You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
Add CPU allocation test for multiple GPU distributed run (#15829)
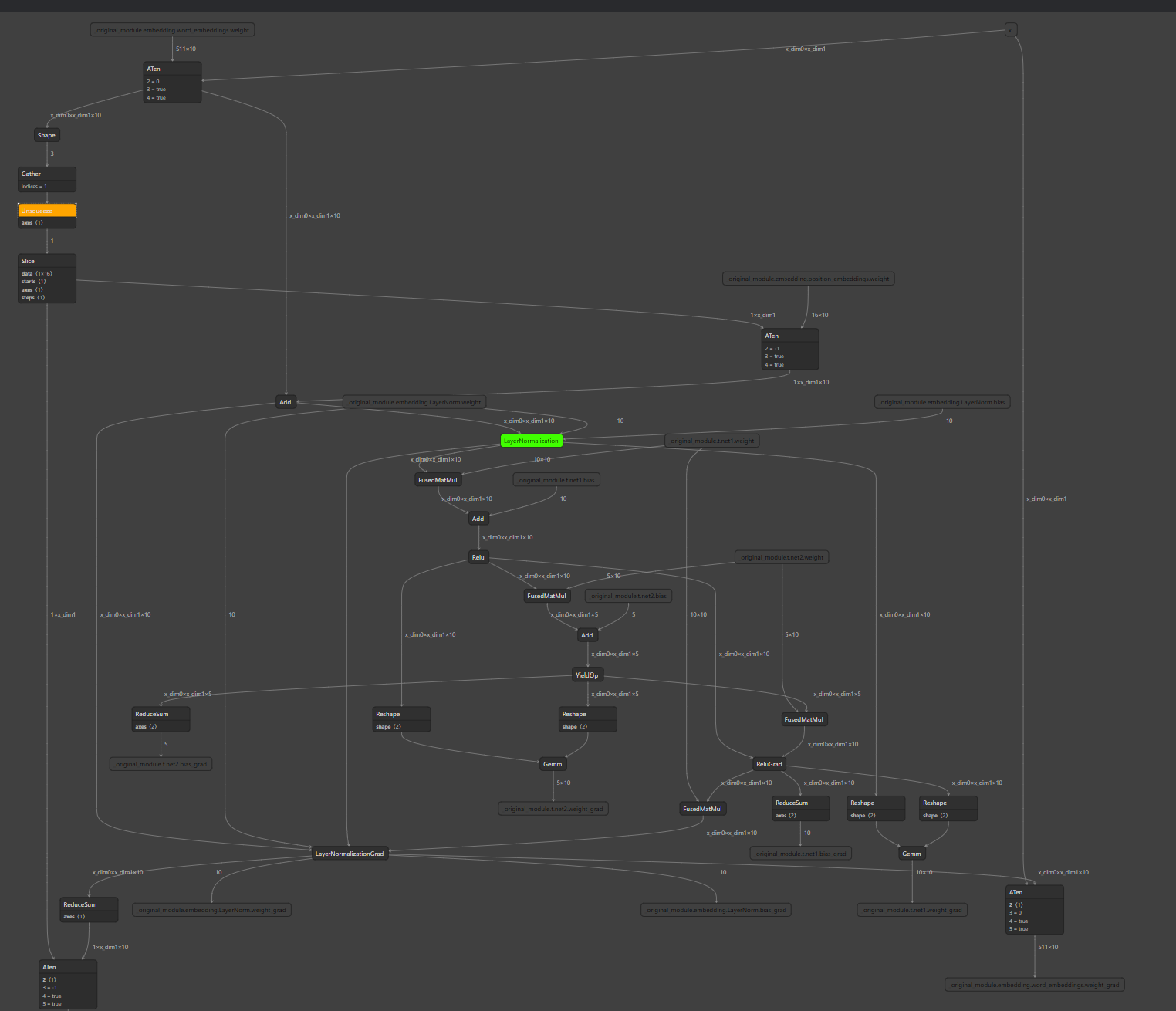
### Add CPU allocation test for non-CPU devices distributed run
When CUDA EP is enabled in distributed training, CPU memory is still
used for some node output. Early we have distributed run test coverage,
but don't cover the case when some of the node are using CPU devices for
storing tensor output. As a result, I recalled we hit regression twice
in the passing months:
- #14050
- #15823
So adding this test to avoid future regressions.
The test graph looks like this:
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
{kind=link}
0 commit comments