\n",
- "Imbalances in the training data can result in unwanted algorithmic bias. For example, the majority of faces in CelebA (our training set) are those of light-skinned females. As a result, a classifier trained on CelebA will be better suited at recognizing and classifying faces with features similar to these, and will thus be biased.\n",
- "\n",
- "How could we overcome this? A naive solution -- and one that is being adopted by many companies and organizations -- would be to annotate different subclasses (i.e., light-skinned females, males with hats, etc.) within the training data, and then manually even out the data with respect to these groups.\n",
- "\n",
- "But this approach has two major disadvantages. First, it requires annotating massive amounts of data, which is not scalable. Second, it requires that we know what potential biases (e.g., race, gender, pose, occlusion, hats, glasses, etc.) to look for in the data. As a result, manual annotation may not capture all the different features that are imbalanced within the training data.\n",
- "\n",
- "Instead, let's actually **learn** these features in an unbiased, unsupervised manner, without the need for any annotation, and then train a classifier fairly with respect to these features. In the rest of this lab, we'll do exactly that."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "nLemS7dqECsI"
- },
- "source": [
- "## 2.4 Variational autoencoder (VAE) for learning latent structure\n",
- "\n",
- "As you saw, the accuracy of the CNN varies across the four demographics we looked at. To think about why this may be, consider the dataset the model was trained on, CelebA. If certain features, such as dark skin or hats, are *rare* in CelebA, the model may end up biased against these as a result of training with a biased dataset. That is to say, its classification accuracy will be worse on faces that have under-represented features, such as dark-skinned faces or faces with hats, relevative to faces with features well-represented in the training data! This is a problem.\n",
- "\n",
- "Our goal is to train a *debiased* version of this classifier -- one that accounts for potential disparities in feature representation within the training data. Specifically, to build a debiased facial classifier, we'll train a model that **learns a representation of the underlying latent space** to the face training data. The model then uses this information to mitigate unwanted biases by sampling faces with rare features, like dark skin or hats, *more frequently* during training. The key design requirement for our model is that it can learn an *encoding* of the latent features in the face data in an entirely *unsupervised* way. To achieve this, we'll turn to variational autoencoders (VAEs).\n",
- "\n",
- "\n",
- "\n",
- "As shown in the schematic above and in Lecture 4, VAEs rely on an encoder-decoder structure to learn a latent representation of the input data. In the context of computer vision, the encoder network takes in input images, encodes them into a series of variables defined by a mean and standard deviation, and then draws from the distributions defined by these parameters to generate a set of sampled latent variables. The decoder network then \"decodes\" these variables to generate a reconstruction of the original image, which is used during training to help the model identify which latent variables are important to learn.\n",
- "\n",
- "Let's formalize two key aspects of the VAE model and define relevant functions for each.\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "KmbXKtcPkTXA"
- },
- "source": [
- "### Understanding VAEs: loss function\n",
- "\n",
- "In practice, how can we train a VAE? In learning the latent space, we constrain the means and standard deviations to approximately follow a unit Gaussian. Recall that these are learned parameters, and therefore must factor into the loss computation, and that the decoder portion of the VAE is using these parameters to output a reconstruction that should closely match the input image, which also must factor into the loss. What this means is that we'll have two terms in our VAE loss function:\n",
- "\n",
- "1. **Latent loss ($L_{KL}$)**: measures how closely the learned latent variables match a unit Gaussian and is defined by the Kullback-Leibler (KL) divergence.\n",
- "2. **Reconstruction loss ($L_{x}{(x,\\hat{x})}$)**: measures how accurately the reconstructed outputs match the input and is given by the $L^1$ norm of the input image and its reconstructed output."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Ux3jK2wc153s"
- },
- "source": [
- "The equation for the latent loss is provided by:\n",
- "\n",
- "$$L_{KL}(\\mu, \\sigma) = \\frac{1}{2}\\sum_{j=0}^{k-1} (\\sigma_j + \\mu_j^2 - 1 - \\log{\\sigma_j})$$\n",
- "\n",
- "The equation for the reconstruction loss is provided by:\n",
- "\n",
- "$$L_{x}{(x,\\hat{x})} = ||x-\\hat{x}||_1$$\n",
- "\n",
- "Thus for the VAE loss we have:\n",
- "\n",
- "$$L_{VAE} = c\\cdot L_{KL} + L_{x}{(x,\\hat{x})}$$\n",
- "\n",
- "where $c$ is a weighting coefficient used for regularization. Now we're ready to define our VAE loss function:"
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "S00ASo1ImSuh"
- },
- "source": [
- "### Defining the VAE loss function ###\n",
- "\n",
- "''' Function to calculate VAE loss given:\n",
- " an input x,\n",
- " reconstructed output x_recon,\n",
- " encoded means mu,\n",
- " encoded log of standard deviation logsigma,\n",
- " weight parameter for the latent loss kl_weight\n",
- "'''\n",
- "def vae_loss_function(x, x_recon, mu, logsigma, kl_weight=0.0005):\n",
- " # TODO: Define the latent loss. Note this is given in the equation for L_{KL}\n",
- " # in the text block directly above\n",
- " latent_loss = 0.5 * tf.reduce_sum(tf.exp(logsigma) + tf.square(mu) - 1.0 - logsigma, axis=1)\n",
- " # latent_loss = # TODO\n",
- "\n",
- " # TODO: Define the reconstruction loss as the mean absolute pixel-wise\n",
- " # difference between the input and reconstruction. Hint: you'll need to\n",
- " # use tf.reduce_mean, and supply an axis argument which specifies which\n",
- " # dimensions to reduce over. For example, reconstruction loss needs to average\n",
- " # over the height, width, and channel image dimensions.\n",
- " # https://www.tensorflow.org/api_docs/python/tf/math/reduce_mean\n",
- " reconstruction_loss = tf.reduce_mean(tf.abs(x-x_recon), axis=(1,2,3))\n",
- " # reconstruction_loss = # TODO\n",
- "\n",
- " # TODO: Define the VAE loss. Note this is given in the equation for L_{VAE}\n",
- " # in the text block directly above\n",
- " vae_loss = kl_weight * latent_loss + reconstruction_loss\n",
- " # vae_loss = # TODO\n",
- "\n",
- " return vae_loss"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "E8mpb3pJorpu"
- },
- "source": [
- "Great! Now that we have a more concrete sense of how VAEs work, let's explore how we can leverage this network structure to train a *debiased* facial classifier."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "DqtQH4S5fO8F"
- },
- "source": [
- "### Understanding VAEs: reparameterization\n",
- "\n",
- "As you may recall from lecture, VAEs use a \"reparameterization trick\" for sampling learned latent variables. Instead of the VAE encoder generating a single vector of real numbers for each latent variable, it generates a vector of means and a vector of standard deviations that are constrained to roughly follow Gaussian distributions. We then sample from the standard deviations and add back the mean to output this as our sampled latent vector. Formalizing this for a latent variable $z$ where we sample $\\epsilon \\sim N(0,(I))$ we have:\n",
- "\n",
- "$$z = \\mu + e^{\\left(\\frac{1}{2} \\cdot \\log{\\Sigma}\\right)}\\circ \\epsilon$$\n",
- "\n",
- "where $\\mu$ is the mean and $\\Sigma$ is the covariance matrix. This is useful because it will let us neatly define the loss function for the VAE, generate randomly sampled latent variables, achieve improved network generalization, **and** make our complete VAE network differentiable so that it can be trained via backpropagation. Quite powerful!\n",
- "\n",
- "Let's define a function to implement the VAE sampling operation:"
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "cT6PGdNajl3K"
- },
- "source": [
- "### VAE Reparameterization ###\n",
- "\n",
- "\"\"\"Reparameterization trick by sampling from an isotropic unit Gaussian.\n",
- "# Arguments\n",
- " z_mean, z_logsigma (tensor): mean and log of standard deviation of latent distribution (Q(z|X))\n",
- "# Returns\n",
- " z (tensor): sampled latent vector\n",
- "\"\"\"\n",
- "def sampling(z_mean, z_logsigma):\n",
- " # By default, random.normal is \"standard\" (ie. mean=0 and std=1.0)\n",
- " batch, latent_dim = z_mean.shape\n",
- " epsilon = tf.random.normal(shape=(batch, latent_dim))\n",
- "\n",
- " # TODO: Define the reparameterization computation!\n",
- " # Note the equation is given in the text block immediately above.\n",
- " z = z_mean + tf.math.exp(0.5 * z_logsigma) * epsilon\n",
- " # z = # TODO\n",
- " return z"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "qtHEYI9KNn0A"
- },
- "source": [
- "## 2.5 Debiasing variational autoencoder (DB-VAE)\n",
- "\n",
- "Now, we'll use the general idea behind the VAE architecture to build a model, termed a [*debiasing variational autoencoder*](https://lmrt.mit.edu/sites/default/files/AIES-19_paper_220.pdf) or DB-VAE, to mitigate (potentially) unknown biases present within the training idea. We'll train our DB-VAE model on the facial detection task, run the debiasing operation during training, evaluate on the PPB dataset, and compare its accuracy to our original, biased CNN model. \n",
- "\n",
- "### The DB-VAE model\n",
- "\n",
- "The key idea behind this debiasing approach is to use the latent variables learned via a VAE to adaptively re-sample the CelebA data during training. Specifically, we will alter the probability that a given image is used during training based on how often its latent features appear in the dataset. So, faces with rarer features (like dark skin, sunglasses, or hats) should become more likely to be sampled during training, while the sampling probability for faces with features that are over-represented in the training dataset should decrease (relative to uniform random sampling across the training data).\n",
- "\n",
- "A general schematic of the DB-VAE approach is shown here:\n",
- "\n",
- ""
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "ziA75SN-UxxO"
- },
- "source": [
- "Recall that we want to apply our DB-VAE to a *supervised classification* problem -- the facial detection task. Importantly, note how the encoder portion in the DB-VAE architecture also outputs a single supervised variable, $z_o$, corresponding to the class prediction -- face or not face. Usually, VAEs are not trained to output any supervised variables (such as a class prediction)! This is another key distinction between the DB-VAE and a traditional VAE.\n",
- "\n",
- "Keep in mind that we only want to learn the latent representation of *faces*, as that's what we're ultimately debiasing against, even though we are training a model on a binary classification problem. We'll need to ensure that, **for faces**, our DB-VAE model both learns a representation of the unsupervised latent variables, captured by the distribution $q_\\phi(z|x)$, **and** outputs a supervised class prediction $z_o$, but that, **for negative examples**, it only outputs a class prediction $z_o$."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "XggIKYPRtOZR"
- },
- "source": [
- "### Defining the DB-VAE loss function\n",
- "\n",
- "This means we'll need to be a bit clever about the loss function for the DB-VAE. The form of the loss will depend on whether it's a face image or a non-face image that's being considered.\n",
- "\n",
- "For **face images**, our loss function will have two components:\n",
- "\n",
- "\n",
- "1. **VAE loss ($L_{VAE}$)**: consists of the latent loss and the reconstruction loss.\n",
- "2. **Classification loss ($L_y(y,\\hat{y})$)**: standard cross-entropy loss for a binary classification problem.\n",
- "\n",
- "In contrast, for images of **non-faces**, our loss function is solely the classification loss.\n",
- "\n",
- "We can write a single expression for the loss by defining an indicator variable ${I}_f$which reflects which training data are images of faces (${I}_f(y) = 1$ ) and which are images of non-faces (${I}_f(y) = 0$). Using this, we obtain:\n",
- "\n",
- "$$L_{total} = L_y(y,\\hat{y}) + {I}_f(y)\\Big[L_{VAE}\\Big]$$\n",
- "\n",
- "Let's write a function to define the DB-VAE loss function:\n"
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "VjieDs8Ovcqs"
- },
- "source": [
- "### Loss function for DB-VAE ###\n",
- "\n",
- "\"\"\"Loss function for DB-VAE.\n",
- "# Arguments\n",
- " x: true input x\n",
- " x_pred: reconstructed x\n",
- " y: true label (face or not face)\n",
- " y_logit: predicted labels\n",
- " mu: mean of latent distribution (Q(z|X))\n",
- " logsigma: log of standard deviation of latent distribution (Q(z|X))\n",
- "# Returns\n",
- " total_loss: DB-VAE total loss\n",
- " classification_loss = DB-VAE classification loss\n",
- "\"\"\"\n",
- "def debiasing_loss_function(x, x_pred, y, y_logit, mu, logsigma):\n",
- "\n",
- " # TODO: call the relevant function to obtain VAE loss\n",
- " vae_loss = vae_loss_function(x, x_pred, mu, logsigma)\n",
- " # vae_loss = vae_loss_function('''TODO''') # TODO\n",
- "\n",
- " # TODO: define the classification loss using sigmoid_cross_entropy\n",
- " # https://www.tensorflow.org/api_docs/python/tf/nn/sigmoid_cross_entropy_with_logits\n",
- " classification_loss = tf.nn.sigmoid_cross_entropy_with_logits(labels=y, logits=y_logit)\n",
- " # classification_loss = # TODO\n",
- "\n",
- " # Use the training data labels to create variable face_indicator:\n",
- " # indicator that reflects which training data are images of faces\n",
- " face_indicator = tf.cast(tf.equal(y, 1), tf.float32)\n",
- "\n",
- " # TODO: define the DB-VAE total loss! Use tf.reduce_mean to average over all\n",
- " # samples\n",
- " total_loss = tf.reduce_mean(\n",
- " classification_loss +\n",
- " face_indicator * vae_loss\n",
- " )\n",
- " # total_loss = # TODO\n",
- "\n",
- " return total_loss, classification_loss"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "YIu_2LzNWwWY"
- },
- "source": [
- "### DB-VAE architecture\n",
- "\n",
- "Now we're ready to define the DB-VAE architecture. To build the DB-VAE, we will use the standard CNN classifier from above as our encoder, and then define a decoder network. We will create and initialize the two models, and then construct the end-to-end VAE. We will use a latent space with 100 latent variables.\n",
- "\n",
- "The decoder network will take as input the sampled latent variables, run them through a series of deconvolutional layers, and output a reconstruction of the original input image."
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "JfWPHGrmyE7R"
- },
- "source": [
- "### Define the decoder portion of the DB-VAE ###\n",
- "\n",
- "n_filters = 12 # base number of convolutional filters, same as standard CNN\n",
- "latent_dim = 100 # number of latent variables\n",
- "\n",
- "def make_face_decoder_network():\n",
- " # Functionally define the different layer types we will use\n",
- " Conv2DTranspose = functools.partial(tf.keras.layers.Conv2DTranspose, padding='same', activation='relu')\n",
- " BatchNormalization = tf.keras.layers.BatchNormalization\n",
- " Flatten = tf.keras.layers.Flatten\n",
- " Dense = functools.partial(tf.keras.layers.Dense, activation='relu')\n",
- " Reshape = tf.keras.layers.Reshape\n",
- "\n",
- " # Build the decoder network using the Sequential API\n",
- " decoder = tf.keras.Sequential([\n",
- " # Transform to pre-convolutional generation\n",
- " Dense(units=4*4*6*n_filters), # 4x4 feature maps (with 6N occurances)\n",
- " Reshape(target_shape=(4, 4, 6*n_filters)),\n",
- "\n",
- " # Upscaling convolutions (inverse of encoder)\n",
- " Conv2DTranspose(filters=4*n_filters, kernel_size=3, strides=2),\n",
- " Conv2DTranspose(filters=2*n_filters, kernel_size=3, strides=2),\n",
- " Conv2DTranspose(filters=1*n_filters, kernel_size=5, strides=2),\n",
- " Conv2DTranspose(filters=3, kernel_size=5, strides=2),\n",
- " ])\n",
- "\n",
- " return decoder"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "yWCMu12w1BuD"
- },
- "source": [
- "Now, we will put this decoder together with the standard CNN classifier as our encoder to define the DB-VAE. Note that at this point, there is nothing special about how we put the model together that makes it a \"debiasing\" model -- that will come when we define the training operation. Here, we will define the core VAE architecture by sublassing the `Model` class; defining encoding, reparameterization, and decoding operations; and calling the network end-to-end."
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "dSFDcFBL13c3"
- },
- "source": [
- "### Defining and creating the DB-VAE ###\n",
- "\n",
- "class DB_VAE(tf.keras.Model):\n",
- " def __init__(self, latent_dim):\n",
- " super(DB_VAE, self).__init__()\n",
- " self.latent_dim = latent_dim\n",
- "\n",
- " # Define the number of outputs for the encoder. Recall that we have\n",
- " # `latent_dim` latent variables, as well as a supervised output for the\n",
- " # classification.\n",
- " num_encoder_dims = 2*self.latent_dim + 1\n",
- "\n",
- " self.encoder = make_standard_classifier(num_encoder_dims)\n",
- " self.decoder = make_face_decoder_network()\n",
- "\n",
- " # function to feed images into encoder, encode the latent space, and output\n",
- " # classification probability\n",
- " def encode(self, x):\n",
- " # encoder output\n",
- " encoder_output = self.encoder(x)\n",
- "\n",
- " # classification prediction\n",
- " y_logit = tf.expand_dims(encoder_output[:, 0], -1)\n",
- " # latent variable distribution parameters\n",
- " z_mean = encoder_output[:, 1:self.latent_dim+1]\n",
- " z_logsigma = encoder_output[:, self.latent_dim+1:]\n",
- "\n",
- " return y_logit, z_mean, z_logsigma\n",
- "\n",
- " # VAE reparameterization: given a mean and logsigma, sample latent variables\n",
- " def reparameterize(self, z_mean, z_logsigma):\n",
- " # TODO: call the sampling function defined above\n",
- " z = sampling(z_mean, z_logsigma)\n",
- " # z = # TODO\n",
- " return z\n",
- "\n",
- " # Decode the latent space and output reconstruction\n",
- " def decode(self, z):\n",
- " # TODO: use the decoder to output the reconstruction\n",
- " reconstruction = self.decoder(z)\n",
- " # reconstruction = # TODO\n",
- " return reconstruction\n",
- "\n",
- " # The call function will be used to pass inputs x through the core VAE\n",
- " def call(self, x):\n",
- " # Encode input to a prediction and latent space\n",
- " y_logit, z_mean, z_logsigma = self.encode(x)\n",
- "\n",
- " # TODO: reparameterization\n",
- " z = self.reparameterize(z_mean, z_logsigma)\n",
- " # z = # TODO\n",
- "\n",
- " # TODO: reconstruction\n",
- " recon = self.decode(z)\n",
- " # recon = # TODO\n",
- " return y_logit, z_mean, z_logsigma, recon\n",
- "\n",
- " # Predict face or not face logit for given input x\n",
- " def predict(self, x):\n",
- " y_logit, z_mean, z_logsigma = self.encode(x)\n",
- " return y_logit\n",
- "\n",
- "dbvae = DB_VAE(latent_dim)"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "M-clbYAj2waY"
- },
- "source": [
- "As stated, the encoder architecture is identical to the CNN from earlier in this lab. Note the outputs of our constructed DB_VAE model in the `call` function: `y_logit, z_mean, z_logsigma, z`. Think carefully about why each of these are outputted and their significance to the problem at hand.\n",
- "\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "nbDNlslgQc5A"
- },
- "source": [
- "### Adaptive resampling for automated debiasing with DB-VAE\n",
- "\n",
- "So, how can we actually use DB-VAE to train a debiased facial detection classifier?\n",
- "\n",
- "Recall the DB-VAE architecture: as input images are fed through the network, the encoder learns an estimate ${Q}(z|X)$ of the latent space. We want to increase the relative frequency of rare data by increased sampling of under-represented regions of the latent space. We can approximate ${Q}(z|X)$ using the frequency distributions of each of the learned latent variables, and then define the probability distribution of selecting a given datapoint $x$ based on this approximation. These probability distributions will be used during training to re-sample the data.\n",
- "\n",
- "You'll write a function to execute this update of the sampling probabilities, and then call this function within the DB-VAE training loop to actually debias the model."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Fej5FDu37cf7"
- },
- "source": [
- "First, we've defined a short helper function `get_latent_mu` that returns the latent variable means returned by the encoder after a batch of images is inputted to the network:"
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "ewWbf7TE7wVc"
- },
- "source": [
- "# Function to return the means for an input image batch\n",
- "def get_latent_mu(images, dbvae, batch_size=1024):\n",
- " N = images.shape[0]\n",
- " mu = np.zeros((N, latent_dim))\n",
- " for start_ind in range(0, N, batch_size):\n",
- " end_ind = min(start_ind+batch_size, N+1)\n",
- " batch = (images[start_ind:end_ind]).astype(np.float32)/255.\n",
- " _, batch_mu, _ = dbvae.encode(batch)\n",
- " mu[start_ind:end_ind] = batch_mu\n",
- " return mu"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "wn4yK3SC72bo"
- },
- "source": [
- "Now, let's define the actual resampling algorithm `get_training_sample_probabilities`. Importantly note the argument `smoothing_fac`. This parameter tunes the degree of debiasing: for `smoothing_fac=0`, the re-sampled training set will tend towards falling uniformly over the latent space, i.e., the most extreme debiasing."
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "HiX9pmmC7_wn"
- },
- "source": [
- "### Resampling algorithm for DB-VAE ###\n",
- "\n",
- "'''Function that recomputes the sampling probabilities for images within a batch\n",
- " based on how they distribute across the training data'''\n",
- "def get_training_sample_probabilities(images, dbvae, bins=10, smoothing_fac=0.001):\n",
- " print(\"Recomputing the sampling probabilities\")\n",
- "\n",
- " # TODO: run the input batch and get the latent variable means\n",
- " mu = get_latent_mu(images, dbvae)\n",
- " # mu = get_latent_mu('''TODO''') # TODO\n",
- "\n",
- " # sampling probabilities for the images\n",
- " training_sample_p = np.zeros(mu.shape[0])\n",
- "\n",
- " # consider the distribution for each latent variable\n",
- " for i in range(latent_dim):\n",
- "\n",
- " latent_distribution = mu[:,i]\n",
- " # generate a histogram of the latent distribution\n",
- " hist_density, bin_edges = np.histogram(latent_distribution, density=True, bins=bins)\n",
- "\n",
- " # find which latent bin every data sample falls in\n",
- " bin_edges[0] = -float('inf')\n",
- " bin_edges[-1] = float('inf')\n",
- "\n",
- " # TODO: call the digitize function to find which bins in the latent distribution\n",
- " # every data sample falls in to\n",
- " # https://docs.scipy.org/doc/numpy-1.13.0/reference/generated/numpy.digitize.html\n",
- " bin_idx = np.digitize(latent_distribution, bin_edges)\n",
- " # bin_idx = np.digitize('''TODO''', '''TODO''') # TODO\n",
- "\n",
- " # smooth the density function\n",
- " hist_smoothed_density = hist_density + smoothing_fac\n",
- " hist_smoothed_density = hist_smoothed_density / np.sum(hist_smoothed_density)\n",
- "\n",
- " # invert the density function\n",
- " p = 1.0/(hist_smoothed_density[bin_idx-1])\n",
- "\n",
- " # TODO: normalize all probabilities\n",
- " p = p / np.sum(p)\n",
- " # p = # TODO\n",
- "\n",
- " # TODO: update sampling probabilities by considering whether the newly\n",
- " # computed p is greater than the existing sampling probabilities.\n",
- " training_sample_p = np.maximum(p, training_sample_p)\n",
- " # training_sample_p = # TODO\n",
- "\n",
- " # final normalization\n",
- " training_sample_p /= np.sum(training_sample_p)\n",
- "\n",
- " return training_sample_p"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "pF14fQkVUs-a"
- },
- "source": [
- "Now that we've defined the resampling update, we can train our DB-VAE model on the CelebA/ImageNet training data, and run the above operation to re-weight the importance of particular data points as we train the model. Remember again that we only want to debias for features relevant to *faces*, not the set of negative examples. Complete the code block below to execute the training loop!"
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "xwQs-Gu5bKEK"
- },
- "source": [
- "### Training the DB-VAE ###\n",
- "\n",
- "# Hyperparameters\n",
- "params = dict(\n",
- " batch_size = 32,\n",
- " learning_rate = 5e-4,\n",
- " latent_dim = 100,\n",
- " num_epochs = 1, #DB-VAE needs slightly more epochs to train\n",
- ")\n",
- "\n",
- "experiment = create_experiment(\"6S191_Lab2_Part2_DBVAE\", params)\n",
- "\n",
- "# instantiate a new DB-VAE model and optimizer\n",
- "dbvae = DB_VAE(params[\"latent_dim\"])\n",
- "optimizer = tf.keras.optimizers.Adam(params[\"learning_rate\"])\n",
- "\n",
- "# To define the training operation, we will use tf.function which is a powerful tool\n",
- "# that lets us turn a Python function into a TensorFlow computation graph.\n",
- "@tf.function\n",
- "def debiasing_train_step(x, y):\n",
- "\n",
- " with tf.GradientTape() as tape:\n",
- " # Feed input x into dbvae. Note that this is using the DB_VAE call function!\n",
- " y_logit, z_mean, z_logsigma, x_recon = dbvae(x)\n",
- "\n",
- " '''TODO: call the DB_VAE loss function to compute the loss'''\n",
- " loss, class_loss = debiasing_loss_function(x, x_recon, y, y_logit, z_mean, z_logsigma)\n",
- " # loss, class_loss = debiasing_loss_function('''TODO arguments''') # TODO\n",
- "\n",
- " '''TODO: use the GradientTape.gradient method to compute the gradients.\n",
- " Hint: this is with respect to the trainable_variables of the dbvae.'''\n",
- " grads = tape.gradient(loss, dbvae.trainable_variables)\n",
- " # grads = tape.gradient('''TODO''', '''TODO''') # TODO\n",
- "\n",
- " # apply gradients to variables\n",
- " optimizer.apply_gradients(zip(grads, dbvae.trainable_variables))\n",
- " return loss\n",
- "\n",
- "# get training faces from data loader\n",
- "all_faces = loader.get_all_train_faces()\n",
- "\n",
- "if hasattr(tqdm, '_instances'): tqdm._instances.clear() # clear if it exists\n",
- "\n",
- "# The training loop -- outer loop iterates over the number of epochs\n",
- "step = 0\n",
- "for i in range(params[\"num_epochs\"]):\n",
- "\n",
- " IPython.display.clear_output(wait=True)\n",
- " print(\"Starting epoch {}/{}\".format(i+1, params[\"num_epochs\"]))\n",
- "\n",
- " # Recompute data sampling proabilities\n",
- " '''TODO: recompute the sampling probabilities for debiasing'''\n",
- " p_faces = get_training_sample_probabilities(all_faces, dbvae)\n",
- " # p_faces = get_training_sample_probabilities('''TODO''', '''TODO''') # TODO\n",
- "\n",
- " # get a batch of training data and compute the training step\n",
- " for j in tqdm(range(loader.get_train_size() // params[\"batch_size\"])):\n",
- " # load a batch of data\n",
- " (x, y) = loader.get_batch(params[\"batch_size\"], p_pos=p_faces)\n",
- "\n",
- " # loss optimization\n",
- " loss = debiasing_train_step(x, y)\n",
- " experiment.log_metric(\"loss\", loss.numpy().mean(), step=step)\n",
- "\n",
- " # plot the progress every 200 steps\n",
- " if j % 500 == 0:\n",
- " mdl.util.plot_sample(x, y, dbvae)\n",
- "\n",
- " step += 1\n",
- "\n",
- "experiment.end()"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "uZBlWDPOVcHg"
- },
- "source": [
- "Wonderful! Now we should have a trained and (hopefully!) debiased facial classification model, ready for evaluation!"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Eo34xC7MbaiQ"
- },
- "source": [
- "## 2.6 Evaluation of DB-VAE on Test Dataset\n",
- "\n",
- "Finally let's test our DB-VAE model on the test dataset, looking specifically at its accuracy on each the \"Dark Male\", \"Dark Female\", \"Light Male\", and \"Light Female\" demographics. We will compare the performance of this debiased model against the (potentially biased) standard CNN from earlier in the lab."
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "bgK77aB9oDtX"
- },
- "source": [
- "dbvae_logits = [dbvae.predict(np.array(x, dtype=np.float32)) for x in test_faces]\n",
- "dbvae_probs = tf.squeeze(tf.sigmoid(dbvae_logits))\n",
- "\n",
- "xx = np.arange(len(keys))\n",
- "plt.bar(xx, standard_classifier_probs.numpy().mean(1), width=0.2, label=\"Standard CNN\")\n",
- "plt.bar(xx+0.2, dbvae_probs.numpy().mean(1), width=0.2, label=\"DB-VAE\")\n",
- "plt.xticks(xx, keys);\n",
- "plt.title(\"Network predictions on test dataset\")\n",
- "plt.ylabel(\"Probability\"); plt.legend(bbox_to_anchor=(1.04,1), loc=\"upper left\");\n"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "rESoXRPQo_mq"
- },
- "source": [
- "## 2.7 Conclusion and submission information\n",
- "\n",
- "We encourage you to think about and maybe even address some questions raised by the approach and results outlined here:\n",
- "\n",
- "* How does the accuracy of the DB-VAE across the four demographics compare to that of the standard CNN? Do you find this result surprising in any way?\n",
- "* How can the performance of the DB-VAE classifier be improved even further? We purposely did not optimize hyperparameters to leave this up to you!\n",
- "* In which applications (either related to facial detection or not!) would debiasing in this way be desired? Are there applications where you may not want to debias your model?\n",
- "* Do you think it should be necessary for companies to demonstrate that their models, particularly in the context of tasks like facial detection, are not biased? If so, do you have thoughts on how this could be standardized and implemented?\n",
- "* Do you have ideas for other ways to address issues of bias, particularly in terms of the training data?\n",
- "\n",
- "**Try to optimize your model to achieve improved performance. To enter the competition, please upload the following to the lab submission site for the Debiasing Faces Lab ([submission upload link](https://www.dropbox.com/request/dJZUEoqGLB43JEKzzqIc)).**\n",
- "\n",
- "* Jupyter notebook with the code you used to generate your results;\n",
- "* copy of the bar plot from section 2.6 showing the performance of your model;\n",
- "* a written description and/or diagram of the architecture and hyperparameters you used -- if there are any additional or interesting modifications you made to the template code, please include these in your description;\n",
- "* a written discussion of why these modifications helped improve performance.\n",
- "\n",
- "**Name your file in the following format: `[FirstName]_[LastName]_Face`, followed by the file format (.zip, .ipynb, .pdf, etc).** ZIP files are preferred over individual files. If you submit individual files, you must name the individual files according to the above nomenclature (e.g., `[FirstName]_[LastName]_Face_TODO.pdf`, `[FirstName]_[LastName]_Face_Report.pdf`, etc.).\n",
- "\n",
- "Hopefully this lab has shed some light on a few concepts, from vision based tasks, to VAEs, to algorithmic bias. We like to think it has, but we're biased ;).\n",
- "\n",
- ""
- ]
- }
- ]
-}
diff --git a/lab3/solutions/LLM_Finetuning_Solution.ipynb b/lab3/solutions/LLM_Finetuning_Solution.ipynb
deleted file mode 100644
index 04548c20..00000000
--- a/lab3/solutions/LLM_Finetuning_Solution.ipynb
+++ /dev/null
@@ -1,5432 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "\n",
- "\n",
- "# Copyright Information"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "# Copyright 2025 MIT Introduction to Deep Learning. All Rights Reserved.\n",
- "#\n",
- "# Licensed under the MIT License. You may not use this file except in compliance\n",
- "# with the License. Use and/or modification of this code outside of MIT Introduction\n",
- "# to Deep Learning must reference:\n",
- "#\n",
- "# © MIT Introduction to Deep Learning\n",
- "# http://introtodeeplearning.com\n",
- "#"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "# Laboratory 3: Large Language Model (LLM) Fine-tuning\n",
- "\n",
- "In this lab, you will fine-tune a multi-billion parameter large language model (LLM). We will go through several fundamental concepts of LLMs, including tokenization, templates, and fine-tuning. This lab provides a complete pipeline for fine-tuning a language model to generate responses in a specific style, and you will explore not only language model fine-tuning, but also ways to evaluate the performance of a language model.\n",
- "\n",
- "You will use Google's [Gemma 2B](https://huggingface.co/google/gemma-2b-it) model as the base language model to fine-tune; [Liquid AI's](https://www.liquid.ai/) [LFM-40B](https://www.liquid.ai/liquid-foundation-models) as an evaluation \"judge\" model; and Comet ML's [Opik](https://www.comet.com/site/products/opik/) as a framework for streamlined LLM evaluation.\n",
- "\n",
- "First, let's download the MIT deep learning package, install dependencies, and import the relevant packages we'll need for this lab."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "fmkjWI4fVeAh"
- },
- "outputs": [],
- "source": [
- "# Install and import MIT Deep Learning utilities\n",
- "!pip install mitdeeplearning > /dev/null 2>&1\n",
- "import mitdeeplearning as mdl"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "Oo64stjwBvnB"
- },
- "outputs": [],
- "source": [
- "import os\n",
- "import json\n",
- "import numpy as np\n",
- "from tqdm import tqdm\n",
- "import matplotlib.pyplot as plt\n",
- "\n",
- "import torch\n",
- "from torch.nn import functional as F\n",
- "from torch.utils.data import DataLoader\n",
- "\n",
- "from transformers import AutoTokenizer, AutoModelForCausalLM\n",
- "from datasets import load_dataset\n",
- "from peft import LoraConfig, get_peft_model\n",
- "from lion_pytorch import Lion"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "# Part 1: Fine-tuning an LLM for style\n",
- "\n",
- "In the first part of this lab, we will fine-tune an LLM as a chatbot that can generate responses in a specific style. We will use the [Gemma 2B model](https://huggingface.co/google/gemma-2b-it) as the base language model to finetune."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## 1.1: Templating and tokenization\n",
- "\n",
- "### 1.1.1: Templating\n",
- "\n",
- "Language models that function as chatbots are able to generate responses to user queries -- but how do they do this? We need to provide them with a way to understand the conversation and generate responses in a coherent manner -- some structure of what are inputs and outputs.\n",
- "\n",
- "[Templating](https://huggingface.co/docs/transformers/main/chat_templating) is a way to format inputs and outputs in a consistent structure that a language model can understand. It involves adding special tokens or markers to indicate different parts of the conversation, like who is speaking and where turns begin and end. This structure helps the model learn the proper format for generating responses and maintain a coherent conversation flow. Without templates, the model may not know how to properly format its outputs or distinguish between different speakers in a conversation.\n",
- "\n",
- "Let's start by defining some basic templates for the chatbot, for turns where the user asks a question and the model responds with an answer."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "id": "TN2zHVhfBvnE",
- "outputId": "abddea82-12cf-4a16-868b-2e41f85fd7f1"
- },
- "outputs": [],
- "source": [
- "# Basic question-answer template\n",
- "template_without_answer = \"user\\n{question}\\nmodel\\n\"\n",
- "template_with_answer = template_without_answer + \"{answer}\\n\"\n",
- "\n",
- "# Let's try to put something into the template to see how it looks\n",
- "print(template_with_answer.format(question=\"What is your name?\", answer=\"My name is Gemma!\"))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "### 1.1.2: Tokenization\n",
- "\n",
- "To operate on language, we need to prepare the text for the model. Fundamentally we can think of language as a sequence of \"chunks\" of text. We can split the text into individual chunks, and then map these chunks to numerical tokens -- collectively this is the process of [tokenization](https://huggingface.co/docs/transformers/main/tokenizer_summary). Numerical tokens can then be fed into a language model.\n",
- "\n",
- "There are several common approaches to tokenizing natural language text:\n",
- "\n",
- "1. **Word-based tokenization**: splits text into individual words. While simple, this can lead to large vocabularies and does not handle unknown words well.\n",
- "\n",
- "2. **Character-based tokenization**: splits text into individual characters. While this involves a very small vocabulary, it produces long sequences and loses word-level meaning.\n",
- "\n",
- "3. **Subword tokenization**: breaks words into smaller units (subwords) based on their frequency. The most popular and commonly used approach is [byte-pair encoding (BPE)](https://en.wikipedia.org/wiki/Byte_pair_encoding), which iteratively merges the most frequent character pairs. Modern language models typically use subword tokenization as it balances vocabulary size and sequence length while handling unknown words effectively by breaking them into known subword units.\n",
- "\n",
- "In this lab we will use the tokenizer from the Gemma 2B model, which uses BPE. Let's load it and inspect it."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 266,
- "referenced_widgets": [
- "2846d60e43a24160b177166c25dd0122",
- "231e675f282d48a39e023149d4879b8b",
- "ce1a72b3385c44a2b6c8c36acc48867f",
- "57180ced897d4007a6d836665a032802",
- "8d2df8e3bb4b410f9f671d4cd2a6e80d",
- "16d840d19a804bec80ea85cafc850c13",
- "8642a2df48194dc2a0314de10e0a7635",
- "9a7787f0d75847219071be822ccd76ba",
- "bc10c09f48534cc081dc53a4cc7bc20a",
- "ba606012b7a14ad2824fe6843930ca08",
- "9d5116fb35f44752a680fe7dc2b410b7",
- "01bc169362704eeebd69a87d641d269e",
- "7bbc93e57dda4424acb428027a9f014a",
- "09b97b2a1f734e38b2a9908cf59edd8d",
- "74dc454addc64783bbf1b3897a817147",
- "47037605ebef451e91b64dd2fb040475",
- "f701d542971a4238aa8b76affc054743",
- "9498c07f6ad74b248c94de3bad444f62",
- "c4dc3a623a34415a83c2ffab0e19560b",
- "cde4b31291a9493f8ef649269ca11e1c",
- "7899c5e27ac64478a6e6ac767da24a20",
- "0b18c6ae2dee474aae96fdbd81637024",
- "81b9c3a820424c67a4c050545c2daa2e",
- "2318014fa6fd4452b76b5938a7da0c6f",
- "df141f6e170f4af98d009fd42043a359",
- "c34cba3327304cf98154ce2c73218441",
- "1a949dd5e121434dbbf1b0c290d71373",
- "c1d5a98c0f324e29a3628ff49718d7b6",
- "d0cb6b890289454981f6b9ad8cb2a0e1",
- "4495489fb35f495c898b334d75c8e1ed",
- "34976cd4ca634e4cb7a5c0efffa41e81",
- "64d0bc7735bf42ce800f56ebcce3cdce",
- "01b7fbea9de54e338e3862e09d7e353d",
- "9bead4274c0c4fc6acf12bf6b9dec75a",
- "34ff40c5c4cf405d8ef59a12171b03a5",
- "9d8d908e12b846d58aea8b0e48dd6b92",
- "e9c00880fa4b47c7bf645c3f91a950a9",
- "7d93f09ca25a498fbd4776daa0fc4c53",
- "1c35e9b4250f4fca9e65ecfe4dcb4006",
- "1eacc88f8b754c7e93582ce65f99b5db",
- "6311ea720e344309b1d6fa1445f347e3",
- "ba866548b5544345b37e29f6d8e92652",
- "d5f566c5de7d4dd1808975839ab8b973",
- "0e17dd9f94714fb38ecbe3bd68873c1c"
- ]
- },
- "id": "EeDF1JI-BvnF",
- "outputId": "6c9d3a2b-0b6b-4fa1-de66-dc7879ab4d15"
- },
- "outputs": [],
- "source": [
- "# Load the tokenizer for Gemma 2B\n",
- "model_id = \"unsloth/gemma-2-2b-it\" #\"google/gemma-2-2b-it\"\n",
- "tokenizer = AutoTokenizer.from_pretrained(model_id)\n",
- "\n",
- "# How big is the tokenizer?\n",
- "print(f\"Vocab size: {len(tokenizer.get_vocab())}\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "We not only need to be able to tokenize the text into tokens (encode), but also de-tokenize the tokens back into text (decode). Our tokenizer will have:\n",
- "1. an `encode` function to tokenize the text into tokens, and \n",
- "2. a `decode` function to de-tokenize back to text so that we can read out the model's outputs.\n",
- "\n",
- "Let's test out both steps and inspect to get a better understanding of how this works."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "id": "JH1XzPkiBvnF",
- "outputId": "25e68cce-5aa0-432c-ab8c-246910d6c6b0"
- },
- "outputs": [],
- "source": [
- "# Lets test out both steps:\n",
- "text = \"Here is some sample text!\"\n",
- "print(f\"Original text: {text}\")\n",
- "\n",
- "# Tokenize the text\n",
- "tokens = tokenizer.encode(text, return_tensors=\"pt\")\n",
- "print(f\"Encoded tokens: {tokens}\")\n",
- "\n",
- "# Decode the tokens\n",
- "decoded_text = tokenizer.decode(tokens[0], skip_special_tokens=True)\n",
- "print(f\"Decoded text: {decoded_text}\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "This is really cool. Now we have a way to move in and out of the token space.\n",
- "\n",
- "To \"chat\" with our LLM chatbot, we need to use the tokenizer and the chat template together, in order for the model to respond to the user's question. We can use the templates defined earlier to construct a prompt for the model, without the answer. "
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "id": "jyBxl6NIBvnF",
- "outputId": "06e54226-c434-4a84-868f-a8b5b5085bbd"
- },
- "outputs": [],
- "source": [
- "prompt = template_without_answer.format(question=\"What is the capital of France? Use one word.\")\n",
- "print(prompt)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "If we were to feed this to the model, it would see that it is now the start of the model's turn, and it would generate the answer to this question. "
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## 1.2: Getting started with the LLM\n",
- "\n",
- "Now that we have a way to prepare our data, we're ready to work with our LLM!\n",
- "\n",
- "LLMs like Gemma 2B are trained on a large corpus of text, on the task of predicting the next token in a sequence, given the previous tokens. We call this training task \"next token prediction\"; you may also see it called \"causal language modeling\" or \"autoregressive language modeling\". We can leverage models trained in this way to generate new text by sampling from the predicted probability distribution over the next token.\n",
- "\n",
- "Let's load the Gemma 2B model and start working with it. We will construct a prompt in chat template form and tokenize it. Then, we will feed it to the model to predict next token probabilities. Finally, we will get the next token (which is still numerical) and decode it to text."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 113,
- "referenced_widgets": [
- "e715b19f10c64131ba65d96bf968d72d",
- "7d2b9dea260143eb8c2933a6d3592bb0",
- "087ed90b113448aa9f5079457ca4ba2b",
- "0f9fe85f7079487f837ef9a7a6d7cbc5",
- "49680ea9e5ae4916b52e398e27f87ff5",
- "5cd563e97ce742e99942f553b31e3bed",
- "e988eba4dbe546d484a6c4e88cf90b88",
- "f2418db0b0ee4d3ca801f11c75ac1aca",
- "676328ed1fb04ff4983a5b26df17d966",
- "dacf87a2148c49db9306694b5a5f33da",
- "3198b48f531d4e26bff98917f9d2b592",
- "02edcc6aafcf4895843ff5e93ef30f45",
- "44c5c62e4af7441bafbc7734982aa660",
- "4b81f2c217b24406be898b1333b56352",
- "d73b1aa5cf2e46c9ac65c617af00739f",
- "6e626c5ef0dd408eaf3139f6aabaf190",
- "1725a2fb58b94626a34f87c66ba0e8c2",
- "1d6090d1b9e24e3cb550b655b8fbe318",
- "2f803afa195c476fbfb506d53645c381",
- "1734b0819fe74736a0417a9e2b977695",
- "d82e67b97ea24f80a1478783cfb0f365",
- "586958735baa4f29978d399852dc2aff",
- "34ddb97a59d940879eb53d3e4dbe177e",
- "be8a8c70a4c44ca4bd6fa595b29b3a35",
- "f7dba9ee7dd646f5bf4e9f8589addc83",
- "23790096dbc541d49e8db4c11a772a3f",
- "19f8ecfe426246eb93849b324e986d37",
- "efec2d4919314a79bd55fed697631516",
- "389fffd528eb47f4b443b5e311a43629",
- "d26f0017695b4e42b1c2736c07575775",
- "73aa48a573e349b1a05ba0bb5526bc2a",
- "a239a415866d47238ffa50a5c9c0a580",
- "00dffcff57a14ad28d665cd2c2a11960"
- ]
- },
- "id": "mWtWvgiuBvnG",
- "outputId": "b06295c8-b7b7-4d95-e0d6-31f65ac595ef"
- },
- "outputs": [],
- "source": [
- "# Load the model -- note that this may take a few minutes\n",
- "model = AutoModelForCausalLM.from_pretrained(model_id, device_map=\"auto\")"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "id": "2SMDd5dpBvnG",
- "outputId": "b5e63295-683a-4daa-9526-1ef93ed9e95a"
- },
- "outputs": [],
- "source": [
- "### Putting it together to prompt the model and generate a response ###\n",
- "\n",
- "# 1. Construct the prompt in chat template form\n",
- "question = \"What is the capital of France? Use one word.\" \n",
- "prompt = template_without_answer.format(question=question)\n",
- "# prompt = template_without_answer.format('''TODO''') # TODO\n",
- "\n",
- "# 2. Tokenize the prompt\n",
- "tokens = tokenizer.encode(prompt, return_tensors=\"pt\").to(model.device)\n",
- "\n",
- "# 3. Feed through the model to predict the next token probabilities\n",
- "with torch.no_grad():\n",
- " output = model(tokens)\n",
- " # output = '''TODO''' # TODO\n",
- "\n",
- " probs = F.softmax(output.logits, dim=-1)\n",
- "\n",
- "# 4. Get the next token, according to the maximum probability\n",
- "next_token = torch.argmax(probs[0, -1, :]).item()\n",
- "\n",
- "# 5. Decode the next token\n",
- "next_token_text = tokenizer.decode(next_token)\n",
- "# next_token_text = '''TODO''' # TODO\n",
- "\n",
- "print(f\"Prompt: {prompt}\")\n",
- "print(f\"Predicted next token: {next_token_text}\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "Note that the model is not able to predict the answer to the question, it is only able to predict the next token in the sequence! For more complex questions, we can't just generate one token, but rather we need to generate a sequence of tokens.\n",
- "\n",
- "This can be done by doing the process above iteratively, step by step -- after each step we feed the generated token back into the model and predict the next token again.\n",
- "\n",
- "Instead of doing this manually ourselves, we can use the model's built-in [`model.generate()`](https://huggingface.co/docs/transformers/main/en/main_classes/text_generation#transformers.GenerationMixin.generate) functionality (supported by HuggingFace's Transformers library) to generate `max_new_tokens` number of tokens, and decode the output back to text."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "id": "XnWMUQVbBvnG",
- "outputId": "d0c110d0-d740-427e-abf9-312fe2dd9f5e"
- },
- "outputs": [],
- "source": [
- "prompt = template_without_answer.format(question=\"What does MIT stand for?\")\n",
- "tokens = tokenizer.encode(prompt, return_tensors=\"pt\").to(model.device)\n",
- "output = model.generate(tokens, max_new_tokens=20)\n",
- "print(tokenizer.decode(output[0]))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "Now we have the basic pipeline for generating text with an LLM!"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## 1.3: Fine-tuning\n",
- "\n",
- "Fine-tuning is a technique that allows us to adapt a pre-trained neural network to better suit a downstream task, domain, or style, by training the model further on new data. By training the model further on a carefully curated dataset, we can modify its behavior, style, or capabilities. Fine-tuning is used in a variety of applications, not just language modeling. But in language modeling, fine-tuning can be used to:\n",
- "- Adapt the model's writing style \n",
- "- Improve performance on specific tasks or domains\n",
- "- Teach the model new capabilities or knowledge\n",
- "- Reduce unwanted behaviors or biases\n",
- "\n",
- "In this lab, you will fine-tune the Gemma LLM to adapt the model's writing style. Recall that in Lab 1 you built out a RNN-based sequence model to generate Irish folk songs. Continuing with our Irish theme, we will first fine-tune the LLM to chat in the style of a leprechaun.\n",
- "\n",
- "\n",
- "\n",
- "We have prepared a question-answer dataset where the questions are in standard English style (i.e. \"base\" style) and the answers are in \"leprechaun\" style (written by another LLM). Let's load the dataset and inspect it."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 252,
- "referenced_widgets": [
- "453101669bb84ec784d30fdecf9e1052",
- "1acb7981a03c4d8491072db5b0f80b91",
- "f0013cd0e75942a7b6f0af20d710c9f9",
- "1caca54176f24a68841321407d5cb92c",
- "4bf984821d194c64945609ccf5d08ab0",
- "20f4fd378f6b44f386a6bdd9f0e787f7",
- "72693249b56e4995815d950d33ebbbba",
- "5dd29f36fb5745618d95abda81e869bb",
- "f433b043c2ad41d7ba01a9ee1187fffe",
- "304108b55b1c4ae58ac271e2d8616746",
- "1a1e342e7aa943cd82c91b224ea01932",
- "6a550e5a66704b7b819286707bd3a918",
- "3d6d0fa2af094773b593a85d6c51cf48",
- "8127e4af60a149f68318c0222641718f",
- "ec45944210dc46058e722e9969a7dcdc",
- "095a95bac5224763b7f512b468c7431d",
- "b17245b343ee4c2aad1afb45814ec63c",
- "fdffb194cfad4bc2a2adb90614977445",
- "589c07cbcc1b4d3db5bdee5a15dbd8df",
- "ad5c35c060754bc8ae7bae0832af3921",
- "22f90aaa2b1642c9bf9b385010b8a4cb",
- "c7e6412c823d48e9845eecb1b4e4d7f1",
- "578a08d4d89b496dbca00da965b745d2",
- "e8a1e9cc828f4a4d9c8f4e96b7fbb2fb",
- "b631f91b3a5040e0b237936b412d274b",
- "65670d440ae448c1862c9350e2784a3f",
- "bb749eaf05dc4fbb9e134cc61caae11b",
- "861dfc84b7364159a78379c91007e413",
- "b67122a0d1b24d168be2501782effd15",
- "02dbaaf3131648f8a5b0eb6bf7a4d089",
- "ddabe3ec75d247468550ce9b202e30ab",
- "395eb951f3044c20a6416c346c3e1cdd",
- "516627614ee0481aa5ac80cc77673a54",
- "34711f6447034a728316aacfc401a7e8",
- "fb69e7b86acd485e814ffb0f7ef142f3",
- "e92ae53e3bc14aa59b8cee25909c1d2a",
- "a6cc7eb40dbb4eff9c1e9a3f3b2aa381",
- "91bf23bab4a84645b07952fc7a088c36",
- "151b7ed8c9ca4a3192e2a28ff99c3dc6",
- "97f1a984a0a149bc9f305f18eb109b67",
- "4ec2221b24b94685887b091b45f3f746",
- "ee83baaeecd944a99c11f20f9b4f03fd",
- "db15fee2fae44e4babb449d56aeca0f3",
- "389c5f0e14a24cf08aa175f1f21b22fc"
- ]
- },
- "id": "kN0pHHS8BvnH",
- "outputId": "a8422640-ba32-4d64-9379-1761062fd02e"
- },
- "outputs": [],
- "source": [
- "train_loader, test_loader = mdl.lab3.create_dataloader(style=\"leprechaun\")\n",
- "\n",
- "sample = train_loader.dataset[44]\n",
- "question = sample['instruction']\n",
- "answer = sample['response']\n",
- "answer_style = sample['response_style']\n",
- "\n",
- "print(f\"Question: {question}\\n\\n\" +\n",
- " f\"Original Answer: {answer}\\n\\n\" +\n",
- " f\"Answer Style: {answer_style}\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "### 1.3.1: Chat function\n",
- "\n",
- "Before we start finetuning, we will build a function to easily chat with the model, both so we can monitor its progress over the course of finetuning and also to generate responses to questions.\n",
- "\n",
- "Recall our core steps from before:\n",
- "1. Construct the question prompt using the template\n",
- "2. Tokenize the text\n",
- "3. Feed the tokensthrough the model to predict the next token probabilities\n",
- "4. Decode the predicted tokens back to text\n",
- "\n",
- "Use these steps to build out the `chat` function below."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "d-GfGscMBvnH"
- },
- "outputs": [],
- "source": [
- "def chat(question, max_new_tokens=32, temperature=0.7, only_answer=False):\n",
- " # 1. Construct the prompt using the template\n",
- " prompt = template_without_answer.format(question=question)\n",
- " # prompt = template_without_answer.format('''TODO''') # TODO \n",
- "\n",
- " # 2. Tokenize the text\n",
- " input_ids = tokenizer(prompt, return_tensors=\"pt\").to(model.device)\n",
- " # input_ids = tokenizer('''TODO''', '''TODO''').to(model.device) # TODO\n",
- "\n",
- " # 3. Feed through the model to predict the next token probabilities\n",
- " with torch.no_grad():\n",
- " outputs = model.generate(**input_ids, do_sample=True, max_new_tokens=max_new_tokens, temperature=temperature)\n",
- " # outputs = model.generate('''TODO''', do_sample=True, max_new_tokens=max_new_tokens, temperature=temperature) # TODO\n",
- "\n",
- " # 4. Only return the answer if only_answer is True\n",
- " output_tokens = outputs[0]\n",
- " if only_answer:\n",
- " output_tokens = output_tokens[input_ids['input_ids'].shape[1]:]\n",
- "\n",
- " # 5. Decode the tokens\n",
- " result = tokenizer.decode(output_tokens, skip_special_tokens=True)\n",
- " # result = tokenizer.decode('''TODO''', skip_special_tokens=True) # TODO\n",
- "\n",
- " return result\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "Let's try chatting with the model now to test if it works! We have a sample question here (continuing with the Irish theme); feel free to try out other questions!"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "id": "FDr5f2djBvnH",
- "outputId": "c42789d4-fbbf-438b-fd9d-57b3e037daa5"
- },
- "outputs": [],
- "source": [
- "# Let's try chatting with the model now to test if it works!\n",
- "answer = chat(\n",
- " \"What is the capital of Ireland?\",\n",
- " only_answer=True,\n",
- " max_new_tokens=32,\n",
- ")\n",
- "\n",
- "print(answer)\n",
- "\n",
- "'''TODO: Experiment with asking the model different questions and temperature values, and see how it responds!'''"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "### 1.3.2: Parameter-efficient fine-tuning\n",
- "\n",
- "In fine-tuning, the weights of the model are updated to better fit the fine-tuning dataset and/or task. Updating all the weights in a language model like Gemma 2B -- which has ~2 billion parameters -- is computationally expensive. There are many techniques to make fine-tuning more efficient.\n",
- "\n",
- "We will use a technique called [LoRA](https://arxiv.org/abs/2106.09685) -- low-rank adaptation -- to make the fine-tuning process more efficient. LoRA is a way to fine-tune LLMs very efficiently by only updating a small subset of the model's parameters, and it works by adding trainable low-rank matrices to the model. While we will not go into the details of LoRA here, you can read more about it in the [LoRA paper](https://arxiv.org/abs/2106.09685). We will use the [`peft`](https://pypi.org/project/peft/) library to apply LoRA to the Gemma model."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "id": "Fb6Y679hBvnI",
- "outputId": "8070d39e-0fd9-44cd-9c35-d86afcd99caf"
- },
- "outputs": [],
- "source": [
- "# LoRA is a way to finetune LLMs very efficiently by only updating a small subset of the model's parameters\n",
- "\n",
- "def apply_lora(model):\n",
- " # Define LoRA config\n",
- " lora_config = LoraConfig(\n",
- " r=8, # rank of the LoRA matrices\n",
- " task_type=\"CAUSAL_LM\",\n",
- " target_modules=[\n",
- " \"q_proj\", \"o_proj\", \"k_proj\", \"v_proj\", \"gate_proj\", \"up_proj\", \"down_proj\"\n",
- " ],\n",
- " )\n",
- "\n",
- " # Apply LoRA to the model\n",
- " lora_model = get_peft_model(model, lora_config)\n",
- " return lora_model\n",
- "\n",
- "model = apply_lora(model)\n",
- "\n",
- "# Print the number of trainable parameters after applying LoRA\n",
- "trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad)\n",
- "total_params = sum(p.numel() for p in model.parameters())\n",
- "print(f\"number of trainable parameters: {trainable_params}\")\n",
- "print(f\"total parameters: {total_params}\")\n",
- "print(f\"percentage of trainable parameters: {trainable_params / total_params * 100:.2f}%\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "### 1.3.3: Forward pass and loss computation\n",
- "\n",
- "Now let's define a function to perform a forward pass through the LLM and compute the loss. The forward pass gives us the logits -- which reflect the probability distribution over the next token -- for the next token. We can compute the loss by comparing the predicted logits to the true next token -- our target label. Note that this is effectively a classification problem! So, our loss can be captured by the cross entropy loss, and we can use PyTorch's [`nn.functional.cross_entropy`](https://pytorch.org/docs/stable/generated/torch.nn.functional.cross_entropy.html) function to compute it."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "xCLtZwxwBvnI"
- },
- "outputs": [],
- "source": [
- "def forward_and_compute_loss(model, tokens, mask, context_length=512):\n",
- " # Truncate to context length\n",
- " tokens = tokens[:, :context_length]\n",
- " mask = mask[:, :context_length]\n",
- "\n",
- " # Construct the input, output, and mask\n",
- " x = tokens[:, :-1]\n",
- " y = tokens[:, 1:]\n",
- " mask = mask[:, 1:]\n",
- "\n",
- " # Forward pass to compute logits\n",
- " logits = model(x).logits\n",
- "\n",
- " # Compute loss\n",
- " loss = F.cross_entropy(\n",
- " logits.view(-1, logits.size(-1)),\n",
- " y.view(-1),\n",
- " reduction=\"none\"\n",
- " )\n",
- "\n",
- " # Mask out the loss for non-answer tokens\n",
- " loss = loss[mask.view(-1)].mean()\n",
- "\n",
- " return loss"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "### 1.3.4: Training loop for fine-tuning\n",
- "\n",
- "With this function to compute the loss, we can now define a training loop to fine-tune the model using LoRA. This training loop has the same core components as we've seen before in other labs:\n",
- "1. Grab a batch of data from the dataset (using the DataLoader)\n",
- "2. Feed the data through the model to complete a forward pass and compute the loss\n",
- "3. Backward pass to update the model weights\n",
- "\n",
- "The data in our DataLoader is initially text, and is not structured in our question-answer template. So in step (1) we will need to format the data into our question-answer template previously defined, and then tokenize the text.\n",
- "\n",
- "We care about the model's answer to the question; the \"answer\" tokens are the part of the text we want to predict and compute the loss for. So, after tokenizing the text we need to denote to the model which tokens are part of the \"answer\" and which are part of the \"question\". We can do this by computing a mask for the answer tokens, and then using this mask to compute the loss.\n",
- "\n",
- "Finally, we will complete the backward pass to update the model weights.\n",
- "\n",
- "Let's put this all together in the training loop below."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "JfiIrH7jBvnI"
- },
- "outputs": [],
- "source": [
- "### Training loop ###\n",
- "\n",
- "def train(model, dataloader, tokenizer, max_steps=200, context_length=512, learning_rate=1e-4):\n",
- " losses = []\n",
- "\n",
- " # Apply LoRA to the model\n",
- " model = apply_lora(model)\n",
- " # model = '''TODO''' # TODO\n",
- "\n",
- " optimizer = Lion(model.parameters(), lr=learning_rate)\n",
- "\n",
- " # Training loop\n",
- " for step, batch in enumerate(dataloader):\n",
- " question = batch[\"instruction\"][0]\n",
- " answer = batch[\"response_style\"][0]\n",
- "\n",
- " # Format the question and answer into the template\n",
- " text = template_with_answer.format(question=question, answer=answer)\n",
- " # text = template_with_answer.format('''TODO''', '''TODO''') # TODO\n",
- "\n",
- " # Tokenize the text and compute the mask for the answer\n",
- " ids = tokenizer(text, return_tensors=\"pt\", return_offsets_mapping=True).to(model.device)\n",
- " mask = ids[\"offset_mapping\"][:,:,0] >= text.index(answer)\n",
- "\n",
- " # Feed the tokens through the model and compute the loss\n",
- " loss = forward_and_compute_loss(\n",
- " model=model,\n",
- " tokens=ids[\"input_ids\"],\n",
- " mask=mask,\n",
- " context_length=context_length,\n",
- " )\n",
- " # loss = forward_and_compute_loss('''TODO''') # TODO\n",
- "\n",
- " # Backward pass\n",
- " optimizer.zero_grad()\n",
- " loss.backward()\n",
- " optimizer.step()\n",
- "\n",
- " losses.append(loss.item())\n",
- "\n",
- " # monitor progress\n",
- " if step % 10 == 0:\n",
- " print(chat(\"What is the capital of France?\", only_answer=True))\n",
- " print(f\"step {step} loss: {torch.mean(torch.tensor(losses)).item()}\")\n",
- " losses = []\n",
- "\n",
- " if step > 0 and step % max_steps == 0:\n",
- " break\n",
- "\n",
- " return model\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "id": "blFoO-PhBvnI",
- "outputId": "d23f2002-6e4a-41b0-9710-13d394290f34"
- },
- "outputs": [],
- "source": [
- "# Call the train function to fine-tune the model! Hint: you'll start to see results after a few dozen steps.\n",
- "model = train(model, train_loader, tokenizer, max_steps=50)\n",
- "# model = train('''TODO''') # TODO"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "Let's try chatting with the model again to see how it has changed!"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "id": "su4ZAG3eBvnI",
- "outputId": "b21ce134-1763-4872-8b58-19328d98b76a"
- },
- "outputs": [],
- "source": [
- "print(chat(\"What is a good story about tennis\", only_answer=True, max_new_tokens=200))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "2cvhTsptBvnI"
- },
- "source": [
- "# Part 2: Evaluating a style-tuned LLM\n",
- "\n",
- "How do we know if the model is doing well? How closely does the model's style match the style of a leprechaun? As you can see from the example above, determining whether a generated response is good or not is can seem qualitative, and it can be hard to measure how well the model is doing. \n",
- "\n",
- "While benchmarks have been developed to evaluate the performance of language models on a variety of tasks, these benchmarks are not always representative of the real-world performance of the model. For example, a model may perform well on a benchmark but poorly on a more realistic task. Benchmarks are also limited in the scope of tasks they can cover and capabilities they can reflect, and there can be concerns about whether the data in the benchmark was used to train the model. Synthetic data generation and synthetic tasks are a way to address these limitations, and this is an active area of research.\n",
- "\n",
- "We can also turn a qualitative evaluation of a generated response quantitative by deploying someone or something to \"judge\" the outputs. In this lab, we will use a technique called [LLM as a judge](https://arxiv.org/abs/2306.05685) to do exactly this. This involves using a larger LLM to score the outputs of a smaller LLM. The larger LLM is used as a judge, and it is given a system prompt that describes the task we want the smaller LLM to perform and the judging criteria. A \"system prompt\" is a way to set the general context and guide an LLM's behavior. Contextualized with this system prompt, the judge LLM can score the outputs of the smaller LLM, and we can use this score to evaluate how well the smaller LLM is doing."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "### 2.1: Fine-tune well, you must!\n",
- "\n",
- "Our leprechaun-tuned model is already pretty good at generating responses in the leprechaun style. It must be the luck of the Irish.\n",
- "\n",
- "Let's make things more interesting by considering a different style, one that has some clear patterns but also a lot of variability and room for creativity. We will use the style of [Yoda](https://en.wikipedia.org/wiki/Yoda) from Star Wars.\n",
- "\n",
- "
"
- ]
- }
- ]
-}
diff --git a/lab2/solutions/PT_Part1_MNIST_Solution.ipynb b/lab2/solutions/PT_Part1_MNIST_Solution.ipynb
deleted file mode 100644
index 01dc5bfa..00000000
--- a/lab2/solutions/PT_Part1_MNIST_Solution.ipynb
+++ /dev/null
@@ -1,1029 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Xmf_JRJa_N8C"
- },
- "source": [
- "\n",
- "\n",
- "# Copyright Information"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "gKA_J7bdP33T"
- },
- "outputs": [],
- "source": [
- "# Copyright 2025 MIT Introduction to Deep Learning. All Rights Reserved.\n",
- "#\n",
- "# Licensed under the MIT License. You may not use this file except in compliance\n",
- "# with the License. Use and/or modification of this code outside of MIT Introduction\n",
- "# to Deep Learning must reference:\n",
- "#\n",
- "# © MIT Introduction to Deep Learning\n",
- "# http://introtodeeplearning.com\n",
- "#"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Cm1XpLftPi4A"
- },
- "source": [
- "# Laboratory 2: Computer Vision\n",
- "\n",
- "# Part 1: MNIST Digit Classification\n",
- "\n",
- "In the first portion of this lab, we will build and train a convolutional neural network (CNN) for classification of handwritten digits from the famous [MNIST](http://yann.lecun.com/exdb/mnist/) dataset. The MNIST dataset consists of 60,000 training images and 10,000 test images. Our classes are the digits 0-9.\n",
- "\n",
- "First, let's download the course repository, install dependencies, and import the relevant packages we'll need for this lab."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "RsGqx_ai_N8F"
- },
- "outputs": [],
- "source": [
- "# Import PyTorch and other relevant libraries\n",
- "import torch\n",
- "import torch.nn as nn\n",
- "import torch.optim as optim\n",
- "import torchvision\n",
- "import torchvision.datasets as datasets\n",
- "import torchvision.transforms as transforms\n",
- "from torch.utils.data import DataLoader\n",
- "from torchsummary import summary\n",
- "\n",
- "# MIT introduction to deep learning package\n",
- "!pip install mitdeeplearning --quiet\n",
- "import mitdeeplearning as mdl\n",
- "\n",
- "# other packages\n",
- "import matplotlib.pyplot as plt\n",
- "import numpy as np\n",
- "import random\n",
- "from tqdm import tqdm"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "nCpHDxX1bzyZ"
- },
- "source": [
- "We'll also install Comet. If you followed the instructions from Lab 1, you should have your Comet account set up. Enter your API key below."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "GSR_PAqjbzyZ"
- },
- "outputs": [],
- "source": [
- "!pip install comet_ml > /dev/null 2>&1\n",
- "import comet_ml\n",
- "# TODO: ENTER YOUR API KEY HERE!!\n",
- "COMET_API_KEY = \"\"\n",
- "\n",
- "# Check that we are using a GPU, if not switch runtimes\n",
- "# using Runtime > Change Runtime Type > GPU\n",
- "assert torch.cuda.is_available(), \"Please enable GPU from runtime settings\"\n",
- "assert COMET_API_KEY != \"\", \"Please insert your Comet API Key\"\n",
- "\n",
- "# Set GPU for computation\n",
- "device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "wGPDtVxvTtPk"
- },
- "outputs": [],
- "source": [
- "# start a first comet experiment for the first part of the lab\n",
- "comet_ml.init(project_name=\"6S191_lab2_part1_NN\")\n",
- "comet_model_1 = comet_ml.Experiment()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "HKjrdUtX_N8J"
- },
- "source": [
- "## 1.1 MNIST dataset\n",
- "\n",
- "Let's download and load the dataset and display a few random samples from it:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "G1Bryi5ssUNX"
- },
- "outputs": [],
- "source": [
- "# Download and transform the MNIST dataset\n",
- "transform = transforms.Compose([\n",
- " # Convert images to PyTorch tensors which also scales data from [0,255] to [0,1]\n",
- " transforms.ToTensor()\n",
- "])\n",
- "\n",
- "# Download training and test datasets\n",
- "train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)\n",
- "test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "D_AhlQB4sUNX"
- },
- "source": [
- "The MNIST dataset object in PyTorch is not a simple tensor or array. It's an iterable dataset that loads samples (image-label pairs) one at a time or in batches. In a later section of this lab, we will define a handy DataLoader to process the data in batches."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "LpxeLuaysUNX"
- },
- "outputs": [],
- "source": [
- "image, label = train_dataset[0]\n",
- "print(image.size()) # For a tensor: torch.Size([1, 28, 28])\n",
- "print(label) # For a label: integer (e.g., 5)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "5ZtUqOqePsRD"
- },
- "source": [
- "Our training set is made up of 28x28 grayscale images of handwritten digits.\n",
- "\n",
- "Let's visualize what some of these images and their corresponding training labels look like."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "bDBsR2lP_N8O",
- "scrolled": true
- },
- "outputs": [],
- "source": [
- "plt.figure(figsize=(10,10))\n",
- "random_inds = np.random.choice(60000,36)\n",
- "for i in range(36):\n",
- " plt.subplot(6, 6, i + 1)\n",
- " plt.xticks([])\n",
- " plt.yticks([])\n",
- " plt.grid(False)\n",
- " image_ind = random_inds[i]\n",
- " image, label = train_dataset[image_ind]\n",
- " plt.imshow(image.squeeze(), cmap=plt.cm.binary)\n",
- " plt.xlabel(label)\n",
- "comet_model_1.log_figure(figure=plt)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "V6hd3Nt1_N8q"
- },
- "source": [
- "## 1.2 Neural Network for Handwritten Digit Classification\n",
- "\n",
- "We'll first build a simple neural network consisting of two fully connected layers and apply this to the digit classification task. Our network will ultimately output a probability distribution over the 10 digit classes (0-9). This first architecture we will be building is depicted below:\n",
- "\n",
- "\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "rphS2rMIymyZ"
- },
- "source": [
- "### Fully connected neural network architecture\n",
- "To define the architecture of this first fully connected neural network, we'll once again use the the `torch.nn` modules, defining the model using [`nn.Sequential`](https://pytorch.org/docs/stable/generated/torch.nn.Sequential.html). Note how we first use a [`nn.Flatten`](https://www.tensorflow.org/api_docs/python/tf/keras/layers/Flatten) layer, which flattens the input so that it can be fed into the model.\n",
- "\n",
- "In this next block, you'll define the fully connected layers of this simple network."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "MMZsbjAkDKpU"
- },
- "outputs": [],
- "source": [
- "def build_fc_model():\n",
- " fc_model = nn.Sequential(\n",
- " # First define a Flatten layer\n",
- " nn.Flatten(),\n",
- "\n",
- " nn.Linear(28 * 28, 128),\n",
- " # '''TODO: Define the activation function.'''\n",
- " nn.ReLU(),\n",
- "\n",
- " # '''TODO: Define the second Linear layer'''\n",
- " nn.Linear(128, 10),\n",
- " )\n",
- " return fc_model\n",
- "\n",
- "fc_model_sequential = build_fc_model()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "VtGZpHVKz5Jt"
- },
- "source": [
- "As we progress through this next portion, you may find that you'll want to make changes to the architecture defined above. **Note that in order to update the model later on, you'll need to re-run the above cell to re-initialize the model.**"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "mVN1_AeG_N9N"
- },
- "source": [
- "Let's take a step back and think about the network we've just created. The first layer in this network, `nn.Flatten`, transforms the format of the images from a 2d-array (28 x 28 pixels), to a 1d-array of 28 * 28 = 784 pixels. You can think of this layer as unstacking rows of pixels in the image and lining them up. There are no learned parameters in this layer; it only reformats the data.\n",
- "\n",
- "After the pixels are flattened, the network consists of a sequence of two `nn.Linear` layers. These are fully-connected neural layers. The first `nn.Linear` layer has 128 nodes (or neurons). The second (and last) layer (which you've defined!) should return an array of probability scores that sum to 1. Each node contains a score that indicates the probability that the current image belongs to one of the handwritten digit classes.\n",
- "\n",
- "That defines our fully connected model!"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "kquVpHqPsUNX"
- },
- "source": [
- "### Embracing subclassing in PyTorch"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "RyqD3eJgsUNX"
- },
- "source": [
- "Recall that in Lab 1, we explored creating more flexible models by subclassing [`nn.Module`](https://pytorch.org/docs/stable/generated/torch.nn.Module.html). This technique of defining models is more commonly used in PyTorch. We will practice using this approach of subclassing to define our models for the rest of the lab."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "7JhFJXjYsUNX"
- },
- "outputs": [],
- "source": [
- "# Define the fully connected model\n",
- "class FullyConnectedModel(nn.Module):\n",
- " def __init__(self):\n",
- " super(FullyConnectedModel, self).__init__()\n",
- " self.flatten = nn.Flatten()\n",
- " self.fc1 = nn.Linear(28 * 28, 128)\n",
- "\n",
- " # '''TODO: Define the activation function for the first fully connected layer'''\n",
- " self.relu = nn.ReLU()\n",
- "\n",
- " # '''TODO: Define the second Linear layer to output the classification probabilities'''\n",
- " self.fc2 = nn.Linear(128, 10)\n",
- " # self.fc2 = # TODO\n",
- "\n",
- " def forward(self, x):\n",
- " x = self.flatten(x)\n",
- " x = self.fc1(x)\n",
- "\n",
- " # '''TODO: Implement the rest of forward pass of the model using the layers you have defined above'''\n",
- " x = self.relu(x)\n",
- " x = self.fc2(x)\n",
- " # '''TODO'''\n",
- "\n",
- " return x\n",
- "\n",
- "fc_model = FullyConnectedModel().to(device) # send the model to GPU"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "gut8A_7rCaW6"
- },
- "source": [
- "### Model Metrics and Training Parameters\n",
- "\n",
- "Before training the model, we need to define components that govern its performance and guide its learning process. These include the loss function, optimizer, and evaluation metrics:\n",
- "\n",
- "* *Loss function* — This defines how we measure how accurate the model is during training. As was covered in lecture, during training we want to minimize this function, which will \"steer\" the model in the right direction.\n",
- "* *Optimizer* — This defines how the model is updated based on the data it sees and its loss function.\n",
- "* *Metrics* — Here we can define metrics that we want to use to monitor the training and testing steps. In this example, we'll define and take a look at the *accuracy*, the fraction of the images that are correctly classified.\n",
- "\n",
- "We'll start out by using a stochastic gradient descent (SGD) optimizer initialized with a learning rate of 0.1. Since we are performing a categorical classification task, we'll want to use the [cross entropy loss](https://pytorch.org/docs/stable/generated/torch.nn.CrossEntropyLoss.html).\n",
- "\n",
- "You'll want to experiment with both the choice of optimizer and learning rate and evaluate how these affect the accuracy of the trained model."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "Lhan11blCaW7"
- },
- "outputs": [],
- "source": [
- "'''TODO: Experiment with different optimizers and learning rates. How do these affect\n",
- " the accuracy of the trained model? Which optimizers and/or learning rates yield\n",
- " the best performance?'''\n",
- "# Define loss function and optimizer\n",
- "loss_function = nn.CrossEntropyLoss()\n",
- "optimizer = optim.SGD(fc_model.parameters(), lr=0.1)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "qKF6uW-BCaW-"
- },
- "source": [
- "### Train the model\n",
- "\n",
- "We're now ready to train our model, which will involve feeding the training data (`train_dataset`) into the model, and then asking it to learn the associations between images and labels. We'll also need to define the batch size and the number of epochs, or iterations over the MNIST dataset, to use during training. This dataset consists of a (image, label) tuples that we will iteratively access in batches.\n",
- "\n",
- "In Lab 1, we saw how we can use the [`.backward()`](https://pytorch.org/docs/stable/generated/torch.Tensor.backward.html) method to optimize losses and train models with stochastic gradient descent. In this section, we will define a function to train the model using `.backward()` and `optimizer.step()` to automatically update our model parameters (weights and biases) as we saw in Lab 1.\n",
- "\n",
- "Recall, we mentioned in Section 1.1 that the MNIST dataset can be accessed iteratively in batches. Here, we will define a PyTorch [`DataLoader`](https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader) that will enable us to do that."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "EFMbIqIvQ2X0"
- },
- "outputs": [],
- "source": [
- "# Create DataLoaders for batch processing\n",
- "BATCH_SIZE = 64\n",
- "trainset_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)\n",
- "testset_loader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "dfnnoDwEsUNY"
- },
- "outputs": [],
- "source": [
- "def train(model, dataloader, criterion, optimizer, epochs):\n",
- " model.train() # Set the model to training mode\n",
- " for epoch in range(epochs):\n",
- " total_loss = 0\n",
- " correct_pred = 0\n",
- " total_pred = 0\n",
- "\n",
- " for images, labels in trainset_loader:\n",
- " # Move tensors to GPU so compatible with model\n",
- " images, labels = images.to(device), labels.to(device)\n",
- " # Clear gradients before performing backward pass\n",
- " optimizer.zero_grad()\n",
- " # Forward pass\n",
- " outputs = fc_model(images)\n",
- " # Calculate loss based on model predictions\n",
- " loss = loss_function(outputs, labels)\n",
- " # Backpropagate and update model parameters\n",
- " loss.backward()\n",
- " optimizer.step()\n",
- " # multiply loss by total nos. of samples in batch\n",
- " total_loss += loss.item()*images.size(0)\n",
- "\n",
- " # Calculate accuracy\n",
- " predicted = torch.argmax(outputs, dim=1) # Get predicted class\n",
- " correct_pred += (predicted == labels).sum().item() # Count correct predictions\n",
- " total_pred += labels.size(0) # Count total predictions\n",
- "\n",
- " # Compute metrics\n",
- " total_epoch_loss = total_loss / total_pred\n",
- " epoch_accuracy = correct_pred / total_pred\n",
- " print(f\"Epoch {epoch + 1}, Loss: {total_epoch_loss}, Accuracy: {epoch_accuracy:.4f}\")\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "kIpdv-H0sUNY"
- },
- "outputs": [],
- "source": [
- "# TODO: Train the model by calling the function appropriately\n",
- "EPOCHS = 5\n",
- "train(fc_model, trainset_loader, loss_function, optimizer, EPOCHS)\n",
- "# train('''TODO''') # TODO\n",
- "\n",
- "comet_model_1.end()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "W3ZVOhugCaXA"
- },
- "source": [
- "As the model trains, the loss and accuracy metrics are displayed. With five epochs and a learning rate of 0.01, this fully connected model should achieve an accuracy of approximatley 0.97 (or 97%) on the training data."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "oEw4bZgGCaXB"
- },
- "source": [
- "### Evaluate accuracy on the test dataset\n",
- "\n",
- "Now that we've trained the model, we can ask it to make predictions about a test set that it hasn't seen before. In this example, iterating over the `testset_loader` allows us to access our test images and test labels. And to evaluate accuracy, we can check to see if the model's predictions match the labels from this loader.\n",
- "\n",
- "Since we have now trained the mode, we will use the eval state of the model on the test dataset."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "VflXLEeECaXC"
- },
- "outputs": [],
- "source": [
- "'''TODO: Use the model we have defined in its eval state to complete\n",
- "and call the evaluate function, and calculate the accuracy of the model'''\n",
- "\n",
- "def evaluate(model, dataloader, loss_function):\n",
- " # Evaluate model performance on the test dataset\n",
- " model.eval()\n",
- " test_loss = 0\n",
- " correct_pred = 0\n",
- " total_pred = 0\n",
- " # Disable gradient calculations when in inference mode\n",
- " with torch.no_grad():\n",
- " for images, labels in testset_loader:\n",
- " # TODO: ensure evalaution happens on the GPU\n",
- " images, labels = images.to(device), labels.to(device)\n",
- " # images, labels = # TODO\n",
- "\n",
- " # TODO: feed the images into the model and obtain the predictions (forward pass)\n",
- " outputs = model(images)\n",
- " # outputs = # TODO\n",
- "\n",
- " loss = loss_function(outputs, labels)\n",
- "\n",
- " # TODO: Calculate test loss\n",
- " test_loss += loss.item() * images.size(0)\n",
- " # test_loss += # TODO\n",
- "\n",
- " '''TODO: make a prediction and determine whether it is correct!'''\n",
- " # TODO: identify the digit with the highest probability prediction for the images in the test dataset.\n",
- " predicted = torch.argmax(outputs, dim=1)\n",
- " # predicted = # TODO\n",
- "\n",
- " # TODO: tally the number of correct predictions\n",
- " correct_pred += (predicted == labels).sum().item()\n",
- " # correct_pred += TODO\n",
- " # TODO: tally the total number of predictions\n",
- " total_pred += labels.size(0)\n",
- " # total_pred += TODO\n",
- "\n",
- " # Compute average loss and accuracy\n",
- " test_loss /= total_pred\n",
- " test_acc = correct_pred / total_pred\n",
- " return test_loss, test_acc\n",
- "\n",
- "# TODO: call the evaluate function to evaluate the trained model!!\n",
- "test_loss, test_acc = evaluate(fc_model, trainset_loader, loss_function)\n",
- "# test_loss, test_acc = # TODO\n",
- "\n",
- "print('Test accuracy:', test_acc)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "yWfgsmVXCaXG"
- },
- "source": [
- "You may observe that the accuracy on the test dataset is a little lower than the accuracy on the training dataset. This gap between training accuracy and test accuracy is an example of *overfitting*, when a machine learning model performs worse on new data than on its training data.\n",
- "\n",
- "What is the highest accuracy you can achieve with this first fully connected model? Since the handwritten digit classification task is pretty straightforward, you may be wondering how we can do better...\n",
- "\n",
- ""
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "baIw9bDf8v6Z"
- },
- "source": [
- "## 1.3 Convolutional Neural Network (CNN) for handwritten digit classification"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "_J72Yt1o_fY7"
- },
- "source": [
- "As we saw in lecture, convolutional neural networks (CNNs) are particularly well-suited for a variety of tasks in computer vision, and have achieved near-perfect accuracies on the MNIST dataset. We will now build a CNN composed of two convolutional layers and pooling layers, followed by two fully connected layers, and ultimately output a probability distribution over the 10 digit classes (0-9). The CNN we will be building is depicted below:\n",
- "\n",
- ""
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "EEHqzbJJAEoR"
- },
- "source": [
- "### Define the CNN model\n",
- "\n",
- "We'll use the same training and test datasets as before, and proceed similarly as our fully connected network to define and train our new CNN model. To do this we will explore two layers we have not encountered before: you can use [`nn.Conv2d`](https://pytorch.org/docs/stable/generated/torch.nn.Conv2d.html) to define convolutional layers and [`nn.MaxPool2D`](https://pytorch.org/docs/stable/generated/torch.nn.MaxPool2d.html) to define the pooling layers. Use the parameters shown in the network architecture above to define these layers and build the CNN model. You can decide to use `nn.Sequential` or to subclass `nn.Module`based on your preference."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "vec9qcJs-9W5"
- },
- "outputs": [],
- "source": [
- "### Basic CNN in PyTorch ###\n",
- "\n",
- "class CNN(nn.Module):\n",
- " def __init__(self):\n",
- " super(CNN, self).__init__()\n",
- " # TODO: Define the first convolutional layer\n",
- " self.conv1 = nn.Conv2d(1, 24, kernel_size=3)\n",
- " # self.conv1 = # TODO\n",
- "\n",
- " # TODO: Define the first max pooling layer\n",
- " self.pool1 = nn.MaxPool2d(kernel_size=2)\n",
- " # self.pool1 = # TODO\n",
- "\n",
- " # TODO: Define the second convolutional layer\n",
- " self.conv2 = nn.Conv2d(24, 36, kernel_size=3)\n",
- " # self.conv2 = # TODO\n",
- "\n",
- " # TODO: Define the second max pooling layer\n",
- " self.pool2 = nn.MaxPool2d(kernel_size=2)\n",
- " # self.pool2 = # TODO\n",
- "\n",
- " self.flatten = nn.Flatten()\n",
- " self.fc1 = nn.Linear(36 * 5 * 5, 128)\n",
- " self.relu = nn.ReLU()\n",
- "\n",
- " # TODO: Define the Linear layer that outputs the classification\n",
- " # logits over class labels. Remember that CrossEntropyLoss operates over logits.\n",
- " self.fc2 = nn.Linear(128, 10)\n",
- " # self.fc2 = # TODO\n",
- "\n",
- "\n",
- " def forward(self, x):\n",
- " # First convolutional and pooling layers\n",
- " x = self.conv1(x)\n",
- " x = self.relu(x)\n",
- " x = self.pool1(x)\n",
- "\n",
- " # '''TODO: Implement the rest of forward pass of the model using the layers you have defined above'''\n",
- " # '''hint: this will involve another set of convolutional/pooling layers and then the linear layers'''\n",
- " x = self.conv2(x)\n",
- " x = self.relu(x)\n",
- " x = self.pool2(x)\n",
- "\n",
- " x = self.flatten(x)\n",
- " x = self.fc1(x)\n",
- " x = self.relu(x)\n",
- " x = self.fc2(x)\n",
- "\n",
- " return x\n",
- "\n",
- "# Instantiate the model\n",
- "cnn_model = CNN().to(device)\n",
- "# Initialize the model by passing some data through\n",
- "image, label = train_dataset[0]\n",
- "image = image.to(device).unsqueeze(0) # Add batch dimension → Shape: (1, 1, 28, 28)\n",
- "output = cnn_model(image)\n",
- "# Print the model summary\n",
- "print(cnn_model)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "kUAXIBynCih2"
- },
- "source": [
- "### Train and test the CNN model\n",
- "\n",
- "Earlier in the lab, we defined a `train` function. The body of the function is quite useful because it allows us to have control over the training model, and to record differentiation operations during training by computing the gradients using `loss.backward()`. You may recall seeing this in Lab 1 Part 1.\n",
- "\n",
- "We'll use this same framework to train our `cnn_model` using stochastic gradient descent. You are free to implement the following parts with or without the train and evaluate functions we defined above. What is most important is understanding how to manipulate the bodies of those functions to train and test models.\n",
- "\n",
- "As we've done above, we can define the loss function, optimizer, and calculate the accuracy of the model. Define an optimizer and learning rate of choice. Feel free to modify as you see fit to optimize your model's performance."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "vheyanDkCg6a"
- },
- "outputs": [],
- "source": [
- "# Rebuild the CNN model\n",
- "cnn_model = CNN().to(device)\n",
- "\n",
- "# Define hyperparams\n",
- "batch_size = 64\n",
- "epochs = 7\n",
- "optimizer = optim.SGD(cnn_model.parameters(), lr=1e-2)\n",
- "\n",
- "# TODO: instantiate the cross entropy loss function\n",
- "loss_function = nn.CrossEntropyLoss()\n",
- "# loss_function = # TODO\n",
- "\n",
- "# Redefine trainloader with new batch size parameter (tweak as see fit if optimizing)\n",
- "trainset_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)\n",
- "testset_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "bzgOEAXVsUNZ"
- },
- "outputs": [],
- "source": [
- "loss_history = mdl.util.LossHistory(smoothing_factor=0.95) # to record the evolution of the loss\n",
- "plotter = mdl.util.PeriodicPlotter(sec=2, xlabel='Iterations', ylabel='Loss', scale='semilogy')\n",
- "\n",
- "# Initialize new comet experiment\n",
- "comet_ml.init(project_name=\"6.s191lab2_part1_CNN\")\n",
- "comet_model_2 = comet_ml.Experiment()\n",
- "\n",
- "if hasattr(tqdm, '_instances'): tqdm._instances.clear() # clear if it exists\n",
- "\n",
- "# Training loop!\n",
- "cnn_model.train()\n",
- "\n",
- "for epoch in range(epochs):\n",
- " total_loss = 0\n",
- " correct_pred = 0\n",
- " total_pred = 0\n",
- "\n",
- " # First grab a batch of training data which our data loader returns as a tensor\n",
- " for idx, (images, labels) in enumerate(tqdm(trainset_loader)):\n",
- " images, labels = images.to(device), labels.to(device)\n",
- "\n",
- " # Forward pass\n",
- " #'''TODO: feed the images into the model and obtain the predictions'''\n",
- " logits = cnn_model(images)\n",
- " # logits = # TODO\n",
- "\n",
- " #'''TODO: compute the categorical cross entropy loss\n",
- " loss = loss_function(logits, labels)\n",
- " # loss = # TODO\n",
- " # Get the loss and log it to comet and the loss_history record\n",
- " loss_value = loss.item()\n",
- " comet_model_2.log_metric(\"loss\", loss_value, step=idx)\n",
- " loss_history.append(loss_value) # append the loss to the loss_history record\n",
- " plotter.plot(loss_history.get())\n",
- "\n",
- " # Backpropagation/backward pass\n",
- " '''TODO: Compute gradients for all model parameters and propagate backwads\n",
- " to update model parameters. remember to reset your optimizer!'''\n",
- " optimizer.zero_grad()\n",
- " loss.backward()\n",
- " optimizer.step()\n",
- "\n",
- " # Get the prediction and tally metrics\n",
- " predicted = torch.argmax(logits, dim=1)\n",
- " correct_pred += (predicted == labels).sum().item()\n",
- " total_pred += labels.size(0)\n",
- "\n",
- " # Compute metrics\n",
- " total_epoch_loss = total_loss / total_pred\n",
- " epoch_accuracy = correct_pred / total_pred\n",
- " print(f\"Epoch {epoch + 1}, Loss: {total_epoch_loss}, Accuracy: {epoch_accuracy:.4f}\")\n",
- "\n",
- "comet_model_2.log_figure(figure=plt)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "UG3ZXwYOsUNZ"
- },
- "source": [
- "### Evaluate the CNN Model\n",
- "\n",
- "Now that we've trained the model, let's evaluate it on the test dataset."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "JDm4znZcDtNl"
- },
- "outputs": [],
- "source": [
- "'''TODO: Evaluate the CNN model!'''\n",
- "\n",
- "test_loss, test_acc = evaluate(cnn_model, trainset_loader, loss_function)\n",
- "# test_loss, test_acc = # TODO\n",
- "\n",
- "print('Test accuracy:', test_acc)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "2rvEgK82Glv9"
- },
- "source": [
- "What is the highest accuracy you're able to achieve using the CNN model, and how does the accuracy of the CNN model compare to the accuracy of the simple fully connected network? What optimizers and learning rates seem to be optimal for training the CNN model?\n",
- "\n",
- "Feel free to click the Comet links to investigate the training/accuracy curves for your model."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "xsoS7CPDCaXH"
- },
- "source": [
- "### Make predictions with the CNN model\n",
- "\n",
- "With the model trained, we can use it to make predictions about some images."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "Gl91RPhdCaXI"
- },
- "outputs": [],
- "source": [
- "test_image, test_label = test_dataset[0]\n",
- "test_image = test_image.to(device).unsqueeze(0)\n",
- "\n",
- "# put the model in evaluation (inference) mode\n",
- "cnn_model.eval()\n",
- "predictions_test_image = cnn_model(test_image)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "x9Kk1voUCaXJ"
- },
- "source": [
- "With this function call, the model has predicted the label of the first image in the testing set. Let's take a look at the prediction:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "3DmJEUinCaXK"
- },
- "outputs": [],
- "source": [
- "predictions_test_image"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "-hw1hgeSCaXN"
- },
- "source": [
- "As you can see, a prediction is an array of 10 numbers. Recall that the output of our model is a distribution over the 10 digit classes. Thus, these numbers describe the model's predicted likelihood that the image corresponds to each of the 10 different digits.\n",
- "\n",
- "Let's look at the digit that has the highest likelihood for the first image in the test dataset:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "qsqenuPnCaXO"
- },
- "outputs": [],
- "source": [
- "'''TODO: identify the digit with the highest likelihood prediction for the first\n",
- " image in the test dataset. '''\n",
- "predictions_value = predictions_test_image.cpu().detach().numpy() #.cpu() to copy tensor to memory first\n",
- "prediction = np.argmax(predictions_value)\n",
- "# prediction = # TODO\n",
- "print(prediction)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "E51yS7iCCaXO"
- },
- "source": [
- "So, the model is most confident that this image is a \"???\". We can check the test label (remember, this is the true identity of the digit) to see if this prediction is correct:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "Sd7Pgsu6CaXP"
- },
- "outputs": [],
- "source": [
- "print(\"Label of this digit is:\", test_label)\n",
- "plt.imshow(test_image[0,0,:,:].cpu(), cmap=plt.cm.binary)\n",
- "comet_model_2.log_figure(figure=plt)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "ygh2yYC972ne"
- },
- "source": [
- "It is! Let's visualize the classification results on the MNIST dataset. We will plot images from the test dataset along with their predicted label, as well as a histogram that provides the prediction probabilities for each of the digits.\n",
- "\n",
- "Recall that in PyTorch the MNIST dataset is typically accessed using a DataLoader to iterate through the test set in smaller, manageable batches. By appending the predictions, test labels, and test images from each batch, we will first gradually accumulate all the data needed for visualization into singular variables to observe our model's predictions."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "v6OqZSiAsUNf"
- },
- "outputs": [],
- "source": [
- "# Initialize variables to store all data\n",
- "all_predictions = []\n",
- "all_labels = []\n",
- "all_images = []\n",
- "\n",
- "# Process test set in batches\n",
- "with torch.no_grad():\n",
- " for images, labels in testset_loader:\n",
- " outputs = cnn_model(images)\n",
- "\n",
- " # Apply softmax to get probabilities from the predicted logits\n",
- " probabilities = torch.nn.functional.softmax(outputs, dim=1)\n",
- "\n",
- " # Get predicted classes\n",
- " predicted = torch.argmax(probabilities, dim=1)\n",
- "\n",
- " all_predictions.append(probabilities)\n",
- " all_labels.append(labels)\n",
- " all_images.append(images)\n",
- "\n",
- "all_predictions = torch.cat(all_predictions) # Shape: (total_samples, num_classes)\n",
- "all_labels = torch.cat(all_labels) # Shape: (total_samples,)\n",
- "all_images = torch.cat(all_images) # Shape: (total_samples, 1, 28, 28)\n",
- "\n",
- "# Convert tensors to NumPy for compatibility with plotting functions\n",
- "predictions = all_predictions.cpu().numpy() # Shape: (total_samples, num_classes)\n",
- "test_labels = all_labels.cpu().numpy() # Shape: (total_samples,)\n",
- "test_images = all_images.cpu().numpy() # Shape: (total_samples, 1, 28, 28)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "HV5jw-5HwSmO"
- },
- "outputs": [],
- "source": [
- "#@title Change the slider to look at the model's predictions! { run: \"auto\" }\n",
- "\n",
- "image_index = 79 #@param {type:\"slider\", min:0, max:100, step:1}\n",
- "plt.subplot(1,2,1)\n",
- "mdl.lab2.plot_image_prediction(image_index, predictions, test_labels, test_images)\n",
- "plt.subplot(1,2,2)\n",
- "mdl.lab2.plot_value_prediction(image_index, predictions, test_labels)\n",
- "comet_model_2.log_figure(figure=plt)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "kgdvGD52CaXR"
- },
- "source": [
- "We can also plot several images along with their predictions, where correct prediction labels are blue and incorrect prediction labels are grey. The number gives the percent confidence (out of 100) for the predicted label. Note the model can be very confident in an incorrect prediction!"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "hQlnbqaw2Qu_"
- },
- "outputs": [],
- "source": [
- "# Plots the first X test images, their predicted label, and the true label\n",
- "# Color correct predictions in blue, incorrect predictions in red\n",
- "num_rows = 5\n",
- "num_cols = 4\n",
- "num_images = num_rows*num_cols\n",
- "plt.figure(figsize=(2*2*num_cols, 2*num_rows))\n",
- "for i in range(num_images):\n",
- " plt.subplot(num_rows, 2*num_cols, 2*i+1)\n",
- " mdl.lab2.plot_image_prediction(i, predictions, test_labels, test_images)\n",
- " plt.subplot(num_rows, 2*num_cols, 2*i+2)\n",
- " mdl.lab2.plot_value_prediction(i, predictions, test_labels)\n",
- "comet_model_2.log_figure(figure=plt)\n",
- "comet_model_2.end()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "3cNtDhVaqEdR"
- },
- "source": [
- "## 1.5 Conclusion\n",
- "In this part of the lab, you had the chance to play with different MNIST classifiers with different architectures (fully-connected layers only, CNN), and experiment with how different hyperparameters affect accuracy (learning rate, etc.). The next part of the lab explores another application of CNNs, facial detection, and some drawbacks of AI systems in real world applications, like issues of bias."
- ]
- }
- ],
- "metadata": {
- "accelerator": "GPU",
- "colab": {
- "collapsed_sections": [
- "Xmf_JRJa_N8C"
- ],
- "name": "PT_Part1_MNIST_Solution.ipynb",
- "provenance": []
- },
- "kernelspec": {
- "display_name": "Python 3",
- "name": "python3"
- },
- "language_info": {
- "codemirror_mode": {
- "name": "ipython",
- "version": 3
- },
- "file_extension": ".py",
- "mimetype": "text/x-python",
- "name": "python",
- "nbconvert_exporter": "python",
- "pygments_lexer": "ipython3",
- "version": "3.10.7"
- }
- },
- "nbformat": 4,
- "nbformat_minor": 0
-}
\ No newline at end of file
diff --git a/lab2/solutions/PT_Part2_Debiasing_Solution.ipynb b/lab2/solutions/PT_Part2_Debiasing_Solution.ipynb
deleted file mode 100644
index b258530b..00000000
--- a/lab2/solutions/PT_Part2_Debiasing_Solution.ipynb
+++ /dev/null
@@ -1,1367 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Ag_e7xtTzT1W"
- },
- "source": [
- "\n",
- "\n",
- "# Copyright Information"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "rNbf1pRlSDby"
- },
- "outputs": [],
- "source": [
- "# Copyright 2025 MIT 6.S191 Introduction to Deep Learning. All Rights Reserved.\n",
- "#\n",
- "# Licensed under the MIT License. You may not use this file except in compliance\n",
- "# with the License. Use and/or modification of this code outside of 6.S191 must\n",
- "# reference:\n",
- "#\n",
- "# © MIT 6.S191: Introduction to Deep Learning\n",
- "# http://introtodeeplearning.com\n",
- "#"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "QOpPUH3FR179"
- },
- "source": [
- "# Laboratory 2: Computer Vision\n",
- "\n",
- "# Part 2: Debiasing Facial Detection Systems\n",
- "\n",
- "In the second portion of the lab, we'll explore two prominent aspects of applied deep learning: facial detection and algorithmic bias.\n",
- "\n",
- "Deploying fair, unbiased AI systems is critical to their long-term acceptance. Consider the task of facial detection: given an image, is it an image of a face? This seemingly simple, but extremely important, task is subject to significant amounts of algorithmic bias among select demographics.\n",
- "\n",
- "In this lab, we'll investigate [one recently published approach](http://introtodeeplearning.com/AAAI_MitigatingAlgorithmicBias.pdf) to addressing algorithmic bias. We'll build a facial detection model that learns the *latent variables* underlying face image datasets and uses this to adaptively re-sample the training data, thus mitigating any biases that may be present in order to train a *debiased* model.\n",
- "\n",
- "\n",
- "Run the next code block for a short video from Google that explores how and why it's important to consider bias when thinking about machine learning:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "XQh5HZfbupFF"
- },
- "outputs": [],
- "source": [
- "import IPython\n",
- "\n",
- "IPython.display.YouTubeVideo(\"59bMh59JQDo\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "3Ezfc6Yv6IhI"
- },
- "source": [
- "Let's get started by installing the relevant dependencies.\n",
- "\n",
- "We will be using Comet ML to track our model development and training runs.\n",
- "\n",
- "1. Sign up for a Comet account: [HERE](https://www.comet.com/signup?utm_source=mit_dl&utm_medium=partner&utm_content=github)\n",
- "2. This will generate a personal API Key, which you can find either in the first 'Get Started with Comet' page, under your account settings, or by pressing the '?' in the top right corner and then 'Quickstart Guide'. Enter this API key as the global variable `COMET_API_KEY` below.\n",
- "\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "9MLH3vHqy741"
- },
- "outputs": [],
- "source": [
- "## Comet ML\n",
- "!pip install comet_ml --quiet\n",
- "import comet_ml\n",
- "\n",
- "# TODO: ENTER YOUR API KEY HERE!! instructions above\n",
- "COMET_API_KEY = \"\"\n",
- "assert COMET_API_KEY != \"\", \"Please insert your Comet API Key\"\n",
- "\n",
- "# MIT introduction to deep learning package\n",
- "!pip install mitdeeplearning --quiet\n",
- "import mitdeeplearning as mdl"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "E46sWVKK6LP9"
- },
- "outputs": [],
- "source": [
- "import os\n",
- "import random\n",
- "import IPython\n",
- "import functools\n",
- "import matplotlib.pyplot as plt\n",
- "import numpy as np\n",
- "from tqdm import tqdm\n",
- "from pathlib import Path\n",
- "\n",
- "# Import torch\n",
- "import torch\n",
- "import torch.nn as nn\n",
- "import torch.optim as optim\n",
- "import torch.nn.functional as F\n",
- "import torch.backends.cudnn as cudnn\n",
- "\n",
- "\n",
- "# Check that we are using a GPU, if not switch runtimes\n",
- "# using Runtime > Change Runtime Type > GPU\n",
- "if torch.cuda.is_available():\n",
- " device = torch.device(\"cuda\")\n",
- " cudnn.benchmark = True\n",
- "else:\n",
- " raise ValueError(\"GPU is not available. Change Colab runtime.\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "V0e77oOM3udR"
- },
- "source": [
- "## 2.1 Datasets\n",
- "\n",
- "We'll be using three datasets in this lab. In order to train our facial detection models, we'll need a dataset of positive examples (i.e., of faces) and a dataset of negative examples (i.e., of things that are not faces). We'll use these data to train our models to classify images as either faces or not faces. Finally, we'll need a test dataset of face images. Since we're concerned about the potential *bias* of our learned models against certain demographics, it's important that the test dataset we use has equal representation across the demographics or features of interest. In this lab, we'll consider skin tone and gender.\n",
- "\n",
- "1. **Positive training data**: [CelebA Dataset](http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html). A large-scale (over 200K images) of celebrity faces. \n",
- "2. **Negative training data**: [ImageNet](http://www.image-net.org/). Many images across many different categories. We'll take negative examples from a variety of non-human categories.\n",
- "[Fitzpatrick Scale](https://en.wikipedia.org/wiki/Fitzpatrick_scale) skin type classification system, with each image labeled as \"Lighter'' or \"Darker''.\n",
- "\n",
- "Let's begin by importing these datasets. We've written a class that does a bit of data pre-processing to import the training data in a usable format."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "RWXaaIWy6jVw"
- },
- "outputs": [],
- "source": [
- "CACHE_DIR = Path.home() / \".cache\" / \"mitdeeplearning\"\n",
- "CACHE_DIR.mkdir(parents=True, exist_ok=True)\n",
- "\n",
- "# Get the training data: both images from CelebA and ImageNet\n",
- "path_to_training_data = CACHE_DIR.joinpath(\"train_face.h5\")\n",
- "\n",
- "# Create a simple check to avoid re-downloading\n",
- "if path_to_training_data.is_file():\n",
- " print(f\"Using cached training data from {path_to_training_data}\")\n",
- "else:\n",
- " print(f\"Downloading training data to {path_to_training_data}\")\n",
- " url = \"https://www.dropbox.com/s/hlz8atheyozp1yx/train_face.h5?dl=1\"\n",
- " torch.hub.download_url_to_file(url, path_to_training_data)\n",
- "\n",
- "# Instantiate a TrainingDatasetLoader using the downloaded dataset\n",
- "channels_last = False\n",
- "loader = mdl.lab2.TrainingDatasetLoader(\n",
- " path_to_training_data, channels_last=channels_last\n",
- ")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "yIE321rxa_b3"
- },
- "source": [
- "We can look at the size of the training dataset and grab a batch of size 100:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "DjPSjZZ_bGqe"
- },
- "outputs": [],
- "source": [
- "number_of_training_examples = loader.get_train_size()\n",
- "(images, labels) = loader.get_batch(100)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "tpa3a2z0y742"
- },
- "outputs": [],
- "source": [
- "B, C, H, W = images.shape"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "sxtkJoqF6oH1"
- },
- "source": [
- "Play around with displaying images to get a sense of what the training data actually looks like!"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "Jg17jzwtbxDA"
- },
- "outputs": [],
- "source": [
- "### Examining the CelebA training dataset ###\n",
- "\n",
- "# @title Change the sliders to look at positive and negative training examples! { run: \"auto\" }\n",
- "\n",
- "face_images = images[np.where(labels == 1)[0]].transpose(0, 2, 3, 1)\n",
- "not_face_images = images[np.where(labels == 0)[0]].transpose(0, 2, 3, 1)\n",
- "\n",
- "idx_face = 23 # @param {type:\"slider\", min:0, max:50, step:1}\n",
- "idx_not_face = 9 # @param {type:\"slider\", min:0, max:50, step:1}\n",
- "\n",
- "plt.figure(figsize=(5, 5))\n",
- "plt.subplot(1, 2, 1)\n",
- "plt.imshow(face_images[idx_face])\n",
- "plt.title(\"Face\")\n",
- "plt.grid(False)\n",
- "\n",
- "plt.subplot(1, 2, 2)\n",
- "plt.imshow(not_face_images[idx_not_face])\n",
- "plt.title(\"Not Face\")\n",
- "plt.grid(False)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "NDj7KBaW8Asz"
- },
- "source": [
- "### Thinking about bias\n",
- "\n",
- "Remember we'll be training our facial detection classifiers on the large, well-curated CelebA dataset (and ImageNet), and then evaluating their accuracy by testing them on an independent test dataset. Our goal is to build a model that trains on CelebA *and* achieves high classification accuracy on the the test dataset across all demographics, and to thus show that this model does not suffer from any hidden bias.\n",
- "\n",
- "What exactly do we mean when we say a classifier is biased? In order to formalize this, we'll need to think about [*latent variables*](https://en.wikipedia.org/wiki/Latent_variable), variables that define a dataset but are not strictly observed. As defined in the generative modeling lecture, we'll use the term *latent space* to refer to the probability distributions of the aforementioned latent variables. Putting these ideas together, we consider a classifier *biased* if its classification decision changes after it sees some additional latent features. This notion of bias may be helpful to keep in mind throughout the rest of the lab."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "AIFDvU4w8OIH"
- },
- "source": [
- "## 2.2 CNN for facial detection\n",
- "\n",
- "First, we'll define and train a CNN on the facial classification task, and evaluate its accuracy. Later, we'll evaluate the performance of our debiased models against this baseline CNN. The CNN model has a relatively standard architecture consisting of a series of convolutional layers with batch normalization followed by two fully connected layers to flatten the convolution output and generate a class prediction.\n",
- "\n",
- "### Define and train the CNN model\n",
- "\n",
- "Like we did in the first part of the lab, we'll define our CNN model, and then train on the CelebA and ImageNet datasets by leveraging PyTorch's automatic differentiation (`torch.autograd`) by using the `loss.backward()` and `optimizer.step()` functions."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "82EVTAAW7B_X"
- },
- "outputs": [],
- "source": [
- "### Define the CNN model ###\n",
- "\n",
- "n_filters = 12 # base number of convolutional filters\n",
- "in_channels = images.shape[1]\n",
- "\n",
- "def make_standard_classifier(n_outputs):\n",
- " \"\"\"Create a standard CNN classifier.\"\"\"\n",
- "\n",
- " # Start by first defining a convolutional block\n",
- " class ConvBlock(nn.Module):\n",
- " def __init__(self, in_channels, out_channels, kernel_size, stride, padding=0):\n",
- " super().__init__()\n",
- " self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)\n",
- " self.relu = nn.ReLU(inplace=True)\n",
- " self.bn = nn.BatchNorm2d(out_channels)\n",
- "\n",
- " def forward(self, x):\n",
- " x = self.conv(x)\n",
- " x = self.relu(x)\n",
- " x = self.bn(x)\n",
- " return x\n",
- "\n",
- " # now use the block to define the classifier\n",
- " model = nn.Sequential(\n",
- " ConvBlock(in_channels, n_filters, kernel_size=5, stride=2, padding=2),\n",
- " ConvBlock(n_filters, 2*n_filters, kernel_size=5, stride=2, padding=2),\n",
- " ConvBlock(2*n_filters, 4*n_filters, kernel_size=3, stride=2, padding=1),\n",
- " ConvBlock(4*n_filters, 6*n_filters, kernel_size=3, stride=2, padding=1),\n",
- " nn.Flatten(),\n",
- " nn.Linear(H // 16 * W // 16 * 6 * n_filters, 512),\n",
- " nn.ReLU(inplace=True),\n",
- " nn.Linear(512, n_outputs),\n",
- " )\n",
- "\n",
- " return model.to(device)\n",
- "\n",
- "# call the function to instantiate a classifier model\n",
- "standard_classifier = make_standard_classifier(n_outputs=1)\n",
- "print(standard_classifier)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "c-eWf3l_lCri"
- },
- "source": [
- "Now let's train the standard CNN!"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "mi-04SAfK6lm"
- },
- "outputs": [],
- "source": [
- "### Create a Comet experiment to track our training run ###\n",
- "def create_experiment(project_name, params):\n",
- " # end any prior experiments\n",
- " if \"experiment\" in locals():\n",
- " experiment.end()\n",
- "\n",
- " # initiate the comet experiment for tracking\n",
- " experiment = comet_ml.Experiment(api_key=COMET_API_KEY, project_name=project_name)\n",
- " # log our hyperparameters, defined above, to the experiment\n",
- " for param, value in params.items():\n",
- " experiment.log_parameter(param, value)\n",
- " experiment.flush()\n",
- "\n",
- " return experiment\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "eJlDGh1o31G1"
- },
- "outputs": [],
- "source": [
- "### Train the standard CNN ###\n",
- "loss_fn = nn.BCEWithLogitsLoss()\n",
- "# Training hyperparameters\n",
- "params = dict(\n",
- " batch_size=32,\n",
- " num_epochs=2, # keep small to run faster\n",
- " learning_rate=5e-4,\n",
- ")\n",
- "\n",
- "experiment = create_experiment(\"6S191_Lab2_Part2_CNN\", params)\n",
- "\n",
- "optimizer = optim.Adam(\n",
- " standard_classifier.parameters(), lr=params[\"learning_rate\"]\n",
- ") # define our optimizer\n",
- "loss_history = mdl.util.LossHistory(smoothing_factor=0.99) # to record loss evolution\n",
- "plotter = mdl.util.PeriodicPlotter(sec=2, scale=\"semilogy\")\n",
- "if hasattr(tqdm, \"_instances\"):\n",
- " tqdm._instances.clear() # clear if it exists\n",
- "\n",
- "# set the model to train mode\n",
- "standard_classifier.train()\n",
- "\n",
- "\n",
- "def standard_train_step(x, y):\n",
- " x = torch.from_numpy(x).float().to(device)\n",
- " y = torch.from_numpy(y).float().to(device)\n",
- "\n",
- " # clear the gradients\n",
- " optimizer.zero_grad()\n",
- "\n",
- " # feed the images into the model\n",
- " logits = standard_classifier(x)\n",
- " # Compute the loss\n",
- " loss = loss_fn(logits, y)\n",
- "\n",
- " # Backpropagation\n",
- " loss.backward()\n",
- " optimizer.step()\n",
- "\n",
- " return loss\n",
- "\n",
- "\n",
- "# The training loop!\n",
- "step = 0\n",
- "for epoch in range(params[\"num_epochs\"]):\n",
- " for idx in tqdm(range(loader.get_train_size() // params[\"batch_size\"])):\n",
- " # Grab a batch of training data and propagate through the network\n",
- " x, y = loader.get_batch(params[\"batch_size\"])\n",
- " loss = standard_train_step(x, y)\n",
- " loss_value = loss.detach().cpu().numpy()\n",
- "\n",
- " # Record the loss and plot the evolution of the loss as a function of training\n",
- " loss_history.append(loss_value)\n",
- " plotter.plot(loss_history.get())\n",
- "\n",
- " experiment.log_metric(\"loss\", loss_value, step=step)\n",
- " step += 1\n",
- "\n",
- "experiment.end()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "AKMdWVHeCxj8"
- },
- "source": [
- "### Evaluate performance of the standard CNN\n",
- "\n",
- "Next, let's evaluate the classification performance of our CelebA-trained standard CNN on the training dataset.\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "35-PDgjdWk6_"
- },
- "outputs": [],
- "source": [
- "### Evaluation of standard CNN ###\n",
- "\n",
- "# set the model to eval mode\n",
- "standard_classifier.eval()\n",
- "\n",
- "# TRAINING DATA\n",
- "# Evaluate on a subset of CelebA+Imagenet\n",
- "(batch_x, batch_y) = loader.get_batch(5000)\n",
- "batch_x = torch.from_numpy(batch_x).float().to(device)\n",
- "batch_y = torch.from_numpy(batch_y).float().to(device)\n",
- "\n",
- "with torch.inference_mode():\n",
- " y_pred_logits = standard_classifier(batch_x)\n",
- " y_pred_standard = torch.round(torch.sigmoid(y_pred_logits))\n",
- " acc_standard = torch.mean((batch_y == y_pred_standard).float())\n",
- "\n",
- "print(\n",
- " \"Standard CNN accuracy on (potentially biased) training set: {:.4f}\".format(\n",
- " acc_standard.item()\n",
- " )\n",
- ")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Qu7R14KaEEvU"
- },
- "source": [
- "We will also evaluate our networks on an independent test dataset containing faces that were not seen during training. For the test data, we'll look at the classification accuracy across four different demographics, based on the Fitzpatrick skin scale and sex-based labels: dark-skinned male, dark-skinned female, light-skinned male, and light-skinned female.\n",
- "\n",
- "Let's take a look at some sample faces in the test set."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "vfDD8ztGWk6x"
- },
- "outputs": [],
- "source": [
- "### Load test dataset and plot examples ###\n",
- "\n",
- "test_faces = mdl.lab2.get_test_faces(channels_last=channels_last)\n",
- "keys = [\"Light Female\", \"Light Male\", \"Dark Female\", \"Dark Male\"]\n",
- "\n",
- "fig, axs = plt.subplots(1, len(keys), figsize=(7.5, 7.5))\n",
- "for i, (group, key) in enumerate(zip(test_faces, keys)):\n",
- " axs[i].imshow(np.hstack(group).transpose(1, 2, 0))\n",
- " axs[i].set_title(key, fontsize=15)\n",
- " axs[i].axis(\"off\")\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "uo1z3cdbEUMM"
- },
- "source": [
- "Now, let's evaluate the probability of each of these face demographics being classified as a face using the standard CNN classifier we've just trained."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "GI4O0Y1GAot9"
- },
- "outputs": [],
- "source": [
- "### Evaluate the standard CNN on the test data ###\n",
- "\n",
- "standard_classifier_probs_list = [] # store each demographic's probabilities\n",
- "\n",
- "with torch.inference_mode():\n",
- " for x in test_faces:\n",
- " x = torch.from_numpy(np.array(x, dtype=np.float32)).to(device)\n",
- " logits = standard_classifier(x) # [B, 1]\n",
- " probs = torch.sigmoid(logits) # [B, 1]\n",
- " probs = torch.squeeze(probs, dim=-1) # shape [B]\n",
- " standard_classifier_probs_list.append(probs.cpu().numpy())\n",
- "\n",
- "standard_classifier_probs = np.stack(standard_classifier_probs_list, axis=0)\n",
- "\n",
- "\n",
- "# Plot the prediction accuracies per demographic\n",
- "xx = range(len(keys))\n",
- "yy = standard_classifier_probs.mean(axis=1) # shape [D]\n",
- "plt.bar(xx, yy)\n",
- "plt.xticks(xx, keys)\n",
- "plt.ylim(max(0, yy.min() - np.ptp(yy) / 2.0), yy.max() + np.ptp(yy) / 2.0)\n",
- "plt.title(\"Standard classifier predictions\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "j0Cvvt90DoAm"
- },
- "source": [
- "Take a look at the accuracies for this first model across these four groups. What do you observe? Would you consider this model biased or unbiased? What are some reasons why a trained model may have biased accuracies?"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "0AKcHnXVtgqJ"
- },
- "source": [
- "## 2.3 Mitigating algorithmic bias\n",
- "\n",
- "Imbalances in the training data can result in unwanted algorithmic bias. For example, the majority of faces in CelebA (our training set) are those of light-skinned females. As a result, a classifier trained on CelebA will be better suited at recognizing and classifying faces with features similar to these, and will thus be biased.\n",
- "\n",
- "How could we overcome this? A naive solution -- and one that is being adopted by many companies and organizations -- would be to annotate different subclasses (i.e., light-skinned females, males with hats, etc.) within the training data, and then manually even out the data with respect to these groups.\n",
- "\n",
- "But this approach has two major disadvantages. First, it requires annotating massive amounts of data, which is not scalable. Second, it requires that we know what potential biases (e.g., race, gender, pose, occlusion, hats, glasses, etc.) to look for in the data. As a result, manual annotation may not capture all the different features that are imbalanced within the training data.\n",
- "\n",
- "Instead, let's actually **learn** these features in an unbiased, unsupervised manner, without the need for any annotation, and then train a classifier fairly with respect to these features. In the rest of this lab, we'll do exactly that."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "nLemS7dqECsI"
- },
- "source": [
- "## 2.4 Variational autoencoder (VAE) for learning latent structure\n",
- "\n",
- "As you saw, the accuracy of the CNN varies across the four demographics we looked at. To think about why this may be, consider the dataset the model was trained on, CelebA. If certain features, such as dark skin or hats, are *rare* in CelebA, the model may end up biased against these as a result of training with a biased dataset. That is to say, its classification accuracy will be worse on faces that have under-represented features, such as dark-skinned faces or faces with hats, relevative to faces with features well-represented in the training data! This is a problem.\n",
- "\n",
- "Our goal is to train a *debiased* version of this classifier -- one that accounts for potential disparities in feature representation within the training data. Specifically, to build a debiased facial classifier, we'll train a model that **learns a representation of the underlying latent space** to the face training data. The model then uses this information to mitigate unwanted biases by sampling faces with rare features, like dark skin or hats, *more frequently* during training. The key design requirement for our model is that it can learn an *encoding* of the latent features in the face data in an entirely *unsupervised* way. To achieve this, we'll turn to variational autoencoders (VAEs).\n",
- "\n",
- "\n",
- "\n",
- "As shown in the schematic above and in Lecture 4, VAEs rely on an encoder-decoder structure to learn a latent representation of the input data. In the context of computer vision, the encoder network takes in input images, encodes them into a series of variables defined by a mean and standard deviation, and then draws from the distributions defined by these parameters to generate a set of sampled latent variables. The decoder network then \"decodes\" these variables to generate a reconstruction of the original image, which is used during training to help the model identify which latent variables are important to learn.\n",
- "\n",
- "Let's formalize two key aspects of the VAE model and define relevant functions for each.\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "KmbXKtcPkTXA"
- },
- "source": [
- "### Understanding VAEs: loss function\n",
- "\n",
- "In practice, how can we train a VAE? In learning the latent space, we constrain the means and standard deviations to approximately follow a unit Gaussian. Recall that these are learned parameters, and therefore must factor into the loss computation, and that the decoder portion of the VAE is using these parameters to output a reconstruction that should closely match the input image, which also must factor into the loss. What this means is that we'll have two terms in our VAE loss function:\n",
- "\n",
- "1. **Latent loss ($L_{KL}$)**: measures how closely the learned latent variables match a unit Gaussian and is defined by the Kullback-Leibler (KL) divergence.\n",
- "2. **Reconstruction loss ($L_{x}{(x,\\hat{x})}$)**: measures how accurately the reconstructed outputs match the input and is given by the $L^1$ norm of the input image and its reconstructed output."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Ux3jK2wc153s"
- },
- "source": [
- "The equation for the latent loss is provided by:\n",
- "\n",
- "$$L_{KL}(\\mu, \\sigma) = \\frac{1}{2}\\sum_{j=0}^{k-1} (\\sigma_j + \\mu_j^2 - 1 - \\log{\\sigma_j})$$\n",
- "\n",
- "The equation for the reconstruction loss is provided by:\n",
- "\n",
- "$$L_{x}{(x,\\hat{x})} = ||x-\\hat{x}||_1$$\n",
- "\n",
- "Thus for the VAE loss we have:\n",
- "\n",
- "$$L_{VAE} = c\\cdot L_{KL} + L_{x}{(x,\\hat{x})}$$\n",
- "\n",
- "where $c$ is a weighting coefficient used for regularization. Now we're ready to define our VAE loss function:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "S00ASo1ImSuh"
- },
- "outputs": [],
- "source": [
- "### Defining the VAE loss function ###\n",
- "\n",
- "\"\"\" Function to calculate VAE loss given:\n",
- " an input x,\n",
- " reconstructed output x_recon,\n",
- " encoded means mu,\n",
- " encoded log of standard deviation logsigma,\n",
- " weight parameter for the latent loss kl_weight\n",
- "\"\"\"\n",
- "def vae_loss_function(x, x_recon, mu, logsigma, kl_weight=0.0005):\n",
- " # TODO: Define the latent loss. Note this is given in the equation for L_{KL}\n",
- " # in the text block directly above\n",
- " latent_loss = 0.5 * torch.sum(torch.exp(logsigma) + mu**2 - 1 - logsigma, dim=1)\n",
- " # latent_loss = # TODO\n",
- "\n",
- " # TODO: Define the reconstruction loss as the mean absolute pixel-wise\n",
- " # difference between the input and reconstruction. Hint: you'll need to\n",
- " # use torch.mean, and specify the dimensions to reduce over.\n",
- " # For example, reconstruction loss needs to average\n",
- " # over the height, width, and channel image dimensions.\n",
- " # https://pytorch.org/docs/stable/generated/torch.mean.html\n",
- " reconstruction_loss = torch.mean(torch.abs(x - x_recon), dim=(1, 2, 3))\n",
- " # reconstruction_loss = # TODO\n",
- "\n",
- " # TODO: Define the VAE loss. Note this is given in the equation for L_{VAE}\n",
- " # in the text block directly above\n",
- " vae_loss = kl_weight * latent_loss + reconstruction_loss\n",
- " # vae_loss = # TODO\n",
- "\n",
- " return vae_loss"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "E8mpb3pJorpu"
- },
- "source": [
- "Great! Now that we have a more concrete sense of how VAEs work, let's explore how we can leverage this network structure to train a *debiased* facial classifier."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "DqtQH4S5fO8F"
- },
- "source": [
- "### Understanding VAEs: reparameterization\n",
- "\n",
- "As you may recall from lecture, VAEs use a \"reparameterization trick\" for sampling learned latent variables. Instead of the VAE encoder generating a single vector of real numbers for each latent variable, it generates a vector of means and a vector of standard deviations that are constrained to roughly follow Gaussian distributions. We then sample from the standard deviations and add back the mean to output this as our sampled latent vector. Formalizing this for a latent variable $z$ where we sample $\\epsilon \\sim N(0,(I))$ we have:\n",
- "\n",
- "$$z = \\mu + e^{\\left(\\frac{1}{2} \\cdot \\log{\\Sigma}\\right)}\\circ \\epsilon$$\n",
- "\n",
- "where $\\mu$ is the mean and $\\Sigma$ is the covariance matrix. This is useful because it will let us neatly define the loss function for the VAE, generate randomly sampled latent variables, achieve improved network generalization, **and** make our complete VAE network differentiable so that it can be trained via backpropagation. Quite powerful!\n",
- "\n",
- "Let's define a function to implement the VAE sampling operation:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "cT6PGdNajl3K"
- },
- "outputs": [],
- "source": [
- "### VAE Reparameterization ###\n",
- "\n",
- "\"\"\"Reparameterization trick by sampling from an isotropic unit Gaussian.\n",
- "# Arguments\n",
- " z_mean, z_logsigma (tensor): mean and log of standard deviation of latent distribution (Q(z|X))\n",
- "# Returns\n",
- " z (tensor): sampled latent vector\n",
- "\"\"\"\n",
- "def sampling(z_mean, z_logsigma):\n",
- " # Generate random noise with the same shape as z_mean, sampled from a standard normal distribution (mean=0, std=1)\n",
- " eps = torch.randn_like(z_mean)\n",
- "\n",
- " # # TODO: Define the reparameterization computation!\n",
- " # # Note the equation is given in the text block immediately above.\n",
- " z = z_mean + torch.exp(z_logsigma) * eps\n",
- " # z = # TODO\n",
- "\n",
- " return z"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "qtHEYI9KNn0A"
- },
- "source": [
- "## 2.5 Debiasing variational autoencoder (DB-VAE)\n",
- "\n",
- "Now, we'll use the general idea behind the VAE architecture to build a model, termed a [*debiasing variational autoencoder*](https://lmrt.mit.edu/sites/default/files/AIES-19_paper_220.pdf) or DB-VAE, to mitigate (potentially) unknown biases present within the training idea. We'll train our DB-VAE model on the facial detection task, run the debiasing operation during training, evaluate on the PPB dataset, and compare its accuracy to our original, biased CNN model. \n",
- "\n",
- "### The DB-VAE model\n",
- "\n",
- "The key idea behind this debiasing approach is to use the latent variables learned via a VAE to adaptively re-sample the CelebA data during training. Specifically, we will alter the probability that a given image is used during training based on how often its latent features appear in the dataset. So, faces with rarer features (like dark skin, sunglasses, or hats) should become more likely to be sampled during training, while the sampling probability for faces with features that are over-represented in the training dataset should decrease (relative to uniform random sampling across the training data).\n",
- "\n",
- "A general schematic of the DB-VAE approach is shown here:\n",
- "\n",
- ""
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "ziA75SN-UxxO"
- },
- "source": [
- "Recall that we want to apply our DB-VAE to a *supervised classification* problem -- the facial detection task. Importantly, note how the encoder portion in the DB-VAE architecture also outputs a single supervised variable, $z_o$, corresponding to the class prediction -- face or not face. Usually, VAEs are not trained to output any supervised variables (such as a class prediction)! This is another key distinction between the DB-VAE and a traditional VAE.\n",
- "\n",
- "Keep in mind that we only want to learn the latent representation of *faces*, as that's what we're ultimately debiasing against, even though we are training a model on a binary classification problem. We'll need to ensure that, **for faces**, our DB-VAE model both learns a representation of the unsupervised latent variables, captured by the distribution $q_\\phi(z|x)$, **and** outputs a supervised class prediction $z_o$, but that, **for negative examples**, it only outputs a class prediction $z_o$."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "XggIKYPRtOZR"
- },
- "source": [
- "### Defining the DB-VAE loss function\n",
- "\n",
- "This means we'll need to be a bit clever about the loss function for the DB-VAE. The form of the loss will depend on whether it's a face image or a non-face image that's being considered.\n",
- "\n",
- "For **face images**, our loss function will have two components:\n",
- "\n",
- "\n",
- "1. **VAE loss ($L_{VAE}$)**: consists of the latent loss and the reconstruction loss.\n",
- "2. **Classification loss ($L_y(y,\\hat{y})$)**: standard cross-entropy loss for a binary classification problem.\n",
- "\n",
- "In contrast, for images of **non-faces**, our loss function is solely the classification loss.\n",
- "\n",
- "We can write a single expression for the loss by defining an indicator variable ${I}_f$which reflects which training data are images of faces (${I}_f(y) = 1$ ) and which are images of non-faces (${I}_f(y) = 0$). Using this, we obtain:\n",
- "\n",
- "$$L_{total} = L_y(y,\\hat{y}) + {I}_f(y)\\Big[L_{VAE}\\Big]$$\n",
- "\n",
- "Let's write a function to define the DB-VAE loss function:\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "VjieDs8Ovcqs"
- },
- "outputs": [],
- "source": [
- "### Loss function for DB-VAE ###\n",
- "\n",
- "\"\"\"Loss function for DB-VAE.\n",
- "# Arguments\n",
- " x: true input x\n",
- " x_pred: reconstructed x\n",
- " y: true label (face or not face)\n",
- " y_logit: predicted labels\n",
- " mu: mean of latent distribution (Q(z|X))\n",
- " logsigma: log of standard deviation of latent distribution (Q(z|X))\n",
- "# Returns\n",
- " total_loss: DB-VAE total loss\n",
- " classification_loss = DB-VAE classification loss\n",
- "\"\"\"\n",
- "def debiasing_loss_function(x, x_pred, y, y_logit, mu, logsigma):\n",
- " # TODO: call the relevant function to obtain VAE loss\n",
- " vae_loss = vae_loss_function(x, x_pred, mu, logsigma)\n",
- " # vae_loss = vae_loss_function('''TODO''') # TODO\n",
- "\n",
- " # TODO: define the classification loss using binary_cross_entropy\n",
- " # https://pytorch.org/docs/stable/generated/torch.nn.functional.binary_cross_entropy_with_logits.html\n",
- " classification_loss = F.binary_cross_entropy_with_logits(\n",
- " y_logit, y, reduction=\"none\"\n",
- " )\n",
- " # classification_loss = # TODO\n",
- "\n",
- " # Use the training data labels to create variable face_indicator:\n",
- " # indicator that reflects which training data are images of faces\n",
- " y = y.float()\n",
- " face_indicator = (y == 1.0).float()\n",
- "\n",
- " # TODO: define the DB-VAE total loss! Use torch.mean to average over all\n",
- " # samples\n",
- " total_loss = torch.mean(classification_loss * face_indicator + vae_loss)\n",
- " # total_loss = # TODO\n",
- "\n",
- " return total_loss, classification_loss"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "YIu_2LzNWwWY"
- },
- "source": [
- "### DB-VAE architecture\n",
- "\n",
- "Now we're ready to define the DB-VAE architecture. To build the DB-VAE, we will use the standard CNN classifier from above as our encoder, and then define a decoder network. We will create and initialize the two models, and then construct the end-to-end VAE. We will use a latent space with 100 latent variables.\n",
- "\n",
- "The decoder network will take as input the sampled latent variables, run them through a series of deconvolutional layers, and output a reconstruction of the original input image."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "JfWPHGrmyE7R"
- },
- "outputs": [],
- "source": [
- "### Define the decoder portion of the DB-VAE ###\n",
- "\n",
- "n_filters = 12 # base number of convolutional filters, same as standard CNN\n",
- "latent_dim = 100 # number of latent variables\n",
- "\n",
- "\n",
- "def make_face_decoder_network(latent_dim=100, n_filters=12):\n",
- " \"\"\"\n",
- " Function builds a face-decoder network.\n",
- "\n",
- " Args:\n",
- " latent_dim (int): the dimension of the latent representation\n",
- " n_filters (int): base number of convolutional filters\n",
- "\n",
- " Returns:\n",
- " decoder_model (nn.Module): the decoder network\n",
- " \"\"\"\n",
- "\n",
- " class FaceDecoder(nn.Module):\n",
- " def __init__(self, latent_dim, n_filters):\n",
- " super(FaceDecoder, self).__init__()\n",
- "\n",
- " self.latent_dim = latent_dim\n",
- " self.n_filters = n_filters\n",
- "\n",
- " # Linear (fully connected) layer to project from latent space\n",
- " # to a 4 x 4 feature map with (6*n_filters) channels\n",
- " self.linear = nn.Sequential(\n",
- " nn.Linear(latent_dim, 4 * 4 * 6 * n_filters), nn.ReLU()\n",
- " )\n",
- "\n",
- " # Convolutional upsampling (inverse of an encoder)\n",
- " self.deconv = nn.Sequential(\n",
- " # [B, 6n_filters, 4, 4] -> [B, 4n_filters, 8, 8]\n",
- " nn.ConvTranspose2d(\n",
- " in_channels=6 * n_filters,\n",
- " out_channels=4 * n_filters,\n",
- " kernel_size=3,\n",
- " stride=2,\n",
- " padding=1,\n",
- " output_padding=1,\n",
- " ),\n",
- " nn.ReLU(),\n",
- " # [B, 4n_filters, 8, 8] -> [B, 2n_filters, 16, 16]\n",
- " nn.ConvTranspose2d(\n",
- " in_channels=4 * n_filters,\n",
- " out_channels=2 * n_filters,\n",
- " kernel_size=3,\n",
- " stride=2,\n",
- " padding=1,\n",
- " output_padding=1,\n",
- " ),\n",
- " nn.ReLU(),\n",
- " # [B, 2n_filters, 16, 16] -> [B, n_filters, 32, 32]\n",
- " nn.ConvTranspose2d(\n",
- " in_channels=2 * n_filters,\n",
- " out_channels=n_filters,\n",
- " kernel_size=5,\n",
- " stride=2,\n",
- " padding=2,\n",
- " output_padding=1,\n",
- " ),\n",
- " nn.ReLU(),\n",
- " # [B, n_filters, 32, 32] -> [B, 3, 64, 64]\n",
- " nn.ConvTranspose2d(\n",
- " in_channels=n_filters,\n",
- " out_channels=3,\n",
- " kernel_size=5,\n",
- " stride=2,\n",
- " padding=2,\n",
- " output_padding=1,\n",
- " ),\n",
- " )\n",
- "\n",
- " def forward(self, z):\n",
- " \"\"\"\n",
- " Forward pass of the decoder.\n",
- "\n",
- " Args:\n",
- " z (Tensor): Latent codes of shape [batch_size, latent_dim].\n",
- "\n",
- " Returns:\n",
- " Tensor of shape [batch_size, 3, 64, 64], representing\n",
- " the reconstructed images.\n",
- " \"\"\"\n",
- " x = self.linear(z) # [B, 4*4*6*n_filters]\n",
- " x = x.view(-1, 6 * self.n_filters, 4, 4) # [B, 6n_filters, 4, 4]\n",
- "\n",
- " # Upsample through transposed convolutions\n",
- " x = self.deconv(x) # [B, 3, 64, 64]\n",
- " return x\n",
- "\n",
- " return FaceDecoder(latent_dim, n_filters)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "yWCMu12w1BuD"
- },
- "source": [
- "Now, we will put this decoder together with the standard CNN classifier as our encoder to define the DB-VAE. Note that at this point, there is nothing special about how we put the model together that makes it a \"debiasing\" model -- that will come when we define the training operation. Here, we will define the core VAE architecture by sublassing `nn.Module` class; defining encoding, reparameterization, and decoding operations; and calling the network end-to-end."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "dSFDcFBL13c3"
- },
- "outputs": [],
- "source": [
- "### Defining and creating the DB-VAE ###\n",
- "\n",
- "\n",
- "class DB_VAE(nn.Module):\n",
- " def __init__(self, latent_dim=100):\n",
- " super(DB_VAE, self).__init__()\n",
- " self.latent_dim = latent_dim\n",
- "\n",
- " # Define the number of outputs for the encoder.\n",
- " self.encoder = make_standard_classifier(n_outputs=2 * latent_dim + 1)\n",
- " self.decoder = make_face_decoder_network()\n",
- "\n",
- " # function to feed images into encoder, encode the latent space, and output\n",
- " def encode(self, x):\n",
- " encoder_output = self.encoder(x)\n",
- "\n",
- " # classification prediction\n",
- " y_logit = encoder_output[:, 0].unsqueeze(-1)\n",
- " # latent variable distribution parameters\n",
- " z_mean = encoder_output[:, 1 : self.latent_dim + 1]\n",
- " z_logsigma = encoder_output[:, self.latent_dim + 1 :]\n",
- "\n",
- " return y_logit, z_mean, z_logsigma\n",
- "\n",
- " # VAE reparameterization: given a mean and logsigma, sample latent variables\n",
- " def reparameterize(self, z_mean, z_logsigma):\n",
- " # TODO: call the sampling function defined above\n",
- " z = sampling(z_mean, z_logsigma)\n",
- " # z = # TODO\n",
- " return z\n",
- "\n",
- " # Decode the latent space and output reconstruction\n",
- " def decode(self, z):\n",
- " # TODO: use the decoder to output the reconstruction\n",
- " reconstruction = self.decoder(z)\n",
- " # reconstruction = # TODO\n",
- " return reconstruction\n",
- "\n",
- " # The forward function will be used to pass inputs x through the core VAE\n",
- " def forward(self, x):\n",
- " # Encode input to a prediction and latent space\n",
- " y_logit, z_mean, z_logsigma = self.encode(x)\n",
- "\n",
- " # TODO: reparameterization\n",
- " z = self.reparameterize(z_mean, z_logsigma)\n",
- " # z = # TODO\n",
- "\n",
- " # TODO: reconstruction\n",
- " recon = self.decode(z)\n",
- " # recon = # TODO\n",
- "\n",
- " return y_logit, z_mean, z_logsigma, recon\n",
