diff --git a/units/en/unit1/rl-framework.mdx b/units/en/unit1/rl-framework.mdx
index 97453575..f8c6deed 100644
--- a/units/en/unit1/rl-framework.mdx
+++ b/units/en/unit1/rl-framework.mdx
@@ -1,72 +1,71 @@
# The Reinforcement Learning Framework [[the-reinforcement-learning-framework]]
-## The RL Process [[the-rl-process]]
+## Understanding the RL Process [[the-rl-process]]
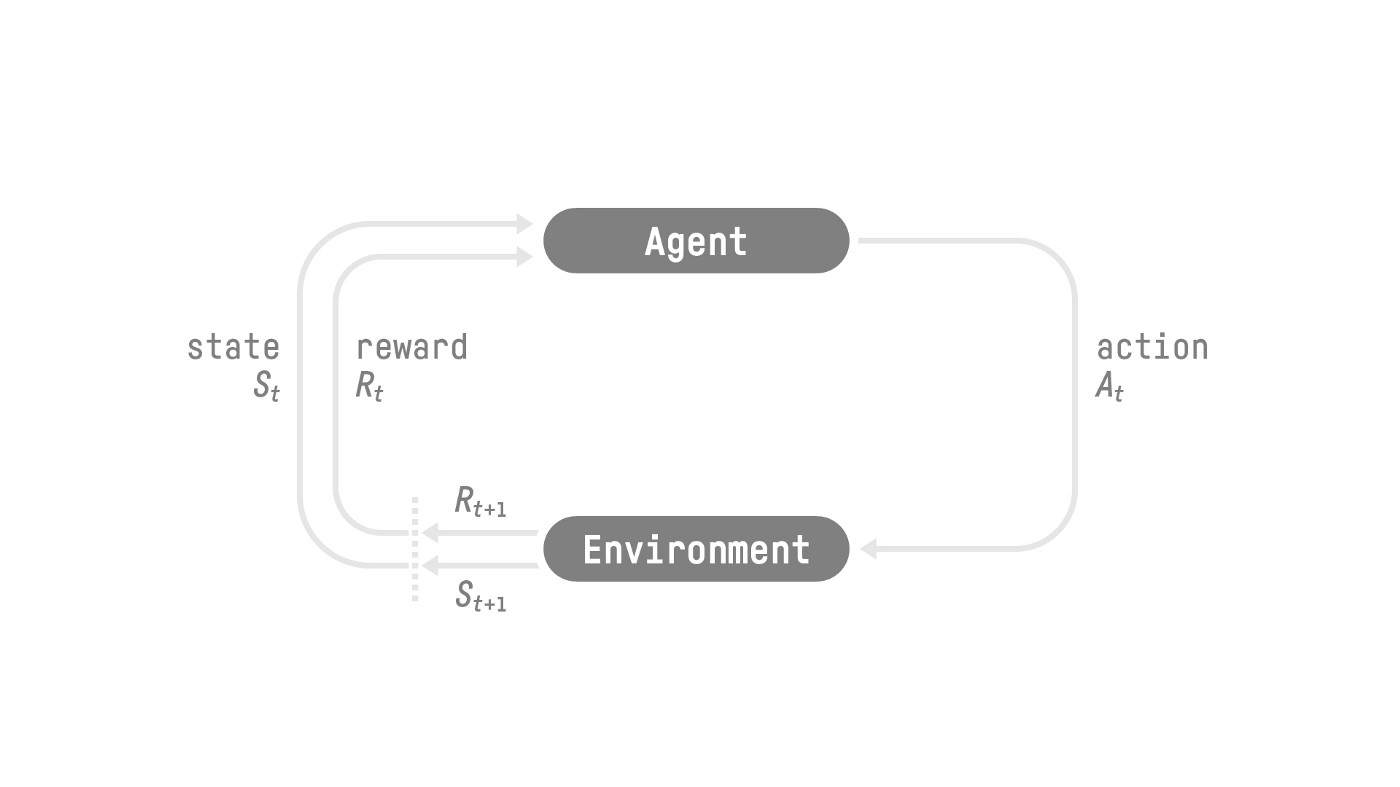
-The RL Process: a loop of state, action, reward and next state
+The RL Process: a loop of state, action, reward and next state.
