|
| 1 | +{ |
| 2 | + "cells": [ |
| 3 | + { |
| 4 | + "cell_type": "markdown", |
| 5 | + "metadata": {}, |
| 6 | + "source": [ |
| 7 | + "# Example : Optimized Tensorflow workflow\n", |
| 8 | + "\n", |
| 9 | + "## Summary\n", |
| 10 | + "This example is optimized tensorflow training workflow.\n", |
| 11 | + "\n", |
| 12 | + "On this example, we will train hand-writing number classification model with [MNIST dataset](https://en.wikipedia.org/wiki/MNIST_database).\n", |
| 13 | + "\n", |
| 14 | + "\n", |
| 15 | + "We will a lots of skills for solve problem of common training workflow\n", |
| 16 | + "\n", |
| 17 | + "#### Problem of unoptimized workflow\n", |
| 18 | + "* Use too much VRAM(Even it really doesn't need)\n", |
| 19 | + "* Slow Training Speed\n", |
| 20 | + "\n", |
| 21 | + "- - -\n", |
| 22 | + "### Import pacakges" |
| 23 | + ] |
| 24 | + }, |
| 25 | + { |
| 26 | + "cell_type": "code", |
| 27 | + "execution_count": null, |
| 28 | + "metadata": {}, |
| 29 | + "outputs": [], |
| 30 | + "source": [ |
| 31 | + "import tensorflow as tf\n", |
| 32 | + "from nvidia.dali import pipeline_def, fn, types\n", |
| 33 | + "import nvidia.dali.plugin.tf as dali_tf\n", |
| 34 | + "\n", |
| 35 | + "import os\n", |
| 36 | + "import glob\n", |
| 37 | + "import math\n" |
| 38 | + ] |
| 39 | + }, |
| 40 | + { |
| 41 | + "cell_type": "markdown", |
| 42 | + "metadata": {}, |
| 43 | + "source": [ |
| 44 | + "#### What those packages do?\n", |
| 45 | + "* [TensorFlow](https://www.tensorflow.org/) : Define and training model.\n", |
| 46 | + "* [nvidia.dali](https://developer.nvidia.com/dali/) : Preprocess and load data with GPU-acceleration.\n", |
| 47 | + "* [os](https://docs.python.org/3/library/os.html) : Get label and join splited path to one.\n", |
| 48 | + "* [glob](https://docs.python.org/3/library/glob.html) : Get all image files absolute path.\n", |
| 49 | + "* [math](https://docs.python.org/3/library/math.html) : Compute iteration per epoch with ceil.\n", |
| 50 | + "---\n", |
| 51 | + "## Optimizing method\n", |
| 52 | + "* GPU Accelerated Dataloader - [Nvidia DALI](https://developer.nvidia.com/dali/)\n", |
| 53 | + " * Reduce RAM - CPU - GPU Memory bottleneck with [GPU Direct Storage](https://docs.nvidia.com/gpudirect-storage/overview-guide/index.html)\n", |
| 54 | + " * Data augmentation with GPU Acceleration\n", |
| 55 | + "* Fast Forward/Backward Computation - [Mixed Precision Training](https://arxiv.org/abs/1710.03740)\n", |
| 56 | + " * Effective [MMA (Matrix Multiply-accumulate)](https://en.wikipedia.org/wiki/Multiply%E2%80%93accumulate_operation) Computation on Nvidia Ampere GPU\n", |
| 57 | + "* Optimized GPU job scheduler - [XLA](https://www.tensorflow.org/xla)\n", |
| 58 | + " * Optimize [SM (Stream Multiprocessor)](https://images.nvidia.com/aem-dam/en-zz/Solutions/data-center/nvidia-ampere-architecture-whitepaper.pdf#page=22) interal job scheduling\n", |
| 59 | + "* Change TensorFlow GPU memory strategy\n", |
| 60 | + " * Reduce GPU memory consumption of TensorFlow process\n", |
| 61 | + "\n", |
| 62 | + "### Set TensorFlow runtime setting\n", |
| 63 | + "To enable mixed precision training and change GPU memory strategy, this code block need to be run." |
| 64 | + ] |
| 65 | + }, |
| 66 | + { |
| 67 | + "cell_type": "code", |
