You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
Recently, I ran into a weird issue in production where sometimes our Worker would just explode, and throw obscure CONNECT_TIMEOUT errors to Postgres, despite working previously for months. Our production environment was down, but with assistance from @WalshyDev and hours of debugging, we found that massively reducing our number of PG connections resolved the problem.
Locally, this works without issue. However if you deploy this to production Workers, it'll end up in an exception being thrown as can be seen at https://postgres-deadlock-example.jross.workers.dev/, and errors like this in the logs:
I suspect this is something to do with the 6 concurrent connections that Workers allow, before subsequent ones are queued, but considering that these DB connections aren't closed until the end of the requests, they're hanging open forever and causing a deadlock? This is a pretty common pattern in production apps that use Hono, Next.js, etc - you have a function that either returns a db instance, or creates one and then sets it on some reusable storage like context, ALS, etc. so you don't constantly spin up and down new connections to the DB.
The default postgresmax connections is 10, which is what I've been using up to this point in my works since all the Cloudflare docs don't specify any options in all of their docs examples, and I believe I've seen folks mention that defaults are fine. If I drop max to 3, with something like postgres(..., { max: 3 }), the problem doesn't happen because only 3 connections are being spun up by the driver.
I reported this to a few folks, and there's a couple of changes in docs and postgres now at:
Ideally, with TCP connections, deadlocks would be logged in some way that's much easier to debug. Chasing obscure timeout errors led to the most confusion here.
The text was updated successfully, but these errors were encountered:
Recently, I ran into a weird issue in production where sometimes our Worker would just explode, and throw obscure
CONNECT_TIMEOUTerrors to Postgres, despite working previously for months. Our production environment was down, but with assistance from @WalshyDev and hours of debugging, we found that massively reducing our number of PG connections resolved the problem.However, take this example worker:
Locally, this works without issue. However if you deploy this to production Workers, it'll end up in an exception being thrown as can be seen at https://postgres-deadlock-example.jross.workers.dev/, and errors like this in the logs:
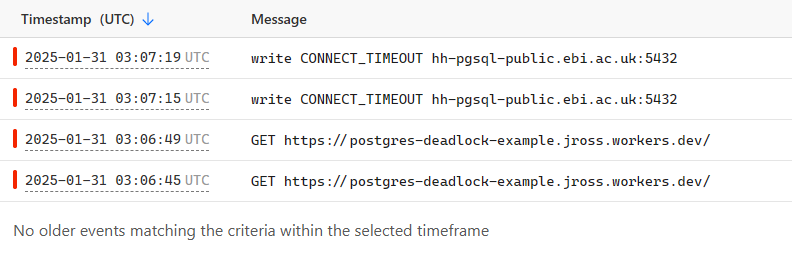
I suspect this is something to do with the 6 concurrent connections that Workers allow, before subsequent ones are queued, but considering that these DB connections aren't closed until the end of the requests, they're hanging open forever and causing a deadlock? This is a pretty common pattern in production apps that use Hono, Next.js, etc - you have a function that either returns a
dbinstance, or creates one and then sets it on some reusable storage likecontext, ALS, etc. so you don't constantly spin up and down new connections to the DB.The default
postgresmaxconnections is 10, which is what I've been using up to this point in my works since all the Cloudflare docs don't specify any options in all of their docs examples, and I believe I've seen folks mention that defaults are fine. If I dropmaxto3, with something likepostgres(..., { max: 3 }), the problem doesn't happen because only 3 connections are being spun up by the driver.I reported this to a few folks, and there's a couple of changes in docs and
postgresnow at:Ideally, with TCP connections, deadlocks would be logged in some way that's much easier to debug. Chasing obscure timeout errors led to the most confusion here.
The text was updated successfully, but these errors were encountered: