Diferentemente de uma aplicação Desktop (em uma máquina local), uma aplicação Web funciona sob uma arquitetura diferente: Cliente-Servidor. Na arquitetura Cliente-Servidor, o processamento das requisições é realizado por dois “lados” o Servidor (Server side) e Cliente (Client side). Assim, quando o usuário (cliente), através de um browser (navegador) faz acesso a uma página específica, o servidor faz o processamento da requisição, processa-a e enviar de para o cliente arquivos em diferentes formatos, por exemplo, HTML ou CSS. Desta forma, uma aplicação web possui basicamente dois programas que podem ser executados:
- O código que está no servidor e responde às requisições HTTP;
- E o código que está no cliente (interpretado pelo browser) e responde às entradas dos usuários.
O código disponibilizado do “lado” do servidor possui algumas peculiaridades, dentre elas:
- São quaisquer códigos que podem ser executados no Servidor e que podem responder às requisições HTTP. Por exemplo, códigos Java, C# e PHP.
- Permite a persistência de dados;
- Não pode ser visualizado pelo usuário;
- Respondem às requisições HTTP através de uma particular URL;
- Caso a aplicação seja web, cria páginas que o usuário pode visualizar através de um navegador (browser).
Um Servidor Web tem como função receber requisições e, a partir delas, oferecer respostas para o cliente. Estas requisições podem ser realizadas através de um navegador de internet (browser) pelo usuário e, geralmente, recebem como resposta uma página HTML que é interpretada pelo browser e apresentada ao usuário. Mais informações relacionadas a estas comunicação são apresentadas na seção de Comunicação e Serviços.
O código disponibilizado do “lado” do cliente também possui suas particularidades, dentre elas
- Permite o uso das linguagens HTML, CSS e JavaScript;
- Código interpretado pelo browser do usuário;
- Reage às entradas dos usuários;
- Permite a leitura de arquivos de um servidor através de requisições HTTP;
- Torna possível a exibição de conteúdos (por exemplo, uma página web) para os usuários.
Os códigos do “lado” do cliente são analisados pelo próprio navegador do cliente e são, geralmente, gerados a partir de solicitações destes clientes ao servidor. Se por acaso o servidor hospedar um determinado documento HTML (processado do lado do cliente), o servidor então tira uma cópia deste arquivo HTML e o envia para o cliente.
A comunicação no ambiente web é feita sobre a internet e, portanto, utiliza protocolos de comunicação e intercâmbio de dados em rede. O principal protocolo de comunicação na internet é o HTTP (HyperText Transfer Protocol). Como protocolo, o HTTP estabelece uma série de critérios de comunicação entre duas partes, chamadas cliente e servidor. Para mais detalhes do HTTP, leia a sua especificação.
O cliente gera uma requisição para o servidor, que a responde. Uma requisição é um pedido, uma solicitação para o servidor. O cliente solicita para o servidor um recurso, que pode ser, por exemplo, uma imagem ou um arquivo .html. Geralmente, o cliente é representado por um browser. Entre os browsers mais conhecidos e utilizados estão Google Chrome, Firefox, Internet Explorer e Safari.
O servidor responde solicitações do cliente. É por isso que este processo de comunicação sempre se dá início no cliente. Entretanto, há tecnologias que permitem que a comunicação seja iniciada no servidor, como o serviço PUSH, utilizado em softwares que, por exemplo, enviam notificações para os clientes. Uma vez que o cliente é representado pelo browser, o servidor é representado pelo servidor web (web server). Alguns dos servidores web mais conhecidos e utilizados são Apache HTTP, IIS e Nginx.
Este processo de comunicação cliente-servidor é conhecido como solicitação e resposta. A figura a seguir ilustra o processo.
Como tanto cliente quanto servidor são software (programas) é possível ter mais de um deles executando na mesma máquina (computador) e, até mesmo, é possível que tanto cliente quanto servidor estejam em execução na mesma máquina. Portanto, é importante perceber que a abstração é uma generalização e não requer que, obrigatoriamente, cliente e servidor estejam em máquinas diferentes.
Um elemento importante a ser considerado é que, embora se tenha popularizado o entendimento de utilizar a internet por meio do browser, são inúmeras as aplicações que utilizam a internet, seja para consultar ou enviar dados para uma parte remota. Por exemplo, ao utilizar um aplicativo mobile que consulta notícias a internet é utilizada. Ao consultar dados de uma rede social, o mesmo acontece. O interessante é, então, que a popularização destes recursos tornou a internet tão presente e tão inserida no dia-a-dia das pessoas que não se pode dizer que o cliente é sempre o browser. Neste sentido, recentemente (25/jun/2015) um dos presidentes do Google, Eric Schmidt, pronunciou: A Internet vai desaparecer.