+Source: Reinforcement Learning: An Introduction, Richard Sutton and Andrew G. Barto
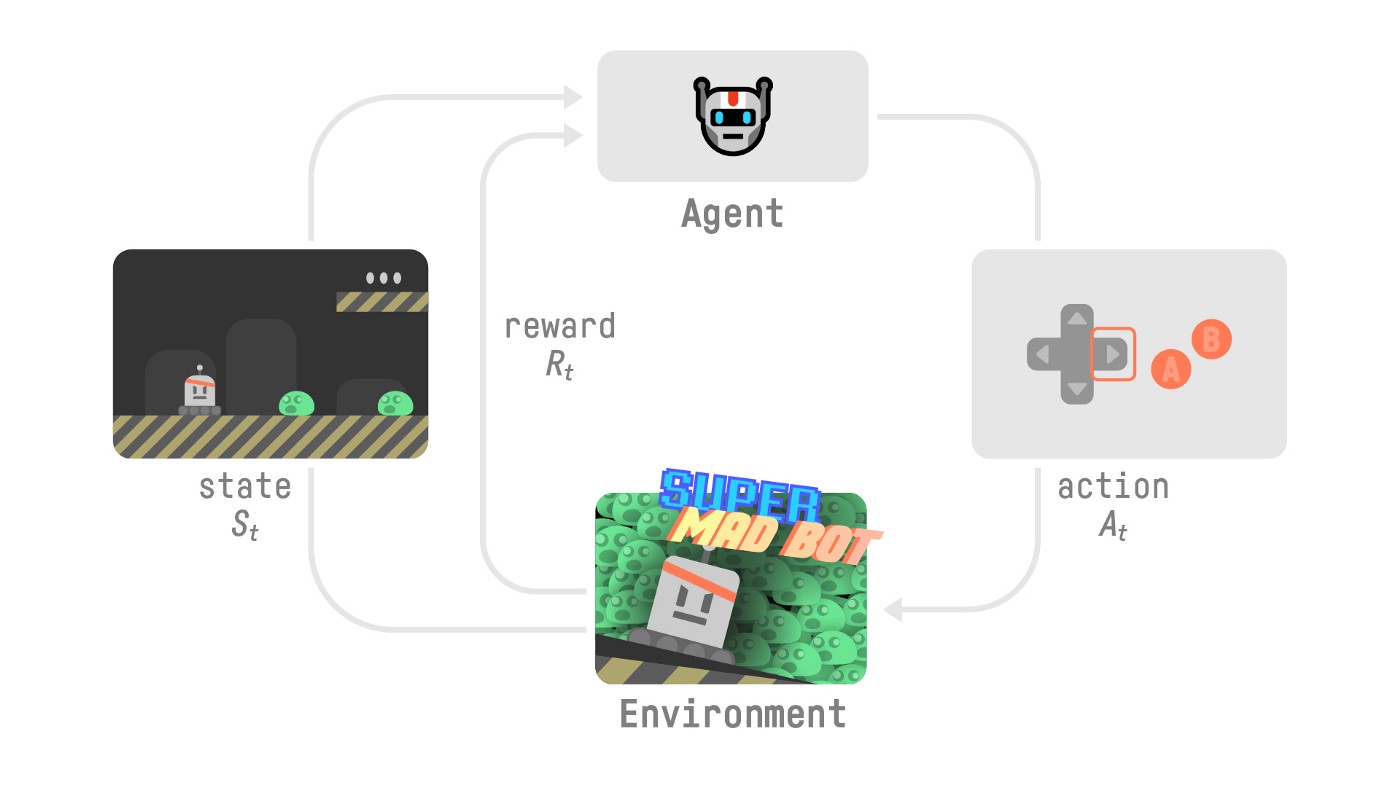
-To understand the RL process, let’s imagine an agent learning to play a platform game:
+Reinforcement Learning is like teaching an agent to play a video game. Imagine you're coaching a player in a platform game:
-- Our Agent receives **state \\(S_0\\)** from the **Environment** — we receive the first frame of our game (Environment).
-- Based on that **state \\(S_0\\),** the Agent takes **action \\(A_0\\)** — our Agent will move to the right.
-- The environment goes to a **new** **state \\(S_1\\)** — new frame.
-- The environment gives some **reward \\(R_1\\)** to the Agent — we’re not dead *(Positive Reward +1)*.
+- Our agent starts with an initial **state \\(S_0\\)** from the **Environment**; think of it as the first frame of our game.
+- Based on this **state \\(S_0\\)**, the agent makes an **action \\(A_0\\)**; in this case, our agent decides to move to the right.
+- This action leads to a **new state \\(S_1\\)**, representing the new frame.
+- The environment provides a **reward \\(R_1\\)**; luckily, we're still alive, resulting in a positive reward of +1.
-This RL loop outputs a sequence of **state, action, reward and next state.**
+This RL loop generates a sequence of **state, action, reward, and next state.**
-The agent's goal is to _maximize_ its cumulative reward, **called the expected return.**
-
-## The reward hypothesis: the central idea of Reinforcement Learning [[reward-hypothesis]]
+The agent's goal is to **maximize** its cumulative reward, which we call the **expected return.**
-⇒ Why is the goal of the agent to maximize the expected return?
+## The Reward Hypothesis: RL's Central Idea [[reward-hypothesis]]
-Because RL is based on the **reward hypothesis**, which is that all goals can be described as the **maximization of the expected return** (expected cumulative reward).
+⇒ Why does the agent aim to maximize expected return?
-That’s why in Reinforcement Learning, **to have the best behavior,** we aim to learn to take actions that **maximize the expected cumulative reward.**
+RL is built on the **reward hypothesis**, which means that all goals can be described as **maximizing expected return** (the expected cumulative reward).
+In RL, achieving the **best behavior** means learning to take actions that **maximize the expected cumulative reward.**
-## Markov Property [[markov-property]]
+## Understanding the Markov Property [[markov-property]]
-In papers, you’ll see that the RL process is called a **Markov Decision Process** (MDP).
+In academic circles, the RL process is often referred to as a **Markov Decision Process** (MDP).
-We’ll talk again about the Markov Property in the following units. But if you need to remember something today about it, it's this: the Markov Property implies that our agent needs **only the current state to decide** what action to take and **not the history of all the states and actions** they took before.
+We'll discuss the Markov Property in depth later, but for now, remember this: the Markov Property implies that our agent **only** needs the **current state** to decide its action, **not the entire history of states and actions** taken previously.
## Observations/States Space [[obs-space]]
-Observations/States are the **information our agent gets from the environment.** In the case of a video game, it can be a frame (a screenshot). In the case of the trading agent, it can be the value of a certain stock, etc.
-
-There is a differentiation to make between *observation* and *state*, however:
+Observations/States are the **information our agent receives from the environment**. In a video game, it could be a single frame, like a screenshot. In trading, it might be the value of a stock.
-- *State s*: is **a complete description of the state of the world** (there is no hidden information). In a fully observed environment.
+However, it's key to distinguish between *observation* and *state* as explained below:
+- *State s*: This is a **complete description of the world** with no hidden information.
-In chess game, we receive a state from the environment since we have access to the whole check board information.
+Game of chess depicting the entire board.
+
-In a chess game, we have access to the whole board information, so we receive a state from the environment. In other words, the environment is fully observed.
+In a fully observed environment, we have access to the entire board, just like in a game of chess.
-- *Observation o*: is a **partial description of the state.** In a partially observed environment.
+- *Observation o*: This provides only a **partial description of the state**, a **partially observed environment**.
-In Super Mario Bros, we only see the part of the level close to the player, so we receive an observation.
+Super Mario Bros screenshot depicting a portion of the environment.
+
-In Super Mario Bros, we only see the part of the level close to the player, so we receive an observation.
-
-In Super Mario Bros, we are in a partially observed environment. We receive an observation **since we only see a part of the level.**
+In a **partially observed environment**, such as Super Mario Bros, we can't see the whole level, just the section that is surrounding the character.
-In this course, we use the term "state" to denote both state and observation, but we will make the distinction in implementations.
+To keep it simple, we'll use the term "state" to refer to both state and observation in this course, but we'll distinguish them in practice.
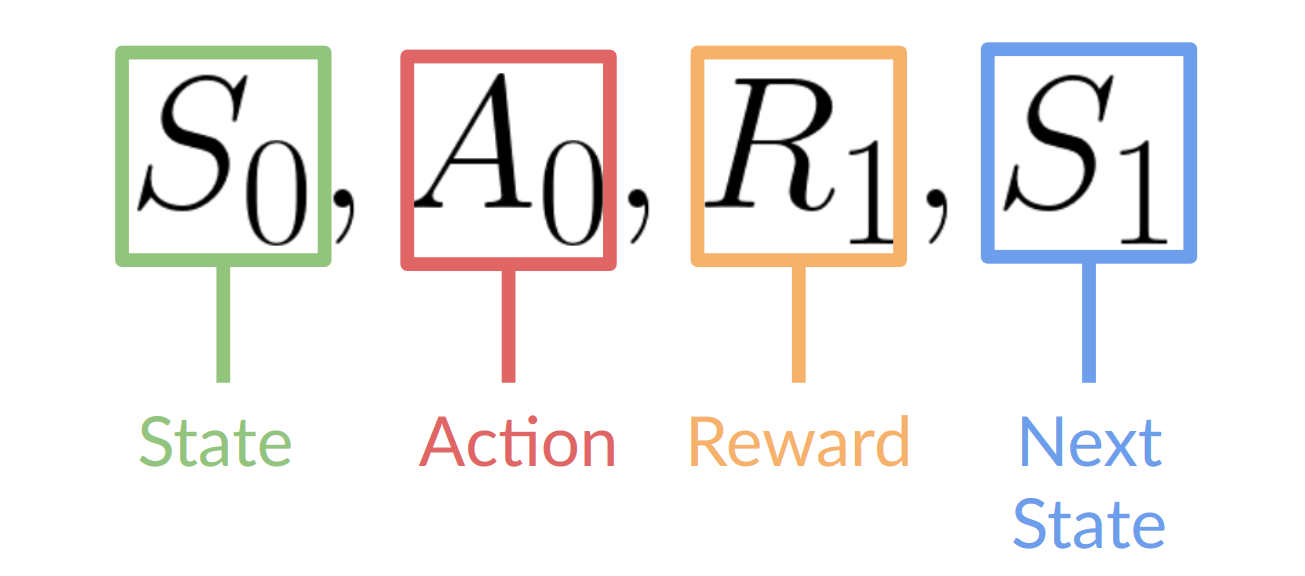
To recap:
@@ -75,70 +74,73 @@ To recap:
## Action Space [[action-space]]
-The Action space is the set of **all possible actions in an environment.**
+The Action space encompasses **all possible actions** an agent can take in an environment.
