diff --git a/.gitignore b/.gitignore
new file mode 100644
index 0000000..e948919
--- /dev/null
+++ b/.gitignore
@@ -0,0 +1,89 @@
+# Windows image file caches
+Thumbs.db
+ehthumbs.db
+
+# Folder config file
+Desktop.ini
+
+# Recycle Bin used on file shares
+$RECYCLE.BIN/
+
+# Windows Installer files
+*.cab
+*.msi
+*.msm
+*.msp
+
+# Windows shortcuts
+*.lnk
+
+# =========================
+# Operating System Files
+# =========================
+
+
+# OSX
+# =========================
+
+.DS_Store
+*/.DS_Store
+.AppleDouble
+.LSOverride
+
+# Thumbnails
+._*
+
+# Files that might appear in the root of a volume
+.DocumentRevisions-V100
+.fseventsd
+.Spotlight-V100
+.TemporaryItems
+.Trashes
+.VolumeIcon.icns
+
+# Directories potentially created on remote AFP share
+.AppleDB
+.AppleDesktop
+Network Trash Folder
+Temporary Items
+.apdisk
+
+*.class
+logs/*
+*/logs/*
+**/logs/*
+
+*.o
+
+# xcode
+*.xcodeproj*
+
+# idea
+.idea*
+.idea/*
+*/.idea*
+*.iml
+*/*.iml
+
+# sbt specific
+.cache/
+.history/
+.lib/
+dist/*
+target/*
+out/*
+lib_managed/
+src_managed/
+project/boot/
+project/plugins/project/
+.sbtserver/
+classes/*
+
+# Scala-IDE specific
+.scala_dependencies
+.worksheet
+.*.swp
+
+# sbt-assembly
+*-assembly.jar
+sg_agent/
diff --git a/LICENSE b/LICENSE
new file mode 100644
index 0000000..89e08fb
--- /dev/null
+++ b/LICENSE
@@ -0,0 +1,339 @@
+ GNU GENERAL PUBLIC LICENSE
+ Version 2, June 1991
+
+ Copyright (C) 1989, 1991 Free Software Foundation, Inc.,
+ 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA
+ Everyone is permitted to copy and distribute verbatim copies
+ of this license document, but changing it is not allowed.
+
+ Preamble
+
+ The licenses for most software are designed to take away your
+freedom to share and change it. By contrast, the GNU General Public
+License is intended to guarantee your freedom to share and change free
+software--to make sure the software is free for all its users. This
+General Public License applies to most of the Free Software
+Foundation's software and to any other program whose authors commit to
+using it. (Some other Free Software Foundation software is covered by
+the GNU Lesser General Public License instead.) You can apply it to
+your programs, too.
+
+ When we speak of free software, we are referring to freedom, not
+price. Our General Public Licenses are designed to make sure that you
+have the freedom to distribute copies of free software (and charge for
+this service if you wish), that you receive source code or can get it
+if you want it, that you can change the software or use pieces of it
+in new free programs; and that you know you can do these things.
+
+ To protect your rights, we need to make restrictions that forbid
+anyone to deny you these rights or to ask you to surrender the rights.
+These restrictions translate to certain responsibilities for you if you
+distribute copies of the software, or if you modify it.
+
+ For example, if you distribute copies of such a program, whether
+gratis or for a fee, you must give the recipients all the rights that
+you have. You must make sure that they, too, receive or can get the
+source code. And you must show them these terms so they know their
+rights.
+
+ We protect your rights with two steps: (1) copyright the software, and
+(2) offer you this license which gives you legal permission to copy,
+distribute and/or modify the software.
+
+ Also, for each author's protection and ours, we want to make certain
+that everyone understands that there is no warranty for this free
+software. If the software is modified by someone else and passed on, we
+want its recipients to know that what they have is not the original, so
+that any problems introduced by others will not reflect on the original
+authors' reputations.
+
+ Finally, any free program is threatened constantly by software
+patents. We wish to avoid the danger that redistributors of a free
+program will individually obtain patent licenses, in effect making the
+program proprietary. To prevent this, we have made it clear that any
+patent must be licensed for everyone's free use or not licensed at all.
+
+ The precise terms and conditions for copying, distribution and
+modification follow.
+
+ GNU GENERAL PUBLIC LICENSE
+ TERMS AND CONDITIONS FOR COPYING, DISTRIBUTION AND MODIFICATION
+
+ 0. This License applies to any program or other work which contains
+a notice placed by the copyright holder saying it may be distributed
+under the terms of this General Public License. The "Program", below,
+refers to any such program or work, and a "work based on the Program"
+means either the Program or any derivative work under copyright law:
+that is to say, a work containing the Program or a portion of it,
+either verbatim or with modifications and/or translated into another
+language. (Hereinafter, translation is included without limitation in
+the term "modification".) Each licensee is addressed as "you".
+
+Activities other than copying, distribution and modification are not
+covered by this License; they are outside its scope. The act of
+running the Program is not restricted, and the output from the Program
+is covered only if its contents constitute a work based on the
+Program (independent of having been made by running the Program).
+Whether that is true depends on what the Program does.
+
+ 1. You may copy and distribute verbatim copies of the Program's
+source code as you receive it, in any medium, provided that you
+conspicuously and appropriately publish on each copy an appropriate
+copyright notice and disclaimer of warranty; keep intact all the
+notices that refer to this License and to the absence of any warranty;
+and give any other recipients of the Program a copy of this License
+along with the Program.
+
+You may charge a fee for the physical act of transferring a copy, and
+you may at your option offer warranty protection in exchange for a fee.
+
+ 2. You may modify your copy or copies of the Program or any portion
+of it, thus forming a work based on the Program, and copy and
+distribute such modifications or work under the terms of Section 1
+above, provided that you also meet all of these conditions:
+
+ a) You must cause the modified files to carry prominent notices
+ stating that you changed the files and the date of any change.
+
+ b) You must cause any work that you distribute or publish, that in
+ whole or in part contains or is derived from the Program or any
+ part thereof, to be licensed as a whole at no charge to all third
+ parties under the terms of this License.
+
+ c) If the modified program normally reads commands interactively
+ when run, you must cause it, when started running for such
+ interactive use in the most ordinary way, to print or display an
+ announcement including an appropriate copyright notice and a
+ notice that there is no warranty (or else, saying that you provide
+ a warranty) and that users may redistribute the program under
+ these conditions, and telling the user how to view a copy of this
+ License. (Exception: if the Program itself is interactive but
+ does not normally print such an announcement, your work based on
+ the Program is not required to print an announcement.)
+
+These requirements apply to the modified work as a whole. If
+identifiable sections of that work are not derived from the Program,
+and can be reasonably considered independent and separate works in
+themselves, then this License, and its terms, do not apply to those
+sections when you distribute them as separate works. But when you
+distribute the same sections as part of a whole which is a work based
+on the Program, the distribution of the whole must be on the terms of
+this License, whose permissions for other licensees extend to the
+entire whole, and thus to each and every part regardless of who wrote it.
+
+Thus, it is not the intent of this section to claim rights or contest
+your rights to work written entirely by you; rather, the intent is to
+exercise the right to control the distribution of derivative or
+collective works based on the Program.
+
+In addition, mere aggregation of another work not based on the Program
+with the Program (or with a work based on the Program) on a volume of
+a storage or distribution medium does not bring the other work under
+the scope of this License.
+
+ 3. You may copy and distribute the Program (or a work based on it,
+under Section 2) in object code or executable form under the terms of
+Sections 1 and 2 above provided that you also do one of the following:
+
+ a) Accompany it with the complete corresponding machine-readable
+ source code, which must be distributed under the terms of Sections
+ 1 and 2 above on a medium customarily used for software interchange; or,
+
+ b) Accompany it with a written offer, valid for at least three
+ years, to give any third party, for a charge no more than your
+ cost of physically performing source distribution, a complete
+ machine-readable copy of the corresponding source code, to be
+ distributed under the terms of Sections 1 and 2 above on a medium
+ customarily used for software interchange; or,
+
+ c) Accompany it with the information you received as to the offer
+ to distribute corresponding source code. (This alternative is
+ allowed only for noncommercial distribution and only if you
+ received the program in object code or executable form with such
+ an offer, in accord with Subsection b above.)
+
+The source code for a work means the preferred form of the work for
+making modifications to it. For an executable work, complete source
+code means all the source code for all modules it contains, plus any
+associated interface definition files, plus the scripts used to
+control compilation and installation of the executable. However, as a
+special exception, the source code distributed need not include
+anything that is normally distributed (in either source or binary
+form) with the major components (compiler, kernel, and so on) of the
+operating system on which the executable runs, unless that component
+itself accompanies the executable.
+
+If distribution of executable or object code is made by offering
+access to copy from a designated place, then offering equivalent
+access to copy the source code from the same place counts as
+distribution of the source code, even though third parties are not
+compelled to copy the source along with the object code.
+
+ 4. You may not copy, modify, sublicense, or distribute the Program
+except as expressly provided under this License. Any attempt
+otherwise to copy, modify, sublicense or distribute the Program is
+void, and will automatically terminate your rights under this License.
+However, parties who have received copies, or rights, from you under
+this License will not have their licenses terminated so long as such
+parties remain in full compliance.
+
+ 5. You are not required to accept this License, since you have not
+signed it. However, nothing else grants you permission to modify or
+distribute the Program or its derivative works. These actions are
+prohibited by law if you do not accept this License. Therefore, by
+modifying or distributing the Program (or any work based on the
+Program), you indicate your acceptance of this License to do so, and
+all its terms and conditions for copying, distributing or modifying
+the Program or works based on it.
+
+ 6. Each time you redistribute the Program (or any work based on the
+Program), the recipient automatically receives a license from the
+original licensor to copy, distribute or modify the Program subject to
+these terms and conditions. You may not impose any further
+restrictions on the recipients' exercise of the rights granted herein.
+You are not responsible for enforcing compliance by third parties to
+this License.
+
+ 7. If, as a consequence of a court judgment or allegation of patent
+infringement or for any other reason (not limited to patent issues),
+conditions are imposed on you (whether by court order, agreement or
+otherwise) that contradict the conditions of this License, they do not
+excuse you from the conditions of this License. If you cannot
+distribute so as to satisfy simultaneously your obligations under this
+License and any other pertinent obligations, then as a consequence you
+may not distribute the Program at all. For example, if a patent
+license would not permit royalty-free redistribution of the Program by
+all those who receive copies directly or indirectly through you, then
+the only way you could satisfy both it and this License would be to
+refrain entirely from distribution of the Program.
+
+If any portion of this section is held invalid or unenforceable under
+any particular circumstance, the balance of the section is intended to
+apply and the section as a whole is intended to apply in other
+circumstances.
+
+It is not the purpose of this section to induce you to infringe any
+patents or other property right claims or to contest validity of any
+such claims; this section has the sole purpose of protecting the
+integrity of the free software distribution system, which is
+implemented by public license practices. Many people have made
+generous contributions to the wide range of software distributed
+through that system in reliance on consistent application of that
+system; it is up to the author/donor to decide if he or she is willing
+to distribute software through any other system and a licensee cannot
+impose that choice.
+
+This section is intended to make thoroughly clear what is believed to
+be a consequence of the rest of this License.
+
+ 8. If the distribution and/or use of the Program is restricted in
+certain countries either by patents or by copyrighted interfaces, the
+original copyright holder who places the Program under this License
+may add an explicit geographical distribution limitation excluding
+those countries, so that distribution is permitted only in or among
+countries not thus excluded. In such case, this License incorporates
+the limitation as if written in the body of this License.
+
+ 9. The Free Software Foundation may publish revised and/or new versions
+of the General Public License from time to time. Such new versions will
+be similar in spirit to the present version, but may differ in detail to
+address new problems or concerns.
+
+Each version is given a distinguishing version number. If the Program
+specifies a version number of this License which applies to it and "any
+later version", you have the option of following the terms and conditions
+either of that version or of any later version published by the Free
+Software Foundation. If the Program does not specify a version number of
+this License, you may choose any version ever published by the Free Software
+Foundation.
+
+ 10. If you wish to incorporate parts of the Program into other free
+programs whose distribution conditions are different, write to the author
+to ask for permission. For software which is copyrighted by the Free
+Software Foundation, write to the Free Software Foundation; we sometimes
+make exceptions for this. Our decision will be guided by the two goals
+of preserving the free status of all derivatives of our free software and
+of promoting the sharing and reuse of software generally.
+
+ NO WARRANTY
+
+ 11. BECAUSE THE PROGRAM IS LICENSED FREE OF CHARGE, THERE IS NO WARRANTY
+FOR THE PROGRAM, TO THE EXTENT PERMITTED BY APPLICABLE LAW. EXCEPT WHEN
+OTHERWISE STATED IN WRITING THE COPYRIGHT HOLDERS AND/OR OTHER PARTIES
+PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESSED
+OR IMPLIED, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF
+MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE. THE ENTIRE RISK AS
+TO THE QUALITY AND PERFORMANCE OF THE PROGRAM IS WITH YOU. SHOULD THE
+PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF ALL NECESSARY SERVICING,
+REPAIR OR CORRECTION.
+
+ 12. IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING
+WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MAY MODIFY AND/OR
+REDISTRIBUTE THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES,
+INCLUDING ANY GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING
+OUT OF THE USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED
+TO LOSS OF DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY
+YOU OR THIRD PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER
+PROGRAMS), EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE
+POSSIBILITY OF SUCH DAMAGES.
+
+ END OF TERMS AND CONDITIONS
+
+ How to Apply These Terms to Your New Programs
+
+ If you develop a new program, and you want it to be of the greatest
+possible use to the public, the best way to achieve this is to make it
+free software which everyone can redistribute and change under these terms.
+
+ To do so, attach the following notices to the program. It is safest
+to attach them to the start of each source file to most effectively
+convey the exclusion of warranty; and each file should have at least
+the "copyright" line and a pointer to where the full notice is found.
+
+ <one line to give the program's name and a brief idea of what it does.>
+ Copyright (C) <year> <name of author>
+
+ This program is free software; you can redistribute it and/or modify
+ it under the terms of the GNU General Public License as published by
+ the Free Software Foundation; either version 2 of the License, or
+ (at your option) any later version.
+
+ This program is distributed in the hope that it will be useful,
+ but WITHOUT ANY WARRANTY; without even the implied warranty of
+ MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
+ GNU General Public License for more details.
+
+ You should have received a copy of the GNU General Public License along
+ with this program; if not, write to the Free Software Foundation, Inc.,
+ 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
+
+Also add information on how to contact you by electronic and paper mail.
+
+If the program is interactive, make it output a short notice like this
+when it starts in an interactive mode:
+
+ Gnomovision version 69, Copyright (C) year name of author
+ Gnomovision comes with ABSOLUTELY NO WARRANTY; for details type `show w'.
+ This is free software, and you are welcome to redistribute it
+ under certain conditions; type `show c' for details.
+
+The hypothetical commands `show w' and `show c' should show the appropriate
+parts of the General Public License. Of course, the commands you use may
+be called something other than `show w' and `show c'; they could even be
+mouse-clicks or menu items--whatever suits your program.
+
+You should also get your employer (if you work as a programmer) or your
+school, if any, to sign a "copyright disclaimer" for the program, if
+necessary. Here is a sample; alter the names:
+
+ Yoyodyne, Inc., hereby disclaims all copyright interest in the program
+ `Gnomovision' (which makes passes at compilers) written by James Hacker.
+
+ <signature of Ty Coon>, 1 April 1989
+ Ty Coon, President of Vice
+
+This General Public License does not permit incorporating your program into
+proprietary programs. If your program is a subroutine library, you may
+consider it more useful to permit linking proprietary applications with the
+library. If this is what you want to do, use the GNU Lesser General
+Public License instead of this License.
diff --git a/README.md b/README.md
index eabe3f0..57a59e2 100644
--- a/README.md
+++ b/README.md
@@ -225,8 +225,8 @@
---
- Go语言基本数据类型内部实现
+ [golang官方网站下载go1.4版本源代码](https://github.com/golang/go/releases)
- + 越老版本的代码越纯粹,越适合新手学习
- + 随着代码的更新迭代会逐步变得非常复杂, 所以此处建议下载1.4版本
+ + 越老版本的代码越纯粹,越适合新手学习
+ + 随着代码的更新迭代会逐步变得非常复杂, 所以此处建议下载1.4版本
+ 解压后打开路径: ```go\src\runtime\runtime.h```
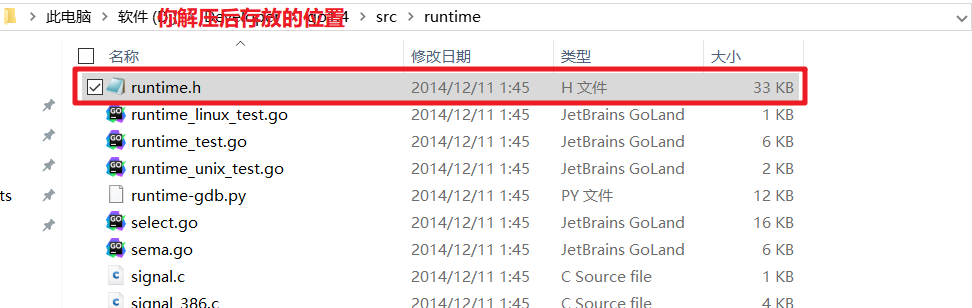
+ 得到如下实现代码
@@ -295,9 +295,9 @@ const 变量名称 数据类型 = 值;
## 运算符对比
- 算数运算符和C语言几乎一样
+ Go语言中++、--运算符不支持前置
- + 错误写法: ++i; --i;
+ + 错误写法: ++i; --i;
+ Go语言中++、--是语句,不是表达式,所以必须独占一行
- + 错误写法: a = i++; return i++;
+ + 错误写法: a = i++; return i++;
|运算符 |描述 |实例|
|--|--|--|
@@ -403,23 +403,23 @@ int main(){
- C语言定义函数格式
```c
返回值类型 函数名称(形参列表) {
- 函数体相关语句;
- return 返回值;
+ 函数体相关语句;
+ return 返回值;
}
```
- Go语言定义函数格式
```go
func 函数名称(形参列表)(返回值列表) {
- 函数体相关语句;
- return 返回值;
+ 函数体相关语句;
+ return 返回值;
}
```
- C语言中没有方法的概念, 但是Go语言中有方法
+ 对于初学者而言,可以简单的把方法理解为一种特殊的函数
```go
func (接收者 接受者类型)函数名称(形参列表)(返回值列表) {
- 函数体相关语句;
- return 返回值;
+ 函数体相关语句;
+ return 返回值;
}
```
---
@@ -427,13 +427,13 @@ func (接收者 接受者类型)函数名称(形参列表)(返回值列表) {
- C语言是一门面向过程的编程语言
+ 面向过程: 按部就班, 亲力亲为,关注的是我应该怎么做?
+ 做饭例子: 面向过程做饭
- + 1.上街买菜
- + 2.摘菜
- + 3.洗菜
- + 4.切菜
- + 5.开火炒菜
- + 6.淘米煮饭
- + 7.吃饭
+ + 1.上街买菜
+ + 2.摘菜
+ + 3.洗菜
+ + 4.切菜
+ + 5.开火炒菜
+ + 6.淘米煮饭
+ + 7.吃饭
- Go语言是门面向对象的编程语言
+ 面向对象:化繁为简, 能不自己干自己就不干,关注的是我应该让谁来做?
+ 做饭例子: 面向对象做饭
@@ -470,25 +470,25 @@ func (接收者 接受者类型)函数名称(形参列表)(返回值列表) {
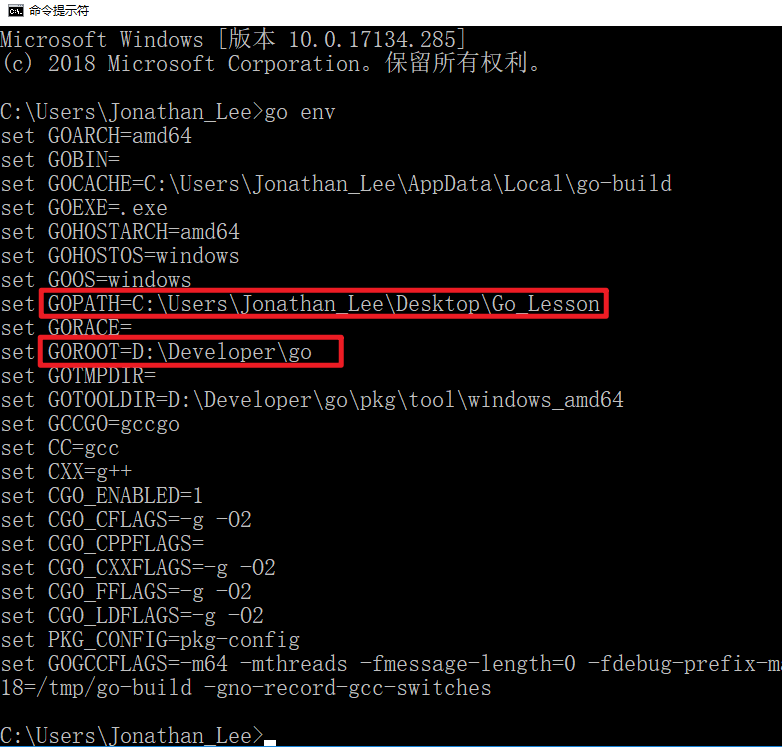
+ **3.1.添加GOROOT环境变量**
- + 用于告诉操作系统,我们把Go语言SDK安装到哪了
- 
+ + 用于告诉操作系统,我们把Go语言SDK安装到哪了
+ 
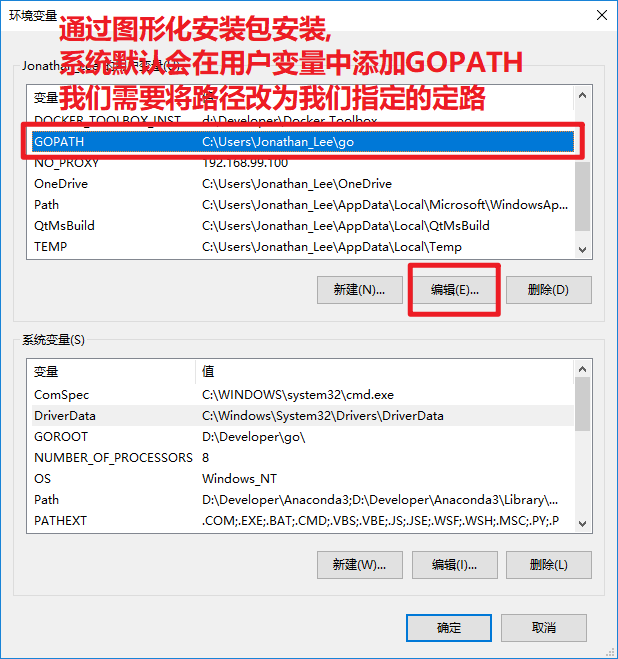
+ **3.2.配置GOPATH环境变量**
- + 用于告诉操作系统,将来我们要在哪里编写Go语言程序
- 
- 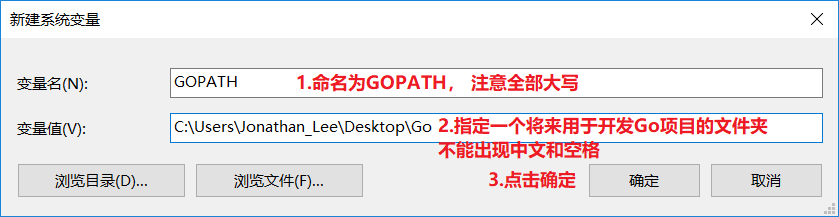
+ + 用于告诉操作系统,将来我们要在哪里编写Go语言程序
+ 
+ 
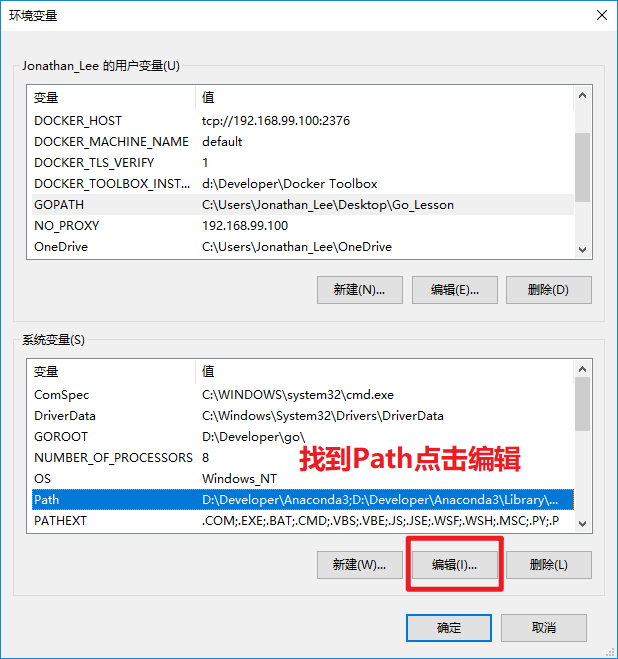
+ **3.3.配置GoBin环境变量**
- + 用于告诉操作系统,去哪查找Go语言提供的一些应用程序
- 
- 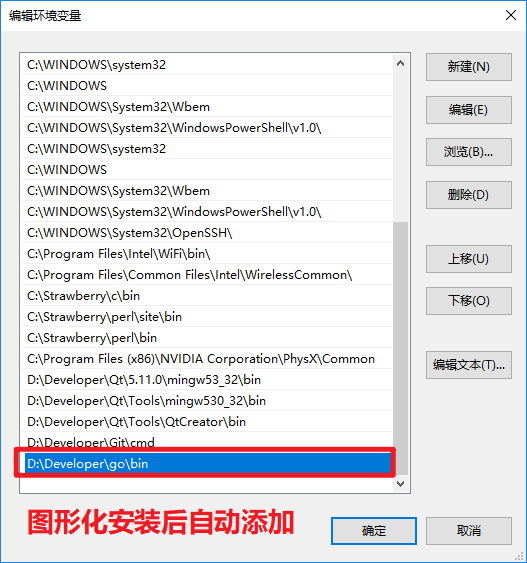
+ + 用于告诉操作系统,去哪查找Go语言提供的一些应用程序
+ 
+ 
+ **最终结果**
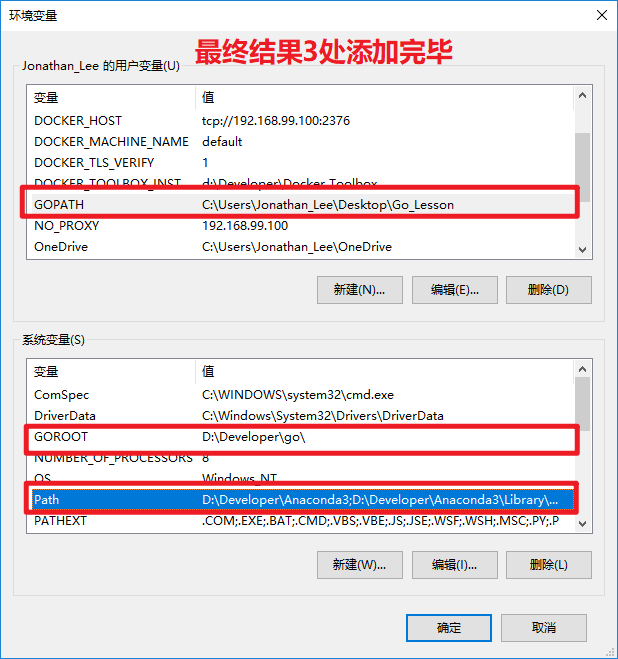
+ ***4.检查是否安装配置成功***
- + 4.1打开CMD
- 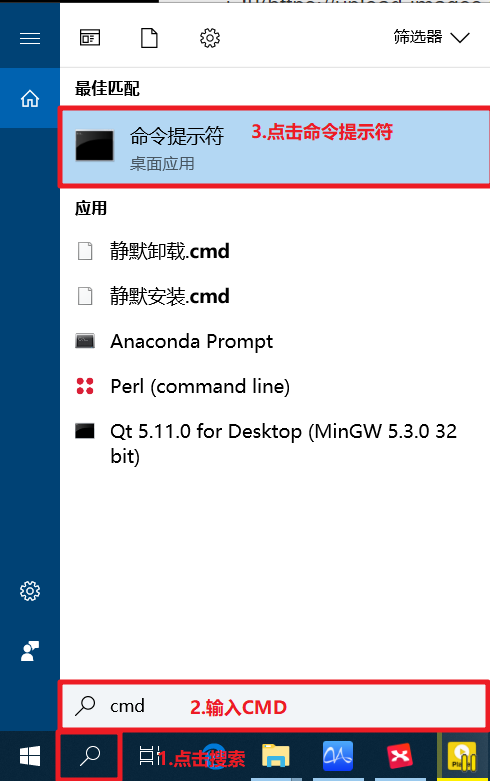
- + 4.2输入```go version```
- 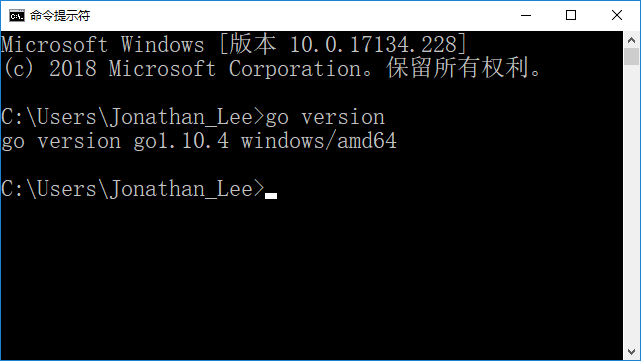
- + 4.3输入```go env```
- 
+ + 4.1打开CMD
+ 
+ + 4.2输入```go version```
+ 
+ + 4.3输入```go env```
+ 
---
## 安装Go语言开发工具
- 记事本(开发效率极低)
@@ -544,7 +544,7 @@ func (接收者 接受者类型)函数名称(形参列表)(返回值列表) {
- C语言main函数格式
```go
int main(int argc, const char * argv[]) {
- return 0;
+ return 0;
}
```
- Go语言main函数格式
@@ -565,43 +565,43 @@ func main() {
package main // 告诉系统当前代码属于main这个包
import "fmt" // 导入打印函数对应的fmt包
func main() {
- // 通过包名.函数名称的方式, 利用fmt包中的打印函数输出语句
+ // 通过包名.函数名称的方式, 利用fmt包中的打印函数输出语句
fmt.Println("Hello World!!!")
}
```
---
## Go语言HelloWorld和C语言HelloWorld异同
- ***1.文件类型不同***
- + C语言代码保存在.c为后缀的文件中
- + Go语言代码保存在.go为后缀的文件中
+ + C语言代码保存在.c为后缀的文件中
+ + Go语言代码保存在.go为后缀的文件中
- ***2.代码管理方式不同***
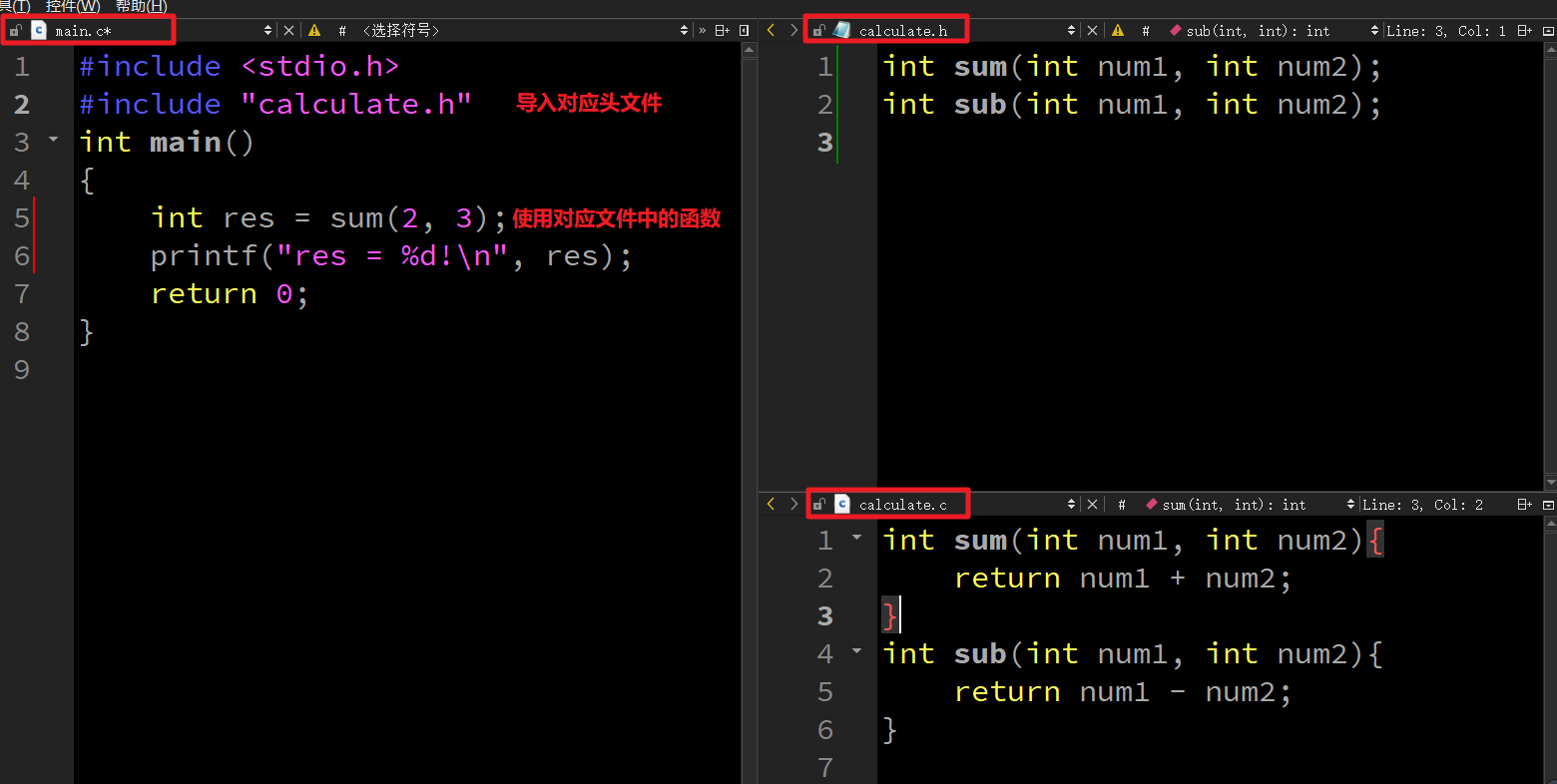
- + C语言程序用***文件***的方式管理代码
- + C语言会把不同类型的代码放到不同的.c文件中, 然后再编写对应的.h文件
- + 需要使用时直接通过#include导入对应文件的.h文件即可
- 
+ + C语言程序用***文件***的方式管理代码
+ + C语言会把不同类型的代码放到不同的.c文件中, 然后再编写对应的.h文件
+ + 需要使用时直接通过#include导入对应文件的.h文件即可
+ 
+ Go语言程序用**包**的形式管理代码
- + 我们会把不同类型的代码放到不同的.go文件中,然后通过package给该文件指定一个包名
- + 需要使用时直接通过import导入对应的包名即可
- 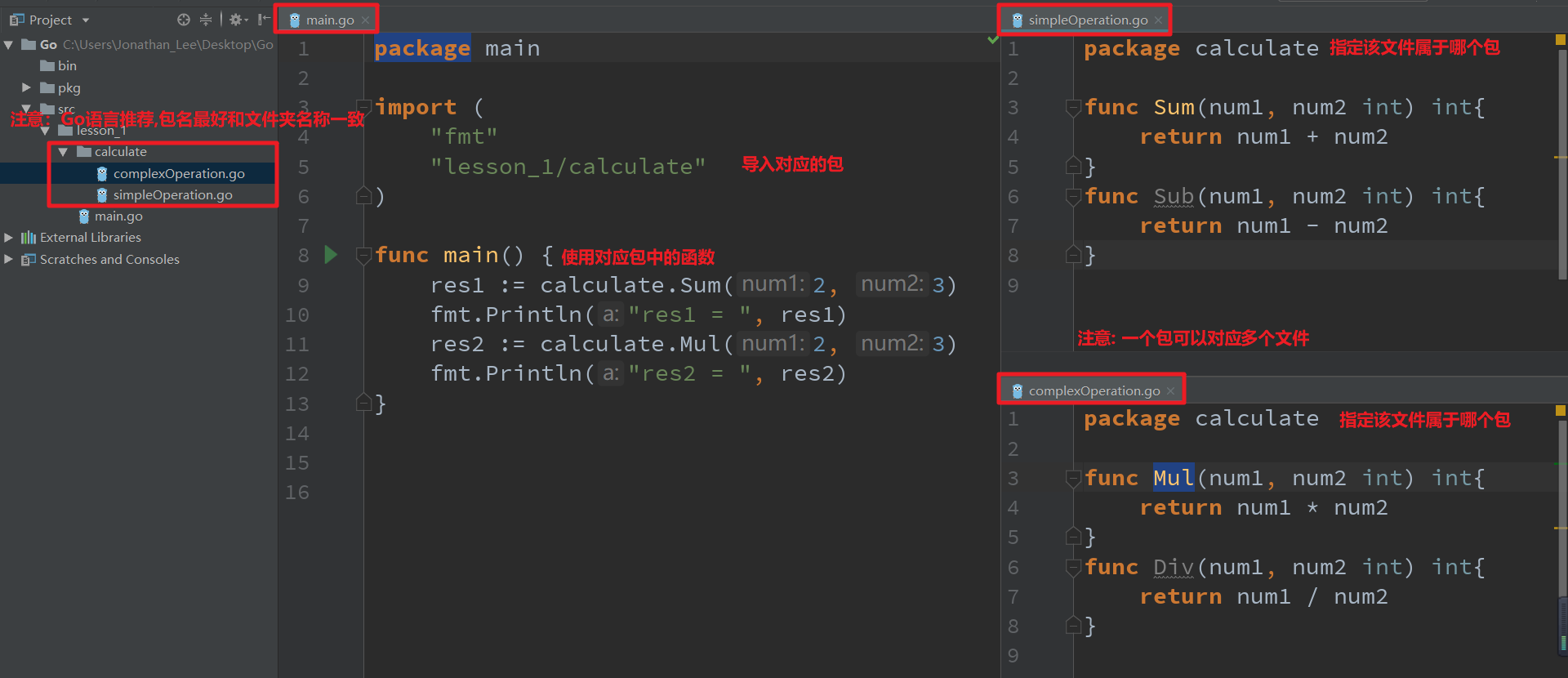
+ + 我们会把不同类型的代码放到不同的.go文件中,然后通过package给该文件指定一个包名
+ + 需要使用时直接通过import导入对应的包名即可
+ 
- **3.main函数书写文件不同**
+ C语言中main函数可以写在任意文件中, 只要保证一个程序只有一个main函数即可
+ Go语言中main函数只能写在包名为main的文件夹中, 同样需要保存一个程序只有一个main函数
- ***4.函数编写的格式不同***
- + C语言中函数的格式为
- + 注意:C语言函数的左括号可以和函数名称在同一行, 也可以不在同一行
+ + C语言中函数的格式为
+ + 注意:C语言函数的左括号可以和函数名称在同一行, 也可以不在同一行
```go
返回值类型 函数名称(形参列表) {
- 函数体相关语句;
- return 返回值;
+ 函数体相关语句;
+ return 返回值;
}
```
+ Go语言函数定义格式
- 注意:Go语言函数的左括号必须和函数名称在同一行,否则会报错
+ 注意:Go语言函数的左括号必须和函数名称在同一行,否则会报错
```go
func 函数名称(形参列表)(返回值列表) {
- 函数体相关语句;
- return 返回值;
+ 函数体相关语句;
+ return 返回值;
}
```
- ***5.函数调用的格式不同***
@@ -612,9 +612,9 @@ func 函数名称(形参列表)(返回值列表) {
#include "calculate.h"
int main()
{
- int res = sum(2, 3); // 直接利用函数名称调用函数
- printf("res = %d!\n", res);
- return 0;
+ int res = sum(2, 3); // 直接利用函数名称调用函数
+ printf("res = %d!\n", res);
+ return 0;
}
```
```go
@@ -629,16 +629,16 @@ func main() {
}
```
- ***6.语句的结束方式不同***
- + C语言中每条语句都必须以分号结尾
- + Go语言中每条语句后面不用添加分号(编译器会自动添加)
+ + C语言中每条语句都必须以分号结尾
+ + Go语言中每条语句后面不用添加分号(编译器会自动添加)
```c
#include <stdio.h>
#include "calculate.h"
int main()
{
- int res = sum(2, 3); // 不写分号会报错
- printf("res = %d!\n", res); // 不写分号会报错
- return 0; // 不写分号会报错
+ int res = sum(2, 3); // 不写分号会报错
+ printf("res = %d!\n", res); // 不写分号会报错
+ return 0; // 不写分号会报错
}
```
```go
@@ -787,8 +787,8 @@ func main() {
- 和C语言一样,标识符除了有`命名规则`以外,还有标识符`命名规范`
+ 规则必须遵守, 规范不一定要遵守, 但是建议遵守
+ Go语言的命名规范和C语言一样, 都是采用驼峰命名, 避免采用_命名
- + 驼峰命名: sendMessage / sayHello
- + _命名: send_message / say_hello
+ + 驼峰命名: sendMessage / sayHello
+ + _命名: send_message / say_hello
## Go语言数据类型
- Go语言本质是用C语言编写的一套高级开发语言, 所以Go语言中的数据类型大部分都是由C语言演变而来的
@@ -864,8 +864,8 @@ func main() {
---
- Go语言基本数据类型内部实现
+ [golang官方网站下载go1.4版本源代码](https://github.com/golang/go/releases)
- + 越老版本的代码越纯粹,越适合新手学习
- + 随着代码的更新迭代会逐步变得非常复杂, 所以此处建议下载1.4版本
+ + 越老版本的代码越纯粹,越适合新手学习
+ + 随着代码的更新迭代会逐步变得非常复杂, 所以此处建议下载1.4版本
+ 解压后打开路径: ```go\src\runtime\runtime.h```

+ 得到如下实现代码
@@ -924,21 +924,21 @@ enum
int main(int argc, const char * argv[])
{
- int num1; // 先定义
- num1 = 10; // 后初始化
- printf("num1 = %d\n", num1);
+ int num1; // 先定义
+ num1 = 10; // 后初始化
+ printf("num1 = %d\n", num1);
- int num2 = 20; // 定义的同时初始化
- printf("num2 = %d\n", num2);
+ int num2 = 20; // 定义的同时初始化
+ printf("num2 = %d\n", num2);
- // 注意: 同时定义多个变量,不支持定义时初始化, 只能先定义后初始化
- int num3, num4; //同时定义多个变量
- num3 = 30;
- num4 = 40;
- printf("num3 = %d\n", num3);
- printf("num4 = %d\n", num4);
+ // 注意: 同时定义多个变量,不支持定义时初始化, 只能先定义后初始化
+ int num3, num4; //同时定义多个变量
+ num3 = 30;
+ num4 = 40;
+ printf("num3 = %d\n", num3);
+ printf("num4 = %d\n", num4);
- return 0;
+ return 0;
}
```
- Go语言中定义变量有三种格式
@@ -963,7 +963,7 @@ func main() {
var num3 = 30 // 定义的同时赋值, 并省略数据类型
fmt.Println("num3 = ", num3)
-
+
num4 := 40 // 定义的同时赋值, 并省略关键字和数据类型
/*
num4 := 40 等价于
@@ -1056,7 +1056,7 @@ var num = 10 // 定义一个全局变量
func main() {
num := 20 // 定义一个局部变量
fmt.Println("num = ", num)
- test()
+ test()
}
func test() {
fmt.Println("num = ", num) // 还是输出10
@@ -1280,11 +1280,12 @@ int main(){
var num2 float32 = 3.14
// 不能将其它基本类型强制转换为字符串类型
+ // Cannot convert an expression of the type 'float32' to the type 'string'
var str2 string = string(num2)
fmt.Println(str2)
var str3 string = "97"
- // 不能强制转换, cannot convert str2 (type string) to type int
+ // 不能强制转换, cannot convert str3 (type string) to type int
var num3 int = int(str3)
fmt.Println(num3)
}
@@ -1310,8 +1311,9 @@ int main(){
// 第二个参数: 转换为什么格式,f小数格式, e指数格式
// 第三个参数: 转换之后保留多少位小数, 传入-1按照指定类型有效位保留
// 第四个参数: 被转换数据的实际位数,float32就传32, float64就传64
+
// 将float64位实型,按照小数格式并保留默认有效位转换为字符串
- str3 := strconv.FormatFloat(num5, 'f', -1, 64)
+ str3 := strconv.FormatFloat(num5, 'f', -1, 32)
fmt.Println(str3) // 3.1234567
str4 := strconv.FormatFloat(num5, 'f', -1, 64)
fmt.Println(str4) // 3.1234567890123457
@@ -1320,8 +1322,8 @@ int main(){
fmt.Println(str5) // 3.12
// 将float64位实型,按照指数格式并保留2位有效位转换为字符串
str6 := strconv.FormatFloat(num5, 'e', 2, 64)
- fmt.Println(str6) // 3.12
-
+ fmt.Println(str6) // 3.12e+00
+
var num6 bool = true
str7 := strconv.FormatBool(num6)
fmt.Println(str7) // true
@@ -1438,14 +1440,14 @@ int main(){
- 自定义常量
+ C语言自定义常量: ```const 数据类型 常量名称 = 值;```
```go
- #include <stdio.h>
- int main(int argc, const char * argv[])
- {
- const float PI = 998;
- PI = 110; // 报错
- printf("PI = %d\n", PI );
- return 0;
- }
+ #include <stdio.h>
+ int main(int argc, const char * argv[])
+ {
+ const float PI = 998;
+ PI = 110; // 报错
+ printf("PI = %d\n", PI );
+ return 0;
+ }
```
+ Go语言自定义常量: ```const 常量名称 数据类型 = 值```or ```const 常量名称 = 值```
```go
@@ -1536,9 +1538,9 @@ int main(){
- C语言枚举格式:
```go
enum 枚举名 {
- 枚举元素1,
- 枚举元素2,
- … …
+ 枚举元素1,
+ 枚举元素2,
+ … …
};
```
- C语言枚举中,如果没有指定初始值,那么从0开始递增
@@ -1546,18 +1548,18 @@ int main(){
#include <stdio.h>
int main(int argc, const char * argv[])
{
- enum Gender{
- male,
- female,
- yao,
- };
+ enum Gender{
+ male,
+ female,
+ yao,
+ };
// enum Gender g = male;
// printf("%d\n", g); // 0
// enum Gender g = female;
// printf("%d\n", g); // 1
- enum Gender g = yao;
- printf("%d\n", g); // 2
- return 0;
+ enum Gender g = yao;
+ printf("%d\n", g); // 2
+ return 0;
}
```
+ C语言枚举中, 如果指定了初始值,那么从指定的数开始递增
@@ -1565,18 +1567,18 @@ int main(){
#include <stdio.h>
int main(int argc, const char * argv[])
{
- enum Gender{
- male = 5,
- female,
- yao,
- };
+ enum Gender{
+ male = 5,
+ female,
+ yao,
+ };
// enum Gender g = male;
// printf("%d\n", g); // 5
// enum Gender g = female;
// printf("%d\n", g); // 6
- enum Gender g = yao;
- printf("%d\n", g); // 7
- return 0;
+ enum Gender g = yao;
+ printf("%d\n", g); // 7
+ return 0;
}
```
---
@@ -1589,10 +1591,10 @@ const(
)
```
- 利用iota标识符标识符实现从0开始递增的枚举
- ```go
- package main
- import "fmt"
- func main() {
+ ```go
+ package main
+ import "fmt"
+ func main() {
const (
male = iota
female = iota
@@ -1601,15 +1603,15 @@ const(
fmt.Println("male = ", male) // 0
fmt.Println("male = ", female) // 1
fmt.Println("male = ", yao) // 2
- }
- ```
+ }
+ ```
- iota注意点:
- + 在同一个常量组中,iota从0开始递增, `每一行递增1`
- + 在同一个常量组中,只要上一行出现了iota,那么后续行就会自动递增
- ```go
- package main
- import "fmt"
- func main() {
+ + 在同一个常量组中,iota从0开始递增, `每一行递增1`
+ + 在同一个常量组中,只要上一行出现了iota,那么后续行就会自动递增
+ ```go
+ package main
+ import "fmt"
+ func main() {
const (
male = iota // 这里出现了iota
female // 这里会自动递增
@@ -1618,13 +1620,13 @@ const(
fmt.Println("male = ", male) // 0
fmt.Println("male = ", female) // 1
fmt.Println("male = ", yao) // 2
- }
- ```
- + 在同一个常量组中,如果iota被中断, 那么必须显示恢复
- ```go
- package main
- import "fmt"
- func main() {
+ }
+ ```
+ + 在同一个常量组中,如果iota被中断, 那么必须显示恢复
+ ```go
+ package main
+ import "fmt"
+ func main() {
const (
male = iota
female = 666 // 这里被中断, 如果没有显示恢复, 那么下面没有赋值的常量都和上一行一样
@@ -1633,12 +1635,12 @@ const(
fmt.Println("male = ", male) // 0
fmt.Println("male = ", female) // 666
fmt.Println("male = ", yao) // 666
- }
- ```
- ```go
- package main
- import "fmt"
- func main() {
+ }
+ ```
+ ```go
+ package main
+ import "fmt"
+ func main() {
const (
male = iota
female = 666 // 这里被中断
@@ -1647,28 +1649,28 @@ const(
fmt.Println("male = ", male) // 0
fmt.Println("male = ", female) // 666
fmt.Println("male = ", yao) // 2
- }
- ```
- + iota也支持常量组+多重赋值, 在同一行的iota值相同
- ```go
- package main
- import "fmt"
- func main() {
- const (
+ }
+ ```
+ + iota也支持常量组+多重赋值, 在同一行的iota值相同
+ ```go
+ package main
+ import "fmt"
+ func main() {
+ const (
a, b = iota, iota
c, d = iota, iota
- )
- fmt.Println("a = ", a) // 0
- fmt.Println("b = ", b) // 0
- fmt.Println("c = ", c) // 1
- fmt.Println("d = ", d) // 1
- }
- ```
- + iota自增默认数据类型为int类型, 也可以显示指定类型
- ```go
- package main
- import "fmt"
- func main() {
+ )
+ fmt.Println("a = ", a) // 0
+ fmt.Println("b = ", b) // 0
+ fmt.Println("c = ", c) // 1
+ fmt.Println("d = ", d) // 1
+ }
+ ```
+ + iota自增默认数据类型为int类型, 也可以显示指定类型
+ ```go
+ package main
+ import "fmt"
+ func main() {
const (
male float32 = iota // 显示指定类型,后续自增都会按照指定类型自增
female
@@ -1678,8 +1680,8 @@ const(
fmt.Printf("%f\n", female) // 1.0
fmt.Printf("%f\n", yao) // 2.0
fmt.Println("male = ", reflect.TypeOf(female)) // float32
- }
- ```
+ }
+ ```
- Go语言fmt包实现了类似C语言printf和scanf的格式化I/O, 格式化动作源自C语言但更简单
##输出函数
- func Printf(format string, a ...interface{}) (n int, err error)
@@ -1724,8 +1726,8 @@ const(
}
```
+ 除此之外,Go语言还增加了%v控制符,用于打印所有类型数据
- + Go语言中输出某一个值,很少使用%d%f等, 一般都使用%v即可
- + 输出复合类型时会自动生成对应格式后再输出
+ + Go语言中输出某一个值,很少使用%d%f等, 一般都使用%v即可
+ + 输出复合类型时会自动生成对应格式后再输出
```go
package main
import "fmt"
@@ -1747,9 +1749,9 @@ const(
---
- func Println(a ...interface{}) (n int, err error)
+ 采用默认格式将其参数格式化并写入标准输出,
- + 输出之后`会`在结尾处添加换行
- + 传入多个参数时, 会自动在相邻参数之间添加空格
- + 传入符合类型数据时, 会自动生成对应格式后再输出
+ + 输出之后`会`在结尾处添加换行
+ + 传入多个参数时, 会自动在相邻参数之间添加空格
+ + 传入符合类型数据时, 会自动生成对应格式后再输出
```go
package main
import "fmt"
@@ -1770,9 +1772,9 @@ const(
---
- func Print(a ...interface{}) (n int, err error)
+ 和Println几乎一样
- + 输出之后`不会`在结尾处添加换行
- + 传入多个参数时, 只有两个相邻的参数`都不是`字符串,才会在相邻参数之间添加空格
- + 传入符合类型数据时, 会自动生成对应格式后再输出
+ + 输出之后`不会`在结尾处添加换行
+ + 传入多个参数时, 只有两个相邻的参数`都不是`字符串,才会在相邻参数之间添加空格
+ + 传入符合类型数据时, 会自动生成对应格式后再输出
```gi
package main
import "fmt"
@@ -1931,8 +1933,8 @@ func main() {
- 标准go语言项目文件目录格式
+ 项目文件夹就是GOPATH指向的文件夹
+ src文件夹是专门用于存放源码文件的
- + main文件夹是专门用于存储package main包相关源码文件的
- + 其它文件夹是专门用于存储除package main包以外源码文件的
+ + main文件夹是专门用于存储package main包相关源码文件的
+ + 其它文件夹是专门用于存储除package main包以外源码文件的
+ bin文件夹是专门用于存储编译之后的可执行程序的
+ pag文件夹是专门用于存储编译之后的.a文件的
@@ -1970,10 +1972,10 @@ func main() {
#include <stdio.h>
int main(int argc, const char * argv[])
{
- for(int i = 0; i < argc; i++){
- printf("argv[%d] = %s\n", i, argv[i]);
- }
- return 0;
+ for(int i = 0; i < argc; i++){
+ printf("argv[%d] = %s\n", i, argv[i]);
+ }
+ return 0;
}
```

@@ -2011,7 +2013,7 @@ import (
)
func main() {
/*
- flag.Xxxx(name, value, usage)
+ flag.Xxxx(name, value, usage)
第一个参数: 命令行参数名称
第二个参数: 命令行参数对应的默认值
第三个参数: 命令行参数对应的说明
@@ -2142,9 +2144,9 @@ int main(){
}
```
+ Go语言中++、--运算符不支持前置
- + 错误写法: ++i; --i;
+ + 错误写法: ++i; --i;
+ Go语言中++、--是语句,不是表达式,所以必须独占一行
- + 错误写法: a = i++; return i++;
+ + 错误写法: a = i++; return i++;
```go
package main
import "fmt"
@@ -2237,7 +2239,7 @@ int main(){
---
## 赋值运算符
- 赋值运算符和C语言几乎一样
- + 新增一个&^=运算符
+ + 新增一个&^=运算符
|运算符 |描述 |实例|
|--|--|--|
@@ -2283,12 +2285,12 @@ int main(){
#include <stdio.h>
int main()
{
- int ages[3] = {19, 23, 22};
- int *arrayP = &ages[0];
- printf("ages[0] = %i\n", *(arrayP + 0)); // *(arrayP + 0) == *arrayP
- printf("ages[1] = %i\n", *(arrayP + 1));
- printf("ages[2] = %i\n", *(arrayP + 2));
- return 0;
+ int ages[3] = {19, 23, 22};
+ int *arrayP = &ages[0];
+ printf("ages[0] = %i\n", *(arrayP + 0)); // *(arrayP + 0) == *arrayP
+ printf("ages[1] = %i\n", *(arrayP + 1));
+ printf("ages[2] = %i\n", *(arrayP + 2));
+ return 0;
}
```
```go
@@ -2321,7 +2323,7 @@ int main(){
+ 条件表达式结果为true,那么执行if后面{}中代码
```c
if 初始化语句; 条件表达式{
- 语句块;
+ 语句块;
}
```
```go
@@ -2351,9 +2353,9 @@ func main() {
+ 否则执行else后面{}中代码
```c
if 初始化语句; 条件表达式{
- 语句块;
+ 语句块;
}else{
- 语句块;
+ 语句块;
}
```
```go
@@ -2374,13 +2376,13 @@ func main() {
+ 都不满足则执行else后面{}中代码
```c
if 初始化语句; 条件表达式{
- 语句块;
+ 语句块;
}else if 条件表达式{
- 语句块;
+ 语句块;
}
... ...
else{
- 语句块;
+ 语句块;
}
```
```go
@@ -2414,11 +2416,11 @@ func main() {
```c
switch 初始化语句; 表达式{
case 表达式1, 表达式2:
- 语句块;
+ 语句块;
case 表达式1, 表达式2:
- 语句块;
+ 语句块;
default:
- 语句块;
+ 语句块;
}
```
```go
@@ -2535,7 +2537,7 @@ func main() {
package main
import "fmt"
func main() {
- switch num := 1;num {
+ switch num := 1;num {
case 1:
value := 10 // 不会报错
fmt.Println(value)
@@ -2554,7 +2556,7 @@ func main() {
- 格式:
```
for 初始化表达式;循环条件表达式;循环后的操作表达式 {
- 循环体语句;
+ 循环体语句;
}
```
```go
@@ -2739,7 +2741,7 @@ outer:
- 格式:
```go
func 函数名称(形参列表)(返回值列表){
- 函数体;
+ 函数体;
}
```
- 无参数无返回值函数
@@ -2902,16 +2904,16 @@ func change(mp map[string]string) {
import "fmt"
// 方式一
var a = func() {
- fmt.Println("hello world1")
+ fmt.Println("hello world1")
}
// 方式二
var (
- b = func() {
- fmt.Println("hello world2")
- }
+ b = func() {
+ fmt.Println("hello world2")
+ }
)
func main() {
- a()
+ a()
b()
}
```
@@ -3236,7 +3238,7 @@ func abc() int {
}
```
+ 和C语言一样,Go语言中如果定义数组的同时初始化,那么元素个数可以省略,但是必须使用`...`来替代
- + ...会根据初始化元素个数自动确定数组长度
+ + ...会根据初始化元素个数自动确定数组长度
```go
package main
import "fmt"
@@ -3358,9 +3360,9 @@ package main
+ 切片源码
```go
type slice struct{
- array unsafe.Pointer // 指向底层数组指针
- len int // 切片长度(保存了多少个元素)
- cap int // 切片容量(可以保存多少个元素)
+ array unsafe.Pointer // 指向底层数组指针
+ len int // 切片长度(保存了多少个元素)
+ cap int // 切片容量(可以保存多少个元素)
}
```
---
@@ -3477,22 +3479,22 @@ package main
```
+ 和数组一样, 如果通过`切片名称[索引]`方式操作切片, 不能越界
```go
- package main
- import "fmt"
- func main() {
- var sce = []int{1, 3, 5}
- // 编译报错, 越界
- sce[3] = 666
- }
+ package main
+ import "fmt"
+ func main() {
+ var sce = []int{1, 3, 5}
+ // 编译报错, 越界
+ sce[3] = 666
+ }
```
+ 如果希望切片自动扩容,那么添加数据时必须使用append方法
- + append函数会在切片`末尾`添加一个元素, 并返回一个追加数据之后的切片
- + 利用append函数追加数据时,如果追加之后没有超出切片的容量,那么返回原来的切片, 如果追加之后超出了切片的容量,那么返回一个新的切片
- + append函数每次给切片扩容都会按照原有切片容量*2的方式扩容
+ + append函数会在切片`末尾`添加一个元素, 并返回一个追加数据之后的切片
+ + 利用append函数追加数据时,如果追加之后没有超出切片的容量,那么返回原来的切片, 如果追加之后超出了切片的容量,那么返回一个新的切片
+ + append函数每次给切片扩容都会按照原有切片容量*2的方式扩容
```go
- package main
- import "fmt"
- func main() {
+ package main
+ import "fmt"
+ func main() {
var sce = []int{1, 3, 5}
fmt.Println("追加数据前:", sce) // [1 3 5]
fmt.Println("追加数据前:", len(sce)) // 3
@@ -3505,14 +3507,14 @@ package main
fmt.Println("追加数据后:", len(sce)) // 4
fmt.Println("追加数据后:", cap(sce)) // 6
fmt.Printf("追加数据前: %p\n", sce) // 0xc042076b60
- }
+ }
```
+ 除了append函数外,Go语言还提供了一个copy函数, 用于两个切片之间数据的快速拷贝
- + 格式: `copy(目标切片, 源切片)`, 会将源切片中数据拷贝到目标切片中
+ + 格式: `copy(目标切片, 源切片)`, 会将源切片中数据拷贝到目标切片中
```go
- package main
- import "fmt"
- func main() {
+ package main
+ import "fmt"
+ func main() {
var sce1 = []int{1, 3, 5}
var sce2 = make([]int, 5)
fmt.Printf("赋值前:%p\n", sce1) // 0xc0420600a0
@@ -3527,12 +3529,12 @@ package main
sce2[1] = 666
fmt.Println(sce1) // [1 666 5]
fmt.Println(sce2) // [1 666 5]
- }
+ }
```
```go
- package main
- import "fmt"
- func main() {
+ package main
+ import "fmt"
+ func main() {
var sce1 = []int{1, 3, 5}
var sce2 = make([]int, 5)
fmt.Printf("赋值前:%p\n", sce1) // 0xc0420600a0
@@ -3547,13 +3549,13 @@ package main
sce2[1] = 666
fmt.Println(sce1) // [1 3 5]
fmt.Println(sce2) // [1 666 5 0 0]
- }
+ }
```
+ copy函数在拷贝数据时永远以小容量为准
```go
- package main
- import "fmt"
- func main() {
+ package main
+ import "fmt"
+ func main() {
// 容量为3
var sce1 = []int{1, 3, 5}
// 容量为5
@@ -3562,12 +3564,12 @@ package main
// sce2容量足够, 会将sce1所有内容拷贝到sce2
copy(sce2, sce1)
fmt.Println("拷贝后:", sce2) // [1 3 5 0 0]
- }
+ }
```
```go
- package main
- import "fmt"
- func main() {
+ package main
+ import "fmt"
+ func main() {
// 容量为3
var sce1 = []int{1, 3, 5}
// 容量为2
@@ -3576,47 +3578,47 @@ package main
// sce2容量不够, 会将sce1前2个元素拷贝到sce2中
copy(sce2, sce1)
fmt.Println("拷贝后:", sce2) // [1 3]
- }
+ }
```
---
- ***切片的注意点***
+ 可以通过切片再次生成新的切片, 两个切片底层指向同一数组
```go
- package main
- import "fmt"
- func main() {
- arr := [5]int{1, 3, 5, 7, 9}
- sce1 := arr[0:4]
- sce2 := sce1[0:3]
- fmt.Println(sce1) // [1 3 5 7]
- fmt.Println(sce2) // [1 3 5]
- // 由于底层指向同一数组, 所以修改sce2会影响sce1
- sce2[1] = 666
- fmt.Println(sce1) // [1 666 5 7]
- fmt.Println(sce2) // [1 666 5]
- }
+ package main
+ import "fmt"
+ func main() {
+ arr := [5]int{1, 3, 5, 7, 9}
+ sce1 := arr[0:4]
+ sce2 := sce1[0:3]
+ fmt.Println(sce1) // [1 3 5 7]
+ fmt.Println(sce2) // [1 3 5]
+ // 由于底层指向同一数组, 所以修改sce2会影响sce1
+ sce2[1] = 666
+ fmt.Println(sce1) // [1 666 5 7]
+ fmt.Println(sce2) // [1 666 5]
+ }
```
+ 和数组不同, 切片只支持判断是否为nil, 不支持==、!=判断
```go
package main
import "fmt"
func main() {
- var arr1 [3]int = [3]int{1, 3, 5}
- var arr2 [3]int = [3]int{1, 3, 5}
- var arr3 [3]int = [3]int{2, 4, 6}
- // 首先会判断`数据类型`是否相同,如果相同会依次取出数组中`对应索引的元素`进行比较,
- // 如果所有元素都相同返回true,否则返回false
- fmt.Println(arr1 == arr2) // true
- fmt.Println(arr1 == arr3) // false
+ var arr1 [3]int = [3]int{1, 3, 5}
+ var arr2 [3]int = [3]int{1, 3, 5}
+ var arr3 [3]int = [3]int{2, 4, 6}
+ // 首先会判断`数据类型`是否相同,如果相同会依次取出数组中`对应索引的元素`进行比较,
+ // 如果所有元素都相同返回true,否则返回false
+ fmt.Println(arr1 == arr2) // true
+ fmt.Println(arr1 == arr3) // false
- sce1 := []int{1, 3, 5}
- sce2 := []int{1, 3, 5}
- //fmt.Println(sce1 == sce2) // 编译报错
- fmt.Println(sce1 != nil) // true
- fmt.Println(sce2 == nil) // false
+ sce1 := []int{1, 3, 5}
+ sce2 := []int{1, 3, 5}
+ //fmt.Println(sce1 == sce2) // 编译报错
+ fmt.Println(sce1 != nil) // true
+ fmt.Println(sce2 == nil) // false
}
```
- + 只声明当没有被创建的切片是不能使用的
+ + 只声明当没有被创建的切片是不能使用的
```go
package main
import "fmt"
@@ -3642,7 +3644,7 @@ package main
import "fmt"
func main() {
str := "abcdefg"
- // 通过字符串生成切片
+ // 通过字符串切片 生成新字符串
sce1 := str[3:]
fmt.Println(sce1) // defg
@@ -3658,9 +3660,9 @@ package main
+ 切片是用来存储一组相同类型的数据的, map也是用来存储一组相同类型的数据的
+ 在切片中我们可以通过索引获取对应的元素, 在map中我们可以通过key获取对应的元素
+ 切片的索引是系统自动生成的,从0开始递增. map中的key需要我们自己指定
- + 只要是可以做==、!=判断的数据类型都可以作为key(数值类型、字符串、数组、指针、结构体、接口)
- + map的key的数据类型不能是:slice、map、function
- + map和切片一样容量都不是固定的, 当容量不足时底层会自动扩容
+ + 只要是可以做==、!=判断的数据类型都可以作为key(数值类型、字符串、数组、指针、结构体、接口)
+ + map的key的数据类型不能是:slice、map、function
+ + map和切片一样容量都不是固定的, 当容量不足时底层会自动扩容
- map格式:`var dic map[key数据类型]value数据类型`
```go
package main
@@ -3807,14 +3809,14 @@ type 类型名称 struct{
}
```
```c
-type Studentstruct {
+type Student struct {
name string
age int
}
```
- 创建结构体变量的两种方式
+ 方式一: 先定义结构体类型, 再定义结构体变量
- * 和C语言中的结构体一样, 如果结构体类型需要多次使用, 那么建议先定义类型再定义变量
+ * 和C语言中的结构体一样, 如果结构体类型需要多次使用, 那么建议先定义类型再定义变量
```go
package main
import "fmt"
@@ -3834,7 +3836,7 @@ type Studentstruct {
}
```
+ 方式二: 定义结构体类型同时定义结构体变量(匿名结构体)
- * 和C语言中的结构体一样, 如果结构体类型只需要使用一次, 那么建议定义类型同时定义变量
+ * 和C语言中的结构体一样, 如果结构体类型只需要使用一次, 那么建议定义类型同时定义变量
```go
package main
import "fmt"
@@ -4217,10 +4219,10 @@ func main() {
#include <stdio.h>
int main(){
- int arr[3] = {1, 3, 5};
- printf("%p\n", arr); // 0060FEA4
- printf("%p\n", &arr); // 0060FEA4
- printf("%p\n", &arr[0]); // 0060FEA4
+ int arr[3] = {1, 3, 5};
+ printf("%p\n", arr); // 0060FEA4
+ printf("%p\n", &arr); // 0060FEA4
+ printf("%p\n", &arr[0]); // 0060FEA4
}
```
- 在Go语言中通过数组名无法直接获取数组的内存地址
@@ -4240,18 +4242,18 @@ func main() {
#include <stdio.h>
int main(){
- int arr[3] = {1, 3, 5};
- int *p1 = arr;
- p1[1] = 6;
- printf("%d\n", arr[1]);
+ int arr[3] = {1, 3, 5};
+ int *p1 = arr;
+ p1[1] = 6;
+ printf("%d\n", arr[1]);
- int *p2 = &arr;
- p2[1] = 7;
- printf("%d\n", arr[1]);
+ int *p2 = &arr;
+ p2[1] = 7;
+ printf("%d\n", arr[1]);
- int *p3 = &arr[0];
- p3[1] = 8;
- printf("%d\n", arr[1]);
+ int *p3 = &arr[0];
+ p3[1] = 8;
+ printf("%d\n", arr[1]);
}
```
- 在Go语言中, 因为只有数据类型一模一样才能赋值, 所以只能通过&数组名赋值给指针变量, 才代表指针变量指向了这个数组
@@ -4259,13 +4261,13 @@ int main(){
package main
import "fmt"
-
func main() {
- // 1.错误, 在Go语言中必须类型一模一样才能赋值
- // arr类型是[3]int, p1的类型是*[3]int
+ var arr = [3]int{1,2,3}
var p1 *[3]int
fmt.Printf("%T\n", arr)
fmt.Printf("%T\n", p1)
+ // 1.错误, 在Go语言中必须类型一模一样才能赋值
+ // arr类型是[3]int, p1的类型是*[3]int
p1 = arr // 报错
p1[1] = 6
fmt.Println(arr[1])
@@ -4506,7 +4508,7 @@ func main() {
}
// 定义一个方法
func (p Person)say() {
- fmt.Println("my name is", p.name, "my age is", p.age)
+ fmt.Println("my name is", p.name, "my age is", p.age)
}
// 定义一个函数
func test() {
@@ -4529,7 +4531,7 @@ func main() {
}
// 定义一个方法
func (p Person)say() {
- fmt.Println("my name is", p.name, "my age is", p.age)
+ fmt.Println("my name is", p.name, "my age is", p.age)
}
// 定义一个函数
func test(p Person) {
@@ -4936,7 +4938,7 @@ func main() {
// 可以调用read方法,因为studier中声明了这个方法,并且结构体中实现了这个方法
s.read() // lnj 正在学习
}
- }
+ }
```
# Go语言进阶
@@ -4954,112 +4956,112 @@ func main() {
- 面向对象是相对面向过程而言
- 面向对象和面向过程都是一种思想
- 面向过程
- + 强调的是功能行为
- + 关注的是解决问题需要哪些步骤
+ + 强调的是功能行为
+ + 关注的是解决问题需要哪些步骤
- 回想下前面我们完成一个需求的步骤:
- * 首先搞清楚我们要做什么
- * 然后分析怎么做
- * 最后我用代码体现
- * 一步一步去实现,而具体的每一步都需要我们去实现和操作
+ * 首先搞清楚我们要做什么
+ * 然后分析怎么做
+ * 最后我用代码体现
+ * 一步一步去实现,而具体的每一步都需要我们去实现和操作
- 在上面每一个具体步骤中我们都是参与者, 并且需要面对具体的每一个步骤和过程, 这就是面向过程最直接的体现
---
- 面向对象
- + 将功能封装进对象,强调具备了功能的对象
- + 关注的是解决问题需要哪些对象
+ + 将功能封装进对象,强调具备了功能的对象
+ + 关注的是解决问题需要哪些对象
- 当需求单一, 或者简单时, 我们一步一步去操作没问题, 并且效率也挺高。 可随着需求的更改, 功能的增加, 发现需要面对每一个步骤非常麻烦, 这时就开始思索, 能不能把这些步骤和功能再进行封装, 封装时根据不同的功能,进行不同的封装,功能类似的封装在一起。这样结构就清晰多了, 用的时候, 找到对应的类就可以了, 这就是面向对象思想
---
- 示例
- 买电脑
- + 面向过程
- * 了解电脑
- * 了解自己的需求
- * 对比参数
- * 去电脑城
- * 砍价,付钱
- * 买回电脑
- * 被坑
-
- + 面向对象
- * 找班长
- * 描述需求
- * 班长把电脑买回来
- *
+ + 面向过程
+ * 了解电脑
+ * 了解自己的需求
+ * 对比参数
+ * 去电脑城
+ * 砍价,付钱
+ * 买回电脑
+ * 被坑
+
+ + 面向对象
+ * 找班长
+ * 描述需求
+ * 班长把电脑买回来
+ *
---
- 吃饭
- + 面向过程
- * 去超市卖菜
- * 摘菜
- * 洗菜
- * 切菜
- * 炒菜
- * 盛菜
- * 吃
-
- + 面向对象
- * 去饭店
- * 点菜
- * 吃
+ + 面向过程
+ * 去超市卖菜
+ * 摘菜
+ * 洗菜
+ * 切菜
+ * 炒菜
+ * 盛菜
+ * 吃
+
+ + 面向对象
+ * 去饭店
+ * 点菜
+ * 吃
---
- 洗衣服
- + 面向过程
- * 脱衣服
- * 放进盆里
- * 放洗衣液
- * 加水
- * 放衣服
- * 搓一搓
- * 清一清
- * 拧一拧
- * 晒起来
- + 面向对象
- * 脱衣服
- * 打开洗衣机
- * 丢进去
- * 一键洗衣烘干
- + 终极面向对象
- * 买电脑/吃饭/洗衣服
- * 找个对象
+ + 面向过程
+ * 脱衣服
+ * 放进盆里
+ * 放洗衣液
+ * 加水
+ * 放衣服
+ * 搓一搓
+ * 清一清
+ * 拧一拧
+ * 晒起来
+ + 面向对象
+ * 脱衣服
+ * 打开洗衣机
+ * 丢进去
+ * 一键洗衣烘干
+ + 终极面向对象
+ * 买电脑/吃饭/洗衣服
+ * 找个对象
- 现实生活中我们是如何应用面相对象思想的
- + 包工头
- + 汽车坏了
- + 面试
+ + 包工头
+ + 汽车坏了
+ + 面试
---
## 面向对象的特点
- 是一种符合人们思考习惯的思想
- 可以将复杂的事情简单化
- 将程序员从执行者转换成了指挥者
- 完成需求时:
- + 先要去找具有所需的功能的对象来用
- + 如果该对象不存在,那么创建一个具有所需功能的对象
- + 这样简化开发并提高复用
+ + 先要去找具有所需的功能的对象来用
+ + 如果该对象不存在,那么创建一个具有所需功能的对象
+ + 这样简化开发并提高复用
---
## 类与对象的关系
- 面向对象的核心就是对象,那怎么创建对象?
- + 现实生活中可以根据模板创建对象,编程语言也一样,也必须先有一个模板,在这个模板中说清楚将来创建出来的对象有哪些`属性`和`行为`
- 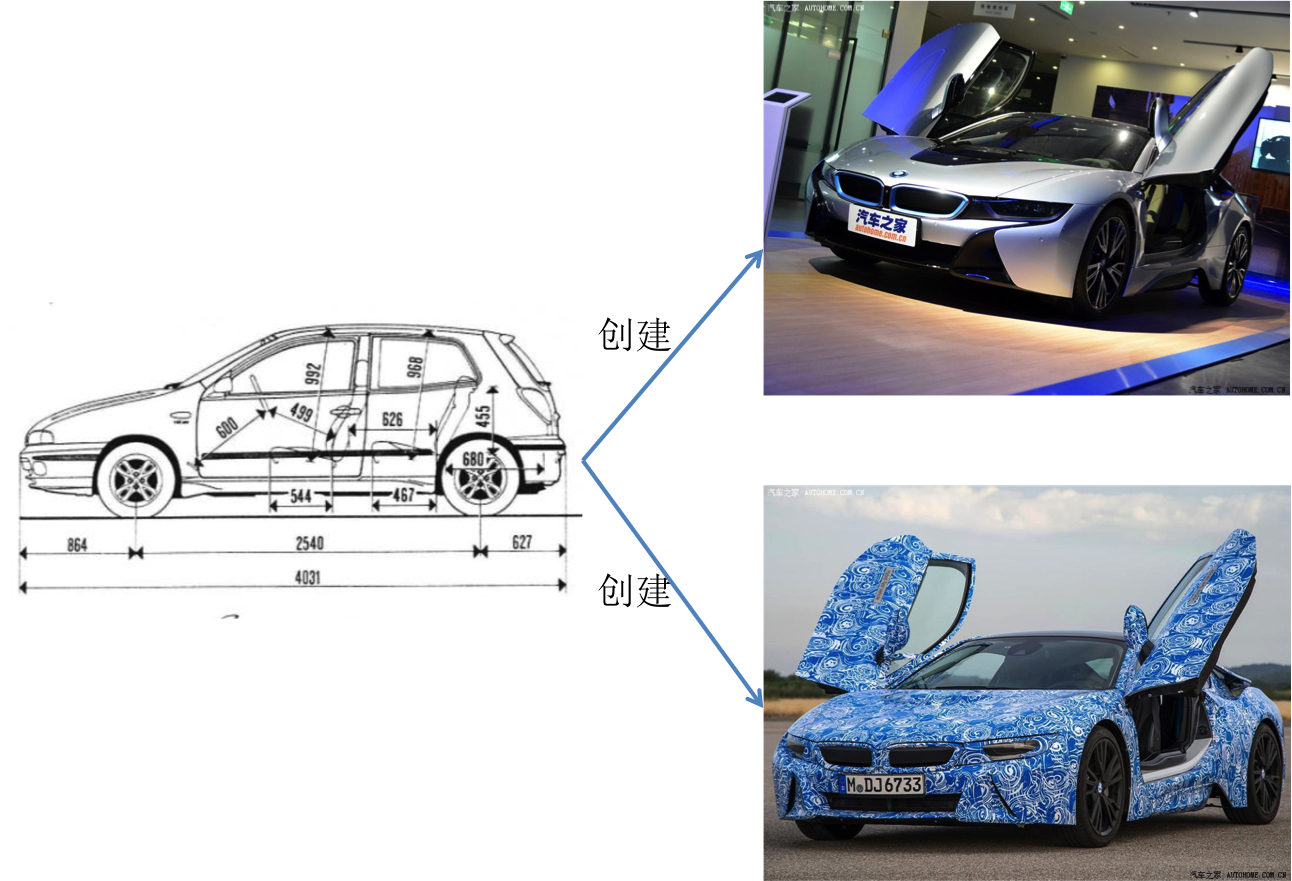
+ + 现实生活中可以根据模板创建对象,编程语言也一样,也必须先有一个模板,在这个模板中说清楚将来创建出来的对象有哪些`属性`和`行为`
+ 
- Go语言中的类相当于图纸,用来描述一类事物。也就是说要想创建对象必须先有类
- Go语言利用类来创建对象,对象是类的具体存在, 因此面向对象解决问题应该是先考虑需要设计哪些类,再利用类创建多少个对象
---
## 如何设计一个类
- 生活中描述事物无非就是描述事物的`属性`和`行为`。
- + 如:人有身高,体重等属性,有说话,打架等行为。
+ + 如:人有身高,体重等属性,有说话,打架等行为。
```go
事物名称(类名):人(Person)
属性:身高(height)、年龄(age)
行为(功能):跑(run)、打架(fight)
```
- Go语言中用类来描述事物也是如此
- + 属性:对应类中的成员变量。
- + 行为:对应类中的成员方法。
+ + 属性:对应类中的成员变量。
+ + 行为:对应类中的成员方法。
- 定义类其实在定义类中的成员(成员变量和成员方法)
- 拥有相同或者类似`属性`(状态特征)和`行为`(能干什么事)的对象都可以抽像成为一个类

---
## 如何分析一个类
- 一般名词都是类(名词提炼法)
- + 飞机发射两颗炮弹摧毁了8辆装甲车
+ + 飞机发射两颗炮弹摧毁了8辆装甲车
```
飞机
炮弹
@@ -5077,23 +5079,23 @@ func main() {
- 所以在Go语言中我们使用结构体来定义一个类型
```go
type Person struct {
- name string // 人的属性
- age int // 人的属性
+ name string // 人的属性
+ age int // 人的属性
}
// 人的行为
func (p Person)Say() {
- fmt.Println("my name is", p.name, "my age is", p.age)
+ fmt.Println("my name is", p.name, "my age is", p.age)
}
```
## 如何通过类创建一个对象
- 不过就是创建结构体的时候, 根据每个对象的特征赋值不同的属性罢了
```go
// 3.创建一个结构体变量
- p1 := Person{"lnj", 33}
- per.say()
+ p1 := Person{"lnj", 33}
+ per.say()
- p2 := Person{"zs", 18}
- per.Say()
+ p2 := Person{"zs", 18}
+ per.Say()
```
---
## 不同包中变量、函数、方法、类型公私有问题
@@ -5471,7 +5473,7 @@ func (e *errorString) Error() string {
// 定义了一个New函数, 用于创建异常信息
// 注意: New函数的返回值是一个接口类型
func New(text string) error {
- // 返回一个创建好的errorString结构体地址
+ // 返回一个创建好的errorString结构体地址
return &errorString{text}
}
```
@@ -5649,8 +5651,8 @@ import "fmt"
func main() {
str1 := "lnj"
fmt.Println(len(str1)) // 3
- str2 := "公号:代码情缘"
- fmt.Println(len(str2)) // 12
+ str2 := "公号:代码情缘"
+ fmt.Println(len(str2)) // 19
}
```
- 如果字符串中包含中文, 又想精确的计算字符串中字符的个数而不是占用的字节, 那么必须先将字符串转换为rune类型数组
@@ -5661,17 +5663,17 @@ import "fmt"
func main() {
str := "公号:代码情缘"
// 注意byte占1个字节, 只能保存字符不能保存汉字,因为一个汉字占用3个字节
- arr1 := []byte(str) // 12
+ arr1 := []byte(str) // 21
fmt.Println(len(arr1))
for _, v := range arr1{
- fmt.Printf("%c", v) // lnjæåæ±
+ fmt.Printf("%c", v) // å
¬å·ï¼ä»£ç æ
ç¼7
}
// Go语言中rune类型就是专门用于保存汉字的
arr2 := []rune(str)
- fmt.Println(len(arr2)) // 6
+ fmt.Println(len(arr2)) // 7
for _, v := range arr2{
- fmt.Printf("%c", v) // lnj李南江
+ fmt.Printf("%c", v) // 公号:代码情缘
}
}
```
@@ -5721,7 +5723,7 @@ func main() {
// 会将字符串先转换为[]rune, 然后遍历rune切片逐个取出传给自定义函数
// 只要函数返回true,代表符合我们的需求, 既立即停止查找
res = strings.IndexFunc("hello 李南江", custom)
- fmt.Println(res) // 6
+ fmt.Println(res) // 4
// 倒序查找`子串`在字符串第一次出现的位置, 找不到返回-1
res := strings.LastIndex("hello 李南江", "l")
@@ -5758,7 +5760,7 @@ func main() {
res = strings.ContainsRune( "hello 代码情缘", 'l')
fmt.Println(res) // true
res = strings.ContainsRune( "hello 代码情缘", '李')
- fmt.Println(res) // true
+ fmt.Println(res) // false
// 查找`汉字`OR`字符`中任意一个在字符串中是否存在, 存在返回true, 不存在返回false
// 底层实现就是调用strings.IndexAny函数
@@ -6114,7 +6116,7 @@ import (
)
func main() {
var t time.Time = time.Now()
- // 2006/01/02 15:04:05这个字符串是Go语言规定的, 各个数字都是固定的
+ // 2006/01/02 15:04:05这个字符串是Go语言规定的, 各个数字都是固定的 06年1月2日3点4分5秒(下午)
// 字符串中的各个数字可以只有组合, 这样就能按照需求返回格式化好的时间
str1 := t.Format("2006/01/02 15:04:05")
fmt.Println(str1)
@@ -6255,8 +6257,8 @@ package main
extern void GoFunction();
void CFunction() {
- printf("CFunction!\n");
- GoFunction();
+ printf("CFunction!\n");
+ GoFunction();
}
*/
import "C"
@@ -6355,7 +6357,7 @@ func main() {
- 指针类型
+ 原生数值类型的指针类型可按Go语法在类型前面加上*,例如:var p *C.int。
+ 而void*比较特殊,用Go中的unsafe.Pointer表示。
- + unsafe.Pointer:通用指针类型,用于转换不同类型的指针,不能进行指针运算
+ + unsafe.Pointer:通用指针类型,用于转换不同类型的指针,不能进行指针运算
+ uintptr:用于指针运算,GC 不把 uintptr 当指针,uintptr 无法持有对象。uintptr 类型的目标会被回收
+ 也就是说 unsafe.Pointer 是桥梁,可以让任意类型的指针实现相互转换,也可以将任意类型的指针转换为uintptr 进行指针运算
@@ -6422,8 +6424,8 @@ package main
/*
#include <stdio.h>
struct Point {
- float x;
- float y;
+ float x;
+ float y;
};
*/
import "C"
@@ -6475,25 +6477,25 @@ package main
/*
#include <stdio.h>
char lowerCase(char ch){
- // 1.判断当前是否是小写字母
- if(ch >= 'a' && ch <= 'z'){
- return ch;
- }
- // 注意点: 不能直接编写else, 因为执行到else不一定是一个大写字母
- else if(ch >= 'A' && ch <= 'Z'){
- return ch + ('a' - 'A');
- }
- return ' ';
+ // 1.判断当前是否是小写字母
+ if(ch >= 'a' && ch <= 'z'){
+ return ch;
+ }
+ // 注意点: 不能直接编写else, 因为执行到else不一定是一个大写字母
+ else if(ch >= 'A' && ch <= 'Z'){
+ return ch + ('a' - 'A');
+ }
+ return ' ';
}
char getCh(){
- // 1.接收用户输入的数据
- char ch;
- scanf("%c", &ch);
- setbuf(stdin, NULL);
- // 2.大小写转换
- ch = lowerCase(ch);
- // 3.返回转换好的字符
- return ch;
+ // 1.接收用户输入的数据
+ char ch;
+ scanf("%c", &ch);
+ setbuf(stdin, NULL);
+ // 2.大小写转换
+ ch = lowerCase(ch);
+ // 3.返回转换好的字符
+ return ch;
}
*/
import "C"
@@ -6609,10 +6611,10 @@ func main() {
}
```
- ReadBytes和ReadString函数(带缓冲区去读)
- + func (b *Reader) ReadBytes(delim byte) (line []byte, err error)
- + ReadBytes读取直到第一次遇到delim字节
- + func (b *Reader) ReadString(delim byte) (line string, err error)
- + ReadString读取直到第一次遇到delim字节
+ + func (b *Reader) ReadBytes(delim byte) (line []byte, err error)
+ + ReadBytes读取直到第一次遇到delim字节
+ + func (b *Reader) ReadString(delim byte) (line string, err error)
+ + ReadString读取直到第一次遇到delim字节
```go
package main
@@ -6739,43 +6741,43 @@ func main() {
+ 第二个参数: 打开的模式
```go
const (
- O_RDONLY int = syscall.O_RDONLY // 只读模式打开文件
- O_WRONLY int = syscall.O_WRONLY // 只写模式打开文件
- O_RDWR int = syscall.O_RDWR // 读写模式打开文件
- O_APPEND int = syscall.O_APPEND // 写操作时将数据附加到文件尾部
- O_CREATE int = syscall.O_CREAT // 如果不存在将创建一个新文件
- O_EXCL int = syscall.O_EXCL // 和O_CREATE配合使用,文件必须不存在
- O_SYNC int = syscall.O_SYNC // 打开文件用于同步I/O
- O_TRUNC int = syscall.O_TRUNC // 如果可能,打开时清空文件
+ O_RDONLY int = syscall.O_RDONLY // 只读模式打开文件
+ O_WRONLY int = syscall.O_WRONLY // 只写模式打开文件
+ O_RDWR int = syscall.O_RDWR // 读写模式打开文件
+ O_APPEND int = syscall.O_APPEND // 写操作时将数据附加到文件尾部
+ O_CREATE int = syscall.O_CREAT // 如果不存在将创建一个新文件
+ O_EXCL int = syscall.O_EXCL // 和O_CREATE配合使用,文件必须不存在
+ O_SYNC int = syscall.O_SYNC // 打开文件用于同步I/O
+ O_TRUNC int = syscall.O_TRUNC // 如果可能,打开时清空文件
)
```
+ 第三个参数: 指定权限
- + 0没有任何权限
- + 1.执行权限(如果是可执行程序, 可以运行)
- + 2.写权限
- + 3.写权限和执行权限
- + 4.读权限
- + 5.读权限和执行权限
- + 6.读权限和写权限
- + 7.读权限和写权限以及执行权限
+ + 0没有任何权限
+ + 1.执行权限(如果是可执行程序, 可以运行)
+ + 2.写权限
+ + 3.写权限和执行权限
+ + 4.读权限
+ + 5.读权限和执行权限
+ + 6.读权限和写权限
+ + 7.读权限和写权限以及执行权限
```go
const (
- // 单字符是被String方法用于格式化的属性缩写。
- ModeDir FileMode = 1 << (32 - 1 - iota) // d: 目录
- ModeAppend // a: 只能写入,且只能写入到末尾
- ModeExclusive // l: 用于执行
- ModeTemporary // T: 临时文件(非备份文件)
- ModeSymlink // L: 符号链接(不是快捷方式文件)
- ModeDevice // D: 设备
- ModeNamedPipe // p: 命名管道(FIFO)
- ModeSocket // S: Unix域socket
- ModeSetuid // u: 表示文件具有其创建者用户id权限
- ModeSetgid // g: 表示文件具有其创建者组id的权限
- ModeCharDevice // c: 字符设备,需已设置ModeDevice
- ModeSticky // t: 只有root/创建者能删除/移动文件
- // 覆盖所有类型位(用于通过&获取类型位),对普通文件,所有这些位都不应被设置
- ModeType = ModeDir | ModeSymlink | ModeNamedPipe | ModeSocket | ModeDevice
- ModePerm FileMode = 0777 // 覆盖所有Unix权限位(用于通过&获取类型位)
+ // 单字符是被String方法用于格式化的属性缩写。
+ ModeDir FileMode = 1 << (32 - 1 - iota) // d: 目录
+ ModeAppend // a: 只能写入,且只能写入到末尾
+ ModeExclusive // l: 用于执行
+ ModeTemporary // T: 临时文件(非备份文件)
+ ModeSymlink // L: 符号链接(不是快捷方式文件)
+ ModeDevice // D: 设备
+ ModeNamedPipe // p: 命名管道(FIFO)
+ ModeSocket // S: Unix域socket
+ ModeSetuid // u: 表示文件具有其创建者用户id权限
+ ModeSetgid // g: 表示文件具有其创建者组id的权限
+ ModeCharDevice // c: 字符设备,需已设置ModeDevice
+ ModeSticky // t: 只有root/创建者能删除/移动文件
+ // 覆盖所有类型位(用于通过&获取类型位),对普通文件,所有这些位都不应被设置
+ ModeType = ModeDir | ModeSymlink | ModeNamedPipe | ModeSocket | ModeDevice
+ ModePerm FileMode = 0777 // 覆盖所有Unix权限位(用于通过&获取类型位)
)
```
- 不带缓冲区写入
@@ -6879,12 +6881,12 @@ func main() {
- 返回值: FileInfo
```go
type FileInfo interface {
- Name() string // 文件的名字(不含扩展名)
- Size() int64 // 普通文件返回值表示其大小;其他文件的返回值含义各系统不同
- Mode() FileMode // 文件的模式位
- ModTime() time.Time // 文件的修改时间
- IsDir() bool // 等价于Mode().IsDir()
- Sys() interface{} // 底层数据来源(可以返回nil)
+ Name() string // 文件的名字(不含扩展名)
+ Size() int64 // 普通文件返回值表示其大小;其他文件的返回值含义各系统不同
+ Mode() FileMode // 文件的模式位
+ ModTime() time.Time // 文件的修改时间
+ IsDir() bool // 等价于Mode().IsDir()
+ Sys() interface{} // 底层数据来源(可以返回nil)
}
```
- 返回值: error
@@ -7015,14 +7017,14 @@ func main() {
## 什么是串行?
+ 串行就是按顺序执行, 就好比银行只有1个窗口, 有3个人要办事, 那么必须排队, 只有前面的人办完走人, 才能轮到你
+ 在计算机中, ***同一时刻, 只能有一条指令, 在一个CPU上执行, 后面的指令必须等到前面指令执行完才能执行***, 就是串行
- +
+ +
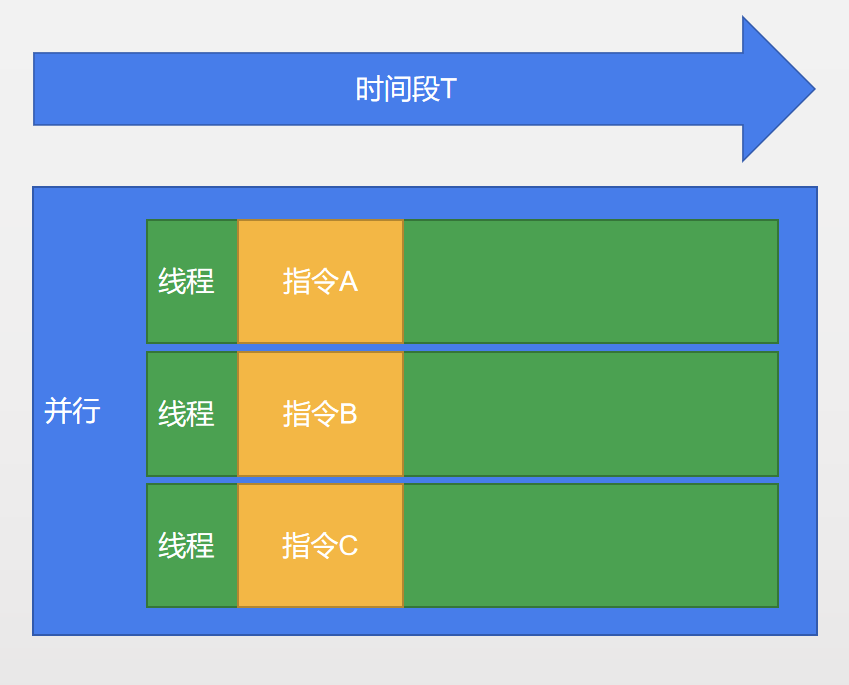
## 什么是并行?
+ 并行就是同时执行, 就好比银行有3个窗口, 有3个人要办事, 只需要到空窗口即可立即办事.
+ 在计算机中, ***同一时刻, 有多条指令, 在多个CPU上执行***, 就是并行
+ 从以上分析不难看出, 并行的速度优于串行
- +
+ +
## 什么是并发?
@@ -7038,22 +7040,22 @@ func main() {
---
## 什么是程序?
+ `程序`是指将`编译型语言`编写好的代码通过编译工具编译之后`存储在硬盘`上的一个`二进制文件`, 会占用磁盘空间, 但不会占用系统资源
- - 例如我们通过C++编写了一个聊天程序, 然后通过C++编译器将编写好的代码编译成一个二进制的文件, 那么这个二进制的文件就是一个程序
+ - 例如我们通过C++编写了一个聊天程序, 然后通过C++编译器将编写好的代码编译成一个二进制的文件, 那么这个二进制的文件就是一个程序
## 什么是进程?
+ `进程`是指`程序`在操作系统中的一次执行过程, 是系统进行资源分配和调度的基本单位
+ 例如:
- * 启动记事本这个程序, 在系统中就会创建一个记事本进程
- * 再次启动记事本这个程序, 又会在系统中创建一个记事本进程
+ * 启动记事本这个程序, 在系统中就会创建一个记事本进程
+ * 再次启动记事本这个程序, 又会在系统中创建一个记事本进程
+ 程序和进程的关系就好比剧本和演出的关系
- * 剧本对应程序, 演出对应进程. 同一个剧本可以在多个舞台同时演出互不影响, 同一个程序可以在系统中开启多个进程互不影响
+ * 剧本对应程序, 演出对应进程. 同一个剧本可以在多个舞台同时演出互不影响, 同一个程序可以在系统中开启多个进程互不影响
+ 所以程序和进程的关系是1:N, 所以多个进程的空间是独立的
## 什么是线程?
+ 线程是指进程中的一个执行实例, 是程序执行的最小单元, 它是比进程更小的能独立运行的基本单位
+ 一个进程中至少有一个线程, 这个线程我们称之为`主线程`
+ 一个进程中除了`主线程`以外, 我们还可以创建和销毁多个线程
+ 例如:
- * 启动迅雷这个程序, 系统会创建一个`迅雷进程`, 并且默认会有一个`主线程`, 用于执行迅雷默认的业务逻辑
- * 当我们利用迅雷下载`多个任务`的时候, 会发现多个任务都在`同时下载`, 此时为了能够`同时执行`下载操作, 迅雷就会创建多个线程, 将不同的下载任务放到不同的线程中执行
+ * 启动迅雷这个程序, 系统会创建一个`迅雷进程`, 并且默认会有一个`主线程`, 用于执行迅雷默认的业务逻辑
+ * 当我们利用迅雷下载`多个任务`的时候, 会发现多个任务都在`同时下载`, 此时为了能够`同时执行`下载操作, 迅雷就会创建多个线程, 将不同的下载任务放到不同的线程中执行
+ 
## 什么是协程?
+ 协程是一种用户态的轻量级线程,又称微线程,英文名Coroutine
@@ -7181,16 +7183,16 @@ func main() {
}
```
+ GOMAXPROCS: 设置可同时执行的最大CPU数,并返回先前的设置
- * Go语言1.8之前, 需要我们手动设置
- * Go语言1.8之后, 不需要我们手动设置
+ * Go语言1.8之前, 需要我们手动设置
+ * Go语言1.8之后, 不需要我们手动设置
```
func main() {
- // 获取带来了CPU个数
- num := runtime.NumCPU()
- // 设置同时使用CPU个数
- runtime.GOMAXPROCS(num)
- }
+ // 获取带来了CPU个数
+ num := runtime.NumCPU()
+ // 设置同时使用CPU个数
+ runtime.GOMAXPROCS(num)
+ }
```
## 多线程同步问题
@@ -7201,7 +7203,7 @@ func main() {
+ 有一个打印函数, 用于逐个打印字符串中的字符, 有两个人都开启了goroutine去打印
+ 如果没有添加互斥锁, 那么两个人都有机会输出自己的内容
+ 如果添加了互斥锁, 那么会先输出某一个的, 输出完毕之后再输出另外一个人的
-```go
+```go
package main
import (
"fmt"
@@ -7236,7 +7238,8 @@ func main() {
;
}
}
- ```
+```
+
---
## 生产者消费者问题
- 所谓的生产者消费者模型就是
@@ -7318,7 +7321,7 @@ func main() {
+ 
- Channel是线程安全的, 也就是自带锁定功能
- Channel声明和初始化
- + 声明: ```var 变量名chan 数据类型```
+ + 声明: ```var 变量名 chan 数据类型```
+ 初始化: ```mych := make(chan 数据类型, 容量)```
+ Channel和切片还有字典一样, 必须make之后才能使用
+ Channel和切片还有字典一样, 是引用类型
@@ -7879,8 +7882,8 @@ func main() {
+ 和NewTimer差不多, 只不过NewTimer只会往管道中写入一次数据, 而NewTicker每隔一段时间就会写一次
```c
type Ticker struct {
- C <-chan Time // 周期性传递时间信息的通道
- // 内含隐藏或非导出字段
+ C <-chan Time // 周期性传递时间信息的通道
+ // 内含隐藏或非导出字段
}
```
```go
diff --git a/src/goguidecode/cInGoTest01.go b/src/goguidecode/cInGoTest01.go
new file mode 100644
index 0000000..e2f8914
--- /dev/null
+++ b/src/goguidecode/cInGoTest01.go
@@ -0,0 +1,11 @@
+package main
+
+//#include <stdio.h>
+//void say(){
+// printf("Hello World\n");
+//}
+import "C"
+
+func main() {
+ C.say()
+}
diff --git a/src/goguidecode/chanTest01.go b/src/goguidecode/chanTest01.go
new file mode 100644
index 0000000..f63e21e
--- /dev/null
+++ b/src/goguidecode/chanTest01.go
@@ -0,0 +1,118 @@
+package main
+
+import "fmt"
+
+func main() {
+
+ // producerAndConsumerNaiveTest01.go
+ /*
+ goRoutineInGoTest01.go 实现并发的代码中为了保持主线程不挂掉, 我们都会在最后写上一个死循环或者写上一个定时器来实现等待goroutine执行完毕
+ producerAndConsumerNaiveTest01.go 实现并发的代码中为了解决生产者消费者资源同步问题, 我们利用加锁来解决, 但是这仅仅是一对一的情况, 如果是一对多或者多对多, 上述代码还是会出现问题
+ 综上所述, 企业开发中需要一种更牛X的技术来解决上述问题, 那就是管道(Channel)
+ */
+
+ // 1.声明一个管道
+ var mych chan int
+ // 2.初始化一个管道
+ mych = make(chan int, 4)
+ // 3.查看管道的长度和容量
+ fmt.Println("长度是", len(mych), "容量是", cap(mych))
+ // 4.像管道中写入数据
+ mych <- 777
+ mych <- 666
+ fmt.Println("长度是", len(mych), "容量是", cap(mych))
+ // 5.取出管道中写入的数据
+ num := <-mych
+ fmt.Println("num = ", num)
+ fmt.Println("长度是", len(mych), "容量是", cap(mych))
+
+ // 注意点: 管道中只能存放声明的数据类型, 不能存放其它数据类型
+ //mych<-3.14
+
+ // 注意点: 管道中如果已经没有数据,
+ // 并且检测不到有其它协程再往管道中写入数据, 那么再取就会报错
+ //num = <-mych
+ //fmt.Println("num = ", num)
+
+ mych <- 777
+ mych <- 888
+ mych <- 999
+
+ // 3.遍历管道
+ // 第一次遍历i等于0, len = 3
+ // 第二次遍历i等于1, len = 2
+ // 第三次遍历i等于2, len = 1
+ for i := 0; i < len(mych); i++ {
+ fmt.Print("--len--", len(mych), " i ", i, " --")
+ fmt.Println(<-mych) // 输出结果不正确
+ }
+
+ // 3.写入完数据之后先关闭管道
+ // 注意点: 管道关闭之后只能读不能写
+ close(mych)
+ //mych <- 999 // 报错
+
+ // 4.遍历管道
+ // 利用for range遍历, 必须先关闭管道, 否则会报错
+ //for value := range mych{
+ // fmt.Println(value)
+ //}
+
+ // close主要用途:
+ // 在企业开发中我们可能不确定管道有还没有有数据, 所以我们可能一直获取
+ // 但是我们可以通过ok-idiom模式判断管道是否关闭, 如果关闭会返回false给ok. 必须先关闭管道, 否则会报错
+ for {
+ if num, ok := <-mych; ok {
+ fmt.Println(num)
+ } else {
+ break
+ }
+ }
+ fmt.Println("数据读取完毕")
+
+ /*
+ 注意点: 如果管道中数据已满, 再写入就会报错
+ mych<- 888
+ mych<- 999
+ goroutine 1 [chan send]:
+ main.main()
+ D:/Devops/gohome/GoGuide/src/goguidecode/chanTest01.go:40 +0x3cf
+ */
+
+ var myCh2 = make(chan int, 0)
+ // 无缓冲管道
+ // 只有两端同时准备好才不会报错
+ go func() {
+ fmt.Println(<-myCh2)
+ }()
+ // 只写入, 不读取会报错
+ myCh2 <- 1
+ fmt.Println("len =", len(myCh2), "cap =", cap(myCh2))
+ // 写入之后在同一个线程读取也会报错
+ //fmt.Println(<-myCh2)
+
+ // 在主程中先写入, 在子程中后读取也会报错
+ //go func() {
+ // fmt.Println(<-myCh2)
+ //}()
+
+ // 1.定义一个双向管道
+ var myCh chan int = make(chan int, 5)
+ // 2.将双向管道转换单向管道
+ var myCh4 chan<- int
+ myCh4 = myCh
+ fmt.Println(myCh4)
+ var myCh3 <-chan int
+ myCh3 = myCh
+ fmt.Println(myCh3)
+ // 3.双向管道,可读可写
+ myCh <- 1
+ fmt.Println(<-myCh)
+ // 3.只写管道,只能写, 不能读
+ myCh4 <- 666
+ // fmt.Println(<-myCh2)
+ // 4.指读管道, 只能读,不能写
+ fmt.Println(<-myCh3)
+ //myCh3<-666
+ // 注意点: 管道之间赋值是地址传递, 以上三个管道底层指向相同容器
+}
diff --git a/src/goguidecode/chanTest02.go b/src/goguidecode/chanTest02.go
new file mode 100644
index 0000000..b7018ac
--- /dev/null
+++ b/src/goguidecode/chanTest02.go
@@ -0,0 +1,117 @@
+package main
+
+import (
+ "fmt"
+ "math/rand"
+ "time"
+)
+// 定义缓冲区
+var myCh = make(chan int, 5)
+var exitCh = make(chan bool, 1)
+
+// 定义生产者
+func producer2(){
+ rand.Seed(time.Now().UnixNano())
+ for i:=0;i<10;i++{
+ num := rand.Intn(100)
+ fmt.Println("生产者生产了: ", num)
+ // 往管道中写入数据
+ myCh<-num
+ time.Sleep(time.Millisecond * 100)
+ }
+ // 生产完毕之后关闭管道
+ close(myCh)
+ fmt.Println("生产者停止生产")
+}
+// 定义消费者
+func consumer2() {
+ // 不断从管道中获取数据, 直到管道关闭位置
+ for{
+ if num, ok := <-myCh; !ok{
+ break
+ }else{
+ fmt.Println("---消费者消费了", num)
+ }
+ }
+ fmt.Println("消费者停止消费")
+ exitCh<-true
+}
+
+func main() {
+ go producer2()
+ go consumer2()
+ fmt.Println("exitCh之前代码")
+ // 这个是在阻塞。等待结束。
+ <-exitCh
+ fmt.Println("exitCh之后代码")
+
+ go producer3()
+ go consumer3()
+ <- exitCh2
+
+ var myCh4 = make(chan int, 5)
+ go producer4(myCh4)
+ consumer4(myCh4)
+}
+
+
+// 定义无缓冲Channel
+//var myCh = make(chan int, 0)
+var myCh2 = make(chan int, 0)
+var exitCh2 = make(chan bool, 1)
+
+// 定义生产者
+func producer3(){
+ rand.Seed(time.Now().UnixNano())
+ for i:=0;i<10;i++{
+ num := rand.Intn(100)
+ fmt.Println("生产者生产了: ", num)
+ // 往管道中写入数据
+ myCh2<-num
+ //time.Sleep(time.Millisecond * 500)
+ }
+ // 生产完毕之后关闭管道
+ close(myCh2)
+ fmt.Println("生产者停止生产")
+}
+// 定义消费者
+func consumer3() {
+ // 不断从管道中获取数据, 直到管道关闭位置
+ for{
+ if num, ok := <-myCh2; !ok{
+ break
+ }else{
+ fmt.Println("---消费者消费了", num)
+ }
+ }
+ fmt.Println("消费者停止消费")
+ exitCh2<-true
+}
+
+// 定义生产者
+func producer4(myCh chan<- int){
+ rand.Seed(time.Now().UnixNano())
+ for i:=0;i<10;i++{
+ num := rand.Intn(100)
+ fmt.Println("生产者生产了: ", num)
+ // 往管道中写入数据
+ myCh<-num
+ //time.Sleep(time.Millisecond * 500)
+ }
+ // 生产完毕之后关闭管道
+ close(myCh)
+ fmt.Println("生产者停止生产")
+}
+// 定义消费者
+func consumer4(myCh <-chan int) {
+ // 不断从管道中获取数据, 直到管道关闭位置
+ for{
+ if num, ok := <-myCh; !ok{
+ break
+ }else{
+ fmt.Println("---消费者消费了", num)
+ }
+ }
+ fmt.Println("消费者停止消费")
+
+}
diff --git a/src/goguidecode/errorpanicTest01.go b/src/goguidecode/errorpanicTest01.go
new file mode 100644
index 0000000..9153ebb
--- /dev/null
+++ b/src/goguidecode/errorpanicTest01.go
@@ -0,0 +1,55 @@
+package main
+import "fmt"
+
+func div(a, b int) (res int) {
+ // 定义一个延迟调用的函数, 用于捕获panic异常
+ // 注意: 一定要在panic之前定义
+ defer func() {
+ if err := recover(); err != nil{
+ res = -1
+ fmt.Println(err) // 除数不能为0
+ }
+ }()
+
+ if b == 0 {
+ //err = errors.New("除数不能为0")
+ panic("除数不能为0")
+ }else{
+ res = a / b
+ }
+
+ defer func() {
+ panic("异常被defer捕获")
+ }()
+
+ return
+}
+
+func setValue(arr []int, index int ,value int) {
+ arr[index] = value
+}
+
+func main() {
+ res := div(10, 0)
+ fmt.Println(res) // -1
+
+ defer func() {
+ panic("异常被defer捕获")
+ }()
+
+ //panic("异常2")
+}
+
+func test2() {
+ // 如果有异常写在defer中, 并且其它异常写在defer后面, 那么只有defer中的异常会被捕获
+ defer func() {
+ if err := recover(); err != nil{
+ fmt.Println(err) // 异常A
+ }
+ }()
+
+ defer func() {
+ panic("异常B")
+ }()
+ panic("异常A")
+}
\ No newline at end of file
diff --git a/src/goguidecode/errorpanicTest02.go b/src/goguidecode/errorpanicTest02.go
new file mode 100644
index 0000000..aaaebea
--- /dev/null
+++ b/src/goguidecode/errorpanicTest02.go
@@ -0,0 +1,31 @@
+package main
+import "fmt"
+
+func test3(a int, b int) {
+ // 如果有异常写在defer中, 并且其它异常写在defer后面, 那么只有defer中的异常会被捕获
+ defer func() {
+ if err := recover(); err != nil{
+ fmt.Println(err) // 异常A
+ }
+ }()
+
+ defer func() {
+ panic("异常B")
+ }()
+ panic("异常A")
+}
+
+func test1() {
+ // 多个异常,只有第一个会被捕获
+ defer func() {
+ if err := recover(); err != nil{
+ fmt.Println(err) // 异常A
+ }
+ }()
+ panic("异常A") // 相当于return, 后面代码不会继续执行
+ panic("异常B")
+}
+
+func main() {
+ test3(10, 0)
+}
\ No newline at end of file
diff --git a/src/goguidecode/fileTest01-mac.go b/src/goguidecode/fileTest01-mac.go
new file mode 100644
index 0000000..524c936
--- /dev/null
+++ b/src/goguidecode/fileTest01-mac.go
@@ -0,0 +1,97 @@
+package main
+
+import (
+ "bufio"
+ "fmt"
+ "io"
+ "io/ioutil"
+ "os"
+)
+
+func main() {
+ // 1.打开一个文件
+ // 注意: 文件不存在不会创建, 会报错
+ // 注意: 通过Open打开只能读取, 不能写入
+ /* 文件内容
+ helloFile
+ helloFile1
+ helloFile2
+ */
+ fp, err := os.Open("/Users/citi/testFile01.txt")
+ if err != nil {
+ fmt.Println(err)
+ } else {
+ fmt.Println(fp)
+ }
+
+ defer func() {
+ err = fp.Close()
+ if err != nil {
+ fmt.Println(err)
+ }
+ }()
+
+ // 3.读取指定字节个数据
+ // 注意点: \n也会被读取进来
+ buf := make([]byte, 5)
+ count, err := fp.Read(buf)
+ if err != nil {
+ fmt.Println(err) // hello
+ }else{
+ fmt.Println(count) // 5
+ fmt.Println(string(buf))
+ }
+
+ // 4.循环使用一个切片,读取文件中所有内容, 直到文件末尾为止
+ buf = make([]byte, 7)
+ for{
+ count, err := fp.Read(buf)
+ // 注意: 这行代码要放到判断EOF之前, 否则会出现少读一行情况
+ fmt.Print(string(buf[:count]))
+ /* 3 中读走了5个byte了
+ File
+ helloFile1
+ helloFile2
+ */
+ if err == io.EOF {
+ break
+ }
+ }
+
+ // 重新打开一遍。不重开,就在文件末尾。
+ fp, err = os.Open("/Users/citi/testFile01.txt")
+ if err != nil {
+ fmt.Println(err)
+ } else {
+ fmt.Println(fp)
+ }
+ // 3.读取一行数据
+ // 创建读取缓冲区, 默认大小4096
+ r1 :=bufio.NewReader(fp)
+ buf21, err := r1.ReadBytes('\n')
+ buf22, err := r1.ReadString('\n')
+ if err != nil{
+ fmt.Println(err)
+ }else{
+ fmt.Print(string(buf21))
+ fmt.Print(buf22)
+ }
+
+ // 新建一个缓冲区,有问题,读取不到 r1 :=bufio.NewReader(fp)
+ // 4.读取文件中所有内容, 直到文件末尾为止
+ for{
+ //buf, err := r.ReadBytes('\n')
+ buf, err := r1.ReadString('\n')
+ fmt.Println(buf)
+ if err == io.EOF{
+ break
+ }
+ }
+
+ buf, err = ioutil.ReadFile("/Users/citi/testFile01.txt")
+ if err !=nil {
+ fmt.Println(err)
+ }else{
+ fmt.Println(string(buf))
+ }
+}
\ No newline at end of file
diff --git a/src/goguidecode/fileTest01-win.go b/src/goguidecode/fileTest01-win.go
new file mode 100644
index 0000000..06bcb32
--- /dev/null
+++ b/src/goguidecode/fileTest01-win.go
@@ -0,0 +1,110 @@
+package main
+
+import (
+ "bufio"
+ "fmt"
+ "io/ioutil"
+ "os"
+)
+
+func main() {
+ /*
+ Create函数
+ func Create(name string) (file *File, err error)
+ Create采用模式0666(任何人都可读写,不可执行)创建一个名为name的文件
+ 如果文件存在会覆盖原有文件
+ Write函数
+ func (f *File) Write(b []byte) (n int, err error)
+ 将指定字节数组写入到文件中
+ WriteString函数
+ func (f *File) WriteString(s string) (ret int, err error)
+ 将指定字符串写入到文件中
+ */
+
+ filePath := "d:/tmpTestCreate.txt"
+ // 1.创建一个文件
+ fp, err := os.Create(filePath)
+ if err != nil {
+ fmt.Println(err)
+ }
+ // 2.关闭打开的文件
+ defer func() {
+ err := fp.Close()
+ if err != nil {
+ fmt.Println(err)
+ }
+ }()
+
+ // 3.往文件中写入数据
+ // 注意: Windows换行是\r\n
+ bytes := []byte{'c', 'i', 't', 'y', '\r', '\n'}
+ fp.Write(bytes)
+
+ fp.WriteString("www.baidu.com\r\n")
+ fp.WriteString("www.kuaishou.com\r\n")
+ // 注意: Go语言采用UTF-8编码, 一个中文占用3个字节
+ fp.WriteString("城市\n")
+
+
+ // 注意点: 第三个参数在Windows没有效果
+ // -rw-rw-rw- (666) 所有用户都有文件读、写权限。
+ //-rwxrwxrwx (777) 所有用户都有读、写、执行权限。
+ // 4.打开文件
+ //fp, err := os.OpenFile("d:/lnj.txt", os.O_CREATE|os.O_RDWR, 0666)
+ fp, err = os.OpenFile(filePath, os.O_CREATE|os.O_APPEND, 0666)
+ if err != nil {
+ fmt.Println(err)
+ }
+
+ // 注意点:
+ // 如果O_RDWR模式打开, 被打开文件已经有内容, 会从最前面开始覆盖
+ // 如果O_APPEND模式打开, 被打开文件已经有内容, 会从在最后追加
+ // 5.往文件中写入数据
+ bytes = []byte{'2','c','i','t','y','\r','\n'}
+ fp.Write(bytes)
+ fp.WriteString("www.google.com\r\n")
+
+ // 6.1创建缓冲区
+ w := bufio.NewWriter(fp)
+
+ // 6.2.写入数据到缓冲区
+ bytes = []byte{'3','c','i','t','y','\r','\n'}
+ w.Write(bytes)
+ w.WriteString("www.tencent.com\r\n")
+
+ // 6.3.将缓冲区中的数据刷新到文件
+ w.Flush()
+
+ // 7.写入数据到指定文件
+ str2 := "2022BeijingWinterOlympicGames\r\n"
+ data := make([]byte, len(str2))
+ copy(data, str2)
+ //data := []byte(str2) 直接將str强转为byte切片
+ err = ioutil.WriteFile("d:/tempTest02.txt", data, 0666)
+ if err != nil {
+ fmt.Println(err)
+ }else{
+ fmt.Println("写入成功")
+ }
+
+ info, err := os.Stat("d:/notExist.txt")
+ if err == nil {
+ fmt.Println("文件存在")
+ fmt.Println(info.Name())
+ }else if os.IsNotExist(err) {
+ fmt.Println("文件不存在")
+ }else{
+ fmt.Println("不确定")
+ }
+
+ info, err = os.Stat(filePath)
+ if err == nil {
+ fmt.Println("文件存在")
+ fmt.Println(info.Name())
+ fmt.Println(info.Mode())
+ }else if os.IsNotExist(err) {
+ fmt.Println("文件不存在")
+ }else{
+ fmt.Println("不确定")
+ }
+}
diff --git a/src/goguidecode/goHasNoExtendsTest01.go b/src/goguidecode/goHasNoExtendsTest01.go
new file mode 100644
index 0000000..2f8ce78
--- /dev/null
+++ b/src/goguidecode/goHasNoExtendsTest01.go
@@ -0,0 +1,78 @@
+package main
+
+import "fmt"
+
+type person struct {
+ name string
+ age int
+}
+
+func (p person) say() {
+ fmt.Println("name is", p.name, "age is", p.age)
+}
+
+type student struct {
+ person
+ score float32
+}
+
+func (s student) say() {
+ fmt.Println("name is", s.name, "age is", s.age, "score is ", s.score)
+}
+
+// Animal 1.定义接口
+type Animal interface {
+ Eat()
+}
+type Dog struct {
+ name string
+ age int
+}
+
+// Eat 2.实现接口方法
+func (d Dog)Eat() {
+ fmt.Println(d.name, "正在吃东西")
+}
+
+type Cat struct {
+ name string
+ age int
+}
+
+// Eat 2.实现接口方法
+func (c Cat)Eat() {
+ fmt.Println(c.name, "正在吃东西")
+}
+
+// Special 3.对象特有方法
+func (c Cat)Special() {
+ fmt.Println(c.name, "特有方法")
+}
+
+func main() {
+ stu := student{person{"zs", 18}, 59.9}
+ stu.say() // name is zs age is 18 score is 59.9
+ stu.person.say() // name is zs age is 18
+
+ var a Animal
+
+ a = Dog{"dog", 9}
+ a.Eat()
+
+ a = Cat{"cat", 10}
+ a.Eat()
+
+ if cat,ok := a.(Cat);ok {
+ fmt.Println("ok-idiom 命中")
+ cat.Special()
+ }
+
+ switch scat := a.(type) {
+ case Cat:
+ fmt.Println("switch type 命中")
+ scat.Special()
+ default:
+ fmt.Println("not Cat type")
+ }
+
+}
diff --git a/src/goguidecode/goRoutineInGoTest01.go b/src/goguidecode/goRoutineInGoTest01.go
new file mode 100644
index 0000000..be573f3
--- /dev/null
+++ b/src/goguidecode/goRoutineInGoTest01.go
@@ -0,0 +1,74 @@
+package main
+
+import (
+ "fmt"
+ "runtime"
+ "sync"
+ "time"
+)
+
+var lock sync.Mutex
+
+func dance() {
+ for i := 0; i < 5; i++ {
+ fmt.Println("dancing")
+ time.Sleep(time.Millisecond)
+ runtime.Gosched()
+ }
+}
+
+func sing(){
+ for i := 0; i < 5; i++ {
+ fmt.Println("singing")
+ time.Sleep(time.Millisecond)
+ runtime.Gosched()
+ }
+}
+
+func test() {
+ fmt.Println("test do go exit")
+ // 只会结束当前函数, 协程中的其它代码会继续执行
+ //return
+ // 会结束整个协程, Goexit之后整个协程中的其它代码不会执行
+ runtime.Goexit()
+ fmt.Println("not reach")
+}
+
+func main() {
+ go sing()
+ go dance()
+ go func() {
+ fmt.Println("abc")
+ test()
+ fmt.Println("test exit this not print")
+ }()
+
+ go person1()
+ go person2()
+
+ for{
+ ;
+ }
+}
+
+func goToilet(str string) {
+ // 让先来的人拿到锁, 把当前函数锁住, 其它人都无法执行
+ // 上厕所关门
+ lock.Lock()
+ for _, v := range str{
+ time.Sleep(time.Millisecond * 500)
+ fmt.Printf("%c", v)
+ }
+ fmt.Println(" is shitting")
+ // 先来的人执行完毕之后, 把锁释放掉, 让其它人可以继续使用当前函数
+ // 上厕所开门
+ lock.Unlock()
+}
+
+func person1() {
+ goToilet("zhangSan")
+}
+
+func person2() {
+ goToilet("LiSi")
+}
\ No newline at end of file
diff --git a/src/goguidecode/interTesto0o1.go b/src/goguidecode/interTesto0o1.go
new file mode 100644
index 0000000..ffbd39e
--- /dev/null
+++ b/src/goguidecode/interTesto0o1.go
@@ -0,0 +1,103 @@
+package main
+
+import "fmt"
+
+type aer interface {
+ fna()
+}
+
+type ber interface {
+ aer
+ fnb()
+}
+
+type studier interface {
+ read()
+}
+
+// Person Person实现了超集接口所有方法
+type Person struct{
+ name string
+ age int
+}
+
+func (p Person) fna() {
+ fmt.Println("Person 实现A接口中的方法")
+}
+func (p Person) fnb() {
+ fmt.Println("Person 实现B接口中的方法")
+}
+
+func (p Person)read() {
+ fmt.Println(p.name, "正在学习")
+}
+
+// Student Student实现了子集接口所有方法
+type Student struct{}
+
+func (s Student) fna() {
+ fmt.Println("Student 实现A接口中的方法")
+}
+
+// 1.定义一个接口
+type usber interface {
+ start()
+ stop()
+}
+
+// 2.自定义int类型
+type integer int
+
+// 2.实现接口中的所有方法
+func (i integer) start() {
+ fmt.Println("int类型实现 start接口", i)
+}
+func (i integer) stop() {
+ fmt.Println("int类型实现 stop接口", i)
+}
+
+func main() {
+ var i ber
+ // 子集接口变量不能转换为超集接口变量
+ //i = Student{}
+ fmt.Println(i)
+ var j1 aer
+ // 超集接口变量可以自动转换成子集接口变量,
+ j1 = Person{}
+ j1.fna()
+
+ var j2 ber
+ j2 = Person{}
+ j2.fna()
+ j2.fnb()
+
+ var j3 aer
+ j3 = Student{}
+ j3.fna()
+
+ var ii integer
+ ii.start() // int类型实现接口
+ ii.stop() // int类型实现接口
+
+ var s studier
+ s = Person{"lnj", 33}
+
+ // 2.利用ok-idiom模式将接口类型还原为原始类型
+ // s.(Person)这种格式我们称之为: 类型断言
+ if p, ok := s.(Person); ok {
+ p.name = "zs"
+ p.age = 32
+ fmt.Println(p)
+ }
+
+ // 2.通过 type switch将接口类型还原为原始类型
+ // 注意: type switch不支持fallthrought
+ switch p := s.(type) {
+ case Person:
+ p.name = "ppq"
+ p.age = 56
+ fmt.Println(p) // {zs 33}
+ default:
+ fmt.Println("不是Person类型")
+ }
+}
diff --git a/src/goguidecode/mapTest01.go b/src/goguidecode/mapTest01.go
new file mode 100644
index 0000000..1c26e15
--- /dev/null
+++ b/src/goguidecode/mapTest01.go
@@ -0,0 +1,28 @@
+package main
+
+import "fmt"
+
+func main() {
+ // map格式:var dic map[key数据类型]value数据类型
+ var dic = map[int]int{0: 1, 1: 3, 3: 5}
+ fmt.Println(dic, len(dic)) // map[0:1 1:3 3:5] 3
+ dic[4] = 7
+ fmt.Println(dic, len(dic)) // map[0:1 1:3 3:5 4:7] 4
+ delete(dic, dic[0])
+ fmt.Println(dic, len(dic)) // map[0:1 3:5 4:7] 3
+
+ // 查询: 通过ok-idiom模式判断指定键值对是否存储 idiom(习语、俗语)
+ // i: 0 1 2 3 4
+ // v: 1 0 0 5 7
+ // ok: true false false true true
+ for i := 0; i < 5; {
+ v, ok := dic[i]
+ fmt.Println(i, v, ok)
+ i++
+ }
+ // k: 0 3 4
+ // v: 1 5 7
+ for k, v := range dic {
+ fmt.Println(k, v)
+ }
+}
diff --git a/src/goguidecode/pointerTest01.go b/src/goguidecode/pointerTest01.go
new file mode 100644
index 0000000..c834e5c
--- /dev/null
+++ b/src/goguidecode/pointerTest01.go
@@ -0,0 +1,97 @@
+package main
+
+import "fmt"
+
+func main() {
+ // 1.定义一个普通变量
+ var num = 666
+ // 2.定义一个指针变量
+ var p *int = &num
+ fmt.Printf("%p\n", &num) // 0xc0000b4008
+ fmt.Printf("%p\n", p) // 0xc0000b4008
+ fmt.Printf("%T\n", p) // *int
+ // 3.通过指针变量操作指向的存储空间
+ *p = 888
+ // 4.指针变量操作的就是指向变量的存储空间
+ fmt.Println(num) // 888
+ fmt.Println(*p) // 888
+
+ var arr = [3]int{1, 2, 3}
+ // 1.错误, 在Go语言中必须类型一模一样才能赋值
+ // arr类型是[3]int, p1的类型是*[3]int
+ var p1 *[3]int
+ fmt.Printf("%T\n", arr)
+ fmt.Printf("%T\n", p1)
+ fmt.Printf("%T\n", &arr)
+ // p1 = arr // 报错 type(arr) != type(p1)
+ p1 = &arr // 正确 type(&arr) = type(p1)
+ p1[1] = 6 // 我猜这个是个语法糖,和p6结构体的指针一样?
+ (*p1)[2] = 8
+ fmt.Println(arr[1])
+
+ // 2 &arr[0]的类型是*int, p3作为普通指针指向 arr[0]
+ fmt.Printf("%T\n", &arr[0])
+ p3 := &arr[0]
+ *p3 = 6
+
+ // 1.定义一个切片
+ var sce = []int{1, 3, 5}
+ // 2.打印切片的地址
+ // 切片变量中保存的地址, 也就是指向的那个数组的地址 sce = 0xc0420620a0
+ fmt.Printf("sce = %p\n", sce)
+ fmt.Println(sce) // [1 3 5]
+ // 切片变量自己的地址, &sce = 0xc04205e3e0
+ fmt.Printf("&sce = %p\n", &sce)
+ fmt.Println(&sce) // &[1 3 5]
+ // 3.定义一个指向切片的指针
+ // 因为必须类型一致才能赋值, 所以将切片变量自己的地址给了指针
+ var p4 *[]int
+ p4 = &sce
+ // 4.打印指针保存的地址
+ // 直接打印p打印出来的是保存的切片变量的地址 p = 0xc04205e3e0
+ fmt.Printf("p4 = %p\n", p4)
+ fmt.Println(p4) // &[1 3 5]
+ // 打印*p打印出来的是切片变量保存的地址, 也就是数组的地址 *p = 0xc0420620a0
+ fmt.Printf("*p4 = %p\n", *p4)
+ fmt.Printf("p4 type %T\n", p4)
+ fmt.Printf("*p4 type %T\n", *p4)
+ fmt.Println(*p4) // [1 3 5]
+ // 5.修改切片的值
+ // 通过*p找到切片变量指向的存储空间(数组), 然后修改数组中保存的数据
+ (*p4)[1] = 666
+ fmt.Println(sce)
+
+ // 字典指针与切片指针很像
+ var dict map[string]string = map[string]string{"name": "lnj", "age": "33"}
+ var p5 *map[string]string = &dict
+ fmt.Printf("%T\n", dict)
+ fmt.Printf("%T\n", p5)
+ fmt.Printf("%T\n", &p5)
+ var pp5 = &p5
+ (*(*pp5))["name"] = "?"
+ (*p5)["name"] = "zs"
+ fmt.Println(dict)
+
+ type Student struct {
+ name string
+ age int
+ }
+ var p6 = &Student{}
+ // 方式一: 传统方式操作
+ // 修改结构体中某个属性对应的值
+ // 注意: 由于.运算符优先级比*高, 所以一定要加上()
+ (*p6).name = "lnj"
+ // 获取结构体中某个属性对应的值
+ fmt.Println((*p6).name) // lnj
+
+ // 方式二: 通过Go语法糖操作
+ // Go语言作者为了程序员使用起来更加方便, 在操作指向结构体的指针时可以像操作接头体变量一样通过.来操作
+ // 编译时底层会自动转发为(*p).age方式
+ p6.age = 33
+ fmt.Println(p6.age) // 33
+
+ //指针作为函数参数和返回值
+ //如果指针类型作为函数参数, 修改形参会影响实参
+ //不能将函数内的指向局部变量的指针作为返回值, 函数结束指向空间会被释放
+ //可以将函数内的局部变量作为返回值, 本质是拷贝一份
+}
diff --git a/src/goguidecode/producerAndConsumerNaiveTest01.go b/src/goguidecode/producerAndConsumerNaiveTest01.go
new file mode 100644
index 0000000..c01a87f
--- /dev/null
+++ b/src/goguidecode/producerAndConsumerNaiveTest01.go
@@ -0,0 +1,47 @@
+package main
+
+import (
+ "fmt"
+ "math/rand"
+ "sync"
+ "time"
+)
+// 创建一把互斥锁
+var lock2 = sync.Mutex{}
+
+// 定义缓冲区
+var sce []int = make([]int, 10)
+
+// 定义生产者
+func producer(){
+ // 加锁, 注意是lock就是我们的锁, 全局公用一把锁
+ lock2.Lock()
+ rand.Seed(time.Now().UnixNano())
+ for i:=0;i<10;i++{
+ num := rand.Intn(100)
+ sce[i] = num
+ fmt.Println("生产者生产了: ", num)
+ time.Sleep(time.Millisecond * 500)
+ }
+ // 解锁
+ lock2.Unlock()
+}
+// 定义消费者
+func consumer() {
+ // 加锁, 注意和生产者中用的是同一把锁
+ // 如果生产者中已加过了, 则阻塞直到解锁后再重新加锁
+ lock.Lock()
+ for i:=0;i<10;i++{
+ num := sce[i]
+ fmt.Println("---消费者消费了", num)
+ }
+ lock.Unlock()
+}
+
+func main() {
+ go producer()
+ go consumer()
+ for{
+ ;
+ }
+}
\ No newline at end of file
diff --git a/src/goguidecode/regexpTest01.go b/src/goguidecode/regexpTest01.go
new file mode 100644
index 0000000..ddff104
--- /dev/null
+++ b/src/goguidecode/regexpTest01.go
@@ -0,0 +1,60 @@
+package main
+
+import (
+ "fmt"
+ "regexp"
+)
+
+func main() {
+ // 创建一个正则表达式匹配规则对象
+ // reg := regexp.MustCompile(规则字符串)
+ // 利用正则表达式匹配规则对象匹配指定字符串
+ // 会将所有匹配到的数据放到一个字符串切片中返回
+ // 如果没有匹配到数据会返回nil
+ // res := reg.FindAllString(需要匹配的字符串, 匹配多少个)
+
+ str := "Hello 李南江 1232"
+ reg := regexp.MustCompile("2")
+ res := reg.FindAllString(str, -1)
+ fmt.Println(res) // [2 2]
+ res = reg.FindAllString(str, 1)
+ fmt.Println(res) // [2]
+
+ res2 := isPhoneNumber("13554499311")
+ fmt.Println(res2) // true
+
+ res2 = isPhoneNumber("03554499311")
+ fmt.Println(res2) // false
+
+ res2 = isPhoneNumber("1355449931")
+ fmt.Println(res2) // false
+
+ res2 = isEmail("123@qq.com")
+ fmt.Println(res2) // true
+
+ res2 = isEmail("ab?de@qq.com")
+ fmt.Println(res2) // false
+
+ res2 = isEmail("123@qqcom")
+ fmt.Println(res2) // false
+}
+
+func isPhoneNumber(str string) bool {
+ // 创建一个正则表达式匹配规则对象
+ reg := regexp.MustCompile("^1[1-9]{10}")
+ // 利用正则表达式匹配规则对象匹配指定字符串
+ res := reg.FindAllString(str, -1)
+ if res == nil {
+ return false
+ }
+ return true
+}
+
+func isEmail(str string) bool {
+ reg := regexp.MustCompile("^[a-zA-Z0-9_]+@[a-zA-Z0-9]+\\.[a-zA-Z0-9]+")
+ res := reg.FindAllString(str, -1)
+ if res == nil {
+ return false
+ }
+ return true
+}
diff --git a/src/goguidecode/sliceTest01.go b/src/goguidecode/sliceTest01.go
new file mode 100644
index 0000000..c0076ff
--- /dev/null
+++ b/src/goguidecode/sliceTest01.go
@@ -0,0 +1,91 @@
+package main
+
+import (
+ "fmt"
+)
+
+func main() {
+
+ // generate slice from array. array[startIndex:endIndex]
+ var arr = [5]int{0, 1, 2, 3, 4}
+ // var sce = arr[a:b] 从索引下标a开始,到第b个元素结束。 最终取到的索引范围 [a, b - 1]
+ var sce = arr[1:4]
+ fmt.Println(sce) // [1 2 3]
+ // len = 切片结束位置索引 - 开始位置 3
+ // cap = 切片截取的数组长度 - 切片开始位置 4
+ fmt.Println("sce len =", len(sce), "cap = ", cap(sce))
+ // 数组地址就是数组首元素的地址
+ fmt.Printf("%p\n", &arr) // 0xc00001c0f0
+ fmt.Printf("%p\n", &arr[1]) // 0xc00001c0f8
+ // 切片地址就是数组中指定的开始元素的地址. arr[1:4]开始地址为1, 所以就是arr[1]的地址
+ fmt.Printf("%p\n", sce) // 0xc00001c0f8
+ // 同理 &arr[2] == &sce[1]
+ fmt.Printf("%p\n", &arr[2]) // 0xc00001c100
+ fmt.Printf("%p\n", &sce[1]) // 0xc00001c100
+ fmt.Println(&arr[2] == &sce[1] && arr[2] == sce[1]) // true
+
+ // 目前slice长度为3 索引最大为2 sce[3] = 68 会报错 -- panic: runtime error: index out of range [3] with length 3
+ // sce[3] = 68
+
+ // 未超过cap 不会扩容
+ sce = append(sce, 67)
+ // 扩容1后 指定索引位置3 进行赋值. slice是指针操作,原数组arr的内容跟着发生改动
+ sce[3] = 68
+ // len = 4 cap = 4
+ fmt.Println("sce len =", len(sce), "cap = ", cap(sce))
+ // arr = [0 1 2 3 68] sce = [1 2 3 68]
+ fmt.Println("arr = ", arr, "sce =", sce)
+
+ sce = append(sce, 99)
+ // 扩容1后,len > cap, slice 扩容一倍。len = 5 cap = 8
+ fmt.Println("sce len =", len(sce), "cap = ", cap(sce))
+
+ // 通过make函数创建 make(类型, 长度, 容量)
+ // 内部会先创建一个数组, 然后让切片指向数组
+ // 如果没有指定容量,那么容量和长度一样
+ var sce1 = []int{1, 3, 5}
+ var sce2 = make([]int, 5)
+ fmt.Println("len =", len(sce1), "cap = ", cap(sce1)) // len = 3 cap = 3
+ fmt.Println("len =", len(sce2), "cap = ", cap(sce2)) // len = 5 cap = 5
+ fmt.Printf("赋值前:%p\n", sce1) // 0xc0000c2020
+ fmt.Printf("赋值前:%p\n", sce2) // 0xc0000b6090
+ // 将sce2的指向修改为sce1, 此时sce1和sce2底层指向同一个数组
+ sce2 = sce1
+ fmt.Printf("赋值后:%p\n", sce1) // 0xc0000c2020
+ fmt.Printf("赋值后:%p\n", sce2) // 0xc0000c2020
+ fmt.Println("len =", len(sce1), "cap = ", cap(sce1)) // len = 3 cap = 3
+ fmt.Println("len =", len(sce2), "cap = ", cap(sce2)) // len = 3 cap = 3
+ fmt.Println(sce1, sce2) // [1 3 5] [1 3 5]
+
+ //copy(sce2, sce1)
+ sce2 = make([]int, 5)
+ copy(sce2, sce1)
+ // sce2 已经是独立的地址\堆内存
+ fmt.Printf("赋值后:%p\n", sce1) // 0xc0000c2020
+ fmt.Printf("赋值后:%p\n", sce2) // 0xc00001c180
+ fmt.Println("len =", len(sce1), "cap = ", cap(sce1)) // len = 3 cap = 3
+ fmt.Println("len =", len(sce2), "cap = ", cap(sce2)) // len = 5 cap = 5
+ sce2[1] = 666
+ fmt.Println(sce1, sce2) // [1 3 5] [1 666 5 0 0 ]
+
+ var sce3 []int
+ fmt.Println("sce3 len =", len(sce3), "cap = ", cap(sce3)) // sce3 len = 0 cap = 0
+ sce3 = make([]int, 4)
+ sce3[0] = 1
+ fmt.Println("sce3 len =", len(sce3), "cap = ", cap(sce3)) // sce3 len = 4 cap = 4
+ sce3 = []int{3, 2, 0, 0, 0, 0}
+ fmt.Println("sce3 len =", len(sce3), "cap = ", cap(sce3)) // sce3 len = 6 cap = 6
+
+ // 字符串的底层是[]byte数组, 所以字符也支持切片相关操作
+ var str string
+ str = "hello-world"
+ // 通过字符串切片 生成新字符串
+ sce4 := str[3:]
+ fmt.Println(sce4) // lo-world
+
+ sce5 := make([]byte, 10)
+ // 将字符串拷贝到切片中
+ // 第二个参数只能是slice或者是数组
+ copy(sce5, str)
+ fmt.Println(sce5) //[97 98 99 100 101 102 103 0 0 0]
+}
\ No newline at end of file
diff --git a/src/goguidecode/strOpTest01.go b/src/goguidecode/strOpTest01.go
new file mode 100644
index 0000000..8425862
--- /dev/null
+++ b/src/goguidecode/strOpTest01.go
@@ -0,0 +1,264 @@
+package main
+
+import (
+ "fmt"
+ "strings"
+)
+
+func main() {
+ lenTest()
+ fmt.Println()
+ findTest()
+ containsTest()
+ compareTest()
+ toSomethingTest()
+ splitAndJoinTest()
+ trimTest()
+}
+
+func lenTest() {
+ str1 := "lnj"
+ fmt.Println(len(str1)) // 3
+ str2 := "公号:代码情缘"
+ fmt.Println(len(str2)) // 19
+
+ str := "公号:代码情缘"
+ // 注意byte占1个字节, 只能保存字符不能保存汉字,因为一个汉字占用3个字节
+ arr1 := []byte(str) // 21
+ fmt.Println(len(arr1))
+ for _, v := range arr1{
+ fmt.Printf("%c", v) // å
¬å·ï¼ä»£ç æ
ç¼7
+ }
+
+ // Go语言中rune类型就是专门用于保存汉字的
+ arr2 := []rune(str)
+ fmt.Println(len(arr2)) // 7
+ for _, v := range arr2{
+ fmt.Printf("%c", v) // 公号:代码情缘
+ }
+}
+
+func findTest() {
+ // 查找`字符`在字符串中第一次出现的位置, 找不到返回-1
+ res := strings.IndexByte("hello 李南江", 'l')
+ fmt.Println(res) // 2
+
+ // '李' is not byte, panic. # command-line-arguments constant 26446 overflows byte
+ //res = strings.IndexByte("hello 李南江", '李')
+
+ // 查找`汉字`OR`字符`在字符串中第一次出现的位置, 找不到返回-1
+ res = strings.IndexRune("hello 李南江", '李')
+ fmt.Println(res) // 6
+ res = strings.IndexRune("hello 李南江", 'l')
+ fmt.Println(res) // 2
+
+ // 查找`汉字`OR`字符`中任意一个在字符串中第一次出现的位置, 找不到返回-1
+ res = strings.IndexAny("hello 李南江", "wml")
+ fmt.Println(res) // 2
+ // 会把wmhl拆开逐个查找, w、m、h、l只要任意一个被找到, 立刻停止查找
+ res = strings.IndexAny("hello 李南江", "wmhl")
+ fmt.Println(res) // 0
+ // 查找`子串`在字符串第一次出现的位置, 找不到返回-1
+ res = strings.Index("hello 李南江", "llo")
+ fmt.Println(res) // 2
+ // 会把lle当做一个整体去查找, 而不是拆开
+ res = strings.Index("hello 李南江", "lle")
+ fmt.Println(res) // -1
+ // 可以查找字符也可以查找汉字
+ res = strings.Index("hello 李南江", "李")
+ fmt.Println(res) // 6
+
+ // 会将字符串先转换为[]rune, 然后遍历rune切片逐个取出传给自定义函数
+ // 只要函数返回true,代表符合我们的需求, 既立即停止查找
+ res = strings.IndexFunc("hello 李南江", custom)
+ fmt.Println(res) // 4
+
+ // 倒序查找`子串`在字符串第一次出现的位置, 找不到返回-1
+ res = strings.LastIndex("hello 李南江", "l")
+ fmt.Println(res) // 3
+}
+
+func custom(r rune) bool {
+ fmt.Printf("被调用了, 当前传入的是%c\n", r)
+ if r == 'o' {
+ return true
+ }
+ return false
+}
+
+//判断字符串中是否包含子串
+func containsTest() {
+ // 查找`子串`在字符串中是否存在, 存在返回true, 不存在返回false
+ // 底层实现就是调用strings.Index函数
+ res := strings.Contains( "hello 代码情缘", "llo")
+ fmt.Println(res) // true
+
+ // 查找`汉字`OR`字符`在字符串中是否存在, 存在返回true, 不存在返回false
+ // 底层实现就是调用strings.IndexRune函数
+ res = strings.ContainsRune( "hello 代码情缘", 'l')
+ fmt.Println(res) // true
+ res = strings.ContainsRune( "hello 代码情缘", '李')
+ fmt.Println(res) // false
+
+ // 查找`汉字`OR`字符`中任意一个在字符串中是否存在, 存在返回true, 不存在返回false
+ // 底层实现就是调用strings.IndexAny函数
+ res = strings.ContainsAny( "hello 代码情缘", "wmhl")
+ fmt.Println(res) // true
+
+ // 判断字符串是否以某个字符串开头
+ res = strings.HasPrefix("lnj-book.avi", "lnj")
+ fmt.Println(res) // true
+
+ // 判断字符串是否已某个字符串结尾
+ res = strings.HasSuffix("lnj-book.avi", ".avi")
+ fmt.Println(res) // true
+}
+
+func compareTest() {
+ // 比较两个字符串大小, 会逐个字符地进行比较ASCII值
+ // 第一个参数 > 第二个参数 返回 1
+ // 第一个参数 < 第二个参数 返回 -1
+ // 第一个参数 == 第二个参数 返回 0
+ res := strings.Compare("bcd", "abc")
+ fmt.Println(res) // 1
+ res = strings.Compare("bcd", "bdc")
+ fmt.Println(res) // -1
+ res = strings.Compare("bcd", "bcd")
+ fmt.Println(res) // 0
+
+ // 判断两个字符串是否相等, 可以判断字符和中文
+ // 判断时会忽略大小写进行判断
+ res2 := strings.EqualFold("abc", "def")
+ fmt.Println(res2) // false
+ res2 = strings.EqualFold("abc", "abc")
+ fmt.Println(res2) // true
+ res2 = strings.EqualFold("abc", "ABC")
+ fmt.Println(res2) // true
+ res2 = strings.EqualFold("代码情缘", "代码情缘")
+ fmt.Println(res2) // true
+}
+
+//字符串转换
+func toSomethingTest() {
+ // 将字符串转换为小写
+ res := strings.ToLower("ABC")
+ fmt.Println(res) // abc
+
+ // 将字符串转换为大写
+ res = strings.ToUpper("abc")
+ fmt.Println(res) // ABC
+
+ // 将字符串转换为标题格式, 大部分`字符`标题格式就是大写
+ res = strings.ToTitle("hello world,./-='!")
+ fmt.Println(res) // HELLO WORLD
+ res = strings.ToTitle("HELLO WORLD")
+ fmt.Println(res) // HELLO WORLD
+
+ // 将单词首字母变为大写, 其它字符不变
+ // 单词之间用空格OR特殊字符隔开
+ res = strings.Title("hello world")
+ fmt.Println(res) // Hello World
+}
+
+func splitAndJoinTest() {
+ // 按照指定字符串切割原字符串
+ // 用,切割字符串
+ arr1 := strings.Split("a,b,c", ",")
+ fmt.Println(arr1) // [a b c]
+ arr2 := strings.Split("ambmc", "m")
+ fmt.Println(arr2) // [a b c]
+
+ // 按照指定字符串切割原字符串, 并且指定切割为几份,从前开始尽量切分到n-1份
+ // 如果最后一个参数为0, 那么会范围一个空数组
+ arr3 := strings.SplitN("a,b,c,d", ",", 3)
+ fmt.Println(arr3) // [a b c,d]
+ arr4 := strings.SplitN("a,b,c", ",", 0)
+ fmt.Println(arr4) // []
+
+ // 按照指定字符串切割原字符串, 切割时包含指定字符串
+ arr5 := strings.SplitAfter("a,b,c", ",")
+ fmt.Println(arr5) // [a, b, c]
+
+ // 按照指定字符串切割原字符串, 切割时包含指定字符串, 并且指定切割为几份
+ arr6 := strings.SplitAfterN("a,b,c", ",", 2)
+ fmt.Println(arr6) // [a, b,c]
+
+ // 按照空格切割字符串, 多个空格会合并为一个空格处理
+ arr7 := strings.Fields("a b c d")
+ fmt.Println(arr7) // [a b c d]
+
+ // 将字符串转换成切片传递给函数之后由函数决定如何切割
+ // 类似于IndexFunc
+ arr8 := strings.FieldsFunc("a,b,c", fieldsTest)
+ fmt.Println(arr8) // [a b c]
+
+ // 将字符串切片按照指定连接符号转换为字符串
+ sce := []string{"aa", "bb", "cc"}
+ str1 := strings.Join(sce, "-")
+ fmt.Println(str1) // aa-bb-cc
+
+
+ // 返回count个s串联的指定字符串
+ str2 := strings.Repeat("abc", 2)
+ fmt.Println(str2) // abcabc
+
+ // 第一个参数: 需要替换的字符串
+ // 第二个参数: 旧字符串
+ // 第三个参数: 新字符串
+ // 第四个参数: 用新字符串 替换 多少个旧字符串
+ // 注意点: 传入-1代表只要有旧字符串就替换. 传入大于0的数表示从前到后替换的个数。
+ // 注意点: 替换之后会生成新字符串, 原字符串不会受到影响
+ str3 := "abcdefabcdefabc"
+ str4 := strings.Replace(str3, "abc", "mmm", -1)
+ fmt.Println(str3) // abcdefabcdefabc
+ fmt.Println(str4) // mmmdefmmmdefmmm
+}
+
+func fieldsTest(r rune) bool {
+ fmt.Printf("被调用了, 当前传入的是%c\n", r)
+ if r == ',' {
+ return true
+ }
+ return false
+}
+
+func trimTest() {
+ // 去除字符串两端指定字符
+ str1 := strings.Trim("!!!abc!!!def!!!", "!")
+ fmt.Println(str1) // abc!!!def
+ // 去除字符串左端指定字符
+ str2 := strings.TrimLeft("!!!abc!!!def!!!", "!")
+ fmt.Println(str2) // abc!!!def!!!
+ // 去除字符串右端指定字符
+ str3 := strings.TrimRight("!!!abc!!!def!!!", "!")
+ fmt.Println(str3) // !!!abc!!!def
+ // 去除字符串两端空格
+ str4 := strings.TrimSpace(" abc!!!def ")
+ fmt.Println(str4) // abc!!!def
+
+ // 按照方法定义规则,去除字符串两端符合规则内容
+ str5 := strings.TrimFunc("!!!abc!!!def!!!", trimFunc)
+ fmt.Println(str5) // abc!!!def
+ // 按照方法定义规则,去除字符串左端符合规则内容
+ str6 := strings.TrimLeftFunc("!!!abc!!!def!!!", trimFunc)
+ fmt.Println(str6) // abc!!!def!!!
+ // 按照方法定义规则,去除字符串右端符合规则内容
+ str7 := strings.TrimRightFunc("!!!abc!!!def!!!", trimFunc)
+ fmt.Println(str7) // !!!abc!!!def
+
+ // 取出字符串开头的指定字符串
+ str8 := strings.TrimPrefix("lnj-book.avi", "lnj-")
+ fmt.Println(str8) // book.avi
+
+ // 取出字符串结尾的指定字符串
+ str9 := strings.TrimSuffix("lnj-book.avi", ".avi")
+ fmt.Println(str9) // lnj-book
+}
+
+func trimFunc(r rune) bool {
+ fmt.Printf("被调用了, 当前传入的是%c\n", r)
+ if r == '!' {
+ return true
+ }
+ return false
+}
\ No newline at end of file
diff --git a/src/goguidecode/timeTest01.go b/src/goguidecode/timeTest01.go
new file mode 100644
index 0000000..35e74e5
--- /dev/null
+++ b/src/goguidecode/timeTest01.go
@@ -0,0 +1,67 @@
+package main
+
+import (
+ "fmt"
+ "math/rand"
+ "time"
+)
+
+func main() {
+ var t time.Time = time.Now()
+ fmt.Println(t) // 2022-02-09 00:57:12.08913 +0800 CST m=+0.010149201
+
+ fmt.Println(t.Year()) // 2022
+ fmt.Println(t.Month()) // February
+ fmt.Println(t.Day()) // 9
+ fmt.Println(t.Hour())
+ fmt.Println(t.Minute())
+ fmt.Println(t.Second())
+
+ fmt.Printf("当前的时间是: %d-%d-%d %d:%d:%d\n", t.Year(),
+ t.Month(), t.Day(), t.Hour(), t.Minute(), t.Second())
+
+ var dateStr = fmt.Sprintf("%d-%d-%d %d:%d:%d", t.Year(),
+ t.Month(), t.Day(), t.Hour(), t.Minute(), t.Second())
+ fmt.Println("当前的时间是:", dateStr)
+
+ // 2006/01/02 15:04:05这个字符串是Go语言规定的, 各个数字都是固定的. 06年1月2日3点4分5秒(下午)
+ // 字符串中的各个数字可以只有组合, 这样就能按照需求返回格式化好的时间
+ str1 := t.Format("2006/01/02 15:04:05")
+ fmt.Println(str1)
+ strx := t.Format("2017-09-07 18:05:32")
+ fmt.Println(strx)
+ str2 := t.Format("2006-01-02")
+ fmt.Println(str2)
+ str3 := t.Format("15:04:05")
+ fmt.Println(str3)
+
+ for i := 0; i < 2;{
+ // 1秒钟打印一次
+ time.Sleep(time.Second * 1)
+ fmt.Println(time.Now().Format("2006/01/02 15:04:05"), "Hello one second")
+ i++
+ }
+
+ t = time.Now()
+ fmt.Println(t.Nanosecond())
+ for i := 0; i < 2; {
+ // 0.1秒打印一次
+ time.Sleep(time.Millisecond * 100)
+ t := time.Now()
+ fmt.Println(t.Nanosecond(), "Hello 100 Millisecond")
+ i++
+ }
+
+ // 获取1970年1月1日距离当前的时间(秒)
+ fmt.Println(t.Unix())
+ // 获取1970年1月1日距离当前的时间(毫秒)
+ fmt.Println(t.UnixMilli())
+ // 获取1970年1月1日距离当前的时间(纳秒)
+ fmt.Println(t.UnixNano())
+
+ // 创建随机数种子
+ rand.Seed(time.Now().UnixNano())
+ // 生成一个随机数
+ fmt.Println(rand.Intn(10))
+
+}