Desta forma, embora este curso esteja mais voltado para software cliente e servidor baseado em tecnologias da internet como HTML, parte do conteúdo aqui presente também serve para software mobile ou desktop.
REST (Representational State Transfer) é estilo ou padrão de arquitetura de aplicações na internet. Surgiu como alternativa aos Web Services, um padrão de comunicação voltado para interoperabilidade entre sistemas baseado em HTTP e XML. Com o alto nível de complexidade dos sistemas baseados em Web Services, a utilização de REST procurou flexibilizar a comunicação entre sistemas. Principalmente, um fator importante foi a evolução dos padrões de arquitetura de software na internet e a adoção de novos padrões. Por exemplo, ao invés de utilizar exclusivamente XML, os softwares passaram a utilizar o formato JSON. Ao invés de complicados esquemas de comunicação e codificação de mensagens, o uso de REST popularizou o surgimento e a utilização das APIs REST. A figura a seguir ilustra a utilização de uma API fictícia.
A figura ilustra três situações:
- O cliente solicita a lista de produtos: em uma API REST o cliente está interessado nos dados, não no conteúdo de uma página, por exemplo. Assim, ao invés de pedir ao servidor o conteúdo de uma página que lista os produtos, o cliente solicita a lista de produtos. Os dados são codificados em JSON. Ao receber a lista, o cliente interpreta os dados e os apresenta.
- O cliente solicita um produto: como no item anterior, o cliente solicita os dados do produto, não a página de produto.
- O cliente quer cadastrar um produto: em uma API REST, o servidor trata situações de consulta e de cadastro de forma diferenciada. Neste caso, os dados são enviados para o servidor, que realiza uma atualização no banco de dados e retorna uma resposta com código HTTP 200, indicando que a requisição foi atendida com sucesso.
Alguns elementos importantes neste processo são os verbos e os códigos de status.
Com a utilização de REST, os verbos HTTP ganham mais importância. Os verbos definem, especificamente, uma semântica de comunicação com o servidor. Os mais conhecidos ou utilizados são:
- GET é usado para solicitar dados.
- POST é usado para enviar dados.
- PUT é usado para enviar dados. A diferença entre POST e PUT fica a cargo de cada API. Por exemplo, a API pode definir que POST é usado para cadastro de produto, enquanto PUT é usado para atualizar dados de um produto existente.
- DELETE é usado para excluir dados. Por exemplo, uma requisição DELETE para a URL
/produtos/1significa a solicitação da exclusão de um produto com identificador 1.
Da mesma forma que os verbos, os códigos HTTP se tornaram mais populares. Os códigos mais utilizados são:
- 200: indica que a solicitação foi atendida com sucesso.
- 404: indica que a solicitação não pode ser atendida porque o recurso solicitado não foi encontrado. Por exemplo, quando o cliente solicitar
GET /produtos/1o servidor pode responder com conteúdo vazio e código HTTP 400 para indicar que o produto solicitado não foi encontrado. O importante disso é que não é necessário retornar a mensagem textual indicando isso. - 403: indica que a solicitação não pode ser atendida por causa de falha de permissão. Por exemplo, quando o cliente solicitar
GET /produtos/1o servidor pode retornar o código 403 para indicar que o cliente não pode acessar o recurso porque não possui permissão para fazê-lo. - 500: indica um erro no servidor. O servidor pode retornar o código 500 para, por exemplo, indicar que um acesso ao banco de dados não pode ser realizado.
A utilização de REST proporcionou um crescimento no número de softwares que consomem ou disponibilizam serviços por meio de APIs. Um repositório bastante popular de APIs é o www.programmableweb.com.
O Google é bastante conhecido por sua política de acesso aos seus produtos. Grande parte deles está disponível via API. Por exemplo, você pode criar um software que consulta os dados da agenda de um usuário, ou pode consultar as coordenadas de um ponto no mapa a partir do endereço. Para conhecer mais sobre produtos do Google disponíveis via API acesse o Google Developers.
Quando se pensa em dados ou conteúdos disponíveis na internet, uma questão é justamente a proteção ou a garantia do método de acesso a estes dados ou conteúdos.
Basicamente, aplicações e sites web popularizaram a utilização de formulários como mecanismos de autenticação. A figura a seguir ilustra este processo.