| 68 | + "execution_count": null, |
| 69 | + "metadata": {}, |
| 70 | + "outputs": [], |
| 71 | + "source": [ |
| 72 | + "gpu_ids = [0]\n", |
| 73 | + "# Replace 0 with device id what you will use.\n", |
| 74 | + "\n", |
| 75 | + "# Get available GPUs\n", |
| 76 | + "gpus = tf.config.list_physical_devices('GPU')\n", |
| 77 | + "target_gpus = [gpus[gpu_id] for gpu_id in gpu_ids]\n", |
| 78 | + "\n", |
| 79 | + "# Set tensorflow can use all selected GPUs\n", |
| 80 | + "tf.config.set_visible_devices(target_gpus, 'GPU')\n", |
| 81 | + "\n", |
| 82 | + "#Memory strategy change : allocate as much as possible -> allocate as need\n", |
| 83 | + "for target_gpu in target_gpus:\n", |
| 84 | + " tf.config.experimental.set_memory_growth(target_gpu, True)\n", |
| 85 | + "\n", |
| 86 | + "# Make TensorFlow use mixed precision training\n", |
| 87 | + "tf.keras.mixed_precision.set_global_policy('mixed_float16')" |
| 88 | + ] |
| 89 | + }, |
| 90 | + { |
| 91 | + "cell_type": "markdown", |
| 92 | + "metadata": {}, |
| 93 | + "source": [ |
| 94 | + "### Define dataset and dataloader\n", |
| 95 | + "We will assume dataset is infinite or It can only stored partial dataset in [RAM](https://en.wikipedia.org/wiki/Random-access_memory).\\\n", |
| 96 | + "So we will use `DALI` to load every decoded data to GPU Memory with [DMA(Direct Memory Access)](https://en.wikipedia.org/wiki/Direct_memory_access) and augment it.\n", |
| 97 | + "\n", |
| 98 | + "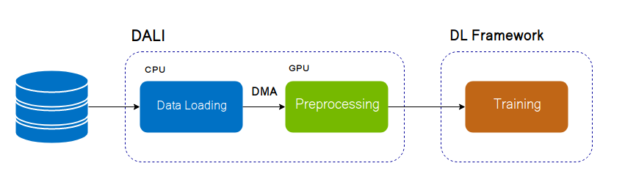" |
| 99 | + ] |
| 100 | + }, |
| 101 | + { |
| 102 | + "cell_type": "code", |
| 103 | + "execution_count": null, |
| 104 | + "metadata": {}, |
| 105 | + "outputs": [], |
| 106 | + "source": [ |
| 107 | + "# Define batch size and images path for dataloader\n", |
| 108 | + "batch_size = 2560\n", |
| 109 | + "image_dir = r'./mnist_png/training/'\n", |
| 110 | + "\n", |
| 111 | + "# Define dali image pipeline\n", |
| 112 | + "@pipeline_def(batch_size=batch_size)\n", |
| 113 | + "def mnist_pipeline(image_dir):\n", |
| 114 | + " images, labels = fn.readers.file(file_root=image_dir)\n", |
| 115 | + " images = fn.decoders.image(images, device='mixed', output_type=types.GRAY)\n", |
| 116 | + " images = fn.crop_mirror_normalize(images, device=\"gpu\", dtype=types.FLOAT, std=[255.], output_layout=\"CHW\")\n", |
| 117 | + " labels = labels.gpu()\n", |
| 118 | + " return (images, labels)\n", |
| 119 | + "\n", |
| 120 | + "# Define shapes and dtypes for dali tensorflow dataloader\n", |
| 121 | + "shapes = (\n", |
| 122 | + " (batch_size, 1, 28, 28),\n", |
| 123 | + " (batch_size))\n", |
| 124 | + "dtypes = (\n", |
| 125 | + " tf.float32,\n", |
| 126 | + " tf.int32)\n", |
| 127 | + "\n", |
| 128 | + "\n", |
| 129 | + "dataloader = dali_tf.DALIDataset(\n", |
| 130 | + " pipeline=mnist_pipeline(image_dir),\n", |
| 131 | + " batch_size=batch_size,\n", |
| 132 | + " output_shapes=shapes,\n", |
| 133 | + " output_dtypes=dtypes,\n", |
| 134 | + " device_id=gpu_ids[0]\n", |
| 135 | + ")" |
| 136 | + ] |
| 137 | + }, |
| 138 | + { |
| 139 | + "cell_type": "markdown", |
| 140 | + "metadata": {}, |
| 141 | + "source": [ |
| 142 | + "#### How DALI works\n", |
| 143 | + "\n", |
| 144 | + "\n", |
| 145 | + "On this dataloader, `DALI` will load batch with this process\n", |
| 146 | + "1. Decode image file on CPU to transform it to array.\n", |
| 147 | + "2. Directly send raw array to GPU.\n", |
| 148 | + "3. Preprocess data with GPU-Acceleration.\n", |
| 149 | + "4. Prefetch next batch and load batch it to training process when batch end.\n", |
| 150 | + "\n", |
| 151 | + "Batch will prefetched like image below.\n", |
| 152 | + "\n", |
| 153 | + "\n", |
| 154 | + "\n", |
| 155 | + "dataflow will be like picture below:\n", |
| 156 | + "\n", |
| 157 | + "<img src=\"./imgs/gpudirect_storage.png\" width='425px' height='450px'>\n", |
| 158 | + "\n", |
| 159 | + "---\n", |
| 160 | + "\n", |
| 161 | + "### Define model, optimizer, loss function\n", |
| 162 | + "\n", |
| 163 | + "This example Task is 'Multi labels classification'. so model would like below.\n", |
| 164 | + "\n", |
| 165 | + "* Model is simple model Based on [Convolutional Layers](https://arxiv.org/abs/1511.08458).\n", |
| 166 | + "* Loss function will be [sparse categorical crossentropy](https://datascience.stackexchange.com/questions/41921/sparse-categorical-crossentropy-vs-categorical-crossentropy-keras-accuracy).\n", |
| 167 | + "* Optimizer will be [AdamW](https://arxiv.org/abs/1711.05101).\n", |
| 168 | + "\n", |
| 169 | + "For convenience, model's performance would be only measured by train set accuracy.\n", |
| 170 | + "\n", |
| 171 | + "#### Model architecture\n", |
| 172 | + "<img src=\"./imgs/model_architecture.png\" width=\"300px\" height=\"500px\">" |
| 173 | + ] |
| 174 | + }, |
| 175 | + { |
| 176 | + "cell_type": "code", |
| 177 | + "execution_count": null, |
| 178 | + "metadata": {}, |
| 179 | + "outputs": [], |
| 180 | + "source": [ |
| 181 | + "model = tf.keras.Sequential([\n", |
| 182 | + " tf.keras.layers.Conv2D(32, kernel_size=(3,3), input_shape=(1, 28, 28), activation='relu', data_format='channels_first'),\n", |
| 183 | + " tf.keras.layers.Conv2D(64, kernel_size=(3,3), activation='relu'),\n", |
| 184 | + " tf.keras.layers.MaxPool2D(pool_size=(2,2)),\n", |
| 185 | + " tf.keras.layers.Flatten(),\n", |
| 186 | + " tf.keras.layers.Dense(512, activation='relu'),\n", |
| 187 | + " tf.keras.layers.Dense(128)\n", |
| 188 | + "])\n", |
| 189 | + "\n", |
| 190 | + "optimizer = tf.keras.optimizers.AdamW(learning_rate=0.001)\n", |
| 191 | + "loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)\n", |
| 192 | + "metrics = ['accuracy']" |
| 193 | + ] |
| 194 | + }, |
| 195 | + { |
| 196 | + "cell_type": "markdown", |
| 197 | + "metadata": {}, |
| 198 | + "source": [ |
| 199 | + "### Compile model and start training\n", |
| 200 | + "\n", |
| 201 | + "For use XLA, `jit_compile` flag must be `True` on model compile.\n", |
| 202 | + "```\n", |
| 203 | + "model.compile(..., jit_compile=True)\n", |
| 204 | + "```\n", |
| 205 | + "\n", |
| 206 | + "\n", |
| 207 | + "Current Training Environment is like below:\n", |
| 208 | + "\n", |
| 209 | + "|Precision|Batch preprocssing|Batch caching|GPU select|GPU memory strategy|\n", |
| 210 | + "|---|---|---|---|---|\n", |
| 211 | + "|FP16|Inline<br>Compute by GPU|Prefetch on batch demands<br>Stored in GPU memory|Selectable By user|Grow up when need|\n" |
| 212 | + ] |
| 213 | + }, |
| 214 | + { |
| 215 | + "cell_type": "code", |
| 216 | + "execution_count": null, |
| 217 | + "metadata": {}, |
| 218 | + "outputs": [], |
| 219 | + "source": [ |
| 220 | + "# Define train epochs\n", |
| 221 | + "epochs = 100\n", |
| 222 | + "\n", |
| 223 | + "# Compile model with XLA\n", |
| 224 | + "model.compile(optimizer=optimizer,\n", |
| 225 | + " loss=loss_fn,\n", |
| 226 | + " metrics=metrics,\n", |
| 227 | + "\t\t\tjit_compile=True)\n", |
| 228 | + "\n", |
| 229 | + "# Compute interation per epoch for 'large but limited size dataset'\n", |
| 230 | + "# If dataset's size is infinite, set how many step to do on 1 epoch\n", |
| 231 | + "iteration_per_epoch = math.ceil(len(glob.glob(os.path.join(image_dir, '*/*.png')))/batch_size)\n", |
| 232 | + "\n", |
| 233 | + "model.fit(dataloader, epochs=epochs, steps_per_epoch=iteration_per_epoch)" |
| 234 | + ] |
| 235 | + }, |
| 236 | + { |
| 237 | + "cell_type": "markdown", |
| 238 | + "metadata": {}, |
| 239 | + "source": [ |
| 240 | + "### After Training\n", |
| 241 | + "TensorFlow have [critical bug](https://github.com/tensorflow/tensorflow/issues/1727#issuecomment-225665915) that **won't release GPU memory** after model used(both Training, Evaluation).\\\n", |
| 242 | + "So we need to free GPU memory for other users.\n", |
| 243 | + "\n", |
| 244 | + "#### Step\n", |
| 245 | + "1. [Save trained model](https://www.tensorflow.org/guide/keras/save_and_serialize)\n", |
| 246 | + "2. Kill Tensorflow Process" |
| 247 | + ] |
| 248 | + }, |
| 249 | + { |
| 250 | + "cell_type": "code", |
| 251 | + "execution_count": null, |
| 252 | + "metadata": {}, |
| 253 | + "outputs": [], |
| 254 | + "source": [ |
| 255 | + "model_save_path = r'./latest.h5'\n", |
| 256 | + "\n", |
| 257 | + "# save model to file\n", |
| 258 | + "model.save(model_save_path)\n", |
| 259 | + "exit(0)\n" |
| 260 | + ] |
| 261 | + }, |
| 262 | + { |
| 263 | + "cell_type": "markdown", |
| 264 | + "metadata": {}, |
| 265 | + "source": [ |
| 266 | + "### Compare optimization Before & After \n", |
| 267 | + "\n", |
| 268 | + "\n", |
| 269 | + "||Before|After|\n", |
| 270 | + "|---|---|---\n", |
| 271 | + "|**Precision**|TF32|FP16|\n", |
| 272 | + "|**Dataloader**|TensorFlow|Nvidia DALI|\n", |
| 273 | + "|**Batch caching**|Next batch only<br>RAM|Auto-Adjusted by DALI<br>GPU memory|\n", |
| 274 | + "|**Batch preprocessing**|OpenCV/Numpy<br>CPU|DALI<br>GPU|\n", |
| 275 | + "|**GPU Usage**|Training|Training<br>Preprocessing|\n", |
| 276 | + "|**GPU Select**|Automatically Selected by TensorFlow|Selectable By user|\n", |
| 277 | + "|**GPU memory strategy**|As much as Possible<br>([Automatically Selected by TensorFlow]((https://www.tensorflow.org/guide/gpu#limiting_gpu_memory_growth)))|Grow up when need|" |
| 278 | + ] |
| 279 | + } |
| 280 | + ], |
| 281 | + "metadata": { |
| 282 | + "kernelspec": { |
| 283 | + "display_name": "tensorflow", |
| 284 | + "language": "python", |
| 285 | + "name": "python3" |
| 286 | + }, |
| 287 | + "language_info": { |
| 288 | + "codemirror_mode": { |
| 289 | + "name": "ipython", |
| 290 | + "version": 3 |
| 291 | + }, |
| 292 | + "file_extension": ".py", |
| 293 | + "mimetype": "text/x-python", |
| 294 | + "name": "python", |
| 295 | + "nbconvert_exporter": "python", |
| 296 | + "pygments_lexer": "ipython3", |
| 297 | + "version": "3.10.11" |
| 298 | + }, |
| 299 | + "orig_nbformat": 4 |
| 300 | + }, |
| 301 | + "nbformat": 4, |
| 302 | + "nbformat_minor": 2 |
| 303 | +} |
0 commit comments