-The actions can come from a *discrete* or *continuous space*:
+Actions can belong to either a *discrete* or *continuous space*:
-- *Discrete space*: the number of possible actions is **finite**.
+- *Discrete space*: Here, the number of possible actions is **finite**.
-In Super Mario Bros, we have only 4 possible actions: left, right, up (jumping) and down (crouching).
-
+Super Mario Bros screenshot depicting the character's carrying out actions.
+/figcaption>
-Again, in Super Mario Bros, we have a finite set of actions since we have only 4 directions.
+For example, in Super Mario Bros, there are only four possible actions: left, right, up (jumping), and down (crouching). It is a **finite** set of actions.
-- *Continuous space*: the number of possible actions is **infinite**.
+- *Continuous space*: This involves an **infinite** number of possible actions.
-A Self Driving Car agent has an infinite number of possible actions since it can turn left 20°, 21,1°, 21,2°, honk, turn right 20°…
+Self Driving Car depiction of an agent with infinite possible actions.
+For instance, as seen in the above figure, a Self-Driving Car agent can perform a wide range of continuous actions, such as turning at different angles (left or right 20°, 21,1°, 21,2°) or honking.
+
+Understanding these action spaces is crucial when **choosing RL algorithms** in the future.
+
To recap:
-Taking this information into consideration is crucial because it will **have importance when choosing the RL algorithm in the future.**
+## Rewards and Discounting [[rewards]]
-## Rewards and the discounting [[rewards]]
+In RL, the **reward** is the agent's only feedback. It helps the agent determine whether an action was **good** or ***not**.
-The reward is fundamental in RL because it’s **the only feedback** for the agent. Thanks to it, our agent knows **if the action taken was good or not.**
-
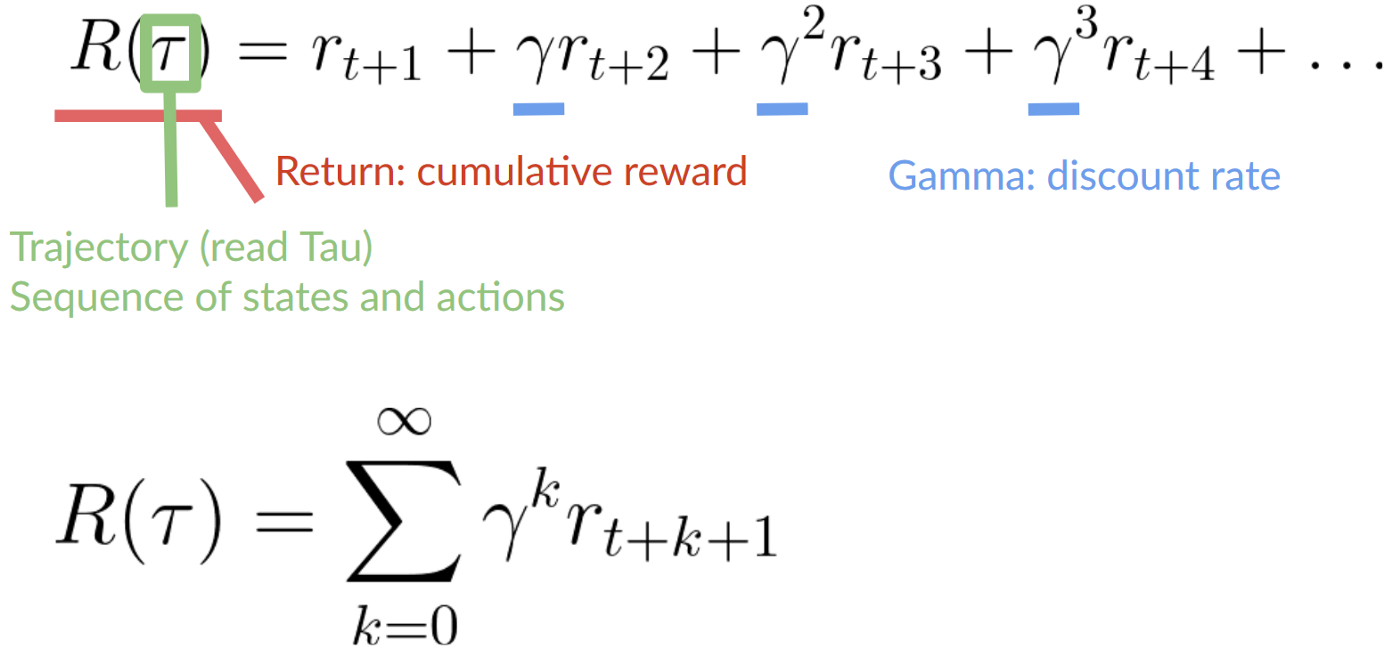
-The cumulative reward at each time step **t** can be written as:
+The cumulative reward at each time step **t** can be expressed as:
-The cumulative reward equals the sum of all rewards in the sequence.
+Depiction of how a cumulative reward equals the sum of all rewards in the sequence.
-Which is equivalent to:
+This is equivalent to:
-The cumulative reward = rt+1 (rt+k+1 = rt+0+1 = rt+1)+ rt+2 (rt+k+1 = rt+1+1 = rt+2) + ...
+Depiction of a cumulative reward = rt+1 (rt+k+1 = rt+0+1 = rt+1)+ rt+2 (rt+k+1 = rt+1+1 = rt+2) + ...
-However, in reality, **we can’t just add them like that.** The rewards that come sooner (at the beginning of the game) **are more likely to happen** since they are more predictable than the long-term future reward.