- "\n",
- " # Predict face or not face logit for given input x\n",
- " def predict(self, x):\n",
- " y_logit, z_mean, z_logsigma = self.encode(x)\n",
- " return y_logit\n",
- "\n",
- "dbvae = DB_VAE(latent_dim)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "M-clbYAj2waY"
- },
- "source": [
- "As stated, the encoder architecture is identical to the CNN from earlier in this lab. Note the outputs of our constructed DB_VAE model in the `forward` function: `y_logit, z_mean, z_logsigma, z`. Think carefully about why each of these are outputted and their significance to the problem at hand.\n",
- "\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "nbDNlslgQc5A"
- },
- "source": [
- "### Adaptive resampling for automated debiasing with DB-VAE\n",
- "\n",
- "So, how can we actually use DB-VAE to train a debiased facial detection classifier?\n",
- "\n",
- "Recall the DB-VAE architecture: as input images are fed through the network, the encoder learns an estimate ${Q}(z|X)$ of the latent space. We want to increase the relative frequency of rare data by increased sampling of under-represented regions of the latent space. We can approximate ${Q}(z|X)$ using the frequency distributions of each of the learned latent variables, and then define the probability distribution of selecting a given datapoint $x$ based on this approximation. These probability distributions will be used during training to re-sample the data.\n",
- "\n",
- "You'll write a function to execute this update of the sampling probabilities, and then call this function within the DB-VAE training loop to actually debias the model."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Fej5FDu37cf7"
- },
- "source": [
- "First, we've defined a short helper function `get_latent_mu` that returns the latent variable means returned by the encoder after a batch of images is inputted to the network:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "ewWbf7TE7wVc"
- },
- "outputs": [],
- "source": [
- "# Function to return the means for an input image batch\n",
- "\n",
- "def get_latent_mu(images, dbvae, batch_size=64):\n",
- " dbvae.eval()\n",
- " all_z_mean = []\n",
- "\n",
- " # If images is NumPy, convert once outside the loop\n",
- " images_t = torch.from_numpy(images).float()\n",
- "\n",
- " with torch.inference_mode():\n",
- " for start in range(0, len(images_t), batch_size):\n",
- " end = start + batch_size\n",
- " batch = images_t[start:end]\n",
- " batch = batch.to(device).permute(0, 3, 1, 2)\n",
- " # Forward pass on this chunk only\n",
- " _, z_mean, _, _ = dbvae(batch)\n",
- " all_z_mean.append(z_mean.cpu())\n",
- "\n",
- " # Concatenate all partial z_mean\n",
- " z_mean_full = torch.cat(all_z_mean, dim=0) # shape [N, latent_dim]\n",
- " mu = z_mean_full.numpy() # convert to NumPy if needed\n",
- " return mu"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "wn4yK3SC72bo"
- },
- "source": [
- "Now, let's define the actual resampling algorithm `get_training_sample_probabilities`. Importantly note the argument `smoothing_fac`. This parameter tunes the degree of debiasing: for `smoothing_fac=0`, the re-sampled training set will tend towards falling uniformly over the latent space, i.e., the most extreme debiasing."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "HiX9pmmC7_wn"
- },
- "outputs": [],
- "source": [
- "### Resampling algorithm for DB-VAE ###\n",
- "\n",
- "\"\"\"Function that recomputes the sampling probabilities for images within a batch\n",
- " based on how they distribute across the training data\"\"\"\n",
- "def get_training_sample_probabilities(images, dbvae, bins=10, smoothing_fac=0.001):\n",
- " print(\"Recomputing the sampling probabilities\")\n",
- "\n",
- " # TODO: run the input batch and get the latent variable means\n",
- " mu = get_latent_mu(images, dbvae)\n",
- " # mu = get_latent_mu('''TODO''', '''TODO''') # TODO\n",
- "\n",
- " # sampling probabilities for the images\n",
- " training_sample_p = np.zeros(mu.shape[0], dtype=np.float64)\n",
- "\n",
- " # consider the distribution for each latent variable\n",
- " for i in range(latent_dim):\n",
- " latent_distribution = mu[:, i]\n",
- " # generate a histogram of the latent distribution\n",
- " hist_density, bin_edges = np.histogram(\n",
- " latent_distribution, density=True, bins=bins\n",
- " )\n",
- "\n",
- " # find which latent bin every data sample falls in\n",
- " bin_edges[0] = -float(\"inf\")\n",
- " bin_edges[-1] = float(\"inf\")\n",
- "\n",
- " # TODO: call the digitize function to find which bins in the latent distribution\n",
- " # every data sample falls in to\n",
- " # https://docs.scipy.org/doc/numpy-1.13.0/reference/generated/numpy.digitize.html\n",
- " bin_idx = np.digitize(latent_distribution, bin_edges)\n",
- " # bin_idx = np.digitize('''TODO''', '''TODO''') # TODO\n",
- "\n",
- " # smooth the density function\n",
- " hist_smoothed_density = hist_density + smoothing_fac\n",
- " hist_smoothed_density = hist_smoothed_density / np.sum(hist_smoothed_density)\n",
- "\n",
- " # invert the density function\n",
- " p = 1.0 / (hist_smoothed_density[bin_idx - 1])\n",
- "\n",
- " # TODO: normalize all probabilities\n",
- " p = p / np.sum(p)\n",
- " # p = # TODO\n",
- "\n",
- " # TODO: update sampling probabilities by considering whether the newly\n",
- " # computed p is greater than the existing sampling probabilities.\n",
- " training_sample_p = np.maximum(training_sample_p, p)\n",
- " # training_sample_p = # TODO\n",
- "\n",
- " # final normalization\n",
- " training_sample_p /= np.sum(training_sample_p)\n",
- "\n",
- " return training_sample_p"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "pF14fQkVUs-a"
- },
- "source": [
- "Now that we've defined the resampling update, we can train our DB-VAE model on the CelebA/ImageNet training data, and run the above operation to re-weight the importance of particular data points as we train the model. Remember again that we only want to debias for features relevant to *faces*, not the set of negative examples. Complete the code block below to execute the training loop!"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "xwQs-Gu5bKEK"
- },
- "outputs": [],
- "source": [
- "### Training the DB-VAE ###\n",
- "\n",
- "# Hyperparameters\n",
- "params = dict(\n",
- " batch_size=32,\n",
- " learning_rate=5e-4,\n",
- " latent_dim=100,\n",
- " num_epochs=2, # DB-VAE needs slightly more epochs to train\n",
- ")\n",
- "\n",
- "experiment = create_experiment(\"6S191_Lab2_Part2_DBVAE\", params)\n",
- "\n",
- "# instantiate a new DB-VAE model and optimizer\n",
- "dbvae = DB_VAE(params[\"latent_dim\"]).to(device)\n",
- "optimizer = optim.Adam(dbvae.parameters(), lr=params[\"learning_rate\"])\n",
- "\n",
- "\n",
- "def debiasing_train_step(x, y):\n",
- " optimizer.zero_grad()\n",
- "\n",
- " y_logit, z_mean, z_logsigma, x_recon = dbvae(x)\n",
- "\n",
- " '''TODO: call the DB_VAE loss function to compute the loss'''\n",
- " loss, class_loss = debiasing_loss_function(\n",
- " x, x_recon, y, y_logit, z_mean, z_logsigma\n",
- " )\n",
- " # loss, class_loss = debiasing_loss_function('''TODO arguments''') # TODO\n",
- "\n",
- " loss.backward()\n",
- " optimizer.step()\n",
- "\n",
- " return loss\n",
- "\n",
- "\n",
- "# get training faces from data loader\n",
- "all_faces = loader.get_all_train_faces()\n",
- "\n",
- "# The training loop -- outer loop iterates over the number of epochs\n",
- "step = 0\n",
- "for i in range(params[\"num_epochs\"]):\n",
- " IPython.display.clear_output(wait=True)\n",
- " print(\"Starting epoch {}/{}\".format(i + 1, params[\"num_epochs\"]))\n",
- "\n",
- " # Recompute data sampling proabilities\n",
- " \"\"\"TODO: recompute the sampling probabilities for debiasing\"\"\"\n",
- " p_faces = get_training_sample_probabilities(all_faces, dbvae)\n",
- " # p_faces = get_training_sample_probabilities('''TODO''', '''TODO''') # TODO\n",
- "\n",
- " # get a batch of training data and compute the training step\n",
- " for j in tqdm(range(loader.get_train_size() // params[\"batch_size\"])):\n",
- " # load a batch of data\n",
- " (x, y) = loader.get_batch(params[\"batch_size\"], p_pos=p_faces)\n",
- " x = torch.from_numpy(x).float().to(device)\n",
- " y = torch.from_numpy(y).float().to(device)\n",
- "\n",
- " # loss optimization\n",
- " loss = debiasing_train_step(x, y)\n",
- " loss_value = loss.detach().cpu().numpy()\n",
- " experiment.log_metric(\"loss\", loss_value, step=step)\n",
- "\n",
- " # plot the progress every 200 steps\n",
- " if j % 500 == 0:\n",
- " mdl.util.plot_sample(x, y, dbvae, backend=\"pt\")\n",
- "\n",
- " step += 1\n",
- "\n",
- "experiment.end()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "uZBlWDPOVcHg"
- },
- "source": [
- "Wonderful! Now we should have a trained and (hopefully!) debiased facial classification model, ready for evaluation!"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Eo34xC7MbaiQ"
- },
- "source": [
- "## 2.6 Evaluation of DB-VAE on Test Dataset\n",
- "\n",
- "Finally let's test our DB-VAE model on the test dataset, looking specifically at its accuracy on each the \"Dark Male\", \"Dark Female\", \"Light Male\", and \"Light Female\" demographics. We will compare the performance of this debiased model against the (potentially biased) standard CNN from earlier in the lab."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "bgK77aB9oDtX"
- },
- "outputs": [],
- "source": [
- "dbvae.to(device)\n",
- "dbvae_logits_list = []\n",
- "for face in test_faces:\n",
- " face = np.asarray(face, dtype=np.float32)\n",
- " face = torch.from_numpy(face).to(device)\n",
- "\n",
- " # Forward pass to get the classification logit\n",
- " with torch.inference_mode():\n",
- " logit = dbvae.predict(face)\n",
- "\n",
- " dbvae_logits_list.append(logit.detach().cpu().numpy())\n",
- "\n",
- "dbvae_logits_array = np.concatenate(dbvae_logits_list, axis=0)\n",
- "dbvae_logits_tensor = torch.from_numpy(dbvae_logits_array)\n",
- "dbvae_probs_tensor = torch.sigmoid(dbvae_logits_tensor)\n",
- "dbvae_probs_array = dbvae_probs_tensor.squeeze(dim=-1).numpy()\n",
- "\n",
- "xx = np.arange(len(keys))\n",
- "\n",
- "std_probs_mean = standard_classifier_probs.mean(axis=1)\n",
- "dbvae_probs_mean = dbvae_probs_array.reshape(len(keys), -1).mean(axis=1)\n",
- "\n",
- "plt.bar(xx, std_probs_mean, width=0.2, label=\"Standard CNN\")\n",
- "plt.bar(xx + 0.2, dbvae_probs_mean, width=0.2, label=\"DB-VAE\")\n",
- "\n",
- "plt.xticks(xx, keys)\n",
- "plt.title(\"Network predictions on test dataset\")\n",
- "plt.ylabel(\"Probability\")\n",
- "plt.legend(bbox_to_anchor=(1.04, 1), loc=\"upper left\")\n",
- "plt.show()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "rESoXRPQo_mq"
- },
- "source": [
- "## 2.7 Conclusion and submission information\n",
- "\n",
- "We encourage you to think about and maybe even address some questions raised by the approach and results outlined here:\n",
- "\n",
- "* How does the accuracy of the DB-VAE across the four demographics compare to that of the standard CNN? Do you find this result surprising in any way?\n",
- "* Can the performance of the DB-VAE classifier be improved even further?\n",
- "* In which applications (either related to facial detection or not!) would debiasing in this way be desired? Are there applications where you may not want to debias your model?\n",
- "* Do you think it should be necessary for companies to demonstrate that their models, particularly in the context of tasks like facial detection, are not biased? If so, do you have thoughts on how this could be standardized and implemented?\n",
- "* Do you have ideas for other ways to address issues of bias, particularly in terms of the training data?\n",
- "\n",
- "**The debiased model may or may not perform well based on the initial hyperparameters. This lab competition will be focused on your answers to the questions above, experiments you tried, and your interpretation and analysis of the results. To enter the competition, please upload the following to the lab submission site for the Debiasing Faces Lab ([submission upload link](https://www.dropbox.com/request/dJZUEoqGLB43JEKzzqIc)).**\n",
- "\n",
- "* Jupyter notebook with the code you used to generate your results;\n",
- "* copy of the bar plot from section 2.6 showing the performance of your model;\n",
- "* a written description and/or diagram of the architecture and hyperparameters you used -- if there are any additional or interesting modifications you made to the template code, please include these in your description;\n",
- "* a written discussion of why and how these modifications changed performance.\n",
- "\n",
- "**Name your file in the following format: `[FirstName]_[LastName]_Face`, followed by the file format (.zip, .ipynb, .pdf, etc).** ZIP files are preferred over individual files. If you submit individual files, you must name the individual files according to the above nomenclature (e.g., `[FirstName]_[LastName]_Face_TODO.pdf`, `[FirstName]_[LastName]_Face_Report.pdf`, etc.).\n",
- "\n",
- "Hopefully this lab has shed some light on a few concepts, from vision based tasks, to VAEs, to algorithmic bias. We like to think it has, but we're biased ;).\n",
- "\n",
- ""
- ]
- }
- ],
- "metadata": {
- "accelerator": "GPU",
- "colab": {
- "collapsed_sections": [
- "Ag_e7xtTzT1W",
- "NDj7KBaW8Asz"
- ],
- "name": "PT_Part2_Debiasing_Solution.ipynb",
- "provenance": []
- },
- "kernelspec": {
- "display_name": "Python 3",
- "name": "python3"
- },
- "language_info": {
- "codemirror_mode": {
- "name": "ipython",
- "version": 3
- },
- "file_extension": ".py",
- "mimetype": "text/x-python",
- "name": "python",
- "nbconvert_exporter": "python",
- "pygments_lexer": "ipython3",
- "version": "3.10.16"
- }
- },
- "nbformat": 4,
- "nbformat_minor": 0
-}
diff --git a/lab2/solutions/TF_Part1_MNIST_Solution.ipynb b/lab2/solutions/TF_Part1_MNIST_Solution.ipynb
deleted file mode 100644
index c2ae8377..00000000
--- a/lab2/solutions/TF_Part1_MNIST_Solution.ipynb
+++ /dev/null
@@ -1,789 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Xmf_JRJa_N8C"
- },
- "source": [
- "\n",
- "\n",
- "# Copyright Information"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "gKA_J7bdP33T"
- },
- "outputs": [],
- "source": [
- "# Copyright 2025 MIT Introduction to Deep Learning. All Rights Reserved.\n",
- "#\n",
- "# Licensed under the MIT License. You may not use this file except in compliance\n",
- "# with the License. Use and/or modification of this code outside of MIT Introduction\n",
- "# to Deep Learning must reference:\n",
- "#\n",
- "# © MIT Introduction to Deep Learning\n",
- "# http://introtodeeplearning.com\n",
- "#"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Cm1XpLftPi4A"
- },
- "source": [
- "# Laboratory 2: Computer Vision\n",
- "\n",
- "# Part 1: MNIST Digit Classification\n",
- "\n",
- "In the first portion of this lab, we will build and train a convolutional neural network (CNN) for classification of handwritten digits from the famous [MNIST](http://yann.lecun.com/exdb/mnist/) dataset. The MNIST dataset consists of 60,000 training images and 10,000 test images. Our classes are the digits 0-9.\n",
- "\n",
- "First, let's download the course repository, install dependencies, and import the relevant packages we'll need for this lab."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "RsGqx_ai_N8F"
- },
- "outputs": [],
- "source": [
- "# Import Tensorflow 2.0\n",
- "# !pip install tensorflow\n",
- "import tensorflow as tf\n",
- "\n",
- "# MIT introduction to deep learning package\n",
- "!pip install mitdeeplearning --quiet\n",
- "import mitdeeplearning as mdl\n",
- "\n",
- "# other packages\n",
- "import matplotlib.pyplot as plt\n",
- "import numpy as np\n",
- "import random\n",
- "from tqdm import tqdm"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "nCpHDxX1bzyZ"
- },
- "source": [
- "We'll also install Comet. If you followed the instructions from Lab 1, you should have your Comet account set up. Enter your API key below."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "GSR_PAqjbzyZ"
- },
- "outputs": [],
- "source": [
- "!pip install comet_ml > /dev/null 2>&1\n",
- "import comet_ml\n",
- "# TODO: ENTER YOUR API KEY HERE!!\n",
- "COMET_API_KEY = \"\"\n",
- "\n",
- "# Check that we are using a GPU, if not switch runtimes\n",
- "# using Runtime > Change Runtime Type > GPU\n",
- "assert len(tf.config.list_physical_devices('GPU')) > 0\n",
- "assert COMET_API_KEY != \"\", \"Please insert your Comet API Key\""
- ]
- },
- {
- "cell_type": "code",
- "source": [
- "# start a first comet experiment for the first part of the lab\n",
- "comet_ml.init(project_name=\"6S191_lab2_part1_NN\")\n",
- "comet_model_1 = comet_ml.Experiment()"
- ],
- "metadata": {
- "id": "wGPDtVxvTtPk"
- },
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "HKjrdUtX_N8J"
- },
- "source": [
- "## 1.1 MNIST dataset\n",
- "\n",
- "Let's download and load the dataset and display a few random samples from it:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "p2dQsHI3_N8K"
- },
- "outputs": [],
- "source": [
- "mnist = tf.keras.datasets.mnist\n",
- "(train_images, train_labels), (test_images, test_labels) = mnist.load_data()\n",
- "train_images = (np.expand_dims(train_images, axis=-1)/255.).astype(np.float32)\n",
- "train_labels = (train_labels).astype(np.int64)\n",
- "test_images = (np.expand_dims(test_images, axis=-1)/255.).astype(np.float32)\n",
- "test_labels = (test_labels).astype(np.int64)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "5ZtUqOqePsRD"
- },
- "source": [
- "Our training set is made up of 28x28 grayscale images of handwritten digits.\n",
- "\n",
- "Let's visualize what some of these images and their corresponding training labels look like."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "bDBsR2lP_N8O",
- "scrolled": true
- },
- "outputs": [],
- "source": [
- "plt.figure(figsize=(10,10))\n",
- "random_inds = np.random.choice(60000,36)\n",
- "for i in range(36):\n",
- " plt.subplot(6,6,i+1)\n",
- " plt.xticks([])\n",
- " plt.yticks([])\n",
- " plt.grid(False)\n",
- " image_ind = random_inds[i]\n",
- " plt.imshow(np.squeeze(train_images[image_ind]), cmap=plt.cm.binary)\n",
- " plt.xlabel(train_labels[image_ind])\n",
- "comet_model_1.log_figure(figure=plt)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "V6hd3Nt1_N8q"
- },
- "source": [
- "## 1.2 Neural Network for Handwritten Digit Classification\n",
- "\n",
- "We'll first build a simple neural network consisting of two fully connected layers and apply this to the digit classification task. Our network will ultimately output a probability distribution over the 10 digit classes (0-9). This first architecture we will be building is depicted below:\n",
- "\n",
- "\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "rphS2rMIymyZ"
- },
- "source": [
- "### Fully connected neural network architecture\n",
- "To define the architecture of this first fully connected neural network, we'll once again use the Keras API and define the model using the [`Sequential`](https://www.tensorflow.org/api_docs/python/tf/keras/models/Sequential) class. Note how we first use a [`Flatten`](https://www.tensorflow.org/api_docs/python/tf/keras/layers/Flatten) layer, which flattens the input so that it can be fed into the model.\n",
- "\n",
- "In this next block, you'll define the fully connected layers of this simple work."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "MMZsbjAkDKpU"
- },
- "outputs": [],
- "source": [
- "def build_fc_model():\n",
- " fc_model = tf.keras.Sequential([\n",
- " # First define a Flatten layer\n",
- " tf.keras.layers.Flatten(),\n",
- "\n",
- " # '''TODO: Define the activation function for the first fully connected (Dense) layer.'''\n",
- " tf.keras.layers.Dense(128, activation=tf.nn.relu),\n",
- " # tf.keras.layers.Dense(128, activation= '''TODO'''),\n",
- "\n",
- " # '''TODO: Define the second Dense layer to output the classification probabilities'''\n",
- " tf.keras.layers.Dense(10, activation=tf.nn.softmax)\n",
- " # [TODO Dense layer to output classification probabilities]\n",
- "\n",
- " ])\n",
- " return fc_model\n",
- "\n",
- "model = build_fc_model()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "VtGZpHVKz5Jt"
- },
- "source": [
- "As we progress through this next portion, you may find that you'll want to make changes to the architecture defined above. **Note that in order to update the model later on, you'll need to re-run the above cell to re-initialize the model.**"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "mVN1_AeG_N9N"
- },
- "source": [
- "Let's take a step back and think about the network we've just created. The first layer in this network, `tf.keras.layers.Flatten`, transforms the format of the images from a 2d-array (28 x 28 pixels), to a 1d-array of 28 * 28 = 784 pixels. You can think of this layer as unstacking rows of pixels in the image and lining them up. There are no learned parameters in this layer; it only reformats the data.\n",
- "\n",
- "After the pixels are flattened, the network consists of a sequence of two `tf.keras.layers.Dense` layers. These are fully-connected neural layers. The first `Dense` layer has 128 nodes (or neurons). The second (and last) layer (which you've defined!) should return an array of probability scores that sum to 1. Each node contains a score that indicates the probability that the current image belongs to one of the handwritten digit classes.\n",
- "\n",
- "That defines our fully connected model!"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "gut8A_7rCaW6"
- },
- "source": [
- "\n",
- "\n",
- "### Compile the model\n",
- "\n",
- "Before training the model, we need to define a few more settings. These are added during the model's [`compile`](https://www.tensorflow.org/api_docs/python/tf/keras/models/Sequential#compile) step:\n",
- "\n",
- "* *Loss function* — This defines how we measure how accurate the model is during training. As was covered in lecture, during training we want to minimize this function, which will \"steer\" the model in the right direction.\n",
- "* *Optimizer* — This defines how the model is updated based on the data it sees and its loss function.\n",
- "* *Metrics* — Here we can define metrics used to monitor the training and testing steps. In this example, we'll look at the *accuracy*, the fraction of the images that are correctly classified.\n",
- "\n",
- "We'll start out by using a stochastic gradient descent (SGD) optimizer initialized with a learning rate of 0.1. Since we are performing a categorical classification task, we'll want to use the [cross entropy loss](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/sparse_categorical_crossentropy).\n",
- "\n",
- "You'll want to experiment with both the choice of optimizer and learning rate and evaluate how these affect the accuracy of the trained model."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "Lhan11blCaW7"
- },
- "outputs": [],
- "source": [
- "'''TODO: Experiment with different optimizers and learning rates. How do these affect\n",
- " the accuracy of the trained model? Which optimizers and/or learning rates yield\n",
- " the best performance?'''\n",
- "model.compile(optimizer=tf.keras.optimizers.SGD(learning_rate=1e-1),\n",
- " loss='sparse_categorical_crossentropy',\n",
- " metrics=['accuracy'])"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "qKF6uW-BCaW-"
- },
- "source": [
- "### Train the model\n",
- "\n",
- "We're now ready to train our model, which will involve feeding the training data (`train_images` and `train_labels`) into the model, and then asking it to learn the associations between images and labels. We'll also need to define the batch size and the number of epochs, or iterations over the MNIST dataset, to use during training.\n",
- "\n",
- "In Lab 1, we saw how we can use `GradientTape` to optimize losses and train models with stochastic gradient descent. After defining the model settings in the `compile` step, we can also accomplish training by calling the [`fit`](https://www.tensorflow.org/api_docs/python/tf/keras/models/Sequential#fit) method on an instance of the `Model` class. We will use this to train our fully connected model\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "EFMbIqIvQ2X0"
- },
- "outputs": [],
- "source": [
- "# Define the batch size and the number of epochs to use during training\n",
- "BATCH_SIZE = 64\n",
- "EPOCHS = 5\n",
- "\n",
- "model.fit(train_images, train_labels, batch_size=BATCH_SIZE, epochs=EPOCHS)\n",
- "comet_model_1.end()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "W3ZVOhugCaXA"
- },
- "source": [
- "As the model trains, the loss and accuracy metrics are displayed. With five epochs and a learning rate of 0.01, this fully connected model should achieve an accuracy of approximatley 0.97 (or 97%) on the training data."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "oEw4bZgGCaXB"
- },
- "source": [
- "### Evaluate accuracy on the test dataset\n",
- "\n",
- "Now that we've trained the model, we can ask it to make predictions about a test set that it hasn't seen before. In this example, the `test_images` array comprises our test dataset. To evaluate accuracy, we can check to see if the model's predictions match the labels from the `test_labels` array.\n",
- "\n",
- "Use the [`evaluate`](https://www.tensorflow.org/api_docs/python/tf/keras/models/Sequential#evaluate) method to evaluate the model on the test dataset!"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "VflXLEeECaXC"
- },
- "outputs": [],
- "source": [
- "'''TODO: Use the evaluate method to test the model!'''\n",
- "test_loss, test_acc = model.evaluate(test_images, test_labels) # TODO\n",
- "# test_loss, test_acc = # TODO\n",
- "\n",
- "print('Test accuracy:', test_acc)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "yWfgsmVXCaXG"
- },
- "source": [
- "You may observe that the accuracy on the test dataset is a little lower than the accuracy on the training dataset. This gap between training accuracy and test accuracy is an example of *overfitting*, when a machine learning model performs worse on new data than on its training data.\n",
- "\n",
- "What is the highest accuracy you can achieve with this first fully connected model? Since the handwritten digit classification task is pretty straightforward, you may be wondering how we can do better...\n",
- "\n",
- ""
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "baIw9bDf8v6Z"
- },
- "source": [
- "## 1.3 Convolutional Neural Network (CNN) for handwritten digit classification"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "_J72Yt1o_fY7"
- },
- "source": [
- "As we saw in lecture, convolutional neural networks (CNNs) are particularly well-suited for a variety of tasks in computer vision, and have achieved near-perfect accuracies on the MNIST dataset. We will now build a CNN composed of two convolutional layers and pooling layers, followed by two fully connected layers, and ultimately output a probability distribution over the 10 digit classes (0-9). The CNN we will be building is depicted below:\n",
- "\n",
- ""
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "EEHqzbJJAEoR"
- },
- "source": [
- "### Define the CNN model\n",
- "\n",
- "We'll use the same training and test datasets as before, and proceed similarly as our fully connected network to define and train our new CNN model. To do this we will explore two layers we have not encountered before: you can use [`keras.layers.Conv2D` ](https://www.tensorflow.org/api_docs/python/tf/keras/layers/Conv2D) to define convolutional layers and [`keras.layers.MaxPool2D`](https://www.tensorflow.org/api_docs/python/tf/keras/layers/MaxPool2D) to define the pooling layers. Use the parameters shown in the network architecture above to define these layers and build the CNN model."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "vec9qcJs-9W5"
- },
- "outputs": [],
- "source": [
- "def build_cnn_model():\n",
- " cnn_model = tf.keras.Sequential([\n",
- "\n",
- " # TODO: Define the first convolutional layer\n",
- " tf.keras.layers.Conv2D(filters=24, kernel_size=(3,3), activation=tf.nn.relu),\n",
- " # tf.keras.layers.Conv2D('''TODO''')\n",
- "\n",
- " # TODO: Define the first max pooling layer\n",
- " tf.keras.layers.MaxPool2D(pool_size=(2,2)),\n",
- " # tf.keras.layers.MaxPool2D('''TODO''')\n",
- "\n",
- " # TODO: Define the second convolutional layer\n",
- " tf.keras.layers.Conv2D(filters=36, kernel_size=(3,3), activation=tf.nn.relu),\n",
- " # tf.keras.layers.Conv2D('''TODO''')\n",
- "\n",
- " # TODO: Define the second max pooling layer\n",
- " tf.keras.layers.MaxPool2D(pool_size=(2,2)),\n",
- " # tf.keras.layers.MaxPool2D('''TODO''')\n",
- "\n",
- " tf.keras.layers.Flatten(),\n",
- " tf.keras.layers.Dense(128, activation=tf.nn.relu),\n",
- "\n",
- " # TODO: Define the last Dense layer to output the classification\n",
- " # probabilities. Pay attention to the activation needed a probability\n",
- " # output\n",
- " tf.keras.layers.Dense(10, activation=tf.nn.softmax)\n",
- " # [TODO Dense layer to output classification probabilities]\n",
- " ])\n",
- "\n",
- " return cnn_model\n",
- "\n",
- "cnn_model = build_cnn_model()\n",
- "# Initialize the model by passing some data through\n",
- "cnn_model.predict(train_images[[0]])\n",
- "# Print the summary of the layers in the model.\n",
- "print(cnn_model.summary())"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "kUAXIBynCih2"
- },
- "source": [
- "### Train and test the CNN model\n",
- "\n",
- "Now, as before, we can define the loss function, optimizer, and metrics through the `compile` method. Compile the CNN model with an optimizer and learning rate of choice:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "vheyanDkCg6a"
- },
- "outputs": [],
- "source": [
- "comet_ml.init(project_name=\"6.s191lab2_part1_CNN\")\n",
- "comet_model_2 = comet_ml.Experiment()\n",
- "\n",
- "'''TODO: Define the compile operation with your optimizer and learning rate of choice'''\n",
- "cnn_model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=1e-3),\n",
- " loss='sparse_categorical_crossentropy',\n",
- " metrics=['accuracy'])\n",
- "# cnn_model.compile(optimizer='''TODO''', loss='''TODO''', metrics=['accuracy']) # TODO"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "U19bpRddC7H_"
- },
- "source": [
- "As was the case with the fully connected model, we can train our CNN using the `fit` method via the Keras API."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "YdrGZVmWDK4p"
- },
- "outputs": [],
- "source": [
- "'''TODO: Use model.fit to train the CNN model, with the same batch_size and number of epochs previously used.'''\n",
- "cnn_model.fit(train_images, train_labels, batch_size=BATCH_SIZE, epochs=EPOCHS)\n",
- "# cnn_model.fit('''TODO''')\n",
- "# comet_model_2.end()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "pEszYWzgDeIc"
- },
- "source": [
- "Great! Now that we've trained the model, let's evaluate it on the test dataset using the [`evaluate`](https://www.tensorflow.org/api_docs/python/tf/keras/models/Sequential#evaluate) method:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "JDm4znZcDtNl"
- },
- "outputs": [],
- "source": [
- "'''TODO: Use the evaluate method to test the model!'''\n",
- "test_loss, test_acc = cnn_model.evaluate(test_images, test_labels)\n",
- "# test_loss, test_acc = # TODO\n",
- "\n",
- "print('Test accuracy:', test_acc)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "2rvEgK82Glv9"
- },
- "source": [
- "What is the highest accuracy you're able to achieve using the CNN model, and how does the accuracy of the CNN model compare to the accuracy of the simple fully connected network? What optimizers and learning rates seem to be optimal for training the CNN model?\n",
- "\n",
- "Feel free to click the Comet links to investigate the training/accuracy curves for your model."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "xsoS7CPDCaXH"
- },
- "source": [
- "### Make predictions with the CNN model\n",
- "\n",
- "With the model trained, we can use it to make predictions about some images. The [`predict`](https://www.tensorflow.org/api_docs/python/tf/keras/models/Sequential#predict) function call generates the output predictions given a set of input samples.\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "Gl91RPhdCaXI"
- },
- "outputs": [],
- "source": [
- "predictions = cnn_model.predict(test_images)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "x9Kk1voUCaXJ"
- },
- "source": [
- "With this function call, the model has predicted the label for each image in the testing set. Let's take a look at the prediction for the first image in the test dataset:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "3DmJEUinCaXK"
- },
- "outputs": [],
- "source": [
- "predictions[0]"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "-hw1hgeSCaXN"
- },
- "source": [
- "As you can see, a prediction is an array of 10 numbers. Recall that the output of our model is a probability distribution over the 10 digit classes. Thus, these numbers describe the model's \"confidence\" that the image corresponds to each of the 10 different digits.\n",
- "\n",
- "Let's look at the digit that has the highest confidence for the first image in the test dataset:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "qsqenuPnCaXO"
- },
- "outputs": [],
- "source": [
- "'''TODO: identify the digit with the highest confidence prediction for the first\n",
- " image in the test dataset. '''\n",
- "prediction = np.argmax(predictions[0])\n",
- "# prediction = # TODO\n",
- "\n",
- "print(prediction)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "E51yS7iCCaXO"
- },
- "source": [
- "So, the model is most confident that this image is a \"???\". We can check the test label (remember, this is the true identity of the digit) to see if this prediction is correct:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "Sd7Pgsu6CaXP"
- },
- "outputs": [],
- "source": [
- "print(\"Label of this digit is:\", test_labels[0])\n",
- "plt.imshow(test_images[0,:,:,0], cmap=plt.cm.binary)\n",
- "comet_model_2.log_figure(figure=plt)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "ygh2yYC972ne"
- },
- "source": [
- "It is! Let's visualize the classification results on the MNIST dataset. We will plot images from the test dataset along with their predicted label, as well as a histogram that provides the prediction probabilities for each of the digits:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "HV5jw-5HwSmO"
- },
- "outputs": [],
- "source": [
- "#@title Change the slider to look at the model's predictions! { run: \"auto\" }\n",
- "\n",
- "image_index = 79 #@param {type:\"slider\", min:0, max:100, step:1}\n",
- "plt.subplot(1,2,1)\n",
- "mdl.lab2.plot_image_prediction(image_index, predictions, test_labels, test_images)\n",
- "plt.subplot(1,2,2)\n",
- "mdl.lab2.plot_value_prediction(image_index, predictions, test_labels)\n",
- "comet_model_2.log_figure(figure=plt)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "kgdvGD52CaXR"
- },
- "source": [
- "We can also plot several images along with their predictions, where correct prediction labels are blue and incorrect prediction labels are grey. The number gives the percent confidence (out of 100) for the predicted label. Note the model can be very confident in an incorrect prediction!"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "hQlnbqaw2Qu_"
- },
- "outputs": [],
- "source": [
- "# Plots the first X test images, their predicted label, and the true label\n",
- "# Color correct predictions in blue, incorrect predictions in red\n",
- "num_rows = 5\n",
- "num_cols = 4\n",
- "num_images = num_rows*num_cols\n",
- "plt.figure(figsize=(2*2*num_cols, 2*num_rows))\n",
- "for i in range(num_images):\n",
- " plt.subplot(num_rows, 2*num_cols, 2*i+1)\n",
- " mdl.lab2.plot_image_prediction(i, predictions, test_labels, test_images)\n",
- " plt.subplot(num_rows, 2*num_cols, 2*i+2)\n",
- " mdl.lab2.plot_value_prediction(i, predictions, test_labels)\n",
- "comet_model_2.log_figure(figure=plt)\n",
- "comet_model_2.end()\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "k-2glsRiMdqa"
- },
- "source": [
- "## 1.4 Training the model 2.0\n",
- "\n",
- "Earlier in the lab, we used the [`fit`](https://www.tensorflow.org/api_docs/python/tf/keras/models/Sequential#fit) function call to train the model. This function is quite high-level and intuitive, which is really useful for simpler models. As you may be able to tell, this function abstracts away many details in the training call, and we have less control over training model, which could be useful in other contexts.\n",
- "\n",
- "As an alternative to this, we can use the [`tf.GradientTape`](https://www.tensorflow.org/api_docs/python/tf/GradientTape) class to record differentiation operations during training, and then call the [`tf.GradientTape.gradient`](https://www.tensorflow.org/api_docs/python/tf/GradientTape#gradient) function to actually compute the gradients. You may recall seeing this in Lab 1 Part 1, but let's take another look at this here.\n",
- "\n",
- "We'll use this framework to train our `cnn_model` using stochastic gradient descent."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "Wq34id-iN1Ml"
- },
- "outputs": [],
- "source": [
- "# Rebuild the CNN model\n",
- "cnn_model = build_cnn_model()\n",
- "\n",
- "batch_size = 12\n",
- "loss_history = mdl.util.LossHistory(smoothing_factor=0.95) # to record the evolution of the loss\n",
- "plotter = mdl.util.PeriodicPlotter(sec=2, xlabel='Iterations', ylabel='Loss', scale='semilogy')\n",
- "optimizer = tf.keras.optimizers.SGD(learning_rate=1e-2) # define our optimizer\n",
- "\n",
- "comet_ml.init(project_name=\"6.s191lab2_part1_CNN2\")\n",
- "comet_model_3 = comet_ml.Experiment()\n",
- "\n",
- "if hasattr(tqdm, '_instances'): tqdm._instances.clear() # clear if it exists\n",
- "\n",
- "for idx in tqdm(range(0, train_images.shape[0], batch_size)):\n",
- " # First grab a batch of training data and convert the input images to tensors\n",
- " (images, labels) = (train_images[idx:idx+batch_size], train_labels[idx:idx+batch_size])\n",
- " images = tf.convert_to_tensor(images, dtype=tf.float32)\n",
- "\n",
- " # GradientTape to record differentiation operations\n",
- " with tf.GradientTape() as tape:\n",
- " #'''TODO: feed the images into the model and obtain the predictions'''\n",
- " logits = cnn_model(images)\n",
- " # logits = # TODO\n",
- "\n",
- " #'''TODO: compute the categorical cross entropy loss\n",
- " loss_value = tf.keras.backend.sparse_categorical_crossentropy(labels, logits)\n",
- " comet_model_3.log_metric(\"loss\", loss_value.numpy().mean(), step=idx)\n",
- " # loss_value = tf.keras.backend.sparse_categorical_crossentropy('''TODO''', '''TODO''') # TODO\n",
- "\n",
- " loss_history.append(loss_value.numpy().mean()) # append the loss to the loss_history record\n",
- " plotter.plot(loss_history.get())\n",
- "\n",
- " # Backpropagation\n",
- " '''TODO: Use the tape to compute the gradient against all parameters in the CNN model.\n",
- " Use cnn_model.trainable_variables to access these parameters.'''\n",
- " grads = tape.gradient(loss_value, cnn_model.trainable_variables)\n",
- " # grads = # TODO\n",
- " optimizer.apply_gradients(zip(grads, cnn_model.trainable_variables))\n",
- "\n",
- "comet_model_3.log_figure(figure=plt)\n",
- "comet_model_3.end()\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "3cNtDhVaqEdR"
- },
- "source": [
- "## 1.5 Conclusion\n",
- "In this part of the lab, you had the chance to play with different MNIST classifiers with different architectures (fully-connected layers only, CNN), and experiment with how different hyperparameters affect accuracy (learning rate, etc.). The next part of the lab explores another application of CNNs, facial detection, and some drawbacks of AI systems in real world applications, like issues of bias."
- ]
- }
- ],
- "metadata": {
- "accelerator": "GPU",
- "colab": {
- "collapsed_sections": [
- "Xmf_JRJa_N8C"
- ],
- "name": "TF_Part1_MNIST_Solution.ipynb",
- "provenance": []
- },
- "kernelspec": {
- "display_name": "Python 3",
- "name": "python3"
- },
- "language_info": {
- "codemirror_mode": {
- "name": "ipython",
- "version": 3
- },
- "file_extension": ".py",
- "mimetype": "text/x-python",
- "name": "python",
- "nbconvert_exporter": "python",
- "pygments_lexer": "ipython3",
- "version": "3.9.6"
- }
- },
- "nbformat": 4,
- "nbformat_minor": 0
-}
diff --git a/lab2/solutions/TF_Part2_Debiasing_Solution.ipynb b/lab2/solutions/TF_Part2_Debiasing_Solution.ipynb
deleted file mode 100644
index d6ccba60..00000000
--- a/lab2/solutions/TF_Part2_Debiasing_Solution.ipynb
+++ /dev/null
@@ -1,1166 +0,0 @@
-{
- "nbformat": 4,
- "nbformat_minor": 0,
- "metadata": {
- "colab": {
- "name": "TF_Part2_Debiasing_Solution.ipynb",
- "provenance": [],
- "collapsed_sections": [
- "Ag_e7xtTzT1W",
- "NDj7KBaW8Asz"
- ]
- },
- "kernelspec": {
- "name": "python3",
- "display_name": "Python 3"
- },
- "accelerator": "GPU"
- },
- "cells": [
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Ag_e7xtTzT1W"
- },
- "source": [
- "\n",
- "\n",
- "# Copyright Information"
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "rNbf1pRlSDby"
- },
- "source": [
- "# Copyright 2025 MIT 6.S191 Introduction to Deep Learning. All Rights Reserved.\n",
- "#\n",
- "# Licensed under the MIT License. You may not use this file except in compliance\n",
- "# with the License. Use and/or modification of this code outside of 6.S191 must\n",
- "# reference:\n",
- "#\n",
- "# © MIT 6.S191: Introduction to Deep Learning\n",
- "# http://introtodeeplearning.com\n",
- "#"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "QOpPUH3FR179"
- },
- "source": [
- "# Laboratory 2: Computer Vision\n",
- "\n",
- "# Part 2: Debiasing Facial Detection Systems\n",
- "\n",
- "In the second portion of the lab, we'll explore two prominent aspects of applied deep learning: facial detection and algorithmic bias.\n",
- "\n",
- "Deploying fair, unbiased AI systems is critical to their long-term acceptance. Consider the task of facial detection: given an image, is it an image of a face? This seemingly simple, but extremely important, task is subject to significant amounts of algorithmic bias among select demographics.\n",
- "\n",
- "In this lab, we'll investigate [one recently published approach](http://introtodeeplearning.com/AAAI_MitigatingAlgorithmicBias.pdf) to addressing algorithmic bias. We'll build a facial detection model that learns the *latent variables* underlying face image datasets and uses this to adaptively re-sample the training data, thus mitigating any biases that may be present in order to train a *debiased* model.\n",
- "\n",
- "\n",
- "Run the next code block for a short video from Google that explores how and why it's important to consider bias when thinking about machine learning:"
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "XQh5HZfbupFF"
- },
- "source": [
- "import IPython\n",
- "IPython.display.YouTubeVideo('59bMh59JQDo')"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "3Ezfc6Yv6IhI"
- },
- "source": [
- "Let's get started by installing the relevant dependencies.\n",
- "\n",
- "We will be using Comet ML to track our model development and training runs.\n",
- "\n",
- "1. Sign up for a Comet account: [HERE](https://www.comet.com/signup?utm_source=mit_dl&utm_medium=partner&utm_content=github)\n",
- "2. This will generate a personal API Key, which you can find either in the first 'Get Started with Comet' page, under your account settings, or by pressing the '?' in the top right corner and then 'Quickstart Guide'. Enter this API key as the global variable `COMET_API_KEY` below.\n",
- "\n"
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "E46sWVKK6LP9"
- },
- "source": [
- "!pip install comet_ml --quiet\n",
- "import comet_ml\n",
- "# TODO: ENTER YOUR API KEY HERE!! instructions above\n",
- "COMET_API_KEY = \"\"\n",
- "\n",
- "# Import Tensorflow 2.0\n",
- "import tensorflow as tf\n",
- "\n",
- "import IPython\n",
- "import functools\n",
- "import matplotlib.pyplot as plt\n",
- "import numpy as np\n",
- "from tqdm import tqdm\n",
- "\n",
- "# Download and import the MIT 6.S191 package\n",
- "!pip install mitdeeplearning --quiet\n",
- "import mitdeeplearning as mdl\n",
- "\n",
- "# Check that we are using a GPU, if not switch runtimes\n",
- "# using Runtime > Change Runtime Type > GPU\n",
- "assert len(tf.config.list_physical_devices('GPU')) > 0\n",
- "assert COMET_API_KEY != \"\", \"Please insert your Comet API Key\""
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "V0e77oOM3udR"
- },
- "source": [
- "## 2.1 Datasets\n",
- "\n",
- "We'll be using three datasets in this lab. In order to train our facial detection models, we'll need a dataset of positive examples (i.e., of faces) and a dataset of negative examples (i.e., of things that are not faces). We'll use these data to train our models to classify images as either faces or not faces. Finally, we'll need a test dataset of face images. Since we're concerned about the potential *bias* of our learned models against certain demographics, it's important that the test dataset we use has equal representation across the demographics or features of interest. In this lab, we'll consider skin tone and gender.\n",
- "\n",
- "1. **Positive training data**: [CelebA Dataset](http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html). A large-scale (over 200K images) of celebrity faces. \n",
- "2. **Negative training data**: [ImageNet](http://www.image-net.org/). Many images across many different categories. We'll take negative examples from a variety of non-human categories.\n",
- "[Fitzpatrick Scale](https://en.wikipedia.org/wiki/Fitzpatrick_scale) skin type classification system, with each image labeled as \"Lighter'' or \"Darker''.\n",
- "\n",
- "Let's begin by importing these datasets. We've written a class that does a bit of data pre-processing to import the training data in a usable format."
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "RWXaaIWy6jVw"
- },
- "source": [
- "# Get the training data: both images from CelebA and ImageNet\n",
- "path_to_training_data = tf.keras.utils.get_file('train_face.h5', 'https://www.dropbox.com/s/hlz8atheyozp1yx/train_face.h5?dl=1')\n",
- "# Instantiate a TrainingDatasetLoader using the downloaded dataset\n",
- "loader = mdl.lab2.TrainingDatasetLoader(path_to_training_data)"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "yIE321rxa_b3"
- },
- "source": [
- "We can look at the size of the training dataset and grab a batch of size 100:"
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "DjPSjZZ_bGqe"
- },
- "source": [
- "number_of_training_examples = loader.get_train_size()\n",
- "(images, labels) = loader.get_batch(100)"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "sxtkJoqF6oH1"
- },
- "source": [
- "Play around with displaying images to get a sense of what the training data actually looks like!"
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "Jg17jzwtbxDA"
- },
- "source": [
- "### Examining the CelebA training dataset ###\n",
- "\n",
- "#@title Change the sliders to look at positive and negative training examples! { run: \"auto\" }\n",
- "\n",
- "face_images = images[np.where(labels==1)[0]]\n",
- "not_face_images = images[np.where(labels==0)[0]]\n",
- "\n",
- "idx_face = 23 #@param {type:\"slider\", min:0, max:50, step:1}\n",
- "idx_not_face = 9 #@param {type:\"slider\", min:0, max:50, step:1}\n",
- "\n",
- "plt.figure(figsize=(5,5))\n",
- "plt.subplot(1, 2, 1)\n",
- "plt.imshow(face_images[idx_face])\n",
- "plt.title(\"Face\"); plt.grid(False)\n",
- "\n",
- "plt.subplot(1, 2, 2)\n",
- "plt.imshow(not_face_images[idx_not_face])\n",
- "plt.title(\"Not Face\"); plt.grid(False)"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "NDj7KBaW8Asz"
- },
- "source": [
- "### Thinking about bias\n",
- "\n",
- "Remember we'll be training our facial detection classifiers on the large, well-curated CelebA dataset (and ImageNet), and then evaluating their accuracy by testing them on an independent test dataset. Our goal is to build a model that trains on CelebA *and* achieves high classification accuracy on the the test dataset across all demographics, and to thus show that this model does not suffer from any hidden bias.\n",
- "\n",
- "What exactly do we mean when we say a classifier is biased? In order to formalize this, we'll need to think about [*latent variables*](https://en.wikipedia.org/wiki/Latent_variable), variables that define a dataset but are not strictly observed. As defined in the generative modeling lecture, we'll use the term *latent space* to refer to the probability distributions of the aforementioned latent variables. Putting these ideas together, we consider a classifier *biased* if its classification decision changes after it sees some additional latent features. This notion of bias may be helpful to keep in mind throughout the rest of the lab."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "AIFDvU4w8OIH"
- },
- "source": [
- "## 2.2 CNN for facial detection\n",
- "\n",
- "First, we'll define and train a CNN on the facial classification task, and evaluate its accuracy. Later, we'll evaluate the performance of our debiased models against this baseline CNN. The CNN model has a relatively standard architecture consisting of a series of convolutional layers with batch normalization followed by two fully connected layers to flatten the convolution output and generate a class prediction.\n",
- "\n",
- "### Define and train the CNN model\n",
- "\n",
- "Like we did in the first part of the lab, we'll define our CNN model, and then train on the CelebA and ImageNet datasets using the `tf.GradientTape` class and the `tf.GradientTape.gradient` method."
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "82EVTAAW7B_X"
- },
- "source": [
- "### Define the CNN model ###\n",
- "\n",
- "n_filters = 12 # base number of convolutional filters\n",
- "\n",
- "'''Function to define a standard CNN model'''\n",
- "def make_standard_classifier(n_outputs=1):\n",
- " Conv2D = functools.partial(tf.keras.layers.Conv2D, padding='same', activation='relu')\n",
- " BatchNormalization = tf.keras.layers.BatchNormalization\n",
- " Flatten = tf.keras.layers.Flatten\n",
- " Dense = functools.partial(tf.keras.layers.Dense, activation='relu')\n",
- "\n",
- " model = tf.keras.Sequential([\n",
- " Conv2D(filters=1*n_filters, kernel_size=5, strides=2),\n",
- " BatchNormalization(),\n",
- "\n",
- " Conv2D(filters=2*n_filters, kernel_size=5, strides=2),\n",
- " BatchNormalization(),\n",
- "\n",
- " Conv2D(filters=4*n_filters, kernel_size=3, strides=2),\n",
- " BatchNormalization(),\n",
- "\n",
- " Conv2D(filters=6*n_filters, kernel_size=3, strides=2),\n",
- " BatchNormalization(),\n",
- "\n",
- " Flatten(),\n",
- " Dense(512),\n",
- " Dense(n_outputs, activation=None),\n",
- " ])\n",
- " return model\n",
- "\n",
- "standard_classifier = make_standard_classifier()"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "c-eWf3l_lCri"
- },
- "source": [
- "Now let's train the standard CNN!"
- ]
- },
- {
- "cell_type": "code",
- "source": [
- "### Create a Comet experiment to track our training run ###\n",
- "def create_experiment(project_name, params):\n",
- " # end any prior experiments\n",
- " if 'experiment' in locals():\n",
- " experiment.end()\n",
- "\n",
- " # initiate the comet experiment for tracking\n",
- " experiment = comet_ml.Experiment(\n",
- " api_key=COMET_API_KEY,\n",
- " project_name=project_name)\n",
- " # log our hyperparameters, defined above, to the experiment\n",
- " for param, value in params.items():\n",
- " experiment.log_parameter(param, value)\n",
- " experiment.flush()\n",
- "\n",
- " return experiment\n"
- ],
- "metadata": {
- "id": "mi-04SAfK6lm"
- },
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "eJlDGh1o31G1"
- },
- "source": [
- "### Train the standard CNN ###\n",
- "\n",
- "# Training hyperparameters\n",
- "params = dict(\n",
- " batch_size = 32,\n",
- " num_epochs = 2, # keep small to run faster\n",
- " learning_rate = 5e-4,\n",
- ")\n",
- "\n",
- "experiment = create_experiment(\"6S191_Lab2_Part2_CNN\", params)\n",
- "\n",
- "optimizer = tf.keras.optimizers.Adam(params[\"learning_rate\"]) # define our optimizer\n",
- "loss_history = mdl.util.LossHistory(smoothing_factor=0.99) # to record loss evolution\n",
- "plotter = mdl.util.PeriodicPlotter(sec=2, scale='semilogy')\n",
- "if hasattr(tqdm, '_instances'): tqdm._instances.clear() # clear if it exists\n",
- "\n",
- "@tf.function\n",
- "def standard_train_step(x, y):\n",
- " with tf.GradientTape() as tape:\n",
- " # feed the images into the model\n",
- " logits = standard_classifier(x)\n",
- " # Compute the loss\n",
- " loss = tf.nn.sigmoid_cross_entropy_with_logits(labels=y, logits=logits)\n",
- "\n",
- " # Backpropagation\n",
- " grads = tape.gradient(loss, standard_classifier.trainable_variables)\n",
- " optimizer.apply_gradients(zip(grads, standard_classifier.trainable_variables))\n",
- " return loss\n",
- "\n",
- "# The training loop!\n",
- "step = 0\n",
- "for epoch in range(params[\"num_epochs\"]):\n",
- " for idx in tqdm(range(loader.get_train_size()//params[\"batch_size\"])):\n",
- " # Grab a batch of training data and propagate through the network\n",
- " x, y = loader.get_batch(params[\"batch_size\"])\n",
- " loss = standard_train_step(x, y)\n",
- "\n",
- " # Record the loss and plot the evolution of the loss as a function of training\n",
- " loss_history.append(loss.numpy().mean())\n",
- " plotter.plot(loss_history.get())\n",
- "\n",
- " experiment.log_metric(\"loss\", loss.numpy().mean(), step=step)\n",
- " step += 1"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "AKMdWVHeCxj8"
- },
- "source": [
- "### Evaluate performance of the standard CNN\n",
- "\n",
- "Next, let's evaluate the classification performance of our CelebA-trained standard CNN on the training dataset.\n"
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "35-PDgjdWk6_"
- },
- "source": [
- "### Evaluation of standard CNN ###\n",
- "\n",
- "# TRAINING DATA\n",
- "# Evaluate on a subset of CelebA+Imagenet\n",
- "(batch_x, batch_y) = loader.get_batch(5000)\n",
- "y_pred_standard = tf.round(tf.nn.sigmoid(standard_classifier.predict(batch_x)))\n",
- "acc_standard = tf.reduce_mean(tf.cast(tf.equal(batch_y, y_pred_standard), tf.float32))\n",
- "\n",
- "print(\"Standard CNN accuracy on (potentially biased) training set: {:.4f}\".format(acc_standard.numpy()))"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Qu7R14KaEEvU"
- },
- "source": [
- "We will also evaluate our networks on an independent test dataset containing faces that were not seen during training. For the test data, we'll look at the classification accuracy across four different demographics, based on the Fitzpatrick skin scale and sex-based labels: dark-skinned male, dark-skinned female, light-skinned male, and light-skinned female.\n",
- "\n",
- "Let's take a look at some sample faces in the test set."
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "vfDD8ztGWk6x"
- },
- "source": [
- "### Load test dataset and plot examples ###\n",
- "\n",
- "test_faces = mdl.lab2.get_test_faces()\n",
- "keys = [\"Light Female\", \"Light Male\", \"Dark Female\", \"Dark Male\"]\n",
- "for group, key in zip(test_faces,keys):\n",
- " plt.figure(figsize=(5,5))\n",
- " plt.imshow(np.hstack(group))\n",
- " plt.title(key, fontsize=15)"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "uo1z3cdbEUMM"
- },
- "source": [
- "Now, let's evaluate the probability of each of these face demographics being classified as a face using the standard CNN classifier we've just trained."
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "GI4O0Y1GAot9"
- },
- "source": [
- "### Evaluate the standard CNN on the test data ###\n",
- "\n",
- "standard_classifier_logits = [standard_classifier(np.array(x, dtype=np.float32)) for x in test_faces]\n",
- "standard_classifier_probs = tf.squeeze(tf.sigmoid(standard_classifier_logits))\n",
- "\n",
- "# Plot the prediction accuracies per demographic\n",
- "xx = range(len(keys))\n",
- "yy = standard_classifier_probs.numpy().mean(1)\n",
- "plt.bar(xx, yy)\n",
- "plt.xticks(xx, keys)\n",
- "plt.ylim(max(0,yy.min()-yy.ptp()/2.), yy.max()+yy.ptp()/2.)\n",
- "plt.title(\"Standard classifier predictions\");"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "j0Cvvt90DoAm"
- },
- "source": [
- "Take a look at the accuracies for this first model across these four groups. What do you observe? Would you consider this model biased or unbiased? What are some reasons why a trained model may have biased accuracies?"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "0AKcHnXVtgqJ"
- },
- "source": [
- "## 2.3 Mitigating algorithmic bias\n",
- "\n",
- "Imbalances in the training data can result in unwanted algorithmic bias. For example, the majority of faces in CelebA (our training set) are those of light-skinned females. As a result, a classifier trained on CelebA will be better suited at recognizing and classifying faces with features similar to these, and will thus be biased.\n",
- "\n",
- "How could we overcome this? A naive solution -- and one that is being adopted by many companies and organizations -- would be to annotate different subclasses (i.e., light-skinned females, males with hats, etc.) within the training data, and then manually even out the data with respect to these groups.\n",
- "\n",
- "But this approach has two major disadvantages. First, it requires annotating massive amounts of data, which is not scalable. Second, it requires that we know what potential biases (e.g., race, gender, pose, occlusion, hats, glasses, etc.) to look for in the data. As a result, manual annotation may not capture all the different features that are imbalanced within the training data.\n",
- "\n",
- "Instead, let's actually **learn** these features in an unbiased, unsupervised manner, without the need for any annotation, and then train a classifier fairly with respect to these features. In the rest of this lab, we'll do exactly that."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "nLemS7dqECsI"
- },
- "source": [
- "## 2.4 Variational autoencoder (VAE) for learning latent structure\n",
- "\n",
- "As you saw, the accuracy of the CNN varies across the four demographics we looked at. To think about why this may be, consider the dataset the model was trained on, CelebA. If certain features, such as dark skin or hats, are *rare* in CelebA, the model may end up biased against these as a result of training with a biased dataset. That is to say, its classification accuracy will be worse on faces that have under-represented features, such as dark-skinned faces or faces with hats, relevative to faces with features well-represented in the training data! This is a problem.\n",
- "\n",
- "Our goal is to train a *debiased* version of this classifier -- one that accounts for potential disparities in feature representation within the training data. Specifically, to build a debiased facial classifier, we'll train a model that **learns a representation of the underlying latent space** to the face training data. The model then uses this information to mitigate unwanted biases by sampling faces with rare features, like dark skin or hats, *more frequently* during training. The key design requirement for our model is that it can learn an *encoding* of the latent features in the face data in an entirely *unsupervised* way. To achieve this, we'll turn to variational autoencoders (VAEs).\n",
- "\n",
- "\n",
- "\n",
- "As shown in the schematic above and in Lecture 4, VAEs rely on an encoder-decoder structure to learn a latent representation of the input data. In the context of computer vision, the encoder network takes in input images, encodes them into a series of variables defined by a mean and standard deviation, and then draws from the distributions defined by these parameters to generate a set of sampled latent variables. The decoder network then \"decodes\" these variables to generate a reconstruction of the original image, which is used during training to help the model identify which latent variables are important to learn.\n",
- "\n",
- "Let's formalize two key aspects of the VAE model and define relevant functions for each.\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "KmbXKtcPkTXA"
- },
- "source": [
- "### Understanding VAEs: loss function\n",
- "\n",
- "In practice, how can we train a VAE? In learning the latent space, we constrain the means and standard deviations to approximately follow a unit Gaussian. Recall that these are learned parameters, and therefore must factor into the loss computation, and that the decoder portion of the VAE is using these parameters to output a reconstruction that should closely match the input image, which also must factor into the loss. What this means is that we'll have two terms in our VAE loss function:\n",
- "\n",
- "1. **Latent loss ($L_{KL}$)**: measures how closely the learned latent variables match a unit Gaussian and is defined by the Kullback-Leibler (KL) divergence.\n",
- "2. **Reconstruction loss ($L_{x}{(x,\\hat{x})}$)**: measures how accurately the reconstructed outputs match the input and is given by the $L^1$ norm of the input image and its reconstructed output."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Ux3jK2wc153s"
- },
- "source": [
- "The equation for the latent loss is provided by:\n",
- "\n",
- "$$L_{KL}(\\mu, \\sigma) = \\frac{1}{2}\\sum_{j=0}^{k-1} (\\sigma_j + \\mu_j^2 - 1 - \\log{\\sigma_j})$$\n",
- "\n",
- "The equation for the reconstruction loss is provided by:\n",
- "\n",
- "$$L_{x}{(x,\\hat{x})} = ||x-\\hat{x}||_1$$\n",
- "\n",
- "Thus for the VAE loss we have:\n",
- "\n",
- "$$L_{VAE} = c\\cdot L_{KL} + L_{x}{(x,\\hat{x})}$$\n",
- "\n",
- "where $c$ is a weighting coefficient used for regularization. Now we're ready to define our VAE loss function:"
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "S00ASo1ImSuh"
- },
- "source": [
- "### Defining the VAE loss function ###\n",
- "\n",
- "''' Function to calculate VAE loss given:\n",
- " an input x,\n",
- " reconstructed output x_recon,\n",
- " encoded means mu,\n",
- " encoded log of standard deviation logsigma,\n",
- " weight parameter for the latent loss kl_weight\n",
- "'''\n",
- "def vae_loss_function(x, x_recon, mu, logsigma, kl_weight=0.0005):\n",
- " # TODO: Define the latent loss. Note this is given in the equation for L_{KL}\n",
- " # in the text block directly above\n",
- " latent_loss = 0.5 * tf.reduce_sum(tf.exp(logsigma) + tf.square(mu) - 1.0 - logsigma, axis=1)\n",
- " # latent_loss = # TODO\n",
- "\n",
- " # TODO: Define the reconstruction loss as the mean absolute pixel-wise\n",
- " # difference between the input and reconstruction. Hint: you'll need to\n",
- " # use tf.reduce_mean, and supply an axis argument which specifies which\n",
- " # dimensions to reduce over. For example, reconstruction loss needs to average\n",
- " # over the height, width, and channel image dimensions.\n",
- " # https://www.tensorflow.org/api_docs/python/tf/math/reduce_mean\n",
- " reconstruction_loss = tf.reduce_mean(tf.abs(x-x_recon), axis=(1,2,3))\n",
- " # reconstruction_loss = # TODO\n",
- "\n",
- " # TODO: Define the VAE loss. Note this is given in the equation for L_{VAE}\n",
- " # in the text block directly above\n",
- " vae_loss = kl_weight * latent_loss + reconstruction_loss\n",
- " # vae_loss = # TODO\n",
- "\n",
- " return vae_loss"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "E8mpb3pJorpu"
- },
- "source": [
- "Great! Now that we have a more concrete sense of how VAEs work, let's explore how we can leverage this network structure to train a *debiased* facial classifier."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "DqtQH4S5fO8F"
- },
- "source": [
- "### Understanding VAEs: reparameterization\n",
- "\n",
- "As you may recall from lecture, VAEs use a \"reparameterization trick\" for sampling learned latent variables. Instead of the VAE encoder generating a single vector of real numbers for each latent variable, it generates a vector of means and a vector of standard deviations that are constrained to roughly follow Gaussian distributions. We then sample from the standard deviations and add back the mean to output this as our sampled latent vector. Formalizing this for a latent variable $z$ where we sample $\\epsilon \\sim N(0,(I))$ we have:\n",
- "\n",
- "$$z = \\mu + e^{\\left(\\frac{1}{2} \\cdot \\log{\\Sigma}\\right)}\\circ \\epsilon$$\n",
- "\n",
- "where $\\mu$ is the mean and $\\Sigma$ is the covariance matrix. This is useful because it will let us neatly define the loss function for the VAE, generate randomly sampled latent variables, achieve improved network generalization, **and** make our complete VAE network differentiable so that it can be trained via backpropagation. Quite powerful!\n",
- "\n",
- "Let's define a function to implement the VAE sampling operation:"
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "cT6PGdNajl3K"
- },
- "source": [
- "### VAE Reparameterization ###\n",
- "\n",
- "\"\"\"Reparameterization trick by sampling from an isotropic unit Gaussian.\n",
- "# Arguments\n",
- " z_mean, z_logsigma (tensor): mean and log of standard deviation of latent distribution (Q(z|X))\n",
- "# Returns\n",
- " z (tensor): sampled latent vector\n",
- "\"\"\"\n",
- "def sampling(z_mean, z_logsigma):\n",
- " # By default, random.normal is \"standard\" (ie. mean=0 and std=1.0)\n",
- " batch, latent_dim = z_mean.shape\n",
- " epsilon = tf.random.normal(shape=(batch, latent_dim))\n",
- "\n",
- " # TODO: Define the reparameterization computation!\n",
- " # Note the equation is given in the text block immediately above.\n",
- " z = z_mean + tf.math.exp(0.5 * z_logsigma) * epsilon\n",
- " # z = # TODO\n",
- " return z"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "qtHEYI9KNn0A"
- },
- "source": [
- "## 2.5 Debiasing variational autoencoder (DB-VAE)\n",
- "\n",
- "Now, we'll use the general idea behind the VAE architecture to build a model, termed a [*debiasing variational autoencoder*](https://lmrt.mit.edu/sites/default/files/AIES-19_paper_220.pdf) or DB-VAE, to mitigate (potentially) unknown biases present within the training idea. We'll train our DB-VAE model on the facial detection task, run the debiasing operation during training, evaluate on the PPB dataset, and compare its accuracy to our original, biased CNN model. \n",
- "\n",
- "### The DB-VAE model\n",
- "\n",
- "The key idea behind this debiasing approach is to use the latent variables learned via a VAE to adaptively re-sample the CelebA data during training. Specifically, we will alter the probability that a given image is used during training based on how often its latent features appear in the dataset. So, faces with rarer features (like dark skin, sunglasses, or hats) should become more likely to be sampled during training, while the sampling probability for faces with features that are over-represented in the training dataset should decrease (relative to uniform random sampling across the training data).\n",
- "\n",
- "A general schematic of the DB-VAE approach is shown here:\n",
- "\n",
- ""
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "ziA75SN-UxxO"
- },
- "source": [
- "Recall that we want to apply our DB-VAE to a *supervised classification* problem -- the facial detection task. Importantly, note how the encoder portion in the DB-VAE architecture also outputs a single supervised variable, $z_o$, corresponding to the class prediction -- face or not face. Usually, VAEs are not trained to output any supervised variables (such as a class prediction)! This is another key distinction between the DB-VAE and a traditional VAE.\n",
- "\n",
- "Keep in mind that we only want to learn the latent representation of *faces*, as that's what we're ultimately debiasing against, even though we are training a model on a binary classification problem. We'll need to ensure that, **for faces**, our DB-VAE model both learns a representation of the unsupervised latent variables, captured by the distribution $q_\\phi(z|x)$, **and** outputs a supervised class prediction $z_o$, but that, **for negative examples**, it only outputs a class prediction $z_o$."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "XggIKYPRtOZR"
- },
- "source": [
- "### Defining the DB-VAE loss function\n",
- "\n",
- "This means we'll need to be a bit clever about the loss function for the DB-VAE. The form of the loss will depend on whether it's a face image or a non-face image that's being considered.\n",
- "\n",
- "For **face images**, our loss function will have two components:\n",
- "\n",
- "\n",
- "1. **VAE loss ($L_{VAE}$)**: consists of the latent loss and the reconstruction loss.\n",
- "2. **Classification loss ($L_y(y,\\hat{y})$)**: standard cross-entropy loss for a binary classification problem.\n",
- "\n",
- "In contrast, for images of **non-faces**, our loss function is solely the classification loss.\n",
- "\n",
- "We can write a single expression for the loss by defining an indicator variable ${I}_f$which reflects which training data are images of faces (${I}_f(y) = 1$ ) and which are images of non-faces (${I}_f(y) = 0$). Using this, we obtain:\n",
- "\n",
- "$$L_{total} = L_y(y,\\hat{y}) + {I}_f(y)\\Big[L_{VAE}\\Big]$$\n",
- "\n",
- "Let's write a function to define the DB-VAE loss function:\n"
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "VjieDs8Ovcqs"
- },
- "source": [
- "### Loss function for DB-VAE ###\n",
- "\n",
- "\"\"\"Loss function for DB-VAE.\n",
- "# Arguments\n",
- " x: true input x\n",
- " x_pred: reconstructed x\n",
- " y: true label (face or not face)\n",
- " y_logit: predicted labels\n",
- " mu: mean of latent distribution (Q(z|X))\n",
- " logsigma: log of standard deviation of latent distribution (Q(z|X))\n",
- "# Returns\n",
- " total_loss: DB-VAE total loss\n",
- " classification_loss = DB-VAE classification loss\n",
- "\"\"\"\n",
- "def debiasing_loss_function(x, x_pred, y, y_logit, mu, logsigma):\n",
- "\n",
- " # TODO: call the relevant function to obtain VAE loss\n",
- " vae_loss = vae_loss_function(x, x_pred, mu, logsigma)\n",
- " # vae_loss = vae_loss_function('''TODO''') # TODO\n",
- "\n",
- " # TODO: define the classification loss using sigmoid_cross_entropy\n",
- " # https://www.tensorflow.org/api_docs/python/tf/nn/sigmoid_cross_entropy_with_logits\n",
- " classification_loss = tf.nn.sigmoid_cross_entropy_with_logits(labels=y, logits=y_logit)\n",
- " # classification_loss = # TODO\n",
- "\n",
- " # Use the training data labels to create variable face_indicator:\n",
- " # indicator that reflects which training data are images of faces\n",
- " face_indicator = tf.cast(tf.equal(y, 1), tf.float32)\n",
- "\n",
- " # TODO: define the DB-VAE total loss! Use tf.reduce_mean to average over all\n",
- " # samples\n",
- " total_loss = tf.reduce_mean(\n",
- " classification_loss +\n",
- " face_indicator * vae_loss\n",
- " )\n",
- " # total_loss = # TODO\n",
- "\n",
- " return total_loss, classification_loss"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "YIu_2LzNWwWY"
- },
- "source": [
- "### DB-VAE architecture\n",
- "\n",
- "Now we're ready to define the DB-VAE architecture. To build the DB-VAE, we will use the standard CNN classifier from above as our encoder, and then define a decoder network. We will create and initialize the two models, and then construct the end-to-end VAE. We will use a latent space with 100 latent variables.\n",
- "\n",
- "The decoder network will take as input the sampled latent variables, run them through a series of deconvolutional layers, and output a reconstruction of the original input image."
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "JfWPHGrmyE7R"
- },
- "source": [
- "### Define the decoder portion of the DB-VAE ###\n",
- "\n",
- "n_filters = 12 # base number of convolutional filters, same as standard CNN\n",
- "latent_dim = 100 # number of latent variables\n",
- "\n",
- "def make_face_decoder_network():\n",
- " # Functionally define the different layer types we will use\n",
- " Conv2DTranspose = functools.partial(tf.keras.layers.Conv2DTranspose, padding='same', activation='relu')\n",
- " BatchNormalization = tf.keras.layers.BatchNormalization\n",
- " Flatten = tf.keras.layers.Flatten\n",
- " Dense = functools.partial(tf.keras.layers.Dense, activation='relu')\n",
- " Reshape = tf.keras.layers.Reshape\n",
- "\n",
- " # Build the decoder network using the Sequential API\n",
- " decoder = tf.keras.Sequential([\n",
- " # Transform to pre-convolutional generation\n",
- " Dense(units=4*4*6*n_filters), # 4x4 feature maps (with 6N occurances)\n",
- " Reshape(target_shape=(4, 4, 6*n_filters)),\n",
- "\n",
- " # Upscaling convolutions (inverse of encoder)\n",
- " Conv2DTranspose(filters=4*n_filters, kernel_size=3, strides=2),\n",
- " Conv2DTranspose(filters=2*n_filters, kernel_size=3, strides=2),\n",
- " Conv2DTranspose(filters=1*n_filters, kernel_size=5, strides=2),\n",
- " Conv2DTranspose(filters=3, kernel_size=5, strides=2),\n",
- " ])\n",
- "\n",
- " return decoder"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "yWCMu12w1BuD"
- },
- "source": [
- "Now, we will put this decoder together with the standard CNN classifier as our encoder to define the DB-VAE. Note that at this point, there is nothing special about how we put the model together that makes it a \"debiasing\" model -- that will come when we define the training operation. Here, we will define the core VAE architecture by sublassing the `Model` class; defining encoding, reparameterization, and decoding operations; and calling the network end-to-end."
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "dSFDcFBL13c3"
- },
- "source": [
- "### Defining and creating the DB-VAE ###\n",
- "\n",
- "class DB_VAE(tf.keras.Model):\n",
- " def __init__(self, latent_dim):\n",
- " super(DB_VAE, self).__init__()\n",
- " self.latent_dim = latent_dim\n",
- "\n",
- " # Define the number of outputs for the encoder. Recall that we have\n",
- " # `latent_dim` latent variables, as well as a supervised output for the\n",
- " # classification.\n",
- " num_encoder_dims = 2*self.latent_dim + 1\n",
- "\n",
- " self.encoder = make_standard_classifier(num_encoder_dims)\n",
- " self.decoder = make_face_decoder_network()\n",
- "\n",
- " # function to feed images into encoder, encode the latent space, and output\n",
- " # classification probability\n",
- " def encode(self, x):\n",
- " # encoder output\n",
- " encoder_output = self.encoder(x)\n",
- "\n",
- " # classification prediction\n",
- " y_logit = tf.expand_dims(encoder_output[:, 0], -1)\n",
- " # latent variable distribution parameters\n",
- " z_mean = encoder_output[:, 1:self.latent_dim+1]\n",
- " z_logsigma = encoder_output[:, self.latent_dim+1:]\n",
- "\n",
- " return y_logit, z_mean, z_logsigma\n",
- "\n",
- " # VAE reparameterization: given a mean and logsigma, sample latent variables\n",
- " def reparameterize(self, z_mean, z_logsigma):\n",
- " # TODO: call the sampling function defined above\n",
- " z = sampling(z_mean, z_logsigma)\n",
- " # z = # TODO\n",
- " return z\n",
- "\n",
- " # Decode the latent space and output reconstruction\n",
- " def decode(self, z):\n",
- " # TODO: use the decoder to output the reconstruction\n",
- " reconstruction = self.decoder(z)\n",
- " # reconstruction = # TODO\n",
- " return reconstruction\n",
- "\n",
- " # The call function will be used to pass inputs x through the core VAE\n",
- " def call(self, x):\n",
- " # Encode input to a prediction and latent space\n",
- " y_logit, z_mean, z_logsigma = self.encode(x)\n",
- "\n",
- " # TODO: reparameterization\n",
- " z = self.reparameterize(z_mean, z_logsigma)\n",
- " # z = # TODO\n",
- "\n",
- " # TODO: reconstruction\n",
- " recon = self.decode(z)\n",
- " # recon = # TODO\n",
- " return y_logit, z_mean, z_logsigma, recon\n",
- "\n",
- " # Predict face or not face logit for given input x\n",
- " def predict(self, x):\n",
- " y_logit, z_mean, z_logsigma = self.encode(x)\n",
- " return y_logit\n",
- "\n",
- "dbvae = DB_VAE(latent_dim)"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "M-clbYAj2waY"
- },
- "source": [
- "As stated, the encoder architecture is identical to the CNN from earlier in this lab. Note the outputs of our constructed DB_VAE model in the `call` function: `y_logit, z_mean, z_logsigma, z`. Think carefully about why each of these are outputted and their significance to the problem at hand.\n",
- "\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "nbDNlslgQc5A"
- },
- "source": [
- "### Adaptive resampling for automated debiasing with DB-VAE\n",
- "\n",
- "So, how can we actually use DB-VAE to train a debiased facial detection classifier?\n",
- "\n",
- "Recall the DB-VAE architecture: as input images are fed through the network, the encoder learns an estimate ${Q}(z|X)$ of the latent space. We want to increase the relative frequency of rare data by increased sampling of under-represented regions of the latent space. We can approximate ${Q}(z|X)$ using the frequency distributions of each of the learned latent variables, and then define the probability distribution of selecting a given datapoint $x$ based on this approximation. These probability distributions will be used during training to re-sample the data.\n",
- "\n",
- "You'll write a function to execute this update of the sampling probabilities, and then call this function within the DB-VAE training loop to actually debias the model."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Fej5FDu37cf7"
- },
- "source": [
- "First, we've defined a short helper function `get_latent_mu` that returns the latent variable means returned by the encoder after a batch of images is inputted to the network:"
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "ewWbf7TE7wVc"
- },
- "source": [
- "# Function to return the means for an input image batch\n",
- "def get_latent_mu(images, dbvae, batch_size=1024):\n",
- " N = images.shape[0]\n",
- " mu = np.zeros((N, latent_dim))\n",
- " for start_ind in range(0, N, batch_size):\n",
- " end_ind = min(start_ind+batch_size, N+1)\n",
- " batch = (images[start_ind:end_ind]).astype(np.float32)/255.\n",
- " _, batch_mu, _ = dbvae.encode(batch)\n",
- " mu[start_ind:end_ind] = batch_mu\n",
- " return mu"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "wn4yK3SC72bo"
- },
- "source": [
- "Now, let's define the actual resampling algorithm `get_training_sample_probabilities`. Importantly note the argument `smoothing_fac`. This parameter tunes the degree of debiasing: for `smoothing_fac=0`, the re-sampled training set will tend towards falling uniformly over the latent space, i.e., the most extreme debiasing."
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "HiX9pmmC7_wn"
- },
- "source": [
- "### Resampling algorithm for DB-VAE ###\n",
- "\n",
- "'''Function that recomputes the sampling probabilities for images within a batch\n",
- " based on how they distribute across the training data'''\n",
- "def get_training_sample_probabilities(images, dbvae, bins=10, smoothing_fac=0.001):\n",
- " print(\"Recomputing the sampling probabilities\")\n",
- "\n",
- " # TODO: run the input batch and get the latent variable means\n",
- " mu = get_latent_mu(images, dbvae)\n",
- " # mu = get_latent_mu('''TODO''') # TODO\n",
- "\n",
- " # sampling probabilities for the images\n",
- " training_sample_p = np.zeros(mu.shape[0])\n",
- "\n",
- " # consider the distribution for each latent variable\n",
- " for i in range(latent_dim):\n",
- "\n",
- " latent_distribution = mu[:,i]\n",
- " # generate a histogram of the latent distribution\n",
- " hist_density, bin_edges = np.histogram(latent_distribution, density=True, bins=bins)\n",
- "\n",
- " # find which latent bin every data sample falls in\n",
- " bin_edges[0] = -float('inf')\n",
- " bin_edges[-1] = float('inf')\n",
- "\n",
- " # TODO: call the digitize function to find which bins in the latent distribution\n",
- " # every data sample falls in to\n",
- " # https://docs.scipy.org/doc/numpy-1.13.0/reference/generated/numpy.digitize.html\n",
- " bin_idx = np.digitize(latent_distribution, bin_edges)\n",
- " # bin_idx = np.digitize('''TODO''', '''TODO''') # TODO\n",
- "\n",
- " # smooth the density function\n",
- " hist_smoothed_density = hist_density + smoothing_fac\n",
- " hist_smoothed_density = hist_smoothed_density / np.sum(hist_smoothed_density)\n",
- "\n",
- " # invert the density function\n",
- " p = 1.0/(hist_smoothed_density[bin_idx-1])\n",
- "\n",
- " # TODO: normalize all probabilities\n",
- " p = p / np.sum(p)\n",
- " # p = # TODO\n",
- "\n",
- " # TODO: update sampling probabilities by considering whether the newly\n",
- " # computed p is greater than the existing sampling probabilities.\n",
- " training_sample_p = np.maximum(p, training_sample_p)\n",
- " # training_sample_p = # TODO\n",
- "\n",
- " # final normalization\n",
- " training_sample_p /= np.sum(training_sample_p)\n",
- "\n",
- " return training_sample_p"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "pF14fQkVUs-a"
- },
- "source": [
- "Now that we've defined the resampling update, we can train our DB-VAE model on the CelebA/ImageNet training data, and run the above operation to re-weight the importance of particular data points as we train the model. Remember again that we only want to debias for features relevant to *faces*, not the set of negative examples. Complete the code block below to execute the training loop!"
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "xwQs-Gu5bKEK"
- },
- "source": [
- "### Training the DB-VAE ###\n",
- "\n",
- "# Hyperparameters\n",
- "params = dict(\n",
- " batch_size = 32,\n",
- " learning_rate = 5e-4,\n",
- " latent_dim = 100,\n",
- " num_epochs = 1, #DB-VAE needs slightly more epochs to train\n",
- ")\n",
- "\n",
- "experiment = create_experiment(\"6S191_Lab2_Part2_DBVAE\", params)\n",
- "\n",
- "# instantiate a new DB-VAE model and optimizer\n",
- "dbvae = DB_VAE(params[\"latent_dim\"])\n",
- "optimizer = tf.keras.optimizers.Adam(params[\"learning_rate\"])\n",
- "\n",
- "# To define the training operation, we will use tf.function which is a powerful tool\n",
- "# that lets us turn a Python function into a TensorFlow computation graph.\n",
- "@tf.function\n",
- "def debiasing_train_step(x, y):\n",
- "\n",
- " with tf.GradientTape() as tape:\n",
- " # Feed input x into dbvae. Note that this is using the DB_VAE call function!\n",
- " y_logit, z_mean, z_logsigma, x_recon = dbvae(x)\n",
- "\n",
- " '''TODO: call the DB_VAE loss function to compute the loss'''\n",
- " loss, class_loss = debiasing_loss_function(x, x_recon, y, y_logit, z_mean, z_logsigma)\n",
- " # loss, class_loss = debiasing_loss_function('''TODO arguments''') # TODO\n",
- "\n",
- " '''TODO: use the GradientTape.gradient method to compute the gradients.\n",
- " Hint: this is with respect to the trainable_variables of the dbvae.'''\n",
- " grads = tape.gradient(loss, dbvae.trainable_variables)\n",
- " # grads = tape.gradient('''TODO''', '''TODO''') # TODO\n",
- "\n",
- " # apply gradients to variables\n",
- " optimizer.apply_gradients(zip(grads, dbvae.trainable_variables))\n",
- " return loss\n",
- "\n",
- "# get training faces from data loader\n",
- "all_faces = loader.get_all_train_faces()\n",
- "\n",
- "if hasattr(tqdm, '_instances'): tqdm._instances.clear() # clear if it exists\n",
- "\n",
- "# The training loop -- outer loop iterates over the number of epochs\n",
- "step = 0\n",
- "for i in range(params[\"num_epochs\"]):\n",
- "\n",
- " IPython.display.clear_output(wait=True)\n",
- " print(\"Starting epoch {}/{}\".format(i+1, params[\"num_epochs\"]))\n",
- "\n",
- " # Recompute data sampling proabilities\n",
- " '''TODO: recompute the sampling probabilities for debiasing'''\n",
- " p_faces = get_training_sample_probabilities(all_faces, dbvae)\n",
- " # p_faces = get_training_sample_probabilities('''TODO''', '''TODO''') # TODO\n",
- "\n",
- " # get a batch of training data and compute the training step\n",
- " for j in tqdm(range(loader.get_train_size() // params[\"batch_size\"])):\n",
- " # load a batch of data\n",
- " (x, y) = loader.get_batch(params[\"batch_size\"], p_pos=p_faces)\n",
- "\n",
- " # loss optimization\n",
- " loss = debiasing_train_step(x, y)\n",
- " experiment.log_metric(\"loss\", loss.numpy().mean(), step=step)\n",
- "\n",
- " # plot the progress every 200 steps\n",
- " if j % 500 == 0:\n",
- " mdl.util.plot_sample(x, y, dbvae)\n",
- "\n",
- " step += 1\n",
- "\n",
- "experiment.end()"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "uZBlWDPOVcHg"
- },
- "source": [
- "Wonderful! Now we should have a trained and (hopefully!) debiased facial classification model, ready for evaluation!"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Eo34xC7MbaiQ"
- },
- "source": [
- "## 2.6 Evaluation of DB-VAE on Test Dataset\n",
- "\n",
- "Finally let's test our DB-VAE model on the test dataset, looking specifically at its accuracy on each the \"Dark Male\", \"Dark Female\", \"Light Male\", and \"Light Female\" demographics. We will compare the performance of this debiased model against the (potentially biased) standard CNN from earlier in the lab."
- ]
- },
- {
- "cell_type": "code",
- "metadata": {
- "id": "bgK77aB9oDtX"
- },
- "source": [
- "dbvae_logits = [dbvae.predict(np.array(x, dtype=np.float32)) for x in test_faces]\n",
- "dbvae_probs = tf.squeeze(tf.sigmoid(dbvae_logits))\n",
- "\n",
- "xx = np.arange(len(keys))\n",
- "plt.bar(xx, standard_classifier_probs.numpy().mean(1), width=0.2, label=\"Standard CNN\")\n",
- "plt.bar(xx+0.2, dbvae_probs.numpy().mean(1), width=0.2, label=\"DB-VAE\")\n",
- "plt.xticks(xx, keys);\n",
- "plt.title(\"Network predictions on test dataset\")\n",
- "plt.ylabel(\"Probability\"); plt.legend(bbox_to_anchor=(1.04,1), loc=\"upper left\");\n"
- ],
- "execution_count": null,
- "outputs": []
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "rESoXRPQo_mq"
- },
- "source": [
- "## 2.7 Conclusion and submission information\n",
- "\n",
- "We encourage you to think about and maybe even address some questions raised by the approach and results outlined here:\n",
- "\n",
- "* How does the accuracy of the DB-VAE across the four demographics compare to that of the standard CNN? Do you find this result surprising in any way?\n",
- "* How can the performance of the DB-VAE classifier be improved even further? We purposely did not optimize hyperparameters to leave this up to you!\n",
- "* In which applications (either related to facial detection or not!) would debiasing in this way be desired? Are there applications where you may not want to debias your model?\n",
- "* Do you think it should be necessary for companies to demonstrate that their models, particularly in the context of tasks like facial detection, are not biased? If so, do you have thoughts on how this could be standardized and implemented?\n",
- "* Do you have ideas for other ways to address issues of bias, particularly in terms of the training data?\n",
- "\n",
- "**Try to optimize your model to achieve improved performance. To enter the competition, please upload the following to the lab submission site for the Debiasing Faces Lab ([submission upload link](https://www.dropbox.com/request/dJZUEoqGLB43JEKzzqIc)).**\n",
- "\n",
- "* Jupyter notebook with the code you used to generate your results;\n",
- "* copy of the bar plot from section 2.6 showing the performance of your model;\n",
- "* a written description and/or diagram of the architecture and hyperparameters you used -- if there are any additional or interesting modifications you made to the template code, please include these in your description;\n",
- "* a written discussion of why these modifications helped improve performance.\n",
- "\n",
- "**Name your file in the following format: `[FirstName]_[LastName]_Face`, followed by the file format (.zip, .ipynb, .pdf, etc).** ZIP files are preferred over individual files. If you submit individual files, you must name the individual files according to the above nomenclature (e.g., `[FirstName]_[LastName]_Face_TODO.pdf`, `[FirstName]_[LastName]_Face_Report.pdf`, etc.).\n",
- "\n",
- "Hopefully this lab has shed some light on a few concepts, from vision based tasks, to VAEs, to algorithmic bias. We like to think it has, but we're biased ;).\n",
- "\n",
- ""
- ]
- }
- ]
-}
diff --git a/lab3/solutions/LLM_Finetuning_Solution.ipynb b/lab3/solutions/LLM_Finetuning_Solution.ipynb
deleted file mode 100644
index 04548c20..00000000
--- a/lab3/solutions/LLM_Finetuning_Solution.ipynb
+++ /dev/null
@@ -1,5432 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "\n",
- "\n",
- "# Copyright Information"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "# Copyright 2025 MIT Introduction to Deep Learning. All Rights Reserved.\n",
- "#\n",
- "# Licensed under the MIT License. You may not use this file except in compliance\n",
- "# with the License. Use and/or modification of this code outside of MIT Introduction\n",
- "# to Deep Learning must reference:\n",
- "#\n",
- "# © MIT Introduction to Deep Learning\n",
- "# http://introtodeeplearning.com\n",
- "#"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "# Laboratory 3: Large Language Model (LLM) Fine-tuning\n",
- "\n",
- "In this lab, you will fine-tune a multi-billion parameter large language model (LLM). We will go through several fundamental concepts of LLMs, including tokenization, templates, and fine-tuning. This lab provides a complete pipeline for fine-tuning a language model to generate responses in a specific style, and you will explore not only language model fine-tuning, but also ways to evaluate the performance of a language model.\n",
- "\n",
- "You will use Google's [Gemma 2B](https://huggingface.co/google/gemma-2b-it) model as the base language model to fine-tune; [Liquid AI's](https://www.liquid.ai/) [LFM-40B](https://www.liquid.ai/liquid-foundation-models) as an evaluation \"judge\" model; and Comet ML's [Opik](https://www.comet.com/site/products/opik/) as a framework for streamlined LLM evaluation.\n",
- "\n",
- "First, let's download the MIT deep learning package, install dependencies, and import the relevant packages we'll need for this lab."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "fmkjWI4fVeAh"
- },
- "outputs": [],
- "source": [
- "# Install and import MIT Deep Learning utilities\n",
- "!pip install mitdeeplearning > /dev/null 2>&1\n",
- "import mitdeeplearning as mdl"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "Oo64stjwBvnB"
- },
- "outputs": [],
- "source": [
- "import os\n",
- "import json\n",
- "import numpy as np\n",
- "from tqdm import tqdm\n",
- "import matplotlib.pyplot as plt\n",
- "\n",
- "import torch\n",
- "from torch.nn import functional as F\n",
- "from torch.utils.data import DataLoader\n",
- "\n",
- "from transformers import AutoTokenizer, AutoModelForCausalLM\n",
- "from datasets import load_dataset\n",
- "from peft import LoraConfig, get_peft_model\n",
- "from lion_pytorch import Lion"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "# Part 1: Fine-tuning an LLM for style\n",
- "\n",
- "In the first part of this lab, we will fine-tune an LLM as a chatbot that can generate responses in a specific style. We will use the [Gemma 2B model](https://huggingface.co/google/gemma-2b-it) as the base language model to finetune."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## 1.1: Templating and tokenization\n",
- "\n",
- "### 1.1.1: Templating\n",
- "\n",
- "Language models that function as chatbots are able to generate responses to user queries -- but how do they do this? We need to provide them with a way to understand the conversation and generate responses in a coherent manner -- some structure of what are inputs and outputs.\n",
- "\n",
- "[Templating](https://huggingface.co/docs/transformers/main/chat_templating) is a way to format inputs and outputs in a consistent structure that a language model can understand. It involves adding special tokens or markers to indicate different parts of the conversation, like who is speaking and where turns begin and end. This structure helps the model learn the proper format for generating responses and maintain a coherent conversation flow. Without templates, the model may not know how to properly format its outputs or distinguish between different speakers in a conversation.\n",
- "\n",
- "Let's start by defining some basic templates for the chatbot, for turns where the user asks a question and the model responds with an answer."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "id": "TN2zHVhfBvnE",
- "outputId": "abddea82-12cf-4a16-868b-2e41f85fd7f1"
- },
- "outputs": [],
- "source": [
- "# Basic question-answer template\n",
- "template_without_answer = \"user\\n{question}\\nmodel\\n\"\n",
- "template_with_answer = template_without_answer + \"{answer}\\n\"\n",
- "\n",
- "# Let's try to put something into the template to see how it looks\n",
- "print(template_with_answer.format(question=\"What is your name?\", answer=\"My name is Gemma!\"))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "### 1.1.2: Tokenization\n",
- "\n",
- "To operate on language, we need to prepare the text for the model. Fundamentally we can think of language as a sequence of \"chunks\" of text. We can split the text into individual chunks, and then map these chunks to numerical tokens -- collectively this is the process of [tokenization](https://huggingface.co/docs/transformers/main/tokenizer_summary). Numerical tokens can then be fed into a language model.\n",
- "\n",
- "There are several common approaches to tokenizing natural language text:\n",
- "\n",
- "1. **Word-based tokenization**: splits text into individual words. While simple, this can lead to large vocabularies and does not handle unknown words well.\n",
- "\n",
- "2. **Character-based tokenization**: splits text into individual characters. While this involves a very small vocabulary, it produces long sequences and loses word-level meaning.\n",
- "\n",
- "3. **Subword tokenization**: breaks words into smaller units (subwords) based on their frequency. The most popular and commonly used approach is [byte-pair encoding (BPE)](https://en.wikipedia.org/wiki/Byte_pair_encoding), which iteratively merges the most frequent character pairs. Modern language models typically use subword tokenization as it balances vocabulary size and sequence length while handling unknown words effectively by breaking them into known subword units.\n",
- "\n",
- "In this lab we will use the tokenizer from the Gemma 2B model, which uses BPE. Let's load it and inspect it."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 266,
- "referenced_widgets": [
- "2846d60e43a24160b177166c25dd0122",
- "231e675f282d48a39e023149d4879b8b",
- "ce1a72b3385c44a2b6c8c36acc48867f",
- "57180ced897d4007a6d836665a032802",
- "8d2df8e3bb4b410f9f671d4cd2a6e80d",
- "16d840d19a804bec80ea85cafc850c13",
- "8642a2df48194dc2a0314de10e0a7635",
- "9a7787f0d75847219071be822ccd76ba",
- "bc10c09f48534cc081dc53a4cc7bc20a",
- "ba606012b7a14ad2824fe6843930ca08",
- "9d5116fb35f44752a680fe7dc2b410b7",
- "01bc169362704eeebd69a87d641d269e",
- "7bbc93e57dda4424acb428027a9f014a",
- "09b97b2a1f734e38b2a9908cf59edd8d",
- "74dc454addc64783bbf1b3897a817147",
- "47037605ebef451e91b64dd2fb040475",
- "f701d542971a4238aa8b76affc054743",
- "9498c07f6ad74b248c94de3bad444f62",
- "c4dc3a623a34415a83c2ffab0e19560b",
- "cde4b31291a9493f8ef649269ca11e1c",
- "7899c5e27ac64478a6e6ac767da24a20",
- "0b18c6ae2dee474aae96fdbd81637024",
- "81b9c3a820424c67a4c050545c2daa2e",
- "2318014fa6fd4452b76b5938a7da0c6f",
- "df141f6e170f4af98d009fd42043a359",
- "c34cba3327304cf98154ce2c73218441",
- "1a949dd5e121434dbbf1b0c290d71373",
- "c1d5a98c0f324e29a3628ff49718d7b6",
- "d0cb6b890289454981f6b9ad8cb2a0e1",
- "4495489fb35f495c898b334d75c8e1ed",
- "34976cd4ca634e4cb7a5c0efffa41e81",
- "64d0bc7735bf42ce800f56ebcce3cdce",
- "01b7fbea9de54e338e3862e09d7e353d",
- "9bead4274c0c4fc6acf12bf6b9dec75a",
- "34ff40c5c4cf405d8ef59a12171b03a5",
- "9d8d908e12b846d58aea8b0e48dd6b92",
- "e9c00880fa4b47c7bf645c3f91a950a9",
- "7d93f09ca25a498fbd4776daa0fc4c53",
- "1c35e9b4250f4fca9e65ecfe4dcb4006",
- "1eacc88f8b754c7e93582ce65f99b5db",
- "6311ea720e344309b1d6fa1445f347e3",
- "ba866548b5544345b37e29f6d8e92652",
- "d5f566c5de7d4dd1808975839ab8b973",
- "0e17dd9f94714fb38ecbe3bd68873c1c"
- ]
- },
- "id": "EeDF1JI-BvnF",
- "outputId": "6c9d3a2b-0b6b-4fa1-de66-dc7879ab4d15"
- },
- "outputs": [],
- "source": [
- "# Load the tokenizer for Gemma 2B\n",
- "model_id = \"unsloth/gemma-2-2b-it\" #\"google/gemma-2-2b-it\"\n",
- "tokenizer = AutoTokenizer.from_pretrained(model_id)\n",
- "\n",
- "# How big is the tokenizer?\n",
- "print(f\"Vocab size: {len(tokenizer.get_vocab())}\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "We not only need to be able to tokenize the text into tokens (encode), but also de-tokenize the tokens back into text (decode). Our tokenizer will have:\n",
- "1. an `encode` function to tokenize the text into tokens, and \n",
- "2. a `decode` function to de-tokenize back to text so that we can read out the model's outputs.\n",
- "\n",
- "Let's test out both steps and inspect to get a better understanding of how this works."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "id": "JH1XzPkiBvnF",
- "outputId": "25e68cce-5aa0-432c-ab8c-246910d6c6b0"
- },
- "outputs": [],
- "source": [
- "# Lets test out both steps:\n",
- "text = \"Here is some sample text!\"\n",
- "print(f\"Original text: {text}\")\n",
- "\n",
- "# Tokenize the text\n",
- "tokens = tokenizer.encode(text, return_tensors=\"pt\")\n",
- "print(f\"Encoded tokens: {tokens}\")\n",
- "\n",
- "# Decode the tokens\n",
- "decoded_text = tokenizer.decode(tokens[0], skip_special_tokens=True)\n",
- "print(f\"Decoded text: {decoded_text}\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "This is really cool. Now we have a way to move in and out of the token space.\n",
- "\n",
- "To \"chat\" with our LLM chatbot, we need to use the tokenizer and the chat template together, in order for the model to respond to the user's question. We can use the templates defined earlier to construct a prompt for the model, without the answer. "
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "id": "jyBxl6NIBvnF",
- "outputId": "06e54226-c434-4a84-868f-a8b5b5085bbd"
- },
- "outputs": [],
- "source": [
- "prompt = template_without_answer.format(question=\"What is the capital of France? Use one word.\")\n",
- "print(prompt)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "If we were to feed this to the model, it would see that it is now the start of the model's turn, and it would generate the answer to this question. "
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## 1.2: Getting started with the LLM\n",
- "\n",
- "Now that we have a way to prepare our data, we're ready to work with our LLM!\n",
- "\n",
- "LLMs like Gemma 2B are trained on a large corpus of text, on the task of predicting the next token in a sequence, given the previous tokens. We call this training task \"next token prediction\"; you may also see it called \"causal language modeling\" or \"autoregressive language modeling\". We can leverage models trained in this way to generate new text by sampling from the predicted probability distribution over the next token.\n",
- "\n",
- "Let's load the Gemma 2B model and start working with it. We will construct a prompt in chat template form and tokenize it. Then, we will feed it to the model to predict next token probabilities. Finally, we will get the next token (which is still numerical) and decode it to text."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 113,
- "referenced_widgets": [
- "e715b19f10c64131ba65d96bf968d72d",
- "7d2b9dea260143eb8c2933a6d3592bb0",
- "087ed90b113448aa9f5079457ca4ba2b",
- "0f9fe85f7079487f837ef9a7a6d7cbc5",
- "49680ea9e5ae4916b52e398e27f87ff5",
- "5cd563e97ce742e99942f553b31e3bed",
- "e988eba4dbe546d484a6c4e88cf90b88",
- "f2418db0b0ee4d3ca801f11c75ac1aca",
- "676328ed1fb04ff4983a5b26df17d966",
- "dacf87a2148c49db9306694b5a5f33da",
- "3198b48f531d4e26bff98917f9d2b592",
- "02edcc6aafcf4895843ff5e93ef30f45",
- "44c5c62e4af7441bafbc7734982aa660",
- "4b81f2c217b24406be898b1333b56352",
- "d73b1aa5cf2e46c9ac65c617af00739f",
- "6e626c5ef0dd408eaf3139f6aabaf190",
- "1725a2fb58b94626a34f87c66ba0e8c2",
- "1d6090d1b9e24e3cb550b655b8fbe318",
- "2f803afa195c476fbfb506d53645c381",
- "1734b0819fe74736a0417a9e2b977695",
- "d82e67b97ea24f80a1478783cfb0f365",
- "586958735baa4f29978d399852dc2aff",
- "34ddb97a59d940879eb53d3e4dbe177e",
- "be8a8c70a4c44ca4bd6fa595b29b3a35",
- "f7dba9ee7dd646f5bf4e9f8589addc83",
- "23790096dbc541d49e8db4c11a772a3f",
- "19f8ecfe426246eb93849b324e986d37",
- "efec2d4919314a79bd55fed697631516",
- "389fffd528eb47f4b443b5e311a43629",
- "d26f0017695b4e42b1c2736c07575775",
- "73aa48a573e349b1a05ba0bb5526bc2a",
- "a239a415866d47238ffa50a5c9c0a580",
- "00dffcff57a14ad28d665cd2c2a11960"
- ]
- },
- "id": "mWtWvgiuBvnG",
- "outputId": "b06295c8-b7b7-4d95-e0d6-31f65ac595ef"
- },
- "outputs": [],
- "source": [
- "# Load the model -- note that this may take a few minutes\n",
- "model = AutoModelForCausalLM.from_pretrained(model_id, device_map=\"auto\")"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "id": "2SMDd5dpBvnG",
- "outputId": "b5e63295-683a-4daa-9526-1ef93ed9e95a"
- },
- "outputs": [],
- "source": [
- "### Putting it together to prompt the model and generate a response ###\n",
- "\n",
- "# 1. Construct the prompt in chat template form\n",
- "question = \"What is the capital of France? Use one word.\" \n",
- "prompt = template_without_answer.format(question=question)\n",
- "# prompt = template_without_answer.format('''TODO''') # TODO\n",
- "\n",
- "# 2. Tokenize the prompt\n",
- "tokens = tokenizer.encode(prompt, return_tensors=\"pt\").to(model.device)\n",
- "\n",
- "# 3. Feed through the model to predict the next token probabilities\n",
- "with torch.no_grad():\n",
- " output = model(tokens)\n",
- " # output = '''TODO''' # TODO\n",
- "\n",
- " probs = F.softmax(output.logits, dim=-1)\n",
- "\n",
- "# 4. Get the next token, according to the maximum probability\n",
- "next_token = torch.argmax(probs[0, -1, :]).item()\n",
- "\n",
- "# 5. Decode the next token\n",
- "next_token_text = tokenizer.decode(next_token)\n",
- "# next_token_text = '''TODO''' # TODO\n",
- "\n",
- "print(f\"Prompt: {prompt}\")\n",
- "print(f\"Predicted next token: {next_token_text}\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "Note that the model is not able to predict the answer to the question, it is only able to predict the next token in the sequence! For more complex questions, we can't just generate one token, but rather we need to generate a sequence of tokens.\n",
- "\n",
- "This can be done by doing the process above iteratively, step by step -- after each step we feed the generated token back into the model and predict the next token again.\n",
- "\n",
- "Instead of doing this manually ourselves, we can use the model's built-in [`model.generate()`](https://huggingface.co/docs/transformers/main/en/main_classes/text_generation#transformers.GenerationMixin.generate) functionality (supported by HuggingFace's Transformers library) to generate `max_new_tokens` number of tokens, and decode the output back to text."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "id": "XnWMUQVbBvnG",
- "outputId": "d0c110d0-d740-427e-abf9-312fe2dd9f5e"
- },
- "outputs": [],
- "source": [
- "prompt = template_without_answer.format(question=\"What does MIT stand for?\")\n",
- "tokens = tokenizer.encode(prompt, return_tensors=\"pt\").to(model.device)\n",
- "output = model.generate(tokens, max_new_tokens=20)\n",
- "print(tokenizer.decode(output[0]))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "Now we have the basic pipeline for generating text with an LLM!"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## 1.3: Fine-tuning\n",
- "\n",
- "Fine-tuning is a technique that allows us to adapt a pre-trained neural network to better suit a downstream task, domain, or style, by training the model further on new data. By training the model further on a carefully curated dataset, we can modify its behavior, style, or capabilities. Fine-tuning is used in a variety of applications, not just language modeling. But in language modeling, fine-tuning can be used to:\n",
- "- Adapt the model's writing style \n",
- "- Improve performance on specific tasks or domains\n",
- "- Teach the model new capabilities or knowledge\n",
- "- Reduce unwanted behaviors or biases\n",
- "\n",
- "In this lab, you will fine-tune the Gemma LLM to adapt the model's writing style. Recall that in Lab 1 you built out a RNN-based sequence model to generate Irish folk songs. Continuing with our Irish theme, we will first fine-tune the LLM to chat in the style of a leprechaun.\n",
- "\n",
- "\n",
- "\n",
- "We have prepared a question-answer dataset where the questions are in standard English style (i.e. \"base\" style) and the answers are in \"leprechaun\" style (written by another LLM). Let's load the dataset and inspect it."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 252,
- "referenced_widgets": [
- "453101669bb84ec784d30fdecf9e1052",
- "1acb7981a03c4d8491072db5b0f80b91",
- "f0013cd0e75942a7b6f0af20d710c9f9",
- "1caca54176f24a68841321407d5cb92c",
- "4bf984821d194c64945609ccf5d08ab0",
- "20f4fd378f6b44f386a6bdd9f0e787f7",
- "72693249b56e4995815d950d33ebbbba",
- "5dd29f36fb5745618d95abda81e869bb",
- "f433b043c2ad41d7ba01a9ee1187fffe",
- "304108b55b1c4ae58ac271e2d8616746",
- "1a1e342e7aa943cd82c91b224ea01932",
- "6a550e5a66704b7b819286707bd3a918",
- "3d6d0fa2af094773b593a85d6c51cf48",
- "8127e4af60a149f68318c0222641718f",
- "ec45944210dc46058e722e9969a7dcdc",
- "095a95bac5224763b7f512b468c7431d",
- "b17245b343ee4c2aad1afb45814ec63c",
- "fdffb194cfad4bc2a2adb90614977445",
- "589c07cbcc1b4d3db5bdee5a15dbd8df",
- "ad5c35c060754bc8ae7bae0832af3921",
- "22f90aaa2b1642c9bf9b385010b8a4cb",
- "c7e6412c823d48e9845eecb1b4e4d7f1",
- "578a08d4d89b496dbca00da965b745d2",
- "e8a1e9cc828f4a4d9c8f4e96b7fbb2fb",
- "b631f91b3a5040e0b237936b412d274b",
- "65670d440ae448c1862c9350e2784a3f",
- "bb749eaf05dc4fbb9e134cc61caae11b",
- "861dfc84b7364159a78379c91007e413",
- "b67122a0d1b24d168be2501782effd15",
- "02dbaaf3131648f8a5b0eb6bf7a4d089",
- "ddabe3ec75d247468550ce9b202e30ab",
- "395eb951f3044c20a6416c346c3e1cdd",
- "516627614ee0481aa5ac80cc77673a54",
- "34711f6447034a728316aacfc401a7e8",
- "fb69e7b86acd485e814ffb0f7ef142f3",
- "e92ae53e3bc14aa59b8cee25909c1d2a",
- "a6cc7eb40dbb4eff9c1e9a3f3b2aa381",
- "91bf23bab4a84645b07952fc7a088c36",
- "151b7ed8c9ca4a3192e2a28ff99c3dc6",
- "97f1a984a0a149bc9f305f18eb109b67",
- "4ec2221b24b94685887b091b45f3f746",
- "ee83baaeecd944a99c11f20f9b4f03fd",
- "db15fee2fae44e4babb449d56aeca0f3",
- "389c5f0e14a24cf08aa175f1f21b22fc"
- ]
- },
- "id": "kN0pHHS8BvnH",
- "outputId": "a8422640-ba32-4d64-9379-1761062fd02e"
- },
- "outputs": [],
- "source": [
- "train_loader, test_loader = mdl.lab3.create_dataloader(style=\"leprechaun\")\n",
- "\n",
- "sample = train_loader.dataset[44]\n",
- "question = sample['instruction']\n",
- "answer = sample['response']\n",
- "answer_style = sample['response_style']\n",
- "\n",
- "print(f\"Question: {question}\\n\\n\" +\n",
- " f\"Original Answer: {answer}\\n\\n\" +\n",
- " f\"Answer Style: {answer_style}\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "### 1.3.1: Chat function\n",
- "\n",
- "Before we start finetuning, we will build a function to easily chat with the model, both so we can monitor its progress over the course of finetuning and also to generate responses to questions.\n",
- "\n",
- "Recall our core steps from before:\n",
- "1. Construct the question prompt using the template\n",
- "2. Tokenize the text\n",
- "3. Feed the tokensthrough the model to predict the next token probabilities\n",
- "4. Decode the predicted tokens back to text\n",
- "\n",
- "Use these steps to build out the `chat` function below."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "d-GfGscMBvnH"
- },
- "outputs": [],
- "source": [
- "def chat(question, max_new_tokens=32, temperature=0.7, only_answer=False):\n",
- " # 1. Construct the prompt using the template\n",
- " prompt = template_without_answer.format(question=question)\n",
- " # prompt = template_without_answer.format('''TODO''') # TODO \n",
- "\n",
- " # 2. Tokenize the text\n",
- " input_ids = tokenizer(prompt, return_tensors=\"pt\").to(model.device)\n",
- " # input_ids = tokenizer('''TODO''', '''TODO''').to(model.device) # TODO\n",
- "\n",
- " # 3. Feed through the model to predict the next token probabilities\n",
- " with torch.no_grad():\n",
- " outputs = model.generate(**input_ids, do_sample=True, max_new_tokens=max_new_tokens, temperature=temperature)\n",
- " # outputs = model.generate('''TODO''', do_sample=True, max_new_tokens=max_new_tokens, temperature=temperature) # TODO\n",
- "\n",
- " # 4. Only return the answer if only_answer is True\n",
- " output_tokens = outputs[0]\n",
- " if only_answer:\n",
- " output_tokens = output_tokens[input_ids['input_ids'].shape[1]:]\n",
- "\n",
- " # 5. Decode the tokens\n",
- " result = tokenizer.decode(output_tokens, skip_special_tokens=True)\n",
- " # result = tokenizer.decode('''TODO''', skip_special_tokens=True) # TODO\n",
- "\n",
- " return result\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "Let's try chatting with the model now to test if it works! We have a sample question here (continuing with the Irish theme); feel free to try out other questions!"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "id": "FDr5f2djBvnH",
- "outputId": "c42789d4-fbbf-438b-fd9d-57b3e037daa5"
- },
- "outputs": [],
- "source": [
- "# Let's try chatting with the model now to test if it works!\n",
- "answer = chat(\n",
- " \"What is the capital of Ireland?\",\n",
- " only_answer=True,\n",
- " max_new_tokens=32,\n",
- ")\n",
- "\n",
- "print(answer)\n",
- "\n",
- "'''TODO: Experiment with asking the model different questions and temperature values, and see how it responds!'''"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "### 1.3.2: Parameter-efficient fine-tuning\n",
- "\n",
- "In fine-tuning, the weights of the model are updated to better fit the fine-tuning dataset and/or task. Updating all the weights in a language model like Gemma 2B -- which has ~2 billion parameters -- is computationally expensive. There are many techniques to make fine-tuning more efficient.\n",
- "\n",
- "We will use a technique called [LoRA](https://arxiv.org/abs/2106.09685) -- low-rank adaptation -- to make the fine-tuning process more efficient. LoRA is a way to fine-tune LLMs very efficiently by only updating a small subset of the model's parameters, and it works by adding trainable low-rank matrices to the model. While we will not go into the details of LoRA here, you can read more about it in the [LoRA paper](https://arxiv.org/abs/2106.09685). We will use the [`peft`](https://pypi.org/project/peft/) library to apply LoRA to the Gemma model."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "id": "Fb6Y679hBvnI",
- "outputId": "8070d39e-0fd9-44cd-9c35-d86afcd99caf"
- },
- "outputs": [],
- "source": [
- "# LoRA is a way to finetune LLMs very efficiently by only updating a small subset of the model's parameters\n",
- "\n",
- "def apply_lora(model):\n",
- " # Define LoRA config\n",
- " lora_config = LoraConfig(\n",
- " r=8, # rank of the LoRA matrices\n",
- " task_type=\"CAUSAL_LM\",\n",
- " target_modules=[\n",
- " \"q_proj\", \"o_proj\", \"k_proj\", \"v_proj\", \"gate_proj\", \"up_proj\", \"down_proj\"\n",
- " ],\n",
- " )\n",
- "\n",
- " # Apply LoRA to the model\n",
- " lora_model = get_peft_model(model, lora_config)\n",
- " return lora_model\n",
- "\n",
- "model = apply_lora(model)\n",
- "\n",
- "# Print the number of trainable parameters after applying LoRA\n",
- "trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad)\n",
- "total_params = sum(p.numel() for p in model.parameters())\n",
- "print(f\"number of trainable parameters: {trainable_params}\")\n",
- "print(f\"total parameters: {total_params}\")\n",
- "print(f\"percentage of trainable parameters: {trainable_params / total_params * 100:.2f}%\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "### 1.3.3: Forward pass and loss computation\n",
- "\n",
- "Now let's define a function to perform a forward pass through the LLM and compute the loss. The forward pass gives us the logits -- which reflect the probability distribution over the next token -- for the next token. We can compute the loss by comparing the predicted logits to the true next token -- our target label. Note that this is effectively a classification problem! So, our loss can be captured by the cross entropy loss, and we can use PyTorch's [`nn.functional.cross_entropy`](https://pytorch.org/docs/stable/generated/torch.nn.functional.cross_entropy.html) function to compute it."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "xCLtZwxwBvnI"
- },
- "outputs": [],
- "source": [
- "def forward_and_compute_loss(model, tokens, mask, context_length=512):\n",
- " # Truncate to context length\n",
- " tokens = tokens[:, :context_length]\n",
- " mask = mask[:, :context_length]\n",
- "\n",
- " # Construct the input, output, and mask\n",
- " x = tokens[:, :-1]\n",
- " y = tokens[:, 1:]\n",
- " mask = mask[:, 1:]\n",
- "\n",
- " # Forward pass to compute logits\n",
- " logits = model(x).logits\n",
- "\n",
- " # Compute loss\n",
- " loss = F.cross_entropy(\n",
- " logits.view(-1, logits.size(-1)),\n",
- " y.view(-1),\n",
- " reduction=\"none\"\n",
- " )\n",
- "\n",
- " # Mask out the loss for non-answer tokens\n",
- " loss = loss[mask.view(-1)].mean()\n",
- "\n",
- " return loss"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "### 1.3.4: Training loop for fine-tuning\n",
- "\n",
- "With this function to compute the loss, we can now define a training loop to fine-tune the model using LoRA. This training loop has the same core components as we've seen before in other labs:\n",
- "1. Grab a batch of data from the dataset (using the DataLoader)\n",
- "2. Feed the data through the model to complete a forward pass and compute the loss\n",
- "3. Backward pass to update the model weights\n",
- "\n",
- "The data in our DataLoader is initially text, and is not structured in our question-answer template. So in step (1) we will need to format the data into our question-answer template previously defined, and then tokenize the text.\n",
- "\n",
- "We care about the model's answer to the question; the \"answer\" tokens are the part of the text we want to predict and compute the loss for. So, after tokenizing the text we need to denote to the model which tokens are part of the \"answer\" and which are part of the \"question\". We can do this by computing a mask for the answer tokens, and then using this mask to compute the loss.\n",
- "\n",
- "Finally, we will complete the backward pass to update the model weights.\n",
- "\n",
- "Let's put this all together in the training loop below."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "JfiIrH7jBvnI"
- },
- "outputs": [],
- "source": [
- "### Training loop ###\n",
- "\n",
- "def train(model, dataloader, tokenizer, max_steps=200, context_length=512, learning_rate=1e-4):\n",
- " losses = []\n",
- "\n",
- " # Apply LoRA to the model\n",
- " model = apply_lora(model)\n",
- " # model = '''TODO''' # TODO\n",
- "\n",
- " optimizer = Lion(model.parameters(), lr=learning_rate)\n",
- "\n",
- " # Training loop\n",
- " for step, batch in enumerate(dataloader):\n",
- " question = batch[\"instruction\"][0]\n",
- " answer = batch[\"response_style\"][0]\n",
- "\n",
- " # Format the question and answer into the template\n",
- " text = template_with_answer.format(question=question, answer=answer)\n",
- " # text = template_with_answer.format('''TODO''', '''TODO''') # TODO\n",
- "\n",
- " # Tokenize the text and compute the mask for the answer\n",
- " ids = tokenizer(text, return_tensors=\"pt\", return_offsets_mapping=True).to(model.device)\n",
- " mask = ids[\"offset_mapping\"][:,:,0] >= text.index(answer)\n",
- "\n",
- " # Feed the tokens through the model and compute the loss\n",
- " loss = forward_and_compute_loss(\n",
- " model=model,\n",
- " tokens=ids[\"input_ids\"],\n",
- " mask=mask,\n",
- " context_length=context_length,\n",
- " )\n",
- " # loss = forward_and_compute_loss('''TODO''') # TODO\n",
- "\n",
- " # Backward pass\n",
- " optimizer.zero_grad()\n",
- " loss.backward()\n",
- " optimizer.step()\n",
- "\n",
- " losses.append(loss.item())\n",
- "\n",
- " # monitor progress\n",
- " if step % 10 == 0:\n",
- " print(chat(\"What is the capital of France?\", only_answer=True))\n",
- " print(f\"step {step} loss: {torch.mean(torch.tensor(losses)).item()}\")\n",
- " losses = []\n",
- "\n",
- " if step > 0 and step % max_steps == 0:\n",
- " break\n",
- "\n",
- " return model\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "id": "blFoO-PhBvnI",
- "outputId": "d23f2002-6e4a-41b0-9710-13d394290f34"
- },
- "outputs": [],
- "source": [
- "# Call the train function to fine-tune the model! Hint: you'll start to see results after a few dozen steps.\n",
- "model = train(model, train_loader, tokenizer, max_steps=50)\n",
- "# model = train('''TODO''') # TODO"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "Let's try chatting with the model again to see how it has changed!"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "id": "su4ZAG3eBvnI",
- "outputId": "b21ce134-1763-4872-8b58-19328d98b76a"
- },
- "outputs": [],
- "source": [
- "print(chat(\"What is a good story about tennis\", only_answer=True, max_new_tokens=200))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "2cvhTsptBvnI"
- },
- "source": [
- "# Part 2: Evaluating a style-tuned LLM\n",
- "\n",
- "How do we know if the model is doing well? How closely does the model's style match the style of a leprechaun? As you can see from the example above, determining whether a generated response is good or not is can seem qualitative, and it can be hard to measure how well the model is doing. \n",
- "\n",
- "While benchmarks have been developed to evaluate the performance of language models on a variety of tasks, these benchmarks are not always representative of the real-world performance of the model. For example, a model may perform well on a benchmark but poorly on a more realistic task. Benchmarks are also limited in the scope of tasks they can cover and capabilities they can reflect, and there can be concerns about whether the data in the benchmark was used to train the model. Synthetic data generation and synthetic tasks are a way to address these limitations, and this is an active area of research.\n",
- "\n",
- "We can also turn a qualitative evaluation of a generated response quantitative by deploying someone or something to \"judge\" the outputs. In this lab, we will use a technique called [LLM as a judge](https://arxiv.org/abs/2306.05685) to do exactly this. This involves using a larger LLM to score the outputs of a smaller LLM. The larger LLM is used as a judge, and it is given a system prompt that describes the task we want the smaller LLM to perform and the judging criteria. A \"system prompt\" is a way to set the general context and guide an LLM's behavior. Contextualized with this system prompt, the judge LLM can score the outputs of the smaller LLM, and we can use this score to evaluate how well the smaller LLM is doing."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "### 2.1: Fine-tune well, you must!\n",
- "\n",
- "Our leprechaun-tuned model is already pretty good at generating responses in the leprechaun style. It must be the luck of the Irish.\n",
- "\n",
- "Let's make things more interesting by considering a different style, one that has some clear patterns but also a lot of variability and room for creativity. We will use the style of [Yoda](https://en.wikipedia.org/wiki/Yoda) from Star Wars.\n",
- "\n",
- " \n",
- "\n",
- "Your goal is to try to fine-tune your model to generate responses in the Yoda style, use the LLM judge to evaluate how well the outputs of your chat model follow Yoda speak, and then use that information to improve the model."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 292,
- "referenced_widgets": [
- "fe486852cda849d5b2cf2dda69c46feb",
- "9af5e516b8594e7da181917ff351e019",
- "c6487dbfe53345b9822b372069f34922",
- "baace428cd5545718ddc6d0749e53562",
- "b12294da6032493e9ac7783b8e3ddaff",
- "43e58008991640f1a96e123f545ca52d",
- "5c780ea0aeee467da497547d78453492",
- "bf06c4115ae54e7b9da2838c9b6069a0",
- "b73ef786040243589d43806a965f0eea",
- "0d4c7d8c22dc49b4be6d4948a3224852",
- "d95ba2612d5e409da8899e679e39c4ee"
- ]
- },
- "id": "-gLgE41YBvnJ",
- "outputId": "174004bd-f5f1-42e0-96ff-41d480254c87"
- },
- "outputs": [],
- "source": [
- "# Load the Yoda-speak dataset and fine-tune the model using your training function\n",
- "train_loader, test_loader = mdl.lab3.create_dataloader(style=\"yoda\")\n",
- "model = train(model, train_loader, tokenizer, max_steps=50)\n",
- "# model = train('''TODO''') # TODO"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "Start by defining a system prompt for the judge LLM, setting the context that it will evaluate how well the outputs of your chat model follow Yoda speak. Experiment with different system prompts to see how they affect the judge LLM's evaluation! Keep in mind that a better judge LLM will give you a better evaluation of how well your Yoda model is doing, and that a better evaluation will help you improve your Yoda model."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "id": "REkrJ1SCBvnJ",
- "outputId": "a5630cfb-5a6c-4874-9007-fe519de32220"
- },
- "outputs": [],
- "source": [
- "### LLM as a judge ###\n",
- "\n",
- "'''TODO: Experiment with different system prompts to see how they affect the judge LLM's evaluation!\n",
- " Come back to this cell after you've generated some text from your model.'''\n",
- " \n",
- "system_prompt = \"\"\"\n",
- "You are an impartial judge that evaluates if text was written by {style}.\n",
- "\n",
- "An example piece of text from {style} is:\n",
- "{example}\n",
- "\n",
- "Now, analyze some new text carefully and respond on if it follows the\n",
- "same style of {style}. Be critical to identify any issues in the text.\n",
- "Then convert your feedback into a number between 0 and 10: 10 if the text\n",
- "is written exactly in the style of {style}, 5 if mixed faithfulness to the\n",
- "style, or 0 if the text is not at all written in the style of {style}.\n",
- "\n",
- "The format of the your response should be a JSON dictionary and nothing else:\n",
- "{{\"score\": }}\n",
- "\"\"\"\n",
- "\n",
- "style = \"Yoda\"\n",
- "# example = \"\"\"The very Republic is threatened, if involved the Sith are. Hard to see, the dark side is. \"\"\"\n",
- "example = \"The very Republic is threatened, if involved the Sith are. Hard to see, the dark side is. Discover who this assassin is, we must. With this Naboo queen you must stay, Qui-Gon. Protect her. May the Force be with you. A vergence, you say? But you do! Revealed your opinion is. Trained as a Jedi, you request for him? Good, good, young one.\"\n",
- "\n",
- "system_prompt = system_prompt.format(style=style, example=example)\n",
- "print(\"=== System prompt ===\")\n",
- "print(system_prompt)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "### 2.2: Setting up the judge LLM\n",
- "\n",
- "In LLM as a judge, we need to use a model that is larger (and therefore more capable) than our \"performer\" model, in our case the style fine-tuned Gemma 2B. Since it is infeasible to load larger models locally into notebooks, you will gain experience interfacing with these larger LLMs through an API served on [OpenRouter](https://openrouter.ai/). \n",
- "\n",
- "You will need to sign up for an [OpenRouter account](https://openrouter.ai/sign-up) and then [generate an API key](https://openrouter.ai/keys). Running powerful LLMs of this scale costs money -- for students in the in-person course, we can provide a credit to your OpenRouter account to allow you to run this lab. Come to office hours to receive your credit. \n",
- "\n",
- "Through the OpenRouter interface, you will be able to experiment with different judge LLMs -- here we have suggested two possible larger LLMs to get you started: [Liquid AI's](https://www.liquid.ai/) [LFM-40B](https://openrouter.ai/models/liquid-ai/lfm-40b) andGoogle's [Gemma 9B](https://openrouter.ai/models/google/gemma-9b). Note there are also free models available on OpenRouter (e.g., [gemma-2-9b-it:free](https://openrouter.ai/google/gemma-2-9b-it:free)), but these will run into rate limitations if you run them too much.\n",
- "\n",
- "We have defined a simple class, `LLMClient`, to interact with the OpenRouter API. This class has a method `ask` that takes a user prompt and returns the model's response. Keep in mind that the judge LLM's response will be conditioned on the system prompt you provide -- the system prompt is critical to set the criteria for the evaluation!"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "id": "9S7DtGZ5BvnJ",
- "outputId": "4ac889ba-43a8-4636-9341-f0b1f260faef"
- },
- "outputs": [],
- "source": [
- "OPENROUTER_API_KEY = \"\" # TODO: add your OpenRouter API key here\n",
- "assert OPENROUTER_API_KEY != \"\", \"You must set your OpenRouter API key before running this cell!\"\n",
- "\n",
- "model_name = \"liquid/lfm-40b\"\n",
- "# model_name = \"google/gemma-2-9b-it\"\n",
- "llm = mdl.lab3.LLMClient(model=model_name, api_key=OPENROUTER_API_KEY)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "### 2.3: Defining the evaluation metric\n",
- "\n",
- "Great! We have set up our judge LLM, but we still need to make this quantitative. We can do this by defining a metric that uses the judge LLM to score the outputs of the model. Doing this is streamlined with Comet ML's [Opik library](https://www.comet.com/docs/opik/python-sdk-reference/), a platform for LLM evaluation and benchmarking.\n",
- "\n",
- "In prior labs, we used Comet for experiment tracking, so you should have an account and API key. If not, you can sign up for a Comet account [here](https://www.comet.com/signup?from=llm&utm_source=mit_dl&utm_medium=notebook&utm_campaign=opik) if you have not done so already. Now we will use the Comet Opik library to define a metric that uses the judge LLM to score the outputs of the model.\n",
- "\n",
- "Opik has a base class for defining metrics, [`base_metric.BaseMetric`](https://www.comet.com/docs/opik/python-sdk-reference/evaluation/metrics/BaseMetric.html). You will use this to define a custom metric that uses the judge LLM to evaluate text for how well it adheres to Yoda speak. Note that the judge LLM and the metric can be applied to any text, not just the outputs of the model. This is important to keep in mind, since we need both a negative control -- text in the \"base\" standard English style -- and a positive control -- training-set text in Yoda-speak style -- against which to compare the model's generations.\n",
- "\n",
- "Set the judging criteria in the system prompt, and define the `score` function to evaluate text by querying the judge LLM."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "id": "llB3FgiwBvnJ",
- "outputId": "6c1dbf01-298c-4097-d2fa-8a212ca69822"
- },
- "outputs": [],
- "source": [
- "from opik.evaluation.metrics import base_metric, score_result\n",
- "\n",
- "class LLMJudgeEvaluator(base_metric.BaseMetric):\n",
- " def __init__(self, judge: mdl.lab3.LLMClient = None, system_prompt: str = None):\n",
- " self.judge = judge\n",
- " self.system_prompt = system_prompt\n",
- " self.prompt_template = \"Evaluate this text: {text}\"\n",
- "\n",
- " def score(self, text: str, n_tries=20, **kwargs):\n",
- " \"\"\" Evaluate by asking an LLM to score it. \"\"\"\n",
- "\n",
- " for attempt in range(n_tries):\n",
- " try:\n",
- " # TODO: Convert the text to template form before passing it to the judge LLM\n",
- " prompt = self.prompt_template.format(text=text)\n",
- " # prompt = self.prompt_template.format('''TODO''') # TODO\n",
- "\n",
- " # The system prompt asks the judge to output a JSON dictionary of the form: \n",
- " # {\"score\": }\n",
- " # To do this, we need to specify the judge to stop generating after it \n",
- " # closes the JSON dictionary (i.e., when it outputs \"}\")\n",
- " # Hint: Use the stop=[\"}\"] argument within the judge.ask() method to specify this.\n",
- " stop = \"}\"\n",
- "\n",
- " # TODO: Call the judge LLM with the system prompt and the prompt template. \n",
- " # Remember to stop the generation when the judge LLM outputs \"}\".\n",
- " res = self.judge.ask(\n",
- " system=self.system_prompt,\n",
- " user=prompt,\n",
- " max_tokens=10,\n",
- " stop=[stop]\n",
- " )\n",
- " # res = self.judge.ask(\n",
- " # system='''TODO''', \n",
- " # user='''TODO''', \n",
- " # max_tokens='''TODO'''\n",
- " # stop='''TODO'''\n",
- " # ) # TODO\n",
- "\n",
- " # Extract the assistant's content from the API response\n",
- " # Remember to add the stop character back to the end of the response to be a \n",
- " # valid JSON dictionary (its not there the judge LLM stoped once it saw it)\n",
- " res = res.choices[0].message.content + stop\n",
- " res_dict = json.loads(res)\n",
- "\n",
- " max_score = 10 # The maximum score that the LLM should output\n",
- " score = res_dict[\"score\"] / max_score # Normalize\n",
- " score = max(0.0, min(score, 1.0)) # Clip between 0 and 1\n",
- "\n",
- " # Return the score object\n",
- " return score_result.ScoreResult(name=\"StyleScore\", value=score)\n",
- "\n",
- " except Exception as e:\n",
- " if attempt == n_tries - 1: # Last attempt\n",
- " raise e # Re-raise the exception if all attempts failed\n",
- " continue # Try again if not the last attempt"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "Instaniate your Comet Opik judge using the LLMJudgeEvaluator class and system prompt."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "judge = LLMJudgeEvaluator(llm, system_prompt=system_prompt)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## 2.4: Evaluating the model by scoring with your judge LLM\n",
- "\n",
- "Now we can use the judge LLM to score the outputs of the model. We will use the `scoring_function` to score text using the judge LLM. \n",
- "\n",
- "Feed in a few probe sentences to get a vibe check on the judge LLM."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "id": "D_rvQDrvBvnJ",
- "outputId": "5d460cfb-4237-4a5b-e5d2-4974ea984805"
- },
- "outputs": [],
- "source": [
- "def scoring_function(text):\n",
- " return judge.score(text).value\n",
- "\n",
- "test_texts = [\n",
- " \"Tennis is a fun sport. But you must concentrate.\",\n",
- " \"Fun sport, tennis is. But work hard, you must.\",\n",
- " \"Hard to see, the dark side is.\"\n",
- "]\n",
- "\n",
- "for text in test_texts:\n",
- " score = scoring_function(text)\n",
- " print(f\"{text} ==> Score: {score}\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "We will evaluate how well our fine-tuned model is doing by scoring the outputs of the model, as well as our base-style text (negative control) and the training-set text in Yoda-speak style (positive control).\n",
- "\n",
- "Generate text from your model by asking it new questions.\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "9tzp4HPZBvnJ"
- },
- "outputs": [],
- "source": [
- "# Generate text from your model by asking it new questions.\n",
- "def generate_samples_from_test(test_loader, num_samples):\n",
- " samples = []\n",
- " for test_sample in tqdm(test_loader, total=num_samples):\n",
- " test_question = test_sample['instruction'][0]\n",
- " with torch.no_grad():\n",
- " generated = chat(test_question, only_answer=True, max_new_tokens=100)\n",
- " samples.append(generated)\n",
- " if len(samples) >= num_samples:\n",
- " break\n",
- " return samples\n",
- "\n",
- "n_samples = 20\n",
- "generated_samples = generate_samples_from_test(test_loader, num_samples=n_samples)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "Let's also collect some base-style text (`base_samples`) and the training-set text in Yoda-speak style (`style_samples`). For these, we won't need to generate text, since we already have the text in the dataset."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "id": "ZEpUWV2EBvnK",
- "outputId": "ff1192d3-ca28-4429-d110-47736fbaf90c"
- },
- "outputs": [],
- "source": [
- "base_samples = [sample['response'][0] for i, sample in enumerate(train_loader) if i < n_samples]\n",
- "style_samples = [sample['response_style'][0] for i, sample in enumerate(train_loader) if i < n_samples]"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "Now that we have our samples, we can score them using the judge LLM. We will use a multiprocessed scoring function to score the samples in parallel, because each sample is independent and we can submit them all as simultaneous requests to the judge LLM."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "2X6MNQc3BvnK"
- },
- "outputs": [],
- "source": [
- "# Create a multiprocessed scoring function to score the samples in parallel\n",
- "\n",
- "os.environ[\"TOKENIZERS_PARALLELISM\"] = \"false\"\n",
- "from multiprocessing import Pool\n",
- "\n",
- "def compute_scores_in_parallel(samples):\n",
- " with Pool(processes=10) as pool:\n",
- " scores = pool.map(scoring_function, samples)\n",
- " return scores\n",
- "\n",
- "# Compute and print the scores for the base-style text, generated text, and training-set text in Yoda-speak style\n",
- "base_scores = compute_scores_in_parallel(base_samples)\n",
- "print(f\"Base: {np.mean(base_scores):.2f} ± {np.std(base_scores):.2f}\")\n",
- "\n",
- "generated_scores = compute_scores_in_parallel(generated_samples)\n",
- "print(f\"Gen: {np.mean(generated_scores):.2f} ± {np.std(generated_scores):.2f}\")\n",
- "\n",
- "style_scores = compute_scores_in_parallel(style_samples)\n",
- "print(f\"Train: {np.mean(style_scores):.2f} ± {np.std(style_scores):.2f}\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "Look at the average scores for each of the three types of text -- what do you observe? \n",
- "\n",
- "We can also plot the distribution of scores for each of the three types of text.\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 472
- },
- "id": "V4-g0Z3_BvnK",
- "outputId": "5497bdad-7878-4df5-b2b0-015b896ea072"
- },
- "outputs": [],
- "source": [
- "import seaborn as sns\n",
- "import pandas as pd\n",
- "\n",
- "# Create clean DataFrame\n",
- "df = pd.DataFrame({\n",
- " 'Score': [*base_scores, *generated_scores, *style_scores],\n",
- " 'Type': ['Base']*len(base_scores) + ['Generated']*len(generated_scores) + ['Style']*len(style_scores)\n",
- "})\n",
- "\n",
- "# Plot with seaborn\n",
- "sns.histplot(data=df, x='Score', hue='Type', multiple=\"dodge\", bins=6, shrink=.8)\n",
- "\n",
- "plt.title('Distribution of Scores')\n",
- "plt.show()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "Use these observations to improve your model. Remember that the judge LLM is not perfect, and you can try to improve the judge LLM to better evaluate the model's outputs. A better judge LLM will give you a better evaluation of how well your Yoda model is doing, and that better evaluation will help you improve your Yoda model."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## 2.5: Conclusion\n",
- "\n",
- "Experiment with both your chat model and your judge LLM to try to improve the quality of the Yoda-speak. The competition for this lab will be based on the following criteria:\n",
- "* **Likelihood of true Yoda-speak under your chat model**: the better your chat model does at understanding Yoda-speak, it will estimate a lower cross entropy loss for language that is true Yoda-speak. At the end of this lab, you will evaluate the likelihood of a held-out test-sample of true Yoda-speak under your chat model. Include this likelihood in your report. This gives us a quantitative measure to compare different chat models (which may have interacted with different judge LLMs).\n",
- "* **Experiments and changes you tried to improve your chat model**: include a description of changes you made and the results you observed.\n",
- "\n",
- "#### IMPORTANT: RUN THE FOLLOWING CELL BELOW TO PRINT THE RESULT BUT DO NOT MODIFY ITS CONTENTS."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "id": "MqnrG24FBvnK",
- "outputId": "b93c17db-6968-40f3-a012-b3b202185bb6"
- },
- "outputs": [],
- "source": [
- "# DO NOT CHANGE/MODIFY THIS CELL.\n",
- "# EXECUTE IT BEFORE SUBMITTING YOUR ENTRY TO THE LAB.\n",
- "\n",
- "yoda_test_text = mdl.lab3.yoda_test_text\n",
- "tokens = tokenizer(yoda_test_text, return_tensors=\"pt\").to(model.device)\n",
- "\n",
- "# Get the loglikelihood from the model\n",
- "with torch.no_grad():\n",
- " outputs = model(**tokens)\n",
- " logits = outputs.logits[:, :-1]\n",
- " targets = tokens.input_ids[:, 1:]\n",
- " loss = F.cross_entropy(logits.reshape(-1, logits.size(-1)),\n",
- " targets.reshape(-1))\n",
- "\n",
- "print(f\"Yoda test loglikelihood: {loss.item():.2f}\")\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "# Submission information\n",
- "\n",
- "To enter the competition, please upload the following to the lab [submission site for the Large Language Models Lab](https://www.dropbox.com/request/vrDrNCkj4yDxgsi2O5Sw)):\n",
- "\n",
- "* Jupyter notebook with the code you used to generate your results;\n",
- "* copy of the bar plot showing the judge LLM's scores of text in base style, generated text, and text in true Yoda-speak style;\n",
- "* a written description modifications you made and experimentes you tried;\n",
- "* a written discussion of why and how these modifications changed performance;\n",
- "* **the numerical result of the last cell in this notebook**.\n",
- "\n",
- "Submissions without the result of the last cell will be automatically disqualified.\n",
- "\n",
- "**Name your file in the following format: `[FirstName]_[LastName]_LLM`, followed by the file format (.zip, .ipynb, .pdf, etc).** ZIP files are preferred over individual files. If you submit individual files, you must name the individual files according to the above nomenclature (e.g., `[FirstName]_[LastName]_LLM_Report.pdf`, etc.).\n",
- "\n",
- "
\n",
- "\n",
- "Your goal is to try to fine-tune your model to generate responses in the Yoda style, use the LLM judge to evaluate how well the outputs of your chat model follow Yoda speak, and then use that information to improve the model."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 292,
- "referenced_widgets": [
- "fe486852cda849d5b2cf2dda69c46feb",
- "9af5e516b8594e7da181917ff351e019",
- "c6487dbfe53345b9822b372069f34922",
- "baace428cd5545718ddc6d0749e53562",
- "b12294da6032493e9ac7783b8e3ddaff",
- "43e58008991640f1a96e123f545ca52d",
- "5c780ea0aeee467da497547d78453492",
- "bf06c4115ae54e7b9da2838c9b6069a0",
- "b73ef786040243589d43806a965f0eea",
- "0d4c7d8c22dc49b4be6d4948a3224852",
- "d95ba2612d5e409da8899e679e39c4ee"
- ]
- },
- "id": "-gLgE41YBvnJ",
- "outputId": "174004bd-f5f1-42e0-96ff-41d480254c87"
- },
- "outputs": [],
- "source": [
- "# Load the Yoda-speak dataset and fine-tune the model using your training function\n",
- "train_loader, test_loader = mdl.lab3.create_dataloader(style=\"yoda\")\n",
- "model = train(model, train_loader, tokenizer, max_steps=50)\n",
- "# model = train('''TODO''') # TODO"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "Start by defining a system prompt for the judge LLM, setting the context that it will evaluate how well the outputs of your chat model follow Yoda speak. Experiment with different system prompts to see how they affect the judge LLM's evaluation! Keep in mind that a better judge LLM will give you a better evaluation of how well your Yoda model is doing, and that a better evaluation will help you improve your Yoda model."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "id": "REkrJ1SCBvnJ",
- "outputId": "a5630cfb-5a6c-4874-9007-fe519de32220"
- },
- "outputs": [],
- "source": [
- "### LLM as a judge ###\n",
- "\n",
- "'''TODO: Experiment with different system prompts to see how they affect the judge LLM's evaluation!\n",
- " Come back to this cell after you've generated some text from your model.'''\n",
- " \n",
- "system_prompt = \"\"\"\n",
- "You are an impartial judge that evaluates if text was written by {style}.\n",
- "\n",
- "An example piece of text from {style} is:\n",
- "{example}\n",
- "\n",
- "Now, analyze some new text carefully and respond on if it follows the\n",
- "same style of {style}. Be critical to identify any issues in the text.\n",
- "Then convert your feedback into a number between 0 and 10: 10 if the text\n",
- "is written exactly in the style of {style}, 5 if mixed faithfulness to the\n",
- "style, or 0 if the text is not at all written in the style of {style}.\n",
- "\n",
- "The format of the your response should be a JSON dictionary and nothing else:\n",
- "{{\"score\": }}\n",
- "\"\"\"\n",
- "\n",
- "style = \"Yoda\"\n",
- "# example = \"\"\"The very Republic is threatened, if involved the Sith are. Hard to see, the dark side is. \"\"\"\n",
- "example = \"The very Republic is threatened, if involved the Sith are. Hard to see, the dark side is. Discover who this assassin is, we must. With this Naboo queen you must stay, Qui-Gon. Protect her. May the Force be with you. A vergence, you say? But you do! Revealed your opinion is. Trained as a Jedi, you request for him? Good, good, young one.\"\n",
- "\n",
- "system_prompt = system_prompt.format(style=style, example=example)\n",
- "print(\"=== System prompt ===\")\n",
- "print(system_prompt)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "### 2.2: Setting up the judge LLM\n",
- "\n",
- "In LLM as a judge, we need to use a model that is larger (and therefore more capable) than our \"performer\" model, in our case the style fine-tuned Gemma 2B. Since it is infeasible to load larger models locally into notebooks, you will gain experience interfacing with these larger LLMs through an API served on [OpenRouter](https://openrouter.ai/). \n",
- "\n",
- "You will need to sign up for an [OpenRouter account](https://openrouter.ai/sign-up) and then [generate an API key](https://openrouter.ai/keys). Running powerful LLMs of this scale costs money -- for students in the in-person course, we can provide a credit to your OpenRouter account to allow you to run this lab. Come to office hours to receive your credit. \n",
- "\n",
- "Through the OpenRouter interface, you will be able to experiment with different judge LLMs -- here we have suggested two possible larger LLMs to get you started: [Liquid AI's](https://www.liquid.ai/) [LFM-40B](https://openrouter.ai/models/liquid-ai/lfm-40b) andGoogle's [Gemma 9B](https://openrouter.ai/models/google/gemma-9b). Note there are also free models available on OpenRouter (e.g., [gemma-2-9b-it:free](https://openrouter.ai/google/gemma-2-9b-it:free)), but these will run into rate limitations if you run them too much.\n",
- "\n",
- "We have defined a simple class, `LLMClient`, to interact with the OpenRouter API. This class has a method `ask` that takes a user prompt and returns the model's response. Keep in mind that the judge LLM's response will be conditioned on the system prompt you provide -- the system prompt is critical to set the criteria for the evaluation!"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "id": "9S7DtGZ5BvnJ",
- "outputId": "4ac889ba-43a8-4636-9341-f0b1f260faef"
- },
- "outputs": [],
- "source": [
- "OPENROUTER_API_KEY = \"\" # TODO: add your OpenRouter API key here\n",
- "assert OPENROUTER_API_KEY != \"\", \"You must set your OpenRouter API key before running this cell!\"\n",
- "\n",
- "model_name = \"liquid/lfm-40b\"\n",
- "# model_name = \"google/gemma-2-9b-it\"\n",
- "llm = mdl.lab3.LLMClient(model=model_name, api_key=OPENROUTER_API_KEY)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "### 2.3: Defining the evaluation metric\n",
- "\n",
- "Great! We have set up our judge LLM, but we still need to make this quantitative. We can do this by defining a metric that uses the judge LLM to score the outputs of the model. Doing this is streamlined with Comet ML's [Opik library](https://www.comet.com/docs/opik/python-sdk-reference/), a platform for LLM evaluation and benchmarking.\n",
- "\n",
- "In prior labs, we used Comet for experiment tracking, so you should have an account and API key. If not, you can sign up for a Comet account [here](https://www.comet.com/signup?from=llm&utm_source=mit_dl&utm_medium=notebook&utm_campaign=opik) if you have not done so already. Now we will use the Comet Opik library to define a metric that uses the judge LLM to score the outputs of the model.\n",
- "\n",
- "Opik has a base class for defining metrics, [`base_metric.BaseMetric`](https://www.comet.com/docs/opik/python-sdk-reference/evaluation/metrics/BaseMetric.html). You will use this to define a custom metric that uses the judge LLM to evaluate text for how well it adheres to Yoda speak. Note that the judge LLM and the metric can be applied to any text, not just the outputs of the model. This is important to keep in mind, since we need both a negative control -- text in the \"base\" standard English style -- and a positive control -- training-set text in Yoda-speak style -- against which to compare the model's generations.\n",
- "\n",
- "Set the judging criteria in the system prompt, and define the `score` function to evaluate text by querying the judge LLM."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "id": "llB3FgiwBvnJ",
- "outputId": "6c1dbf01-298c-4097-d2fa-8a212ca69822"
- },
- "outputs": [],
- "source": [
- "from opik.evaluation.metrics import base_metric, score_result\n",
- "\n",
- "class LLMJudgeEvaluator(base_metric.BaseMetric):\n",
- " def __init__(self, judge: mdl.lab3.LLMClient = None, system_prompt: str = None):\n",
- " self.judge = judge\n",
- " self.system_prompt = system_prompt\n",
- " self.prompt_template = \"Evaluate this text: {text}\"\n",
- "\n",
- " def score(self, text: str, n_tries=20, **kwargs):\n",
- " \"\"\" Evaluate by asking an LLM to score it. \"\"\"\n",
- "\n",
- " for attempt in range(n_tries):\n",
- " try:\n",
- " # TODO: Convert the text to template form before passing it to the judge LLM\n",
- " prompt = self.prompt_template.format(text=text)\n",
- " # prompt = self.prompt_template.format('''TODO''') # TODO\n",
- "\n",
- " # The system prompt asks the judge to output a JSON dictionary of the form: \n",
- " # {\"score\": }\n",
- " # To do this, we need to specify the judge to stop generating after it \n",
- " # closes the JSON dictionary (i.e., when it outputs \"}\")\n",
- " # Hint: Use the stop=[\"}\"] argument within the judge.ask() method to specify this.\n",
- " stop = \"}\"\n",
- "\n",
- " # TODO: Call the judge LLM with the system prompt and the prompt template. \n",
- " # Remember to stop the generation when the judge LLM outputs \"}\".\n",
- " res = self.judge.ask(\n",
- " system=self.system_prompt,\n",
- " user=prompt,\n",
- " max_tokens=10,\n",
- " stop=[stop]\n",
- " )\n",
- " # res = self.judge.ask(\n",
- " # system='''TODO''', \n",
- " # user='''TODO''', \n",
- " # max_tokens='''TODO'''\n",
- " # stop='''TODO'''\n",
- " # ) # TODO\n",
- "\n",
- " # Extract the assistant's content from the API response\n",
- " # Remember to add the stop character back to the end of the response to be a \n",
- " # valid JSON dictionary (its not there the judge LLM stoped once it saw it)\n",
- " res = res.choices[0].message.content + stop\n",
- " res_dict = json.loads(res)\n",
- "\n",
- " max_score = 10 # The maximum score that the LLM should output\n",
- " score = res_dict[\"score\"] / max_score # Normalize\n",
- " score = max(0.0, min(score, 1.0)) # Clip between 0 and 1\n",
- "\n",
- " # Return the score object\n",
- " return score_result.ScoreResult(name=\"StyleScore\", value=score)\n",
- "\n",
- " except Exception as e:\n",
- " if attempt == n_tries - 1: # Last attempt\n",
- " raise e # Re-raise the exception if all attempts failed\n",
- " continue # Try again if not the last attempt"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "Instaniate your Comet Opik judge using the LLMJudgeEvaluator class and system prompt."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "judge = LLMJudgeEvaluator(llm, system_prompt=system_prompt)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## 2.4: Evaluating the model by scoring with your judge LLM\n",
- "\n",
- "Now we can use the judge LLM to score the outputs of the model. We will use the `scoring_function` to score text using the judge LLM. \n",
- "\n",
- "Feed in a few probe sentences to get a vibe check on the judge LLM."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "id": "D_rvQDrvBvnJ",
- "outputId": "5d460cfb-4237-4a5b-e5d2-4974ea984805"
- },
- "outputs": [],
- "source": [
- "def scoring_function(text):\n",
- " return judge.score(text).value\n",
- "\n",
- "test_texts = [\n",
- " \"Tennis is a fun sport. But you must concentrate.\",\n",
- " \"Fun sport, tennis is. But work hard, you must.\",\n",
- " \"Hard to see, the dark side is.\"\n",
- "]\n",
- "\n",
- "for text in test_texts:\n",
- " score = scoring_function(text)\n",
- " print(f\"{text} ==> Score: {score}\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "We will evaluate how well our fine-tuned model is doing by scoring the outputs of the model, as well as our base-style text (negative control) and the training-set text in Yoda-speak style (positive control).\n",
- "\n",
- "Generate text from your model by asking it new questions.\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "9tzp4HPZBvnJ"
- },
- "outputs": [],
- "source": [
- "# Generate text from your model by asking it new questions.\n",
- "def generate_samples_from_test(test_loader, num_samples):\n",
- " samples = []\n",
- " for test_sample in tqdm(test_loader, total=num_samples):\n",
- " test_question = test_sample['instruction'][0]\n",
- " with torch.no_grad():\n",
- " generated = chat(test_question, only_answer=True, max_new_tokens=100)\n",
- " samples.append(generated)\n",
- " if len(samples) >= num_samples:\n",
- " break\n",
- " return samples\n",
- "\n",
- "n_samples = 20\n",
- "generated_samples = generate_samples_from_test(test_loader, num_samples=n_samples)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "Let's also collect some base-style text (`base_samples`) and the training-set text in Yoda-speak style (`style_samples`). For these, we won't need to generate text, since we already have the text in the dataset."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "id": "ZEpUWV2EBvnK",
- "outputId": "ff1192d3-ca28-4429-d110-47736fbaf90c"
- },
- "outputs": [],
- "source": [
- "base_samples = [sample['response'][0] for i, sample in enumerate(train_loader) if i < n_samples]\n",
- "style_samples = [sample['response_style'][0] for i, sample in enumerate(train_loader) if i < n_samples]"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "Now that we have our samples, we can score them using the judge LLM. We will use a multiprocessed scoring function to score the samples in parallel, because each sample is independent and we can submit them all as simultaneous requests to the judge LLM."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "2X6MNQc3BvnK"
- },
- "outputs": [],
- "source": [
- "# Create a multiprocessed scoring function to score the samples in parallel\n",
- "\n",
- "os.environ[\"TOKENIZERS_PARALLELISM\"] = \"false\"\n",
- "from multiprocessing import Pool\n",
- "\n",
- "def compute_scores_in_parallel(samples):\n",
- " with Pool(processes=10) as pool:\n",
- " scores = pool.map(scoring_function, samples)\n",
- " return scores\n",
- "\n",
- "# Compute and print the scores for the base-style text, generated text, and training-set text in Yoda-speak style\n",
- "base_scores = compute_scores_in_parallel(base_samples)\n",
- "print(f\"Base: {np.mean(base_scores):.2f} ± {np.std(base_scores):.2f}\")\n",
- "\n",
- "generated_scores = compute_scores_in_parallel(generated_samples)\n",
- "print(f\"Gen: {np.mean(generated_scores):.2f} ± {np.std(generated_scores):.2f}\")\n",
- "\n",
- "style_scores = compute_scores_in_parallel(style_samples)\n",
- "print(f\"Train: {np.mean(style_scores):.2f} ± {np.std(style_scores):.2f}\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "Look at the average scores for each of the three types of text -- what do you observe? \n",
- "\n",
- "We can also plot the distribution of scores for each of the three types of text.\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 472
- },
- "id": "V4-g0Z3_BvnK",
- "outputId": "5497bdad-7878-4df5-b2b0-015b896ea072"
- },
- "outputs": [],
- "source": [
- "import seaborn as sns\n",
- "import pandas as pd\n",
- "\n",
- "# Create clean DataFrame\n",
- "df = pd.DataFrame({\n",
- " 'Score': [*base_scores, *generated_scores, *style_scores],\n",
- " 'Type': ['Base']*len(base_scores) + ['Generated']*len(generated_scores) + ['Style']*len(style_scores)\n",
- "})\n",
- "\n",
- "# Plot with seaborn\n",
- "sns.histplot(data=df, x='Score', hue='Type', multiple=\"dodge\", bins=6, shrink=.8)\n",
- "\n",
- "plt.title('Distribution of Scores')\n",
- "plt.show()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "Use these observations to improve your model. Remember that the judge LLM is not perfect, and you can try to improve the judge LLM to better evaluate the model's outputs. A better judge LLM will give you a better evaluation of how well your Yoda model is doing, and that better evaluation will help you improve your Yoda model."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## 2.5: Conclusion\n",
- "\n",
- "Experiment with both your chat model and your judge LLM to try to improve the quality of the Yoda-speak. The competition for this lab will be based on the following criteria:\n",
- "* **Likelihood of true Yoda-speak under your chat model**: the better your chat model does at understanding Yoda-speak, it will estimate a lower cross entropy loss for language that is true Yoda-speak. At the end of this lab, you will evaluate the likelihood of a held-out test-sample of true Yoda-speak under your chat model. Include this likelihood in your report. This gives us a quantitative measure to compare different chat models (which may have interacted with different judge LLMs).\n",
- "* **Experiments and changes you tried to improve your chat model**: include a description of changes you made and the results you observed.\n",
- "\n",
- "#### IMPORTANT: RUN THE FOLLOWING CELL BELOW TO PRINT THE RESULT BUT DO NOT MODIFY ITS CONTENTS."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "id": "MqnrG24FBvnK",
- "outputId": "b93c17db-6968-40f3-a012-b3b202185bb6"
- },
- "outputs": [],
- "source": [
- "# DO NOT CHANGE/MODIFY THIS CELL.\n",
- "# EXECUTE IT BEFORE SUBMITTING YOUR ENTRY TO THE LAB.\n",
- "\n",
- "yoda_test_text = mdl.lab3.yoda_test_text\n",
- "tokens = tokenizer(yoda_test_text, return_tensors=\"pt\").to(model.device)\n",
- "\n",
- "# Get the loglikelihood from the model\n",
- "with torch.no_grad():\n",
- " outputs = model(**tokens)\n",
- " logits = outputs.logits[:, :-1]\n",
- " targets = tokens.input_ids[:, 1:]\n",
- " loss = F.cross_entropy(logits.reshape(-1, logits.size(-1)),\n",
- " targets.reshape(-1))\n",
- "\n",
- "print(f\"Yoda test loglikelihood: {loss.item():.2f}\")\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "# Submission information\n",
- "\n",
- "To enter the competition, please upload the following to the lab [submission site for the Large Language Models Lab](https://www.dropbox.com/request/vrDrNCkj4yDxgsi2O5Sw)):\n",
- "\n",
- "* Jupyter notebook with the code you used to generate your results;\n",
- "* copy of the bar plot showing the judge LLM's scores of text in base style, generated text, and text in true Yoda-speak style;\n",
- "* a written description modifications you made and experimentes you tried;\n",
- "* a written discussion of why and how these modifications changed performance;\n",
- "* **the numerical result of the last cell in this notebook**.\n",
- "\n",
- "Submissions without the result of the last cell will be automatically disqualified.\n",
- "\n",
- "**Name your file in the following format: `[FirstName]_[LastName]_LLM`, followed by the file format (.zip, .ipynb, .pdf, etc).** ZIP files are preferred over individual files. If you submit individual files, you must name the individual files according to the above nomenclature (e.g., `[FirstName]_[LastName]_LLM_Report.pdf`, etc.).\n",
- "\n",
- " "
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": []
- }
- ],
- "metadata": {
- "accelerator": "GPU",
- "colab": {
- "gpuType": "T4",
- "provenance": []
- },
- "kernelspec": {
- "display_name": "Python 3",
- "name": "python3"
- },
- "language_info": {
- "codemirror_mode": {
- "name": "ipython",
- "version": 3
- },
- "file_extension": ".py",
- "mimetype": "text/x-python",
- "name": "python",
- "nbconvert_exporter": "python",
- "pygments_lexer": "ipython3",
- "version": "3.11.11"
- },
- "widgets": {
- "application/vnd.jupyter.widget-state+json": {
- "00dffcff57a14ad28d665cd2c2a11960": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "01b7fbea9de54e338e3862e09d7e353d": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "01bc169362704eeebd69a87d641d269e": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HBoxModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HBoxModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HBoxView",
- "box_style": "",
- "children": [
- "IPY_MODEL_7bbc93e57dda4424acb428027a9f014a",
- "IPY_MODEL_09b97b2a1f734e38b2a9908cf59edd8d",
- "IPY_MODEL_74dc454addc64783bbf1b3897a817147"
- ],
- "layout": "IPY_MODEL_47037605ebef451e91b64dd2fb040475"
- }
- },
- "02dbaaf3131648f8a5b0eb6bf7a4d089": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "02edcc6aafcf4895843ff5e93ef30f45": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HBoxModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HBoxModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HBoxView",
- "box_style": "",
- "children": [
- "IPY_MODEL_44c5c62e4af7441bafbc7734982aa660",
- "IPY_MODEL_4b81f2c217b24406be898b1333b56352",
- "IPY_MODEL_d73b1aa5cf2e46c9ac65c617af00739f"
- ],
- "layout": "IPY_MODEL_6e626c5ef0dd408eaf3139f6aabaf190"
- }
- },
- "087ed90b113448aa9f5079457ca4ba2b": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "FloatProgressModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "FloatProgressModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "ProgressView",
- "bar_style": "success",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_f2418db0b0ee4d3ca801f11c75ac1aca",
- "max": 913,
- "min": 0,
- "orientation": "horizontal",
- "style": "IPY_MODEL_676328ed1fb04ff4983a5b26df17d966",
- "value": 913
- }
- },
- "095a95bac5224763b7f512b468c7431d": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "09b97b2a1f734e38b2a9908cf59edd8d": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "FloatProgressModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "FloatProgressModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "ProgressView",
- "bar_style": "success",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_c4dc3a623a34415a83c2ffab0e19560b",
- "max": 4241003,
- "min": 0,
- "orientation": "horizontal",
- "style": "IPY_MODEL_cde4b31291a9493f8ef649269ca11e1c",
- "value": 4241003
- }
- },
- "0b18c6ae2dee474aae96fdbd81637024": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "0d4c7d8c22dc49b4be6d4948a3224852": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "0e17dd9f94714fb38ecbe3bd68873c1c": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "0f9fe85f7079487f837ef9a7a6d7cbc5": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_dacf87a2148c49db9306694b5a5f33da",
- "placeholder": "",
- "style": "IPY_MODEL_3198b48f531d4e26bff98917f9d2b592",
- "value": " 913/913 [00:00<00:00, 69.3kB/s]"
- }
- },
- "151b7ed8c9ca4a3192e2a28ff99c3dc6": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "16d840d19a804bec80ea85cafc850c13": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "1725a2fb58b94626a34f87c66ba0e8c2": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "1734b0819fe74736a0417a9e2b977695": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "ProgressStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "ProgressStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "bar_color": null,
- "description_width": ""
- }
- },
- "19f8ecfe426246eb93849b324e986d37": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "1a1e342e7aa943cd82c91b224ea01932": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "1a949dd5e121434dbbf1b0c290d71373": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "1acb7981a03c4d8491072db5b0f80b91": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_20f4fd378f6b44f386a6bdd9f0e787f7",
- "placeholder": "",
- "style": "IPY_MODEL_72693249b56e4995815d950d33ebbbba",
- "value": "README.md: 100%"
- }
- },
- "1c35e9b4250f4fca9e65ecfe4dcb4006": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "1caca54176f24a68841321407d5cb92c": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_304108b55b1c4ae58ac271e2d8616746",
- "placeholder": "",
- "style": "IPY_MODEL_1a1e342e7aa943cd82c91b224ea01932",
- "value": " 8.20k/8.20k [00:00<00:00, 349kB/s]"
- }
- },
- "1d6090d1b9e24e3cb550b655b8fbe318": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "1eacc88f8b754c7e93582ce65f99b5db": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "20f4fd378f6b44f386a6bdd9f0e787f7": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "22f90aaa2b1642c9bf9b385010b8a4cb": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "2318014fa6fd4452b76b5938a7da0c6f": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_c1d5a98c0f324e29a3628ff49718d7b6",
- "placeholder": "",
- "style": "IPY_MODEL_d0cb6b890289454981f6b9ad8cb2a0e1",
- "value": "tokenizer.json: 100%"
- }
- },
- "231e675f282d48a39e023149d4879b8b": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_16d840d19a804bec80ea85cafc850c13",
- "placeholder": "",
- "style": "IPY_MODEL_8642a2df48194dc2a0314de10e0a7635",
- "value": "tokenizer_config.json: 100%"
- }
- },
- "23790096dbc541d49e8db4c11a772a3f": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_a239a415866d47238ffa50a5c9c0a580",
- "placeholder": "",
- "style": "IPY_MODEL_00dffcff57a14ad28d665cd2c2a11960",
- "value": " 209/209 [00:00<00:00, 14.3kB/s]"
- }
- },
- "2846d60e43a24160b177166c25dd0122": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HBoxModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HBoxModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HBoxView",
- "box_style": "",
- "children": [
- "IPY_MODEL_231e675f282d48a39e023149d4879b8b",
- "IPY_MODEL_ce1a72b3385c44a2b6c8c36acc48867f",
- "IPY_MODEL_57180ced897d4007a6d836665a032802"
- ],
- "layout": "IPY_MODEL_8d2df8e3bb4b410f9f671d4cd2a6e80d"
- }
- },
- "2f803afa195c476fbfb506d53645c381": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "304108b55b1c4ae58ac271e2d8616746": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "3198b48f531d4e26bff98917f9d2b592": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "34711f6447034a728316aacfc401a7e8": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HBoxModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HBoxModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HBoxView",
- "box_style": "",
- "children": [
- "IPY_MODEL_fb69e7b86acd485e814ffb0f7ef142f3",
- "IPY_MODEL_e92ae53e3bc14aa59b8cee25909c1d2a",
- "IPY_MODEL_a6cc7eb40dbb4eff9c1e9a3f3b2aa381"
- ],
- "layout": "IPY_MODEL_91bf23bab4a84645b07952fc7a088c36"
- }
- },
- "34976cd4ca634e4cb7a5c0efffa41e81": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "ProgressStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "ProgressStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "bar_color": null,
- "description_width": ""
- }
- },
- "34ddb97a59d940879eb53d3e4dbe177e": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HBoxModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HBoxModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HBoxView",
- "box_style": "",
- "children": [
- "IPY_MODEL_be8a8c70a4c44ca4bd6fa595b29b3a35",
- "IPY_MODEL_f7dba9ee7dd646f5bf4e9f8589addc83",
- "IPY_MODEL_23790096dbc541d49e8db4c11a772a3f"
- ],
- "layout": "IPY_MODEL_19f8ecfe426246eb93849b324e986d37"
- }
- },
- "34ff40c5c4cf405d8ef59a12171b03a5": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_1c35e9b4250f4fca9e65ecfe4dcb4006",
- "placeholder": "",
- "style": "IPY_MODEL_1eacc88f8b754c7e93582ce65f99b5db",
- "value": "special_tokens_map.json: 100%"
- }
- },
- "389c5f0e14a24cf08aa175f1f21b22fc": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "389fffd528eb47f4b443b5e311a43629": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "395eb951f3044c20a6416c346c3e1cdd": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "3d6d0fa2af094773b593a85d6c51cf48": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_b17245b343ee4c2aad1afb45814ec63c",
- "placeholder": "",
- "style": "IPY_MODEL_fdffb194cfad4bc2a2adb90614977445",
- "value": "databricks-dolly-15k.jsonl: 100%"
- }
- },
- "43e58008991640f1a96e123f545ca52d": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "4495489fb35f495c898b334d75c8e1ed": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "44c5c62e4af7441bafbc7734982aa660": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_1725a2fb58b94626a34f87c66ba0e8c2",
- "placeholder": "",
- "style": "IPY_MODEL_1d6090d1b9e24e3cb550b655b8fbe318",
- "value": "model.safetensors: 100%"
- }
- },
- "453101669bb84ec784d30fdecf9e1052": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HBoxModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HBoxModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HBoxView",
- "box_style": "",
- "children": [
- "IPY_MODEL_1acb7981a03c4d8491072db5b0f80b91",
- "IPY_MODEL_f0013cd0e75942a7b6f0af20d710c9f9",
- "IPY_MODEL_1caca54176f24a68841321407d5cb92c"
- ],
- "layout": "IPY_MODEL_4bf984821d194c64945609ccf5d08ab0"
- }
- },
- "47037605ebef451e91b64dd2fb040475": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "49680ea9e5ae4916b52e398e27f87ff5": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "4b81f2c217b24406be898b1333b56352": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "FloatProgressModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "FloatProgressModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "ProgressView",
- "bar_style": "success",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_2f803afa195c476fbfb506d53645c381",
- "max": 5228717512,
- "min": 0,
- "orientation": "horizontal",
- "style": "IPY_MODEL_1734b0819fe74736a0417a9e2b977695",
- "value": 5228717512
- }
- },
- "4bf984821d194c64945609ccf5d08ab0": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "4ec2221b24b94685887b091b45f3f746": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "516627614ee0481aa5ac80cc77673a54": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "57180ced897d4007a6d836665a032802": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_ba606012b7a14ad2824fe6843930ca08",
- "placeholder": "",
- "style": "IPY_MODEL_9d5116fb35f44752a680fe7dc2b410b7",
- "value": " 47.0k/47.0k [00:00<00:00, 2.43MB/s]"
- }
- },
- "578a08d4d89b496dbca00da965b745d2": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HBoxModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HBoxModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HBoxView",
- "box_style": "",
- "children": [
- "IPY_MODEL_e8a1e9cc828f4a4d9c8f4e96b7fbb2fb",
- "IPY_MODEL_b631f91b3a5040e0b237936b412d274b",
- "IPY_MODEL_65670d440ae448c1862c9350e2784a3f"
- ],
- "layout": "IPY_MODEL_bb749eaf05dc4fbb9e134cc61caae11b"
- }
- },
- "586958735baa4f29978d399852dc2aff": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "589c07cbcc1b4d3db5bdee5a15dbd8df": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "5c780ea0aeee467da497547d78453492": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "5cd563e97ce742e99942f553b31e3bed": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "5dd29f36fb5745618d95abda81e869bb": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "6311ea720e344309b1d6fa1445f347e3": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "64d0bc7735bf42ce800f56ebcce3cdce": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "65670d440ae448c1862c9350e2784a3f": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_395eb951f3044c20a6416c346c3e1cdd",
- "placeholder": "",
- "style": "IPY_MODEL_516627614ee0481aa5ac80cc77673a54",
- "value": " 15011/15011 [00:00<00:00, 62410.60 examples/s]"
- }
- },
- "676328ed1fb04ff4983a5b26df17d966": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "ProgressStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "ProgressStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "bar_color": null,
- "description_width": ""
- }
- },
- "6a550e5a66704b7b819286707bd3a918": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HBoxModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HBoxModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HBoxView",
- "box_style": "",
- "children": [
- "IPY_MODEL_3d6d0fa2af094773b593a85d6c51cf48",
- "IPY_MODEL_8127e4af60a149f68318c0222641718f",
- "IPY_MODEL_ec45944210dc46058e722e9969a7dcdc"
- ],
- "layout": "IPY_MODEL_095a95bac5224763b7f512b468c7431d"
- }
- },
- "6e626c5ef0dd408eaf3139f6aabaf190": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "72693249b56e4995815d950d33ebbbba": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "73aa48a573e349b1a05ba0bb5526bc2a": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "ProgressStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "ProgressStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "bar_color": null,
- "description_width": ""
- }
- },
- "74dc454addc64783bbf1b3897a817147": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_7899c5e27ac64478a6e6ac767da24a20",
- "placeholder": "",
- "style": "IPY_MODEL_0b18c6ae2dee474aae96fdbd81637024",
- "value": " 4.24M/4.24M [00:00<00:00, 31.6MB/s]"
- }
- },
- "7899c5e27ac64478a6e6ac767da24a20": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "7bbc93e57dda4424acb428027a9f014a": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_f701d542971a4238aa8b76affc054743",
- "placeholder": "",
- "style": "IPY_MODEL_9498c07f6ad74b248c94de3bad444f62",
- "value": "tokenizer.model: 100%"
- }
- },
- "7d2b9dea260143eb8c2933a6d3592bb0": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_5cd563e97ce742e99942f553b31e3bed",
- "placeholder": "",
- "style": "IPY_MODEL_e988eba4dbe546d484a6c4e88cf90b88",
- "value": "config.json: 100%"
- }
- },
- "7d93f09ca25a498fbd4776daa0fc4c53": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "8127e4af60a149f68318c0222641718f": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "FloatProgressModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "FloatProgressModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "ProgressView",
- "bar_style": "success",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_589c07cbcc1b4d3db5bdee5a15dbd8df",
- "max": 13085339,
- "min": 0,
- "orientation": "horizontal",
- "style": "IPY_MODEL_ad5c35c060754bc8ae7bae0832af3921",
- "value": 13085339
- }
- },
- "81b9c3a820424c67a4c050545c2daa2e": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HBoxModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HBoxModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HBoxView",
- "box_style": "",
- "children": [
- "IPY_MODEL_2318014fa6fd4452b76b5938a7da0c6f",
- "IPY_MODEL_df141f6e170f4af98d009fd42043a359",
- "IPY_MODEL_c34cba3327304cf98154ce2c73218441"
- ],
- "layout": "IPY_MODEL_1a949dd5e121434dbbf1b0c290d71373"
- }
- },
- "861dfc84b7364159a78379c91007e413": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "8642a2df48194dc2a0314de10e0a7635": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "8d2df8e3bb4b410f9f671d4cd2a6e80d": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "91bf23bab4a84645b07952fc7a088c36": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "9498c07f6ad74b248c94de3bad444f62": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "97f1a984a0a149bc9f305f18eb109b67": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "9a7787f0d75847219071be822ccd76ba": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "9af5e516b8594e7da181917ff351e019": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_43e58008991640f1a96e123f545ca52d",
- "placeholder": "",
- "style": "IPY_MODEL_5c780ea0aeee467da497547d78453492",
- "value": "Map: 100%"
- }
- },
- "9bead4274c0c4fc6acf12bf6b9dec75a": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HBoxModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HBoxModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HBoxView",
- "box_style": "",
- "children": [
- "IPY_MODEL_34ff40c5c4cf405d8ef59a12171b03a5",
- "IPY_MODEL_9d8d908e12b846d58aea8b0e48dd6b92",
- "IPY_MODEL_e9c00880fa4b47c7bf645c3f91a950a9"
- ],
- "layout": "IPY_MODEL_7d93f09ca25a498fbd4776daa0fc4c53"
- }
- },
- "9d5116fb35f44752a680fe7dc2b410b7": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "9d8d908e12b846d58aea8b0e48dd6b92": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "FloatProgressModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "FloatProgressModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "ProgressView",
- "bar_style": "success",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_6311ea720e344309b1d6fa1445f347e3",
- "max": 636,
- "min": 0,
- "orientation": "horizontal",
- "style": "IPY_MODEL_ba866548b5544345b37e29f6d8e92652",
- "value": 636
- }
- },
- "a239a415866d47238ffa50a5c9c0a580": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "a6cc7eb40dbb4eff9c1e9a3f3b2aa381": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_db15fee2fae44e4babb449d56aeca0f3",
- "placeholder": "",
- "style": "IPY_MODEL_389c5f0e14a24cf08aa175f1f21b22fc",
- "value": " 2048/2048 [00:00<00:00, 6639.89 examples/s]"
- }
- },
- "ad5c35c060754bc8ae7bae0832af3921": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "ProgressStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "ProgressStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "bar_color": null,
- "description_width": ""
- }
- },
- "b12294da6032493e9ac7783b8e3ddaff": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "b17245b343ee4c2aad1afb45814ec63c": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "b631f91b3a5040e0b237936b412d274b": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "FloatProgressModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "FloatProgressModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "ProgressView",
- "bar_style": "success",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_02dbaaf3131648f8a5b0eb6bf7a4d089",
- "max": 15011,
- "min": 0,
- "orientation": "horizontal",
- "style": "IPY_MODEL_ddabe3ec75d247468550ce9b202e30ab",
- "value": 15011
- }
- },
- "b67122a0d1b24d168be2501782effd15": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "b73ef786040243589d43806a965f0eea": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "ProgressStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "ProgressStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "bar_color": null,
- "description_width": ""
- }
- },
- "ba606012b7a14ad2824fe6843930ca08": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "ba866548b5544345b37e29f6d8e92652": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "ProgressStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "ProgressStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "bar_color": null,
- "description_width": ""
- }
- },
- "baace428cd5545718ddc6d0749e53562": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_0d4c7d8c22dc49b4be6d4948a3224852",
- "placeholder": "",
- "style": "IPY_MODEL_d95ba2612d5e409da8899e679e39c4ee",
- "value": " 2048/2048 [00:00<00:00, 8114.30 examples/s]"
- }
- },
- "bb749eaf05dc4fbb9e134cc61caae11b": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "bc10c09f48534cc081dc53a4cc7bc20a": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "ProgressStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "ProgressStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "bar_color": null,
- "description_width": ""
- }
- },
- "be8a8c70a4c44ca4bd6fa595b29b3a35": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_efec2d4919314a79bd55fed697631516",
- "placeholder": "",
- "style": "IPY_MODEL_389fffd528eb47f4b443b5e311a43629",
- "value": "generation_config.json: 100%"
- }
- },
- "bf06c4115ae54e7b9da2838c9b6069a0": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "c1d5a98c0f324e29a3628ff49718d7b6": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "c34cba3327304cf98154ce2c73218441": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_64d0bc7735bf42ce800f56ebcce3cdce",
- "placeholder": "",
- "style": "IPY_MODEL_01b7fbea9de54e338e3862e09d7e353d",
- "value": " 17.5M/17.5M [00:00<00:00, 42.3MB/s]"
- }
- },
- "c4dc3a623a34415a83c2ffab0e19560b": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "c6487dbfe53345b9822b372069f34922": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "FloatProgressModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "FloatProgressModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "ProgressView",
- "bar_style": "success",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_bf06c4115ae54e7b9da2838c9b6069a0",
- "max": 2048,
- "min": 0,
- "orientation": "horizontal",
- "style": "IPY_MODEL_b73ef786040243589d43806a965f0eea",
- "value": 2048
- }
- },
- "c7e6412c823d48e9845eecb1b4e4d7f1": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "cde4b31291a9493f8ef649269ca11e1c": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "ProgressStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "ProgressStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "bar_color": null,
- "description_width": ""
- }
- },
- "ce1a72b3385c44a2b6c8c36acc48867f": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "FloatProgressModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "FloatProgressModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "ProgressView",
- "bar_style": "success",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_9a7787f0d75847219071be822ccd76ba",
- "max": 47022,
- "min": 0,
- "orientation": "horizontal",
- "style": "IPY_MODEL_bc10c09f48534cc081dc53a4cc7bc20a",
- "value": 47022
- }
- },
- "d0cb6b890289454981f6b9ad8cb2a0e1": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "d26f0017695b4e42b1c2736c07575775": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "d5f566c5de7d4dd1808975839ab8b973": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "d73b1aa5cf2e46c9ac65c617af00739f": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_d82e67b97ea24f80a1478783cfb0f365",
- "placeholder": "",
- "style": "IPY_MODEL_586958735baa4f29978d399852dc2aff",
- "value": " 5.23G/5.23G [02:03<00:00, 42.5MB/s]"
- }
- },
- "d82e67b97ea24f80a1478783cfb0f365": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "d95ba2612d5e409da8899e679e39c4ee": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "dacf87a2148c49db9306694b5a5f33da": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "db15fee2fae44e4babb449d56aeca0f3": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "ddabe3ec75d247468550ce9b202e30ab": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "ProgressStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "ProgressStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "bar_color": null,
- "description_width": ""
- }
- },
- "df141f6e170f4af98d009fd42043a359": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "FloatProgressModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "FloatProgressModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "ProgressView",
- "bar_style": "success",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_4495489fb35f495c898b334d75c8e1ed",
- "max": 17525357,
- "min": 0,
- "orientation": "horizontal",
- "style": "IPY_MODEL_34976cd4ca634e4cb7a5c0efffa41e81",
- "value": 17525357
- }
- },
- "e715b19f10c64131ba65d96bf968d72d": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HBoxModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HBoxModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HBoxView",
- "box_style": "",
- "children": [
- "IPY_MODEL_7d2b9dea260143eb8c2933a6d3592bb0",
- "IPY_MODEL_087ed90b113448aa9f5079457ca4ba2b",
- "IPY_MODEL_0f9fe85f7079487f837ef9a7a6d7cbc5"
- ],
- "layout": "IPY_MODEL_49680ea9e5ae4916b52e398e27f87ff5"
- }
- },
- "e8a1e9cc828f4a4d9c8f4e96b7fbb2fb": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_861dfc84b7364159a78379c91007e413",
- "placeholder": "",
- "style": "IPY_MODEL_b67122a0d1b24d168be2501782effd15",
- "value": "Generating train split: 100%"
- }
- },
- "e92ae53e3bc14aa59b8cee25909c1d2a": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "FloatProgressModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "FloatProgressModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "ProgressView",
- "bar_style": "success",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_4ec2221b24b94685887b091b45f3f746",
- "max": 2048,
- "min": 0,
- "orientation": "horizontal",
- "style": "IPY_MODEL_ee83baaeecd944a99c11f20f9b4f03fd",
- "value": 2048
- }
- },
- "e988eba4dbe546d484a6c4e88cf90b88": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "e9c00880fa4b47c7bf645c3f91a950a9": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_d5f566c5de7d4dd1808975839ab8b973",
- "placeholder": "",
- "style": "IPY_MODEL_0e17dd9f94714fb38ecbe3bd68873c1c",
- "value": " 636/636 [00:00<00:00, 33.0kB/s]"
- }
- },
- "ec45944210dc46058e722e9969a7dcdc": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_22f90aaa2b1642c9bf9b385010b8a4cb",
- "placeholder": "",
- "style": "IPY_MODEL_c7e6412c823d48e9845eecb1b4e4d7f1",
- "value": " 13.1M/13.1M [00:00<00:00, 49.8MB/s]"
- }
- },
- "ee83baaeecd944a99c11f20f9b4f03fd": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "ProgressStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "ProgressStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "bar_color": null,
- "description_width": ""
- }
- },
- "efec2d4919314a79bd55fed697631516": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "f0013cd0e75942a7b6f0af20d710c9f9": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "FloatProgressModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "FloatProgressModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "ProgressView",
- "bar_style": "success",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_5dd29f36fb5745618d95abda81e869bb",
- "max": 8199,
- "min": 0,
- "orientation": "horizontal",
- "style": "IPY_MODEL_f433b043c2ad41d7ba01a9ee1187fffe",
- "value": 8199
- }
- },
- "f2418db0b0ee4d3ca801f11c75ac1aca": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "f433b043c2ad41d7ba01a9ee1187fffe": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "ProgressStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "ProgressStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "bar_color": null,
- "description_width": ""
- }
- },
- "f701d542971a4238aa8b76affc054743": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "f7dba9ee7dd646f5bf4e9f8589addc83": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "FloatProgressModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "FloatProgressModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "ProgressView",
- "bar_style": "success",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_d26f0017695b4e42b1c2736c07575775",
- "max": 209,
- "min": 0,
- "orientation": "horizontal",
- "style": "IPY_MODEL_73aa48a573e349b1a05ba0bb5526bc2a",
- "value": 209
- }
- },
- "fb69e7b86acd485e814ffb0f7ef142f3": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_151b7ed8c9ca4a3192e2a28ff99c3dc6",
- "placeholder": "",
- "style": "IPY_MODEL_97f1a984a0a149bc9f305f18eb109b67",
- "value": "Map: 100%"
- }
- },
- "fdffb194cfad4bc2a2adb90614977445": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "fe486852cda849d5b2cf2dda69c46feb": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HBoxModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HBoxModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HBoxView",
- "box_style": "",
- "children": [
- "IPY_MODEL_9af5e516b8594e7da181917ff351e019",
- "IPY_MODEL_c6487dbfe53345b9822b372069f34922",
- "IPY_MODEL_baace428cd5545718ddc6d0749e53562"
- ],
- "layout": "IPY_MODEL_b12294da6032493e9ac7783b8e3ddaff"
- }
- }
- }
- }
- },
- "nbformat": 4,
- "nbformat_minor": 0
-}
"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": []
- }
- ],
- "metadata": {
- "accelerator": "GPU",
- "colab": {
- "gpuType": "T4",
- "provenance": []
- },
- "kernelspec": {
- "display_name": "Python 3",
- "name": "python3"
- },
- "language_info": {
- "codemirror_mode": {
- "name": "ipython",
- "version": 3
- },
- "file_extension": ".py",
- "mimetype": "text/x-python",
- "name": "python",
- "nbconvert_exporter": "python",
- "pygments_lexer": "ipython3",
- "version": "3.11.11"
- },
- "widgets": {
- "application/vnd.jupyter.widget-state+json": {
- "00dffcff57a14ad28d665cd2c2a11960": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "01b7fbea9de54e338e3862e09d7e353d": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "01bc169362704eeebd69a87d641d269e": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HBoxModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HBoxModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HBoxView",
- "box_style": "",
- "children": [
- "IPY_MODEL_7bbc93e57dda4424acb428027a9f014a",
- "IPY_MODEL_09b97b2a1f734e38b2a9908cf59edd8d",
- "IPY_MODEL_74dc454addc64783bbf1b3897a817147"
- ],
- "layout": "IPY_MODEL_47037605ebef451e91b64dd2fb040475"
- }
- },
- "02dbaaf3131648f8a5b0eb6bf7a4d089": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "02edcc6aafcf4895843ff5e93ef30f45": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HBoxModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HBoxModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HBoxView",
- "box_style": "",
- "children": [
- "IPY_MODEL_44c5c62e4af7441bafbc7734982aa660",
- "IPY_MODEL_4b81f2c217b24406be898b1333b56352",
- "IPY_MODEL_d73b1aa5cf2e46c9ac65c617af00739f"
- ],
- "layout": "IPY_MODEL_6e626c5ef0dd408eaf3139f6aabaf190"
- }
- },
- "087ed90b113448aa9f5079457ca4ba2b": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "FloatProgressModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "FloatProgressModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "ProgressView",
- "bar_style": "success",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_f2418db0b0ee4d3ca801f11c75ac1aca",
- "max": 913,
- "min": 0,
- "orientation": "horizontal",
- "style": "IPY_MODEL_676328ed1fb04ff4983a5b26df17d966",
- "value": 913
- }
- },
- "095a95bac5224763b7f512b468c7431d": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "09b97b2a1f734e38b2a9908cf59edd8d": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "FloatProgressModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "FloatProgressModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "ProgressView",
- "bar_style": "success",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_c4dc3a623a34415a83c2ffab0e19560b",
- "max": 4241003,
- "min": 0,
- "orientation": "horizontal",
- "style": "IPY_MODEL_cde4b31291a9493f8ef649269ca11e1c",
- "value": 4241003
- }
- },
- "0b18c6ae2dee474aae96fdbd81637024": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "0d4c7d8c22dc49b4be6d4948a3224852": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "0e17dd9f94714fb38ecbe3bd68873c1c": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "0f9fe85f7079487f837ef9a7a6d7cbc5": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_dacf87a2148c49db9306694b5a5f33da",
- "placeholder": "",
- "style": "IPY_MODEL_3198b48f531d4e26bff98917f9d2b592",
- "value": " 913/913 [00:00<00:00, 69.3kB/s]"
- }
- },
- "151b7ed8c9ca4a3192e2a28ff99c3dc6": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "16d840d19a804bec80ea85cafc850c13": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "1725a2fb58b94626a34f87c66ba0e8c2": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "1734b0819fe74736a0417a9e2b977695": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "ProgressStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "ProgressStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "bar_color": null,
- "description_width": ""
- }
- },
- "19f8ecfe426246eb93849b324e986d37": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "1a1e342e7aa943cd82c91b224ea01932": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "1a949dd5e121434dbbf1b0c290d71373": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "1acb7981a03c4d8491072db5b0f80b91": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_20f4fd378f6b44f386a6bdd9f0e787f7",
- "placeholder": "",
- "style": "IPY_MODEL_72693249b56e4995815d950d33ebbbba",
- "value": "README.md: 100%"
- }
- },
- "1c35e9b4250f4fca9e65ecfe4dcb4006": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "1caca54176f24a68841321407d5cb92c": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_304108b55b1c4ae58ac271e2d8616746",
- "placeholder": "",
- "style": "IPY_MODEL_1a1e342e7aa943cd82c91b224ea01932",
- "value": " 8.20k/8.20k [00:00<00:00, 349kB/s]"
- }
- },
- "1d6090d1b9e24e3cb550b655b8fbe318": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "1eacc88f8b754c7e93582ce65f99b5db": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "20f4fd378f6b44f386a6bdd9f0e787f7": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "22f90aaa2b1642c9bf9b385010b8a4cb": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "2318014fa6fd4452b76b5938a7da0c6f": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_c1d5a98c0f324e29a3628ff49718d7b6",
- "placeholder": "",
- "style": "IPY_MODEL_d0cb6b890289454981f6b9ad8cb2a0e1",
- "value": "tokenizer.json: 100%"
- }
- },
- "231e675f282d48a39e023149d4879b8b": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_16d840d19a804bec80ea85cafc850c13",
- "placeholder": "",
- "style": "IPY_MODEL_8642a2df48194dc2a0314de10e0a7635",
- "value": "tokenizer_config.json: 100%"
- }
- },
- "23790096dbc541d49e8db4c11a772a3f": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_a239a415866d47238ffa50a5c9c0a580",
- "placeholder": "",
- "style": "IPY_MODEL_00dffcff57a14ad28d665cd2c2a11960",
- "value": " 209/209 [00:00<00:00, 14.3kB/s]"
- }
- },
- "2846d60e43a24160b177166c25dd0122": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HBoxModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HBoxModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HBoxView",
- "box_style": "",
- "children": [
- "IPY_MODEL_231e675f282d48a39e023149d4879b8b",
- "IPY_MODEL_ce1a72b3385c44a2b6c8c36acc48867f",
- "IPY_MODEL_57180ced897d4007a6d836665a032802"
- ],
- "layout": "IPY_MODEL_8d2df8e3bb4b410f9f671d4cd2a6e80d"
- }
- },
- "2f803afa195c476fbfb506d53645c381": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "304108b55b1c4ae58ac271e2d8616746": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "3198b48f531d4e26bff98917f9d2b592": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "34711f6447034a728316aacfc401a7e8": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HBoxModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HBoxModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HBoxView",
- "box_style": "",
- "children": [
- "IPY_MODEL_fb69e7b86acd485e814ffb0f7ef142f3",
- "IPY_MODEL_e92ae53e3bc14aa59b8cee25909c1d2a",
- "IPY_MODEL_a6cc7eb40dbb4eff9c1e9a3f3b2aa381"
- ],
- "layout": "IPY_MODEL_91bf23bab4a84645b07952fc7a088c36"
- }
- },
- "34976cd4ca634e4cb7a5c0efffa41e81": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "ProgressStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "ProgressStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "bar_color": null,
- "description_width": ""
- }
- },
- "34ddb97a59d940879eb53d3e4dbe177e": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HBoxModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HBoxModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HBoxView",
- "box_style": "",
- "children": [
- "IPY_MODEL_be8a8c70a4c44ca4bd6fa595b29b3a35",
- "IPY_MODEL_f7dba9ee7dd646f5bf4e9f8589addc83",
- "IPY_MODEL_23790096dbc541d49e8db4c11a772a3f"
- ],
- "layout": "IPY_MODEL_19f8ecfe426246eb93849b324e986d37"
- }
- },
- "34ff40c5c4cf405d8ef59a12171b03a5": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_1c35e9b4250f4fca9e65ecfe4dcb4006",
- "placeholder": "",
- "style": "IPY_MODEL_1eacc88f8b754c7e93582ce65f99b5db",
- "value": "special_tokens_map.json: 100%"
- }
- },
- "389c5f0e14a24cf08aa175f1f21b22fc": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "389fffd528eb47f4b443b5e311a43629": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "395eb951f3044c20a6416c346c3e1cdd": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "3d6d0fa2af094773b593a85d6c51cf48": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_b17245b343ee4c2aad1afb45814ec63c",
- "placeholder": "",
- "style": "IPY_MODEL_fdffb194cfad4bc2a2adb90614977445",
- "value": "databricks-dolly-15k.jsonl: 100%"
- }
- },
- "43e58008991640f1a96e123f545ca52d": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "4495489fb35f495c898b334d75c8e1ed": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "44c5c62e4af7441bafbc7734982aa660": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_1725a2fb58b94626a34f87c66ba0e8c2",
- "placeholder": "",
- "style": "IPY_MODEL_1d6090d1b9e24e3cb550b655b8fbe318",
- "value": "model.safetensors: 100%"
- }
- },
- "453101669bb84ec784d30fdecf9e1052": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HBoxModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HBoxModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HBoxView",
- "box_style": "",
- "children": [
- "IPY_MODEL_1acb7981a03c4d8491072db5b0f80b91",
- "IPY_MODEL_f0013cd0e75942a7b6f0af20d710c9f9",
- "IPY_MODEL_1caca54176f24a68841321407d5cb92c"
- ],
- "layout": "IPY_MODEL_4bf984821d194c64945609ccf5d08ab0"
- }
- },
- "47037605ebef451e91b64dd2fb040475": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "49680ea9e5ae4916b52e398e27f87ff5": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "4b81f2c217b24406be898b1333b56352": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "FloatProgressModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "FloatProgressModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "ProgressView",
- "bar_style": "success",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_2f803afa195c476fbfb506d53645c381",
- "max": 5228717512,
- "min": 0,
- "orientation": "horizontal",
- "style": "IPY_MODEL_1734b0819fe74736a0417a9e2b977695",
- "value": 5228717512
- }
- },
- "4bf984821d194c64945609ccf5d08ab0": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "4ec2221b24b94685887b091b45f3f746": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "516627614ee0481aa5ac80cc77673a54": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "57180ced897d4007a6d836665a032802": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_ba606012b7a14ad2824fe6843930ca08",
- "placeholder": "",
- "style": "IPY_MODEL_9d5116fb35f44752a680fe7dc2b410b7",
- "value": " 47.0k/47.0k [00:00<00:00, 2.43MB/s]"
- }
- },
- "578a08d4d89b496dbca00da965b745d2": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HBoxModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HBoxModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HBoxView",
- "box_style": "",
- "children": [
- "IPY_MODEL_e8a1e9cc828f4a4d9c8f4e96b7fbb2fb",
- "IPY_MODEL_b631f91b3a5040e0b237936b412d274b",
- "IPY_MODEL_65670d440ae448c1862c9350e2784a3f"
- ],
- "layout": "IPY_MODEL_bb749eaf05dc4fbb9e134cc61caae11b"
- }
- },
- "586958735baa4f29978d399852dc2aff": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "589c07cbcc1b4d3db5bdee5a15dbd8df": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "5c780ea0aeee467da497547d78453492": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "5cd563e97ce742e99942f553b31e3bed": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "5dd29f36fb5745618d95abda81e869bb": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "6311ea720e344309b1d6fa1445f347e3": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "64d0bc7735bf42ce800f56ebcce3cdce": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "65670d440ae448c1862c9350e2784a3f": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_395eb951f3044c20a6416c346c3e1cdd",
- "placeholder": "",
- "style": "IPY_MODEL_516627614ee0481aa5ac80cc77673a54",
- "value": " 15011/15011 [00:00<00:00, 62410.60 examples/s]"
- }
- },
- "676328ed1fb04ff4983a5b26df17d966": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "ProgressStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "ProgressStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "bar_color": null,
- "description_width": ""
- }
- },
- "6a550e5a66704b7b819286707bd3a918": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HBoxModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HBoxModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HBoxView",
- "box_style": "",
- "children": [
- "IPY_MODEL_3d6d0fa2af094773b593a85d6c51cf48",
- "IPY_MODEL_8127e4af60a149f68318c0222641718f",
- "IPY_MODEL_ec45944210dc46058e722e9969a7dcdc"
- ],
- "layout": "IPY_MODEL_095a95bac5224763b7f512b468c7431d"
- }
- },
- "6e626c5ef0dd408eaf3139f6aabaf190": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "72693249b56e4995815d950d33ebbbba": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "73aa48a573e349b1a05ba0bb5526bc2a": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "ProgressStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "ProgressStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "bar_color": null,
- "description_width": ""
- }
- },
- "74dc454addc64783bbf1b3897a817147": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_7899c5e27ac64478a6e6ac767da24a20",
- "placeholder": "",
- "style": "IPY_MODEL_0b18c6ae2dee474aae96fdbd81637024",
- "value": " 4.24M/4.24M [00:00<00:00, 31.6MB/s]"
- }
- },
- "7899c5e27ac64478a6e6ac767da24a20": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "7bbc93e57dda4424acb428027a9f014a": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_f701d542971a4238aa8b76affc054743",
- "placeholder": "",
- "style": "IPY_MODEL_9498c07f6ad74b248c94de3bad444f62",
- "value": "tokenizer.model: 100%"
- }
- },
- "7d2b9dea260143eb8c2933a6d3592bb0": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_5cd563e97ce742e99942f553b31e3bed",
- "placeholder": "",
- "style": "IPY_MODEL_e988eba4dbe546d484a6c4e88cf90b88",
- "value": "config.json: 100%"
- }
- },
- "7d93f09ca25a498fbd4776daa0fc4c53": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "8127e4af60a149f68318c0222641718f": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "FloatProgressModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "FloatProgressModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "ProgressView",
- "bar_style": "success",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_589c07cbcc1b4d3db5bdee5a15dbd8df",
- "max": 13085339,
- "min": 0,
- "orientation": "horizontal",
- "style": "IPY_MODEL_ad5c35c060754bc8ae7bae0832af3921",
- "value": 13085339
- }
- },
- "81b9c3a820424c67a4c050545c2daa2e": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HBoxModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HBoxModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HBoxView",
- "box_style": "",
- "children": [
- "IPY_MODEL_2318014fa6fd4452b76b5938a7da0c6f",
- "IPY_MODEL_df141f6e170f4af98d009fd42043a359",
- "IPY_MODEL_c34cba3327304cf98154ce2c73218441"
- ],
- "layout": "IPY_MODEL_1a949dd5e121434dbbf1b0c290d71373"
- }
- },
- "861dfc84b7364159a78379c91007e413": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "8642a2df48194dc2a0314de10e0a7635": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "8d2df8e3bb4b410f9f671d4cd2a6e80d": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "91bf23bab4a84645b07952fc7a088c36": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "9498c07f6ad74b248c94de3bad444f62": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "97f1a984a0a149bc9f305f18eb109b67": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "9a7787f0d75847219071be822ccd76ba": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "9af5e516b8594e7da181917ff351e019": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_43e58008991640f1a96e123f545ca52d",
- "placeholder": "",
- "style": "IPY_MODEL_5c780ea0aeee467da497547d78453492",
- "value": "Map: 100%"
- }
- },
- "9bead4274c0c4fc6acf12bf6b9dec75a": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HBoxModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HBoxModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HBoxView",
- "box_style": "",
- "children": [
- "IPY_MODEL_34ff40c5c4cf405d8ef59a12171b03a5",
- "IPY_MODEL_9d8d908e12b846d58aea8b0e48dd6b92",
- "IPY_MODEL_e9c00880fa4b47c7bf645c3f91a950a9"
- ],
- "layout": "IPY_MODEL_7d93f09ca25a498fbd4776daa0fc4c53"
- }
- },
- "9d5116fb35f44752a680fe7dc2b410b7": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "9d8d908e12b846d58aea8b0e48dd6b92": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "FloatProgressModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "FloatProgressModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "ProgressView",
- "bar_style": "success",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_6311ea720e344309b1d6fa1445f347e3",
- "max": 636,
- "min": 0,
- "orientation": "horizontal",
- "style": "IPY_MODEL_ba866548b5544345b37e29f6d8e92652",
- "value": 636
- }
- },
- "a239a415866d47238ffa50a5c9c0a580": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "a6cc7eb40dbb4eff9c1e9a3f3b2aa381": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_db15fee2fae44e4babb449d56aeca0f3",
- "placeholder": "",
- "style": "IPY_MODEL_389c5f0e14a24cf08aa175f1f21b22fc",
- "value": " 2048/2048 [00:00<00:00, 6639.89 examples/s]"
- }
- },
- "ad5c35c060754bc8ae7bae0832af3921": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "ProgressStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "ProgressStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "bar_color": null,
- "description_width": ""
- }
- },
- "b12294da6032493e9ac7783b8e3ddaff": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "b17245b343ee4c2aad1afb45814ec63c": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "b631f91b3a5040e0b237936b412d274b": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "FloatProgressModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "FloatProgressModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "ProgressView",
- "bar_style": "success",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_02dbaaf3131648f8a5b0eb6bf7a4d089",
- "max": 15011,
- "min": 0,
- "orientation": "horizontal",
- "style": "IPY_MODEL_ddabe3ec75d247468550ce9b202e30ab",
- "value": 15011
- }
- },
- "b67122a0d1b24d168be2501782effd15": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "b73ef786040243589d43806a965f0eea": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "ProgressStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "ProgressStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "bar_color": null,
- "description_width": ""
- }
- },
- "ba606012b7a14ad2824fe6843930ca08": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "ba866548b5544345b37e29f6d8e92652": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "ProgressStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "ProgressStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "bar_color": null,
- "description_width": ""
- }
- },
- "baace428cd5545718ddc6d0749e53562": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_0d4c7d8c22dc49b4be6d4948a3224852",
- "placeholder": "",
- "style": "IPY_MODEL_d95ba2612d5e409da8899e679e39c4ee",
- "value": " 2048/2048 [00:00<00:00, 8114.30 examples/s]"
- }
- },
- "bb749eaf05dc4fbb9e134cc61caae11b": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "bc10c09f48534cc081dc53a4cc7bc20a": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "ProgressStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "ProgressStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "bar_color": null,
- "description_width": ""
- }
- },
- "be8a8c70a4c44ca4bd6fa595b29b3a35": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_efec2d4919314a79bd55fed697631516",
- "placeholder": "",
- "style": "IPY_MODEL_389fffd528eb47f4b443b5e311a43629",
- "value": "generation_config.json: 100%"
- }
- },
- "bf06c4115ae54e7b9da2838c9b6069a0": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "c1d5a98c0f324e29a3628ff49718d7b6": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "c34cba3327304cf98154ce2c73218441": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_64d0bc7735bf42ce800f56ebcce3cdce",
- "placeholder": "",
- "style": "IPY_MODEL_01b7fbea9de54e338e3862e09d7e353d",
- "value": " 17.5M/17.5M [00:00<00:00, 42.3MB/s]"
- }
- },
- "c4dc3a623a34415a83c2ffab0e19560b": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "c6487dbfe53345b9822b372069f34922": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "FloatProgressModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "FloatProgressModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "ProgressView",
- "bar_style": "success",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_bf06c4115ae54e7b9da2838c9b6069a0",
- "max": 2048,
- "min": 0,
- "orientation": "horizontal",
- "style": "IPY_MODEL_b73ef786040243589d43806a965f0eea",
- "value": 2048
- }
- },
- "c7e6412c823d48e9845eecb1b4e4d7f1": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "cde4b31291a9493f8ef649269ca11e1c": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "ProgressStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "ProgressStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "bar_color": null,
- "description_width": ""
- }
- },
- "ce1a72b3385c44a2b6c8c36acc48867f": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "FloatProgressModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "FloatProgressModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "ProgressView",
- "bar_style": "success",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_9a7787f0d75847219071be822ccd76ba",
- "max": 47022,
- "min": 0,
- "orientation": "horizontal",
- "style": "IPY_MODEL_bc10c09f48534cc081dc53a4cc7bc20a",
- "value": 47022
- }
- },
- "d0cb6b890289454981f6b9ad8cb2a0e1": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "d26f0017695b4e42b1c2736c07575775": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "d5f566c5de7d4dd1808975839ab8b973": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "d73b1aa5cf2e46c9ac65c617af00739f": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_d82e67b97ea24f80a1478783cfb0f365",
- "placeholder": "",
- "style": "IPY_MODEL_586958735baa4f29978d399852dc2aff",
- "value": " 5.23G/5.23G [02:03<00:00, 42.5MB/s]"
- }
- },
- "d82e67b97ea24f80a1478783cfb0f365": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "d95ba2612d5e409da8899e679e39c4ee": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "dacf87a2148c49db9306694b5a5f33da": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "db15fee2fae44e4babb449d56aeca0f3": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "ddabe3ec75d247468550ce9b202e30ab": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "ProgressStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "ProgressStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "bar_color": null,
- "description_width": ""
- }
- },
- "df141f6e170f4af98d009fd42043a359": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "FloatProgressModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "FloatProgressModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "ProgressView",
- "bar_style": "success",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_4495489fb35f495c898b334d75c8e1ed",
- "max": 17525357,
- "min": 0,
- "orientation": "horizontal",
- "style": "IPY_MODEL_34976cd4ca634e4cb7a5c0efffa41e81",
- "value": 17525357
- }
- },
- "e715b19f10c64131ba65d96bf968d72d": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HBoxModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HBoxModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HBoxView",
- "box_style": "",
- "children": [
- "IPY_MODEL_7d2b9dea260143eb8c2933a6d3592bb0",
- "IPY_MODEL_087ed90b113448aa9f5079457ca4ba2b",
- "IPY_MODEL_0f9fe85f7079487f837ef9a7a6d7cbc5"
- ],
- "layout": "IPY_MODEL_49680ea9e5ae4916b52e398e27f87ff5"
- }
- },
- "e8a1e9cc828f4a4d9c8f4e96b7fbb2fb": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_861dfc84b7364159a78379c91007e413",
- "placeholder": "",
- "style": "IPY_MODEL_b67122a0d1b24d168be2501782effd15",
- "value": "Generating train split: 100%"
- }
- },
- "e92ae53e3bc14aa59b8cee25909c1d2a": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "FloatProgressModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "FloatProgressModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "ProgressView",
- "bar_style": "success",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_4ec2221b24b94685887b091b45f3f746",
- "max": 2048,
- "min": 0,
- "orientation": "horizontal",
- "style": "IPY_MODEL_ee83baaeecd944a99c11f20f9b4f03fd",
- "value": 2048
- }
- },
- "e988eba4dbe546d484a6c4e88cf90b88": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "e9c00880fa4b47c7bf645c3f91a950a9": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_d5f566c5de7d4dd1808975839ab8b973",
- "placeholder": "",
- "style": "IPY_MODEL_0e17dd9f94714fb38ecbe3bd68873c1c",
- "value": " 636/636 [00:00<00:00, 33.0kB/s]"
- }
- },
- "ec45944210dc46058e722e9969a7dcdc": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_22f90aaa2b1642c9bf9b385010b8a4cb",
- "placeholder": "",
- "style": "IPY_MODEL_c7e6412c823d48e9845eecb1b4e4d7f1",
- "value": " 13.1M/13.1M [00:00<00:00, 49.8MB/s]"
- }
- },
- "ee83baaeecd944a99c11f20f9b4f03fd": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "ProgressStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "ProgressStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "bar_color": null,
- "description_width": ""
- }
- },
- "efec2d4919314a79bd55fed697631516": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "f0013cd0e75942a7b6f0af20d710c9f9": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "FloatProgressModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "FloatProgressModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "ProgressView",
- "bar_style": "success",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_5dd29f36fb5745618d95abda81e869bb",
- "max": 8199,
- "min": 0,
- "orientation": "horizontal",
- "style": "IPY_MODEL_f433b043c2ad41d7ba01a9ee1187fffe",
- "value": 8199
- }
- },
- "f2418db0b0ee4d3ca801f11c75ac1aca": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "f433b043c2ad41d7ba01a9ee1187fffe": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "ProgressStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "ProgressStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "bar_color": null,
- "description_width": ""
- }
- },
- "f701d542971a4238aa8b76affc054743": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "1.2.0",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "f7dba9ee7dd646f5bf4e9f8589addc83": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "FloatProgressModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "FloatProgressModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "ProgressView",
- "bar_style": "success",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_d26f0017695b4e42b1c2736c07575775",
- "max": 209,
- "min": 0,
- "orientation": "horizontal",
- "style": "IPY_MODEL_73aa48a573e349b1a05ba0bb5526bc2a",
- "value": 209
- }
- },
- "fb69e7b86acd485e814ffb0f7ef142f3": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_151b7ed8c9ca4a3192e2a28ff99c3dc6",
- "placeholder": "",
- "style": "IPY_MODEL_97f1a984a0a149bc9f305f18eb109b67",
- "value": "Map: 100%"
- }
- },
- "fdffb194cfad4bc2a2adb90614977445": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "fe486852cda849d5b2cf2dda69c46feb": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "1.5.0",
- "model_name": "HBoxModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HBoxModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HBoxView",
- "box_style": "",
- "children": [
- "IPY_MODEL_9af5e516b8594e7da181917ff351e019",
- "IPY_MODEL_c6487dbfe53345b9822b372069f34922",
- "IPY_MODEL_baace428cd5545718ddc6d0749e53562"
- ],
- "layout": "IPY_MODEL_b12294da6032493e9ac7783b8e3ddaff"
- }
- }
- }
- }
- },
- "nbformat": 4,
- "nbformat_minor": 0
-}
 \n",
- " Visit MIT Deep Learning
\n",
- " Visit MIT Deep Learning Run in Google Colab
Run in Google Colab View Source on GitHub
View Source on GitHub