Our implementation of a RAG is inspired from this Lang Chain tutorial, but we ensured that everything is running locally using ollama or Hugging Face-based LLMs.
Python dependencies that are required for this module are mostly based on langchain: langchain, langchain-chroma, langchain-huggingface, langchain-ollama, and langgraph.
To install them, run the following command:
pip3 install langchain langchain-chroma langchain-huggingface langchain-ollama langgraphRetrieval-Augmented Generation (RAG) is a framework that enhances generative models by providing additional and contextually relevant information to the LLMs context, in order to provide better responses to queries.
As highlighed in the following diagram, whenever we pose a question to a RAG agent, we perform a retrieval step that search in a database documents which likely contains information of the prompted question. Such content is fed, alongside with the question, to the LLM agent to provide a context-based response.
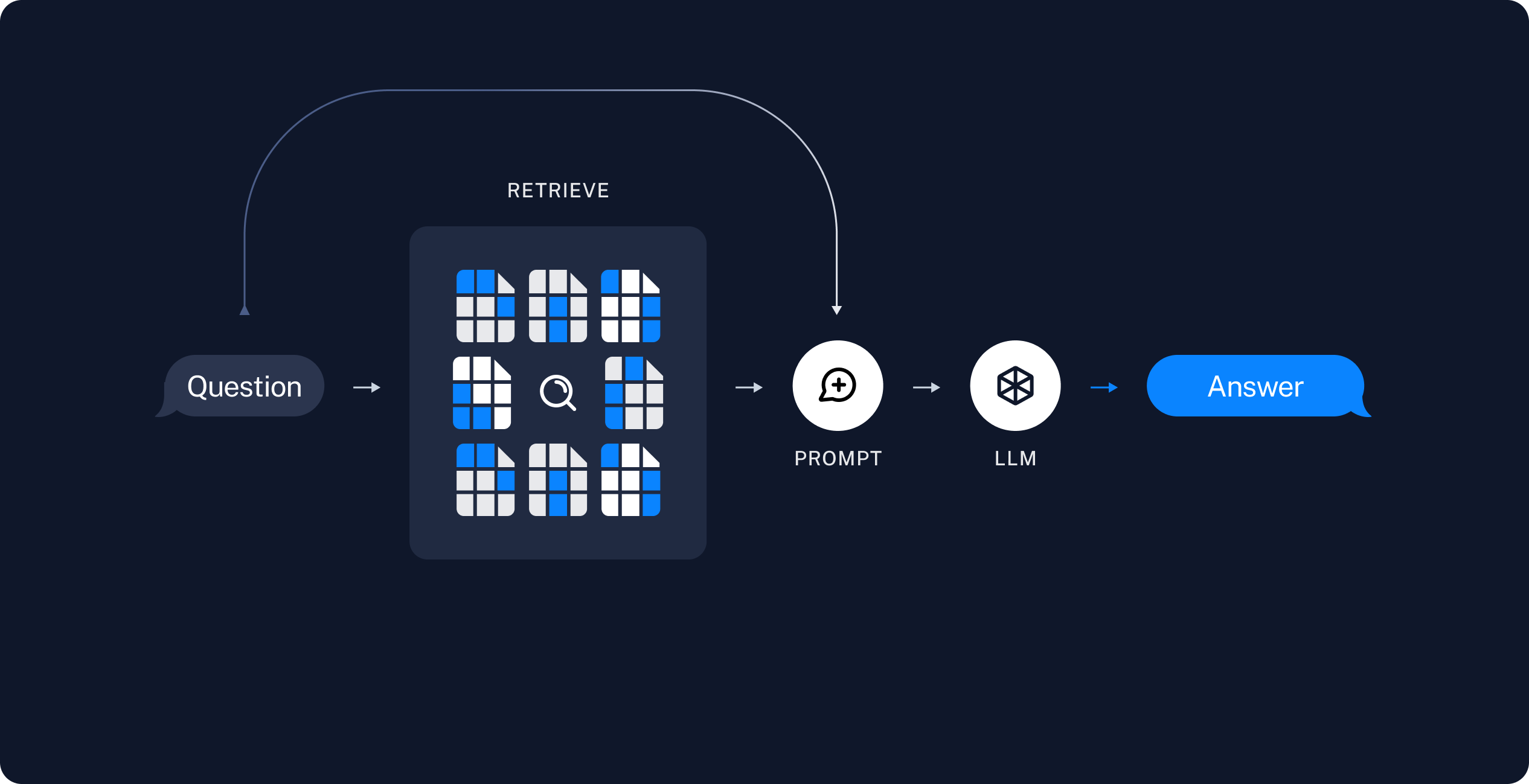
In practise, a RAG application encompasses the following steps:
- a document database (that can be generated offline) that contains relevant information that we may want to use to augment the LLMs response quality. Such databases are usually referred as vector stores;
- at runtime, when a question is prompted to the user, we firstly query the vector store for relevant documents. With this additional information, we can finally query the LLM with both the original question as well as the improved context.
To run the RAG application, simply call
python3 -m rag.rag