+However, we can't simply **add rewards** like this. Rewards that arrive early (at the game's start) are **more likely to occur** than long-term future rewards.
-Let’s say your agent is this tiny mouse that can move one tile each time step, and your opponent is the cat (that can move too). The mouse's goal is **to eat the maximum amount of cheese before being eaten by the cat.**
+Imagine your agent as a small mouse, trying to eat as much cheese as possible before being caught by the cat. The mouse can move one tile at a time, just like the cat. The mouse's objective is to eat the maximum amount of cheese (**maximum reward**) before being eaten by the cat (**discount**).
-As we can see in the diagram, **it’s more probable to eat the cheese near us than the cheese close to the cat** (the closer we are to the cat, the more dangerous it is).
+In this scenario, it's more probable to eat cheese nearby than cheese close to the cat (dangerous territory).
+
+As a result, rewards near the cat, even if larger, are more heavily discounted since we're unsure if we'll reach them.
-Consequently, **the reward near the cat, even if it is bigger (more cheese), will be more discounted** since we’re not really sure we’ll be able to eat it.
+To incorporate this discounting, we follow these steps:
-To discount the rewards, we proceed like this:
+1. We will be defining a discount rate as **gamma**. This rate value must be **between 0 and 1**. Typically, the values would fall between **0.95 and 0.99**.
+- A higher gamma value equals a **higher discount**, meaning that our agent would prioritize **long-term rewards**
+- On the other hand, a lower gamma value equals a **lower discount**, meaning that our agent would prioritize **short-term rewards**.
-1. We define a discount rate called gamma. **It must be between 0 and 1.** Most of the time between **0.95 and 0.99**.
-- The larger the gamma, the smaller the discount. This means our agent **cares more about the long-term reward.**
-- On the other hand, the smaller the gamma, the bigger the discount. This means our **agent cares more about the short term reward (the nearest cheese).**
+2. Each reward is **discounted** by the value of **gamma** to the exponent of the time step. As the time step increases, the cat would get closer to the mouse, meaning that the **future reward** would be **lower** and would be **less likely** to take place.
-2. Then, each reward will be discounted by gamma to the exponent of the time step. As the time step increases, the cat gets closer to us, **so the future reward is less and less likely to happen.**
+Our expected cumulative discounted reward would be:
-Our discounted expected cumulative reward is:
 -
- -- Our Agent receives **state \\(S_0\\)** from the **Environment** — we receive the first frame of our game (Environment).
-- Based on that **state \\(S_0\\),** the Agent takes **action \\(A_0\\)** — our Agent will move to the right.
-- The environment goes to a **new** **state \\(S_1\\)** — new frame.
-- The environment gives some **reward \\(R_1\\)** to the Agent — we’re not dead *(Positive Reward +1)*.
+- Our agent starts with an initial **state \\(S_0\\)** from the **Environment**; think of it as the first frame of our game.
+- Based on this **state \\(S_0\\)**, the agent makes an **action \\(A_0\\)**; in this case, our agent decides to move to the right.
+- This action leads to a **new state \\(S_1\\)**, representing the new frame.
+- The environment provides a **reward \\(R_1\\)**; luckily, we're still alive, resulting in a positive reward of +1.
-This RL loop outputs a sequence of **state, action, reward and next state.**
+This RL loop generates a sequence of **state, action, reward, and next state.**
-- Our Agent receives **state \\(S_0\\)** from the **Environment** — we receive the first frame of our game (Environment).
-- Based on that **state \\(S_0\\),** the Agent takes **action \\(A_0\\)** — our Agent will move to the right.
-- The environment goes to a **new** **state \\(S_1\\)** — new frame.
-- The environment gives some **reward \\(R_1\\)** to the Agent — we’re not dead *(Positive Reward +1)*.
+- Our agent starts with an initial **state \\(S_0\\)** from the **Environment**; think of it as the first frame of our game.
+- Based on this **state \\(S_0\\)**, the agent makes an **action \\(A_0\\)**; in this case, our agent decides to move to the right.
+- This action leads to a **new state \\(S_1\\)**, representing the new frame.
+- The environment provides a **reward \\(R_1\\)**; luckily, we're still alive, resulting in a positive reward of +1.
-This RL loop outputs a sequence of **state, action, reward and next state.**
+This RL loop generates a sequence of **state, action, reward, and next state.**
 -The agent's goal is to _maximize_ its cumulative reward, **called the expected return.**
-
-## The reward hypothesis: the central idea of Reinforcement Learning [[reward-hypothesis]]
+The agent's goal is to **maximize** its cumulative reward, which we call the **expected return.**
-⇒ Why is the goal of the agent to maximize the expected return?
+## The Reward Hypothesis: RL's Central Idea [[reward-hypothesis]]
-Because RL is based on the **reward hypothesis**, which is that all goals can be described as the **maximization of the expected return** (expected cumulative reward).
+⇒ Why does the agent aim to maximize expected return?
-That’s why in Reinforcement Learning, **to have the best behavior,** we aim to learn to take actions that **maximize the expected cumulative reward.**
+RL is built on the **reward hypothesis**, which means that all goals can be described as **maximizing expected return** (the expected cumulative reward).
+In RL, achieving the **best behavior** means learning to take actions that **maximize the expected cumulative reward.**
-## Markov Property [[markov-property]]
+## Understanding the Markov Property [[markov-property]]
-In papers, you’ll see that the RL process is called a **Markov Decision Process** (MDP).
+In academic circles, the RL process is often referred to as a **Markov Decision Process** (MDP).
-We’ll talk again about the Markov Property in the following units. But if you need to remember something today about it, it's this: the Markov Property implies that our agent needs **only the current state to decide** what action to take and **not the history of all the states and actions** they took before.
+We'll discuss the Markov Property in depth later, but for now, remember this: the Markov Property implies that our agent **only** needs the **current state** to decide its action, **not the entire history of states and actions** taken previously.
## Observations/States Space [[obs-space]]
-Observations/States are the **information our agent gets from the environment.** In the case of a video game, it can be a frame (a screenshot). In the case of the trading agent, it can be the value of a certain stock, etc.
-
-There is a differentiation to make between *observation* and *state*, however:
+Observations/States are the **information our agent receives from the environment**. In a video game, it could be a single frame, like a screenshot. In trading, it might be the value of a stock.
-- *State s*: is **a complete description of the state of the world** (there is no hidden information). In a fully observed environment.
+However, it's key to distinguish between *observation* and *state* as explained below:
+- *State s*: This is a **complete description of the world** with no hidden information.
-The agent's goal is to _maximize_ its cumulative reward, **called the expected return.**
-
-## The reward hypothesis: the central idea of Reinforcement Learning [[reward-hypothesis]]
+The agent's goal is to **maximize** its cumulative reward, which we call the **expected return.**
-⇒ Why is the goal of the agent to maximize the expected return?
+## The Reward Hypothesis: RL's Central Idea [[reward-hypothesis]]
-Because RL is based on the **reward hypothesis**, which is that all goals can be described as the **maximization of the expected return** (expected cumulative reward).
