{kind=link}
Korean Translation Benchmark, LLM-as-a-judge
Note
현재 KorT 2.0을 준비중입니다! 많은 기대 부탁드립니다.
We are preparing KorT 2.0! Stay tuned.
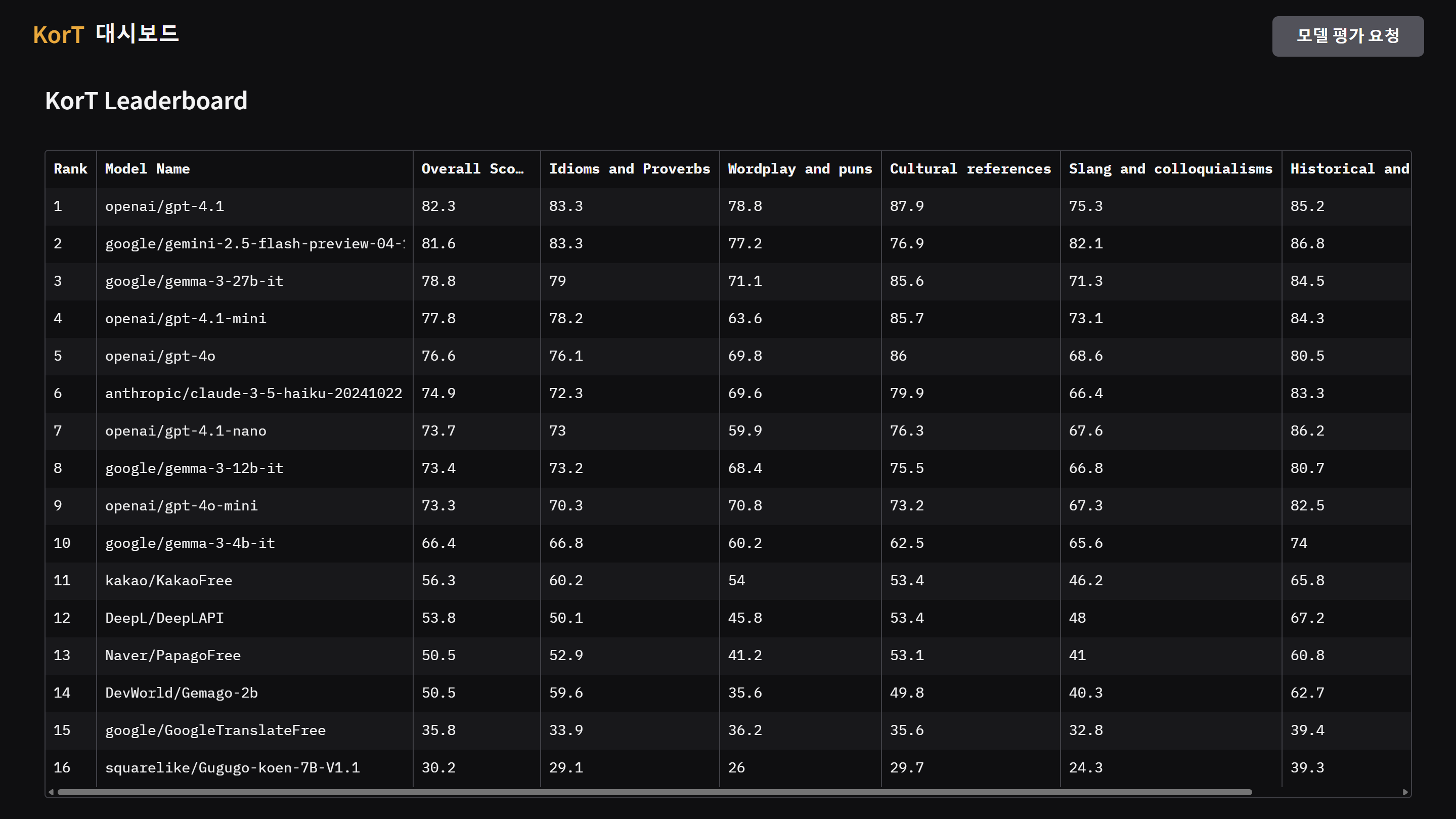
KorT는 대규모 언어 모델(LLM)을 활용하여 번역 품질을 정량적으로 평가하는 벤치마크입니다.
