To understand the basics of DolphinNext, how to use DolphinNext for RNA-seq or any other Next generation Sequencing data analysis.
-
Build: Easily create new pipelines using a drag and drop interface. No need to write commands from scratch, instead reuse existing processes/modules to create new pipelines
-
Run: Execute pipelines in any host environment. Seamless Amazon Cloud and Google Cloud integration to create a cluster (instance), execute the pipeline and transfer the results to the storage services (S3 or GS).
-
Resume: A continuous checkpoint mechanism keeps track of each step of the running pipeline. Partially completed pipelines can be resumed at any stage even after parameter changes.
-
Improve: Revisioning system keeps track of pipelines and processes versions as well as their parameters. Edit, improve shared pipelines and customize them according to your needs.
-
Share: Share pipelines across different platforms. Isolate pipeline-specific dependencies in a container and easily replicate the methods in other clusters
First off, you need to enter DolphinNext web page: https://dolphinnext.umassmed.edu/ and login into your account by using UMASS username and password. If you have an issue about login, please let us know about it ([email protected]). We will set an account for you.
If you prefer, you can check our video to follow the step to run RNA-Seq pipeline.
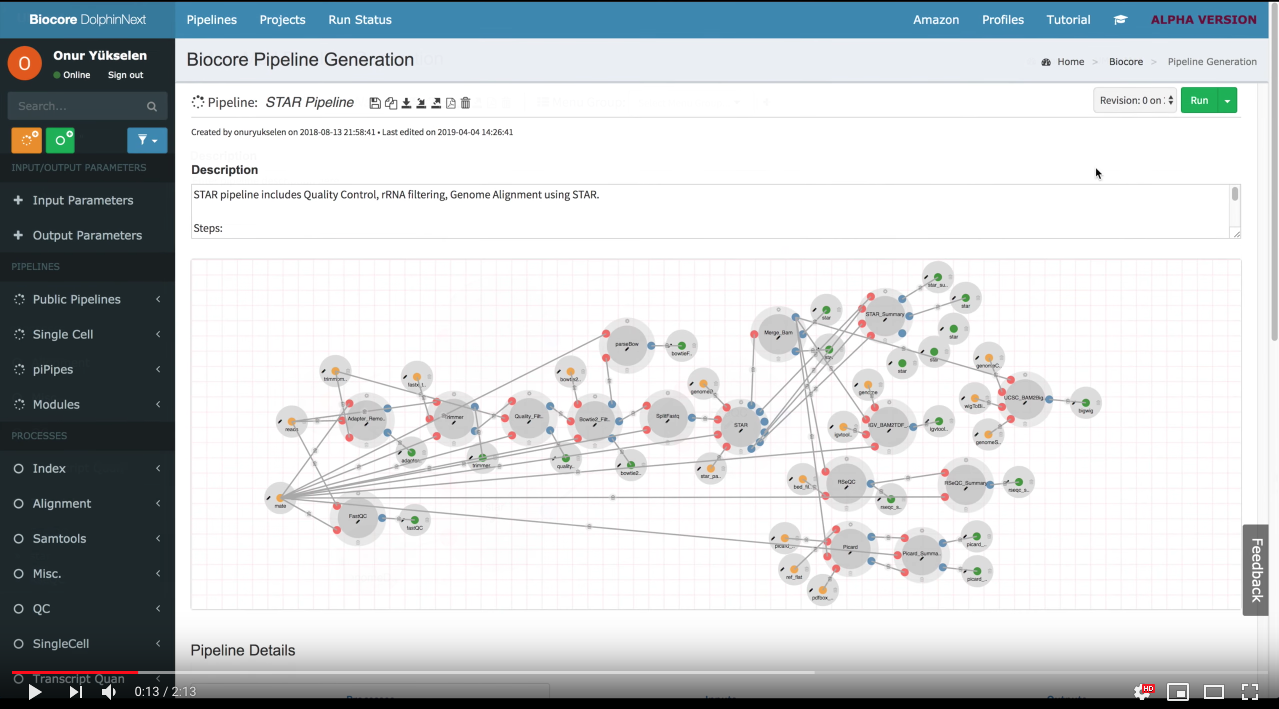
- The easiest way to run pipeline is using main page by clicking the Pipeline button at the top left of the screen. Now, you can investigate publicly available pipelines as shown at below. Select RNA-Seq Pipeline by clicking Learn More button.

- Once pipeline is loaded, you will notice "Run" button at the right top of the page.

- This button opens new window where you can create new project by clicking "Create a Project" button. After entering and saving the name of the project (e.g.
RNA-Seq test project), it will be added to your project list. Now you can select your project by clicking on the project as shown in the figure below.

-
Next, click "select project" button and proceed with entering run name (e.g.
Bootcamp RNA-Seq Run) which will be added to your project. Clicking "Save run" will redirect to "run page". -
Initially, in the header of the run page, orange
Waitingbutton will be shown. In order to initiate run, following data need to be entered:

A. Work Directory: Please enter /home/your_username/bootcamp/dolphinnext as work directory.
B. Run Environment: Please choose Run Environment for ghpcc06.umassrc.org
C. Inputs:
- reads: Choose paired reads found in your
/home/your_username/bootcamp/RNA-Seq/readsdirectory. For adding paired reads please check this video: Adding reads - mate: pair
- genome_build: mousetest_mm10
- run_STAR: yes
- run_RSEM: yes
- run_RSEM Module Countdata DE settings: Edit as follows:
- cols: control_rep1, control_rep2, control_rep3, exper_rep1, exper_rep2, exper_rep3
- conds: control, control, control, treat, treat, treat
- run_FastQC: yes
- run_RseQC: yes
- run_Sequential_Mapping: yes
- run_Sequential_Mapping Settings: Edit by clicking settings icon and add rRNA as shown at below:

- Once all requirements are satisfied,
Waitingbutton will turn in to greenready to runbutton as shown below. You can initiate your run by clickingrunbutton.

- Run RNA-Seq pipeline with GEO files. Run will take about 150 GB while running, please make use you enter your project space for the run.
- If you don't have enough space, you can only choose to download 1 file (
SRR1173457) as (control_rep1).
Here are settings of the pipeline:
- mate: pair
- genome_build: mouse_mm10_refseq
- run_RSEM: yes
- run_RSEM Module Countdata DE settings: Edit as follows: - cols:
control_rep1, control_rep2, control_rep3, exper_rep1, exper_rep2, exper_rep3- conds:control, control, control, treat, treat, treat

- run_STAR: no
- run_FastQC: yes
- run_RseQC: yes
- run_Sequential_Mapping: yes
- run_Sequential_Mapping Settings: Edit by clicking settings icon and add rRNA as shown at below:
- reads: - Please use NCBI/GEO Files menu and search following GEO id's:
SRR1173457, SRR1173458, SRR1173459, SRR1173478, SRR1173479, SRR1173480. - Please rename those files according to example below and save collection as "mouse_geo_dataset".