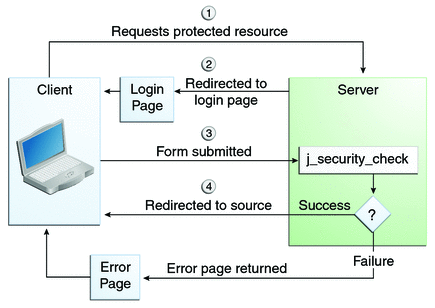
Ao acessar um recurso protegido, o servidor apresenta ao usuário uma interface de autenticação (por exemplo, um formulário por meio do qual o usuário informa seu login e senha). Se o login e a senha estiverem corretos, então o usuário continua acessando o recurso. Caso contrário, o formulário de autenticação é apresentado novamente, com uma mensagem de erro indicando a falha da autenticação.
Este processo funciona muito bem quando se trata da utilização de software por pessoas. Entretanto, no cenário de APIs a comunicação é feita via máquinas, ou seja, é software interagindo com software. Desta forma, novos mecanismos de autenticação precisaram ser estabelecidos, dentre os quais os mais populares são:
- Utilização de Cookies (de sessão ou persistentes)
- Autenticação baseada em POST (dados de autenticação ou identidade são enviados via POST em toda requisição)
- Autenticação baseada em OAuth.
Dentre estes mecanismos, o mais utilizado atualmente é, sem dúvidas, o protocolo OAuth. OAuth é um padrão aberto de comunicação que estabelece formas rígidas e bem definidas para autenticação entre sistemas. A imagem a seguir ilustra a autenticação via OAuth.
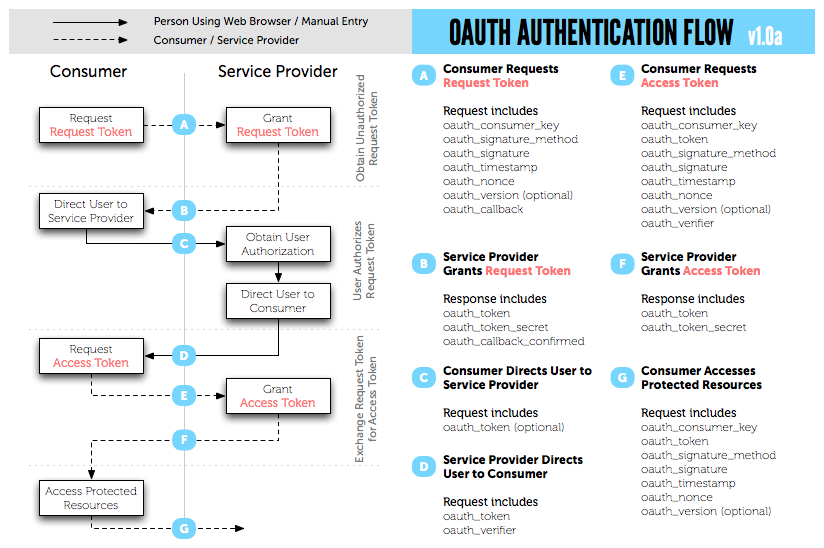
Neste cenário, são comuns termos como consumer, service provider e token.
Por exemplo, ao desenvolver software que consome dados do Twitter, do Google Plus ou do Facebook, você precisará seguir um processo (considerado burocrático, até) para acessar os dados. Geralmente isso envolve o cadastro do seu software (também chamado app), a solicitação de uma chave e a utilização dela para a comunicação com a API.
É importante informar que a utilização deste mecanismo se dá mais por causa de uma característica do próprio REST: geralmente, não utiliza cookies de sessão. Desta forma, o cliente precisa solicitar um token para o servidor e o utilizará durante o processo de comunicação (que pode ser maior do que uma sessão tradicional, de 30min, por exemplo).
Para finalizar o conjunto de ferramentas e conceitos utilizados na comunicação na internet, um recurso adicional de segurança é o HTTP seguro, ou HTTPS. Na verdade, é comum uma API ser acessada apenas via HTTPS, ao invés de HTTP. O interessante em utilizar este mecanismo é que os dados trocados entre cliente e servidor são transmitidos via um canal de comunicação seguro, baseado na utilização de algoritmos criptográficos e dos certificados digitais. A figura a seguir ilustra este processo.
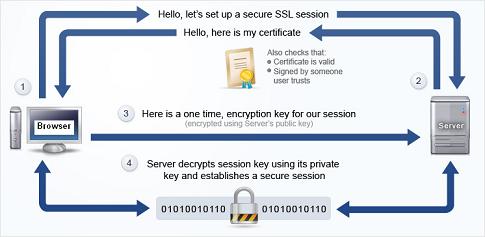
Para saber mais, leia este artigo sobre HTTPS na Wikipedia.