배경
현재 다양한 번역 서비스가 존재하지만, 번역 품질을 정량적으로 평가하고 체계적으로 비교하는 연구는 부족합니다. 기존의 BLEU와 같은 자동 평가 지표는 은어, 문화적 맥락 등 미묘한 언어적 차이를 정확히 포착하기 어렵고, 인간 평가는 시간과 비용이 많이 소요된다는 한계가 있습니다.이에 저는 한국어-다국어 번역 역량을 엄격하게 평가하기 위해 설계된 새로운 벤치마크, KorT를 제안합니다. KorT는 'LLM 기반 평가(LLM-as-a-judge)' 패러다임을 적용하여 대규모 언어 모델(LLM)의 정교한 언어 이해 능력을 평가에 활용합니다. 이를 위해 번역하기 어려운 다양한 문장으로 구성된 데이터셋을 구축했습니다. 이 데이터셋은 여러 도메인과 언어적 현상(예: 중의성, 관용 표현, 문화적 참조 등)을 포괄합니다. 다양한 기계 번역(MT) 모델과 LLM이 생성한 번역 결과는, 평가 프롬프트를 사용하여 고성능 LLM에 의해 평가됩니다.
KorT의 핵심 목표는 기존 자동 평가 지표보다 인간의 판단과 높은 상관관계를 가지면서도 신뢰할 수 있고, 확장 가능하며, 정교한 평가 체계를 구축하는 것입니다. KorT 벤치마크 결과를 기반으로 MT 시스템의 순위를 보여주는 공개 리더보드를 운영할 예정입니다. 이를 통해 현재 번역 기술의 강점과 약점에 대한 통찰력을 제공하고, 특히 한국어와 관련된 까다로운 언어적 맥락에서의 번역 성능 향상을 촉진하고자 합니다. 궁극적으로는 고품질 다국어 기계 번역 기술 발전에 기여하는 것을 목표로 합니다.
- 현재 리더보드는 여기서 확인하실 수 있습니다.
- 평가 LLM은
claude-3-7-sonnet-20250219 (Reasoning)입니다. (Anthropic측의 지원) - 모델 평가를 원하시면 여기 이메일로 문의해 주세요.
- 만약 자체 평가 프롬프트를 사용하셨다면, 함께 제공해 주시기 바랍니다.
KorT 설치하기
pip install -U kort-cli[all]
로컬 모델을 위해 Transformers, Torch가 설치됩니다. 이를 원치 않다면 [all]을 빼고 설치해주세요.
pip install -U kort-cli
직접 설치할 수도 있습니다!
git clone https://github.com/deveworld/kort
cd kort
pip install .[all]
마찬가지로 Transformers, Torch가 설치되는 것을 원치 않으시다면 [all]을 빼고 설치해주세요.
pip install .
직접적으로 설치하지 않고도 사용 가능합니다!
사용 가능한 번역기 목록 확인
python -m kort.scripts.generate -l
번역기를 선택하여 번역 생성
python -m kort.scripts.generate \
-t openai \
-n gpt-4.1-mini \
--api_key sk-xxx
평가 가능한 모델 목록 확인
python -m kort.scripts.evaluate -l
생성된 파일을 입력으로 사용하여 평가 진행
python -m kort.scripts.evaluate \
-t gemini \
-n gemini-2.5-pro-preview-03-25 \
--api_key AIzaxxx \
--input generated/openai_gpt-4.1-mini.json
Batch API를 사용하여 평가할 경우:
- Batch Job 등록
python -m kort.scripts.eval_batch \
-t claudebatch \
-n claude-3-7-sonnet-20250219 \
--api_key sk-ant-api03-xxx \
--input generated/openai_gpt-4.1-mini.json
- Batch Job 완료 후, Job ID를 사용하여 결과 취합
python -m kort.scripts.eval_batch \
-t claudebatch \
-n claude-3-7-sonnet-20250219 \
--api_key sk-ant-api03-xxx \
--input generated/openai_gpt-4.1-mini.json \
--job_id msgbatch_xxx
아래 명령어로 리더보드 웹 서버 실행
python -m kort.scripts.leaderboard
또는 텍스트로 바로 보기
python -m kort.scripts.leaderboard -t
- 문제가 있다면 주저하지 마시고 GitHub Issue를 등록해주세요.
- 코드 수정이나 개선 제안은 Pull Request(PR)를 통해 보내주시면 적극적으로 검토하겠습니다! ❤️