+⇒ Why does the agent aim to maximize expected return?
-That’s why in Reinforcement Learning, **to have the best behavior,** we aim to learn to take actions that **maximize the expected cumulative reward.**
+RL is built on the **reward hypothesis**, which means that all goals can be described as **maximizing expected return** (the expected cumulative reward).
+In RL, achieving the **best behavior** means learning to take actions that **maximize the expected cumulative reward.**
-## Markov Property [[markov-property]]
+## Understanding the Markov Property [[markov-property]]
-In papers, you’ll see that the RL process is called a **Markov Decision Process** (MDP).
+In academic circles, the RL process is often referred to as a **Markov Decision Process** (MDP).
-We’ll talk again about the Markov Property in the following units. But if you need to remember something today about it, it's this: the Markov Property implies that our agent needs **only the current state to decide** what action to take and **not the history of all the states and actions** they took before.
+We'll discuss the Markov Property in depth later, but for now, remember this: the Markov Property implies that our agent **only** needs the **current state** to decide its action, **not the entire history of states and actions** taken previously.
## Observations/States Space [[obs-space]]
-Observations/States are the **information our agent gets from the environment.** In the case of a video game, it can be a frame (a screenshot). In the case of the trading agent, it can be the value of a certain stock, etc.
-
-There is a differentiation to make between *observation* and *state*, however:
+Observations/States are the **information our agent receives from the environment**. In a video game, it could be a single frame, like a screenshot. In trading, it might be the value of a stock.
-- *State s*: is **a complete description of the state of the world** (there is no hidden information). In a fully observed environment.
+However, it's key to distinguish between *observation* and *state* as explained below:
+- *State s*: This is a **complete description of the world** with no hidden information.
 -
- -
- -
- -Taking this information into consideration is crucial because it will **have importance when choosing the RL algorithm in the future.**
+## Rewards and Discounting [[rewards]]
-## Rewards and the discounting [[rewards]]
+In RL, the **reward** is the agent's only feedback. It helps the agent determine whether an action was **good** or ***not**.
-The reward is fundamental in RL because it’s **the only feedback** for the agent. Thanks to it, our agent knows **if the action taken was good or not.**
-
-The cumulative reward at each time step **t** can be written as:
+The cumulative reward at each time step **t** can be expressed as:
-Taking this information into consideration is crucial because it will **have importance when choosing the RL algorithm in the future.**
+## Rewards and Discounting [[rewards]]
-## Rewards and the discounting [[rewards]]
+In RL, the **reward** is the agent's only feedback. It helps the agent determine whether an action was **good** or ***not**.
-The reward is fundamental in RL because it’s **the only feedback** for the agent. Thanks to it, our agent knows **if the action taken was good or not.**
-
-The cumulative reward at each time step **t** can be written as:
+The cumulative reward at each time step **t** can be expressed as:
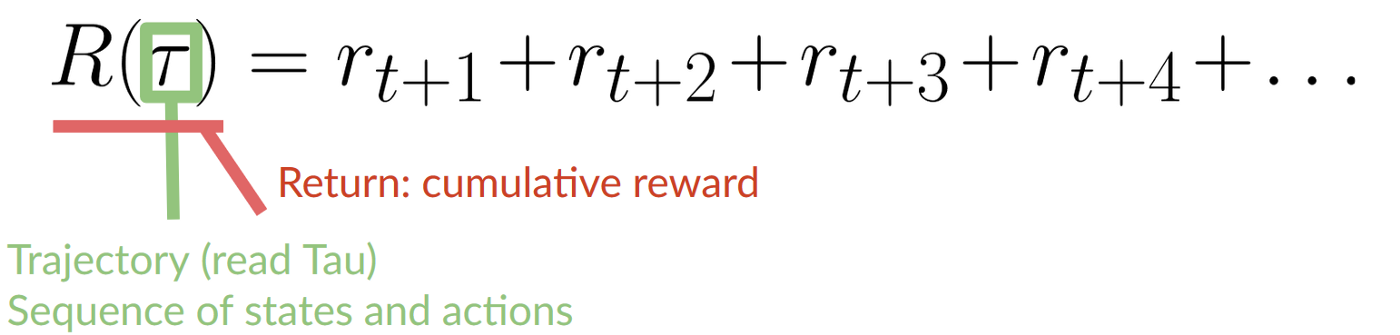 -
-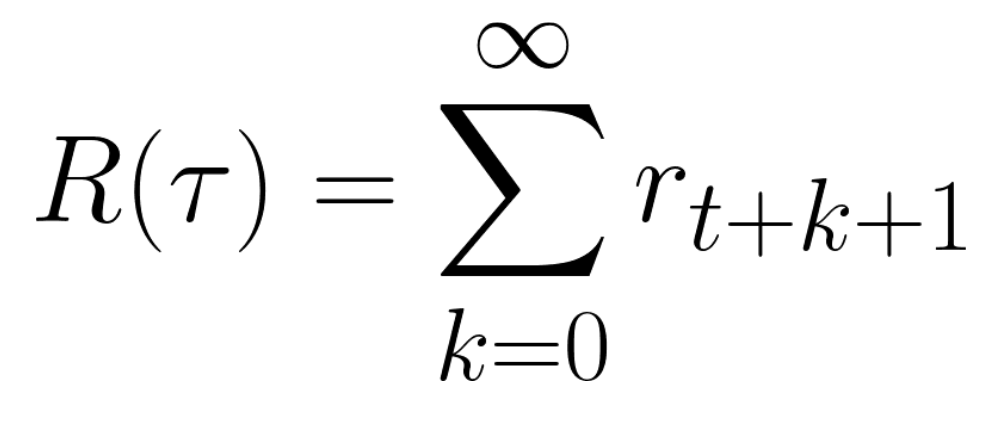 -
- -As we can see in the diagram, **it’s more probable to eat the cheese near us than the cheese close to the cat** (the closer we are to the cat, the more dangerous it is).
+In this scenario, it's more probable to eat cheese nearby than cheese close to the cat (dangerous territory).
+
+As a result, rewards near the cat, even if larger, are more heavily discounted since we're unsure if we'll reach them.
-Consequently, **the reward near the cat, even if it is bigger (more cheese), will be more discounted** since we’re not really sure we’ll be able to eat it.
+To incorporate this discounting, we follow these steps:
-To discount the rewards, we proceed like this:
+1. We will be defining a discount rate as **gamma**. This rate value must be **between 0 and 1**. Typically, the values would fall between **0.95 and 0.99**.
+- A higher gamma value equals a **higher discount**, meaning that our agent would prioritize **long-term rewards**
+- On the other hand, a lower gamma value equals a **lower discount**, meaning that our agent would prioritize **short-term rewards**.
-1. We define a discount rate called gamma. **It must be between 0 and 1.** Most of the time between **0.95 and 0.99**.
-- The larger the gamma, the smaller the discount. This means our agent **cares more about the long-term reward.**
-- On the other hand, the smaller the gamma, the bigger the discount. This means our **agent cares more about the short term reward (the nearest cheese).**
+2. Each reward is **discounted** by the value of **gamma** to the exponent of the time step. As the time step increases, the cat would get closer to the mouse, meaning that the **future reward** would be **lower** and would be **less likely** to take place.
-2. Then, each reward will be discounted by gamma to the exponent of the time step. As the time step increases, the cat gets closer to us, **so the future reward is less and less likely to happen.**
+Our expected cumulative discounted reward would be:
-Our discounted expected cumulative reward is:
-As we can see in the diagram, **it’s more probable to eat the cheese near us than the cheese close to the cat** (the closer we are to the cat, the more dangerous it is).
+In this scenario, it's more probable to eat cheese nearby than cheese close to the cat (dangerous territory).
+
+As a result, rewards near the cat, even if larger, are more heavily discounted since we're unsure if we'll reach them.
-Consequently, **the reward near the cat, even if it is bigger (more cheese), will be more discounted** since we’re not really sure we’ll be able to eat it.
+To incorporate this discounting, we follow these steps:
-To discount the rewards, we proceed like this:
+1. We will be defining a discount rate as **gamma**. This rate value must be **between 0 and 1**. Typically, the values would fall between **0.95 and 0.99**.
+- A higher gamma value equals a **higher discount**, meaning that our agent would prioritize **long-term rewards**
+- On the other hand, a lower gamma value equals a **lower discount**, meaning that our agent would prioritize **short-term rewards**.
-1. We define a discount rate called gamma. **It must be between 0 and 1.** Most of the time between **0.95 and 0.99**.
-- The larger the gamma, the smaller the discount. This means our agent **cares more about the long-term reward.**
-- On the other hand, the smaller the gamma, the bigger the discount. This means our **agent cares more about the short term reward (the nearest cheese).**
+2. Each reward is **discounted** by the value of **gamma** to the exponent of the time step. As the time step increases, the cat would get closer to the mouse, meaning that the **future reward** would be **lower** and would be **less likely** to take place.
-2. Then, each reward will be discounted by gamma to the exponent of the time step. As the time step increases, the cat gets closer to us, **so the future reward is less and less likely to happen.**
+Our expected cumulative discounted reward would be:
-Our discounted expected cumulative reward is: