-
 +
+ 
 -| Models | Dataset | SWD | MS-SSIM | Config | Download |
-| :---------: | :------------: | :----------------------: | :-----: | :---------------------------------------------------------------------: | :-----------------------------------------------------------------------: |
-| DCGAN 64x64 | MNIST (64x64) | 21.16, 4.4, 8.41/11.32 | 0.1395 | [config](/configs/dcgan/dcgan_Glr4e-4_Dlr1e-4_1xb128-5kiters_mnist-64x64.py) | [model](https://download.openmmlab.com/mmgen/base_dcgan_mnist-64_b128x1_Glr4e-4_Dlr1e-4_5k_20210512_163926-207a1eaf.pth) \| [log](https://download.openmmlab.com//mmgen/dcgan/dcgan_mnist-64_b128x1_Glr4e-4_Dlr1e-4_5k_20210512_163926-207a1eaf.json) |
-| DCGAN 64x64 | CelebA-Cropped | 8.93,10.53,50.32/23.26 | 0.2899 | [config](/configs/dcgan/dcgan_1xb128-300kiters_celeba-cropped-64.py) | [model](https://download.openmmlab.com/mmgen/base_dcgan_celeba-cropped_64_b128x1_300kiter_20210408_161607-1f8a2277.pth) \| [log](https://download.openmmlab.com/mmgen/dcgan/base_dcgan_celeba-cropped_64_b128x1_300kiter_20210408_161607-1f8a2277.json) |
-| DCGAN 64x64 | LSUN-Bedroom | 42.79, 34.55, 98.46/58.6 | 0.2095 | [config](/configs/dcgan/dcgan_1xb128-5epoches_lsun-bedroom-64x64.py) | [model](https://download.openmmlab.com/mmgen/base_dcgan_lsun-bedroom_64_b128x1_5e_20210408_161713-117c498b.pth) \| [log](https://download.openmmlab.com/mmgen/dcgan/base_dcgan_lsun-bedroom_64_b128x1_5e_20210408_161713-117c498b.json) |
+| Models | Dataset | SWD | MS-SSIM | Config | Download |
+| :---------: | :------------: | :----------------------: | :-----: | :-------------------------------------------------------------: | :-------------------------------------------------------------------------------: |
+| DCGAN 64x64 | MNIST (64x64) | 21.16, 4.4, 8.41/11.32 | 0.1395 | [config](./dcgan_Glr4e-4_Dlr1e-4_1xb128-5kiters_mnist-64x64.py) | [model](https://download.openmmlab.com/mmediting/dcgan/dcgan_mnist-64_b128x1_Glr4e-4_Dlr1e-4_5k_20210512_163926-207a1eaf.pth) \| [log](https://download.openmmlab.com//mmgen/dcgan/dcgan_mnist-64_b128x1_Glr4e-4_Dlr1e-4_5k_20210512_163926-207a1eaf.json) |
+| DCGAN 64x64 | CelebA-Cropped | 8.93,10.53,50.32/23.26 | 0.2899 | [config](./dcgan_1xb128-300kiters_celeba-cropped-64.py) | [model](https://download.openmmlab.com/mmediting/dcgan/dcgan_celeba-cropped_64_b128x1_300kiter_20210408_161607-1f8a2277.pth) \| [log](https://download.openmmlab.com/mmediting/dcgan/dcgan_celeba-cropped_64_b128x1_300kiter_20210408_161607-1f8a2277.json) |
+| DCGAN 64x64 | LSUN-Bedroom | 42.79, 34.55, 98.46/58.6 | 0.2095 | [config](./dcgan_1xb128-5epoches_lsun-bedroom-64x64.py) | [model](https://download.openmmlab.com/mmediting/dcgan/dcgan_lsun-bedroom_64_b128x1_5e_20210408_161713-117c498b.pth) \| [log](https://download.openmmlab.com/mmediting/dcgan/dcgan_lsun-bedroom_64_b128x1_5e_20210408_161713-117c498b.json) |
## Citation
diff --git a/configs/dcgan/dcgan_1xb128-300kiters_celeba-cropped-64.py b/configs/dcgan/dcgan_1xb128-300kiters_celeba-cropped-64.py
index 95324ff8e4..2f1ab816e6 100644
--- a/configs/dcgan/dcgan_1xb128-300kiters_celeba-cropped-64.py
+++ b/configs/dcgan/dcgan_1xb128-300kiters_celeba-cropped-64.py
@@ -45,6 +45,8 @@
sample_model='orig',
image_shape=(3, 64, 64))
]
+# save best checkpoints
+default_hooks = dict(checkpoint=dict(save_best='swd/avg', rule='less'))
val_evaluator = dict(metrics=metrics)
test_evaluator = dict(metrics=metrics)
diff --git a/configs/dcgan/dcgan_1xb128-5epoches_lsun-bedroom-64x64.py b/configs/dcgan/dcgan_1xb128-5epoches_lsun-bedroom-64x64.py
index 79f4e56f5f..e4396a3462 100644
--- a/configs/dcgan/dcgan_1xb128-5epoches_lsun-bedroom-64x64.py
+++ b/configs/dcgan/dcgan_1xb128-5epoches_lsun-bedroom-64x64.py
@@ -44,6 +44,8 @@
sample_model='orig',
image_shape=(3, 64, 64))
]
+# save best checkpoints
+default_hooks = dict(checkpoint=dict(save_best='swd/avg', rule='less'))
val_evaluator = dict(metrics=metrics)
test_evaluator = dict(metrics=metrics)
diff --git a/configs/dcgan/dcgan_Glr4e-4_Dlr1e-4_1xb128-5kiters_mnist-64x64.py b/configs/dcgan/dcgan_Glr4e-4_Dlr1e-4_1xb128-5kiters_mnist-64x64.py
index 3eb1b4ad99..3625022ccf 100644
--- a/configs/dcgan/dcgan_Glr4e-4_Dlr1e-4_1xb128-5kiters_mnist-64x64.py
+++ b/configs/dcgan/dcgan_Glr4e-4_Dlr1e-4_1xb128-5kiters_mnist-64x64.py
@@ -5,47 +5,44 @@
]
# output single channel
-model = dict(generator=dict(out_channels=1), discriminator=dict(in_channels=1))
+model = dict(
+ data_preprocessor=dict(mean=[127.5], std=[127.5]),
+ generator=dict(out_channels=1),
+ discriminator=dict(in_channels=1))
# define dataset
# modify train_pipeline to load gray scale images
train_pipeline = [
- dict(
- type='LoadImageFromFile',
- key='img',
- io_backend='disk',
- color_type='grayscale'),
+ dict(type='LoadImageFromFile', key='img', color_type='grayscale'),
dict(type='Resize', scale=(64, 64)),
- dict(type='PackEditInputs', meta_keys=[])
+ dict(type='PackEditInputs')
]
# set ``batch_size``` and ``data_root```
batch_size = 128
data_root = 'data/mnist_64/train'
train_dataloader = dict(
- batch_size=batch_size, dataset=dict(data_root=data_root))
+ batch_size=batch_size,
+ dataset=dict(data_root=data_root, pipeline=train_pipeline))
-val_dataloader = dict(batch_size=batch_size, dataset=dict(data_root=data_root))
+val_dataloader = dict(
+ batch_size=batch_size,
+ dataset=dict(data_root=data_root, pipeline=train_pipeline))
test_dataloader = dict(
- batch_size=batch_size, dataset=dict(data_root=data_root))
-
-default_hooks = dict(
- checkpoint=dict(
- interval=500,
- save_best=['swd/avg', 'ms-ssim/avg'],
- rule=['less', 'greater']))
+ batch_size=batch_size,
+ dataset=dict(data_root=data_root, pipeline=train_pipeline))
# VIS_HOOK
custom_hooks = [
dict(
type='GenVisualizationHook',
- interval=10000,
+ interval=500,
fixed_input=True,
vis_kwargs_list=dict(type='GAN', name='fake_img'))
]
-train_cfg = dict(max_iters=5000)
+train_cfg = dict(max_iters=5000, val_interval=500)
# METRICS
metrics = [
@@ -55,10 +52,13 @@
dict(
type='SWD',
prefix='swd',
- fake_nums=16384,
+ fake_nums=-1,
sample_model='orig',
- image_shape=(3, 64, 64))
+ image_shape=(1, 64, 64))
]
+# save best checkpoints
+default_hooks = dict(
+ checkpoint=dict(interval=500, save_best='swd/avg', rule='less'))
val_evaluator = dict(metrics=metrics)
test_evaluator = dict(metrics=metrics)
diff --git a/configs/dcgan/metafile.yml b/configs/dcgan/metafile.yml
index 62d38230c5..2d201ff980 100644
--- a/configs/dcgan/metafile.yml
+++ b/configs/dcgan/metafile.yml
@@ -8,6 +8,9 @@ Collections:
Paper:
- https://arxiv.org/abs/1511.06434
README: configs/dcgan/README.md
+ Task:
+ - unconditional gans
+ Year: 2016
Models:
- Config: configs/dcgan/dcgan_Glr4e-4_Dlr1e-4_1xb128-5kiters_mnist-64x64.py
In Collection: Unsupervised Representation Learning with Deep Convolutional Generative
@@ -20,7 +23,7 @@ Models:
Metrics:
MS-SSIM: 0.1395
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/base_dcgan_mnist-64_b128x1_Glr4e-4_Dlr1e-4_5k_20210512_163926-207a1eaf.pth
+ Weights: https://download.openmmlab.com/mmediting/dcgan/dcgan_mnist-64_b128x1_Glr4e-4_Dlr1e-4_5k_20210512_163926-207a1eaf.pth
- Config: configs/dcgan/dcgan_1xb128-300kiters_celeba-cropped-64.py
In Collection: Unsupervised Representation Learning with Deep Convolutional Generative
Adversarial Networks
@@ -32,7 +35,7 @@ Models:
Metrics:
MS-SSIM: 0.2899
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/base_dcgan_celeba-cropped_64_b128x1_300kiter_20210408_161607-1f8a2277.pth
+ Weights: https://download.openmmlab.com/mmediting/dcgan/dcgan_celeba-cropped_64_b128x1_300kiter_20210408_161607-1f8a2277.pth
- Config: configs/dcgan/dcgan_1xb128-5epoches_lsun-bedroom-64x64.py
In Collection: Unsupervised Representation Learning with Deep Convolutional Generative
Adversarial Networks
@@ -44,4 +47,4 @@ Models:
Metrics:
MS-SSIM: 0.2095
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/base_dcgan_lsun-bedroom_64_b128x1_5e_20210408_161713-117c498b.pth
+ Weights: https://download.openmmlab.com/mmediting/dcgan/dcgan_lsun-bedroom_64_b128x1_5e_20210408_161713-117c498b.pth
diff --git a/configs/deepfillv1/README.md b/configs/deepfillv1/README.md
index d68c28523c..a020f898ea 100644
--- a/configs/deepfillv1/README.md
+++ b/configs/deepfillv1/README.md
@@ -22,15 +22,15 @@ Recent deep learning based approaches have shown promising results for the chall
**Places365-Challenge**
-| Method | Mask Type | Resolution | Train Iters | Test Set | l1 error | PSNR | SSIM | GPU Info | Download |
-| :-------------------------------------------------------------: | :---------: | :--------: | :---------: | :-----------: | :------: | :----: | :---: | :------: | :---------------------------------------------------------------: |
-| [DeepFillv1](/configs/deepfillv1/deepfillv1_8xb2_places-256x256.py) | square bbox | 256x256 | 3500k | Places365-val | 11.019 | 23.429 | 0.862 | 8 | [model](https://download.openmmlab.com/mmediting/inpainting/deepfillv1/deepfillv1_256x256_8x2_places_20200619-c00a0e21.pth) \| [log](https://download.openmmlab.com/mmediting/inpainting/deepfillv1/deepfillv1_256x256_8x2_places_20200619-c00a0e21.log.json) |
+| Method | Mask Type | Resolution | Train Iters | Test Set | l1 error | PSNR | SSIM | GPU Info | Download |
+| :-----------------------------------------------: | :---------: | :--------: | :---------: | :-----------: | :------: | :----: | :---: | :------: | :-----------------------------------------------------------------------------: |
+| [DeepFillv1](./deepfillv1_8xb2_places-256x256.py) | square bbox | 256x256 | 3500k | Places365-val | 11.019 | 23.429 | 0.862 | 8 | [model](https://download.openmmlab.com/mmediting/inpainting/deepfillv1/deepfillv1_256x256_8x2_places_20200619-c00a0e21.pth) \| [log](https://download.openmmlab.com/mmediting/inpainting/deepfillv1/deepfillv1_256x256_8x2_places_20200619-c00a0e21.log.json) |
**CelebA-HQ**
-| Method | Mask Type | Resolution | Train Iters | Test Set | l1 error | PSNR | SSIM | GPU Info | Download |
-| :--------------------------------------------------------------: | :---------: | :--------: | :---------: | :--------: | :------: | :----: | :---: | :------: | :-----------------------------------------------------------------: |
-| [DeepFillv1](/configs/deepfillv1/deepfillv1_4xb4_celeba-256x256.py) | square bbox | 256x256 | 1500k | CelebA-val | 6.677 | 26.878 | 0.911 | 4 | [model](https://download.openmmlab.com/mmediting/inpainting/deepfillv1/deepfillv1_256x256_4x4_celeba_20200619-dd51a855.pth) \| [log](https://download.openmmlab.com/mmediting/inpainting/deepfillv1/deepfillv1_256x256_4x4_celeba_20200619-dd51a855.log.json) |
+| Method | Mask Type | Resolution | Train Iters | Test Set | l1 error | PSNR | SSIM | GPU Info | Download |
+| :-----------------------------------------------: | :---------: | :--------: | :---------: | :--------: | :------: | :----: | :---: | :------: | :--------------------------------------------------------------------------------: |
+| [DeepFillv1](./deepfillv1_4xb4_celeba-256x256.py) | square bbox | 256x256 | 1500k | CelebA-val | 6.677 | 26.878 | 0.911 | 4 | [model](https://download.openmmlab.com/mmediting/inpainting/deepfillv1/deepfillv1_256x256_4x4_celeba_20200619-dd51a855.pth) \| [log](https://download.openmmlab.com/mmediting/inpainting/deepfillv1/deepfillv1_256x256_4x4_celeba_20200619-dd51a855.log.json) |
## Quick Start
diff --git a/configs/deepfillv1/README_zh-CN.md b/configs/deepfillv1/README_zh-CN.md
index 273a29ac0a..db7625e8ba 100644
--- a/configs/deepfillv1/README_zh-CN.md
+++ b/configs/deepfillv1/README_zh-CN.md
@@ -23,15 +23,15 @@
**Places365-Challenge**
-| 算法 | 掩膜类型 | 分辨率 | 训练集容量 | 测试集 | l1 损失 | PSNR | SSIM | GPU 信息 | 下载 |
-| :----------------------------------------------------------------: | :---------: | :-----: | :--------: | :-----------: | :-----: | :----: | :---: | :------: | :-----------------------------------------------------------------: |
-| [DeepFillv1](/configs/deepfillv1/deepfillv1_8xb2_places-256x256.py) | square bbox | 256x256 | 3500k | Places365-val | 11.019 | 23.429 | 0.862 | 8 | [模型](https://download.openmmlab.com/mmediting/inpainting/deepfillv1/deepfillv1_256x256_8x2_places_20200619-c00a0e21.pth) \| [日志](https://download.openmmlab.com/mmediting/inpainting/deepfillv1/deepfillv1_256x256_8x2_places_20200619-c00a0e21.log.json) |
+| 算法 | 掩膜类型 | 分辨率 | 训练集容量 | 测试集 | l1 损失 | PSNR | SSIM | GPU 信息 | 下载 |
+| :-----------------------------------------------: | :---------: | :-----: | :--------: | :-----------: | :-----: | :----: | :---: | :------: | :----------------------------------------------------------------------------------: |
+| [DeepFillv1](./deepfillv1_8xb2_places-256x256.py) | square bbox | 256x256 | 3500k | Places365-val | 11.019 | 23.429 | 0.862 | 8 | [模型](https://download.openmmlab.com/mmediting/inpainting/deepfillv1/deepfillv1_256x256_8x2_places_20200619-c00a0e21.pth) \| [日志](https://download.openmmlab.com/mmediting/inpainting/deepfillv1/deepfillv1_256x256_8x2_places_20200619-c00a0e21.log.json) |
**CelebA-HQ**
-| 算法 | 掩膜类型 | 分辨率 | 训练集容量 | 测试集 | l1 损失 | PSNR | SSIM | GPU 信息 | 下载 |
-| :-----------------------------------------------------------------: | :---------: | :-----: | :--------: | :--------: | :-----: | :----: | :---: | :------: | :-------------------------------------------------------------------: |
-| [DeepFillv1](/configs/deepfillv1/deepfillv1_4xb4_celeba-256x256.py) | square bbox | 256x256 | 1500k | CelebA-val | 6.677 | 26.878 | 0.911 | 4 | [模型](https://download.openmmlab.com/mmediting/inpainting/deepfillv1/deepfillv1_256x256_4x4_celeba_20200619-dd51a855.pth) \| [日志](https://download.openmmlab.com/mmediting/inpainting/deepfillv1/deepfillv1_256x256_4x4_celeba_20200619-dd51a855.log.json) |
+| 算法 | 掩膜类型 | 分辨率 | 训练集容量 | 测试集 | l1 损失 | PSNR | SSIM | GPU 信息 | 下载 |
+| :-----------------------------------------------: | :---------: | :-----: | :--------: | :--------: | :-----: | :----: | :---: | :------: | :-------------------------------------------------------------------------------------: |
+| [DeepFillv1](./deepfillv1_4xb4_celeba-256x256.py) | square bbox | 256x256 | 1500k | CelebA-val | 6.677 | 26.878 | 0.911 | 4 | [模型](https://download.openmmlab.com/mmediting/inpainting/deepfillv1/deepfillv1_256x256_4x4_celeba_20200619-dd51a855.pth) \| [日志](https://download.openmmlab.com/mmediting/inpainting/deepfillv1/deepfillv1_256x256_4x4_celeba_20200619-dd51a855.log.json) |
## 快速开始
diff --git a/configs/deepfillv1/metafile.yml b/configs/deepfillv1/metafile.yml
index 968b448d38..c8a83d22a4 100644
--- a/configs/deepfillv1/metafile.yml
+++ b/configs/deepfillv1/metafile.yml
@@ -6,6 +6,9 @@ Collections:
Paper:
- https://arxiv.org/abs/1801.07892
README: configs/deepfillv1/README.md
+ Task:
+ - inpainting
+ Year: 2018
Models:
- Config: configs/deepfillv1/deepfillv1_8xb2_places-256x256.py
In Collection: DeepFillv1
diff --git a/configs/deepfillv2/README.md b/configs/deepfillv2/README.md
index dce7150cb5..096bb2f16c 100644
--- a/configs/deepfillv2/README.md
+++ b/configs/deepfillv2/README.md
@@ -22,15 +22,15 @@ We present a generative image inpainting system to complete images with free-for
**Places365-Challenge**
-| Method | Mask Type | Resolution | Train Iters | Test Set | l1 error | PSNR | SSIM | GPU Info | Download |
-| :--------------------------------------------------------------: | :-------: | :--------: | :---------: | :-----------: | :------: | :----: | :---: | :------: | :----------------------------------------------------------------: |
-| [DeepFillv2](/configs/deepfillv2/deepfillv2_8xb2_places-256x256.py) | free-form | 256x256 | 100k | Places365-val | 8.635 | 22.398 | 0.815 | 8 | [model](https://download.openmmlab.com/mmediting/inpainting/deepfillv2/deepfillv2_256x256_8x2_places_20200619-10d15793.pth) \| [log](https://download.openmmlab.com/mmediting/inpainting/deepfillv2/deepfillv2_256x256_8x2_places_20200619-10d15793.log.json) |
+| Method | Mask Type | Resolution | Train Iters | Test Set | l1 error | PSNR | SSIM | GPU Info | Download |
+| :-----------------------------------------------: | :-------: | :--------: | :---------: | :-----------: | :------: | :----: | :---: | :------: | :-------------------------------------------------------------------------------: |
+| [DeepFillv2](./deepfillv2_8xb2_places-256x256.py) | free-form | 256x256 | 100k | Places365-val | 8.635 | 22.398 | 0.815 | 8 | [model](https://download.openmmlab.com/mmediting/inpainting/deepfillv2/deepfillv2_256x256_8x2_places_20200619-10d15793.pth) \| [log](https://download.openmmlab.com/mmediting/inpainting/deepfillv2/deepfillv2_256x256_8x2_places_20200619-10d15793.log.json) |
**CelebA-HQ**
-| Method | Mask Type | Resolution | Train Iters | Test Set | l1 error | PSNR | SSIM | GPU Info | Download |
-| :---------------------------------------------------------------: | :-------: | :--------: | :---------: | :--------: | :------: | :----: | :---: | :------: | :------------------------------------------------------------------: |
-| [DeepFillv2](/configs/deepfillv2/deepfillv2_8xb2_celeba-256x256.py) | free-form | 256x256 | 20k | CelebA-val | 5.411 | 25.721 | 0.871 | 8 | [model](https://download.openmmlab.com/mmediting/inpainting/deepfillv2/deepfillv2_256x256_8x2_celeba_20200619-c96e5f12.pth) \| [log](https://download.openmmlab.com/mmediting/inpainting/deepfillv2/deepfillv2_256x256_8x2_celeba_20200619-c96e5f12.log.json) |
+| Method | Mask Type | Resolution | Train Iters | Test Set | l1 error | PSNR | SSIM | GPU Info | Download |
+| :-----------------------------------------------: | :-------: | :--------: | :---------: | :--------: | :------: | :----: | :---: | :------: | :----------------------------------------------------------------------------------: |
+| [DeepFillv2](./deepfillv2_8xb2_celeba-256x256.py) | free-form | 256x256 | 20k | CelebA-val | 5.411 | 25.721 | 0.871 | 8 | [model](https://download.openmmlab.com/mmediting/inpainting/deepfillv2/deepfillv2_256x256_8x2_celeba_20200619-c96e5f12.pth) \| [log](https://download.openmmlab.com/mmediting/inpainting/deepfillv2/deepfillv2_256x256_8x2_celeba_20200619-c96e5f12.log.json) |
## Quick Start
diff --git a/configs/deepfillv2/README_zh-CN.md b/configs/deepfillv2/README_zh-CN.md
index 3c71037056..eaa1a31f4a 100644
--- a/configs/deepfillv2/README_zh-CN.md
+++ b/configs/deepfillv2/README_zh-CN.md
@@ -23,15 +23,15 @@
**Places365-Challenge**
-| 算法 | 掩膜类型 | 分辨率 | 训练集容量 | 测试集 | l1 损失 | PSNR | SSIM | GPU 信息 | 下载 |
-| :-----------------------------------------------------------------: | :-------: | :-----: | :--------: | :-----------: | :-----: | :----: | :---: | :------: | :------------------------------------------------------------------: |
-| [DeepFillv2](/configs/deepfillv2/deepfillv2_8xb2_places-256x256.py) | free-form | 256x256 | 100k | Places365-val | 8.635 | 22.398 | 0.815 | 8 | [模型](https://download.openmmlab.com/mmediting/inpainting/deepfillv2/deepfillv2_256x256_8x2_places_20200619-10d15793.pth) \| [日志](https://download.openmmlab.com/mmediting/inpainting/deepfillv2/deepfillv2_256x256_8x2_places_20200619-10d15793.log.json) |
+| 算法 | 掩膜类型 | 分辨率 | 训练集容量 | 测试集 | l1 损失 | PSNR | SSIM | GPU 信息 | 下载 |
+| :-----------------------------------------------: | :-------: | :-----: | :--------: | :-----------: | :-----: | :----: | :---: | :------: | :------------------------------------------------------------------------------------: |
+| [DeepFillv2](./deepfillv2_8xb2_places-256x256.py) | free-form | 256x256 | 100k | Places365-val | 8.635 | 22.398 | 0.815 | 8 | [模型](https://download.openmmlab.com/mmediting/inpainting/deepfillv2/deepfillv2_256x256_8x2_places_20200619-10d15793.pth) \| [日志](https://download.openmmlab.com/mmediting/inpainting/deepfillv2/deepfillv2_256x256_8x2_places_20200619-10d15793.log.json) |
**CelebA-HQ**
-| 算法 | 掩膜类型 | 分辨率 | 训练集容量 | 测试集 | l1 损失 | PSNR | SSIM | GPU 信息 | 下载 |
-| :-----------------------------------------------------------------: | :-------: | :-----: | :--------: | :--------: | :-----: | :----: | :---: | :------: | :---------------------------------------------------------------------: |
-| [DeepFillv2](/configs/deepfillv2/deepfillv2_8xb2_celeba-256x256.py) | free-form | 256x256 | 20k | CelebA-val | 5.411 | 25.721 | 0.871 | 8 | [模型](https://download.openmmlab.com/mmediting/inpainting/deepfillv2/deepfillv2_256x256_8x2_celeba_20200619-c96e5f12.pth) \| [日志](https://download.openmmlab.com/mmediting/inpainting/deepfillv2/deepfillv2_256x256_8x2_celeba_20200619-c96e5f12.log.json) |
+| 算法 | 掩膜类型 | 分辨率 | 训练集容量 | 测试集 | l1 损失 | PSNR | SSIM | GPU 信息 | 下载 |
+| :-----------------------------------------------: | :-------: | :-----: | :--------: | :--------: | :-----: | :----: | :---: | :------: | :---------------------------------------------------------------------------------------: |
+| [DeepFillv2](./deepfillv2_8xb2_celeba-256x256.py) | free-form | 256x256 | 20k | CelebA-val | 5.411 | 25.721 | 0.871 | 8 | [模型](https://download.openmmlab.com/mmediting/inpainting/deepfillv2/deepfillv2_256x256_8x2_celeba_20200619-c96e5f12.pth) \| [日志](https://download.openmmlab.com/mmediting/inpainting/deepfillv2/deepfillv2_256x256_8x2_celeba_20200619-c96e5f12.log.json) |
## 快速开始
diff --git a/configs/deepfillv2/metafile.yml b/configs/deepfillv2/metafile.yml
index d84dab7739..d0a57379e7 100644
--- a/configs/deepfillv2/metafile.yml
+++ b/configs/deepfillv2/metafile.yml
@@ -6,6 +6,9 @@ Collections:
Paper:
- https://arxiv.org/abs/1806.03589
README: configs/deepfillv2/README.md
+ Task:
+ - inpainting
+ Year: 2019
Models:
- Config: configs/deepfillv2/deepfillv2_8xb2_places-256x256.py
In Collection: DeepFillv2
diff --git a/configs/dic/README.md b/configs/dic/README.md
index 69b808f74b..90215ae6b8 100644
--- a/configs/dic/README.md
+++ b/configs/dic/README.md
@@ -27,10 +27,10 @@ In the log data of `dic_gan_x8c48b6_g4_150k_CelebAHQ`, DICGAN is verified on the
`GPU Info`: GPU information during training.
-| Method | scale | PSNR | SSIM | GPU Info | Download |
-| :------------------------------------------------------------------------------: | :---: | :-----: | :----: | :-----------------: | :---------------------------------------------------------------------------------: |
-| [dic_x8c48b6_g4_150k_CelebAHQ](/configs/dic/dic_x8c48b6_4xb2-150k_celeba-hq.py) | x8 | 25.2319 | 0.7422 | 4 (Tesla PG503-216) | [model](https://download.openmmlab.com/mmediting/restorers/dic/dic_x8c48b6_g4_150k_CelebAHQ_20210611-5d3439ca.pth) \| [log](https://download.openmmlab.com/mmediting/restorers/dic/dic_x8c48b6_g4_150k_CelebAHQ_20210611-5d3439ca.log.json) |
-| [dic_gan_x8c48b6_g4_500k_CelebAHQ](/configs/dic/dic_gan-x8c48b6_4xb2-500k_celeba-hq.py) | x8 | 23.6241 | 0.6721 | 4 (Tesla PG503-216) | [model](https://download.openmmlab.com/mmediting/restorers/dic/dic_gan_x8c48b6_g4_500k_CelebAHQ_20210625-3b89a358.pth) \| [log](https://download.openmmlab.com/mmediting/restorers/dic/dic_gan_x8c48b6_g4_500k_CelebAHQ_20210625-3b89a358.log.json) |
+| Method | scale | PSNR | SSIM | GPU Info | Download |
+| :--------------------------------------------------------------------------: | :---: | :-----: | :----: | :-----------------: | :-------------------------------------------------------------------------------------: |
+| [dic_x8c48b6_g4_150k_CelebAHQ](./dic_x8c48b6_4xb2-150k_celeba-hq.py) | x8 | 25.2319 | 0.7422 | 4 (Tesla PG503-216) | [model](https://download.openmmlab.com/mmediting/restorers/dic/dic_x8c48b6_g4_150k_CelebAHQ_20210611-5d3439ca.pth) \| [log](https://download.openmmlab.com/mmediting/restorers/dic/dic_x8c48b6_g4_150k_CelebAHQ_20210611-5d3439ca.log.json) |
+| [dic_gan_x8c48b6_g4_500k_CelebAHQ](./dic_gan-x8c48b6_4xb2-500k_celeba-hq.py) | x8 | 23.6241 | 0.6721 | 4 (Tesla PG503-216) | [model](https://download.openmmlab.com/mmediting/restorers/dic/dic_gan_x8c48b6_g4_500k_CelebAHQ_20210625-3b89a358.pth) \| [log](https://download.openmmlab.com/mmediting/restorers/dic/dic_gan_x8c48b6_g4_500k_CelebAHQ_20210625-3b89a358.log.json) |
## Quick Start
diff --git a/configs/dic/README_zh-CN.md b/configs/dic/README_zh-CN.md
index 8333162f54..74ef56d31b 100644
--- a/configs/dic/README_zh-CN.md
+++ b/configs/dic/README_zh-CN.md
@@ -29,10 +29,10 @@
`GPU 信息`: 训练过程中的 GPU 信息.
-| 算法 | scale | CelebA-HQ | GPU 信息 | 下载 |
-| :------------------------------------------------------------------------------: | :---: | :--------------: | :-----------------: | :------------------------------------------------------------------------------: |
-| [dic_x8c48b6_g4_150k_CelebAHQ](/configs/dic/dic_x8c48b6_4xb2-150k_celeba-hq.py) | x8 | 25.2319 / 0.7422 | 4 (Tesla PG503-216) | [模型](https://download.openmmlab.com/mmediting/restorers/dic/dic_x8c48b6_g4_150k_CelebAHQ_20210611-5d3439ca.pth) \| [日志](https://download.openmmlab.com/mmediting/restorers/dic/dic_x8c48b6_g4_150k_CelebAHQ_20210611-5d3439ca.log.json) |
-| [dic_gan_x8c48b6_g4_500k_CelebAHQ](/configs/dic/dic_gan-x8c48b6_4xb2-500k_celeba-hq.py) | x8 | 23.6241 / 0.6721 | 4 (Tesla PG503-216) | [模型](https://download.openmmlab.com/mmediting/restorers/dic/dic_gan_x8c48b6_g4_500k_CelebAHQ_20210625-3b89a358.pth) \| [日志](https://download.openmmlab.com/mmediting/restorers/dic/dic_gan_x8c48b6_g4_500k_CelebAHQ_20210625-3b89a358.log.json) |
+| 算法 | scale | CelebA-HQ | GPU 信息 | 下载 |
+| :--------------------------------------------------------------------------: | :---: | :--------------: | :-----------------: | :----------------------------------------------------------------------------------: |
+| [dic_x8c48b6_g4_150k_CelebAHQ](./dic_x8c48b6_4xb2-150k_celeba-hq.py) | x8 | 25.2319 / 0.7422 | 4 (Tesla PG503-216) | [模型](https://download.openmmlab.com/mmediting/restorers/dic/dic_x8c48b6_g4_150k_CelebAHQ_20210611-5d3439ca.pth) \| [日志](https://download.openmmlab.com/mmediting/restorers/dic/dic_x8c48b6_g4_150k_CelebAHQ_20210611-5d3439ca.log.json) |
+| [dic_gan_x8c48b6_g4_500k_CelebAHQ](./dic_gan-x8c48b6_4xb2-500k_celeba-hq.py) | x8 | 23.6241 / 0.6721 | 4 (Tesla PG503-216) | [模型](https://download.openmmlab.com/mmediting/restorers/dic/dic_gan_x8c48b6_g4_500k_CelebAHQ_20210625-3b89a358.pth) \| [日志](https://download.openmmlab.com/mmediting/restorers/dic/dic_gan_x8c48b6_g4_500k_CelebAHQ_20210625-3b89a358.log.json) |
## 快速开始
diff --git a/configs/dic/metafile.yml b/configs/dic/metafile.yml
index 51d63d50d8..713931d1b1 100644
--- a/configs/dic/metafile.yml
+++ b/configs/dic/metafile.yml
@@ -6,6 +6,9 @@ Collections:
Paper:
- https://arxiv.org/abs/2003.13063
README: configs/dic/README.md
+ Task:
+ - image super-resolution
+ Year: 2020
Models:
- Config: configs/dic/dic_x8c48b6_4xb2-150k_celeba-hq.py
In Collection: DIC
diff --git a/configs/dim/README.md b/configs/dim/README.md
index f2c768d070..9106ec9ac5 100644
--- a/configs/dim/README.md
+++ b/configs/dim/README.md
@@ -20,13 +20,14 @@ Image matting is a fundamental computer vision problem and has many applications
## Results and models
-| Method | SAD | MSE | GRAD | CONN | GPU Info | Download |
-| :------------------------------------------------------------------: | :------: | :-------: | :------: | :------: | :------: | :-----------------------------------------------------------------------------------------: |
-| stage1 (paper) | 54.6 | 0.017 | 36.7 | 55.3 | - | - |
-| stage3 (paper) | **50.4** | **0.014** | 31.0 | 50.8 | - | - |
-| [stage1 (our)](/configs/dim/dim_stage1-v16_1xb1-1000k_comp1k.py) | 53.8 | 0.017 | 32.7 | 54.5 | 1 | [model](https://download.openmmlab.com/mmediting/mattors/dim/dim_stage1_v16_1x1_1000k_comp1k_SAD-53.8_20200605_140257-979a420f.pth) \| [log](https://download.openmmlab.com/mmediting/mattors/dim/dim_stage1_v16_1x1_1000k_comp1k_20200605_140257.log.json) |
-| [stage2 (our)](/configs/dim/dim_stage2-v16-pln_1xb1-1000k_comp1k.py) | 52.3 | 0.016 | 29.4 | 52.4 | 1 | [model](https://download.openmmlab.com/mmediting/mattors/dim/dim_stage2_v16_pln_1x1_1000k_comp1k_SAD-52.3_20200607_171909-d83c4775.pth) \| [log](https://download.openmmlab.com/mmediting/mattors/dim/dim_stage2_v16_pln_1x1_1000k_comp1k_20200607_171909.log.json) |
-| [stage3 (our)](/configs/dim/dim_stage3-v16-pln_1xb1-1000k_comp1k.py) | 50.6 | 0.015 | **29.0** | **50.7** | 1 | [model](https://download.openmmlab.com/mmediting/mattors/dim/dim_stage3_v16_pln_1x1_1000k_comp1k_SAD-50.6_20200609_111851-647f24b6.pth) \| [log](https://download.openmmlab.com/mmediting/mattors/dim/dim_stage3_v16_pln_1x1_1000k_comp1k_20200609_111851.log.json) |
+| Method | SAD | MSE | GRAD | CONN | GPU Info | Download |
+| :-------------------------------------------------------------------------: | :------: | :-------: | :------: | :------: | :------: | :----------------------------------------------------------------------------------: |
+| stage1 (paper) | 54.6 | 0.017 | 36.7 | 55.3 | - | - |
+| stage3 (paper) | **50.4** | **0.014** | 31.0 | 50.8 | - | - |
+| [stage1 (our)](./dim_stage1-v16_1xb1-1000k_comp1k.py) | 53.8 | 0.017 | 32.7 | 54.5 | 1 | [model](https://download.openmmlab.com/mmediting/mattors/dim/dim_stage1_v16_1x1_1000k_comp1k_SAD-53.8_20200605_140257-979a420f.pth) \| [log](https://download.openmmlab.com/mmediting/mattors/dim/dim_stage1_v16_1x1_1000k_comp1k_20200605_140257.log.json) |
+| [stage2 (our)](./dim_stage2-v16-pln_1xb1-1000k_comp1k.py) | 52.3 | 0.016 | 29.4 | 52.4 | 1 | [model](https://download.openmmlab.com/mmediting/mattors/dim/dim_stage2_v16_pln_1x1_1000k_comp1k_SAD-52.3_20200607_171909-d83c4775.pth) \| [log](https://download.openmmlab.com/mmediting/mattors/dim/dim_stage2_v16_pln_1x1_1000k_comp1k_20200607_171909.log.json) |
+| [stage3 (our)](./dim_stage3-v16-pln_1xb1-1000k_comp1k.py) | 50.6 | 0.015 | **29.0** | **50.7** | 1 | [model](https://download.openmmlab.com/mmediting/mattors/dim/dim_stage3_v16_pln_1x1_1000k_comp1k_SAD-50.6_20200609_111851-647f24b6.pth) \| [log](https://download.openmmlab.com/mmediting/mattors/dim/dim_stage3_v16_pln_1x1_1000k_comp1k_20200609_111851.log.json) |
+| [stage1 (online merge)](./dim_stage1-v16_1xb1-1000k_comp1k_online-merge.py) | - | - | - | - | - | - |
**NOTE**
diff --git a/configs/dim/README_zh-CN.md b/configs/dim/README_zh-CN.md
index 4683b3efc0..518dd5f49b 100644
--- a/configs/dim/README_zh-CN.md
+++ b/configs/dim/README_zh-CN.md
@@ -21,13 +21,14 @@
-| Models | Dataset | SWD | MS-SSIM | Config | Download |
-| :---------: | :------------: | :----------------------: | :-----: | :---------------------------------------------------------------------: | :-----------------------------------------------------------------------: |
-| DCGAN 64x64 | MNIST (64x64) | 21.16, 4.4, 8.41/11.32 | 0.1395 | [config](/configs/dcgan/dcgan_Glr4e-4_Dlr1e-4_1xb128-5kiters_mnist-64x64.py) | [model](https://download.openmmlab.com/mmgen/base_dcgan_mnist-64_b128x1_Glr4e-4_Dlr1e-4_5k_20210512_163926-207a1eaf.pth) \| [log](https://download.openmmlab.com//mmgen/dcgan/dcgan_mnist-64_b128x1_Glr4e-4_Dlr1e-4_5k_20210512_163926-207a1eaf.json) |
-| DCGAN 64x64 | CelebA-Cropped | 8.93,10.53,50.32/23.26 | 0.2899 | [config](/configs/dcgan/dcgan_1xb128-300kiters_celeba-cropped-64.py) | [model](https://download.openmmlab.com/mmgen/base_dcgan_celeba-cropped_64_b128x1_300kiter_20210408_161607-1f8a2277.pth) \| [log](https://download.openmmlab.com/mmgen/dcgan/base_dcgan_celeba-cropped_64_b128x1_300kiter_20210408_161607-1f8a2277.json) |
-| DCGAN 64x64 | LSUN-Bedroom | 42.79, 34.55, 98.46/58.6 | 0.2095 | [config](/configs/dcgan/dcgan_1xb128-5epoches_lsun-bedroom-64x64.py) | [model](https://download.openmmlab.com/mmgen/base_dcgan_lsun-bedroom_64_b128x1_5e_20210408_161713-117c498b.pth) \| [log](https://download.openmmlab.com/mmgen/dcgan/base_dcgan_lsun-bedroom_64_b128x1_5e_20210408_161713-117c498b.json) |
+| Models | Dataset | SWD | MS-SSIM | Config | Download |
+| :---------: | :------------: | :----------------------: | :-----: | :-------------------------------------------------------------: | :-------------------------------------------------------------------------------: |
+| DCGAN 64x64 | MNIST (64x64) | 21.16, 4.4, 8.41/11.32 | 0.1395 | [config](./dcgan_Glr4e-4_Dlr1e-4_1xb128-5kiters_mnist-64x64.py) | [model](https://download.openmmlab.com/mmediting/dcgan/dcgan_mnist-64_b128x1_Glr4e-4_Dlr1e-4_5k_20210512_163926-207a1eaf.pth) \| [log](https://download.openmmlab.com//mmgen/dcgan/dcgan_mnist-64_b128x1_Glr4e-4_Dlr1e-4_5k_20210512_163926-207a1eaf.json) |
+| DCGAN 64x64 | CelebA-Cropped | 8.93,10.53,50.32/23.26 | 0.2899 | [config](./dcgan_1xb128-300kiters_celeba-cropped-64.py) | [model](https://download.openmmlab.com/mmediting/dcgan/dcgan_celeba-cropped_64_b128x1_300kiter_20210408_161607-1f8a2277.pth) \| [log](https://download.openmmlab.com/mmediting/dcgan/dcgan_celeba-cropped_64_b128x1_300kiter_20210408_161607-1f8a2277.json) |
+| DCGAN 64x64 | LSUN-Bedroom | 42.79, 34.55, 98.46/58.6 | 0.2095 | [config](./dcgan_1xb128-5epoches_lsun-bedroom-64x64.py) | [model](https://download.openmmlab.com/mmediting/dcgan/dcgan_lsun-bedroom_64_b128x1_5e_20210408_161713-117c498b.pth) \| [log](https://download.openmmlab.com/mmediting/dcgan/dcgan_lsun-bedroom_64_b128x1_5e_20210408_161713-117c498b.json) |
## Citation
diff --git a/configs/dcgan/dcgan_1xb128-300kiters_celeba-cropped-64.py b/configs/dcgan/dcgan_1xb128-300kiters_celeba-cropped-64.py
index 95324ff8e4..2f1ab816e6 100644
--- a/configs/dcgan/dcgan_1xb128-300kiters_celeba-cropped-64.py
+++ b/configs/dcgan/dcgan_1xb128-300kiters_celeba-cropped-64.py
@@ -45,6 +45,8 @@
sample_model='orig',
image_shape=(3, 64, 64))
]
+# save best checkpoints
+default_hooks = dict(checkpoint=dict(save_best='swd/avg', rule='less'))
val_evaluator = dict(metrics=metrics)
test_evaluator = dict(metrics=metrics)
diff --git a/configs/dcgan/dcgan_1xb128-5epoches_lsun-bedroom-64x64.py b/configs/dcgan/dcgan_1xb128-5epoches_lsun-bedroom-64x64.py
index 79f4e56f5f..e4396a3462 100644
--- a/configs/dcgan/dcgan_1xb128-5epoches_lsun-bedroom-64x64.py
+++ b/configs/dcgan/dcgan_1xb128-5epoches_lsun-bedroom-64x64.py
@@ -44,6 +44,8 @@
sample_model='orig',
image_shape=(3, 64, 64))
]
+# save best checkpoints
+default_hooks = dict(checkpoint=dict(save_best='swd/avg', rule='less'))
val_evaluator = dict(metrics=metrics)
test_evaluator = dict(metrics=metrics)
diff --git a/configs/dcgan/dcgan_Glr4e-4_Dlr1e-4_1xb128-5kiters_mnist-64x64.py b/configs/dcgan/dcgan_Glr4e-4_Dlr1e-4_1xb128-5kiters_mnist-64x64.py
index 3eb1b4ad99..3625022ccf 100644
--- a/configs/dcgan/dcgan_Glr4e-4_Dlr1e-4_1xb128-5kiters_mnist-64x64.py
+++ b/configs/dcgan/dcgan_Glr4e-4_Dlr1e-4_1xb128-5kiters_mnist-64x64.py
@@ -5,47 +5,44 @@
]
# output single channel
-model = dict(generator=dict(out_channels=1), discriminator=dict(in_channels=1))
+model = dict(
+ data_preprocessor=dict(mean=[127.5], std=[127.5]),
+ generator=dict(out_channels=1),
+ discriminator=dict(in_channels=1))
# define dataset
# modify train_pipeline to load gray scale images
train_pipeline = [
- dict(
- type='LoadImageFromFile',
- key='img',
- io_backend='disk',
- color_type='grayscale'),
+ dict(type='LoadImageFromFile', key='img', color_type='grayscale'),
dict(type='Resize', scale=(64, 64)),
- dict(type='PackEditInputs', meta_keys=[])
+ dict(type='PackEditInputs')
]
# set ``batch_size``` and ``data_root```
batch_size = 128
data_root = 'data/mnist_64/train'
train_dataloader = dict(
- batch_size=batch_size, dataset=dict(data_root=data_root))
+ batch_size=batch_size,
+ dataset=dict(data_root=data_root, pipeline=train_pipeline))
-val_dataloader = dict(batch_size=batch_size, dataset=dict(data_root=data_root))
+val_dataloader = dict(
+ batch_size=batch_size,
+ dataset=dict(data_root=data_root, pipeline=train_pipeline))
test_dataloader = dict(
- batch_size=batch_size, dataset=dict(data_root=data_root))
-
-default_hooks = dict(
- checkpoint=dict(
- interval=500,
- save_best=['swd/avg', 'ms-ssim/avg'],
- rule=['less', 'greater']))
+ batch_size=batch_size,
+ dataset=dict(data_root=data_root, pipeline=train_pipeline))
# VIS_HOOK
custom_hooks = [
dict(
type='GenVisualizationHook',
- interval=10000,
+ interval=500,
fixed_input=True,
vis_kwargs_list=dict(type='GAN', name='fake_img'))
]
-train_cfg = dict(max_iters=5000)
+train_cfg = dict(max_iters=5000, val_interval=500)
# METRICS
metrics = [
@@ -55,10 +52,13 @@
dict(
type='SWD',
prefix='swd',
- fake_nums=16384,
+ fake_nums=-1,
sample_model='orig',
- image_shape=(3, 64, 64))
+ image_shape=(1, 64, 64))
]
+# save best checkpoints
+default_hooks = dict(
+ checkpoint=dict(interval=500, save_best='swd/avg', rule='less'))
val_evaluator = dict(metrics=metrics)
test_evaluator = dict(metrics=metrics)
diff --git a/configs/dcgan/metafile.yml b/configs/dcgan/metafile.yml
index 62d38230c5..2d201ff980 100644
--- a/configs/dcgan/metafile.yml
+++ b/configs/dcgan/metafile.yml
@@ -8,6 +8,9 @@ Collections:
Paper:
- https://arxiv.org/abs/1511.06434
README: configs/dcgan/README.md
+ Task:
+ - unconditional gans
+ Year: 2016
Models:
- Config: configs/dcgan/dcgan_Glr4e-4_Dlr1e-4_1xb128-5kiters_mnist-64x64.py
In Collection: Unsupervised Representation Learning with Deep Convolutional Generative
@@ -20,7 +23,7 @@ Models:
Metrics:
MS-SSIM: 0.1395
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/base_dcgan_mnist-64_b128x1_Glr4e-4_Dlr1e-4_5k_20210512_163926-207a1eaf.pth
+ Weights: https://download.openmmlab.com/mmediting/dcgan/dcgan_mnist-64_b128x1_Glr4e-4_Dlr1e-4_5k_20210512_163926-207a1eaf.pth
- Config: configs/dcgan/dcgan_1xb128-300kiters_celeba-cropped-64.py
In Collection: Unsupervised Representation Learning with Deep Convolutional Generative
Adversarial Networks
@@ -32,7 +35,7 @@ Models:
Metrics:
MS-SSIM: 0.2899
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/base_dcgan_celeba-cropped_64_b128x1_300kiter_20210408_161607-1f8a2277.pth
+ Weights: https://download.openmmlab.com/mmediting/dcgan/dcgan_celeba-cropped_64_b128x1_300kiter_20210408_161607-1f8a2277.pth
- Config: configs/dcgan/dcgan_1xb128-5epoches_lsun-bedroom-64x64.py
In Collection: Unsupervised Representation Learning with Deep Convolutional Generative
Adversarial Networks
@@ -44,4 +47,4 @@ Models:
Metrics:
MS-SSIM: 0.2095
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/base_dcgan_lsun-bedroom_64_b128x1_5e_20210408_161713-117c498b.pth
+ Weights: https://download.openmmlab.com/mmediting/dcgan/dcgan_lsun-bedroom_64_b128x1_5e_20210408_161713-117c498b.pth
diff --git a/configs/deepfillv1/README.md b/configs/deepfillv1/README.md
index d68c28523c..a020f898ea 100644
--- a/configs/deepfillv1/README.md
+++ b/configs/deepfillv1/README.md
@@ -22,15 +22,15 @@ Recent deep learning based approaches have shown promising results for the chall
**Places365-Challenge**
-| Method | Mask Type | Resolution | Train Iters | Test Set | l1 error | PSNR | SSIM | GPU Info | Download |
-| :-------------------------------------------------------------: | :---------: | :--------: | :---------: | :-----------: | :------: | :----: | :---: | :------: | :---------------------------------------------------------------: |
-| [DeepFillv1](/configs/deepfillv1/deepfillv1_8xb2_places-256x256.py) | square bbox | 256x256 | 3500k | Places365-val | 11.019 | 23.429 | 0.862 | 8 | [model](https://download.openmmlab.com/mmediting/inpainting/deepfillv1/deepfillv1_256x256_8x2_places_20200619-c00a0e21.pth) \| [log](https://download.openmmlab.com/mmediting/inpainting/deepfillv1/deepfillv1_256x256_8x2_places_20200619-c00a0e21.log.json) |
+| Method | Mask Type | Resolution | Train Iters | Test Set | l1 error | PSNR | SSIM | GPU Info | Download |
+| :-----------------------------------------------: | :---------: | :--------: | :---------: | :-----------: | :------: | :----: | :---: | :------: | :-----------------------------------------------------------------------------: |
+| [DeepFillv1](./deepfillv1_8xb2_places-256x256.py) | square bbox | 256x256 | 3500k | Places365-val | 11.019 | 23.429 | 0.862 | 8 | [model](https://download.openmmlab.com/mmediting/inpainting/deepfillv1/deepfillv1_256x256_8x2_places_20200619-c00a0e21.pth) \| [log](https://download.openmmlab.com/mmediting/inpainting/deepfillv1/deepfillv1_256x256_8x2_places_20200619-c00a0e21.log.json) |
**CelebA-HQ**
-| Method | Mask Type | Resolution | Train Iters | Test Set | l1 error | PSNR | SSIM | GPU Info | Download |
-| :--------------------------------------------------------------: | :---------: | :--------: | :---------: | :--------: | :------: | :----: | :---: | :------: | :-----------------------------------------------------------------: |
-| [DeepFillv1](/configs/deepfillv1/deepfillv1_4xb4_celeba-256x256.py) | square bbox | 256x256 | 1500k | CelebA-val | 6.677 | 26.878 | 0.911 | 4 | [model](https://download.openmmlab.com/mmediting/inpainting/deepfillv1/deepfillv1_256x256_4x4_celeba_20200619-dd51a855.pth) \| [log](https://download.openmmlab.com/mmediting/inpainting/deepfillv1/deepfillv1_256x256_4x4_celeba_20200619-dd51a855.log.json) |
+| Method | Mask Type | Resolution | Train Iters | Test Set | l1 error | PSNR | SSIM | GPU Info | Download |
+| :-----------------------------------------------: | :---------: | :--------: | :---------: | :--------: | :------: | :----: | :---: | :------: | :--------------------------------------------------------------------------------: |
+| [DeepFillv1](./deepfillv1_4xb4_celeba-256x256.py) | square bbox | 256x256 | 1500k | CelebA-val | 6.677 | 26.878 | 0.911 | 4 | [model](https://download.openmmlab.com/mmediting/inpainting/deepfillv1/deepfillv1_256x256_4x4_celeba_20200619-dd51a855.pth) \| [log](https://download.openmmlab.com/mmediting/inpainting/deepfillv1/deepfillv1_256x256_4x4_celeba_20200619-dd51a855.log.json) |
## Quick Start
diff --git a/configs/deepfillv1/README_zh-CN.md b/configs/deepfillv1/README_zh-CN.md
index 273a29ac0a..db7625e8ba 100644
--- a/configs/deepfillv1/README_zh-CN.md
+++ b/configs/deepfillv1/README_zh-CN.md
@@ -23,15 +23,15 @@
**Places365-Challenge**
-| 算法 | 掩膜类型 | 分辨率 | 训练集容量 | 测试集 | l1 损失 | PSNR | SSIM | GPU 信息 | 下载 |
-| :----------------------------------------------------------------: | :---------: | :-----: | :--------: | :-----------: | :-----: | :----: | :---: | :------: | :-----------------------------------------------------------------: |
-| [DeepFillv1](/configs/deepfillv1/deepfillv1_8xb2_places-256x256.py) | square bbox | 256x256 | 3500k | Places365-val | 11.019 | 23.429 | 0.862 | 8 | [模型](https://download.openmmlab.com/mmediting/inpainting/deepfillv1/deepfillv1_256x256_8x2_places_20200619-c00a0e21.pth) \| [日志](https://download.openmmlab.com/mmediting/inpainting/deepfillv1/deepfillv1_256x256_8x2_places_20200619-c00a0e21.log.json) |
+| 算法 | 掩膜类型 | 分辨率 | 训练集容量 | 测试集 | l1 损失 | PSNR | SSIM | GPU 信息 | 下载 |
+| :-----------------------------------------------: | :---------: | :-----: | :--------: | :-----------: | :-----: | :----: | :---: | :------: | :----------------------------------------------------------------------------------: |
+| [DeepFillv1](./deepfillv1_8xb2_places-256x256.py) | square bbox | 256x256 | 3500k | Places365-val | 11.019 | 23.429 | 0.862 | 8 | [模型](https://download.openmmlab.com/mmediting/inpainting/deepfillv1/deepfillv1_256x256_8x2_places_20200619-c00a0e21.pth) \| [日志](https://download.openmmlab.com/mmediting/inpainting/deepfillv1/deepfillv1_256x256_8x2_places_20200619-c00a0e21.log.json) |
**CelebA-HQ**
-| 算法 | 掩膜类型 | 分辨率 | 训练集容量 | 测试集 | l1 损失 | PSNR | SSIM | GPU 信息 | 下载 |
-| :-----------------------------------------------------------------: | :---------: | :-----: | :--------: | :--------: | :-----: | :----: | :---: | :------: | :-------------------------------------------------------------------: |
-| [DeepFillv1](/configs/deepfillv1/deepfillv1_4xb4_celeba-256x256.py) | square bbox | 256x256 | 1500k | CelebA-val | 6.677 | 26.878 | 0.911 | 4 | [模型](https://download.openmmlab.com/mmediting/inpainting/deepfillv1/deepfillv1_256x256_4x4_celeba_20200619-dd51a855.pth) \| [日志](https://download.openmmlab.com/mmediting/inpainting/deepfillv1/deepfillv1_256x256_4x4_celeba_20200619-dd51a855.log.json) |
+| 算法 | 掩膜类型 | 分辨率 | 训练集容量 | 测试集 | l1 损失 | PSNR | SSIM | GPU 信息 | 下载 |
+| :-----------------------------------------------: | :---------: | :-----: | :--------: | :--------: | :-----: | :----: | :---: | :------: | :-------------------------------------------------------------------------------------: |
+| [DeepFillv1](./deepfillv1_4xb4_celeba-256x256.py) | square bbox | 256x256 | 1500k | CelebA-val | 6.677 | 26.878 | 0.911 | 4 | [模型](https://download.openmmlab.com/mmediting/inpainting/deepfillv1/deepfillv1_256x256_4x4_celeba_20200619-dd51a855.pth) \| [日志](https://download.openmmlab.com/mmediting/inpainting/deepfillv1/deepfillv1_256x256_4x4_celeba_20200619-dd51a855.log.json) |
## 快速开始
diff --git a/configs/deepfillv1/metafile.yml b/configs/deepfillv1/metafile.yml
index 968b448d38..c8a83d22a4 100644
--- a/configs/deepfillv1/metafile.yml
+++ b/configs/deepfillv1/metafile.yml
@@ -6,6 +6,9 @@ Collections:
Paper:
- https://arxiv.org/abs/1801.07892
README: configs/deepfillv1/README.md
+ Task:
+ - inpainting
+ Year: 2018
Models:
- Config: configs/deepfillv1/deepfillv1_8xb2_places-256x256.py
In Collection: DeepFillv1
diff --git a/configs/deepfillv2/README.md b/configs/deepfillv2/README.md
index dce7150cb5..096bb2f16c 100644
--- a/configs/deepfillv2/README.md
+++ b/configs/deepfillv2/README.md
@@ -22,15 +22,15 @@ We present a generative image inpainting system to complete images with free-for
**Places365-Challenge**
-| Method | Mask Type | Resolution | Train Iters | Test Set | l1 error | PSNR | SSIM | GPU Info | Download |
-| :--------------------------------------------------------------: | :-------: | :--------: | :---------: | :-----------: | :------: | :----: | :---: | :------: | :----------------------------------------------------------------: |
-| [DeepFillv2](/configs/deepfillv2/deepfillv2_8xb2_places-256x256.py) | free-form | 256x256 | 100k | Places365-val | 8.635 | 22.398 | 0.815 | 8 | [model](https://download.openmmlab.com/mmediting/inpainting/deepfillv2/deepfillv2_256x256_8x2_places_20200619-10d15793.pth) \| [log](https://download.openmmlab.com/mmediting/inpainting/deepfillv2/deepfillv2_256x256_8x2_places_20200619-10d15793.log.json) |
+| Method | Mask Type | Resolution | Train Iters | Test Set | l1 error | PSNR | SSIM | GPU Info | Download |
+| :-----------------------------------------------: | :-------: | :--------: | :---------: | :-----------: | :------: | :----: | :---: | :------: | :-------------------------------------------------------------------------------: |
+| [DeepFillv2](./deepfillv2_8xb2_places-256x256.py) | free-form | 256x256 | 100k | Places365-val | 8.635 | 22.398 | 0.815 | 8 | [model](https://download.openmmlab.com/mmediting/inpainting/deepfillv2/deepfillv2_256x256_8x2_places_20200619-10d15793.pth) \| [log](https://download.openmmlab.com/mmediting/inpainting/deepfillv2/deepfillv2_256x256_8x2_places_20200619-10d15793.log.json) |
**CelebA-HQ**
-| Method | Mask Type | Resolution | Train Iters | Test Set | l1 error | PSNR | SSIM | GPU Info | Download |
-| :---------------------------------------------------------------: | :-------: | :--------: | :---------: | :--------: | :------: | :----: | :---: | :------: | :------------------------------------------------------------------: |
-| [DeepFillv2](/configs/deepfillv2/deepfillv2_8xb2_celeba-256x256.py) | free-form | 256x256 | 20k | CelebA-val | 5.411 | 25.721 | 0.871 | 8 | [model](https://download.openmmlab.com/mmediting/inpainting/deepfillv2/deepfillv2_256x256_8x2_celeba_20200619-c96e5f12.pth) \| [log](https://download.openmmlab.com/mmediting/inpainting/deepfillv2/deepfillv2_256x256_8x2_celeba_20200619-c96e5f12.log.json) |
+| Method | Mask Type | Resolution | Train Iters | Test Set | l1 error | PSNR | SSIM | GPU Info | Download |
+| :-----------------------------------------------: | :-------: | :--------: | :---------: | :--------: | :------: | :----: | :---: | :------: | :----------------------------------------------------------------------------------: |
+| [DeepFillv2](./deepfillv2_8xb2_celeba-256x256.py) | free-form | 256x256 | 20k | CelebA-val | 5.411 | 25.721 | 0.871 | 8 | [model](https://download.openmmlab.com/mmediting/inpainting/deepfillv2/deepfillv2_256x256_8x2_celeba_20200619-c96e5f12.pth) \| [log](https://download.openmmlab.com/mmediting/inpainting/deepfillv2/deepfillv2_256x256_8x2_celeba_20200619-c96e5f12.log.json) |
## Quick Start
diff --git a/configs/deepfillv2/README_zh-CN.md b/configs/deepfillv2/README_zh-CN.md
index 3c71037056..eaa1a31f4a 100644
--- a/configs/deepfillv2/README_zh-CN.md
+++ b/configs/deepfillv2/README_zh-CN.md
@@ -23,15 +23,15 @@
**Places365-Challenge**
-| 算法 | 掩膜类型 | 分辨率 | 训练集容量 | 测试集 | l1 损失 | PSNR | SSIM | GPU 信息 | 下载 |
-| :-----------------------------------------------------------------: | :-------: | :-----: | :--------: | :-----------: | :-----: | :----: | :---: | :------: | :------------------------------------------------------------------: |
-| [DeepFillv2](/configs/deepfillv2/deepfillv2_8xb2_places-256x256.py) | free-form | 256x256 | 100k | Places365-val | 8.635 | 22.398 | 0.815 | 8 | [模型](https://download.openmmlab.com/mmediting/inpainting/deepfillv2/deepfillv2_256x256_8x2_places_20200619-10d15793.pth) \| [日志](https://download.openmmlab.com/mmediting/inpainting/deepfillv2/deepfillv2_256x256_8x2_places_20200619-10d15793.log.json) |
+| 算法 | 掩膜类型 | 分辨率 | 训练集容量 | 测试集 | l1 损失 | PSNR | SSIM | GPU 信息 | 下载 |
+| :-----------------------------------------------: | :-------: | :-----: | :--------: | :-----------: | :-----: | :----: | :---: | :------: | :------------------------------------------------------------------------------------: |
+| [DeepFillv2](./deepfillv2_8xb2_places-256x256.py) | free-form | 256x256 | 100k | Places365-val | 8.635 | 22.398 | 0.815 | 8 | [模型](https://download.openmmlab.com/mmediting/inpainting/deepfillv2/deepfillv2_256x256_8x2_places_20200619-10d15793.pth) \| [日志](https://download.openmmlab.com/mmediting/inpainting/deepfillv2/deepfillv2_256x256_8x2_places_20200619-10d15793.log.json) |
**CelebA-HQ**
-| 算法 | 掩膜类型 | 分辨率 | 训练集容量 | 测试集 | l1 损失 | PSNR | SSIM | GPU 信息 | 下载 |
-| :-----------------------------------------------------------------: | :-------: | :-----: | :--------: | :--------: | :-----: | :----: | :---: | :------: | :---------------------------------------------------------------------: |
-| [DeepFillv2](/configs/deepfillv2/deepfillv2_8xb2_celeba-256x256.py) | free-form | 256x256 | 20k | CelebA-val | 5.411 | 25.721 | 0.871 | 8 | [模型](https://download.openmmlab.com/mmediting/inpainting/deepfillv2/deepfillv2_256x256_8x2_celeba_20200619-c96e5f12.pth) \| [日志](https://download.openmmlab.com/mmediting/inpainting/deepfillv2/deepfillv2_256x256_8x2_celeba_20200619-c96e5f12.log.json) |
+| 算法 | 掩膜类型 | 分辨率 | 训练集容量 | 测试集 | l1 损失 | PSNR | SSIM | GPU 信息 | 下载 |
+| :-----------------------------------------------: | :-------: | :-----: | :--------: | :--------: | :-----: | :----: | :---: | :------: | :---------------------------------------------------------------------------------------: |
+| [DeepFillv2](./deepfillv2_8xb2_celeba-256x256.py) | free-form | 256x256 | 20k | CelebA-val | 5.411 | 25.721 | 0.871 | 8 | [模型](https://download.openmmlab.com/mmediting/inpainting/deepfillv2/deepfillv2_256x256_8x2_celeba_20200619-c96e5f12.pth) \| [日志](https://download.openmmlab.com/mmediting/inpainting/deepfillv2/deepfillv2_256x256_8x2_celeba_20200619-c96e5f12.log.json) |
## 快速开始
diff --git a/configs/deepfillv2/metafile.yml b/configs/deepfillv2/metafile.yml
index d84dab7739..d0a57379e7 100644
--- a/configs/deepfillv2/metafile.yml
+++ b/configs/deepfillv2/metafile.yml
@@ -6,6 +6,9 @@ Collections:
Paper:
- https://arxiv.org/abs/1806.03589
README: configs/deepfillv2/README.md
+ Task:
+ - inpainting
+ Year: 2019
Models:
- Config: configs/deepfillv2/deepfillv2_8xb2_places-256x256.py
In Collection: DeepFillv2
diff --git a/configs/dic/README.md b/configs/dic/README.md
index 69b808f74b..90215ae6b8 100644
--- a/configs/dic/README.md
+++ b/configs/dic/README.md
@@ -27,10 +27,10 @@ In the log data of `dic_gan_x8c48b6_g4_150k_CelebAHQ`, DICGAN is verified on the
`GPU Info`: GPU information during training.
-| Method | scale | PSNR | SSIM | GPU Info | Download |
-| :------------------------------------------------------------------------------: | :---: | :-----: | :----: | :-----------------: | :---------------------------------------------------------------------------------: |
-| [dic_x8c48b6_g4_150k_CelebAHQ](/configs/dic/dic_x8c48b6_4xb2-150k_celeba-hq.py) | x8 | 25.2319 | 0.7422 | 4 (Tesla PG503-216) | [model](https://download.openmmlab.com/mmediting/restorers/dic/dic_x8c48b6_g4_150k_CelebAHQ_20210611-5d3439ca.pth) \| [log](https://download.openmmlab.com/mmediting/restorers/dic/dic_x8c48b6_g4_150k_CelebAHQ_20210611-5d3439ca.log.json) |
-| [dic_gan_x8c48b6_g4_500k_CelebAHQ](/configs/dic/dic_gan-x8c48b6_4xb2-500k_celeba-hq.py) | x8 | 23.6241 | 0.6721 | 4 (Tesla PG503-216) | [model](https://download.openmmlab.com/mmediting/restorers/dic/dic_gan_x8c48b6_g4_500k_CelebAHQ_20210625-3b89a358.pth) \| [log](https://download.openmmlab.com/mmediting/restorers/dic/dic_gan_x8c48b6_g4_500k_CelebAHQ_20210625-3b89a358.log.json) |
+| Method | scale | PSNR | SSIM | GPU Info | Download |
+| :--------------------------------------------------------------------------: | :---: | :-----: | :----: | :-----------------: | :-------------------------------------------------------------------------------------: |
+| [dic_x8c48b6_g4_150k_CelebAHQ](./dic_x8c48b6_4xb2-150k_celeba-hq.py) | x8 | 25.2319 | 0.7422 | 4 (Tesla PG503-216) | [model](https://download.openmmlab.com/mmediting/restorers/dic/dic_x8c48b6_g4_150k_CelebAHQ_20210611-5d3439ca.pth) \| [log](https://download.openmmlab.com/mmediting/restorers/dic/dic_x8c48b6_g4_150k_CelebAHQ_20210611-5d3439ca.log.json) |
+| [dic_gan_x8c48b6_g4_500k_CelebAHQ](./dic_gan-x8c48b6_4xb2-500k_celeba-hq.py) | x8 | 23.6241 | 0.6721 | 4 (Tesla PG503-216) | [model](https://download.openmmlab.com/mmediting/restorers/dic/dic_gan_x8c48b6_g4_500k_CelebAHQ_20210625-3b89a358.pth) \| [log](https://download.openmmlab.com/mmediting/restorers/dic/dic_gan_x8c48b6_g4_500k_CelebAHQ_20210625-3b89a358.log.json) |
## Quick Start
diff --git a/configs/dic/README_zh-CN.md b/configs/dic/README_zh-CN.md
index 8333162f54..74ef56d31b 100644
--- a/configs/dic/README_zh-CN.md
+++ b/configs/dic/README_zh-CN.md
@@ -29,10 +29,10 @@
`GPU 信息`: 训练过程中的 GPU 信息.
-| 算法 | scale | CelebA-HQ | GPU 信息 | 下载 |
-| :------------------------------------------------------------------------------: | :---: | :--------------: | :-----------------: | :------------------------------------------------------------------------------: |
-| [dic_x8c48b6_g4_150k_CelebAHQ](/configs/dic/dic_x8c48b6_4xb2-150k_celeba-hq.py) | x8 | 25.2319 / 0.7422 | 4 (Tesla PG503-216) | [模型](https://download.openmmlab.com/mmediting/restorers/dic/dic_x8c48b6_g4_150k_CelebAHQ_20210611-5d3439ca.pth) \| [日志](https://download.openmmlab.com/mmediting/restorers/dic/dic_x8c48b6_g4_150k_CelebAHQ_20210611-5d3439ca.log.json) |
-| [dic_gan_x8c48b6_g4_500k_CelebAHQ](/configs/dic/dic_gan-x8c48b6_4xb2-500k_celeba-hq.py) | x8 | 23.6241 / 0.6721 | 4 (Tesla PG503-216) | [模型](https://download.openmmlab.com/mmediting/restorers/dic/dic_gan_x8c48b6_g4_500k_CelebAHQ_20210625-3b89a358.pth) \| [日志](https://download.openmmlab.com/mmediting/restorers/dic/dic_gan_x8c48b6_g4_500k_CelebAHQ_20210625-3b89a358.log.json) |
+| 算法 | scale | CelebA-HQ | GPU 信息 | 下载 |
+| :--------------------------------------------------------------------------: | :---: | :--------------: | :-----------------: | :----------------------------------------------------------------------------------: |
+| [dic_x8c48b6_g4_150k_CelebAHQ](./dic_x8c48b6_4xb2-150k_celeba-hq.py) | x8 | 25.2319 / 0.7422 | 4 (Tesla PG503-216) | [模型](https://download.openmmlab.com/mmediting/restorers/dic/dic_x8c48b6_g4_150k_CelebAHQ_20210611-5d3439ca.pth) \| [日志](https://download.openmmlab.com/mmediting/restorers/dic/dic_x8c48b6_g4_150k_CelebAHQ_20210611-5d3439ca.log.json) |
+| [dic_gan_x8c48b6_g4_500k_CelebAHQ](./dic_gan-x8c48b6_4xb2-500k_celeba-hq.py) | x8 | 23.6241 / 0.6721 | 4 (Tesla PG503-216) | [模型](https://download.openmmlab.com/mmediting/restorers/dic/dic_gan_x8c48b6_g4_500k_CelebAHQ_20210625-3b89a358.pth) \| [日志](https://download.openmmlab.com/mmediting/restorers/dic/dic_gan_x8c48b6_g4_500k_CelebAHQ_20210625-3b89a358.log.json) |
## 快速开始
diff --git a/configs/dic/metafile.yml b/configs/dic/metafile.yml
index 51d63d50d8..713931d1b1 100644
--- a/configs/dic/metafile.yml
+++ b/configs/dic/metafile.yml
@@ -6,6 +6,9 @@ Collections:
Paper:
- https://arxiv.org/abs/2003.13063
README: configs/dic/README.md
+ Task:
+ - image super-resolution
+ Year: 2020
Models:
- Config: configs/dic/dic_x8c48b6_4xb2-150k_celeba-hq.py
In Collection: DIC
diff --git a/configs/dim/README.md b/configs/dim/README.md
index f2c768d070..9106ec9ac5 100644
--- a/configs/dim/README.md
+++ b/configs/dim/README.md
@@ -20,13 +20,14 @@ Image matting is a fundamental computer vision problem and has many applications
## Results and models
-| Method | SAD | MSE | GRAD | CONN | GPU Info | Download |
-| :------------------------------------------------------------------: | :------: | :-------: | :------: | :------: | :------: | :-----------------------------------------------------------------------------------------: |
-| stage1 (paper) | 54.6 | 0.017 | 36.7 | 55.3 | - | - |
-| stage3 (paper) | **50.4** | **0.014** | 31.0 | 50.8 | - | - |
-| [stage1 (our)](/configs/dim/dim_stage1-v16_1xb1-1000k_comp1k.py) | 53.8 | 0.017 | 32.7 | 54.5 | 1 | [model](https://download.openmmlab.com/mmediting/mattors/dim/dim_stage1_v16_1x1_1000k_comp1k_SAD-53.8_20200605_140257-979a420f.pth) \| [log](https://download.openmmlab.com/mmediting/mattors/dim/dim_stage1_v16_1x1_1000k_comp1k_20200605_140257.log.json) |
-| [stage2 (our)](/configs/dim/dim_stage2-v16-pln_1xb1-1000k_comp1k.py) | 52.3 | 0.016 | 29.4 | 52.4 | 1 | [model](https://download.openmmlab.com/mmediting/mattors/dim/dim_stage2_v16_pln_1x1_1000k_comp1k_SAD-52.3_20200607_171909-d83c4775.pth) \| [log](https://download.openmmlab.com/mmediting/mattors/dim/dim_stage2_v16_pln_1x1_1000k_comp1k_20200607_171909.log.json) |
-| [stage3 (our)](/configs/dim/dim_stage3-v16-pln_1xb1-1000k_comp1k.py) | 50.6 | 0.015 | **29.0** | **50.7** | 1 | [model](https://download.openmmlab.com/mmediting/mattors/dim/dim_stage3_v16_pln_1x1_1000k_comp1k_SAD-50.6_20200609_111851-647f24b6.pth) \| [log](https://download.openmmlab.com/mmediting/mattors/dim/dim_stage3_v16_pln_1x1_1000k_comp1k_20200609_111851.log.json) |
+| Method | SAD | MSE | GRAD | CONN | GPU Info | Download |
+| :-------------------------------------------------------------------------: | :------: | :-------: | :------: | :------: | :------: | :----------------------------------------------------------------------------------: |
+| stage1 (paper) | 54.6 | 0.017 | 36.7 | 55.3 | - | - |
+| stage3 (paper) | **50.4** | **0.014** | 31.0 | 50.8 | - | - |
+| [stage1 (our)](./dim_stage1-v16_1xb1-1000k_comp1k.py) | 53.8 | 0.017 | 32.7 | 54.5 | 1 | [model](https://download.openmmlab.com/mmediting/mattors/dim/dim_stage1_v16_1x1_1000k_comp1k_SAD-53.8_20200605_140257-979a420f.pth) \| [log](https://download.openmmlab.com/mmediting/mattors/dim/dim_stage1_v16_1x1_1000k_comp1k_20200605_140257.log.json) |
+| [stage2 (our)](./dim_stage2-v16-pln_1xb1-1000k_comp1k.py) | 52.3 | 0.016 | 29.4 | 52.4 | 1 | [model](https://download.openmmlab.com/mmediting/mattors/dim/dim_stage2_v16_pln_1x1_1000k_comp1k_SAD-52.3_20200607_171909-d83c4775.pth) \| [log](https://download.openmmlab.com/mmediting/mattors/dim/dim_stage2_v16_pln_1x1_1000k_comp1k_20200607_171909.log.json) |
+| [stage3 (our)](./dim_stage3-v16-pln_1xb1-1000k_comp1k.py) | 50.6 | 0.015 | **29.0** | **50.7** | 1 | [model](https://download.openmmlab.com/mmediting/mattors/dim/dim_stage3_v16_pln_1x1_1000k_comp1k_SAD-50.6_20200609_111851-647f24b6.pth) \| [log](https://download.openmmlab.com/mmediting/mattors/dim/dim_stage3_v16_pln_1x1_1000k_comp1k_20200609_111851.log.json) |
+| [stage1 (online merge)](./dim_stage1-v16_1xb1-1000k_comp1k_online-merge.py) | - | - | - | - | - | - |
**NOTE**
diff --git a/configs/dim/README_zh-CN.md b/configs/dim/README_zh-CN.md
index 4683b3efc0..518dd5f49b 100644
--- a/configs/dim/README_zh-CN.md
+++ b/configs/dim/README_zh-CN.md
@@ -21,13 +21,14 @@
 -| Models | Details | MS-SSIM | SWD(xx,xx,xx,xx/avg) | Config | Download |
-| :-------------: | :------------: | :-----: | :--------------------------: | :-----------------------------------------------------------------: | :-------------------------------------------------------------------: |
-| pggan_128x128 | celeba-cropped | 0.3023 | 3.42, 4.04, 4.78, 20.38/8.15 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/pggan/pggan_8xb4-12Mimgs_celeba-cropped-128x128.py) | [model](https://download.openmmlab.com/mmgen/pggan/pggan_celeba-cropped_128_g8_20210408_181931-85a2e72c.pth) |
-| pggan_128x128 | lsun-bedroom | 0.0602 | 3.5, 2.96, 2.76, 9.65/4.72 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/pggan/pggan_8xb4-12Mimgs_lsun-bedroom-128x128.py) | [model](https://download.openmmlab.com/mmgen/pggan/pggan_lsun-bedroom_128x128_g8_20210408_182033-5e59f45d.pth) |
-| pggan_1024x1024 | celeba-hq | 0.3379 | 8.93, 3.98, 3.07, 2.64/4.655 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/pggan/pggan_8xb4-12Mimg_celeba-hq-1024x1024.py) | [model](https://download.openmmlab.com/mmgen/pggan/pggan_celeba-hq_1024_g8_20210408_181911-f1ef51c3.pth) |
+| Models | Details | MS-SSIM | SWD(xx,xx,xx,xx/avg) | Config | Download |
+| :-------------: | :------------: | :-----: | :--------------------------: | :------------------------------------------------------: | :------------------------------------------------------------------------------: |
+| pggan_128x128 | celeba-cropped | 0.3023 | 3.42, 4.04, 4.78, 20.38/8.15 | [config](./pggan_8xb4-12Mimgs_celeba-cropped-128x128.py) | [model](https://download.openmmlab.com/mmediting/pggan/pggan_celeba-cropped_128_g8_20210408_181931-85a2e72c.pth) |
+| pggan_128x128 | lsun-bedroom | 0.0602 | 3.5, 2.96, 2.76, 9.65/4.72 | [config](./pggan_8xb4-12Mimgs_lsun-bedroom-128x128.py) | [model](https://download.openmmlab.com/mmediting/pggan/pggan_lsun-bedroom_128x128_g8_20210408_182033-5e59f45d.pth) |
+| pggan_1024x1024 | celeba-hq | 0.3379 | 8.93, 3.98, 3.07, 2.64/4.655 | [config](./pggan_8xb4-12Mimg_celeba-hq-1024x1024.py) | [model](https://download.openmmlab.com/mmediting/pggan/pggan_celeba-hq_1024_g8_20210408_181911-f1ef51c3.pth) |
## Citation
diff --git a/configs/pggan/metafile.yml b/configs/pggan/metafile.yml
index 025278cbd7..52b2b08c4f 100644
--- a/configs/pggan/metafile.yml
+++ b/configs/pggan/metafile.yml
@@ -6,8 +6,11 @@ Collections:
Paper:
- https://arxiv.org/abs/1710.10196
README: configs/pggan/README.md
+ Task:
+ - unconditional gans
+ Year: 2018
Models:
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/pggan/pggan_8xb4-12Mimgs_celeba-cropped-128x128.py
+- Config: configs/pggan/pggan_8xb4-12Mimgs_celeba-cropped-128x128.py
In Collection: PGGAN
Metadata:
Training Data: CELEBA
@@ -17,8 +20,8 @@ Models:
Metrics:
MS-SSIM: 0.3023
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/pggan/pggan_celeba-cropped_128_g8_20210408_181931-85a2e72c.pth
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/pggan/pggan_8xb4-12Mimgs_lsun-bedroom-128x128.py
+ Weights: https://download.openmmlab.com/mmediting/pggan/pggan_celeba-cropped_128_g8_20210408_181931-85a2e72c.pth
+- Config: configs/pggan/pggan_8xb4-12Mimgs_lsun-bedroom-128x128.py
In Collection: PGGAN
Metadata:
Training Data: Others
@@ -28,8 +31,8 @@ Models:
Metrics:
MS-SSIM: 0.0602
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/pggan/pggan_lsun-bedroom_128x128_g8_20210408_182033-5e59f45d.pth
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/pggan/pggan_8xb4-12Mimg_celeba-hq-1024x1024.py
+ Weights: https://download.openmmlab.com/mmediting/pggan/pggan_lsun-bedroom_128x128_g8_20210408_182033-5e59f45d.pth
+- Config: configs/pggan/pggan_8xb4-12Mimg_celeba-hq-1024x1024.py
In Collection: PGGAN
Metadata:
Training Data: CELEBA
@@ -39,4 +42,4 @@ Models:
Metrics:
MS-SSIM: 0.3379
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/pggan/pggan_celeba-hq_1024_g8_20210408_181911-f1ef51c3.pth
+ Weights: https://download.openmmlab.com/mmediting/pggan/pggan_celeba-hq_1024_g8_20210408_181911-f1ef51c3.pth
diff --git a/configs/pix2pix/README.md b/configs/pix2pix/README.md
index 99636fa555..2ec6d0457a 100644
--- a/configs/pix2pix/README.md
+++ b/configs/pix2pix/README.md
@@ -2,7 +2,7 @@
> [Pix2Pix: Image-to-Image Translation with Conditional Adversarial Networks](https://openaccess.thecvf.com/content_cvpr_2017/html/Isola_Image-To-Image_Translation_With_CVPR_2017_paper.html)
-> **Task**: Image2Image Translation
+> **Task**: Image2Image
@@ -27,15 +27,17 @@ We investigate conditional adversarial networks as a general-purpose solution to
We use `FID` and `IS` metrics to evaluate the generation performance of pix2pix.1
-| Models | Dataset | FID | IS | Config | Download |
-| :----: | :---------: | :------: | :---: | :----------------------------------------------------------------------------------: | :------------------------------------------------------------------------------------: |
-| Ours | facades | 124.9773 | 1.620 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/pix2pix/pix2pix_vanilla-unet-bn_1xb1-80kiters_facades.py) | [model](https://download.openmmlab.com/mmgen/pix2pix/refactor/pix2pix_vanilla_unet_bn_1x1_80k_facades_20210902_170442-c0958d50.pth) \| [log](https://download.openmmlab.com/mmgen/pix2pix/pix2pix_vanilla_unet_bn_1x1_80k_facades_20210317_172625.log.json)2 |
-| Ours | aerial2maps | 122.5856 | 3.137 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/pix2pix/pix2pix_vanilla-unet-bn_1xb1-220kiters_aerial2maps.py) | [model](https://download.openmmlab.com/mmgen/pix2pix/refactor/pix2pix_vanilla_unet_bn_a2b_1x1_219200_maps_convert-bgr_20210902_170729-59a31517.pth) |
-| Ours | maps2aerial | 88.4635 | 3.310 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/pix2pix/pix2pix_vanilla-unet-bn_1xb1-220kiters_maps2aerial.py) | [model](https://download.openmmlab.com/mmgen/pix2pix/refactor/pix2pix_vanilla_unet_bn_b2a_1x1_219200_maps_convert-bgr_20210902_170814-6d2eac4a.pth) |
-| Ours | edges2shoes | 84.3750 | 2.815 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/pix2pix/pix2pix_vanilla-unet-bn_wo-jitter-flip-1xb4-190kiters_edges2shoes.py) | [model](https://download.openmmlab.com/mmgen/pix2pix/refactor/pix2pix_vanilla_unet_bn_wo_jitter_flip_1x4_186840_edges2shoes_convert-bgr_20210902_170902-0c828552.pth) |
+| Models | Dataset | FID | IS | Config | Download |
+| :----: | :---------: | :------: | :---: | :------------------------------------------------------------------------------: | :----------------------------------------------------------------------------------------: |
+| Ours | facades | 124.9773 | 1.620 | [config](./pix2pix_vanilla-unet-bn_1xb1-80kiters_facades.py) | [model](https://download.openmmlab.com/mmediting/pix2pix/refactor/pix2pix_vanilla_unet_bn_1x1_80k_facades_20210902_170442-c0958d50.pth) \| [log](https://download.openmmlab.com/mmediting/pix2pix/pix2pix_vanilla_unet_bn_1x1_80k_facades_20210317_172625.log.json)2 |
+| Ours | aerial2maps | 122.5856 | 3.137 | [config](./pix2pix_vanilla-unet-bn_1xb1-220kiters_aerial2maps.py) | [model](https://download.openmmlab.com/mmediting/pix2pix/refactor/pix2pix_vanilla_unet_bn_a2b_1x1_219200_maps_convert-bgr_20210902_170729-59a31517.pth) |
+| Ours | maps2aerial | 88.4635 | 3.310 | [config](./pix2pix_vanilla-unet-bn_1xb1-220kiters_maps2aerial.py) | [model](https://download.openmmlab.com/mmediting/pix2pix/refactor/pix2pix_vanilla_unet_bn_b2a_1x1_219200_maps_convert-bgr_20210902_170814-6d2eac4a.pth) |
+| Ours | edges2shoes | 84.3750 | 2.815 | [config](./pix2pix_vanilla-unet-bn_wo-jitter-flip-1xb4-190kiters_edges2shoes.py) | [model](https://download.openmmlab.com/mmediting/pix2pix/refactor/pix2pix_vanilla_unet_bn_wo_jitter_flip_1x4_186840_edges2shoes_convert-bgr_20210902_170902-0c828552.pth) |
`FID` comparison with official:
+
+
| Dataset | facades | aerial2maps | maps2aerial | edges2shoes | average |
| :------: | :---------: | :----------: | :---------: | :---------: | :----------: |
| official | **119.135** | 149.731 | 102.072 | **75.774** | 111.678 |
@@ -43,6 +45,8 @@ We use `FID` and `IS` metrics to evaluate the generation performance of pix2pix.
`IS` comparison with official:
+
+
| Dataset | facades | aerial2maps | maps2aerial | edges2shoes | average |
| :------: | :-------: | :---------: | :---------: | :---------: | :--------: |
| official | **1.650** | 2.529 | **3.552** | 2.766 | 2.624 |
diff --git a/configs/pix2pix/metafile.yml b/configs/pix2pix/metafile.yml
index 48b8c6db13..b0a321d61c 100644
--- a/configs/pix2pix/metafile.yml
+++ b/configs/pix2pix/metafile.yml
@@ -6,8 +6,11 @@ Collections:
Paper:
- https://openaccess.thecvf.com/content_cvpr_2017/html/Isola_Image-To-Image_Translation_With_CVPR_2017_paper.html
README: configs/pix2pix/README.md
+ Task:
+ - image2image
+ Year: 2017
Models:
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/pix2pix/pix2pix_vanilla-unet-bn_1xb1-80kiters_facades.py
+- Config: configs/pix2pix/pix2pix_vanilla-unet-bn_1xb1-80kiters_facades.py
In Collection: Pix2Pix
Metadata:
Training Data: FACADES
@@ -17,9 +20,9 @@ Models:
Metrics:
FID: 124.9773
IS: 1.62
- Task: Image2Image Translation
- Weights: https://download.openmmlab.com/mmgen/pix2pix/refactor/pix2pix_vanilla_unet_bn_1x1_80k_facades_20210902_170442-c0958d50.pth
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/pix2pix/pix2pix_vanilla-unet-bn_1xb1-220kiters_aerial2maps.py
+ Task: Image2Image
+ Weights: https://download.openmmlab.com/mmediting/pix2pix/refactor/pix2pix_vanilla_unet_bn_1x1_80k_facades_20210902_170442-c0958d50.pth
+- Config: configs/pix2pix/pix2pix_vanilla-unet-bn_1xb1-220kiters_aerial2maps.py
In Collection: Pix2Pix
Metadata:
Training Data: MAPS
@@ -29,9 +32,9 @@ Models:
Metrics:
FID: 122.5856
IS: 3.137
- Task: Image2Image Translation
- Weights: https://download.openmmlab.com/mmgen/pix2pix/refactor/pix2pix_vanilla_unet_bn_a2b_1x1_219200_maps_convert-bgr_20210902_170729-59a31517.pth
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/pix2pix/pix2pix_vanilla-unet-bn_1xb1-220kiters_maps2aerial.py
+ Task: Image2Image
+ Weights: https://download.openmmlab.com/mmediting/pix2pix/refactor/pix2pix_vanilla_unet_bn_a2b_1x1_219200_maps_convert-bgr_20210902_170729-59a31517.pth
+- Config: configs/pix2pix/pix2pix_vanilla-unet-bn_1xb1-220kiters_maps2aerial.py
In Collection: Pix2Pix
Metadata:
Training Data: MAPS
@@ -41,9 +44,9 @@ Models:
Metrics:
FID: 88.4635
IS: 3.31
- Task: Image2Image Translation
- Weights: https://download.openmmlab.com/mmgen/pix2pix/refactor/pix2pix_vanilla_unet_bn_b2a_1x1_219200_maps_convert-bgr_20210902_170814-6d2eac4a.pth
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/pix2pix/pix2pix_vanilla-unet-bn_wo-jitter-flip-1xb4-190kiters_edges2shoes.py
+ Task: Image2Image
+ Weights: https://download.openmmlab.com/mmediting/pix2pix/refactor/pix2pix_vanilla_unet_bn_b2a_1x1_219200_maps_convert-bgr_20210902_170814-6d2eac4a.pth
+- Config: configs/pix2pix/pix2pix_vanilla-unet-bn_wo-jitter-flip-1xb4-190kiters_edges2shoes.py
In Collection: Pix2Pix
Metadata:
Training Data: EDGES2SHOES
@@ -53,5 +56,5 @@ Models:
Metrics:
FID: 84.375
IS: 2.815
- Task: Image2Image Translation
- Weights: https://download.openmmlab.com/mmgen/pix2pix/refactor/pix2pix_vanilla_unet_bn_wo_jitter_flip_1x4_186840_edges2shoes_convert-bgr_20210902_170902-0c828552.pth
+ Task: Image2Image
+ Weights: https://download.openmmlab.com/mmediting/pix2pix/refactor/pix2pix_vanilla_unet_bn_wo_jitter_flip_1x4_186840_edges2shoes_convert-bgr_20210902_170902-0c828552.pth
diff --git a/configs/positional_encoding_in_gans/README.md b/configs/positional_encoding_in_gans/README.md
index 4301a696f5..f78e0ca7d2 100644
--- a/configs/positional_encoding_in_gans/README.md
+++ b/configs/positional_encoding_in_gans/README.md
@@ -1,4 +1,4 @@
-# Positional Encoding in GANs
+# Positional Encoding in GANs (CVPR'2021)
> [Positional Encoding as Spatial Inductive Bias in GANs](https://openaccess.thecvf.com/content/CVPR2021/html/Xu_Positional_Encoding_As_Spatial_Inductive_Bias_in_GANs_CVPR_2021_paper.html)
@@ -23,40 +23,40 @@ SinGAN shows impressive capability in learning internal patch distribution despi
+
-| Models | Details | MS-SSIM | SWD(xx,xx,xx,xx/avg) | Config | Download |
-| :-------------: | :------------: | :-----: | :--------------------------: | :-----------------------------------------------------------------: | :-------------------------------------------------------------------: |
-| pggan_128x128 | celeba-cropped | 0.3023 | 3.42, 4.04, 4.78, 20.38/8.15 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/pggan/pggan_8xb4-12Mimgs_celeba-cropped-128x128.py) | [model](https://download.openmmlab.com/mmgen/pggan/pggan_celeba-cropped_128_g8_20210408_181931-85a2e72c.pth) |
-| pggan_128x128 | lsun-bedroom | 0.0602 | 3.5, 2.96, 2.76, 9.65/4.72 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/pggan/pggan_8xb4-12Mimgs_lsun-bedroom-128x128.py) | [model](https://download.openmmlab.com/mmgen/pggan/pggan_lsun-bedroom_128x128_g8_20210408_182033-5e59f45d.pth) |
-| pggan_1024x1024 | celeba-hq | 0.3379 | 8.93, 3.98, 3.07, 2.64/4.655 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/pggan/pggan_8xb4-12Mimg_celeba-hq-1024x1024.py) | [model](https://download.openmmlab.com/mmgen/pggan/pggan_celeba-hq_1024_g8_20210408_181911-f1ef51c3.pth) |
+| Models | Details | MS-SSIM | SWD(xx,xx,xx,xx/avg) | Config | Download |
+| :-------------: | :------------: | :-----: | :--------------------------: | :------------------------------------------------------: | :------------------------------------------------------------------------------: |
+| pggan_128x128 | celeba-cropped | 0.3023 | 3.42, 4.04, 4.78, 20.38/8.15 | [config](./pggan_8xb4-12Mimgs_celeba-cropped-128x128.py) | [model](https://download.openmmlab.com/mmediting/pggan/pggan_celeba-cropped_128_g8_20210408_181931-85a2e72c.pth) |
+| pggan_128x128 | lsun-bedroom | 0.0602 | 3.5, 2.96, 2.76, 9.65/4.72 | [config](./pggan_8xb4-12Mimgs_lsun-bedroom-128x128.py) | [model](https://download.openmmlab.com/mmediting/pggan/pggan_lsun-bedroom_128x128_g8_20210408_182033-5e59f45d.pth) |
+| pggan_1024x1024 | celeba-hq | 0.3379 | 8.93, 3.98, 3.07, 2.64/4.655 | [config](./pggan_8xb4-12Mimg_celeba-hq-1024x1024.py) | [model](https://download.openmmlab.com/mmediting/pggan/pggan_celeba-hq_1024_g8_20210408_181911-f1ef51c3.pth) |
## Citation
diff --git a/configs/pggan/metafile.yml b/configs/pggan/metafile.yml
index 025278cbd7..52b2b08c4f 100644
--- a/configs/pggan/metafile.yml
+++ b/configs/pggan/metafile.yml
@@ -6,8 +6,11 @@ Collections:
Paper:
- https://arxiv.org/abs/1710.10196
README: configs/pggan/README.md
+ Task:
+ - unconditional gans
+ Year: 2018
Models:
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/pggan/pggan_8xb4-12Mimgs_celeba-cropped-128x128.py
+- Config: configs/pggan/pggan_8xb4-12Mimgs_celeba-cropped-128x128.py
In Collection: PGGAN
Metadata:
Training Data: CELEBA
@@ -17,8 +20,8 @@ Models:
Metrics:
MS-SSIM: 0.3023
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/pggan/pggan_celeba-cropped_128_g8_20210408_181931-85a2e72c.pth
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/pggan/pggan_8xb4-12Mimgs_lsun-bedroom-128x128.py
+ Weights: https://download.openmmlab.com/mmediting/pggan/pggan_celeba-cropped_128_g8_20210408_181931-85a2e72c.pth
+- Config: configs/pggan/pggan_8xb4-12Mimgs_lsun-bedroom-128x128.py
In Collection: PGGAN
Metadata:
Training Data: Others
@@ -28,8 +31,8 @@ Models:
Metrics:
MS-SSIM: 0.0602
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/pggan/pggan_lsun-bedroom_128x128_g8_20210408_182033-5e59f45d.pth
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/pggan/pggan_8xb4-12Mimg_celeba-hq-1024x1024.py
+ Weights: https://download.openmmlab.com/mmediting/pggan/pggan_lsun-bedroom_128x128_g8_20210408_182033-5e59f45d.pth
+- Config: configs/pggan/pggan_8xb4-12Mimg_celeba-hq-1024x1024.py
In Collection: PGGAN
Metadata:
Training Data: CELEBA
@@ -39,4 +42,4 @@ Models:
Metrics:
MS-SSIM: 0.3379
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/pggan/pggan_celeba-hq_1024_g8_20210408_181911-f1ef51c3.pth
+ Weights: https://download.openmmlab.com/mmediting/pggan/pggan_celeba-hq_1024_g8_20210408_181911-f1ef51c3.pth
diff --git a/configs/pix2pix/README.md b/configs/pix2pix/README.md
index 99636fa555..2ec6d0457a 100644
--- a/configs/pix2pix/README.md
+++ b/configs/pix2pix/README.md
@@ -2,7 +2,7 @@
> [Pix2Pix: Image-to-Image Translation with Conditional Adversarial Networks](https://openaccess.thecvf.com/content_cvpr_2017/html/Isola_Image-To-Image_Translation_With_CVPR_2017_paper.html)
-> **Task**: Image2Image Translation
+> **Task**: Image2Image
@@ -27,15 +27,17 @@ We investigate conditional adversarial networks as a general-purpose solution to
We use `FID` and `IS` metrics to evaluate the generation performance of pix2pix.1
-| Models | Dataset | FID | IS | Config | Download |
-| :----: | :---------: | :------: | :---: | :----------------------------------------------------------------------------------: | :------------------------------------------------------------------------------------: |
-| Ours | facades | 124.9773 | 1.620 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/pix2pix/pix2pix_vanilla-unet-bn_1xb1-80kiters_facades.py) | [model](https://download.openmmlab.com/mmgen/pix2pix/refactor/pix2pix_vanilla_unet_bn_1x1_80k_facades_20210902_170442-c0958d50.pth) \| [log](https://download.openmmlab.com/mmgen/pix2pix/pix2pix_vanilla_unet_bn_1x1_80k_facades_20210317_172625.log.json)2 |
-| Ours | aerial2maps | 122.5856 | 3.137 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/pix2pix/pix2pix_vanilla-unet-bn_1xb1-220kiters_aerial2maps.py) | [model](https://download.openmmlab.com/mmgen/pix2pix/refactor/pix2pix_vanilla_unet_bn_a2b_1x1_219200_maps_convert-bgr_20210902_170729-59a31517.pth) |
-| Ours | maps2aerial | 88.4635 | 3.310 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/pix2pix/pix2pix_vanilla-unet-bn_1xb1-220kiters_maps2aerial.py) | [model](https://download.openmmlab.com/mmgen/pix2pix/refactor/pix2pix_vanilla_unet_bn_b2a_1x1_219200_maps_convert-bgr_20210902_170814-6d2eac4a.pth) |
-| Ours | edges2shoes | 84.3750 | 2.815 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/pix2pix/pix2pix_vanilla-unet-bn_wo-jitter-flip-1xb4-190kiters_edges2shoes.py) | [model](https://download.openmmlab.com/mmgen/pix2pix/refactor/pix2pix_vanilla_unet_bn_wo_jitter_flip_1x4_186840_edges2shoes_convert-bgr_20210902_170902-0c828552.pth) |
+| Models | Dataset | FID | IS | Config | Download |
+| :----: | :---------: | :------: | :---: | :------------------------------------------------------------------------------: | :----------------------------------------------------------------------------------------: |
+| Ours | facades | 124.9773 | 1.620 | [config](./pix2pix_vanilla-unet-bn_1xb1-80kiters_facades.py) | [model](https://download.openmmlab.com/mmediting/pix2pix/refactor/pix2pix_vanilla_unet_bn_1x1_80k_facades_20210902_170442-c0958d50.pth) \| [log](https://download.openmmlab.com/mmediting/pix2pix/pix2pix_vanilla_unet_bn_1x1_80k_facades_20210317_172625.log.json)2 |
+| Ours | aerial2maps | 122.5856 | 3.137 | [config](./pix2pix_vanilla-unet-bn_1xb1-220kiters_aerial2maps.py) | [model](https://download.openmmlab.com/mmediting/pix2pix/refactor/pix2pix_vanilla_unet_bn_a2b_1x1_219200_maps_convert-bgr_20210902_170729-59a31517.pth) |
+| Ours | maps2aerial | 88.4635 | 3.310 | [config](./pix2pix_vanilla-unet-bn_1xb1-220kiters_maps2aerial.py) | [model](https://download.openmmlab.com/mmediting/pix2pix/refactor/pix2pix_vanilla_unet_bn_b2a_1x1_219200_maps_convert-bgr_20210902_170814-6d2eac4a.pth) |
+| Ours | edges2shoes | 84.3750 | 2.815 | [config](./pix2pix_vanilla-unet-bn_wo-jitter-flip-1xb4-190kiters_edges2shoes.py) | [model](https://download.openmmlab.com/mmediting/pix2pix/refactor/pix2pix_vanilla_unet_bn_wo_jitter_flip_1x4_186840_edges2shoes_convert-bgr_20210902_170902-0c828552.pth) |
`FID` comparison with official:
+
+
| Dataset | facades | aerial2maps | maps2aerial | edges2shoes | average |
| :------: | :---------: | :----------: | :---------: | :---------: | :----------: |
| official | **119.135** | 149.731 | 102.072 | **75.774** | 111.678 |
@@ -43,6 +45,8 @@ We use `FID` and `IS` metrics to evaluate the generation performance of pix2pix.
`IS` comparison with official:
+
+
| Dataset | facades | aerial2maps | maps2aerial | edges2shoes | average |
| :------: | :-------: | :---------: | :---------: | :---------: | :--------: |
| official | **1.650** | 2.529 | **3.552** | 2.766 | 2.624 |
diff --git a/configs/pix2pix/metafile.yml b/configs/pix2pix/metafile.yml
index 48b8c6db13..b0a321d61c 100644
--- a/configs/pix2pix/metafile.yml
+++ b/configs/pix2pix/metafile.yml
@@ -6,8 +6,11 @@ Collections:
Paper:
- https://openaccess.thecvf.com/content_cvpr_2017/html/Isola_Image-To-Image_Translation_With_CVPR_2017_paper.html
README: configs/pix2pix/README.md
+ Task:
+ - image2image
+ Year: 2017
Models:
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/pix2pix/pix2pix_vanilla-unet-bn_1xb1-80kiters_facades.py
+- Config: configs/pix2pix/pix2pix_vanilla-unet-bn_1xb1-80kiters_facades.py
In Collection: Pix2Pix
Metadata:
Training Data: FACADES
@@ -17,9 +20,9 @@ Models:
Metrics:
FID: 124.9773
IS: 1.62
- Task: Image2Image Translation
- Weights: https://download.openmmlab.com/mmgen/pix2pix/refactor/pix2pix_vanilla_unet_bn_1x1_80k_facades_20210902_170442-c0958d50.pth
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/pix2pix/pix2pix_vanilla-unet-bn_1xb1-220kiters_aerial2maps.py
+ Task: Image2Image
+ Weights: https://download.openmmlab.com/mmediting/pix2pix/refactor/pix2pix_vanilla_unet_bn_1x1_80k_facades_20210902_170442-c0958d50.pth
+- Config: configs/pix2pix/pix2pix_vanilla-unet-bn_1xb1-220kiters_aerial2maps.py
In Collection: Pix2Pix
Metadata:
Training Data: MAPS
@@ -29,9 +32,9 @@ Models:
Metrics:
FID: 122.5856
IS: 3.137
- Task: Image2Image Translation
- Weights: https://download.openmmlab.com/mmgen/pix2pix/refactor/pix2pix_vanilla_unet_bn_a2b_1x1_219200_maps_convert-bgr_20210902_170729-59a31517.pth
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/pix2pix/pix2pix_vanilla-unet-bn_1xb1-220kiters_maps2aerial.py
+ Task: Image2Image
+ Weights: https://download.openmmlab.com/mmediting/pix2pix/refactor/pix2pix_vanilla_unet_bn_a2b_1x1_219200_maps_convert-bgr_20210902_170729-59a31517.pth
+- Config: configs/pix2pix/pix2pix_vanilla-unet-bn_1xb1-220kiters_maps2aerial.py
In Collection: Pix2Pix
Metadata:
Training Data: MAPS
@@ -41,9 +44,9 @@ Models:
Metrics:
FID: 88.4635
IS: 3.31
- Task: Image2Image Translation
- Weights: https://download.openmmlab.com/mmgen/pix2pix/refactor/pix2pix_vanilla_unet_bn_b2a_1x1_219200_maps_convert-bgr_20210902_170814-6d2eac4a.pth
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/pix2pix/pix2pix_vanilla-unet-bn_wo-jitter-flip-1xb4-190kiters_edges2shoes.py
+ Task: Image2Image
+ Weights: https://download.openmmlab.com/mmediting/pix2pix/refactor/pix2pix_vanilla_unet_bn_b2a_1x1_219200_maps_convert-bgr_20210902_170814-6d2eac4a.pth
+- Config: configs/pix2pix/pix2pix_vanilla-unet-bn_wo-jitter-flip-1xb4-190kiters_edges2shoes.py
In Collection: Pix2Pix
Metadata:
Training Data: EDGES2SHOES
@@ -53,5 +56,5 @@ Models:
Metrics:
FID: 84.375
IS: 2.815
- Task: Image2Image Translation
- Weights: https://download.openmmlab.com/mmgen/pix2pix/refactor/pix2pix_vanilla_unet_bn_wo_jitter_flip_1x4_186840_edges2shoes_convert-bgr_20210902_170902-0c828552.pth
+ Task: Image2Image
+ Weights: https://download.openmmlab.com/mmediting/pix2pix/refactor/pix2pix_vanilla_unet_bn_wo_jitter_flip_1x4_186840_edges2shoes_convert-bgr_20210902_170902-0c828552.pth
diff --git a/configs/positional_encoding_in_gans/README.md b/configs/positional_encoding_in_gans/README.md
index 4301a696f5..f78e0ca7d2 100644
--- a/configs/positional_encoding_in_gans/README.md
+++ b/configs/positional_encoding_in_gans/README.md
@@ -1,4 +1,4 @@
-# Positional Encoding in GANs
+# Positional Encoding in GANs (CVPR'2021)
> [Positional Encoding as Spatial Inductive Bias in GANs](https://openaccess.thecvf.com/content/CVPR2021/html/Xu_Positional_Encoding_As_Spatial_Inductive_Bias_in_GANs_CVPR_2021_paper.html)
@@ -23,40 +23,40 @@ SinGAN shows impressive capability in learning internal patch distribution despi
+
 +
+
+
+ -| Models | Data | Num Scales | Config | Download |
-| :----: | :---------------------------------------------------------: | :--------: | :-----------------------------------------------------------: | :--------------------------------------------------------------: |
-| SinGAN | [balloons.png](https://download.openmmlab.com/mmgen/dataset/singan/balloons.png) | 8 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/singan/singan_balloons.py) | [ckpt](https://download.openmmlab.com/mmgen/singan/singan_balloons_20210406_191047-8fcd94cf.pth) \| [pkl](https://download.openmmlab.com/mmgen/singan/singan_balloons_20210406_191047-8fcd94cf.pkl) |
-| SinGAN | [fish.jpg](https://download.openmmlab.com/mmgen/dataset/singan/fish-crop.jpg) | 10 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/singan/singan_fish.py) | [ckpt](https://download.openmmlab.com/mmgen/singan/singan_fis_20210406_201006-860d91b6.pth) \| [pkl](https://download.openmmlab.com/mmgen/singan/singan_fis_20210406_201006-860d91b6.pkl) |
-| SinGAN | [bohemian.png](https://download.openmmlab.com/mmgen/dataset/singan/bohemian.png) | 10 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/singan/singan_bohemian.py) | [ckpt](https://download.openmmlab.com/mmgen/singan/singan_bohemian_20210406_175439-f964ee38.pth) \| [pkl](https://download.openmmlab.com/mmgen/singan/singan_bohemian_20210406_175439-f964ee38.pkl) |
+| Models | Data | Num Scales | Config | Download |
+| :----: | :-------------------------------------------------------------------------: | :--------: | :----------------------------: | :-----------------------------------------------------------------------------: |
+| SinGAN | [balloons.png](https://download.openmmlab.com/mmediting/dataset/singan/balloons.png) | 8 | [config](./singan_balloons.py) | [ckpt](https://download.openmmlab.com/mmediting/singan/singan_balloons_20210406_191047-8fcd94cf.pth) \| [pkl](https://download.openmmlab.com/mmediting/singan/singan_balloons_20210406_191047-8fcd94cf.pkl) |
+| SinGAN | [fish.jpg](https://download.openmmlab.com/mmediting/dataset/singan/fish-crop.jpg) | 10 | [config](./singan_fish.py) | [ckpt](https://download.openmmlab.com/mmediting/singan/singan_fis_20210406_201006-860d91b6.pth) \| [pkl](https://download.openmmlab.com/mmediting/singan/singan_fis_20210406_201006-860d91b6.pkl) |
+| SinGAN | [bohemian.png](https://download.openmmlab.com/mmediting/dataset/singan/bohemian.png) | 10 | [config](./singan_bohemian.py) | [ckpt](https://download.openmmlab.com/mmediting/singan/singan_bohemian_20210406_175439-f964ee38.pth) \| [pkl](https://download.openmmlab.com/mmediting/singan/singan_bohemian_20210406_175439-f964ee38.pkl) |
## Notes for using SinGAN
diff --git a/configs/singan/metafile.yml b/configs/singan/metafile.yml
index 1f83fe0814..5cae1250b7 100644
--- a/configs/singan/metafile.yml
+++ b/configs/singan/metafile.yml
@@ -6,8 +6,11 @@ Collections:
Paper:
- https://openaccess.thecvf.com/content_ICCV_2019/html/Shaham_SinGAN_Learning_a_Generative_Model_From_a_Single_Natural_Image_ICCV_2019_paper.html
README: configs/singan/README.md
+ Task:
+ - internal learning
+ Year: 2019
Models:
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/singan/singan_balloons.py
+- Config: configs/singan/singan_balloons.py
In Collection: SinGAN
Metadata:
Training Data: Others
@@ -17,8 +20,8 @@ Models:
Metrics:
Num Scales: 8.0
Task: Internal Learning
- Weights: https://download.openmmlab.com/mmgen/singan/singan_balloons_20210406_191047-8fcd94cf.pth
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/singan/singan_fish.py
+ Weights: https://download.openmmlab.com/mmediting/singan/singan_balloons_20210406_191047-8fcd94cf.pth
+- Config: configs/singan/singan_fish.py
In Collection: SinGAN
Metadata:
Training Data: Others
@@ -28,8 +31,8 @@ Models:
Metrics:
Num Scales: 10.0
Task: Internal Learning
- Weights: https://download.openmmlab.com/mmgen/singan/singan_fis_20210406_201006-860d91b6.pth
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/singan/singan_bohemian.py
+ Weights: https://download.openmmlab.com/mmediting/singan/singan_fis_20210406_201006-860d91b6.pth
+- Config: configs/singan/singan_bohemian.py
In Collection: SinGAN
Metadata:
Training Data: Others
@@ -39,4 +42,4 @@ Models:
Metrics:
Num Scales: 10.0
Task: Internal Learning
- Weights: https://download.openmmlab.com/mmgen/singan/singan_bohemian_20210406_175439-f964ee38.pth
+ Weights: https://download.openmmlab.com/mmediting/singan/singan_bohemian_20210406_175439-f964ee38.pth
diff --git a/configs/sngan_proj/README.md b/configs/sngan_proj/README.md
index 8f3e4c0bec..adfda64dfc 100644
--- a/configs/sngan_proj/README.md
+++ b/configs/sngan_proj/README.md
@@ -29,14 +29,14 @@ One of the challenges in the study of generative adversarial networks is the ins
| Models | Dataset | Inplace ReLU | disc_step | Total Iters\* | Iter | IS | FID | Config | Download | Log |
| :--------------------------------: | :------: | :----------: | :-------: | :-----------: | :----: | :-----: | :-----: | :---------------------------------: | :-----------------------------------: | :------------------------------: |
-| SNGAN_Proj-32x32-woInplaceReLU Best IS | CIFAR10 | w/o | 5 | 500000 | 400000 | 9.6919 | 9.8203 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/sngan_proj/sngan-proj_woReLUinplace_lr2e-4-ndisc5-1xb64_cifar10-32x32.py) | [ckpt](https://download.openmmlab.com/mmgen/sngan_proj/sngan_proj_cifar10_32_lr-2e-4_b64x1_woReLUinplace_is-iter400000_20210709_163823-902ce1ae.pth) | [Log](https://download.openmmlab.com/mmgen/sngan_proj/sngan_proj_cifar10_32_lr-2e-4_b64x1_woReLUinplace_20210624_065306_fid-ba0862a0_is-902ce1ae.json) |
-| SNGAN_Proj-32x32-woInplaceReLU Best FID | CIFAR10 | w/o | 5 | 500000 | 490000 | 9.5659 | 8.1158 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/sngan_proj/sngan-proj_woReLUinplace_lr2e-4-ndisc5-1xb64_cifar10-32x32.py) | [ckpt](https://download.openmmlab.com/mmgen/sngan_proj/sngan_proj_cifar10_32_lr-2e-4_b64x1_woReLUinplace_fid-iter490000_20210709_163329-ba0862a0.pth) | [Log](https://download.openmmlab.com/mmgen/sngan_proj/sngan_proj_cifar10_32_lr-2e-4_b64x1_woReLUinplace_20210624_065306_fid-ba0862a0_is-902ce1ae.json) |
-| SNGAN_Proj-32x32-wInplaceReLU Best IS | CIFAR10 | w | 5 | 500000 | 490000 | 9.5564 | 8.3462 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/sngan_proj/sngan-proj_wReLUinplace_lr2e-4-ndisc5-1xb64_cifar10-32x32.py) | [ckpt](https://download.openmmlab.com/mmgen/sngan_proj/sngan_proj_cifar10_32_lr-2e-4_b64x1_wReLUinplace_is-iter490000_20210709_202230-cd863c74.pth) | [Log](https://download.openmmlab.com/mmgen/sngan_proj/sngan_proj_cifar10_32_lr-2e-4_b64x1_wReLUinplace_20210624_065306_fid-ba0862a0_is-902ce1ae.json) |
-| SNGAN_Proj-32x32-wInplaceReLU Best FID | CIFAR10 | w | 5 | 500000 | 490000 | 9.5564 | 8.3462 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/sngan_proj/sngan-proj_wReLUinplace_lr2e-4-ndisc5-1xb64_cifar10-32x32.py) | [ckpt](https://download.openmmlab.com/mmgen/sngan_proj/sngan_proj_cifar10_32_lr-2e-4-b64x1_wReLUinplace_fid-iter490000_20210709_203038-191b2648.pth) | [Log](https://download.openmmlab.com/mmgen/sngan_proj/sngan_proj_cifar10_32_lr-2e-4_b64x1_wReLUinplace_20210624_065306_fid-ba0862a0_is-902ce1ae.json) |
-| SNGAN_Proj-128x128-woInplaceReLU Best IS | ImageNet | w/o | 5 | 1000000 | 952000 | 30.0651 | 33.4682 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/sngan_proj/sngan-proj_woReLUinplace_Glr2e-4_Dlr5e-5_ndisc5-2xb128_imagenet1k-128x128.py) | [ckpt](https://download.openmmlab.com/mmgen/sngan_proj/sngan_proj_imagenet1k_128_Glr2e-4_Dlr5e-5_ndisc5_b128x2_woReLUinplace_is-iter952000_20210730_132027-9c884a21.pth) | [Log](https://download.openmmlab.com/mmgen/sngan_proj/sngan_proj_imagenet1k_128_Glr2e-4_Dlr5e-5_ndisc5_b128x2_woReLUinplace_20210730_131424_fid-061bf803_is-9c884a21.json) |
-| SNGAN_Proj-128x128-woInplaceReLU Best FID | ImageNet | w/o | 5 | 1000000 | 989000 | 29.5779 | 32.6193 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/sngan_proj/sngan-proj_woReLUinplace_Glr2e-4_Dlr5e-5_ndisc5-2xb128_imagenet1k-128x128.py) | [ckpt](https://download.openmmlab.com/mmgen/sngan_proj/sngan_proj_imagenet1k_128_Glr2e-4_Dlr5e-5_ndisc5_b128x2_woReLUinplace_fid-iter988000_20210730_131424-061bf803.pth) | [Log](https://download.openmmlab.com/mmgen/sngan_proj/sngan_proj_imagenet1k_128_Glr2e-4_Dlr5e-5_ndisc5_b128x2_woReLUinplace_20210730_131424_fid-061bf803_is-9c884a21.json) |
-| SNGAN_Proj-128x128-wInplaceReLU Best IS | ImageNet | w | 5 | 1000000 | 944000 | 28.1799 | 34.3383 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/sngan_proj/sngan-proj_wReLUinplace_Glr2e-4_Dlr5e-5_ndisc5-2xb128_imagenet1k-128x128.py) | [ckpt](https://download.openmmlab.com/mmgen/sngan_proj/sngan_proj_imagenet1k_128_Glr2e-4_Dlr5e-5_ndisc5_b128x2_wReLUinplace_is-iter944000_20210730_132714-ca0ccd07.pth) | [Log](https://download.openmmlab.com/mmgen/sngan_proj/sngan_proj_imagenet1k_128_Glr2e-4_Dlr5e-5_ndisc5_b128x2_wReLUinplace_20210730_132401_fid-9a682411_is-ca0ccd07.json) |
-| SNGAN_Proj-128x128-wInplaceReLU Best FID | ImageNet | w | 5 | 1000000 | 988000 | 27.7948 | 33.4821 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/sngan_proj/sngan-proj_wReLUinplace_Glr2e-4_Dlr5e-5_ndisc5-2xb128_imagenet1k-128x128.py) | [ckpt](https://download.openmmlab.com/mmgen/sngan_proj/sngan_proj_imagenet1k_128_Glr2e-4_Dlr5e-5_ndisc5_b128x2_wReLUinplace_fid-iter988000_20210730_132401-9a682411.pth) | [Log](https://download.openmmlab.com/mmgen/sngan_proj/sngan_proj_imagenet1k_128_Glr2e-4_Dlr5e-5_ndisc5_b128x2_wReLUinplace_20210730_132401_fid-9a682411_is-ca0ccd07.json) |
+| SNGAN_Proj-32x32-woInplaceReLU Best IS | CIFAR10 | w/o | 5 | 500000 | 400000 | 9.6919 | 9.8203 | [config](./sngan-proj_woReLUinplace_lr2e-4-ndisc5-1xb64_cifar10-32x32.py) | [ckpt](https://download.openmmlab.com/mmediting/sngan_proj/sngan_proj_cifar10_32_lr-2e-4_b64x1_woReLUinplace_is-iter400000_20210709_163823-902ce1ae.pth) | [Log](https://download.openmmlab.com/mmediting/sngan_proj/sngan_proj_cifar10_32_lr-2e-4_b64x1_woReLUinplace_20210624_065306_fid-ba0862a0_is-902ce1ae.json) |
+| SNGAN_Proj-32x32-woInplaceReLU Best FID | CIFAR10 | w/o | 5 | 500000 | 490000 | 9.5659 | 8.1158 | [config](./sngan-proj_woReLUinplace_lr2e-4-ndisc5-1xb64_cifar10-32x32.py) | [ckpt](https://download.openmmlab.com/mmediting/sngan_proj/sngan_proj_cifar10_32_lr-2e-4_b64x1_woReLUinplace_fid-iter490000_20210709_163329-ba0862a0.pth) | [Log](https://download.openmmlab.com/mmediting/sngan_proj/sngan_proj_cifar10_32_lr-2e-4_b64x1_woReLUinplace_20210624_065306_fid-ba0862a0_is-902ce1ae.json) |
+| SNGAN_Proj-32x32-wInplaceReLU Best IS | CIFAR10 | w | 5 | 500000 | 490000 | 9.5564 | 8.3462 | [config](./sngan-proj_wReLUinplace_lr2e-4-ndisc5-1xb64_cifar10-32x32.py) | [ckpt](https://download.openmmlab.com/mmediting/sngan_proj/sngan_proj_cifar10_32_lr-2e-4_b64x1_wReLUinplace_is-iter490000_20210709_202230-cd863c74.pth) | [Log](https://download.openmmlab.com/mmediting/sngan_proj/sngan_proj_cifar10_32_lr-2e-4_b64x1_wReLUinplace_20210624_063454_is-cd863c74_fid-191b2648.json) |
+| SNGAN_Proj-32x32-wInplaceReLU Best FID | CIFAR10 | w | 5 | 500000 | 490000 | 9.5564 | 8.3462 | [config](./sngan-proj_wReLUinplace_lr2e-4-ndisc5-1xb64_cifar10-32x32.py) | [ckpt](https://download.openmmlab.com/mmediting/sngan_proj/sngan_proj_cifar10_32_lr-2e-4-b64x1_wReLUinplace_fid-iter490000_20210709_203038-191b2648.pth) | [Log](https://download.openmmlab.com/mmediting/sngan_proj/sngan_proj_cifar10_32_lr-2e-4_b64x1_wReLUinplace_20210624_063454_is-cd863c74_fid-191b2648.json) |
+| SNGAN_Proj-128x128-woInplaceReLU Best IS | ImageNet | w/o | 5 | 1000000 | 952000 | 30.0651 | 33.4682 | [config](./sngan-proj_woReLUinplace_Glr2e-4_Dlr5e-5_ndisc5-2xb128_imagenet1k-128x128.py) | [ckpt](https://download.openmmlab.com/mmediting/sngan_proj/sngan_proj_imagenet1k_128_Glr2e-4_Dlr5e-5_ndisc5_b128x2_woReLUinplace_is-iter952000_20210730_132027-9c884a21.pth) | [Log](https://download.openmmlab.com/mmediting/sngan_proj/sngan_proj_imagenet1k_128_Glr2e-4_Dlr5e-5_ndisc5_b128x2_woReLUinplace_20210730_131424_fid-061bf803_is-9c884a21.json) |
+| SNGAN_Proj-128x128-woInplaceReLU Best FID | ImageNet | w/o | 5 | 1000000 | 989000 | 29.5779 | 32.6193 | [config](./sngan-proj_woReLUinplace_Glr2e-4_Dlr5e-5_ndisc5-2xb128_imagenet1k-128x128.py) | [ckpt](https://download.openmmlab.com/mmediting/sngan_proj/sngan_proj_imagenet1k_128_Glr2e-4_Dlr5e-5_ndisc5_b128x2_woReLUinplace_fid-iter988000_20210730_131424-061bf803.pth) | [Log](https://download.openmmlab.com/mmediting/sngan_proj/sngan_proj_imagenet1k_128_Glr2e-4_Dlr5e-5_ndisc5_b128x2_woReLUinplace_20210730_131424_fid-061bf803_is-9c884a21.json) |
+| SNGAN_Proj-128x128-wInplaceReLU Best IS | ImageNet | w | 5 | 1000000 | 944000 | 28.1799 | 34.3383 | [config](./sngan-proj_wReLUinplace_Glr2e-4_Dlr5e-5_ndisc5-2xb128_imagenet1k-128x128.py) | [ckpt](https://download.openmmlab.com/mmediting/sngan_proj/sngan_proj_imagenet1k_128_Glr2e-4_Dlr5e-5_ndisc5_b128x2_wReLUinplace_is-iter944000_20210730_132714-ca0ccd07.pth) | [Log](https://download.openmmlab.com/mmediting/sngan_proj/sngan_proj_imagenet1k_128_Glr2e-4_Dlr5e-5_ndisc5_b128x2_wReLUinplace_20210730_132401_fid-9a682411_is-ca0ccd07.json) |
+| SNGAN_Proj-128x128-wInplaceReLU Best FID | ImageNet | w | 5 | 1000000 | 988000 | 27.7948 | 33.4821 | [config](./sngan-proj_wReLUinplace_Glr2e-4_Dlr5e-5_ndisc5-2xb128_imagenet1k-128x128.py) | [ckpt](https://download.openmmlab.com/mmediting/sngan_proj/sngan_proj_imagenet1k_128_Glr2e-4_Dlr5e-5_ndisc5_b128x2_wReLUinplace_fid-iter988000_20210730_132401-9a682411.pth) | [Log](https://download.openmmlab.com/mmediting/sngan_proj/sngan_proj_imagenet1k_128_Glr2e-4_Dlr5e-5_ndisc5_b128x2_wReLUinplace_20210730_132401_fid-9a682411_is-ca0ccd07.json) |
'\*' Iteration counting rule in our implementation is different from others. If you want to align with other codebases, you can use the following conversion formula:
@@ -49,8 +49,8 @@ To be noted that, in Pytorch Studio GAN, **inplace ReLU** is used in generator a
| Models | Dataset | Inplace ReLU | disc_step | Total Iters | IS (Our Pipeline) | FID (Our Pipeline) | IS (StudioGAN) | FID (StudioGAN) | Config | Download | Original Download link |
| :-----------------: | :------: | :----------: | :-------: | :---------: | :---------------: | :----------------: | :------------: | :-------------: | :-----------------: | :--------------------: | :----------------------------------: |
-| SAGAN_Proj-32x32 StudioGAN | CIFAR10 | w | 5 | 100000 | 9.372 | 10.2011 | 8.677 | 13.248 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/sngan_proj/sngan-proj-cvt-studioGAN_cifar10-32x32.py) | [model](https://download.openmmlab.com/mmgen/sngan_proj/sngan_cifar10_convert-studio-rgb_20210709_111346-2979202d.pth) | [model](https://drive.google.com/drive/folders/16s5Cr-V-NlfLyy_uyXEkoNxLBt-8wYSM) |
-| SAGAN_Proj-128x128 StudioGAN | ImageNet | w | 2 | 1000000 | 30.218 | 29.8199 | 32.247 | 26.792 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/sngan_proj/sngan-proj-cvt-studioGAN_imagenet1k-128x128.py) | [model](https://download.openmmlab.com/mmgen/sngan_proj/sngan_imagenet1k_convert-studio-rgb_20210709_111406-877b1130.pth) | [model](https://drive.google.com/drive/folders/1Ek2wAMlxpajL_M8aub4DKQ9B313K8XhS) |
+| SAGAN_Proj-32x32 StudioGAN | CIFAR10 | w | 5 | 100000 | 9.372 | 10.2011 | 8.677 | 13.248 | [config](./sngan-proj-cvt-studioGAN_cifar10-32x32.py) | [model](https://download.openmmlab.com/mmediting/sngan_proj/sngan_cifar10_convert-studio-rgb_20210709_111346-2979202d.pth) | [model](https://drive.google.com/drive/folders/16s5Cr-V-NlfLyy_uyXEkoNxLBt-8wYSM) |
+| SAGAN_Proj-128x128 StudioGAN | ImageNet | w | 2 | 1000000 | 30.218 | 29.8199 | 32.247 | 26.792 | [config](./sngan-proj-cvt-studioGAN_imagenet1k-128x128.py) | [model](https://download.openmmlab.com/mmediting/sngan_proj/sngan_imagenet1k_convert-studio-rgb_20210709_111406-877b1130.pth) | [model](https://drive.google.com/drive/folders/1Ek2wAMlxpajL_M8aub4DKQ9B313K8XhS) |
- `Our Pipeline` denote results evaluated with our pipeline.
- `StudioGAN` denote results released by Pytorch-StudioGAN.
@@ -62,7 +62,7 @@ For IS metric, our implementation is different from PyTorch-Studio GAN in the fo
For FID evaluation, we follow the pipeline of [BigGAN](https://github.com/ajbrock/BigGAN-PyTorch/blob/98459431a5d618d644d54cd1e9fceb1e5045648d/calculate_inception_moments.py#L52), where the whole training set is adopted to extract inception statistics, and Pytorch Studio GAN uses 50000 randomly selected samples. Besides, we also use [Tero's Inception](https://nvlabs-fi-cdn.nvidia.com/stylegan2-ada-pytorch/pretrained/metrics/inception-2015-12-05.pt) for feature extraction.
-You can download the preprocessed inception state by the following url: [CIFAR10](https://download.openmmlab.com/mmgen/evaluation/fid_inception_pkl/cifar10.pkl) and [ImageNet1k](https://download.openmmlab.com/mmgen/evaluation/fid_inception_pkl/imagenet.pkl).
+You can download the preprocessed inception state by the following url: [CIFAR10](https://download.openmmlab.com/mmediting/evaluation/fid_inception_pkl/cifar10.pkl) and [ImageNet1k](https://download.openmmlab.com/mmediting/evaluation/fid_inception_pkl/imagenet.pkl).
You can use following commands to extract those inception states by yourself.
diff --git a/configs/sngan_proj/metafile.yml b/configs/sngan_proj/metafile.yml
index d772bd7807..b6f5067693 100644
--- a/configs/sngan_proj/metafile.yml
+++ b/configs/sngan_proj/metafile.yml
@@ -6,8 +6,11 @@ Collections:
Paper:
- https://openreview.net/forum?id=B1QRgziT-
README: configs/sngan_proj/README.md
+ Task:
+ - conditional gans
+ Year: 2018
Models:
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/sngan_proj/sngan-proj_woReLUinplace_lr2e-4-ndisc5-1xb64_cifar10-32x32.py
+- Config: configs/sngan_proj/sngan-proj_woReLUinplace_lr2e-4-ndisc5-1xb64_cifar10-32x32.py
In Collection: SNGAN
Metadata:
Training Data: Others
@@ -21,8 +24,8 @@ Models:
Total Iters\*: 500000.0
disc_step: 5.0
Task: Conditional GANs
- Weights: https://download.openmmlab.com/mmgen/sngan_proj/sngan_proj_cifar10_32_lr-2e-4_b64x1_woReLUinplace_is-iter400000_20210709_163823-902ce1ae.pth
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/sngan_proj/sngan-proj_woReLUinplace_lr2e-4-ndisc5-1xb64_cifar10-32x32.py
+ Weights: https://download.openmmlab.com/mmediting/sngan_proj/sngan_proj_cifar10_32_lr-2e-4_b64x1_woReLUinplace_is-iter400000_20210709_163823-902ce1ae.pth
+- Config: configs/sngan_proj/sngan-proj_woReLUinplace_lr2e-4-ndisc5-1xb64_cifar10-32x32.py
In Collection: SNGAN
Metadata:
Training Data: Others
@@ -36,8 +39,8 @@ Models:
Total Iters\*: 500000.0
disc_step: 5.0
Task: Conditional GANs
- Weights: https://download.openmmlab.com/mmgen/sngan_proj/sngan_proj_cifar10_32_lr-2e-4_b64x1_woReLUinplace_fid-iter490000_20210709_163329-ba0862a0.pth
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/sngan_proj/sngan-proj_wReLUinplace_lr2e-4-ndisc5-1xb64_cifar10-32x32.py
+ Weights: https://download.openmmlab.com/mmediting/sngan_proj/sngan_proj_cifar10_32_lr-2e-4_b64x1_woReLUinplace_fid-iter490000_20210709_163329-ba0862a0.pth
+- Config: configs/sngan_proj/sngan-proj_wReLUinplace_lr2e-4-ndisc5-1xb64_cifar10-32x32.py
In Collection: SNGAN
Metadata:
Training Data: Others
@@ -51,8 +54,8 @@ Models:
Total Iters\*: 500000.0
disc_step: 5.0
Task: Conditional GANs
- Weights: https://download.openmmlab.com/mmgen/sngan_proj/sngan_proj_cifar10_32_lr-2e-4_b64x1_wReLUinplace_is-iter490000_20210709_202230-cd863c74.pth
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/sngan_proj/sngan-proj_wReLUinplace_lr2e-4-ndisc5-1xb64_cifar10-32x32.py
+ Weights: https://download.openmmlab.com/mmediting/sngan_proj/sngan_proj_cifar10_32_lr-2e-4_b64x1_wReLUinplace_is-iter490000_20210709_202230-cd863c74.pth
+- Config: configs/sngan_proj/sngan-proj_wReLUinplace_lr2e-4-ndisc5-1xb64_cifar10-32x32.py
In Collection: SNGAN
Metadata:
Training Data: Others
@@ -66,8 +69,8 @@ Models:
Total Iters\*: 500000.0
disc_step: 5.0
Task: Conditional GANs
- Weights: https://download.openmmlab.com/mmgen/sngan_proj/sngan_proj_cifar10_32_lr-2e-4-b64x1_wReLUinplace_fid-iter490000_20210709_203038-191b2648.pth
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/sngan_proj/sngan-proj_woReLUinplace_Glr2e-4_Dlr5e-5_ndisc5-2xb128_imagenet1k-128x128.py
+ Weights: https://download.openmmlab.com/mmediting/sngan_proj/sngan_proj_cifar10_32_lr-2e-4-b64x1_wReLUinplace_fid-iter490000_20210709_203038-191b2648.pth
+- Config: configs/sngan_proj/sngan-proj_woReLUinplace_Glr2e-4_Dlr5e-5_ndisc5-2xb128_imagenet1k-128x128.py
In Collection: SNGAN
Metadata:
Training Data: Others
@@ -81,8 +84,8 @@ Models:
Total Iters\*: 1000000.0
disc_step: 5.0
Task: Conditional GANs
- Weights: https://download.openmmlab.com/mmgen/sngan_proj/sngan_proj_imagenet1k_128_Glr2e-4_Dlr5e-5_ndisc5_b128x2_woReLUinplace_is-iter952000_20210730_132027-9c884a21.pth
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/sngan_proj/sngan-proj_woReLUinplace_Glr2e-4_Dlr5e-5_ndisc5-2xb128_imagenet1k-128x128.py
+ Weights: https://download.openmmlab.com/mmediting/sngan_proj/sngan_proj_imagenet1k_128_Glr2e-4_Dlr5e-5_ndisc5_b128x2_woReLUinplace_is-iter952000_20210730_132027-9c884a21.pth
+- Config: configs/sngan_proj/sngan-proj_woReLUinplace_Glr2e-4_Dlr5e-5_ndisc5-2xb128_imagenet1k-128x128.py
In Collection: SNGAN
Metadata:
Training Data: Others
@@ -96,8 +99,8 @@ Models:
Total Iters\*: 1000000.0
disc_step: 5.0
Task: Conditional GANs
- Weights: https://download.openmmlab.com/mmgen/sngan_proj/sngan_proj_imagenet1k_128_Glr2e-4_Dlr5e-5_ndisc5_b128x2_woReLUinplace_fid-iter988000_20210730_131424-061bf803.pth
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/sngan_proj/sngan-proj_wReLUinplace_Glr2e-4_Dlr5e-5_ndisc5-2xb128_imagenet1k-128x128.py
+ Weights: https://download.openmmlab.com/mmediting/sngan_proj/sngan_proj_imagenet1k_128_Glr2e-4_Dlr5e-5_ndisc5_b128x2_woReLUinplace_fid-iter988000_20210730_131424-061bf803.pth
+- Config: configs/sngan_proj/sngan-proj_wReLUinplace_Glr2e-4_Dlr5e-5_ndisc5-2xb128_imagenet1k-128x128.py
In Collection: SNGAN
Metadata:
Training Data: Others
@@ -111,8 +114,8 @@ Models:
Total Iters\*: 1000000.0
disc_step: 5.0
Task: Conditional GANs
- Weights: https://download.openmmlab.com/mmgen/sngan_proj/sngan_proj_imagenet1k_128_Glr2e-4_Dlr5e-5_ndisc5_b128x2_wReLUinplace_is-iter944000_20210730_132714-ca0ccd07.pth
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/sngan_proj/sngan-proj_wReLUinplace_Glr2e-4_Dlr5e-5_ndisc5-2xb128_imagenet1k-128x128.py
+ Weights: https://download.openmmlab.com/mmediting/sngan_proj/sngan_proj_imagenet1k_128_Glr2e-4_Dlr5e-5_ndisc5_b128x2_wReLUinplace_is-iter944000_20210730_132714-ca0ccd07.pth
+- Config: configs/sngan_proj/sngan-proj_wReLUinplace_Glr2e-4_Dlr5e-5_ndisc5-2xb128_imagenet1k-128x128.py
In Collection: SNGAN
Metadata:
Training Data: Others
@@ -126,8 +129,8 @@ Models:
Total Iters\*: 1000000.0
disc_step: 5.0
Task: Conditional GANs
- Weights: https://download.openmmlab.com/mmgen/sngan_proj/sngan_proj_imagenet1k_128_Glr2e-4_Dlr5e-5_ndisc5_b128x2_wReLUinplace_fid-iter988000_20210730_132401-9a682411.pth
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/sngan_proj/sngan-proj-cvt-studioGAN_cifar10-32x32.py
+ Weights: https://download.openmmlab.com/mmediting/sngan_proj/sngan_proj_imagenet1k_128_Glr2e-4_Dlr5e-5_ndisc5_b128x2_wReLUinplace_fid-iter988000_20210730_132401-9a682411.pth
+- Config: configs/sngan_proj/sngan-proj-cvt-studioGAN_cifar10-32x32.py
In Collection: SNGAN
Metadata:
Training Data: Others
@@ -142,8 +145,8 @@ Models:
Total Iters: 100000.0
disc_step: 5.0
Task: Conditional GANs
- Weights: https://download.openmmlab.com/mmgen/sngan_proj/sngan_cifar10_convert-studio-rgb_20210709_111346-2979202d.pth
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/sngan_proj/sngan-proj-cvt-studioGAN_imagenet1k-128x128.py
+ Weights: https://download.openmmlab.com/mmediting/sngan_proj/sngan_cifar10_convert-studio-rgb_20210709_111346-2979202d.pth
+- Config: configs/sngan_proj/sngan-proj-cvt-studioGAN_imagenet1k-128x128.py
In Collection: SNGAN
Metadata:
Training Data: Others
@@ -158,4 +161,4 @@ Models:
Total Iters: 1000000.0
disc_step: 2.0
Task: Conditional GANs
- Weights: https://download.openmmlab.com/mmgen/sngan_proj/sngan_imagenet1k_convert-studio-rgb_20210709_111406-877b1130.pth
+ Weights: https://download.openmmlab.com/mmediting/sngan_proj/sngan_imagenet1k_convert-studio-rgb_20210709_111406-877b1130.pth
diff --git a/configs/srcnn/README.md b/configs/srcnn/README.md
index 990c5b9c03..520fc41da6 100644
--- a/configs/srcnn/README.md
+++ b/configs/srcnn/README.md
@@ -25,7 +25,7 @@ The metrics are `PSNR / SSIM` .
| Method | Set5 PSNR | Set14 PSNR | DIV2K PSNR | Set5 SSIM | Set14 SSIM | DIV2K SSIM | GPU Info | Download |
| :----------------------------------------------------------------: | :-------: | :--------: | :--------: | :-------: | :--------: | :--------: | :------: | :------------------------------------------------------------------: |
-| [srcnn_x4k915_1x16_1000k_div2k](/configs/srcnn/srcnn_x4k915_1xb16-1000k_div2k.py) | 28.4316 | 25.6486 | 27.7460 | 0.8099 | 0.7014 | 0.7854 | 1 | [model](https://download.openmmlab.com/mmediting/restorers/srcnn/srcnn_x4k915_1x16_1000k_div2k_20200608-4186f232.pth) \| [log](https://download.openmmlab.com/mmediting/restorers/srcnn/srcnn_x4k915_1x16_1000k_div2k_20200608_120159.log.json) |
+| [srcnn_x4k915_1x16_1000k_div2k](./srcnn_x4k915_1xb16-1000k_div2k.py) | 28.4316 | 25.6486 | 27.7460 | 0.8099 | 0.7014 | 0.7854 | 1 | [model](https://download.openmmlab.com/mmediting/restorers/srcnn/srcnn_x4k915_1x16_1000k_div2k_20200608-4186f232.pth) \| [log](https://download.openmmlab.com/mmediting/restorers/srcnn/srcnn_x4k915_1x16_1000k_div2k_20200608_120159.log.json) |
## Quick Start
diff --git a/configs/srcnn/README_zh-CN.md b/configs/srcnn/README_zh-CN.md
index 757f2c8edc..fb5cc9e83e 100644
--- a/configs/srcnn/README_zh-CN.md
+++ b/configs/srcnn/README_zh-CN.md
@@ -27,9 +27,9 @@
在 RGB 通道上进行评估,在评估之前裁剪每个边界中的 `scale` 像素。
我们使用 `PSNR` 和 `SSIM` 作为指标。
-| 算法 | Set5 | Set14 | DIV2K | GPU 信息 | 下载 |
-| :---------------------------------------------------------------------: | :--------------: | :---------------: | :--------------: | :------: | :----------------------------------------------------------------------: |
-| [srcnn_x4k915_1x16_1000k_div2k](/configs/srcnn/srcnn_x4k915_1xb16-1000k_div2k.py) | 28.4316 / 0.8099 | 25.6486 / 0.7014 | 27.7460 / 0.7854 | 1 | [模型](https://download.openmmlab.com/mmediting/restorers/srcnn/srcnn_x4k915_1x16_1000k_div2k_20200608-4186f232.pth) \| [日志](https://download.openmmlab.com/mmediting/restorers/srcnn/srcnn_x4k915_1x16_1000k_div2k_20200608_120159.log.json) |
+| 算法 | Set5 | Set14 | DIV2K | GPU 信息 | 下载 |
+| :------------------------------------------------------------------: | :--------------: | :---------------: | :--------------: | :------: | :-------------------------------------------------------------------------: |
+| [srcnn_x4k915_1x16_1000k_div2k](./srcnn_x4k915_1xb16-1000k_div2k.py) | 28.4316 / 0.8099 | 25.6486 / 0.7014 | 27.7460 / 0.7854 | 1 | [模型](https://download.openmmlab.com/mmediting/restorers/srcnn/srcnn_x4k915_1x16_1000k_div2k_20200608-4186f232.pth) \| [日志](https://download.openmmlab.com/mmediting/restorers/srcnn/srcnn_x4k915_1x16_1000k_div2k_20200608_120159.log.json) |
## 快速开始
diff --git a/configs/srcnn/metafile.yml b/configs/srcnn/metafile.yml
index 39ffe96499..778d67b92a 100644
--- a/configs/srcnn/metafile.yml
+++ b/configs/srcnn/metafile.yml
@@ -6,6 +6,9 @@ Collections:
Paper:
- https://arxiv.org/abs/1501.00092
README: configs/srcnn/README.md
+ Task:
+ - image super-resolution
+ Year: 2015
Models:
- Config: configs/srcnn/srcnn_x4k915_1xb16-1000k_div2k.py
In Collection: SRCNN
diff --git a/configs/srgan_resnet/README.md b/configs/srgan_resnet/README.md
index 3b51828e1f..b40bb093d3 100644
--- a/configs/srgan_resnet/README.md
+++ b/configs/srgan_resnet/README.md
@@ -26,8 +26,8 @@ The metrics are `PSNR / SSIM` .
| Method | Set5 PSNR | Set14 PSNR | DIV2K PSNR | Set5 SSIM | Set14 SSIM | DIV2K SSIM | GPU Info | Download |
| :----------------------------------------------------------------: | :-------: | :--------: | :--------: | :-------: | :--------: | :--------: | :------: | :------------------------------------------------------------------: |
-| [msrresnet_x4c64b16_1x16_300k_div2k](/configs/srgan_resnet/msrresnet_x4c64b16_1xb16-1000k_div2k.py) | 30.2252 | 26.7762 | 28.9748 | 0.8491 | 0.7369 | 0.8178 | 1 | [model](https://download.openmmlab.com/mmediting/restorers/srresnet_srgan/msrresnet_x4c64b16_1x16_300k_div2k_20200521-61556be5.pth) \| [log](https://download.openmmlab.com/mmediting/restorers/srresnet_srgan/msrresnet_x4c64b16_1x16_300k_div2k_20200521_110246.log.json) |
-| [srgan_x4c64b16_1x16_1000k_div2k](/configs/srgan_resnet/srgan_x4c64b16_1xb16-1000k_div2k.py) | 27.9499 | 24.7383 | 26.5697 | 0.7846 | 0.6491 | 0.7365 | 1 | [model](https://download.openmmlab.com/mmediting/restorers/srresnet_srgan/srgan_x4c64b16_1x16_1000k_div2k_20200606-a1f0810e.pth) \| [log](https://download.openmmlab.com/mmediting/restorers/srresnet_srgan/srgan_x4c64b16_1x16_1000k_div2k_20200506_191442.log.json) |
+| [msrresnet_x4c64b16_1x16_300k_div2k](./msrresnet_x4c64b16_1xb16-1000k_div2k.py) | 30.2252 | 26.7762 | 28.9748 | 0.8491 | 0.7369 | 0.8178 | 1 | [model](https://download.openmmlab.com/mmediting/restorers/srresnet_srgan/msrresnet_x4c64b16_1x16_300k_div2k_20200521-61556be5.pth) \| [log](https://download.openmmlab.com/mmediting/restorers/srresnet_srgan/msrresnet_x4c64b16_1x16_300k_div2k_20200521_110246.log.json) |
+| [srgan_x4c64b16_1x16_1000k_div2k](./srgan_x4c64b16_1xb16-1000k_div2k.py) | 27.9499 | 24.7383 | 26.5697 | 0.7846 | 0.6491 | 0.7365 | 1 | [model](https://download.openmmlab.com/mmediting/restorers/srresnet_srgan/srgan_x4c64b16_1x16_1000k_div2k_20200606-a1f0810e.pth) \| [log](https://download.openmmlab.com/mmediting/restorers/srresnet_srgan/srgan_x4c64b16_1x16_1000k_div2k_20200506_191442.log.json) |
## Quick Start
diff --git a/configs/srgan_resnet/README_zh-CN.md b/configs/srgan_resnet/README_zh-CN.md
index 5d16d8db50..3758d4c1b1 100644
--- a/configs/srgan_resnet/README_zh-CN.md
+++ b/configs/srgan_resnet/README_zh-CN.md
@@ -25,8 +25,8 @@
| 算法 | Set5 | Set14 | DIV2K | GPU 信息 | 下载 |
| :---------------------------------------------------------------------: | :---------------: | :--------------: | :--------------: | :------: | :----------------------------------------------------------------------: |
-| [msrresnet_x4c64b16_1x16_300k_div2k](/configs/srgan_resnet/msrresnet_x4c64b16_1xb16-1000k_div2k.py) | 30.2252 / 0.8491 | 26.7762 / 0.7369 | 28.9748 / 0.8178 | 1 | [模型](https://download.openmmlab.com/mmediting/restorers/srresnet_srgan/msrresnet_x4c64b16_1x16_300k_div2k_20200521-61556be5.pth) \| [日志](https://download.openmmlab.com/mmediting/restorers/srresnet_srgan/msrresnet_x4c64b16_1x16_300k_div2k_20200521_110246.log.json) |
-| [srgan_x4c64b16_1x16_1000k_div2k](/configs/srgan_resnet/srgan_x4c64b16_1xb16-1000k_div2k.py) | 27.9499 / 0.7846 | 24.7383 / 0.6491 | 26.5697 / 0.7365 | 1 | [模型](https://download.openmmlab.com/mmediting/restorers/srresnet_srgan/srgan_x4c64b16_1x16_1000k_div2k_20200606-a1f0810e.pth) \| [日志](https://download.openmmlab.com/mmediting/restorers/srresnet_srgan/srgan_x4c64b16_1x16_1000k_div2k_20200506_191442.log.json) |
+| [msrresnet_x4c64b16_1x16_300k_div2k](./msrresnet_x4c64b16_1xb16-1000k_div2k.py) | 30.2252 / 0.8491 | 26.7762 / 0.7369 | 28.9748 / 0.8178 | 1 | [模型](https://download.openmmlab.com/mmediting/restorers/srresnet_srgan/msrresnet_x4c64b16_1x16_300k_div2k_20200521-61556be5.pth) \| [日志](https://download.openmmlab.com/mmediting/restorers/srresnet_srgan/msrresnet_x4c64b16_1x16_300k_div2k_20200521_110246.log.json) |
+| [srgan_x4c64b16_1x16_1000k_div2k](./srgan_x4c64b16_1xb16-1000k_div2k.py) | 27.9499 / 0.7846 | 24.7383 / 0.6491 | 26.5697 / 0.7365 | 1 | [模型](https://download.openmmlab.com/mmediting/restorers/srresnet_srgan/srgan_x4c64b16_1x16_1000k_div2k_20200606-a1f0810e.pth) \| [日志](https://download.openmmlab.com/mmediting/restorers/srresnet_srgan/srgan_x4c64b16_1x16_1000k_div2k_20200506_191442.log.json) |
## 快速开始
diff --git a/configs/srgan_resnet/metafile.yml b/configs/srgan_resnet/metafile.yml
index bace23e8a9..c80cb0aa74 100644
--- a/configs/srgan_resnet/metafile.yml
+++ b/configs/srgan_resnet/metafile.yml
@@ -6,6 +6,9 @@ Collections:
Paper:
- https://arxiv.org/abs/1609.04802
README: configs/srgan_resnet/README.md
+ Task:
+ - image super-resolution
+ Year: 2016
Models:
- Config: configs/srgan_resnet/msrresnet_x4c64b16_1xb16-1000k_div2k.py
In Collection: SRGAN
diff --git a/configs/stable_diffusion/README.md b/configs/stable_diffusion/README.md
new file mode 100644
index 0000000000..5f11460a2e
--- /dev/null
+++ b/configs/stable_diffusion/README.md
@@ -0,0 +1,67 @@
+# Stable Diffusion (2022)
+
+> [Stable Diffusion](https://github.com/CompVis/stable-diffusion)
+
+> **Task**: Text2Image
+
+
+
+## Abstract
+
+
+
+Stable Diffusion is a latent diffusion model conditioned on the text embeddings of a CLIP text encoder, which allows you to create images from text inputs.
+
+
+
+
-| Models | Data | Num Scales | Config | Download |
-| :----: | :---------------------------------------------------------: | :--------: | :-----------------------------------------------------------: | :--------------------------------------------------------------: |
-| SinGAN | [balloons.png](https://download.openmmlab.com/mmgen/dataset/singan/balloons.png) | 8 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/singan/singan_balloons.py) | [ckpt](https://download.openmmlab.com/mmgen/singan/singan_balloons_20210406_191047-8fcd94cf.pth) \| [pkl](https://download.openmmlab.com/mmgen/singan/singan_balloons_20210406_191047-8fcd94cf.pkl) |
-| SinGAN | [fish.jpg](https://download.openmmlab.com/mmgen/dataset/singan/fish-crop.jpg) | 10 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/singan/singan_fish.py) | [ckpt](https://download.openmmlab.com/mmgen/singan/singan_fis_20210406_201006-860d91b6.pth) \| [pkl](https://download.openmmlab.com/mmgen/singan/singan_fis_20210406_201006-860d91b6.pkl) |
-| SinGAN | [bohemian.png](https://download.openmmlab.com/mmgen/dataset/singan/bohemian.png) | 10 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/singan/singan_bohemian.py) | [ckpt](https://download.openmmlab.com/mmgen/singan/singan_bohemian_20210406_175439-f964ee38.pth) \| [pkl](https://download.openmmlab.com/mmgen/singan/singan_bohemian_20210406_175439-f964ee38.pkl) |
+| Models | Data | Num Scales | Config | Download |
+| :----: | :-------------------------------------------------------------------------: | :--------: | :----------------------------: | :-----------------------------------------------------------------------------: |
+| SinGAN | [balloons.png](https://download.openmmlab.com/mmediting/dataset/singan/balloons.png) | 8 | [config](./singan_balloons.py) | [ckpt](https://download.openmmlab.com/mmediting/singan/singan_balloons_20210406_191047-8fcd94cf.pth) \| [pkl](https://download.openmmlab.com/mmediting/singan/singan_balloons_20210406_191047-8fcd94cf.pkl) |
+| SinGAN | [fish.jpg](https://download.openmmlab.com/mmediting/dataset/singan/fish-crop.jpg) | 10 | [config](./singan_fish.py) | [ckpt](https://download.openmmlab.com/mmediting/singan/singan_fis_20210406_201006-860d91b6.pth) \| [pkl](https://download.openmmlab.com/mmediting/singan/singan_fis_20210406_201006-860d91b6.pkl) |
+| SinGAN | [bohemian.png](https://download.openmmlab.com/mmediting/dataset/singan/bohemian.png) | 10 | [config](./singan_bohemian.py) | [ckpt](https://download.openmmlab.com/mmediting/singan/singan_bohemian_20210406_175439-f964ee38.pth) \| [pkl](https://download.openmmlab.com/mmediting/singan/singan_bohemian_20210406_175439-f964ee38.pkl) |
## Notes for using SinGAN
diff --git a/configs/singan/metafile.yml b/configs/singan/metafile.yml
index 1f83fe0814..5cae1250b7 100644
--- a/configs/singan/metafile.yml
+++ b/configs/singan/metafile.yml
@@ -6,8 +6,11 @@ Collections:
Paper:
- https://openaccess.thecvf.com/content_ICCV_2019/html/Shaham_SinGAN_Learning_a_Generative_Model_From_a_Single_Natural_Image_ICCV_2019_paper.html
README: configs/singan/README.md
+ Task:
+ - internal learning
+ Year: 2019
Models:
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/singan/singan_balloons.py
+- Config: configs/singan/singan_balloons.py
In Collection: SinGAN
Metadata:
Training Data: Others
@@ -17,8 +20,8 @@ Models:
Metrics:
Num Scales: 8.0
Task: Internal Learning
- Weights: https://download.openmmlab.com/mmgen/singan/singan_balloons_20210406_191047-8fcd94cf.pth
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/singan/singan_fish.py
+ Weights: https://download.openmmlab.com/mmediting/singan/singan_balloons_20210406_191047-8fcd94cf.pth
+- Config: configs/singan/singan_fish.py
In Collection: SinGAN
Metadata:
Training Data: Others
@@ -28,8 +31,8 @@ Models:
Metrics:
Num Scales: 10.0
Task: Internal Learning
- Weights: https://download.openmmlab.com/mmgen/singan/singan_fis_20210406_201006-860d91b6.pth
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/singan/singan_bohemian.py
+ Weights: https://download.openmmlab.com/mmediting/singan/singan_fis_20210406_201006-860d91b6.pth
+- Config: configs/singan/singan_bohemian.py
In Collection: SinGAN
Metadata:
Training Data: Others
@@ -39,4 +42,4 @@ Models:
Metrics:
Num Scales: 10.0
Task: Internal Learning
- Weights: https://download.openmmlab.com/mmgen/singan/singan_bohemian_20210406_175439-f964ee38.pth
+ Weights: https://download.openmmlab.com/mmediting/singan/singan_bohemian_20210406_175439-f964ee38.pth
diff --git a/configs/sngan_proj/README.md b/configs/sngan_proj/README.md
index 8f3e4c0bec..adfda64dfc 100644
--- a/configs/sngan_proj/README.md
+++ b/configs/sngan_proj/README.md
@@ -29,14 +29,14 @@ One of the challenges in the study of generative adversarial networks is the ins
| Models | Dataset | Inplace ReLU | disc_step | Total Iters\* | Iter | IS | FID | Config | Download | Log |
| :--------------------------------: | :------: | :----------: | :-------: | :-----------: | :----: | :-----: | :-----: | :---------------------------------: | :-----------------------------------: | :------------------------------: |
-| SNGAN_Proj-32x32-woInplaceReLU Best IS | CIFAR10 | w/o | 5 | 500000 | 400000 | 9.6919 | 9.8203 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/sngan_proj/sngan-proj_woReLUinplace_lr2e-4-ndisc5-1xb64_cifar10-32x32.py) | [ckpt](https://download.openmmlab.com/mmgen/sngan_proj/sngan_proj_cifar10_32_lr-2e-4_b64x1_woReLUinplace_is-iter400000_20210709_163823-902ce1ae.pth) | [Log](https://download.openmmlab.com/mmgen/sngan_proj/sngan_proj_cifar10_32_lr-2e-4_b64x1_woReLUinplace_20210624_065306_fid-ba0862a0_is-902ce1ae.json) |
-| SNGAN_Proj-32x32-woInplaceReLU Best FID | CIFAR10 | w/o | 5 | 500000 | 490000 | 9.5659 | 8.1158 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/sngan_proj/sngan-proj_woReLUinplace_lr2e-4-ndisc5-1xb64_cifar10-32x32.py) | [ckpt](https://download.openmmlab.com/mmgen/sngan_proj/sngan_proj_cifar10_32_lr-2e-4_b64x1_woReLUinplace_fid-iter490000_20210709_163329-ba0862a0.pth) | [Log](https://download.openmmlab.com/mmgen/sngan_proj/sngan_proj_cifar10_32_lr-2e-4_b64x1_woReLUinplace_20210624_065306_fid-ba0862a0_is-902ce1ae.json) |
-| SNGAN_Proj-32x32-wInplaceReLU Best IS | CIFAR10 | w | 5 | 500000 | 490000 | 9.5564 | 8.3462 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/sngan_proj/sngan-proj_wReLUinplace_lr2e-4-ndisc5-1xb64_cifar10-32x32.py) | [ckpt](https://download.openmmlab.com/mmgen/sngan_proj/sngan_proj_cifar10_32_lr-2e-4_b64x1_wReLUinplace_is-iter490000_20210709_202230-cd863c74.pth) | [Log](https://download.openmmlab.com/mmgen/sngan_proj/sngan_proj_cifar10_32_lr-2e-4_b64x1_wReLUinplace_20210624_065306_fid-ba0862a0_is-902ce1ae.json) |
-| SNGAN_Proj-32x32-wInplaceReLU Best FID | CIFAR10 | w | 5 | 500000 | 490000 | 9.5564 | 8.3462 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/sngan_proj/sngan-proj_wReLUinplace_lr2e-4-ndisc5-1xb64_cifar10-32x32.py) | [ckpt](https://download.openmmlab.com/mmgen/sngan_proj/sngan_proj_cifar10_32_lr-2e-4-b64x1_wReLUinplace_fid-iter490000_20210709_203038-191b2648.pth) | [Log](https://download.openmmlab.com/mmgen/sngan_proj/sngan_proj_cifar10_32_lr-2e-4_b64x1_wReLUinplace_20210624_065306_fid-ba0862a0_is-902ce1ae.json) |
-| SNGAN_Proj-128x128-woInplaceReLU Best IS | ImageNet | w/o | 5 | 1000000 | 952000 | 30.0651 | 33.4682 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/sngan_proj/sngan-proj_woReLUinplace_Glr2e-4_Dlr5e-5_ndisc5-2xb128_imagenet1k-128x128.py) | [ckpt](https://download.openmmlab.com/mmgen/sngan_proj/sngan_proj_imagenet1k_128_Glr2e-4_Dlr5e-5_ndisc5_b128x2_woReLUinplace_is-iter952000_20210730_132027-9c884a21.pth) | [Log](https://download.openmmlab.com/mmgen/sngan_proj/sngan_proj_imagenet1k_128_Glr2e-4_Dlr5e-5_ndisc5_b128x2_woReLUinplace_20210730_131424_fid-061bf803_is-9c884a21.json) |
-| SNGAN_Proj-128x128-woInplaceReLU Best FID | ImageNet | w/o | 5 | 1000000 | 989000 | 29.5779 | 32.6193 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/sngan_proj/sngan-proj_woReLUinplace_Glr2e-4_Dlr5e-5_ndisc5-2xb128_imagenet1k-128x128.py) | [ckpt](https://download.openmmlab.com/mmgen/sngan_proj/sngan_proj_imagenet1k_128_Glr2e-4_Dlr5e-5_ndisc5_b128x2_woReLUinplace_fid-iter988000_20210730_131424-061bf803.pth) | [Log](https://download.openmmlab.com/mmgen/sngan_proj/sngan_proj_imagenet1k_128_Glr2e-4_Dlr5e-5_ndisc5_b128x2_woReLUinplace_20210730_131424_fid-061bf803_is-9c884a21.json) |
-| SNGAN_Proj-128x128-wInplaceReLU Best IS | ImageNet | w | 5 | 1000000 | 944000 | 28.1799 | 34.3383 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/sngan_proj/sngan-proj_wReLUinplace_Glr2e-4_Dlr5e-5_ndisc5-2xb128_imagenet1k-128x128.py) | [ckpt](https://download.openmmlab.com/mmgen/sngan_proj/sngan_proj_imagenet1k_128_Glr2e-4_Dlr5e-5_ndisc5_b128x2_wReLUinplace_is-iter944000_20210730_132714-ca0ccd07.pth) | [Log](https://download.openmmlab.com/mmgen/sngan_proj/sngan_proj_imagenet1k_128_Glr2e-4_Dlr5e-5_ndisc5_b128x2_wReLUinplace_20210730_132401_fid-9a682411_is-ca0ccd07.json) |
-| SNGAN_Proj-128x128-wInplaceReLU Best FID | ImageNet | w | 5 | 1000000 | 988000 | 27.7948 | 33.4821 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/sngan_proj/sngan-proj_wReLUinplace_Glr2e-4_Dlr5e-5_ndisc5-2xb128_imagenet1k-128x128.py) | [ckpt](https://download.openmmlab.com/mmgen/sngan_proj/sngan_proj_imagenet1k_128_Glr2e-4_Dlr5e-5_ndisc5_b128x2_wReLUinplace_fid-iter988000_20210730_132401-9a682411.pth) | [Log](https://download.openmmlab.com/mmgen/sngan_proj/sngan_proj_imagenet1k_128_Glr2e-4_Dlr5e-5_ndisc5_b128x2_wReLUinplace_20210730_132401_fid-9a682411_is-ca0ccd07.json) |
+| SNGAN_Proj-32x32-woInplaceReLU Best IS | CIFAR10 | w/o | 5 | 500000 | 400000 | 9.6919 | 9.8203 | [config](./sngan-proj_woReLUinplace_lr2e-4-ndisc5-1xb64_cifar10-32x32.py) | [ckpt](https://download.openmmlab.com/mmediting/sngan_proj/sngan_proj_cifar10_32_lr-2e-4_b64x1_woReLUinplace_is-iter400000_20210709_163823-902ce1ae.pth) | [Log](https://download.openmmlab.com/mmediting/sngan_proj/sngan_proj_cifar10_32_lr-2e-4_b64x1_woReLUinplace_20210624_065306_fid-ba0862a0_is-902ce1ae.json) |
+| SNGAN_Proj-32x32-woInplaceReLU Best FID | CIFAR10 | w/o | 5 | 500000 | 490000 | 9.5659 | 8.1158 | [config](./sngan-proj_woReLUinplace_lr2e-4-ndisc5-1xb64_cifar10-32x32.py) | [ckpt](https://download.openmmlab.com/mmediting/sngan_proj/sngan_proj_cifar10_32_lr-2e-4_b64x1_woReLUinplace_fid-iter490000_20210709_163329-ba0862a0.pth) | [Log](https://download.openmmlab.com/mmediting/sngan_proj/sngan_proj_cifar10_32_lr-2e-4_b64x1_woReLUinplace_20210624_065306_fid-ba0862a0_is-902ce1ae.json) |
+| SNGAN_Proj-32x32-wInplaceReLU Best IS | CIFAR10 | w | 5 | 500000 | 490000 | 9.5564 | 8.3462 | [config](./sngan-proj_wReLUinplace_lr2e-4-ndisc5-1xb64_cifar10-32x32.py) | [ckpt](https://download.openmmlab.com/mmediting/sngan_proj/sngan_proj_cifar10_32_lr-2e-4_b64x1_wReLUinplace_is-iter490000_20210709_202230-cd863c74.pth) | [Log](https://download.openmmlab.com/mmediting/sngan_proj/sngan_proj_cifar10_32_lr-2e-4_b64x1_wReLUinplace_20210624_063454_is-cd863c74_fid-191b2648.json) |
+| SNGAN_Proj-32x32-wInplaceReLU Best FID | CIFAR10 | w | 5 | 500000 | 490000 | 9.5564 | 8.3462 | [config](./sngan-proj_wReLUinplace_lr2e-4-ndisc5-1xb64_cifar10-32x32.py) | [ckpt](https://download.openmmlab.com/mmediting/sngan_proj/sngan_proj_cifar10_32_lr-2e-4-b64x1_wReLUinplace_fid-iter490000_20210709_203038-191b2648.pth) | [Log](https://download.openmmlab.com/mmediting/sngan_proj/sngan_proj_cifar10_32_lr-2e-4_b64x1_wReLUinplace_20210624_063454_is-cd863c74_fid-191b2648.json) |
+| SNGAN_Proj-128x128-woInplaceReLU Best IS | ImageNet | w/o | 5 | 1000000 | 952000 | 30.0651 | 33.4682 | [config](./sngan-proj_woReLUinplace_Glr2e-4_Dlr5e-5_ndisc5-2xb128_imagenet1k-128x128.py) | [ckpt](https://download.openmmlab.com/mmediting/sngan_proj/sngan_proj_imagenet1k_128_Glr2e-4_Dlr5e-5_ndisc5_b128x2_woReLUinplace_is-iter952000_20210730_132027-9c884a21.pth) | [Log](https://download.openmmlab.com/mmediting/sngan_proj/sngan_proj_imagenet1k_128_Glr2e-4_Dlr5e-5_ndisc5_b128x2_woReLUinplace_20210730_131424_fid-061bf803_is-9c884a21.json) |
+| SNGAN_Proj-128x128-woInplaceReLU Best FID | ImageNet | w/o | 5 | 1000000 | 989000 | 29.5779 | 32.6193 | [config](./sngan-proj_woReLUinplace_Glr2e-4_Dlr5e-5_ndisc5-2xb128_imagenet1k-128x128.py) | [ckpt](https://download.openmmlab.com/mmediting/sngan_proj/sngan_proj_imagenet1k_128_Glr2e-4_Dlr5e-5_ndisc5_b128x2_woReLUinplace_fid-iter988000_20210730_131424-061bf803.pth) | [Log](https://download.openmmlab.com/mmediting/sngan_proj/sngan_proj_imagenet1k_128_Glr2e-4_Dlr5e-5_ndisc5_b128x2_woReLUinplace_20210730_131424_fid-061bf803_is-9c884a21.json) |
+| SNGAN_Proj-128x128-wInplaceReLU Best IS | ImageNet | w | 5 | 1000000 | 944000 | 28.1799 | 34.3383 | [config](./sngan-proj_wReLUinplace_Glr2e-4_Dlr5e-5_ndisc5-2xb128_imagenet1k-128x128.py) | [ckpt](https://download.openmmlab.com/mmediting/sngan_proj/sngan_proj_imagenet1k_128_Glr2e-4_Dlr5e-5_ndisc5_b128x2_wReLUinplace_is-iter944000_20210730_132714-ca0ccd07.pth) | [Log](https://download.openmmlab.com/mmediting/sngan_proj/sngan_proj_imagenet1k_128_Glr2e-4_Dlr5e-5_ndisc5_b128x2_wReLUinplace_20210730_132401_fid-9a682411_is-ca0ccd07.json) |
+| SNGAN_Proj-128x128-wInplaceReLU Best FID | ImageNet | w | 5 | 1000000 | 988000 | 27.7948 | 33.4821 | [config](./sngan-proj_wReLUinplace_Glr2e-4_Dlr5e-5_ndisc5-2xb128_imagenet1k-128x128.py) | [ckpt](https://download.openmmlab.com/mmediting/sngan_proj/sngan_proj_imagenet1k_128_Glr2e-4_Dlr5e-5_ndisc5_b128x2_wReLUinplace_fid-iter988000_20210730_132401-9a682411.pth) | [Log](https://download.openmmlab.com/mmediting/sngan_proj/sngan_proj_imagenet1k_128_Glr2e-4_Dlr5e-5_ndisc5_b128x2_wReLUinplace_20210730_132401_fid-9a682411_is-ca0ccd07.json) |
'\*' Iteration counting rule in our implementation is different from others. If you want to align with other codebases, you can use the following conversion formula:
@@ -49,8 +49,8 @@ To be noted that, in Pytorch Studio GAN, **inplace ReLU** is used in generator a
| Models | Dataset | Inplace ReLU | disc_step | Total Iters | IS (Our Pipeline) | FID (Our Pipeline) | IS (StudioGAN) | FID (StudioGAN) | Config | Download | Original Download link |
| :-----------------: | :------: | :----------: | :-------: | :---------: | :---------------: | :----------------: | :------------: | :-------------: | :-----------------: | :--------------------: | :----------------------------------: |
-| SAGAN_Proj-32x32 StudioGAN | CIFAR10 | w | 5 | 100000 | 9.372 | 10.2011 | 8.677 | 13.248 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/sngan_proj/sngan-proj-cvt-studioGAN_cifar10-32x32.py) | [model](https://download.openmmlab.com/mmgen/sngan_proj/sngan_cifar10_convert-studio-rgb_20210709_111346-2979202d.pth) | [model](https://drive.google.com/drive/folders/16s5Cr-V-NlfLyy_uyXEkoNxLBt-8wYSM) |
-| SAGAN_Proj-128x128 StudioGAN | ImageNet | w | 2 | 1000000 | 30.218 | 29.8199 | 32.247 | 26.792 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/sngan_proj/sngan-proj-cvt-studioGAN_imagenet1k-128x128.py) | [model](https://download.openmmlab.com/mmgen/sngan_proj/sngan_imagenet1k_convert-studio-rgb_20210709_111406-877b1130.pth) | [model](https://drive.google.com/drive/folders/1Ek2wAMlxpajL_M8aub4DKQ9B313K8XhS) |
+| SAGAN_Proj-32x32 StudioGAN | CIFAR10 | w | 5 | 100000 | 9.372 | 10.2011 | 8.677 | 13.248 | [config](./sngan-proj-cvt-studioGAN_cifar10-32x32.py) | [model](https://download.openmmlab.com/mmediting/sngan_proj/sngan_cifar10_convert-studio-rgb_20210709_111346-2979202d.pth) | [model](https://drive.google.com/drive/folders/16s5Cr-V-NlfLyy_uyXEkoNxLBt-8wYSM) |
+| SAGAN_Proj-128x128 StudioGAN | ImageNet | w | 2 | 1000000 | 30.218 | 29.8199 | 32.247 | 26.792 | [config](./sngan-proj-cvt-studioGAN_imagenet1k-128x128.py) | [model](https://download.openmmlab.com/mmediting/sngan_proj/sngan_imagenet1k_convert-studio-rgb_20210709_111406-877b1130.pth) | [model](https://drive.google.com/drive/folders/1Ek2wAMlxpajL_M8aub4DKQ9B313K8XhS) |
- `Our Pipeline` denote results evaluated with our pipeline.
- `StudioGAN` denote results released by Pytorch-StudioGAN.
@@ -62,7 +62,7 @@ For IS metric, our implementation is different from PyTorch-Studio GAN in the fo
For FID evaluation, we follow the pipeline of [BigGAN](https://github.com/ajbrock/BigGAN-PyTorch/blob/98459431a5d618d644d54cd1e9fceb1e5045648d/calculate_inception_moments.py#L52), where the whole training set is adopted to extract inception statistics, and Pytorch Studio GAN uses 50000 randomly selected samples. Besides, we also use [Tero's Inception](https://nvlabs-fi-cdn.nvidia.com/stylegan2-ada-pytorch/pretrained/metrics/inception-2015-12-05.pt) for feature extraction.
-You can download the preprocessed inception state by the following url: [CIFAR10](https://download.openmmlab.com/mmgen/evaluation/fid_inception_pkl/cifar10.pkl) and [ImageNet1k](https://download.openmmlab.com/mmgen/evaluation/fid_inception_pkl/imagenet.pkl).
+You can download the preprocessed inception state by the following url: [CIFAR10](https://download.openmmlab.com/mmediting/evaluation/fid_inception_pkl/cifar10.pkl) and [ImageNet1k](https://download.openmmlab.com/mmediting/evaluation/fid_inception_pkl/imagenet.pkl).
You can use following commands to extract those inception states by yourself.
diff --git a/configs/sngan_proj/metafile.yml b/configs/sngan_proj/metafile.yml
index d772bd7807..b6f5067693 100644
--- a/configs/sngan_proj/metafile.yml
+++ b/configs/sngan_proj/metafile.yml
@@ -6,8 +6,11 @@ Collections:
Paper:
- https://openreview.net/forum?id=B1QRgziT-
README: configs/sngan_proj/README.md
+ Task:
+ - conditional gans
+ Year: 2018
Models:
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/sngan_proj/sngan-proj_woReLUinplace_lr2e-4-ndisc5-1xb64_cifar10-32x32.py
+- Config: configs/sngan_proj/sngan-proj_woReLUinplace_lr2e-4-ndisc5-1xb64_cifar10-32x32.py
In Collection: SNGAN
Metadata:
Training Data: Others
@@ -21,8 +24,8 @@ Models:
Total Iters\*: 500000.0
disc_step: 5.0
Task: Conditional GANs
- Weights: https://download.openmmlab.com/mmgen/sngan_proj/sngan_proj_cifar10_32_lr-2e-4_b64x1_woReLUinplace_is-iter400000_20210709_163823-902ce1ae.pth
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/sngan_proj/sngan-proj_woReLUinplace_lr2e-4-ndisc5-1xb64_cifar10-32x32.py
+ Weights: https://download.openmmlab.com/mmediting/sngan_proj/sngan_proj_cifar10_32_lr-2e-4_b64x1_woReLUinplace_is-iter400000_20210709_163823-902ce1ae.pth
+- Config: configs/sngan_proj/sngan-proj_woReLUinplace_lr2e-4-ndisc5-1xb64_cifar10-32x32.py
In Collection: SNGAN
Metadata:
Training Data: Others
@@ -36,8 +39,8 @@ Models:
Total Iters\*: 500000.0
disc_step: 5.0
Task: Conditional GANs
- Weights: https://download.openmmlab.com/mmgen/sngan_proj/sngan_proj_cifar10_32_lr-2e-4_b64x1_woReLUinplace_fid-iter490000_20210709_163329-ba0862a0.pth
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/sngan_proj/sngan-proj_wReLUinplace_lr2e-4-ndisc5-1xb64_cifar10-32x32.py
+ Weights: https://download.openmmlab.com/mmediting/sngan_proj/sngan_proj_cifar10_32_lr-2e-4_b64x1_woReLUinplace_fid-iter490000_20210709_163329-ba0862a0.pth
+- Config: configs/sngan_proj/sngan-proj_wReLUinplace_lr2e-4-ndisc5-1xb64_cifar10-32x32.py
In Collection: SNGAN
Metadata:
Training Data: Others
@@ -51,8 +54,8 @@ Models:
Total Iters\*: 500000.0
disc_step: 5.0
Task: Conditional GANs
- Weights: https://download.openmmlab.com/mmgen/sngan_proj/sngan_proj_cifar10_32_lr-2e-4_b64x1_wReLUinplace_is-iter490000_20210709_202230-cd863c74.pth
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/sngan_proj/sngan-proj_wReLUinplace_lr2e-4-ndisc5-1xb64_cifar10-32x32.py
+ Weights: https://download.openmmlab.com/mmediting/sngan_proj/sngan_proj_cifar10_32_lr-2e-4_b64x1_wReLUinplace_is-iter490000_20210709_202230-cd863c74.pth
+- Config: configs/sngan_proj/sngan-proj_wReLUinplace_lr2e-4-ndisc5-1xb64_cifar10-32x32.py
In Collection: SNGAN
Metadata:
Training Data: Others
@@ -66,8 +69,8 @@ Models:
Total Iters\*: 500000.0
disc_step: 5.0
Task: Conditional GANs
- Weights: https://download.openmmlab.com/mmgen/sngan_proj/sngan_proj_cifar10_32_lr-2e-4-b64x1_wReLUinplace_fid-iter490000_20210709_203038-191b2648.pth
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/sngan_proj/sngan-proj_woReLUinplace_Glr2e-4_Dlr5e-5_ndisc5-2xb128_imagenet1k-128x128.py
+ Weights: https://download.openmmlab.com/mmediting/sngan_proj/sngan_proj_cifar10_32_lr-2e-4-b64x1_wReLUinplace_fid-iter490000_20210709_203038-191b2648.pth
+- Config: configs/sngan_proj/sngan-proj_woReLUinplace_Glr2e-4_Dlr5e-5_ndisc5-2xb128_imagenet1k-128x128.py
In Collection: SNGAN
Metadata:
Training Data: Others
@@ -81,8 +84,8 @@ Models:
Total Iters\*: 1000000.0
disc_step: 5.0
Task: Conditional GANs
- Weights: https://download.openmmlab.com/mmgen/sngan_proj/sngan_proj_imagenet1k_128_Glr2e-4_Dlr5e-5_ndisc5_b128x2_woReLUinplace_is-iter952000_20210730_132027-9c884a21.pth
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/sngan_proj/sngan-proj_woReLUinplace_Glr2e-4_Dlr5e-5_ndisc5-2xb128_imagenet1k-128x128.py
+ Weights: https://download.openmmlab.com/mmediting/sngan_proj/sngan_proj_imagenet1k_128_Glr2e-4_Dlr5e-5_ndisc5_b128x2_woReLUinplace_is-iter952000_20210730_132027-9c884a21.pth
+- Config: configs/sngan_proj/sngan-proj_woReLUinplace_Glr2e-4_Dlr5e-5_ndisc5-2xb128_imagenet1k-128x128.py
In Collection: SNGAN
Metadata:
Training Data: Others
@@ -96,8 +99,8 @@ Models:
Total Iters\*: 1000000.0
disc_step: 5.0
Task: Conditional GANs
- Weights: https://download.openmmlab.com/mmgen/sngan_proj/sngan_proj_imagenet1k_128_Glr2e-4_Dlr5e-5_ndisc5_b128x2_woReLUinplace_fid-iter988000_20210730_131424-061bf803.pth
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/sngan_proj/sngan-proj_wReLUinplace_Glr2e-4_Dlr5e-5_ndisc5-2xb128_imagenet1k-128x128.py
+ Weights: https://download.openmmlab.com/mmediting/sngan_proj/sngan_proj_imagenet1k_128_Glr2e-4_Dlr5e-5_ndisc5_b128x2_woReLUinplace_fid-iter988000_20210730_131424-061bf803.pth
+- Config: configs/sngan_proj/sngan-proj_wReLUinplace_Glr2e-4_Dlr5e-5_ndisc5-2xb128_imagenet1k-128x128.py
In Collection: SNGAN
Metadata:
Training Data: Others
@@ -111,8 +114,8 @@ Models:
Total Iters\*: 1000000.0
disc_step: 5.0
Task: Conditional GANs
- Weights: https://download.openmmlab.com/mmgen/sngan_proj/sngan_proj_imagenet1k_128_Glr2e-4_Dlr5e-5_ndisc5_b128x2_wReLUinplace_is-iter944000_20210730_132714-ca0ccd07.pth
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/sngan_proj/sngan-proj_wReLUinplace_Glr2e-4_Dlr5e-5_ndisc5-2xb128_imagenet1k-128x128.py
+ Weights: https://download.openmmlab.com/mmediting/sngan_proj/sngan_proj_imagenet1k_128_Glr2e-4_Dlr5e-5_ndisc5_b128x2_wReLUinplace_is-iter944000_20210730_132714-ca0ccd07.pth
+- Config: configs/sngan_proj/sngan-proj_wReLUinplace_Glr2e-4_Dlr5e-5_ndisc5-2xb128_imagenet1k-128x128.py
In Collection: SNGAN
Metadata:
Training Data: Others
@@ -126,8 +129,8 @@ Models:
Total Iters\*: 1000000.0
disc_step: 5.0
Task: Conditional GANs
- Weights: https://download.openmmlab.com/mmgen/sngan_proj/sngan_proj_imagenet1k_128_Glr2e-4_Dlr5e-5_ndisc5_b128x2_wReLUinplace_fid-iter988000_20210730_132401-9a682411.pth
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/sngan_proj/sngan-proj-cvt-studioGAN_cifar10-32x32.py
+ Weights: https://download.openmmlab.com/mmediting/sngan_proj/sngan_proj_imagenet1k_128_Glr2e-4_Dlr5e-5_ndisc5_b128x2_wReLUinplace_fid-iter988000_20210730_132401-9a682411.pth
+- Config: configs/sngan_proj/sngan-proj-cvt-studioGAN_cifar10-32x32.py
In Collection: SNGAN
Metadata:
Training Data: Others
@@ -142,8 +145,8 @@ Models:
Total Iters: 100000.0
disc_step: 5.0
Task: Conditional GANs
- Weights: https://download.openmmlab.com/mmgen/sngan_proj/sngan_cifar10_convert-studio-rgb_20210709_111346-2979202d.pth
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/sngan_proj/sngan-proj-cvt-studioGAN_imagenet1k-128x128.py
+ Weights: https://download.openmmlab.com/mmediting/sngan_proj/sngan_cifar10_convert-studio-rgb_20210709_111346-2979202d.pth
+- Config: configs/sngan_proj/sngan-proj-cvt-studioGAN_imagenet1k-128x128.py
In Collection: SNGAN
Metadata:
Training Data: Others
@@ -158,4 +161,4 @@ Models:
Total Iters: 1000000.0
disc_step: 2.0
Task: Conditional GANs
- Weights: https://download.openmmlab.com/mmgen/sngan_proj/sngan_imagenet1k_convert-studio-rgb_20210709_111406-877b1130.pth
+ Weights: https://download.openmmlab.com/mmediting/sngan_proj/sngan_imagenet1k_convert-studio-rgb_20210709_111406-877b1130.pth
diff --git a/configs/srcnn/README.md b/configs/srcnn/README.md
index 990c5b9c03..520fc41da6 100644
--- a/configs/srcnn/README.md
+++ b/configs/srcnn/README.md
@@ -25,7 +25,7 @@ The metrics are `PSNR / SSIM` .
| Method | Set5 PSNR | Set14 PSNR | DIV2K PSNR | Set5 SSIM | Set14 SSIM | DIV2K SSIM | GPU Info | Download |
| :----------------------------------------------------------------: | :-------: | :--------: | :--------: | :-------: | :--------: | :--------: | :------: | :------------------------------------------------------------------: |
-| [srcnn_x4k915_1x16_1000k_div2k](/configs/srcnn/srcnn_x4k915_1xb16-1000k_div2k.py) | 28.4316 | 25.6486 | 27.7460 | 0.8099 | 0.7014 | 0.7854 | 1 | [model](https://download.openmmlab.com/mmediting/restorers/srcnn/srcnn_x4k915_1x16_1000k_div2k_20200608-4186f232.pth) \| [log](https://download.openmmlab.com/mmediting/restorers/srcnn/srcnn_x4k915_1x16_1000k_div2k_20200608_120159.log.json) |
+| [srcnn_x4k915_1x16_1000k_div2k](./srcnn_x4k915_1xb16-1000k_div2k.py) | 28.4316 | 25.6486 | 27.7460 | 0.8099 | 0.7014 | 0.7854 | 1 | [model](https://download.openmmlab.com/mmediting/restorers/srcnn/srcnn_x4k915_1x16_1000k_div2k_20200608-4186f232.pth) \| [log](https://download.openmmlab.com/mmediting/restorers/srcnn/srcnn_x4k915_1x16_1000k_div2k_20200608_120159.log.json) |
## Quick Start
diff --git a/configs/srcnn/README_zh-CN.md b/configs/srcnn/README_zh-CN.md
index 757f2c8edc..fb5cc9e83e 100644
--- a/configs/srcnn/README_zh-CN.md
+++ b/configs/srcnn/README_zh-CN.md
@@ -27,9 +27,9 @@
在 RGB 通道上进行评估,在评估之前裁剪每个边界中的 `scale` 像素。
我们使用 `PSNR` 和 `SSIM` 作为指标。
-| 算法 | Set5 | Set14 | DIV2K | GPU 信息 | 下载 |
-| :---------------------------------------------------------------------: | :--------------: | :---------------: | :--------------: | :------: | :----------------------------------------------------------------------: |
-| [srcnn_x4k915_1x16_1000k_div2k](/configs/srcnn/srcnn_x4k915_1xb16-1000k_div2k.py) | 28.4316 / 0.8099 | 25.6486 / 0.7014 | 27.7460 / 0.7854 | 1 | [模型](https://download.openmmlab.com/mmediting/restorers/srcnn/srcnn_x4k915_1x16_1000k_div2k_20200608-4186f232.pth) \| [日志](https://download.openmmlab.com/mmediting/restorers/srcnn/srcnn_x4k915_1x16_1000k_div2k_20200608_120159.log.json) |
+| 算法 | Set5 | Set14 | DIV2K | GPU 信息 | 下载 |
+| :------------------------------------------------------------------: | :--------------: | :---------------: | :--------------: | :------: | :-------------------------------------------------------------------------: |
+| [srcnn_x4k915_1x16_1000k_div2k](./srcnn_x4k915_1xb16-1000k_div2k.py) | 28.4316 / 0.8099 | 25.6486 / 0.7014 | 27.7460 / 0.7854 | 1 | [模型](https://download.openmmlab.com/mmediting/restorers/srcnn/srcnn_x4k915_1x16_1000k_div2k_20200608-4186f232.pth) \| [日志](https://download.openmmlab.com/mmediting/restorers/srcnn/srcnn_x4k915_1x16_1000k_div2k_20200608_120159.log.json) |
## 快速开始
diff --git a/configs/srcnn/metafile.yml b/configs/srcnn/metafile.yml
index 39ffe96499..778d67b92a 100644
--- a/configs/srcnn/metafile.yml
+++ b/configs/srcnn/metafile.yml
@@ -6,6 +6,9 @@ Collections:
Paper:
- https://arxiv.org/abs/1501.00092
README: configs/srcnn/README.md
+ Task:
+ - image super-resolution
+ Year: 2015
Models:
- Config: configs/srcnn/srcnn_x4k915_1xb16-1000k_div2k.py
In Collection: SRCNN
diff --git a/configs/srgan_resnet/README.md b/configs/srgan_resnet/README.md
index 3b51828e1f..b40bb093d3 100644
--- a/configs/srgan_resnet/README.md
+++ b/configs/srgan_resnet/README.md
@@ -26,8 +26,8 @@ The metrics are `PSNR / SSIM` .
| Method | Set5 PSNR | Set14 PSNR | DIV2K PSNR | Set5 SSIM | Set14 SSIM | DIV2K SSIM | GPU Info | Download |
| :----------------------------------------------------------------: | :-------: | :--------: | :--------: | :-------: | :--------: | :--------: | :------: | :------------------------------------------------------------------: |
-| [msrresnet_x4c64b16_1x16_300k_div2k](/configs/srgan_resnet/msrresnet_x4c64b16_1xb16-1000k_div2k.py) | 30.2252 | 26.7762 | 28.9748 | 0.8491 | 0.7369 | 0.8178 | 1 | [model](https://download.openmmlab.com/mmediting/restorers/srresnet_srgan/msrresnet_x4c64b16_1x16_300k_div2k_20200521-61556be5.pth) \| [log](https://download.openmmlab.com/mmediting/restorers/srresnet_srgan/msrresnet_x4c64b16_1x16_300k_div2k_20200521_110246.log.json) |
-| [srgan_x4c64b16_1x16_1000k_div2k](/configs/srgan_resnet/srgan_x4c64b16_1xb16-1000k_div2k.py) | 27.9499 | 24.7383 | 26.5697 | 0.7846 | 0.6491 | 0.7365 | 1 | [model](https://download.openmmlab.com/mmediting/restorers/srresnet_srgan/srgan_x4c64b16_1x16_1000k_div2k_20200606-a1f0810e.pth) \| [log](https://download.openmmlab.com/mmediting/restorers/srresnet_srgan/srgan_x4c64b16_1x16_1000k_div2k_20200506_191442.log.json) |
+| [msrresnet_x4c64b16_1x16_300k_div2k](./msrresnet_x4c64b16_1xb16-1000k_div2k.py) | 30.2252 | 26.7762 | 28.9748 | 0.8491 | 0.7369 | 0.8178 | 1 | [model](https://download.openmmlab.com/mmediting/restorers/srresnet_srgan/msrresnet_x4c64b16_1x16_300k_div2k_20200521-61556be5.pth) \| [log](https://download.openmmlab.com/mmediting/restorers/srresnet_srgan/msrresnet_x4c64b16_1x16_300k_div2k_20200521_110246.log.json) |
+| [srgan_x4c64b16_1x16_1000k_div2k](./srgan_x4c64b16_1xb16-1000k_div2k.py) | 27.9499 | 24.7383 | 26.5697 | 0.7846 | 0.6491 | 0.7365 | 1 | [model](https://download.openmmlab.com/mmediting/restorers/srresnet_srgan/srgan_x4c64b16_1x16_1000k_div2k_20200606-a1f0810e.pth) \| [log](https://download.openmmlab.com/mmediting/restorers/srresnet_srgan/srgan_x4c64b16_1x16_1000k_div2k_20200506_191442.log.json) |
## Quick Start
diff --git a/configs/srgan_resnet/README_zh-CN.md b/configs/srgan_resnet/README_zh-CN.md
index 5d16d8db50..3758d4c1b1 100644
--- a/configs/srgan_resnet/README_zh-CN.md
+++ b/configs/srgan_resnet/README_zh-CN.md
@@ -25,8 +25,8 @@
| 算法 | Set5 | Set14 | DIV2K | GPU 信息 | 下载 |
| :---------------------------------------------------------------------: | :---------------: | :--------------: | :--------------: | :------: | :----------------------------------------------------------------------: |
-| [msrresnet_x4c64b16_1x16_300k_div2k](/configs/srgan_resnet/msrresnet_x4c64b16_1xb16-1000k_div2k.py) | 30.2252 / 0.8491 | 26.7762 / 0.7369 | 28.9748 / 0.8178 | 1 | [模型](https://download.openmmlab.com/mmediting/restorers/srresnet_srgan/msrresnet_x4c64b16_1x16_300k_div2k_20200521-61556be5.pth) \| [日志](https://download.openmmlab.com/mmediting/restorers/srresnet_srgan/msrresnet_x4c64b16_1x16_300k_div2k_20200521_110246.log.json) |
-| [srgan_x4c64b16_1x16_1000k_div2k](/configs/srgan_resnet/srgan_x4c64b16_1xb16-1000k_div2k.py) | 27.9499 / 0.7846 | 24.7383 / 0.6491 | 26.5697 / 0.7365 | 1 | [模型](https://download.openmmlab.com/mmediting/restorers/srresnet_srgan/srgan_x4c64b16_1x16_1000k_div2k_20200606-a1f0810e.pth) \| [日志](https://download.openmmlab.com/mmediting/restorers/srresnet_srgan/srgan_x4c64b16_1x16_1000k_div2k_20200506_191442.log.json) |
+| [msrresnet_x4c64b16_1x16_300k_div2k](./msrresnet_x4c64b16_1xb16-1000k_div2k.py) | 30.2252 / 0.8491 | 26.7762 / 0.7369 | 28.9748 / 0.8178 | 1 | [模型](https://download.openmmlab.com/mmediting/restorers/srresnet_srgan/msrresnet_x4c64b16_1x16_300k_div2k_20200521-61556be5.pth) \| [日志](https://download.openmmlab.com/mmediting/restorers/srresnet_srgan/msrresnet_x4c64b16_1x16_300k_div2k_20200521_110246.log.json) |
+| [srgan_x4c64b16_1x16_1000k_div2k](./srgan_x4c64b16_1xb16-1000k_div2k.py) | 27.9499 / 0.7846 | 24.7383 / 0.6491 | 26.5697 / 0.7365 | 1 | [模型](https://download.openmmlab.com/mmediting/restorers/srresnet_srgan/srgan_x4c64b16_1x16_1000k_div2k_20200606-a1f0810e.pth) \| [日志](https://download.openmmlab.com/mmediting/restorers/srresnet_srgan/srgan_x4c64b16_1x16_1000k_div2k_20200506_191442.log.json) |
## 快速开始
diff --git a/configs/srgan_resnet/metafile.yml b/configs/srgan_resnet/metafile.yml
index bace23e8a9..c80cb0aa74 100644
--- a/configs/srgan_resnet/metafile.yml
+++ b/configs/srgan_resnet/metafile.yml
@@ -6,6 +6,9 @@ Collections:
Paper:
- https://arxiv.org/abs/1609.04802
README: configs/srgan_resnet/README.md
+ Task:
+ - image super-resolution
+ Year: 2016
Models:
- Config: configs/srgan_resnet/msrresnet_x4c64b16_1xb16-1000k_div2k.py
In Collection: SRGAN
diff --git a/configs/stable_diffusion/README.md b/configs/stable_diffusion/README.md
new file mode 100644
index 0000000000..5f11460a2e
--- /dev/null
+++ b/configs/stable_diffusion/README.md
@@ -0,0 +1,67 @@
+# Stable Diffusion (2022)
+
+> [Stable Diffusion](https://github.com/CompVis/stable-diffusion)
+
+> **Task**: Text2Image
+
+
+
+## Abstract
+
+
+
+Stable Diffusion is a latent diffusion model conditioned on the text embeddings of a CLIP text encoder, which allows you to create images from text inputs.
+
+
+
+ +
+ -| Model | FID50k | P&R50k_full | Config | Download |
-| :------------------: | :----: | :-----------: | :-----------------------------------------------------------------------------: | :--------------------------------------------------------------------------------: |
-| styleganv1_ffhq_256 | 6.090 | 70.228/27.050 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/styleganv1/styleganv1_ffhq-256x256_8xb4-25Mimgs.py) | [model](https://download.openmmlab.com/mmgen/styleganv1/styleganv1_ffhq_256_g8_25Mimg_20210407_161748-0094da86.pth) |
-| styleganv1_ffhq_1024 | 4.056 | 70.302/36.869 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/styleganv1/styleganv1_ffhq-1024x1024_8xb4-25Mimgs.py) | [model](https://download.openmmlab.com/mmgen/styleganv1/styleganv1_ffhq_1024_g8_25Mimg_20210407_161627-850a7234.pth) |
+| Model | FID50k | P&R50k_full | Config | Download |
+| :------------------: | :----: | :-----------: | :---------------------------------------------------: | :----------------------------------------------------------------------------------------------------------: |
+| styleganv1_ffhq_256 | 6.090 | 70.228/27.050 | [config](./styleganv1_ffhq-256x256_8xb4-25Mimgs.py) | [model](https://download.openmmlab.com/mmediting/styleganv1/styleganv1_ffhq_256_g8_25Mimg_20210407_161748-0094da86.pth) |
+| styleganv1_ffhq_1024 | 4.056 | 70.302/36.869 | [config](./styleganv1_ffhq-1024x1024_8xb4-25Mimgs.py) | [model](https://download.openmmlab.com/mmediting/styleganv1/styleganv1_ffhq_1024_g8_25Mimg_20210407_161627-850a7234.pth) |
## Citation
diff --git a/configs/styleganv1/metafile.yml b/configs/styleganv1/metafile.yml
index d1a62f0f92..30611fdbe5 100644
--- a/configs/styleganv1/metafile.yml
+++ b/configs/styleganv1/metafile.yml
@@ -6,8 +6,11 @@ Collections:
Paper:
- https://openaccess.thecvf.com/content_CVPR_2019/html/Karras_A_Style-Based_Generator_Architecture_for_Generative_Adversarial_Networks_CVPR_2019_paper.html
README: configs/styleganv1/README.md
+ Task:
+ - unconditional gans
+ Year: 2019
Models:
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/styleganv1/styleganv1_ffhq-256x256_8xb4-25Mimgs.py
+- Config: configs/styleganv1/styleganv1_ffhq-256x256_8xb4-25Mimgs.py
In Collection: StyleGANv1
Metadata:
Training Data: FFHQ
@@ -20,8 +23,8 @@ Models:
PSNR: 70.228
SSIM: 27.05
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/styleganv1/styleganv1_ffhq_256_g8_25Mimg_20210407_161748-0094da86.pth
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/styleganv1/styleganv1_ffhq-1024x1024_8xb4-25Mimgs.py
+ Weights: https://download.openmmlab.com/mmediting/styleganv1/styleganv1_ffhq_256_g8_25Mimg_20210407_161748-0094da86.pth
+- Config: configs/styleganv1/styleganv1_ffhq-1024x1024_8xb4-25Mimgs.py
In Collection: StyleGANv1
Metadata:
Training Data: FFHQ
@@ -34,4 +37,4 @@ Models:
PSNR: 70.302
SSIM: 36.869
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/styleganv1/styleganv1_ffhq_1024_g8_25Mimg_20210407_161627-850a7234.pth
+ Weights: https://download.openmmlab.com/mmediting/styleganv1/styleganv1_ffhq_1024_g8_25Mimg_20210407_161627-850a7234.pth
diff --git a/configs/styleganv2/README.md b/configs/styleganv2/README.md
index 631ea0dbb4..22edb54cb4 100644
--- a/configs/styleganv2/README.md
+++ b/configs/styleganv2/README.md
@@ -28,14 +28,14 @@ The style-based GAN architecture (StyleGAN) yields state-of-the-art results in d
| Model | Comment | FID50k | Precision50k | Recall50k | Config | Download |
| :---------------------------------: | :-------------: | :----: | :----------: | :-------: | :----------------------------------------------------------: | :-------------------------------------------------------------: |
-| stylegan2_config-f_ffhq_1024 | official weight | 2.8134 | 62.856 | 49.400 | [stylegan2_c2_8xb4_ffhq-1024x1024](/configs/styleganv2/stylegan2_c2_8xb4_ffhq-1024x1024.py) | [model](https://download.openmmlab.com/mmgen/stylegan2/official_weights/stylegan2-ffhq-config-f-official_20210327_171224-bce9310c.pth) |
-| stylegan2_config-f_lsun-car_384x512 | official weight | 5.4316 | 65.986 | 48.190 | [stylegan2_c2_8xb4_lsun-car-384x512](/configs/styleganv2/stylegan2_c2_8xb4_lsun-car-384x512.py) | [model](https://download.openmmlab.com/mmgen/stylegan2/official_weights/stylegan2-car-config-f-official_20210327_172340-8cfe053c.pth) |
-| stylegan2_config-f_horse_256 | official weight | - | - | - | [stylegan2_c2_8xb4-800kiters_lsun-horse-256x256](/configs/styleganv2/stylegan2_c2_8xb4-800kiters_lsun-horse-256x256.py) | [model](https://download.openmmlab.com/mmgen/stylegan2/official_weights/stylegan2-horse-config-f-official_20210327_173203-ef3e69ca.pth) |
-| stylegan2_config-f_church_256 | official weight | - | - | - | [stylegan2_c2_8xb4-800kiters_lsun-church-256x256](/configs/styleganv2/stylegan2_c2_8xb4-800kiters_lsun-church-256x256.py) | [model](https://download.openmmlab.com/mmgen/stylegan2/official_weights/stylegan2-church-config-f-official_20210327_172657-1d42b7d1.pth) |
-| stylegan2_config-f_cat_256 | official weight | - | - | - | [stylegan2_c2_8xb4-800kiters_lsun-cat-256x256](/configs/styleganv2/stylegan2_c2_8xb4-800kiters_lsun-cat-256x256.py) | [model](https://download.openmmlab.com/mmgen/stylegan2/official_weights/stylegan2-cat-config-f-official_20210327_172444-15bc485b.pth) |
-| stylegan2_config-f_ffhq_256 | our training | 3.992 | 69.012 | 40.417 | [stylegan2_c2_8xb4-800kiters_ffhq-256x256](/configs/styleganv2/stylegan2_c2_8xb4-800kiters_ffhq-256x256.py) | [model](https://download.openmmlab.com/mmgen/stylegan2/stylegan2_c2_ffhq_256_b4x8_20210407_160709-7890ae1f.pth) |
-| stylegan2_config-f_ffhq_1024 | our training | 2.8185 | 68.236 | 49.583 | [stylegan2_c2_8xb4_ffhq-1024x1024](/configs/styleganv2/stylegan2_c2_8xb4_ffhq-1024x1024.py) | [model](https://download.openmmlab.com/mmgen/stylegan2/stylegan2_c2_ffhq_1024_b4x8_20210407_150045-618c9024.pth) |
-| stylegan2_config-f_lsun-car_384x512 | our training | 2.4116 | 66.760 | 50.576 | [stylegan2_c2_8xb4_lsun-car-384x512](/configs/styleganv2/stylegan2_c2_8xb4_lsun-car-384x512.py) | [model](https://download.openmmlab.com/mmgen/stylegan2/stylegan2_c2_lsun-car_384x512_b4x8_1800k_20210424_160929-fc9072ca.pth) |
+| stylegan2_config-f_ffhq_1024 | official weight | 2.8134 | 62.856 | 49.400 | [stylegan2_c2_8xb4_ffhq-1024x1024](./stylegan2_c2_8xb4_ffhq-1024x1024.py) | [model](https://download.openmmlab.com/mmediting/stylegan2/official_weights/stylegan2-ffhq-config-f-official_20210327_171224-bce9310c.pth) |
+| stylegan2_config-f_lsun-car_384x512 | official weight | 5.4316 | 65.986 | 48.190 | [stylegan2_c2_8xb4_lsun-car-384x512](./stylegan2_c2_8xb4_lsun-car-384x512.py) | [model](https://download.openmmlab.com/mmediting/stylegan2/official_weights/stylegan2-car-config-f-official_20210327_172340-8cfe053c.pth) |
+| stylegan2_config-f_horse_256 | official weight | - | - | - | [stylegan2_c2_8xb4-800kiters_lsun-horse-256x256](./stylegan2_c2_8xb4-800kiters_lsun-horse-256x256.py) | [model](https://download.openmmlab.com/mmediting/stylegan2/official_weights/stylegan2-horse-config-f-official_20210327_173203-ef3e69ca.pth) |
+| stylegan2_config-f_church_256 | official weight | - | - | - | [stylegan2_c2_8xb4-800kiters_lsun-church-256x256](./stylegan2_c2_8xb4-800kiters_lsun-church-256x256.py) | [model](https://download.openmmlab.com/mmediting/stylegan2/official_weights/stylegan2-church-config-f-official_20210327_172657-1d42b7d1.pth) |
+| stylegan2_config-f_cat_256 | official weight | - | - | - | [stylegan2_c2_8xb4-800kiters_lsun-cat-256x256](./stylegan2_c2_8xb4-800kiters_lsun-cat-256x256.py) | [model](https://download.openmmlab.com/mmediting/stylegan2/official_weights/stylegan2-cat-config-f-official_20210327_172444-15bc485b.pth) |
+| stylegan2_config-f_ffhq_256 | our training | 3.992 | 69.012 | 40.417 | [stylegan2_c2_8xb4-800kiters_ffhq-256x256](./stylegan2_c2_8xb4-800kiters_ffhq-256x256.py) | [model](https://download.openmmlab.com/mmediting/stylegan2/stylegan2_c2_ffhq_256_b4x8_20210407_160709-7890ae1f.pth) |
+| stylegan2_config-f_ffhq_1024 | our training | 2.8185 | 68.236 | 49.583 | [stylegan2_c2_8xb4_ffhq-1024x1024](./stylegan2_c2_8xb4_ffhq-1024x1024.py) | [model](https://download.openmmlab.com/mmediting/stylegan2/stylegan2_c2_ffhq_1024_b4x8_20210407_150045-618c9024.pth) |
+| stylegan2_config-f_lsun-car_384x512 | our training | 2.4116 | 66.760 | 50.576 | [stylegan2_c2_8xb4_lsun-car-384x512](./stylegan2_c2_8xb4_lsun-car-384x512.py) | [model](https://download.openmmlab.com/mmediting/stylegan2/stylegan2_c2_lsun-car_384x512_b4x8_1800k_20210424_160929-fc9072ca.pth) |
## FP16 Support and Experiments
@@ -49,26 +49,16 @@ Currently, we have supported FP16 training for StyleGAN2, and here are the resul
As shown in the figure, we provide **3** ways to do mixed-precision training for `StyleGAN2`:
-- [stylegan2_c2_fp16_PL-no-scaler](/configs/styleganv2/stylegan2_c2-PL_8xb4-fp16-partial-GD-no-scaler-800kiters_ffhq-256x256.py): In this setting, we try our best to follow the official FP16 implementation in [StyleGAN2-ADA](https://github.com/NVlabs/stylegan2-ada). Similar to the official version, we only adopt FP16 training for the higher-resolution feature maps (the last 4 stages in G and the first 4 stages). Note that we do not adopt the `clamp` way to avoid gradient overflow used in the official implementation. We use the `autocast` function from `torch.cuda.amp` package.
-- [stylegan2_c2_fp16-globalG-partialD_PL-R1-no-scaler](/configs/styleganv2/stylegan2_c2-PL-R1_8xb4-fp16-globalG-partialD-no-scaler-800kiters_ffhq-256x256.py): In this config, we try to adopt mixed-precision training for the whole generator, but in partial discriminator (the first 4 higher-resolution stages). Note that we do not apply the loss scaler in the path length loss and gradient penalty loss. Because we always meet divergence after adopting the loss scaler to scale the gradient in these two losses.
-- [stylegan2_c2_apex_fp16_PL-R1-no-scaler](/configs/styleganv2/stylegan2_c2-PL-R1_8xb4-apex-fp16-no-scaler-800kiters_ffhq-256x256.py): In this setting, we adopt the [APEX](https://github.com/NVIDIA/apex) toolkit to implement mixed-precision training with multiple loss/gradient scalers. In APEX, you can assign different loss scalers for the generator and the discriminator respectively. Note that we still ignore the gradient scaler in the path length loss and gradient penalty loss.
+- [stylegan2_c2_fp16_PL-no-scaler](./stylegan2_c2-PL_8xb4-fp16-partial-GD-no-scaler-800kiters_ffhq-256x256.py): In this setting, we try our best to follow the official FP16 implementation in [StyleGAN2-ADA](https://github.com/NVlabs/stylegan2-ada). Similar to the official version, we only adopt FP16 training for the higher-resolution feature maps (the last 4 stages in G and the first 4 stages). Note that we do not adopt the `clamp` way to avoid gradient overflow used in the official implementation. We use the `autocast` function from `torch.cuda.amp` package.
+- [stylegan2_c2_fp16-globalG-partialD_PL-R1-no-scaler](./stylegan2_c2-PL-R1_8xb4-fp16-globalG-partialD-no-scaler-800kiters_ffhq-256x256.py): In this config, we try to adopt mixed-precision training for the whole generator, but in partial discriminator (the first 4 higher-resolution stages). Note that we do not apply the loss scaler in the path length loss and gradient penalty loss. Because we always meet divergence after adopting the loss scaler to scale the gradient in these two losses.
+- [stylegan2_c2_apex_fp16_PL-R1-no-scaler](./stylegan2_c2-PL-R1_8xb4-apex-fp16-no-scaler-800kiters_ffhq-256x256.py): In this setting, we adopt the [APEX](https://github.com/NVIDIA/apex) toolkit to implement mixed-precision training with multiple loss/gradient scalers. In APEX, you can assign different loss scalers for the generator and the discriminator respectively. Note that we still ignore the gradient scaler in the path length loss and gradient penalty loss.
| Model | Comment | Dataset | FID50k | Config | Download |
| :----------------------------------------------: | :-------------------------------------: | :-----: | :----: | :-----------------------------------------------: | :-------------------------------------------------: |
-| stylegan2_config-f_ffhq_256 | baseline | FFHQ256 | 3.992 | [stylegan2_c2_8xb4-800kiters_ffhq-256x256](/configs/styleganv2/stylegan2_c2_8xb4-800kiters_ffhq-256x256.py) | [ckpt](https://download.openmmlab.com/mmgen/stylegan2/stylegan2_c2_ffhq_256_b4x8_20210407_160709-7890ae1f.pth) |
-| stylegan2_c2_fp16_partial-GD_PL-no-scaler_ffhq_256_b4x8_800k | partial layers in fp16 | FFHQ256 | 4.331 | [stylegan2_c2-PL_8xb4-fp16-partial-GD-no-scaler-800kiters_ffhq-256x256](/configs/styleganv2/stylegan2_c2-PL_8xb4-fp16-partial-GD-no-scaler-800kiters_ffhq-256x256.py) | [ckpt](https://download.openmmlab.com/mmgen/stylegan2/stylegan2_c2_fp16_partial-GD_PL-no-scaler_ffhq_256_b4x8_800k_20210508_114854-dacbe4c9.pth) |
-| stylegan2_c2_fp16-globalG-partialD_PL-R1-no-scaler_ffhq_256_b4x8_800k | the whole G in fp16 | FFHQ256 | 4.362 | [stylegan2_c2-PL-R1_8xb4-fp16-globalG-partialD-no-scaler-800kiters_ffhq-256x256](/configs/styleganv2/stylegan2_c2-PL-R1_8xb4-fp16-globalG-partialD-no-scaler-800kiters_ffhq-256x256.py) | [ckpt](https://download.openmmlab.com/mmgen/stylegan2/stylegan2_c2_fp16-globalG-partialD_PL-R1-no-scaler_ffhq_256_b4x8_800k_20210508_114930-ef8270d4.pth) |
-| stylegan2_c2_apex_fp16_PL-R1-no-scaler_ffhq_256_b4x8_800k | the whole G&D in fp16 + two loss scaler | FFHQ256 | 4.614 | [stylegan2_c2-PL-R1_8xb4-apex-fp16-no-scaler-800kiters_ffhq-256x256](/configs/styleganv2/stylegan2_c2-PL-R1_8xb4-apex-fp16-no-scaler-800kiters_ffhq-256x256.py) | [ckpt](https://download.openmmlab.com/mmgen/stylegan2/stylegan2_c2_apex_fp16_PL-R1-no-scaler_ffhq_256_b4x8_800k_20210508_114701-c2bb8afd.pth) |
-
-In addition, we also provide `QuickTestImageDataset` to users for quickly checking whether the code can be run correctly. It's more important for FP16 experiments, because some cuda operations may no support mixed precision training. Esepcially for `APEX`, you can use [this config](/configs/styleganv2/stylegan2_c2_8xb4-apex-fp16-800kiters_quicktest-ffhq-256x256.py) in your local machine by running:
-
-```bash
-bash tools/dist_train.sh \
- configs/styleganv2/stylegan2_c2_8xb4-apex-fp16-800kiters_quicktest-ffhq-256x256.py 1 \
- --work-dir ./work_dirs/quick-test
-```
-
-With a similar way, users can switch to [config for partial-GD](/configs/styleganv2/stylegan2_c2_8xb4-fp16-800kiters_quicktest-ffhq-256x256.py) and [config for globalG-partialD](/configs/styleganv2/stylegan2_c2_8xb4-fp16-global-800kiters_quicktest-ffhq-256x256.py) to test the other two mixed precision training configuration.
+| stylegan2_config-f_ffhq_256 | baseline | FFHQ256 | 3.992 | [stylegan2_c2_8xb4-800kiters_ffhq-256x256](./stylegan2_c2_8xb4-800kiters_ffhq-256x256.py) | [ckpt](https://download.openmmlab.com/mmediting/stylegan2/stylegan2_c2_ffhq_256_b4x8_20210407_160709-7890ae1f.pth) |
+| stylegan2_c2_fp16_partial-GD_PL-no-scaler_ffhq_256_b4x8_800k | partial layers in fp16 | FFHQ256 | 4.331 | [stylegan2_c2-PL_8xb4-fp16-partial-GD-no-scaler-800kiters_ffhq-256x256](./stylegan2_c2-PL_8xb4-fp16-partial-GD-no-scaler-800kiters_ffhq-256x256.py) | [ckpt](https://download.openmmlab.com/mmediting/stylegan2/stylegan2_c2_fp16_partial-GD_PL-no-scaler_ffhq_256_b4x8_800k_20210508_114854-dacbe4c9.pth) |
+| stylegan2_c2_fp16-globalG-partialD_PL-R1-no-scaler_ffhq_256_b4x8_800k | the whole G in fp16 | FFHQ256 | 4.362 | [stylegan2_c2-PL-R1_8xb4-fp16-globalG-partialD-no-scaler-800kiters_ffhq-256x256](./stylegan2_c2-PL-R1_8xb4-fp16-globalG-partialD-no-scaler-800kiters_ffhq-256x256.py) | [ckpt](https://download.openmmlab.com/mmediting/stylegan2/stylegan2_c2_fp16-globalG-partialD_PL-R1-no-scaler_ffhq_256_b4x8_800k_20210508_114930-ef8270d4.pth) |
+| stylegan2_c2_apex_fp16_PL-R1-no-scaler_ffhq_256_b4x8_800k | the whole G&D in fp16 + two loss scaler | FFHQ256 | 4.614 | [stylegan2_c2-PL-R1_8xb4-apex-fp16-no-scaler-800kiters_ffhq-256x256](./stylegan2_c2-PL-R1_8xb4-apex-fp16-no-scaler-800kiters_ffhq-256x256.py) | [ckpt](https://download.openmmlab.com/mmediting/stylegan2/stylegan2_c2_apex_fp16_PL-R1-no-scaler_ffhq_256_b4x8_800k_20210508_114701-c2bb8afd.pth) |
*Note that to use the [APEX](https://github.com/NVIDIA/apex) toolkit, you have to installed it following the official guidance. (APEX is not included in our requirements.) If you are using GPUs without tensor core, you would better to switch to the newer PyTorch version (>= 1.7,0). Otherwise, the APEX installation or running may meet several bugs.*
@@ -76,25 +66,25 @@ With a similar way, users can switch to [config for partial-GD](/configs/stylega
| Model | Comment | FID50k | FID Version | Config | Download |
| :--------------------------: | :-------------: | :----: | :-------------: | :-----------------------------------------------------------------: | :-------------------------------------------------------------------: |
-| stylegan2_config-f_ffhq_1024 | official weight | 2.8732 | Tero's StyleGAN | [stylegan2_c2_8xb4_ffhq-1024x1024](/configs/styleganv2/stylegan2_c2_8xb4_ffhq-1024x1024.py) | [model](https://download.openmmlab.com/mmgen/stylegan2/official_weights/stylegan2-ffhq-config-f-official_20210327_171224-bce9310c.pth) \| [FID-Reals](https://download.openmmlab.com/mmgen/evaluation/fid_inception_pkl/ffhq-1024-50k-stylegan.pkl) |
-| stylegan2_config-f_ffhq_1024 | our training | 2.9413 | Tero's StyleGAN | [stylegan2_c2_8xb4_ffhq-1024x1024](/configs/styleganv2/stylegan2_c2_8xb4_ffhq-1024x1024.py) | [model](https://download.openmmlab.com/mmgen/stylegan2/stylegan2_c2_ffhq_1024_b4x8_20210407_150045-618c9024.pth) \| [FID-Reals](https://download.openmmlab.com/mmgen/evaluation/fid_inception_pkl/ffhq-1024-50k-stylegan.pkl) |
-| stylegan2_config-f_ffhq_1024 | official weight | 2.8134 | Our PyTorch | [stylegan2_c2_8xb4_ffhq-1024x1024](/configs/styleganv2/stylegan2_c2_8xb4_ffhq-1024x1024.py) | [model](https://download.openmmlab.com/mmgen/stylegan2/official_weights/stylegan2-ffhq-config-f-official_20210327_171224-bce9310c.pth) \| [FID-Reals](https://download.openmmlab.com/mmgen/evaluation/fid_inception_pkl/ffhq-1024-50k-rgb.pkl) |
-| stylegan2_config-f_ffhq_1024 | our training | 2.8185 | Our PyTorch | [stylegan2_c2_8xb4_ffhq-1024x1024](/configs/styleganv2/stylegan2_c2_8xb4_ffhq-1024x1024.py) | [model](https://download.openmmlab.com/mmgen/stylegan2/stylegan2_c2_ffhq_1024_b4x8_20210407_150045-618c9024.pth) \| [FID-Reals](https://download.openmmlab.com/mmgen/evaluation/fid_inception_pkl/ffhq-1024-50k-rgb.pkl) |
+| stylegan2_config-f_ffhq_1024 | official weight | 2.8732 | Tero's StyleGAN | [stylegan2_c2_8xb4_ffhq-1024x1024](./stylegan2_c2_8xb4_ffhq-1024x1024.py) | [model](https://download.openmmlab.com/mmediting/stylegan2/official_weights/stylegan2-ffhq-config-f-official_20210327_171224-bce9310c.pth) \| [FID-Reals](https://download.openmmlab.com/mmediting/evaluation/fid_inception_pkl/ffhq-1024-50k-stylegan.pkl) |
+| stylegan2_config-f_ffhq_1024 | our training | 2.9413 | Tero's StyleGAN | [stylegan2_c2_8xb4_ffhq-1024x1024](./stylegan2_c2_8xb4_ffhq-1024x1024.py) | [model](https://download.openmmlab.com/mmediting/stylegan2/stylegan2_c2_ffhq_1024_b4x8_20210407_150045-618c9024.pth) \| [FID-Reals](https://download.openmmlab.com/mmediting/evaluation/fid_inception_pkl/ffhq-1024-50k-stylegan.pkl) |
+| stylegan2_config-f_ffhq_1024 | official weight | 2.8134 | Our PyTorch | [stylegan2_c2_8xb4_ffhq-1024x1024](./stylegan2_c2_8xb4_ffhq-1024x1024.py) | [model](https://download.openmmlab.com/mmediting/stylegan2/official_weights/stylegan2-ffhq-config-f-official_20210327_171224-bce9310c.pth) \| [FID-Reals](https://download.openmmlab.com/mmediting/evaluation/fid_inception_pkl/ffhq-1024-50k-rgb.pkl) |
+| stylegan2_config-f_ffhq_1024 | our training | 2.8185 | Our PyTorch | [stylegan2_c2_8xb4_ffhq-1024x1024](./stylegan2_c2_8xb4_ffhq-1024x1024.py) | [model](https://download.openmmlab.com/mmediting/stylegan2/stylegan2_c2_ffhq_1024_b4x8_20210407_150045-618c9024.pth) \| [FID-Reals](https://download.openmmlab.com/mmediting/evaluation/fid_inception_pkl/ffhq-1024-50k-rgb.pkl) |
In this table, we observe that the FID with Tero's inception network is similar to that with PyTorch Inception (in mmediting). Thus, we use the FID with PyTorch's Inception net (but the weight is not the official model zoo) by default. Because it can be run on different PyTorch versions. If you use [Tero's Inception net](https://nvlabs-fi-cdn.nvidia.com/stylegan2-ada-pytorch/pretrained/metrics/inception-2015-12-05.pt), your PyTorch must meet `>=1.6.0`.
More precalculated inception pickle files are listed here:
-- FFHQ 256x256 real inceptions, PyTorch InceptionV3. [download](https://download.openmmlab.com/mmgen/evaluation/fid_inception_pkl/ffhq-256-50k-rgb.pkl)
-- LSUN-Car 384x512 real inceptions, PyTorch InceptionV3. [download](https://download.openmmlab.com/mmgen/evaluation/fid_inception_pkl/lsun-car-512_50k_rgb.pkl)
+- FFHQ 256x256 real inceptions, PyTorch InceptionV3. [download](https://download.openmmlab.com/mmediting/evaluation/fid_inception_pkl/ffhq-256-50k-rgb.pkl)
+- LSUN-Car 384x512 real inceptions, PyTorch InceptionV3. [download](https://download.openmmlab.com/mmediting/evaluation/fid_inception_pkl/lsun-car-512_50k_rgb.pkl)
## About Different Implementation and Setting of PR Metric
-| Model | P&R Details | Precision | Recall |
-| :--------------------------------------------: | :------------------------------: | :-------: | :----: |
-| stylegan2_config-f_ffhq_1024 (official weight) | use Tero's VGG16, P&R50k_full | 67.876 | 49.299 |
-| stylegan2_config-f_ffhq_1024 (official weight) | use Tero's VGG16, P&R50k | 62.856 | 49.400 |
-| stylegan2_config-f_ffhq_1024 (official weight) | use PyTorch's VGG16, P&R50k_full | 67.662 | 55.460 |
+| Model | Config | Download | P&R Details | Precision | Recall |
+| :--------------------------------------------: | :--------------------------------------------------: | :-----------------------------------------------------: | :------------------------------: | :-------: | :----: |
+| stylegan2_config-f_ffhq_1024 (official weight) | [stylegan2_c2_8xb4_ffhq-1024x1024](./stylegan2_c2_8xb4_ffhq-1024x1024.py) | [model](https://download.openmmlab.com/mmediting/stylegan2/official_weights/stylegan2-ffhq-config-f-official_20210327_171224-bce9310c.pth) | use Tero's VGG16, P&R50k_full | 67.876 | 49.299 |
+| stylegan2_config-f_ffhq_1024 (official weight) | [stylegan2_c2_8xb4_ffhq-1024x1024](./stylegan2_c2_8xb4_ffhq-1024x1024.py) | [model](https://download.openmmlab.com/mmediting/stylegan2/official_weights/stylegan2-ffhq-config-f-official_20210327_171224-bce9310c.pth) | use Tero's VGG16, P&R50k | 62.856 | 49.400 |
+| stylegan2_config-f_ffhq_1024 (official weight) | [stylegan2_c2_8xb4_ffhq-1024x1024](./stylegan2_c2_8xb4_ffhq-1024x1024.py) | [model](https://download.openmmlab.com/mmediting/stylegan2/official_weights/stylegan2-ffhq-config-f-official_20210327_171224-bce9310c.pth) | use PyTorch's VGG16, P&R50k_full | 67.662 | 55.460 |
As shown in this table, `P&R50k_full` is the metric used in StyleGANv1 and StyleGANv2. `full` indicates that we use the whole dataset for extracting the real distribution, e.g., 70000 images in FFHQ dataset. However, adopting the VGG16 provided from [Tero](https://nvlabs-fi-cdn.nvidia.com/stylegan2-ada-pytorch/pretrained/metrics/vgg16.pt) requires that your PyTorch version must fulfill `>=1.6.0`. Be careful about using the PyTorch's VGG16 to extract features, which will cause higher precision and recall.
diff --git a/configs/styleganv2/metafile.yml b/configs/styleganv2/metafile.yml
index e8c2a5f8bf..ff6883d861 100644
--- a/configs/styleganv2/metafile.yml
+++ b/configs/styleganv2/metafile.yml
@@ -6,6 +6,9 @@ Collections:
Paper:
- https://openaccess.thecvf.com/content_CVPR_2020/html/Karras_Analyzing_and_Improving_the_Image_Quality_of_StyleGAN_CVPR_2020_paper.html
README: configs/styleganv2/README.md
+ Task:
+ - unconditional gans
+ Year: 2020
Models:
- Config: configs/styleganv2/stylegan2_c2_8xb4_ffhq-1024x1024.py
In Collection: StyleGANv2
@@ -19,7 +22,7 @@ Models:
Precision50k: 62.856
Recall50k: 49.4
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/stylegan2/official_weights/stylegan2-ffhq-config-f-official_20210327_171224-bce9310c.pth
+ Weights: https://download.openmmlab.com/mmediting/stylegan2/official_weights/stylegan2-ffhq-config-f-official_20210327_171224-bce9310c.pth
- Config: configs/styleganv2/stylegan2_c2_8xb4_lsun-car-384x512.py
In Collection: StyleGANv2
Metadata:
@@ -32,7 +35,7 @@ Models:
Precision50k: 65.986
Recall50k: 48.19
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/stylegan2/official_weights/stylegan2-car-config-f-official_20210327_172340-8cfe053c.pth
+ Weights: https://download.openmmlab.com/mmediting/stylegan2/official_weights/stylegan2-car-config-f-official_20210327_172340-8cfe053c.pth
- Config: configs/styleganv2/stylegan2_c2_8xb4-800kiters_lsun-horse-256x256.py
In Collection: StyleGANv2
Metadata:
@@ -42,7 +45,7 @@ Models:
- Dataset: Others
Metrics: {}
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/stylegan2/official_weights/stylegan2-horse-config-f-official_20210327_173203-ef3e69ca.pth
+ Weights: https://download.openmmlab.com/mmediting/stylegan2/official_weights/stylegan2-horse-config-f-official_20210327_173203-ef3e69ca.pth
- Config: configs/styleganv2/stylegan2_c2_8xb4-800kiters_lsun-church-256x256.py
In Collection: StyleGANv2
Metadata:
@@ -52,7 +55,7 @@ Models:
- Dataset: Others
Metrics: {}
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/stylegan2/official_weights/stylegan2-church-config-f-official_20210327_172657-1d42b7d1.pth
+ Weights: https://download.openmmlab.com/mmediting/stylegan2/official_weights/stylegan2-church-config-f-official_20210327_172657-1d42b7d1.pth
- Config: configs/styleganv2/stylegan2_c2_8xb4-800kiters_lsun-cat-256x256.py
In Collection: StyleGANv2
Metadata:
@@ -62,7 +65,7 @@ Models:
- Dataset: CAT
Metrics: {}
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/stylegan2/official_weights/stylegan2-cat-config-f-official_20210327_172444-15bc485b.pth
+ Weights: https://download.openmmlab.com/mmediting/stylegan2/official_weights/stylegan2-cat-config-f-official_20210327_172444-15bc485b.pth
- Config: configs/styleganv2/stylegan2_c2_8xb4-800kiters_ffhq-256x256.py
In Collection: StyleGANv2
Metadata:
@@ -75,7 +78,7 @@ Models:
Precision50k: 69.012
Recall50k: 40.417
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/stylegan2/stylegan2_c2_ffhq_256_b4x8_20210407_160709-7890ae1f.pth
+ Weights: https://download.openmmlab.com/mmediting/stylegan2/stylegan2_c2_ffhq_256_b4x8_20210407_160709-7890ae1f.pth
- Config: configs/styleganv2/stylegan2_c2_8xb4_ffhq-1024x1024.py
In Collection: StyleGANv2
Metadata:
@@ -88,7 +91,7 @@ Models:
Precision50k: 68.236
Recall50k: 49.583
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/stylegan2/stylegan2_c2_ffhq_1024_b4x8_20210407_150045-618c9024.pth
+ Weights: https://download.openmmlab.com/mmediting/stylegan2/stylegan2_c2_ffhq_1024_b4x8_20210407_150045-618c9024.pth
- Config: configs/styleganv2/stylegan2_c2_8xb4_lsun-car-384x512.py
In Collection: StyleGANv2
Metadata:
@@ -101,7 +104,7 @@ Models:
Precision50k: 66.76
Recall50k: 50.576
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/stylegan2/stylegan2_c2_lsun-car_384x512_b4x8_1800k_20210424_160929-fc9072ca.pth
+ Weights: https://download.openmmlab.com/mmediting/stylegan2/stylegan2_c2_lsun-car_384x512_b4x8_1800k_20210424_160929-fc9072ca.pth
- Config: configs/styleganv2/stylegan2_c2_8xb4-800kiters_ffhq-256x256.py
In Collection: StyleGANv2
Metadata:
@@ -112,7 +115,7 @@ Models:
Metrics:
FID50k: 3.992
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/stylegan2/stylegan2_c2_ffhq_256_b4x8_20210407_160709-7890ae1f.pth
+ Weights: https://download.openmmlab.com/mmediting/stylegan2/stylegan2_c2_ffhq_256_b4x8_20210407_160709-7890ae1f.pth
- Config: configs/styleganv2/stylegan2_c2-PL_8xb4-fp16-partial-GD-no-scaler-800kiters_ffhq-256x256.py
In Collection: StyleGANv2
Metadata:
@@ -123,7 +126,7 @@ Models:
Metrics:
FID50k: 4.331
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/stylegan2/stylegan2_c2_fp16_partial-GD_PL-no-scaler_ffhq_256_b4x8_800k_20210508_114854-dacbe4c9.pth
+ Weights: https://download.openmmlab.com/mmediting/stylegan2/stylegan2_c2_fp16_partial-GD_PL-no-scaler_ffhq_256_b4x8_800k_20210508_114854-dacbe4c9.pth
- Config: configs/styleganv2/stylegan2_c2-PL-R1_8xb4-fp16-globalG-partialD-no-scaler-800kiters_ffhq-256x256.py
In Collection: StyleGANv2
Metadata:
@@ -134,7 +137,7 @@ Models:
Metrics:
FID50k: 4.362
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/stylegan2/stylegan2_c2_fp16-globalG-partialD_PL-R1-no-scaler_ffhq_256_b4x8_800k_20210508_114930-ef8270d4.pth
+ Weights: https://download.openmmlab.com/mmediting/stylegan2/stylegan2_c2_fp16-globalG-partialD_PL-R1-no-scaler_ffhq_256_b4x8_800k_20210508_114930-ef8270d4.pth
- Config: configs/styleganv2/stylegan2_c2-PL-R1_8xb4-apex-fp16-no-scaler-800kiters_ffhq-256x256.py
In Collection: StyleGANv2
Metadata:
@@ -145,7 +148,7 @@ Models:
Metrics:
FID50k: 4.614
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/stylegan2/stylegan2_c2_apex_fp16_PL-R1-no-scaler_ffhq_256_b4x8_800k_20210508_114701-c2bb8afd.pth
+ Weights: https://download.openmmlab.com/mmediting/stylegan2/stylegan2_c2_apex_fp16_PL-R1-no-scaler_ffhq_256_b4x8_800k_20210508_114701-c2bb8afd.pth
- Config: configs/styleganv2/stylegan2_c2_8xb4_ffhq-1024x1024.py
In Collection: StyleGANv2
Metadata:
@@ -156,7 +159,7 @@ Models:
Metrics:
FID50k: 2.8732
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/stylegan2/official_weights/stylegan2-ffhq-config-f-official_20210327_171224-bce9310c.pth
+ Weights: https://download.openmmlab.com/mmediting/stylegan2/official_weights/stylegan2-ffhq-config-f-official_20210327_171224-bce9310c.pth
- Config: configs/styleganv2/stylegan2_c2_8xb4_ffhq-1024x1024.py
In Collection: StyleGANv2
Metadata:
@@ -167,7 +170,7 @@ Models:
Metrics:
FID50k: 2.9413
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/stylegan2/stylegan2_c2_ffhq_1024_b4x8_20210407_150045-618c9024.pth
+ Weights: https://download.openmmlab.com/mmediting/stylegan2/stylegan2_c2_ffhq_1024_b4x8_20210407_150045-618c9024.pth
- Config: configs/styleganv2/stylegan2_c2_8xb4_ffhq-1024x1024.py
In Collection: StyleGANv2
Metadata:
@@ -178,7 +181,7 @@ Models:
Metrics:
FID50k: 2.8134
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/stylegan2/official_weights/stylegan2-ffhq-config-f-official_20210327_171224-bce9310c.pth
+ Weights: https://download.openmmlab.com/mmediting/stylegan2/official_weights/stylegan2-ffhq-config-f-official_20210327_171224-bce9310c.pth
- Config: configs/styleganv2/stylegan2_c2_8xb4_ffhq-1024x1024.py
In Collection: StyleGANv2
Metadata:
@@ -189,4 +192,40 @@ Models:
Metrics:
FID50k: 2.8185
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/stylegan2/stylegan2_c2_ffhq_1024_b4x8_20210407_150045-618c9024.pth
+ Weights: https://download.openmmlab.com/mmediting/stylegan2/stylegan2_c2_ffhq_1024_b4x8_20210407_150045-618c9024.pth
+- Config: configs/styleganv2/stylegan2_c2_8xb4_ffhq-1024x1024.py
+ In Collection: StyleGANv2
+ Metadata:
+ Training Data: FFHQ
+ Name: stylegan2_c2_8xb4_ffhq-1024x1024
+ Results:
+ - Dataset: FFHQ
+ Metrics:
+ Precision: 67.876
+ Recall: 49.299
+ Task: Unconditional GANs
+ Weights: https://download.openmmlab.com/mmediting/stylegan2/official_weights/stylegan2-ffhq-config-f-official_20210327_171224-bce9310c.pth
+- Config: configs/styleganv2/stylegan2_c2_8xb4_ffhq-1024x1024.py
+ In Collection: StyleGANv2
+ Metadata:
+ Training Data: FFHQ
+ Name: stylegan2_c2_8xb4_ffhq-1024x1024
+ Results:
+ - Dataset: FFHQ
+ Metrics:
+ Precision: 62.856
+ Recall: 49.4
+ Task: Unconditional GANs
+ Weights: https://download.openmmlab.com/mmediting/stylegan2/official_weights/stylegan2-ffhq-config-f-official_20210327_171224-bce9310c.pth
+- Config: configs/styleganv2/stylegan2_c2_8xb4_ffhq-1024x1024.py
+ In Collection: StyleGANv2
+ Metadata:
+ Training Data: FFHQ
+ Name: stylegan2_c2_8xb4_ffhq-1024x1024
+ Results:
+ - Dataset: FFHQ
+ Metrics:
+ Precision: 67.662
+ Recall: 55.46
+ Task: Unconditional GANs
+ Weights: https://download.openmmlab.com/mmediting/stylegan2/official_weights/stylegan2-ffhq-config-f-official_20210327_171224-bce9310c.pth
diff --git a/configs/styleganv2/stylegan2_c2_8xb4-apex-fp16-800kiters_quicktest-ffhq-256x256.py b/configs/styleganv2/stylegan2_c2_8xb4-apex-fp16-800kiters_quicktest-ffhq-256x256.py
deleted file mode 100644
index 021613a3f8..0000000000
--- a/configs/styleganv2/stylegan2_c2_8xb4-apex-fp16-800kiters_quicktest-ffhq-256x256.py
+++ /dev/null
@@ -1,39 +0,0 @@
-"""Config for the `config-f` setting in StyleGAN2."""
-
-_base_ = ['./stylegan2_c2_8xb4-800kiters_ffhq-256x256.py']
-
-model = dict(
- generator=dict(out_size=256),
- discriminator=dict(in_size=256, convert_input_fp32=False),
-)
-
-# remain to be refactored
-apex_amp = dict(
- mode='gan', init_args=dict(opt_level='O1', num_losses=2, loss_scale=512.))
-
-train_cfg = dict(max_iters=800002)
-
-batch_size = 2
-dataset_type = 'QuickTestImageDataset'
-
-train_dataloader = dict(batch_size=batch_size, dataset=dict(type=dataset_type))
-
-val_dataloader = dict(batch_size=batch_size, dataset=dict(type=dataset_type))
-
-test_dataloader = dict(
- batch_size=batch_size, dataset=dict(dataset_type=dataset_type))
-
-default_hooks = dict(logger=dict(type='LoggerHook', interval=1))
-
-# METRICS
-metrics = [
- dict(
- type='FrechetInceptionDistance',
- prefix='FID-Full-50k',
- fake_nums=50000,
- inception_style='StyleGAN',
- sample_model='ema')
-]
-
-val_evaluator = dict(metrics=metrics)
-test_evaluator = dict(metrics=metrics)
diff --git a/configs/styleganv2/stylegan2_c2_8xb4-fp16-800kiters_quicktest-ffhq-256x256.py b/configs/styleganv2/stylegan2_c2_8xb4-fp16-800kiters_quicktest-ffhq-256x256.py
deleted file mode 100644
index da117af082..0000000000
--- a/configs/styleganv2/stylegan2_c2_8xb4-fp16-800kiters_quicktest-ffhq-256x256.py
+++ /dev/null
@@ -1,41 +0,0 @@
-"""Config for the `config-f` setting in StyleGAN2."""
-
-_base_ = ['./stylegan2_c2_8xb4-800kiters_ffhq-256x256.py']
-
-model = dict(
- generator=dict(out_size=256, num_fp16_scales=4),
- discriminator=dict(in_size=256, num_fp16_scales=4),
- disc_auxiliary_loss=dict(data_info=dict(loss_scaler='loss_scaler')),
- # gen_auxiliary_loss=dict(data_info=dict(loss_scaler='loss_scaler')),
-)
-
-batch_size = 2
-dataset_type = 'QuickTestImageDataset'
-
-train_dataloader = dict(batch_size=batch_size, dataset=dict(type=dataset_type))
-
-val_dataloader = dict(batch_size=batch_size, dataset=dict(type=dataset_type))
-
-test_dataloader = dict(
- batch_size=batch_size, dataset=dict(dataset_type=dataset_type))
-
-default_hooks = dict(logger=dict(type='LoggerHook', interval=1))
-
-train_cfg = dict(max_iters=800002)
-
-optim_wrapper = dict(
- generator=dict(type='AmpOptimWrapper', loss_scale=512),
- discriminator=dict(type='AmpOptimWrapper', loss_scale=512))
-
-# METRICS
-metrics = [
- dict(
- type='FrechetInceptionDistance',
- prefix='FID-Full-50k',
- fake_nums=50000,
- inception_style='StyleGAN',
- sample_model='ema')
-]
-
-val_evaluator = dict(metrics=metrics)
-test_evaluator = dict(metrics=metrics)
diff --git a/configs/styleganv2/stylegan2_c2_8xb4-fp16-global-800kiters_quicktest-ffhq-256x256.py b/configs/styleganv2/stylegan2_c2_8xb4-fp16-global-800kiters_quicktest-ffhq-256x256.py
deleted file mode 100644
index a053408f29..0000000000
--- a/configs/styleganv2/stylegan2_c2_8xb4-fp16-global-800kiters_quicktest-ffhq-256x256.py
+++ /dev/null
@@ -1,41 +0,0 @@
-"""Config for the `config-f` setting in StyleGAN2."""
-
-_base_ = ['./stylegan2_c2_8xb4-800kiters_ffhq-256x256.py']
-
-model = dict(
- generator=dict(out_size=256, fp16_enabled=True),
- discriminator=dict(in_size=256, fp16_enabled=True),
- disc_auxiliary_loss=dict(data_info=dict(loss_scaler='loss_scaler')),
- # gen_auxiliary_loss=dict(data_info=dict(loss_scaler='loss_scaler')),
-)
-
-batch_size = 2
-dataset_type = 'QuickTestImageDataset'
-
-train_dataloader = dict(batch_size=batch_size, dataset=dict(type=dataset_type))
-
-val_dataloader = dict(batch_size=batch_size, dataset=dict(type=dataset_type))
-
-test_dataloader = dict(
- batch_size=batch_size, dataset=dict(dataset_type=dataset_type))
-
-default_hooks = dict(logger=dict(type='LoggerHook', interval=1))
-
-train_cfg = dict(max_iters=800002)
-
-optim_wrapper = dict(
- generator=dict(type='AmpOptimWrapper', loss_scale=512),
- discriminator=dict(type='AmpOptimWrapper', loss_scale=512))
-
-# METRICS
-metrics = [
- dict(
- type='FrechetInceptionDistance',
- prefix='FID-Full-50k',
- fake_nums=50000,
- inception_style='StyleGAN',
- sample_model='ema')
-]
-
-val_evaluator = dict(metrics=metrics)
-test_evaluator = dict(metrics=metrics)
diff --git a/configs/styleganv3/README.md b/configs/styleganv3/README.md
index bcb1c677d4..7c67da280c 100644
--- a/configs/styleganv3/README.md
+++ b/configs/styleganv3/README.md
@@ -40,26 +40,26 @@ For user convenience, we also offer the converted version of official weights.
| Model | Dataset | Iter | FID50k | Config | Log | Download |
| :-------------: | :---------------: | :----: | :---------------: | :----------------------------------------------: | :--------------------------------------------: | :-------------------------------------------------: |
-| stylegan3-t | ffhq 1024x1024 | 490000 | 3.37\* | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/styleganv3/stylegan3-t_gamma32.8_8xb4-fp16-noaug_ffhq-1024x1024.py) | [log](https://download.openmmlab.com/mmgen/stylegan3/stylegan3_t_noaug_fp16_gamma32.8_ffhq_1024_b4x8_20220322_090417.log.json) | [model](https://download.openmmlab.com/mmgen/stylegan3/stylegan3_t_noaug_fp16_gamma32.8_ffhq_1024_b4x8_best_fid_iter_490000_20220401_120733-4ff83434.pth) |
-| stylegan3-t-ada | metface 1024x1024 | 130000 | 15.09 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/styleganv3/stylegan3-t_ada-gamma6.6_8xb4-fp16_metfaces-1024x1024.py) | [log](https://download.openmmlab.com/mmgen/stylegan3/stylegan3_t_ada_fp16_gamma6.6_metfaces_1024_b4x8_20220328_142211.log.json) | [model](https://download.openmmlab.com/mmgen/stylegan3/stylegan3_t_ada_fp16_gamma6.6_metfaces_1024_b4x8_best_fid_iter_130000_20220401_115101-f2ef498e.pth) |
+| stylegan3-t | ffhq 1024x1024 | 490000 | 3.37\* | [config](./stylegan3-t_gamma32.8_8xb4-fp16-noaug_ffhq-1024x1024.py) | [log](https://download.openmmlab.com/mmediting/stylegan3/stylegan3_t_noaug_fp16_gamma32.8_ffhq_1024_b4x8_20220322_090417.log.json) | [model](https://download.openmmlab.com/mmediting/stylegan3/stylegan3_t_noaug_fp16_gamma32.8_ffhq_1024_b4x8_best_fid_iter_490000_20220401_120733-4ff83434.pth) |
+| stylegan3-t-ada | metface 1024x1024 | 130000 | 15.09 | [config](./stylegan3-t_ada-gamma6.6_8xb4-fp16_metfaces-1024x1024.py) | [log](https://download.openmmlab.com/mmediting/stylegan3/stylegan3_t_ada_fp16_gamma6.6_metfaces_1024_b4x8_20220328_142211.log.json) | [model](https://download.openmmlab.com/mmediting/stylegan3/stylegan3_t_ada_fp16_gamma6.6_metfaces_1024_b4x8_best_fid_iter_130000_20220401_115101-f2ef498e.pth) |
### Experimental Settings
| Model | Dataset | Iter | FID50k | Config | Log | Download |
| :-------------: | :------------: | :----: | :----: | :---------------------------------------------------: | :------------------------------------------------: | :------------------------------------------------------: |
-| stylegan3-t | ffhq 256x256 | 740000 | 4.51 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/styleganv3/stylegan3-t_gamma2.0_8xb4-fp16-noaug_ffhq-256x256.py) | [log](https://download.openmmlab.com/mmgen/stylegan3/stylegan3_t_noaug_fp16_gamma2.0_ffhq_256_b4x8_20220323_144815.log.json) | [model](https://download.openmmlab.com/mmgen/stylegan3/stylegan3_t_noaug_fp16_gamma2.0_ffhq_256_b4x8_best_fid_iter_740000_20220401_122456-730e1fba.pth) |
-| stylegan3-r-ada | ffhq 1024x1024 | - | - | [config](/configs/styleganv3/stylegan3-r_ada-gamma3.3_8xb4-fp16_metfaces-1024x1024.py) | - | - |
+| stylegan3-t | ffhq 256x256 | 740000 | 4.51 | [config](./stylegan3-t_gamma2.0_8xb4-fp16-noaug_ffhq-256x256.py) | [log](https://download.openmmlab.com/mmediting/stylegan3/stylegan3_t_noaug_fp16_gamma2.0_ffhq_256_b4x8_20220323_144815.log.json) | [model](https://download.openmmlab.com/mmediting/stylegan3/stylegan3_t_noaug_fp16_gamma2.0_ffhq_256_b4x8_best_fid_iter_740000_20220401_122456-730e1fba.pth) |
+| stylegan3-r-ada | ffhq 1024x1024 | - | - | [config](./stylegan3-r_ada-gamma3.3_8xb4-fp16_metfaces-1024x1024.py) | - | - |
### Converted Weights
-| Model | Dataset | Comment | FID50k | EQ-T | EQ-R | Config | Download |
-| :---------: | :------------: | :-------------: | :----: | :---: | :---: | :---------------------------------------------------------------------: | :-----------------------------------------------------------------------: |
-| stylegan3-t | ffhqu 256x256 | official weight | 4.62 | 63.01 | 13.12 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/styleganv3/stylegan3-t_cvt-official-rgb_8xb4_ffhqu-256x256.py) | [model](https://download.openmmlab.com/mmgen/stylegan3/stylegan3_t_ffhqu_256_b4x8_cvt_official_rgb_20220329_235046-153df4c8.pth) |
-| stylegan3-t | afhqv2 512x512 | official weight | 4.04 | 60.15 | 13.51 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/styleganv3/stylegan3-t_cvt-official-rgb_8xb4_afhqv2-512x512.py) | [model](https://download.openmmlab.com/mmgen/stylegan3/stylegan3_t_afhqv2_512_b4x8_cvt_official_rgb_20220329_235017-ee6b037a.pth) |
-| stylegan3-t | ffhq 1024x1024 | official weight | 2.79 | 61.21 | 13.82 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/styleganv3/stylegan3-t_cvt-official-rgb_8xb4_ffhq-1024x1024.py) | [model](https://download.openmmlab.com/mmgen/stylegan3/stylegan3_t_ffhq_1024_b4x8_cvt_official_rgb_20220329_235113-db6c6580.pth) |
-| stylegan3-r | ffhqu 256x256 | official weight | 4.50 | 66.65 | 40.48 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/styleganv3/stylegan3-r_cvt-official-rgb_8xb4_ffhqu-256x256.py) | [model](https://download.openmmlab.com/mmgen/stylegan3/stylegan3_r_ffhqu_256_b4x8_cvt_official_rgb_20220329_234909-4521d963.pth) |
-| stylegan3-r | afhqv2 512x512 | official weight | 4.40 | 64.89 | 40.34 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/styleganv3/stylegan3-r_cvt-official-rgb_8xb4x8_afhqv2-512x512.py) | [model](https://download.openmmlab.com/mmgen/stylegan3/stylegan3_r_afhqv2_512_b4x8_cvt_official_rgb_20220329_234829-f2eaca72.pth) |
-| stylegan3-r | ffhq 1024x1024 | official weight | 3.07 | 64.76 | 46.62 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/styleganv3/stylegan3-r_cvt-official-rgb_8xb4_ffhq-1024x1024.py) | [model](https://download.openmmlab.com/mmgen/stylegan3/stylegan3_r_ffhq_1024_b4x8_cvt_official_rgb_20220329_234933-ac0500a1.pth) |
+| Model | Dataset | Comment | FID50k | EQ-T | EQ-R | Config | Download |
+| :---------: | :------------: | :-------------: | :----: | :---: | :---: | :---------------------------------------------------------------: | :-----------------------------------------------------------------------------: |
+| stylegan3-t | ffhqu 256x256 | official weight | 4.62 | 63.01 | 13.12 | [config](./stylegan3-t_cvt-official-rgb_8xb4_ffhqu-256x256.py) | [model](https://download.openmmlab.com/mmediting/stylegan3/stylegan3_t_ffhqu_256_b4x8_cvt_official_rgb_20220329_235046-153df4c8.pth) |
+| stylegan3-t | afhqv2 512x512 | official weight | 4.04 | 60.15 | 13.51 | [config](./stylegan3-t_cvt-official-rgb_8xb4_afhqv2-512x512.py) | [model](https://download.openmmlab.com/mmediting/stylegan3/stylegan3_t_afhqv2_512_b4x8_cvt_official_rgb_20220329_235017-ee6b037a.pth) |
+| stylegan3-t | ffhq 1024x1024 | official weight | 2.79 | 61.21 | 13.82 | [config](./stylegan3-t_cvt-official-rgb_8xb4_ffhq-1024x1024.py) | [model](https://download.openmmlab.com/mmediting/stylegan3/stylegan3_t_ffhq_1024_b4x8_cvt_official_rgb_20220329_235113-db6c6580.pth) |
+| stylegan3-r | ffhqu 256x256 | official weight | 4.50 | 66.65 | 40.48 | [config](./stylegan3-r_cvt-official-rgb_8xb4_ffhqu-256x256.py) | [model](https://download.openmmlab.com/mmediting/stylegan3/stylegan3_r_ffhqu_256_b4x8_cvt_official_rgb_20220329_234909-4521d963.pth) |
+| stylegan3-r | afhqv2 512x512 | official weight | 4.40 | 64.89 | 40.34 | [config](./stylegan3-r_cvt-official-rgb_8xb4x8_afhqv2-512x512.py) | [model](https://download.openmmlab.com/mmediting/stylegan3/stylegan3_r_afhqv2_512_b4x8_cvt_official_rgb_20220329_234829-f2eaca72.pth) |
+| stylegan3-r | ffhq 1024x1024 | official weight | 3.07 | 64.76 | 46.62 | [config](./stylegan3-r_cvt-official-rgb_8xb4_ffhq-1024x1024.py) | [model](https://download.openmmlab.com/mmediting/stylegan3/stylegan3_r_ffhq_1024_b4x8_cvt_official_rgb_20220329_234933-ac0500a1.pth) |
## Interpolation
@@ -67,7 +67,7 @@ We provide a tool to generate video by walking through GAN's latent space.
Run this command to get the following video.
```bash
-python apps/interpolate_sample.py configs/styleganv3/stylegan3_t_afhqv2_512_b4x8_official.py https://download.openmmlab.com/mmgen/stylegan3/stylegan3_t_afhqv2_512_b4x8_cvt_official.pkl --export-video --samples-path work_dirs/demos/ --endpoint 6 --interval 60 --space z --seed 2022 --sample-cfg truncation=0.8
+python apps/interpolate_sample.py configs/styleganv3/stylegan3_t_afhqv2_512_b4x8_official.py https://download.openmmlab.com/mmediting/stylegan3/stylegan3_t_afhqv2_512_b4x8_cvt_official.pkl --export-video --samples-path work_dirs/demos/ --endpoint 6 --interval 60 --space z --seed 2022 --sample-cfg truncation=0.8
```
https://user-images.githubusercontent.com/22982797/151506918-83da9ee3-0d63-4c5b-ad53-a41562b92075.mp4
@@ -78,11 +78,11 @@ We also provide a tool to visualize the equivarience properties for StyleGAN3.
Run these commands to get the results below.
```bash
-python tools/utils/equivariance_viz.py configs/styleganv3/stylegan3_r_ffhqu_256_b4x8_official.py https://download.openmmlab.com/mmgen/stylegan3/stylegan3_r_ffhqu_256_b4x8_cvt_official.pkl --translate_max 0.5 --transform rotate --seed 5432
+python tools/utils/equivariance_viz.py configs/styleganv3/stylegan3_r_ffhqu_256_b4x8_official.py https://download.openmmlab.com/mmediting/stylegan3/stylegan3_r_ffhqu_256_b4x8_cvt_official.pkl --translate_max 0.5 --transform rotate --seed 5432
-python tools/utils/equivariance_viz.py configs/styleganv3/stylegan3_r_ffhqu_256_b4x8_official.py https://openmmlab-share.oss-cn-hangzhou.aliyuncs.com/mmgen/stylegan3/stylegan3_r_ffhqu_256_b4x8_cvt_official.pkl --translate_max 0.25 --transform x_t --seed 5432
+python tools/utils/equivariance_viz.py configs/styleganv3/stylegan3_r_ffhqu_256_b4x8_official.py https://download.openmmlab.com/mmediting/stylegan3/stylegan3_r_ffhqu_256_b4x8_cvt_official.pkl --translate_max 0.25 --transform x_t --seed 5432
-python tools/utils/equivariance_viz.py configs/styleganv3/stylegan3_r_ffhqu_256_b4x8_official.py https://openmmlab-share.oss-cn-hangzhou.aliyuncs.com/mmgen/stylegan3/stylegan3_r_ffhqu_256_b4x8_cvt_official.pkl --translate_max 0.25 --transform y_t --seed 5432
+python tools/utils/equivariance_viz.py configs/styleganv3/stylegan3_r_ffhqu_256_b4x8_official.py https://download.openmmlab.com/mmediting/stylegan3/stylegan3_r_ffhqu_256_b4x8_cvt_official.pkl --translate_max 0.25 --transform y_t --seed 5432
```
https://user-images.githubusercontent.com/22982797/151504902-f3cbfef5-9014-4607-bbe1-deaf48ec6d55.mp4
@@ -102,7 +102,7 @@ metrics = dict(
compute_eqt_int=True, compute_eqt_frac=True, compute_eqr=True)))
```
-And we highly recommend you to use [slurm_eval_multi_gpu](tools/slurm_eval_multi_gpu.sh) script to accelerate evaluation time.
+And we highly recommend you to use [slurm_test.sh](../../tools/slurm_test.sh) script to accelerate evaluation time.
## Citation
diff --git a/configs/styleganv3/metafile.yml b/configs/styleganv3/metafile.yml
index 9389454d6a..4224b0e174 100644
--- a/configs/styleganv3/metafile.yml
+++ b/configs/styleganv3/metafile.yml
@@ -6,8 +6,11 @@ Collections:
Paper:
- https://nvlabs-fi-cdn.nvidia.com/stylegan3/stylegan3-paper.pdf
README: configs/styleganv3/README.md
+ Task:
+ - unconditional gans
+ Year: 2021
Models:
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/styleganv3/stylegan3-t_gamma32.8_8xb4-fp16-noaug_ffhq-1024x1024.py
+- Config: configs/styleganv3/stylegan3-t_gamma32.8_8xb4-fp16-noaug_ffhq-1024x1024.py
In Collection: StyleGANv3
Metadata:
Training Data: FFHQ
@@ -17,8 +20,8 @@ Models:
Metrics:
Iter: 490000.0
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/stylegan3/stylegan3_t_noaug_fp16_gamma32.8_ffhq_1024_b4x8_best_fid_iter_490000_20220401_120733-4ff83434.pth
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/styleganv3/stylegan3-t_ada-gamma6.6_8xb4-fp16_metfaces-1024x1024.py
+ Weights: https://download.openmmlab.com/mmediting/stylegan3/stylegan3_t_noaug_fp16_gamma32.8_ffhq_1024_b4x8_best_fid_iter_490000_20220401_120733-4ff83434.pth
+- Config: configs/styleganv3/stylegan3-t_ada-gamma6.6_8xb4-fp16_metfaces-1024x1024.py
In Collection: StyleGANv3
Metadata:
Training Data: Others
@@ -29,8 +32,8 @@ Models:
FID50k: 15.09
Iter: 130000.0
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/stylegan3/stylegan3_t_ada_fp16_gamma6.6_metfaces_1024_b4x8_best_fid_iter_130000_20220401_115101-f2ef498e.pth
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/styleganv3/stylegan3-t_gamma2.0_8xb4-fp16-noaug_ffhq-256x256.py
+ Weights: https://download.openmmlab.com/mmediting/stylegan3/stylegan3_t_ada_fp16_gamma6.6_metfaces_1024_b4x8_best_fid_iter_130000_20220401_115101-f2ef498e.pth
+- Config: configs/styleganv3/stylegan3-t_gamma2.0_8xb4-fp16-noaug_ffhq-256x256.py
In Collection: StyleGANv3
Metadata:
Training Data: FFHQ
@@ -41,7 +44,7 @@ Models:
FID50k: 4.51
Iter: 740000.0
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/stylegan3/stylegan3_t_noaug_fp16_gamma2.0_ffhq_256_b4x8_best_fid_iter_740000_20220401_122456-730e1fba.pth
+ Weights: https://download.openmmlab.com/mmediting/stylegan3/stylegan3_t_noaug_fp16_gamma2.0_ffhq_256_b4x8_best_fid_iter_740000_20220401_122456-730e1fba.pth
- Config: configs/styleganv3/stylegan3-r_ada-gamma3.3_8xb4-fp16_metfaces-1024x1024.py
In Collection: StyleGANv3
Metadata:
@@ -52,7 +55,7 @@ Models:
Metrics: {}
Task: Unconditional GANs
Weights: ''
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/styleganv3/stylegan3-t_cvt-official-rgb_8xb4_ffhqu-256x256.py
+- Config: configs/styleganv3/stylegan3-t_cvt-official-rgb_8xb4_ffhqu-256x256.py
In Collection: StyleGANv3
Metadata:
Training Data: FFHQ
@@ -64,8 +67,8 @@ Models:
EQ-T: 63.01
FID50k: 4.62
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/stylegan3/stylegan3_t_ffhqu_256_b4x8_cvt_official_rgb_20220329_235046-153df4c8.pth
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/styleganv3/stylegan3-t_cvt-official-rgb_8xb4_afhqv2-512x512.py
+ Weights: https://download.openmmlab.com/mmediting/stylegan3/stylegan3_t_ffhqu_256_b4x8_cvt_official_rgb_20220329_235046-153df4c8.pth
+- Config: configs/styleganv3/stylegan3-t_cvt-official-rgb_8xb4_afhqv2-512x512.py
In Collection: StyleGANv3
Metadata:
Training Data: Others
@@ -77,8 +80,8 @@ Models:
EQ-T: 60.15
FID50k: 4.04
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/stylegan3/stylegan3_t_afhqv2_512_b4x8_cvt_official_rgb_20220329_235017-ee6b037a.pth
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/styleganv3/stylegan3-t_cvt-official-rgb_8xb4_ffhq-1024x1024.py
+ Weights: https://download.openmmlab.com/mmediting/stylegan3/stylegan3_t_afhqv2_512_b4x8_cvt_official_rgb_20220329_235017-ee6b037a.pth
+- Config: configs/styleganv3/stylegan3-t_cvt-official-rgb_8xb4_ffhq-1024x1024.py
In Collection: StyleGANv3
Metadata:
Training Data: FFHQ
@@ -90,8 +93,8 @@ Models:
EQ-T: 61.21
FID50k: 2.79
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/stylegan3/stylegan3_t_ffhq_1024_b4x8_cvt_official_rgb_20220329_235113-db6c6580.pth
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/styleganv3/stylegan3-r_cvt-official-rgb_8xb4_ffhqu-256x256.py
+ Weights: https://download.openmmlab.com/mmediting/stylegan3/stylegan3_t_ffhq_1024_b4x8_cvt_official_rgb_20220329_235113-db6c6580.pth
+- Config: configs/styleganv3/stylegan3-r_cvt-official-rgb_8xb4_ffhqu-256x256.py
In Collection: StyleGANv3
Metadata:
Training Data: FFHQ
@@ -103,8 +106,8 @@ Models:
EQ-T: 66.65
FID50k: 4.5
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/stylegan3/stylegan3_r_ffhqu_256_b4x8_cvt_official_rgb_20220329_234909-4521d963.pth
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/styleganv3/stylegan3-r_cvt-official-rgb_8xb4x8_afhqv2-512x512.py
+ Weights: https://download.openmmlab.com/mmediting/stylegan3/stylegan3_r_ffhqu_256_b4x8_cvt_official_rgb_20220329_234909-4521d963.pth
+- Config: configs/styleganv3/stylegan3-r_cvt-official-rgb_8xb4x8_afhqv2-512x512.py
In Collection: StyleGANv3
Metadata:
Training Data: Others
@@ -116,8 +119,8 @@ Models:
EQ-T: 64.89
FID50k: 4.4
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/stylegan3/stylegan3_r_afhqv2_512_b4x8_cvt_official_rgb_20220329_234829-f2eaca72.pth
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/styleganv3/stylegan3-r_cvt-official-rgb_8xb4_ffhq-1024x1024.py
+ Weights: https://download.openmmlab.com/mmediting/stylegan3/stylegan3_r_afhqv2_512_b4x8_cvt_official_rgb_20220329_234829-f2eaca72.pth
+- Config: configs/styleganv3/stylegan3-r_cvt-official-rgb_8xb4_ffhq-1024x1024.py
In Collection: StyleGANv3
Metadata:
Training Data: FFHQ
@@ -129,4 +132,4 @@ Models:
EQ-T: 64.76
FID50k: 3.07
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/stylegan3/stylegan3_r_ffhq_1024_b4x8_cvt_official_rgb_20220329_234933-ac0500a1.pth
+ Weights: https://download.openmmlab.com/mmediting/stylegan3/stylegan3_r_ffhq_1024_b4x8_cvt_official_rgb_20220329_234933-ac0500a1.pth
diff --git a/configs/styleganv3/stylegan3-r_ada-gamma3.3_8xb4-fp16_metfaces-1024x1024.py b/configs/styleganv3/stylegan3-r_ada-gamma3.3_8xb4-fp16_metfaces-1024x1024.py
index cef1bab104..094fa6edae 100644
--- a/configs/styleganv3/stylegan3-r_ada-gamma3.3_8xb4-fp16_metfaces-1024x1024.py
+++ b/configs/styleganv3/stylegan3-r_ada-gamma3.3_8xb4-fp16_metfaces-1024x1024.py
@@ -19,7 +19,7 @@
g_reg_ratio = g_reg_interval / (g_reg_interval + 1)
d_reg_ratio = d_reg_interval / (d_reg_interval + 1)
-load_from = 'https://download.openmmlab.com/mmgen/stylegan3/stylegan3_r_ffhq_1024_b4x8_cvt_official_rgb_20220329_234933-ac0500a1.pth' # noqa
+load_from = 'https://download.openmmlab.com/mmediting/stylegan3/stylegan3_r_ffhq_1024_b4x8_cvt_official_rgb_20220329_234933-ac0500a1.pth' # noqa
# ada settings
aug_kwargs = {
diff --git a/configs/styleganv3/stylegan3-t_ada-gamma6.6_8xb4-fp16_metfaces-1024x1024.py b/configs/styleganv3/stylegan3-t_ada-gamma6.6_8xb4-fp16_metfaces-1024x1024.py
index eb62691618..56ced90640 100644
--- a/configs/styleganv3/stylegan3-t_ada-gamma6.6_8xb4-fp16_metfaces-1024x1024.py
+++ b/configs/styleganv3/stylegan3-t_ada-gamma6.6_8xb4-fp16_metfaces-1024x1024.py
@@ -17,7 +17,7 @@
g_reg_ratio = g_reg_interval / (g_reg_interval + 1)
d_reg_ratio = d_reg_interval / (d_reg_interval + 1)
-load_from = 'https://download.openmmlab.com/mmgen/stylegan3/stylegan3_t_ffhq_1024_b4x8_cvt_official_rgb_20220329_235113-db6c6580.pth' # noqa
+load_from = 'https://download.openmmlab.com/mmediting/stylegan3/stylegan3_t_ffhq_1024_b4x8_cvt_official_rgb_20220329_235113-db6c6580.pth' # noqa
# ada settings
aug_kwargs = {
'xflip': 1,
diff --git a/configs/swinir/README.md b/configs/swinir/README.md
new file mode 100644
index 0000000000..2ada8e12e6
--- /dev/null
+++ b/configs/swinir/README.md
@@ -0,0 +1,512 @@
+# SwinIR (ICCVW'2021)
+
+> [SwinIR: Image Restoration Using Swin Transformer](https://arxiv.org/abs/2108.10257)
+
+> **Task**: Image Super-Resolution, Image denoising, JPEG compression artifact reduction
+
+
+
+## Abstract
+
+
+
+Image restoration is a long-standing low-level vision problem that aims to restore high-quality images from low-quality images (e.g., downscaled, noisy and compressed images). While state-of-the-art image restoration methods are based on convolutional neural networks, few attempts have been made with Transformers which show impressive performance on high-level vision tasks. In this paper, we propose a strong baseline model SwinIR for image restoration based on the Swin Transformer. SwinIR consists of three parts: shallow feature extraction, deep feature extraction and high-quality image reconstruction. In particular, the deep feature extraction module is composed of several residual Swin Transformer blocks (RSTB), each of which has several Swin Transformer layers together with a residual connection. We conduct experiments on three representative tasks: image super-resolution (including classical, lightweight and real-world image super-resolution), image denoising (including grayscale and color image denoising) and JPEG compression artifact reduction. Experimental results demonstrate that SwinIR outperforms state-of-the-art methods on different tasks by up to 0.14~0.45dB, while the total number of parameters can be reduced by up to 67%.
+
+
+
+
-| Model | FID50k | P&R50k_full | Config | Download |
-| :------------------: | :----: | :-----------: | :-----------------------------------------------------------------------------: | :--------------------------------------------------------------------------------: |
-| styleganv1_ffhq_256 | 6.090 | 70.228/27.050 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/styleganv1/styleganv1_ffhq-256x256_8xb4-25Mimgs.py) | [model](https://download.openmmlab.com/mmgen/styleganv1/styleganv1_ffhq_256_g8_25Mimg_20210407_161748-0094da86.pth) |
-| styleganv1_ffhq_1024 | 4.056 | 70.302/36.869 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/styleganv1/styleganv1_ffhq-1024x1024_8xb4-25Mimgs.py) | [model](https://download.openmmlab.com/mmgen/styleganv1/styleganv1_ffhq_1024_g8_25Mimg_20210407_161627-850a7234.pth) |
+| Model | FID50k | P&R50k_full | Config | Download |
+| :------------------: | :----: | :-----------: | :---------------------------------------------------: | :----------------------------------------------------------------------------------------------------------: |
+| styleganv1_ffhq_256 | 6.090 | 70.228/27.050 | [config](./styleganv1_ffhq-256x256_8xb4-25Mimgs.py) | [model](https://download.openmmlab.com/mmediting/styleganv1/styleganv1_ffhq_256_g8_25Mimg_20210407_161748-0094da86.pth) |
+| styleganv1_ffhq_1024 | 4.056 | 70.302/36.869 | [config](./styleganv1_ffhq-1024x1024_8xb4-25Mimgs.py) | [model](https://download.openmmlab.com/mmediting/styleganv1/styleganv1_ffhq_1024_g8_25Mimg_20210407_161627-850a7234.pth) |
## Citation
diff --git a/configs/styleganv1/metafile.yml b/configs/styleganv1/metafile.yml
index d1a62f0f92..30611fdbe5 100644
--- a/configs/styleganv1/metafile.yml
+++ b/configs/styleganv1/metafile.yml
@@ -6,8 +6,11 @@ Collections:
Paper:
- https://openaccess.thecvf.com/content_CVPR_2019/html/Karras_A_Style-Based_Generator_Architecture_for_Generative_Adversarial_Networks_CVPR_2019_paper.html
README: configs/styleganv1/README.md
+ Task:
+ - unconditional gans
+ Year: 2019
Models:
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/styleganv1/styleganv1_ffhq-256x256_8xb4-25Mimgs.py
+- Config: configs/styleganv1/styleganv1_ffhq-256x256_8xb4-25Mimgs.py
In Collection: StyleGANv1
Metadata:
Training Data: FFHQ
@@ -20,8 +23,8 @@ Models:
PSNR: 70.228
SSIM: 27.05
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/styleganv1/styleganv1_ffhq_256_g8_25Mimg_20210407_161748-0094da86.pth
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/styleganv1/styleganv1_ffhq-1024x1024_8xb4-25Mimgs.py
+ Weights: https://download.openmmlab.com/mmediting/styleganv1/styleganv1_ffhq_256_g8_25Mimg_20210407_161748-0094da86.pth
+- Config: configs/styleganv1/styleganv1_ffhq-1024x1024_8xb4-25Mimgs.py
In Collection: StyleGANv1
Metadata:
Training Data: FFHQ
@@ -34,4 +37,4 @@ Models:
PSNR: 70.302
SSIM: 36.869
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/styleganv1/styleganv1_ffhq_1024_g8_25Mimg_20210407_161627-850a7234.pth
+ Weights: https://download.openmmlab.com/mmediting/styleganv1/styleganv1_ffhq_1024_g8_25Mimg_20210407_161627-850a7234.pth
diff --git a/configs/styleganv2/README.md b/configs/styleganv2/README.md
index 631ea0dbb4..22edb54cb4 100644
--- a/configs/styleganv2/README.md
+++ b/configs/styleganv2/README.md
@@ -28,14 +28,14 @@ The style-based GAN architecture (StyleGAN) yields state-of-the-art results in d
| Model | Comment | FID50k | Precision50k | Recall50k | Config | Download |
| :---------------------------------: | :-------------: | :----: | :----------: | :-------: | :----------------------------------------------------------: | :-------------------------------------------------------------: |
-| stylegan2_config-f_ffhq_1024 | official weight | 2.8134 | 62.856 | 49.400 | [stylegan2_c2_8xb4_ffhq-1024x1024](/configs/styleganv2/stylegan2_c2_8xb4_ffhq-1024x1024.py) | [model](https://download.openmmlab.com/mmgen/stylegan2/official_weights/stylegan2-ffhq-config-f-official_20210327_171224-bce9310c.pth) |
-| stylegan2_config-f_lsun-car_384x512 | official weight | 5.4316 | 65.986 | 48.190 | [stylegan2_c2_8xb4_lsun-car-384x512](/configs/styleganv2/stylegan2_c2_8xb4_lsun-car-384x512.py) | [model](https://download.openmmlab.com/mmgen/stylegan2/official_weights/stylegan2-car-config-f-official_20210327_172340-8cfe053c.pth) |
-| stylegan2_config-f_horse_256 | official weight | - | - | - | [stylegan2_c2_8xb4-800kiters_lsun-horse-256x256](/configs/styleganv2/stylegan2_c2_8xb4-800kiters_lsun-horse-256x256.py) | [model](https://download.openmmlab.com/mmgen/stylegan2/official_weights/stylegan2-horse-config-f-official_20210327_173203-ef3e69ca.pth) |
-| stylegan2_config-f_church_256 | official weight | - | - | - | [stylegan2_c2_8xb4-800kiters_lsun-church-256x256](/configs/styleganv2/stylegan2_c2_8xb4-800kiters_lsun-church-256x256.py) | [model](https://download.openmmlab.com/mmgen/stylegan2/official_weights/stylegan2-church-config-f-official_20210327_172657-1d42b7d1.pth) |
-| stylegan2_config-f_cat_256 | official weight | - | - | - | [stylegan2_c2_8xb4-800kiters_lsun-cat-256x256](/configs/styleganv2/stylegan2_c2_8xb4-800kiters_lsun-cat-256x256.py) | [model](https://download.openmmlab.com/mmgen/stylegan2/official_weights/stylegan2-cat-config-f-official_20210327_172444-15bc485b.pth) |
-| stylegan2_config-f_ffhq_256 | our training | 3.992 | 69.012 | 40.417 | [stylegan2_c2_8xb4-800kiters_ffhq-256x256](/configs/styleganv2/stylegan2_c2_8xb4-800kiters_ffhq-256x256.py) | [model](https://download.openmmlab.com/mmgen/stylegan2/stylegan2_c2_ffhq_256_b4x8_20210407_160709-7890ae1f.pth) |
-| stylegan2_config-f_ffhq_1024 | our training | 2.8185 | 68.236 | 49.583 | [stylegan2_c2_8xb4_ffhq-1024x1024](/configs/styleganv2/stylegan2_c2_8xb4_ffhq-1024x1024.py) | [model](https://download.openmmlab.com/mmgen/stylegan2/stylegan2_c2_ffhq_1024_b4x8_20210407_150045-618c9024.pth) |
-| stylegan2_config-f_lsun-car_384x512 | our training | 2.4116 | 66.760 | 50.576 | [stylegan2_c2_8xb4_lsun-car-384x512](/configs/styleganv2/stylegan2_c2_8xb4_lsun-car-384x512.py) | [model](https://download.openmmlab.com/mmgen/stylegan2/stylegan2_c2_lsun-car_384x512_b4x8_1800k_20210424_160929-fc9072ca.pth) |
+| stylegan2_config-f_ffhq_1024 | official weight | 2.8134 | 62.856 | 49.400 | [stylegan2_c2_8xb4_ffhq-1024x1024](./stylegan2_c2_8xb4_ffhq-1024x1024.py) | [model](https://download.openmmlab.com/mmediting/stylegan2/official_weights/stylegan2-ffhq-config-f-official_20210327_171224-bce9310c.pth) |
+| stylegan2_config-f_lsun-car_384x512 | official weight | 5.4316 | 65.986 | 48.190 | [stylegan2_c2_8xb4_lsun-car-384x512](./stylegan2_c2_8xb4_lsun-car-384x512.py) | [model](https://download.openmmlab.com/mmediting/stylegan2/official_weights/stylegan2-car-config-f-official_20210327_172340-8cfe053c.pth) |
+| stylegan2_config-f_horse_256 | official weight | - | - | - | [stylegan2_c2_8xb4-800kiters_lsun-horse-256x256](./stylegan2_c2_8xb4-800kiters_lsun-horse-256x256.py) | [model](https://download.openmmlab.com/mmediting/stylegan2/official_weights/stylegan2-horse-config-f-official_20210327_173203-ef3e69ca.pth) |
+| stylegan2_config-f_church_256 | official weight | - | - | - | [stylegan2_c2_8xb4-800kiters_lsun-church-256x256](./stylegan2_c2_8xb4-800kiters_lsun-church-256x256.py) | [model](https://download.openmmlab.com/mmediting/stylegan2/official_weights/stylegan2-church-config-f-official_20210327_172657-1d42b7d1.pth) |
+| stylegan2_config-f_cat_256 | official weight | - | - | - | [stylegan2_c2_8xb4-800kiters_lsun-cat-256x256](./stylegan2_c2_8xb4-800kiters_lsun-cat-256x256.py) | [model](https://download.openmmlab.com/mmediting/stylegan2/official_weights/stylegan2-cat-config-f-official_20210327_172444-15bc485b.pth) |
+| stylegan2_config-f_ffhq_256 | our training | 3.992 | 69.012 | 40.417 | [stylegan2_c2_8xb4-800kiters_ffhq-256x256](./stylegan2_c2_8xb4-800kiters_ffhq-256x256.py) | [model](https://download.openmmlab.com/mmediting/stylegan2/stylegan2_c2_ffhq_256_b4x8_20210407_160709-7890ae1f.pth) |
+| stylegan2_config-f_ffhq_1024 | our training | 2.8185 | 68.236 | 49.583 | [stylegan2_c2_8xb4_ffhq-1024x1024](./stylegan2_c2_8xb4_ffhq-1024x1024.py) | [model](https://download.openmmlab.com/mmediting/stylegan2/stylegan2_c2_ffhq_1024_b4x8_20210407_150045-618c9024.pth) |
+| stylegan2_config-f_lsun-car_384x512 | our training | 2.4116 | 66.760 | 50.576 | [stylegan2_c2_8xb4_lsun-car-384x512](./stylegan2_c2_8xb4_lsun-car-384x512.py) | [model](https://download.openmmlab.com/mmediting/stylegan2/stylegan2_c2_lsun-car_384x512_b4x8_1800k_20210424_160929-fc9072ca.pth) |
## FP16 Support and Experiments
@@ -49,26 +49,16 @@ Currently, we have supported FP16 training for StyleGAN2, and here are the resul
As shown in the figure, we provide **3** ways to do mixed-precision training for `StyleGAN2`:
-- [stylegan2_c2_fp16_PL-no-scaler](/configs/styleganv2/stylegan2_c2-PL_8xb4-fp16-partial-GD-no-scaler-800kiters_ffhq-256x256.py): In this setting, we try our best to follow the official FP16 implementation in [StyleGAN2-ADA](https://github.com/NVlabs/stylegan2-ada). Similar to the official version, we only adopt FP16 training for the higher-resolution feature maps (the last 4 stages in G and the first 4 stages). Note that we do not adopt the `clamp` way to avoid gradient overflow used in the official implementation. We use the `autocast` function from `torch.cuda.amp` package.
-- [stylegan2_c2_fp16-globalG-partialD_PL-R1-no-scaler](/configs/styleganv2/stylegan2_c2-PL-R1_8xb4-fp16-globalG-partialD-no-scaler-800kiters_ffhq-256x256.py): In this config, we try to adopt mixed-precision training for the whole generator, but in partial discriminator (the first 4 higher-resolution stages). Note that we do not apply the loss scaler in the path length loss and gradient penalty loss. Because we always meet divergence after adopting the loss scaler to scale the gradient in these two losses.
-- [stylegan2_c2_apex_fp16_PL-R1-no-scaler](/configs/styleganv2/stylegan2_c2-PL-R1_8xb4-apex-fp16-no-scaler-800kiters_ffhq-256x256.py): In this setting, we adopt the [APEX](https://github.com/NVIDIA/apex) toolkit to implement mixed-precision training with multiple loss/gradient scalers. In APEX, you can assign different loss scalers for the generator and the discriminator respectively. Note that we still ignore the gradient scaler in the path length loss and gradient penalty loss.
+- [stylegan2_c2_fp16_PL-no-scaler](./stylegan2_c2-PL_8xb4-fp16-partial-GD-no-scaler-800kiters_ffhq-256x256.py): In this setting, we try our best to follow the official FP16 implementation in [StyleGAN2-ADA](https://github.com/NVlabs/stylegan2-ada). Similar to the official version, we only adopt FP16 training for the higher-resolution feature maps (the last 4 stages in G and the first 4 stages). Note that we do not adopt the `clamp` way to avoid gradient overflow used in the official implementation. We use the `autocast` function from `torch.cuda.amp` package.
+- [stylegan2_c2_fp16-globalG-partialD_PL-R1-no-scaler](./stylegan2_c2-PL-R1_8xb4-fp16-globalG-partialD-no-scaler-800kiters_ffhq-256x256.py): In this config, we try to adopt mixed-precision training for the whole generator, but in partial discriminator (the first 4 higher-resolution stages). Note that we do not apply the loss scaler in the path length loss and gradient penalty loss. Because we always meet divergence after adopting the loss scaler to scale the gradient in these two losses.
+- [stylegan2_c2_apex_fp16_PL-R1-no-scaler](./stylegan2_c2-PL-R1_8xb4-apex-fp16-no-scaler-800kiters_ffhq-256x256.py): In this setting, we adopt the [APEX](https://github.com/NVIDIA/apex) toolkit to implement mixed-precision training with multiple loss/gradient scalers. In APEX, you can assign different loss scalers for the generator and the discriminator respectively. Note that we still ignore the gradient scaler in the path length loss and gradient penalty loss.
| Model | Comment | Dataset | FID50k | Config | Download |
| :----------------------------------------------: | :-------------------------------------: | :-----: | :----: | :-----------------------------------------------: | :-------------------------------------------------: |
-| stylegan2_config-f_ffhq_256 | baseline | FFHQ256 | 3.992 | [stylegan2_c2_8xb4-800kiters_ffhq-256x256](/configs/styleganv2/stylegan2_c2_8xb4-800kiters_ffhq-256x256.py) | [ckpt](https://download.openmmlab.com/mmgen/stylegan2/stylegan2_c2_ffhq_256_b4x8_20210407_160709-7890ae1f.pth) |
-| stylegan2_c2_fp16_partial-GD_PL-no-scaler_ffhq_256_b4x8_800k | partial layers in fp16 | FFHQ256 | 4.331 | [stylegan2_c2-PL_8xb4-fp16-partial-GD-no-scaler-800kiters_ffhq-256x256](/configs/styleganv2/stylegan2_c2-PL_8xb4-fp16-partial-GD-no-scaler-800kiters_ffhq-256x256.py) | [ckpt](https://download.openmmlab.com/mmgen/stylegan2/stylegan2_c2_fp16_partial-GD_PL-no-scaler_ffhq_256_b4x8_800k_20210508_114854-dacbe4c9.pth) |
-| stylegan2_c2_fp16-globalG-partialD_PL-R1-no-scaler_ffhq_256_b4x8_800k | the whole G in fp16 | FFHQ256 | 4.362 | [stylegan2_c2-PL-R1_8xb4-fp16-globalG-partialD-no-scaler-800kiters_ffhq-256x256](/configs/styleganv2/stylegan2_c2-PL-R1_8xb4-fp16-globalG-partialD-no-scaler-800kiters_ffhq-256x256.py) | [ckpt](https://download.openmmlab.com/mmgen/stylegan2/stylegan2_c2_fp16-globalG-partialD_PL-R1-no-scaler_ffhq_256_b4x8_800k_20210508_114930-ef8270d4.pth) |
-| stylegan2_c2_apex_fp16_PL-R1-no-scaler_ffhq_256_b4x8_800k | the whole G&D in fp16 + two loss scaler | FFHQ256 | 4.614 | [stylegan2_c2-PL-R1_8xb4-apex-fp16-no-scaler-800kiters_ffhq-256x256](/configs/styleganv2/stylegan2_c2-PL-R1_8xb4-apex-fp16-no-scaler-800kiters_ffhq-256x256.py) | [ckpt](https://download.openmmlab.com/mmgen/stylegan2/stylegan2_c2_apex_fp16_PL-R1-no-scaler_ffhq_256_b4x8_800k_20210508_114701-c2bb8afd.pth) |
-
-In addition, we also provide `QuickTestImageDataset` to users for quickly checking whether the code can be run correctly. It's more important for FP16 experiments, because some cuda operations may no support mixed precision training. Esepcially for `APEX`, you can use [this config](/configs/styleganv2/stylegan2_c2_8xb4-apex-fp16-800kiters_quicktest-ffhq-256x256.py) in your local machine by running:
-
-```bash
-bash tools/dist_train.sh \
- configs/styleganv2/stylegan2_c2_8xb4-apex-fp16-800kiters_quicktest-ffhq-256x256.py 1 \
- --work-dir ./work_dirs/quick-test
-```
-
-With a similar way, users can switch to [config for partial-GD](/configs/styleganv2/stylegan2_c2_8xb4-fp16-800kiters_quicktest-ffhq-256x256.py) and [config for globalG-partialD](/configs/styleganv2/stylegan2_c2_8xb4-fp16-global-800kiters_quicktest-ffhq-256x256.py) to test the other two mixed precision training configuration.
+| stylegan2_config-f_ffhq_256 | baseline | FFHQ256 | 3.992 | [stylegan2_c2_8xb4-800kiters_ffhq-256x256](./stylegan2_c2_8xb4-800kiters_ffhq-256x256.py) | [ckpt](https://download.openmmlab.com/mmediting/stylegan2/stylegan2_c2_ffhq_256_b4x8_20210407_160709-7890ae1f.pth) |
+| stylegan2_c2_fp16_partial-GD_PL-no-scaler_ffhq_256_b4x8_800k | partial layers in fp16 | FFHQ256 | 4.331 | [stylegan2_c2-PL_8xb4-fp16-partial-GD-no-scaler-800kiters_ffhq-256x256](./stylegan2_c2-PL_8xb4-fp16-partial-GD-no-scaler-800kiters_ffhq-256x256.py) | [ckpt](https://download.openmmlab.com/mmediting/stylegan2/stylegan2_c2_fp16_partial-GD_PL-no-scaler_ffhq_256_b4x8_800k_20210508_114854-dacbe4c9.pth) |
+| stylegan2_c2_fp16-globalG-partialD_PL-R1-no-scaler_ffhq_256_b4x8_800k | the whole G in fp16 | FFHQ256 | 4.362 | [stylegan2_c2-PL-R1_8xb4-fp16-globalG-partialD-no-scaler-800kiters_ffhq-256x256](./stylegan2_c2-PL-R1_8xb4-fp16-globalG-partialD-no-scaler-800kiters_ffhq-256x256.py) | [ckpt](https://download.openmmlab.com/mmediting/stylegan2/stylegan2_c2_fp16-globalG-partialD_PL-R1-no-scaler_ffhq_256_b4x8_800k_20210508_114930-ef8270d4.pth) |
+| stylegan2_c2_apex_fp16_PL-R1-no-scaler_ffhq_256_b4x8_800k | the whole G&D in fp16 + two loss scaler | FFHQ256 | 4.614 | [stylegan2_c2-PL-R1_8xb4-apex-fp16-no-scaler-800kiters_ffhq-256x256](./stylegan2_c2-PL-R1_8xb4-apex-fp16-no-scaler-800kiters_ffhq-256x256.py) | [ckpt](https://download.openmmlab.com/mmediting/stylegan2/stylegan2_c2_apex_fp16_PL-R1-no-scaler_ffhq_256_b4x8_800k_20210508_114701-c2bb8afd.pth) |
*Note that to use the [APEX](https://github.com/NVIDIA/apex) toolkit, you have to installed it following the official guidance. (APEX is not included in our requirements.) If you are using GPUs without tensor core, you would better to switch to the newer PyTorch version (>= 1.7,0). Otherwise, the APEX installation or running may meet several bugs.*
@@ -76,25 +66,25 @@ With a similar way, users can switch to [config for partial-GD](/configs/stylega
| Model | Comment | FID50k | FID Version | Config | Download |
| :--------------------------: | :-------------: | :----: | :-------------: | :-----------------------------------------------------------------: | :-------------------------------------------------------------------: |
-| stylegan2_config-f_ffhq_1024 | official weight | 2.8732 | Tero's StyleGAN | [stylegan2_c2_8xb4_ffhq-1024x1024](/configs/styleganv2/stylegan2_c2_8xb4_ffhq-1024x1024.py) | [model](https://download.openmmlab.com/mmgen/stylegan2/official_weights/stylegan2-ffhq-config-f-official_20210327_171224-bce9310c.pth) \| [FID-Reals](https://download.openmmlab.com/mmgen/evaluation/fid_inception_pkl/ffhq-1024-50k-stylegan.pkl) |
-| stylegan2_config-f_ffhq_1024 | our training | 2.9413 | Tero's StyleGAN | [stylegan2_c2_8xb4_ffhq-1024x1024](/configs/styleganv2/stylegan2_c2_8xb4_ffhq-1024x1024.py) | [model](https://download.openmmlab.com/mmgen/stylegan2/stylegan2_c2_ffhq_1024_b4x8_20210407_150045-618c9024.pth) \| [FID-Reals](https://download.openmmlab.com/mmgen/evaluation/fid_inception_pkl/ffhq-1024-50k-stylegan.pkl) |
-| stylegan2_config-f_ffhq_1024 | official weight | 2.8134 | Our PyTorch | [stylegan2_c2_8xb4_ffhq-1024x1024](/configs/styleganv2/stylegan2_c2_8xb4_ffhq-1024x1024.py) | [model](https://download.openmmlab.com/mmgen/stylegan2/official_weights/stylegan2-ffhq-config-f-official_20210327_171224-bce9310c.pth) \| [FID-Reals](https://download.openmmlab.com/mmgen/evaluation/fid_inception_pkl/ffhq-1024-50k-rgb.pkl) |
-| stylegan2_config-f_ffhq_1024 | our training | 2.8185 | Our PyTorch | [stylegan2_c2_8xb4_ffhq-1024x1024](/configs/styleganv2/stylegan2_c2_8xb4_ffhq-1024x1024.py) | [model](https://download.openmmlab.com/mmgen/stylegan2/stylegan2_c2_ffhq_1024_b4x8_20210407_150045-618c9024.pth) \| [FID-Reals](https://download.openmmlab.com/mmgen/evaluation/fid_inception_pkl/ffhq-1024-50k-rgb.pkl) |
+| stylegan2_config-f_ffhq_1024 | official weight | 2.8732 | Tero's StyleGAN | [stylegan2_c2_8xb4_ffhq-1024x1024](./stylegan2_c2_8xb4_ffhq-1024x1024.py) | [model](https://download.openmmlab.com/mmediting/stylegan2/official_weights/stylegan2-ffhq-config-f-official_20210327_171224-bce9310c.pth) \| [FID-Reals](https://download.openmmlab.com/mmediting/evaluation/fid_inception_pkl/ffhq-1024-50k-stylegan.pkl) |
+| stylegan2_config-f_ffhq_1024 | our training | 2.9413 | Tero's StyleGAN | [stylegan2_c2_8xb4_ffhq-1024x1024](./stylegan2_c2_8xb4_ffhq-1024x1024.py) | [model](https://download.openmmlab.com/mmediting/stylegan2/stylegan2_c2_ffhq_1024_b4x8_20210407_150045-618c9024.pth) \| [FID-Reals](https://download.openmmlab.com/mmediting/evaluation/fid_inception_pkl/ffhq-1024-50k-stylegan.pkl) |
+| stylegan2_config-f_ffhq_1024 | official weight | 2.8134 | Our PyTorch | [stylegan2_c2_8xb4_ffhq-1024x1024](./stylegan2_c2_8xb4_ffhq-1024x1024.py) | [model](https://download.openmmlab.com/mmediting/stylegan2/official_weights/stylegan2-ffhq-config-f-official_20210327_171224-bce9310c.pth) \| [FID-Reals](https://download.openmmlab.com/mmediting/evaluation/fid_inception_pkl/ffhq-1024-50k-rgb.pkl) |
+| stylegan2_config-f_ffhq_1024 | our training | 2.8185 | Our PyTorch | [stylegan2_c2_8xb4_ffhq-1024x1024](./stylegan2_c2_8xb4_ffhq-1024x1024.py) | [model](https://download.openmmlab.com/mmediting/stylegan2/stylegan2_c2_ffhq_1024_b4x8_20210407_150045-618c9024.pth) \| [FID-Reals](https://download.openmmlab.com/mmediting/evaluation/fid_inception_pkl/ffhq-1024-50k-rgb.pkl) |
In this table, we observe that the FID with Tero's inception network is similar to that with PyTorch Inception (in mmediting). Thus, we use the FID with PyTorch's Inception net (but the weight is not the official model zoo) by default. Because it can be run on different PyTorch versions. If you use [Tero's Inception net](https://nvlabs-fi-cdn.nvidia.com/stylegan2-ada-pytorch/pretrained/metrics/inception-2015-12-05.pt), your PyTorch must meet `>=1.6.0`.
More precalculated inception pickle files are listed here:
-- FFHQ 256x256 real inceptions, PyTorch InceptionV3. [download](https://download.openmmlab.com/mmgen/evaluation/fid_inception_pkl/ffhq-256-50k-rgb.pkl)
-- LSUN-Car 384x512 real inceptions, PyTorch InceptionV3. [download](https://download.openmmlab.com/mmgen/evaluation/fid_inception_pkl/lsun-car-512_50k_rgb.pkl)
+- FFHQ 256x256 real inceptions, PyTorch InceptionV3. [download](https://download.openmmlab.com/mmediting/evaluation/fid_inception_pkl/ffhq-256-50k-rgb.pkl)
+- LSUN-Car 384x512 real inceptions, PyTorch InceptionV3. [download](https://download.openmmlab.com/mmediting/evaluation/fid_inception_pkl/lsun-car-512_50k_rgb.pkl)
## About Different Implementation and Setting of PR Metric
-| Model | P&R Details | Precision | Recall |
-| :--------------------------------------------: | :------------------------------: | :-------: | :----: |
-| stylegan2_config-f_ffhq_1024 (official weight) | use Tero's VGG16, P&R50k_full | 67.876 | 49.299 |
-| stylegan2_config-f_ffhq_1024 (official weight) | use Tero's VGG16, P&R50k | 62.856 | 49.400 |
-| stylegan2_config-f_ffhq_1024 (official weight) | use PyTorch's VGG16, P&R50k_full | 67.662 | 55.460 |
+| Model | Config | Download | P&R Details | Precision | Recall |
+| :--------------------------------------------: | :--------------------------------------------------: | :-----------------------------------------------------: | :------------------------------: | :-------: | :----: |
+| stylegan2_config-f_ffhq_1024 (official weight) | [stylegan2_c2_8xb4_ffhq-1024x1024](./stylegan2_c2_8xb4_ffhq-1024x1024.py) | [model](https://download.openmmlab.com/mmediting/stylegan2/official_weights/stylegan2-ffhq-config-f-official_20210327_171224-bce9310c.pth) | use Tero's VGG16, P&R50k_full | 67.876 | 49.299 |
+| stylegan2_config-f_ffhq_1024 (official weight) | [stylegan2_c2_8xb4_ffhq-1024x1024](./stylegan2_c2_8xb4_ffhq-1024x1024.py) | [model](https://download.openmmlab.com/mmediting/stylegan2/official_weights/stylegan2-ffhq-config-f-official_20210327_171224-bce9310c.pth) | use Tero's VGG16, P&R50k | 62.856 | 49.400 |
+| stylegan2_config-f_ffhq_1024 (official weight) | [stylegan2_c2_8xb4_ffhq-1024x1024](./stylegan2_c2_8xb4_ffhq-1024x1024.py) | [model](https://download.openmmlab.com/mmediting/stylegan2/official_weights/stylegan2-ffhq-config-f-official_20210327_171224-bce9310c.pth) | use PyTorch's VGG16, P&R50k_full | 67.662 | 55.460 |
As shown in this table, `P&R50k_full` is the metric used in StyleGANv1 and StyleGANv2. `full` indicates that we use the whole dataset for extracting the real distribution, e.g., 70000 images in FFHQ dataset. However, adopting the VGG16 provided from [Tero](https://nvlabs-fi-cdn.nvidia.com/stylegan2-ada-pytorch/pretrained/metrics/vgg16.pt) requires that your PyTorch version must fulfill `>=1.6.0`. Be careful about using the PyTorch's VGG16 to extract features, which will cause higher precision and recall.
diff --git a/configs/styleganv2/metafile.yml b/configs/styleganv2/metafile.yml
index e8c2a5f8bf..ff6883d861 100644
--- a/configs/styleganv2/metafile.yml
+++ b/configs/styleganv2/metafile.yml
@@ -6,6 +6,9 @@ Collections:
Paper:
- https://openaccess.thecvf.com/content_CVPR_2020/html/Karras_Analyzing_and_Improving_the_Image_Quality_of_StyleGAN_CVPR_2020_paper.html
README: configs/styleganv2/README.md
+ Task:
+ - unconditional gans
+ Year: 2020
Models:
- Config: configs/styleganv2/stylegan2_c2_8xb4_ffhq-1024x1024.py
In Collection: StyleGANv2
@@ -19,7 +22,7 @@ Models:
Precision50k: 62.856
Recall50k: 49.4
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/stylegan2/official_weights/stylegan2-ffhq-config-f-official_20210327_171224-bce9310c.pth
+ Weights: https://download.openmmlab.com/mmediting/stylegan2/official_weights/stylegan2-ffhq-config-f-official_20210327_171224-bce9310c.pth
- Config: configs/styleganv2/stylegan2_c2_8xb4_lsun-car-384x512.py
In Collection: StyleGANv2
Metadata:
@@ -32,7 +35,7 @@ Models:
Precision50k: 65.986
Recall50k: 48.19
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/stylegan2/official_weights/stylegan2-car-config-f-official_20210327_172340-8cfe053c.pth
+ Weights: https://download.openmmlab.com/mmediting/stylegan2/official_weights/stylegan2-car-config-f-official_20210327_172340-8cfe053c.pth
- Config: configs/styleganv2/stylegan2_c2_8xb4-800kiters_lsun-horse-256x256.py
In Collection: StyleGANv2
Metadata:
@@ -42,7 +45,7 @@ Models:
- Dataset: Others
Metrics: {}
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/stylegan2/official_weights/stylegan2-horse-config-f-official_20210327_173203-ef3e69ca.pth
+ Weights: https://download.openmmlab.com/mmediting/stylegan2/official_weights/stylegan2-horse-config-f-official_20210327_173203-ef3e69ca.pth
- Config: configs/styleganv2/stylegan2_c2_8xb4-800kiters_lsun-church-256x256.py
In Collection: StyleGANv2
Metadata:
@@ -52,7 +55,7 @@ Models:
- Dataset: Others
Metrics: {}
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/stylegan2/official_weights/stylegan2-church-config-f-official_20210327_172657-1d42b7d1.pth
+ Weights: https://download.openmmlab.com/mmediting/stylegan2/official_weights/stylegan2-church-config-f-official_20210327_172657-1d42b7d1.pth
- Config: configs/styleganv2/stylegan2_c2_8xb4-800kiters_lsun-cat-256x256.py
In Collection: StyleGANv2
Metadata:
@@ -62,7 +65,7 @@ Models:
- Dataset: CAT
Metrics: {}
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/stylegan2/official_weights/stylegan2-cat-config-f-official_20210327_172444-15bc485b.pth
+ Weights: https://download.openmmlab.com/mmediting/stylegan2/official_weights/stylegan2-cat-config-f-official_20210327_172444-15bc485b.pth
- Config: configs/styleganv2/stylegan2_c2_8xb4-800kiters_ffhq-256x256.py
In Collection: StyleGANv2
Metadata:
@@ -75,7 +78,7 @@ Models:
Precision50k: 69.012
Recall50k: 40.417
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/stylegan2/stylegan2_c2_ffhq_256_b4x8_20210407_160709-7890ae1f.pth
+ Weights: https://download.openmmlab.com/mmediting/stylegan2/stylegan2_c2_ffhq_256_b4x8_20210407_160709-7890ae1f.pth
- Config: configs/styleganv2/stylegan2_c2_8xb4_ffhq-1024x1024.py
In Collection: StyleGANv2
Metadata:
@@ -88,7 +91,7 @@ Models:
Precision50k: 68.236
Recall50k: 49.583
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/stylegan2/stylegan2_c2_ffhq_1024_b4x8_20210407_150045-618c9024.pth
+ Weights: https://download.openmmlab.com/mmediting/stylegan2/stylegan2_c2_ffhq_1024_b4x8_20210407_150045-618c9024.pth
- Config: configs/styleganv2/stylegan2_c2_8xb4_lsun-car-384x512.py
In Collection: StyleGANv2
Metadata:
@@ -101,7 +104,7 @@ Models:
Precision50k: 66.76
Recall50k: 50.576
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/stylegan2/stylegan2_c2_lsun-car_384x512_b4x8_1800k_20210424_160929-fc9072ca.pth
+ Weights: https://download.openmmlab.com/mmediting/stylegan2/stylegan2_c2_lsun-car_384x512_b4x8_1800k_20210424_160929-fc9072ca.pth
- Config: configs/styleganv2/stylegan2_c2_8xb4-800kiters_ffhq-256x256.py
In Collection: StyleGANv2
Metadata:
@@ -112,7 +115,7 @@ Models:
Metrics:
FID50k: 3.992
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/stylegan2/stylegan2_c2_ffhq_256_b4x8_20210407_160709-7890ae1f.pth
+ Weights: https://download.openmmlab.com/mmediting/stylegan2/stylegan2_c2_ffhq_256_b4x8_20210407_160709-7890ae1f.pth
- Config: configs/styleganv2/stylegan2_c2-PL_8xb4-fp16-partial-GD-no-scaler-800kiters_ffhq-256x256.py
In Collection: StyleGANv2
Metadata:
@@ -123,7 +126,7 @@ Models:
Metrics:
FID50k: 4.331
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/stylegan2/stylegan2_c2_fp16_partial-GD_PL-no-scaler_ffhq_256_b4x8_800k_20210508_114854-dacbe4c9.pth
+ Weights: https://download.openmmlab.com/mmediting/stylegan2/stylegan2_c2_fp16_partial-GD_PL-no-scaler_ffhq_256_b4x8_800k_20210508_114854-dacbe4c9.pth
- Config: configs/styleganv2/stylegan2_c2-PL-R1_8xb4-fp16-globalG-partialD-no-scaler-800kiters_ffhq-256x256.py
In Collection: StyleGANv2
Metadata:
@@ -134,7 +137,7 @@ Models:
Metrics:
FID50k: 4.362
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/stylegan2/stylegan2_c2_fp16-globalG-partialD_PL-R1-no-scaler_ffhq_256_b4x8_800k_20210508_114930-ef8270d4.pth
+ Weights: https://download.openmmlab.com/mmediting/stylegan2/stylegan2_c2_fp16-globalG-partialD_PL-R1-no-scaler_ffhq_256_b4x8_800k_20210508_114930-ef8270d4.pth
- Config: configs/styleganv2/stylegan2_c2-PL-R1_8xb4-apex-fp16-no-scaler-800kiters_ffhq-256x256.py
In Collection: StyleGANv2
Metadata:
@@ -145,7 +148,7 @@ Models:
Metrics:
FID50k: 4.614
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/stylegan2/stylegan2_c2_apex_fp16_PL-R1-no-scaler_ffhq_256_b4x8_800k_20210508_114701-c2bb8afd.pth
+ Weights: https://download.openmmlab.com/mmediting/stylegan2/stylegan2_c2_apex_fp16_PL-R1-no-scaler_ffhq_256_b4x8_800k_20210508_114701-c2bb8afd.pth
- Config: configs/styleganv2/stylegan2_c2_8xb4_ffhq-1024x1024.py
In Collection: StyleGANv2
Metadata:
@@ -156,7 +159,7 @@ Models:
Metrics:
FID50k: 2.8732
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/stylegan2/official_weights/stylegan2-ffhq-config-f-official_20210327_171224-bce9310c.pth
+ Weights: https://download.openmmlab.com/mmediting/stylegan2/official_weights/stylegan2-ffhq-config-f-official_20210327_171224-bce9310c.pth
- Config: configs/styleganv2/stylegan2_c2_8xb4_ffhq-1024x1024.py
In Collection: StyleGANv2
Metadata:
@@ -167,7 +170,7 @@ Models:
Metrics:
FID50k: 2.9413
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/stylegan2/stylegan2_c2_ffhq_1024_b4x8_20210407_150045-618c9024.pth
+ Weights: https://download.openmmlab.com/mmediting/stylegan2/stylegan2_c2_ffhq_1024_b4x8_20210407_150045-618c9024.pth
- Config: configs/styleganv2/stylegan2_c2_8xb4_ffhq-1024x1024.py
In Collection: StyleGANv2
Metadata:
@@ -178,7 +181,7 @@ Models:
Metrics:
FID50k: 2.8134
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/stylegan2/official_weights/stylegan2-ffhq-config-f-official_20210327_171224-bce9310c.pth
+ Weights: https://download.openmmlab.com/mmediting/stylegan2/official_weights/stylegan2-ffhq-config-f-official_20210327_171224-bce9310c.pth
- Config: configs/styleganv2/stylegan2_c2_8xb4_ffhq-1024x1024.py
In Collection: StyleGANv2
Metadata:
@@ -189,4 +192,40 @@ Models:
Metrics:
FID50k: 2.8185
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/stylegan2/stylegan2_c2_ffhq_1024_b4x8_20210407_150045-618c9024.pth
+ Weights: https://download.openmmlab.com/mmediting/stylegan2/stylegan2_c2_ffhq_1024_b4x8_20210407_150045-618c9024.pth
+- Config: configs/styleganv2/stylegan2_c2_8xb4_ffhq-1024x1024.py
+ In Collection: StyleGANv2
+ Metadata:
+ Training Data: FFHQ
+ Name: stylegan2_c2_8xb4_ffhq-1024x1024
+ Results:
+ - Dataset: FFHQ
+ Metrics:
+ Precision: 67.876
+ Recall: 49.299
+ Task: Unconditional GANs
+ Weights: https://download.openmmlab.com/mmediting/stylegan2/official_weights/stylegan2-ffhq-config-f-official_20210327_171224-bce9310c.pth
+- Config: configs/styleganv2/stylegan2_c2_8xb4_ffhq-1024x1024.py
+ In Collection: StyleGANv2
+ Metadata:
+ Training Data: FFHQ
+ Name: stylegan2_c2_8xb4_ffhq-1024x1024
+ Results:
+ - Dataset: FFHQ
+ Metrics:
+ Precision: 62.856
+ Recall: 49.4
+ Task: Unconditional GANs
+ Weights: https://download.openmmlab.com/mmediting/stylegan2/official_weights/stylegan2-ffhq-config-f-official_20210327_171224-bce9310c.pth
+- Config: configs/styleganv2/stylegan2_c2_8xb4_ffhq-1024x1024.py
+ In Collection: StyleGANv2
+ Metadata:
+ Training Data: FFHQ
+ Name: stylegan2_c2_8xb4_ffhq-1024x1024
+ Results:
+ - Dataset: FFHQ
+ Metrics:
+ Precision: 67.662
+ Recall: 55.46
+ Task: Unconditional GANs
+ Weights: https://download.openmmlab.com/mmediting/stylegan2/official_weights/stylegan2-ffhq-config-f-official_20210327_171224-bce9310c.pth
diff --git a/configs/styleganv2/stylegan2_c2_8xb4-apex-fp16-800kiters_quicktest-ffhq-256x256.py b/configs/styleganv2/stylegan2_c2_8xb4-apex-fp16-800kiters_quicktest-ffhq-256x256.py
deleted file mode 100644
index 021613a3f8..0000000000
--- a/configs/styleganv2/stylegan2_c2_8xb4-apex-fp16-800kiters_quicktest-ffhq-256x256.py
+++ /dev/null
@@ -1,39 +0,0 @@
-"""Config for the `config-f` setting in StyleGAN2."""
-
-_base_ = ['./stylegan2_c2_8xb4-800kiters_ffhq-256x256.py']
-
-model = dict(
- generator=dict(out_size=256),
- discriminator=dict(in_size=256, convert_input_fp32=False),
-)
-
-# remain to be refactored
-apex_amp = dict(
- mode='gan', init_args=dict(opt_level='O1', num_losses=2, loss_scale=512.))
-
-train_cfg = dict(max_iters=800002)
-
-batch_size = 2
-dataset_type = 'QuickTestImageDataset'
-
-train_dataloader = dict(batch_size=batch_size, dataset=dict(type=dataset_type))
-
-val_dataloader = dict(batch_size=batch_size, dataset=dict(type=dataset_type))
-
-test_dataloader = dict(
- batch_size=batch_size, dataset=dict(dataset_type=dataset_type))
-
-default_hooks = dict(logger=dict(type='LoggerHook', interval=1))
-
-# METRICS
-metrics = [
- dict(
- type='FrechetInceptionDistance',
- prefix='FID-Full-50k',
- fake_nums=50000,
- inception_style='StyleGAN',
- sample_model='ema')
-]
-
-val_evaluator = dict(metrics=metrics)
-test_evaluator = dict(metrics=metrics)
diff --git a/configs/styleganv2/stylegan2_c2_8xb4-fp16-800kiters_quicktest-ffhq-256x256.py b/configs/styleganv2/stylegan2_c2_8xb4-fp16-800kiters_quicktest-ffhq-256x256.py
deleted file mode 100644
index da117af082..0000000000
--- a/configs/styleganv2/stylegan2_c2_8xb4-fp16-800kiters_quicktest-ffhq-256x256.py
+++ /dev/null
@@ -1,41 +0,0 @@
-"""Config for the `config-f` setting in StyleGAN2."""
-
-_base_ = ['./stylegan2_c2_8xb4-800kiters_ffhq-256x256.py']
-
-model = dict(
- generator=dict(out_size=256, num_fp16_scales=4),
- discriminator=dict(in_size=256, num_fp16_scales=4),
- disc_auxiliary_loss=dict(data_info=dict(loss_scaler='loss_scaler')),
- # gen_auxiliary_loss=dict(data_info=dict(loss_scaler='loss_scaler')),
-)
-
-batch_size = 2
-dataset_type = 'QuickTestImageDataset'
-
-train_dataloader = dict(batch_size=batch_size, dataset=dict(type=dataset_type))
-
-val_dataloader = dict(batch_size=batch_size, dataset=dict(type=dataset_type))
-
-test_dataloader = dict(
- batch_size=batch_size, dataset=dict(dataset_type=dataset_type))
-
-default_hooks = dict(logger=dict(type='LoggerHook', interval=1))
-
-train_cfg = dict(max_iters=800002)
-
-optim_wrapper = dict(
- generator=dict(type='AmpOptimWrapper', loss_scale=512),
- discriminator=dict(type='AmpOptimWrapper', loss_scale=512))
-
-# METRICS
-metrics = [
- dict(
- type='FrechetInceptionDistance',
- prefix='FID-Full-50k',
- fake_nums=50000,
- inception_style='StyleGAN',
- sample_model='ema')
-]
-
-val_evaluator = dict(metrics=metrics)
-test_evaluator = dict(metrics=metrics)
diff --git a/configs/styleganv2/stylegan2_c2_8xb4-fp16-global-800kiters_quicktest-ffhq-256x256.py b/configs/styleganv2/stylegan2_c2_8xb4-fp16-global-800kiters_quicktest-ffhq-256x256.py
deleted file mode 100644
index a053408f29..0000000000
--- a/configs/styleganv2/stylegan2_c2_8xb4-fp16-global-800kiters_quicktest-ffhq-256x256.py
+++ /dev/null
@@ -1,41 +0,0 @@
-"""Config for the `config-f` setting in StyleGAN2."""
-
-_base_ = ['./stylegan2_c2_8xb4-800kiters_ffhq-256x256.py']
-
-model = dict(
- generator=dict(out_size=256, fp16_enabled=True),
- discriminator=dict(in_size=256, fp16_enabled=True),
- disc_auxiliary_loss=dict(data_info=dict(loss_scaler='loss_scaler')),
- # gen_auxiliary_loss=dict(data_info=dict(loss_scaler='loss_scaler')),
-)
-
-batch_size = 2
-dataset_type = 'QuickTestImageDataset'
-
-train_dataloader = dict(batch_size=batch_size, dataset=dict(type=dataset_type))
-
-val_dataloader = dict(batch_size=batch_size, dataset=dict(type=dataset_type))
-
-test_dataloader = dict(
- batch_size=batch_size, dataset=dict(dataset_type=dataset_type))
-
-default_hooks = dict(logger=dict(type='LoggerHook', interval=1))
-
-train_cfg = dict(max_iters=800002)
-
-optim_wrapper = dict(
- generator=dict(type='AmpOptimWrapper', loss_scale=512),
- discriminator=dict(type='AmpOptimWrapper', loss_scale=512))
-
-# METRICS
-metrics = [
- dict(
- type='FrechetInceptionDistance',
- prefix='FID-Full-50k',
- fake_nums=50000,
- inception_style='StyleGAN',
- sample_model='ema')
-]
-
-val_evaluator = dict(metrics=metrics)
-test_evaluator = dict(metrics=metrics)
diff --git a/configs/styleganv3/README.md b/configs/styleganv3/README.md
index bcb1c677d4..7c67da280c 100644
--- a/configs/styleganv3/README.md
+++ b/configs/styleganv3/README.md
@@ -40,26 +40,26 @@ For user convenience, we also offer the converted version of official weights.
| Model | Dataset | Iter | FID50k | Config | Log | Download |
| :-------------: | :---------------: | :----: | :---------------: | :----------------------------------------------: | :--------------------------------------------: | :-------------------------------------------------: |
-| stylegan3-t | ffhq 1024x1024 | 490000 | 3.37\* | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/styleganv3/stylegan3-t_gamma32.8_8xb4-fp16-noaug_ffhq-1024x1024.py) | [log](https://download.openmmlab.com/mmgen/stylegan3/stylegan3_t_noaug_fp16_gamma32.8_ffhq_1024_b4x8_20220322_090417.log.json) | [model](https://download.openmmlab.com/mmgen/stylegan3/stylegan3_t_noaug_fp16_gamma32.8_ffhq_1024_b4x8_best_fid_iter_490000_20220401_120733-4ff83434.pth) |
-| stylegan3-t-ada | metface 1024x1024 | 130000 | 15.09 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/styleganv3/stylegan3-t_ada-gamma6.6_8xb4-fp16_metfaces-1024x1024.py) | [log](https://download.openmmlab.com/mmgen/stylegan3/stylegan3_t_ada_fp16_gamma6.6_metfaces_1024_b4x8_20220328_142211.log.json) | [model](https://download.openmmlab.com/mmgen/stylegan3/stylegan3_t_ada_fp16_gamma6.6_metfaces_1024_b4x8_best_fid_iter_130000_20220401_115101-f2ef498e.pth) |
+| stylegan3-t | ffhq 1024x1024 | 490000 | 3.37\* | [config](./stylegan3-t_gamma32.8_8xb4-fp16-noaug_ffhq-1024x1024.py) | [log](https://download.openmmlab.com/mmediting/stylegan3/stylegan3_t_noaug_fp16_gamma32.8_ffhq_1024_b4x8_20220322_090417.log.json) | [model](https://download.openmmlab.com/mmediting/stylegan3/stylegan3_t_noaug_fp16_gamma32.8_ffhq_1024_b4x8_best_fid_iter_490000_20220401_120733-4ff83434.pth) |
+| stylegan3-t-ada | metface 1024x1024 | 130000 | 15.09 | [config](./stylegan3-t_ada-gamma6.6_8xb4-fp16_metfaces-1024x1024.py) | [log](https://download.openmmlab.com/mmediting/stylegan3/stylegan3_t_ada_fp16_gamma6.6_metfaces_1024_b4x8_20220328_142211.log.json) | [model](https://download.openmmlab.com/mmediting/stylegan3/stylegan3_t_ada_fp16_gamma6.6_metfaces_1024_b4x8_best_fid_iter_130000_20220401_115101-f2ef498e.pth) |
### Experimental Settings
| Model | Dataset | Iter | FID50k | Config | Log | Download |
| :-------------: | :------------: | :----: | :----: | :---------------------------------------------------: | :------------------------------------------------: | :------------------------------------------------------: |
-| stylegan3-t | ffhq 256x256 | 740000 | 4.51 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/styleganv3/stylegan3-t_gamma2.0_8xb4-fp16-noaug_ffhq-256x256.py) | [log](https://download.openmmlab.com/mmgen/stylegan3/stylegan3_t_noaug_fp16_gamma2.0_ffhq_256_b4x8_20220323_144815.log.json) | [model](https://download.openmmlab.com/mmgen/stylegan3/stylegan3_t_noaug_fp16_gamma2.0_ffhq_256_b4x8_best_fid_iter_740000_20220401_122456-730e1fba.pth) |
-| stylegan3-r-ada | ffhq 1024x1024 | - | - | [config](/configs/styleganv3/stylegan3-r_ada-gamma3.3_8xb4-fp16_metfaces-1024x1024.py) | - | - |
+| stylegan3-t | ffhq 256x256 | 740000 | 4.51 | [config](./stylegan3-t_gamma2.0_8xb4-fp16-noaug_ffhq-256x256.py) | [log](https://download.openmmlab.com/mmediting/stylegan3/stylegan3_t_noaug_fp16_gamma2.0_ffhq_256_b4x8_20220323_144815.log.json) | [model](https://download.openmmlab.com/mmediting/stylegan3/stylegan3_t_noaug_fp16_gamma2.0_ffhq_256_b4x8_best_fid_iter_740000_20220401_122456-730e1fba.pth) |
+| stylegan3-r-ada | ffhq 1024x1024 | - | - | [config](./stylegan3-r_ada-gamma3.3_8xb4-fp16_metfaces-1024x1024.py) | - | - |
### Converted Weights
-| Model | Dataset | Comment | FID50k | EQ-T | EQ-R | Config | Download |
-| :---------: | :------------: | :-------------: | :----: | :---: | :---: | :---------------------------------------------------------------------: | :-----------------------------------------------------------------------: |
-| stylegan3-t | ffhqu 256x256 | official weight | 4.62 | 63.01 | 13.12 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/styleganv3/stylegan3-t_cvt-official-rgb_8xb4_ffhqu-256x256.py) | [model](https://download.openmmlab.com/mmgen/stylegan3/stylegan3_t_ffhqu_256_b4x8_cvt_official_rgb_20220329_235046-153df4c8.pth) |
-| stylegan3-t | afhqv2 512x512 | official weight | 4.04 | 60.15 | 13.51 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/styleganv3/stylegan3-t_cvt-official-rgb_8xb4_afhqv2-512x512.py) | [model](https://download.openmmlab.com/mmgen/stylegan3/stylegan3_t_afhqv2_512_b4x8_cvt_official_rgb_20220329_235017-ee6b037a.pth) |
-| stylegan3-t | ffhq 1024x1024 | official weight | 2.79 | 61.21 | 13.82 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/styleganv3/stylegan3-t_cvt-official-rgb_8xb4_ffhq-1024x1024.py) | [model](https://download.openmmlab.com/mmgen/stylegan3/stylegan3_t_ffhq_1024_b4x8_cvt_official_rgb_20220329_235113-db6c6580.pth) |
-| stylegan3-r | ffhqu 256x256 | official weight | 4.50 | 66.65 | 40.48 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/styleganv3/stylegan3-r_cvt-official-rgb_8xb4_ffhqu-256x256.py) | [model](https://download.openmmlab.com/mmgen/stylegan3/stylegan3_r_ffhqu_256_b4x8_cvt_official_rgb_20220329_234909-4521d963.pth) |
-| stylegan3-r | afhqv2 512x512 | official weight | 4.40 | 64.89 | 40.34 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/styleganv3/stylegan3-r_cvt-official-rgb_8xb4x8_afhqv2-512x512.py) | [model](https://download.openmmlab.com/mmgen/stylegan3/stylegan3_r_afhqv2_512_b4x8_cvt_official_rgb_20220329_234829-f2eaca72.pth) |
-| stylegan3-r | ffhq 1024x1024 | official weight | 3.07 | 64.76 | 46.62 | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/styleganv3/stylegan3-r_cvt-official-rgb_8xb4_ffhq-1024x1024.py) | [model](https://download.openmmlab.com/mmgen/stylegan3/stylegan3_r_ffhq_1024_b4x8_cvt_official_rgb_20220329_234933-ac0500a1.pth) |
+| Model | Dataset | Comment | FID50k | EQ-T | EQ-R | Config | Download |
+| :---------: | :------------: | :-------------: | :----: | :---: | :---: | :---------------------------------------------------------------: | :-----------------------------------------------------------------------------: |
+| stylegan3-t | ffhqu 256x256 | official weight | 4.62 | 63.01 | 13.12 | [config](./stylegan3-t_cvt-official-rgb_8xb4_ffhqu-256x256.py) | [model](https://download.openmmlab.com/mmediting/stylegan3/stylegan3_t_ffhqu_256_b4x8_cvt_official_rgb_20220329_235046-153df4c8.pth) |
+| stylegan3-t | afhqv2 512x512 | official weight | 4.04 | 60.15 | 13.51 | [config](./stylegan3-t_cvt-official-rgb_8xb4_afhqv2-512x512.py) | [model](https://download.openmmlab.com/mmediting/stylegan3/stylegan3_t_afhqv2_512_b4x8_cvt_official_rgb_20220329_235017-ee6b037a.pth) |
+| stylegan3-t | ffhq 1024x1024 | official weight | 2.79 | 61.21 | 13.82 | [config](./stylegan3-t_cvt-official-rgb_8xb4_ffhq-1024x1024.py) | [model](https://download.openmmlab.com/mmediting/stylegan3/stylegan3_t_ffhq_1024_b4x8_cvt_official_rgb_20220329_235113-db6c6580.pth) |
+| stylegan3-r | ffhqu 256x256 | official weight | 4.50 | 66.65 | 40.48 | [config](./stylegan3-r_cvt-official-rgb_8xb4_ffhqu-256x256.py) | [model](https://download.openmmlab.com/mmediting/stylegan3/stylegan3_r_ffhqu_256_b4x8_cvt_official_rgb_20220329_234909-4521d963.pth) |
+| stylegan3-r | afhqv2 512x512 | official weight | 4.40 | 64.89 | 40.34 | [config](./stylegan3-r_cvt-official-rgb_8xb4x8_afhqv2-512x512.py) | [model](https://download.openmmlab.com/mmediting/stylegan3/stylegan3_r_afhqv2_512_b4x8_cvt_official_rgb_20220329_234829-f2eaca72.pth) |
+| stylegan3-r | ffhq 1024x1024 | official weight | 3.07 | 64.76 | 46.62 | [config](./stylegan3-r_cvt-official-rgb_8xb4_ffhq-1024x1024.py) | [model](https://download.openmmlab.com/mmediting/stylegan3/stylegan3_r_ffhq_1024_b4x8_cvt_official_rgb_20220329_234933-ac0500a1.pth) |
## Interpolation
@@ -67,7 +67,7 @@ We provide a tool to generate video by walking through GAN's latent space.
Run this command to get the following video.
```bash
-python apps/interpolate_sample.py configs/styleganv3/stylegan3_t_afhqv2_512_b4x8_official.py https://download.openmmlab.com/mmgen/stylegan3/stylegan3_t_afhqv2_512_b4x8_cvt_official.pkl --export-video --samples-path work_dirs/demos/ --endpoint 6 --interval 60 --space z --seed 2022 --sample-cfg truncation=0.8
+python apps/interpolate_sample.py configs/styleganv3/stylegan3_t_afhqv2_512_b4x8_official.py https://download.openmmlab.com/mmediting/stylegan3/stylegan3_t_afhqv2_512_b4x8_cvt_official.pkl --export-video --samples-path work_dirs/demos/ --endpoint 6 --interval 60 --space z --seed 2022 --sample-cfg truncation=0.8
```
https://user-images.githubusercontent.com/22982797/151506918-83da9ee3-0d63-4c5b-ad53-a41562b92075.mp4
@@ -78,11 +78,11 @@ We also provide a tool to visualize the equivarience properties for StyleGAN3.
Run these commands to get the results below.
```bash
-python tools/utils/equivariance_viz.py configs/styleganv3/stylegan3_r_ffhqu_256_b4x8_official.py https://download.openmmlab.com/mmgen/stylegan3/stylegan3_r_ffhqu_256_b4x8_cvt_official.pkl --translate_max 0.5 --transform rotate --seed 5432
+python tools/utils/equivariance_viz.py configs/styleganv3/stylegan3_r_ffhqu_256_b4x8_official.py https://download.openmmlab.com/mmediting/stylegan3/stylegan3_r_ffhqu_256_b4x8_cvt_official.pkl --translate_max 0.5 --transform rotate --seed 5432
-python tools/utils/equivariance_viz.py configs/styleganv3/stylegan3_r_ffhqu_256_b4x8_official.py https://openmmlab-share.oss-cn-hangzhou.aliyuncs.com/mmgen/stylegan3/stylegan3_r_ffhqu_256_b4x8_cvt_official.pkl --translate_max 0.25 --transform x_t --seed 5432
+python tools/utils/equivariance_viz.py configs/styleganv3/stylegan3_r_ffhqu_256_b4x8_official.py https://download.openmmlab.com/mmediting/stylegan3/stylegan3_r_ffhqu_256_b4x8_cvt_official.pkl --translate_max 0.25 --transform x_t --seed 5432
-python tools/utils/equivariance_viz.py configs/styleganv3/stylegan3_r_ffhqu_256_b4x8_official.py https://openmmlab-share.oss-cn-hangzhou.aliyuncs.com/mmgen/stylegan3/stylegan3_r_ffhqu_256_b4x8_cvt_official.pkl --translate_max 0.25 --transform y_t --seed 5432
+python tools/utils/equivariance_viz.py configs/styleganv3/stylegan3_r_ffhqu_256_b4x8_official.py https://download.openmmlab.com/mmediting/stylegan3/stylegan3_r_ffhqu_256_b4x8_cvt_official.pkl --translate_max 0.25 --transform y_t --seed 5432
```
https://user-images.githubusercontent.com/22982797/151504902-f3cbfef5-9014-4607-bbe1-deaf48ec6d55.mp4
@@ -102,7 +102,7 @@ metrics = dict(
compute_eqt_int=True, compute_eqt_frac=True, compute_eqr=True)))
```
-And we highly recommend you to use [slurm_eval_multi_gpu](tools/slurm_eval_multi_gpu.sh) script to accelerate evaluation time.
+And we highly recommend you to use [slurm_test.sh](../../tools/slurm_test.sh) script to accelerate evaluation time.
## Citation
diff --git a/configs/styleganv3/metafile.yml b/configs/styleganv3/metafile.yml
index 9389454d6a..4224b0e174 100644
--- a/configs/styleganv3/metafile.yml
+++ b/configs/styleganv3/metafile.yml
@@ -6,8 +6,11 @@ Collections:
Paper:
- https://nvlabs-fi-cdn.nvidia.com/stylegan3/stylegan3-paper.pdf
README: configs/styleganv3/README.md
+ Task:
+ - unconditional gans
+ Year: 2021
Models:
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/styleganv3/stylegan3-t_gamma32.8_8xb4-fp16-noaug_ffhq-1024x1024.py
+- Config: configs/styleganv3/stylegan3-t_gamma32.8_8xb4-fp16-noaug_ffhq-1024x1024.py
In Collection: StyleGANv3
Metadata:
Training Data: FFHQ
@@ -17,8 +20,8 @@ Models:
Metrics:
Iter: 490000.0
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/stylegan3/stylegan3_t_noaug_fp16_gamma32.8_ffhq_1024_b4x8_best_fid_iter_490000_20220401_120733-4ff83434.pth
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/styleganv3/stylegan3-t_ada-gamma6.6_8xb4-fp16_metfaces-1024x1024.py
+ Weights: https://download.openmmlab.com/mmediting/stylegan3/stylegan3_t_noaug_fp16_gamma32.8_ffhq_1024_b4x8_best_fid_iter_490000_20220401_120733-4ff83434.pth
+- Config: configs/styleganv3/stylegan3-t_ada-gamma6.6_8xb4-fp16_metfaces-1024x1024.py
In Collection: StyleGANv3
Metadata:
Training Data: Others
@@ -29,8 +32,8 @@ Models:
FID50k: 15.09
Iter: 130000.0
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/stylegan3/stylegan3_t_ada_fp16_gamma6.6_metfaces_1024_b4x8_best_fid_iter_130000_20220401_115101-f2ef498e.pth
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/styleganv3/stylegan3-t_gamma2.0_8xb4-fp16-noaug_ffhq-256x256.py
+ Weights: https://download.openmmlab.com/mmediting/stylegan3/stylegan3_t_ada_fp16_gamma6.6_metfaces_1024_b4x8_best_fid_iter_130000_20220401_115101-f2ef498e.pth
+- Config: configs/styleganv3/stylegan3-t_gamma2.0_8xb4-fp16-noaug_ffhq-256x256.py
In Collection: StyleGANv3
Metadata:
Training Data: FFHQ
@@ -41,7 +44,7 @@ Models:
FID50k: 4.51
Iter: 740000.0
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/stylegan3/stylegan3_t_noaug_fp16_gamma2.0_ffhq_256_b4x8_best_fid_iter_740000_20220401_122456-730e1fba.pth
+ Weights: https://download.openmmlab.com/mmediting/stylegan3/stylegan3_t_noaug_fp16_gamma2.0_ffhq_256_b4x8_best_fid_iter_740000_20220401_122456-730e1fba.pth
- Config: configs/styleganv3/stylegan3-r_ada-gamma3.3_8xb4-fp16_metfaces-1024x1024.py
In Collection: StyleGANv3
Metadata:
@@ -52,7 +55,7 @@ Models:
Metrics: {}
Task: Unconditional GANs
Weights: ''
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/styleganv3/stylegan3-t_cvt-official-rgb_8xb4_ffhqu-256x256.py
+- Config: configs/styleganv3/stylegan3-t_cvt-official-rgb_8xb4_ffhqu-256x256.py
In Collection: StyleGANv3
Metadata:
Training Data: FFHQ
@@ -64,8 +67,8 @@ Models:
EQ-T: 63.01
FID50k: 4.62
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/stylegan3/stylegan3_t_ffhqu_256_b4x8_cvt_official_rgb_20220329_235046-153df4c8.pth
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/styleganv3/stylegan3-t_cvt-official-rgb_8xb4_afhqv2-512x512.py
+ Weights: https://download.openmmlab.com/mmediting/stylegan3/stylegan3_t_ffhqu_256_b4x8_cvt_official_rgb_20220329_235046-153df4c8.pth
+- Config: configs/styleganv3/stylegan3-t_cvt-official-rgb_8xb4_afhqv2-512x512.py
In Collection: StyleGANv3
Metadata:
Training Data: Others
@@ -77,8 +80,8 @@ Models:
EQ-T: 60.15
FID50k: 4.04
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/stylegan3/stylegan3_t_afhqv2_512_b4x8_cvt_official_rgb_20220329_235017-ee6b037a.pth
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/styleganv3/stylegan3-t_cvt-official-rgb_8xb4_ffhq-1024x1024.py
+ Weights: https://download.openmmlab.com/mmediting/stylegan3/stylegan3_t_afhqv2_512_b4x8_cvt_official_rgb_20220329_235017-ee6b037a.pth
+- Config: configs/styleganv3/stylegan3-t_cvt-official-rgb_8xb4_ffhq-1024x1024.py
In Collection: StyleGANv3
Metadata:
Training Data: FFHQ
@@ -90,8 +93,8 @@ Models:
EQ-T: 61.21
FID50k: 2.79
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/stylegan3/stylegan3_t_ffhq_1024_b4x8_cvt_official_rgb_20220329_235113-db6c6580.pth
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/styleganv3/stylegan3-r_cvt-official-rgb_8xb4_ffhqu-256x256.py
+ Weights: https://download.openmmlab.com/mmediting/stylegan3/stylegan3_t_ffhq_1024_b4x8_cvt_official_rgb_20220329_235113-db6c6580.pth
+- Config: configs/styleganv3/stylegan3-r_cvt-official-rgb_8xb4_ffhqu-256x256.py
In Collection: StyleGANv3
Metadata:
Training Data: FFHQ
@@ -103,8 +106,8 @@ Models:
EQ-T: 66.65
FID50k: 4.5
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/stylegan3/stylegan3_r_ffhqu_256_b4x8_cvt_official_rgb_20220329_234909-4521d963.pth
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/styleganv3/stylegan3-r_cvt-official-rgb_8xb4x8_afhqv2-512x512.py
+ Weights: https://download.openmmlab.com/mmediting/stylegan3/stylegan3_r_ffhqu_256_b4x8_cvt_official_rgb_20220329_234909-4521d963.pth
+- Config: configs/styleganv3/stylegan3-r_cvt-official-rgb_8xb4x8_afhqv2-512x512.py
In Collection: StyleGANv3
Metadata:
Training Data: Others
@@ -116,8 +119,8 @@ Models:
EQ-T: 64.89
FID50k: 4.4
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/stylegan3/stylegan3_r_afhqv2_512_b4x8_cvt_official_rgb_20220329_234829-f2eaca72.pth
-- Config: https://github.com/open-mmlab/mmediting/tree/master/configs/styleganv3/stylegan3-r_cvt-official-rgb_8xb4_ffhq-1024x1024.py
+ Weights: https://download.openmmlab.com/mmediting/stylegan3/stylegan3_r_afhqv2_512_b4x8_cvt_official_rgb_20220329_234829-f2eaca72.pth
+- Config: configs/styleganv3/stylegan3-r_cvt-official-rgb_8xb4_ffhq-1024x1024.py
In Collection: StyleGANv3
Metadata:
Training Data: FFHQ
@@ -129,4 +132,4 @@ Models:
EQ-T: 64.76
FID50k: 3.07
Task: Unconditional GANs
- Weights: https://download.openmmlab.com/mmgen/stylegan3/stylegan3_r_ffhq_1024_b4x8_cvt_official_rgb_20220329_234933-ac0500a1.pth
+ Weights: https://download.openmmlab.com/mmediting/stylegan3/stylegan3_r_ffhq_1024_b4x8_cvt_official_rgb_20220329_234933-ac0500a1.pth
diff --git a/configs/styleganv3/stylegan3-r_ada-gamma3.3_8xb4-fp16_metfaces-1024x1024.py b/configs/styleganv3/stylegan3-r_ada-gamma3.3_8xb4-fp16_metfaces-1024x1024.py
index cef1bab104..094fa6edae 100644
--- a/configs/styleganv3/stylegan3-r_ada-gamma3.3_8xb4-fp16_metfaces-1024x1024.py
+++ b/configs/styleganv3/stylegan3-r_ada-gamma3.3_8xb4-fp16_metfaces-1024x1024.py
@@ -19,7 +19,7 @@
g_reg_ratio = g_reg_interval / (g_reg_interval + 1)
d_reg_ratio = d_reg_interval / (d_reg_interval + 1)
-load_from = 'https://download.openmmlab.com/mmgen/stylegan3/stylegan3_r_ffhq_1024_b4x8_cvt_official_rgb_20220329_234933-ac0500a1.pth' # noqa
+load_from = 'https://download.openmmlab.com/mmediting/stylegan3/stylegan3_r_ffhq_1024_b4x8_cvt_official_rgb_20220329_234933-ac0500a1.pth' # noqa
# ada settings
aug_kwargs = {
diff --git a/configs/styleganv3/stylegan3-t_ada-gamma6.6_8xb4-fp16_metfaces-1024x1024.py b/configs/styleganv3/stylegan3-t_ada-gamma6.6_8xb4-fp16_metfaces-1024x1024.py
index eb62691618..56ced90640 100644
--- a/configs/styleganv3/stylegan3-t_ada-gamma6.6_8xb4-fp16_metfaces-1024x1024.py
+++ b/configs/styleganv3/stylegan3-t_ada-gamma6.6_8xb4-fp16_metfaces-1024x1024.py
@@ -17,7 +17,7 @@
g_reg_ratio = g_reg_interval / (g_reg_interval + 1)
d_reg_ratio = d_reg_interval / (d_reg_interval + 1)
-load_from = 'https://download.openmmlab.com/mmgen/stylegan3/stylegan3_t_ffhq_1024_b4x8_cvt_official_rgb_20220329_235113-db6c6580.pth' # noqa
+load_from = 'https://download.openmmlab.com/mmediting/stylegan3/stylegan3_t_ffhq_1024_b4x8_cvt_official_rgb_20220329_235113-db6c6580.pth' # noqa
# ada settings
aug_kwargs = {
'xflip': 1,
diff --git a/configs/swinir/README.md b/configs/swinir/README.md
new file mode 100644
index 0000000000..2ada8e12e6
--- /dev/null
+++ b/configs/swinir/README.md
@@ -0,0 +1,512 @@
+# SwinIR (ICCVW'2021)
+
+> [SwinIR: Image Restoration Using Swin Transformer](https://arxiv.org/abs/2108.10257)
+
+> **Task**: Image Super-Resolution, Image denoising, JPEG compression artifact reduction
+
+
+
+## Abstract
+
+
+
+Image restoration is a long-standing low-level vision problem that aims to restore high-quality images from low-quality images (e.g., downscaled, noisy and compressed images). While state-of-the-art image restoration methods are based on convolutional neural networks, few attempts have been made with Transformers which show impressive performance on high-level vision tasks. In this paper, we propose a strong baseline model SwinIR for image restoration based on the Swin Transformer. SwinIR consists of three parts: shallow feature extraction, deep feature extraction and high-quality image reconstruction. In particular, the deep feature extraction module is composed of several residual Swin Transformer blocks (RSTB), each of which has several Swin Transformer layers together with a residual connection. We conduct experiments on three representative tasks: image super-resolution (including classical, lightweight and real-world image super-resolution), image denoising (including grayscale and color image denoising) and JPEG compression artifact reduction. Experimental results demonstrate that SwinIR outperforms state-of-the-art methods on different tasks by up to 0.14~0.45dB, while the total number of parameters can be reduced by up to 67%.
+
+
+
+ +
++ Oops! The page you are looking for cannot be found. +
++ This is likely to happen when you are switching document versions and the page you are reading is moved to another location in the new version. You can look for it in the content table left, or go to the homepage. +
++ If you cannot find documentation you want, please open an issue to tell us! +
+ +{% endblock %} diff --git a/docs/en/_templates/python/attribute.rst b/docs/en/_templates/python/attribute.rst new file mode 100644 index 0000000000..ebaba555ad --- /dev/null +++ b/docs/en/_templates/python/attribute.rst @@ -0,0 +1 @@ +{% extends "python/data.rst" %} diff --git a/docs/en/_templates/python/class.rst b/docs/en/_templates/python/class.rst new file mode 100644 index 0000000000..df5edffb62 --- /dev/null +++ b/docs/en/_templates/python/class.rst @@ -0,0 +1,58 @@ +{% if obj.display %} +.. py:{{ obj.type }}:: {{ obj.short_name }}{% if obj.args %}({{ obj.args }}){% endif %} +{% for (args, return_annotation) in obj.overloads %} + {{ " " * (obj.type | length) }} {{ obj.short_name }}{% if args %}({{ args }}){% endif %} +{% endfor %} + + + {% if obj.bases %} + {% if "show-inheritance" in autoapi_options %} + Bases: {% for base in obj.bases %}{{ base|link_objs }}{% if not loop.last %}, {% endif %}{% endfor %} + {% endif %} + + + {% if "show-inheritance-diagram" in autoapi_options and obj.bases != ["object"] %} + .. autoapi-inheritance-diagram:: {{ obj.obj["full_name"] }} + :parts: 1 + {% if "private-members" in autoapi_options %} + :private-bases: + {% endif %} + + {% endif %} + {% endif %} + {% if obj.docstring %} + {{ obj.docstring|indent(3) }} + {% endif %} + {% if "inherited-members" in autoapi_options %} + {% set visible_classes = obj.classes|selectattr("display")|list %} + {% else %} + {% set visible_classes = obj.classes|rejectattr("inherited")|selectattr("display")|list %} + {% endif %} + {% for klass in visible_classes %} + {{ klass.render()|indent(3) }} + {% endfor %} + {% if "inherited-members" in autoapi_options %} + {% set visible_properties = obj.properties|selectattr("display")|list %} + {% else %} + {% set visible_properties = obj.properties|rejectattr("inherited")|selectattr("display")|list %} + {% endif %} + {% for property in visible_properties %} + {{ property.render()|indent(3) }} + {% endfor %} + {% if "inherited-members" in autoapi_options %} + {% set visible_attributes = obj.attributes|selectattr("display")|list %} + {% else %} + {% set visible_attributes = obj.attributes|rejectattr("inherited")|selectattr("display")|list %} + {% endif %} + {% for attribute in visible_attributes %} + {{ attribute.render()|indent(3) }} + {% endfor %} + {% if "inherited-members" in autoapi_options %} + {% set visible_methods = obj.methods|selectattr("display")|list %} + {% else %} + {% set visible_methods = obj.methods|rejectattr("inherited")|selectattr("display")|list %} + {% endif %} + {% for method in visible_methods %} + {{ method.render()|indent(3) }} + {% endfor %} +{% endif %} diff --git a/docs/en/_templates/python/data.rst b/docs/en/_templates/python/data.rst new file mode 100644 index 0000000000..89417f1e15 --- /dev/null +++ b/docs/en/_templates/python/data.rst @@ -0,0 +1,32 @@ +{% if obj.display %} +.. py:{{ obj.type }}:: {{ obj.name }} + {%+ if obj.value is not none or obj.annotation is not none -%} + :annotation: + {%- if obj.annotation %} :{{ obj.annotation }} + {%- endif %} + {%- if obj.value is not none %} = {% + if obj.value is string and obj.value.splitlines()|count > 1 -%} + Multiline-String + + .. raw:: html + + +
+Then, you can clone the repositories to local:
+
+```shell
+git clone git@github.com:{username}/mmediting.git
+```
+
+After that, you should ddd official repository as the upstream repository
+
+```bash
+git remote add upstream git@github.com:open-mmlab/mmediting
+```
+
+Check whether remote repository has been added successfully by `git remote -v`
+
+```bash
+origin git@github.com:{username}/mmediting.git (fetch)
+origin git@github.com:{username}/mmediting.git (push)
+upstream git@github.com:open-mmlab/mmediting (fetch)
+upstream git@github.com:open-mmlab/mmediting (push)
+```
+
+```{note}
+Here's a brief introduction to origin and upstream. When we use "git clone", we create an "origin" remote by default, which points to the repository cloned from. As for "upstream", we add it ourselves to point to the target repository. Of course, if you don't like the name "upstream", you could name it as you wish. Usually, we'll push the code to "origin". If the pushed code conflicts with the latest code in official("upstream"), we should pull the latest code from upstream to resolve the conflicts, and then push to "origin" again. The posted Pull Request will be updated automatically.
+```
+
+#### 2. Configure pre-commit
+
+You should configure [pre-commit](https://pre-commit.com/#intro) in the local development environment to make sure the code style matches that of OpenMMLab. **Note**: The following code should be executed under the mmediting directory.
+
+```shell
+pip install -U pre-commit
+pre-commit install
+```
+
+Check that pre-commit is configured successfully, and install the hooks defined in `.pre-commit-config.yaml`.
+
+```shell
+pre-commit run --all-files
+```
+
+
+
+Then, you can clone the repositories to local:
+
+```shell
+git clone git@github.com:{username}/mmediting.git
+```
+
+After that, you should ddd official repository as the upstream repository
+
+```bash
+git remote add upstream git@github.com:open-mmlab/mmediting
+```
+
+Check whether remote repository has been added successfully by `git remote -v`
+
+```bash
+origin git@github.com:{username}/mmediting.git (fetch)
+origin git@github.com:{username}/mmediting.git (push)
+upstream git@github.com:open-mmlab/mmediting (fetch)
+upstream git@github.com:open-mmlab/mmediting (push)
+```
+
+```{note}
+Here's a brief introduction to origin and upstream. When we use "git clone", we create an "origin" remote by default, which points to the repository cloned from. As for "upstream", we add it ourselves to point to the target repository. Of course, if you don't like the name "upstream", you could name it as you wish. Usually, we'll push the code to "origin". If the pushed code conflicts with the latest code in official("upstream"), we should pull the latest code from upstream to resolve the conflicts, and then push to "origin" again. The posted Pull Request will be updated automatically.
+```
+
+#### 2. Configure pre-commit
+
+You should configure [pre-commit](https://pre-commit.com/#intro) in the local development environment to make sure the code style matches that of OpenMMLab. **Note**: The following code should be executed under the mmediting directory.
+
+```shell
+pip install -U pre-commit
+pre-commit install
+```
+
+Check that pre-commit is configured successfully, and install the hooks defined in `.pre-commit-config.yaml`.
+
+```shell
+pre-commit run --all-files
+```
+
+ +
+
+
+ +
+```{note}
+Chinese users may fail to download the pre-commit hooks due to the network issue. In this case, you could download these hooks from gitee by setting the .pre-commit-config-zh-cn.yaml
+
+pre-commit install -c .pre-commit-config-zh-cn.yaml
+pre-commit run --all-files -c .pre-commit-config-zh-cn.yaml
+```
+
+If the installation process is interrupted, you can repeatedly run `pre-commit run ... ` to continue the installation.
+
+If the code does not conform to the code style specification, pre-commit will raise a warning and fixes some of the errors automatically.
+
+
+
+```{note}
+Chinese users may fail to download the pre-commit hooks due to the network issue. In this case, you could download these hooks from gitee by setting the .pre-commit-config-zh-cn.yaml
+
+pre-commit install -c .pre-commit-config-zh-cn.yaml
+pre-commit run --all-files -c .pre-commit-config-zh-cn.yaml
+```
+
+If the installation process is interrupted, you can repeatedly run `pre-commit run ... ` to continue the installation.
+
+If the code does not conform to the code style specification, pre-commit will raise a warning and fixes some of the errors automatically.
+
+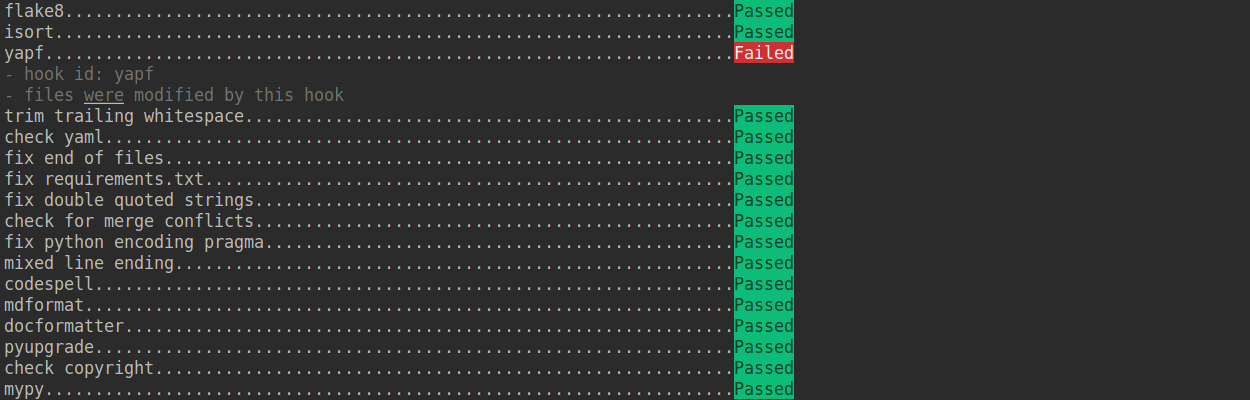 +
+If we want to commit our code bypassing the pre-commit hook, we can use the `--no-verify` option(**only for temporarily commit**.
+
+```shell
+git commit -m "xxx" --no-verify
+```
+
+#### 3. Create a development branch
+
+After configuring the pre-commit, we should create a branch based on the master branch to develop the new feature or fix the bug. The proposed branch name is `username/pr_name`
+
+```shell
+git checkout -b yhc/refactor_contributing_doc
+```
+
+In subsequent development, if the master branch of the local repository is behind the master branch of "upstream", we need to pull the upstream for synchronization, and then execute the above command:
+
+```shell
+git pull upstream master
+```
+
+#### 4. Commit the code and pass the unit test
+
+- MMEditing introduces mypy to do static type checking to increase the robustness of the code. Therefore, we need to add Type Hints to our code and pass the mypy check. If you are not familiar with Type Hints, you can refer to [this tutorial](https://docs.python.org/3/library/typing.html).
+
+- The committed code should pass through the unit test
+
+ ```shell
+ # Pass all unit tests
+ pytest tests
+
+ # Pass the unit test of runner
+ pytest tests/test_runner/test_runner.py
+ ```
+
+ If the unit test fails for lack of dependencies, you can install the dependencies referring to the [guidance](#unit-test)
+
+- If the documents are modified/added, we should check the rendering result referring to [guidance](#document-rendering)
+
+#### 5. Push the code to remote
+
+We could push the local commits to remote after passing through the check of unit test and pre-commit. You can associate the local branch with remote branch by adding `-u` option.
+
+```shell
+git push -u origin {branch_name}
+```
+
+This will allow you to use the `git push` command to push code directly next time, without having to specify a branch or the remote repository.
+
+#### 6. Create a Pull Request
+
+(1) Create a pull request in GitHub's Pull request interface
+
+
+
+If we want to commit our code bypassing the pre-commit hook, we can use the `--no-verify` option(**only for temporarily commit**.
+
+```shell
+git commit -m "xxx" --no-verify
+```
+
+#### 3. Create a development branch
+
+After configuring the pre-commit, we should create a branch based on the master branch to develop the new feature or fix the bug. The proposed branch name is `username/pr_name`
+
+```shell
+git checkout -b yhc/refactor_contributing_doc
+```
+
+In subsequent development, if the master branch of the local repository is behind the master branch of "upstream", we need to pull the upstream for synchronization, and then execute the above command:
+
+```shell
+git pull upstream master
+```
+
+#### 4. Commit the code and pass the unit test
+
+- MMEditing introduces mypy to do static type checking to increase the robustness of the code. Therefore, we need to add Type Hints to our code and pass the mypy check. If you are not familiar with Type Hints, you can refer to [this tutorial](https://docs.python.org/3/library/typing.html).
+
+- The committed code should pass through the unit test
+
+ ```shell
+ # Pass all unit tests
+ pytest tests
+
+ # Pass the unit test of runner
+ pytest tests/test_runner/test_runner.py
+ ```
+
+ If the unit test fails for lack of dependencies, you can install the dependencies referring to the [guidance](#unit-test)
+
+- If the documents are modified/added, we should check the rendering result referring to [guidance](#document-rendering)
+
+#### 5. Push the code to remote
+
+We could push the local commits to remote after passing through the check of unit test and pre-commit. You can associate the local branch with remote branch by adding `-u` option.
+
+```shell
+git push -u origin {branch_name}
+```
+
+This will allow you to use the `git push` command to push code directly next time, without having to specify a branch or the remote repository.
+
+#### 6. Create a Pull Request
+
+(1) Create a pull request in GitHub's Pull request interface
+
+ +
+(2) Modify the PR description according to the guidelines so that other developers can better understand your changes
+
+
+
+(2) Modify the PR description according to the guidelines so that other developers can better understand your changes
+
+ +
+Find more details about Pull Request description in [pull request guidelines](#pr-specs).
+
+**note**
+
+(a) The Pull Request description should contain the reason for the change, the content of the change, and the impact of the change, and be associated with the relevant Issue (see [documentation](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue)
+
+(b) If it is your first contribution, please sign the CLA
+
+
+
+Find more details about Pull Request description in [pull request guidelines](#pr-specs).
+
+**note**
+
+(a) The Pull Request description should contain the reason for the change, the content of the change, and the impact of the change, and be associated with the relevant Issue (see [documentation](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue)
+
+(b) If it is your first contribution, please sign the CLA
+
+ +
+(c) Check whether the Pull Request pass through the CI
+
+
+
+(c) Check whether the Pull Request pass through the CI
+
+ +
+MMEditing will run unit test for the posted Pull Request on different platforms (Linux, Window, Mac), based on different versions of Python, PyTorch, CUDA to make sure the code is correct. We can see the specific test information by clicking `Details` in the above image so that we can modify the code.
+
+(3) If the Pull Request passes the CI, then you can wait for the review from other developers. You'll modify the code based on the reviewer's comments, and repeat the steps [4](#4-commit-the-code-and-pass-the-unit-test)-[5](#5-push-the-code-to-remote) until all reviewers approve it. Then, we will merge it ASAP.
+
+
+
+MMEditing will run unit test for the posted Pull Request on different platforms (Linux, Window, Mac), based on different versions of Python, PyTorch, CUDA to make sure the code is correct. We can see the specific test information by clicking `Details` in the above image so that we can modify the code.
+
+(3) If the Pull Request passes the CI, then you can wait for the review from other developers. You'll modify the code based on the reviewer's comments, and repeat the steps [4](#4-commit-the-code-and-pass-the-unit-test)-[5](#5-push-the-code-to-remote) until all reviewers approve it. Then, we will merge it ASAP.
+
+ +
+#### 7. Resolve conflicts
+
+If your local branch conflicts with the latest master branch of "upstream", you'll need to resolove them. There are two ways to do this:
+
+```shell
+git fetch --all --prune
+git rebase upstream/master
+```
+
+or
+
+```shell
+git fetch --all --prune
+git merge upstream/master
+```
+
+If you are very good at handling conflicts, then you can use rebase to resolve conflicts, as this will keep your commit logs tidy. If you are not familiar with `rebase`, then you can use `merge` to resolve conflicts.
+
+### Guidance
+
+#### Unit test
+
+We should make sure the committed code will not decrease the coverage of unit test, we could run the following command to check the coverage of unit test:
+
+```shell
+python -m coverage run -m pytest /path/to/test_file
+python -m coverage html
+# check file in htmlcov/index.html
+```
+
+#### Document rendering
+
+If the documents are modified/added, we should check the rendering result. We could install the dependencies and run the following command to render the documents and check the results:
+
+```shell
+pip install -r requirements/docs.txt
+cd docs/zh_cn/
+# or docs/en
+make html
+# check file in ./docs/zh_cn/_build/html/index.html
+```
+
+### Code style
+
+#### Python
+
+We adopt [PEP8](https://www.python.org/dev/peps/pep-0008/) as the preferred code style.
+
+We use the following tools for linting and formatting:
+
+- [flake8](https://github.com/PyCQA/flake8): A wrapper around some linter tools.
+- [isort](https://github.com/timothycrosley/isort): A Python utility to sort imports.
+- [yapf](https://github.com/google/yapf): A formatter for Python files.
+- [codespell](https://github.com/codespell-project/codespell): A Python utility to fix common misspellings in text files.
+- [mdformat](https://github.com/executablebooks/mdformat): Mdformat is an opinionated Markdown formatter that can be used to enforce a consistent style in Markdown files.
+- [docformatter](https://github.com/myint/docformatter): A formatter to format docstring.
+
+Style configurations of yapf and isort can be found in [setup.cfg](../../../setup.cfg).
+
+We use [pre-commit hook](https://pre-commit.com/) that checks and formats for `flake8`, `yapf`, `isort`, `trailing whitespaces`, `markdown files`,
+fixes `end-of-files`, `double-quoted-strings`, `python-encoding-pragma`, `mixed-line-ending`, sorts `requirments.txt` automatically on every commit.
+The config for a pre-commit hook is stored in [.pre-commit-config](../../../.pre-commit-config.yaml).
+
+#### C++ and CUDA
+
+We follow the [Google C++ Style Guide](https://google.github.io/styleguide/cppguide.html).
+
+### PR Specs
+
+1. Use [pre-commit](https://pre-commit.com) hook to avoid issues of code style
+
+2. One short-time branch should be matched with only one PR
+
+3. Accomplish a detailed change in one PR. Avoid large PR
+
+ - Bad: Support Faster R-CNN
+ - Acceptable: Add a box head to Faster R-CNN
+ - Good: Add a parameter to box head to support custom conv-layer number
+
+4. Provide clear and significant commit message
+
+5. Provide clear and meaningful PR description
+
+ - Task name should be clarified in title. The general format is: \[Prefix\] Short description of the PR (Suffix)
+ - Prefix: add new feature \[Feature\], fix bug \[Fix\], related to documents \[Docs\], in developing \[WIP\] (which will not be reviewed temporarily)
+ - Introduce main changes, results and influences on other modules in short description
+ - Associate related issues and pull requests with a milestone
diff --git a/docs/en/community/projects.md b/docs/en/community/projects.md
new file mode 100644
index 0000000000..50e25c903f
--- /dev/null
+++ b/docs/en/community/projects.md
@@ -0,0 +1,67 @@
+# MMEditing projects
+
+Welcome to the MMEditing community!
+The MMEditing ecosystem consists of tutorials, libraries, and projects from a broad set of researchers in academia and industry, ML and application engineers.
+The goal of this ecosystem is to support, accelerate, and aid in your exploration with MMEditing for image, video, 3D content generation, editing and processing.
+
+Here are a few projects that are built upon MMEditing. They are examples of how to use MMEditing as a library, to make your projects more maintainable.
+Please find more projects in [MMEditing Ecosystem](https://openmmlab.com/ecosystem).
+
+## Show your projects on OpenMMLab Ecosystem
+
+You can submit your project so that it can be shown on the homepage of [OpenMMLab](https://openmmlab.com/ecosystem).
+
+## Add example projects to MMEditing
+
+Here is an [example project](../../../projects/example_project) about how to add your projects to MMEditing.
+You can copy and create your own project from the [example project](../../../projects/example_project).
+
+We also provide some documentation listed below for your reference:
+
+- [Contribution Guide](https://mmediting.readthedocs.io/en/dev-1.x/community/contributing.html)
+
+ The guides for new contributors about how to add your projects to MMEditing.
+
+- [New Model Guide](https://mmediting.readthedocs.io/en/dev-1.x/howto/models.html)
+
+ The documentation of adding new models.
+
+- [Discussions](https://github.com/open-mmlab/mmediting/discussions)
+
+ Welcome to start a discussion!
+
+## Projects of libraries and toolboxes
+
+- [PowerVQE](https://github.com/ryanxingql/powervqe): Open framework for quality enhancement of compressed videos based on PyTorch and MMEditing.
+
+- [VR-Baseline](https://github.com/linjing7/VR-Baseline): Video Restoration Toolbox.
+
+- [Derain-Toolbox](https://github.com/biubiubiiu/derain-toolbox): Single Image Deraining Toolbox and Benchmark
+
+## Projects of research papers
+
+- [Towards Interpretable Video Super-Resolution via Alternating Optimization, ECCV 2022](https://arxiv.org/abs/2207.10765)[\[github\]](https://github.com/caojiezhang/DAVSR)
+
+- [SepLUT:Separable Image-adaptive Lookup Tables for Real-time Image Enhancement, ECCV 2022](https://arxiv.org/abs/2207.08351)[\[github\]](https://github.com/ImCharlesY/SepLUT)
+
+- [TTVSR: Learning Trajectory-Aware Transformer for Video Super-Resolution, CVPR 2022](https://arxiv.org/abs/2204.04216)[\[github\]](https://github.com/researchmm/TTVSR)
+
+- [Arbitrary-Scale Image Synthesis, CVPR 2022](https://arxiv.org/pdf/2204.02273.pdf)[\[github\]](https://github.com/vglsd/ScaleParty)
+
+- [Investigating Tradeoffs in Real-World Video Super-Resolution(RealBasicVSR), CVPR 2022](https://arxiv.org/abs/2111.12704)[\[github\]](https://github.com/ckkelvinchan/RealBasicVSR)
+
+- [BasicVSR++: Improving Video Super-Resolution with Enhanced Propagation and Alignment, CVPR 2022](https://arxiv.org/abs/2104.13371)[\[github\]](https://github.com/ckkelvinchan/BasicVSR_PlusPlus)
+
+- [Multi-Scale Memory-Based Video Deblurring, CVPR 2022](https://arxiv.org/abs/2204.02977)[\[github\]](https://github.com/jibo27/MemDeblur)
+
+- [AdaInt:Learning Adaptive Intervals for 3D Lookup Tables on Real-time Image Enhancement, CVPR 2022](https://arxiv.org/abs/2204.13983)[\[github\]](https://github.com/ImCharlesY/AdaInt)
+
+- [A New Dataset and Transformer for Stereoscopic Video Super-Resolution, CVPRW 2022](https://openaccess.thecvf.com/content/CVPR2022W/NTIRE/papers/Imani_A_New_Dataset_and_Transformer_for_Stereoscopic_Video_Super-Resolution_CVPRW_2022_paper.pdf)[\[github\]](https://github.com/H-deep/Trans-SVSR)
+
+- [Liquid warping GAN with attention: A unified framework for human image synthesis, TPAMI 2021](https://arxiv.org/pdf/2011.09055.pdf)[\[github\]](https://github.com/iPERDance/iPERCore)
+
+- [BasicVSR:The Search for Essential Components in Video Super-Resolution and Beyond, CVPR 2021](https://arxiv.org/abs/2012.02181)[\[github\]](https://github.com/ckkelvinchan/BasicVSR-IconVSR)
+
+- [GLEAN:Generative Latent Bank for Large-Factor Image Super-Resolution, CVPR 2021](https://arxiv.org/abs/2012.00739)[\[github\]](https://github.com/ckkelvinchan/GLEAN)
+
+- [DAN:Unfolding the Alternating Optimization for Blind Super Resolution, NeurIPS 2020](https://arxiv.org/abs/2010.02631v4)[\[github\]](https://github.com/AlexZou14/DAN-Basd-on-Openmmlab)
diff --git a/docs/en/conf.py b/docs/en/conf.py
index 81909842d5..d6aed67aad 100644
--- a/docs/en/conf.py
+++ b/docs/en/conf.py
@@ -31,21 +31,44 @@
# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
# ones.
extensions = [
- 'sphinx.ext.autodoc',
- 'sphinx.ext.autosummary',
'sphinx.ext.intersphinx',
'sphinx.ext.napoleon',
'sphinx.ext.viewcode',
'sphinx.ext.autosectionlabel',
'sphinx_markdown_tables',
- 'myst_parser',
'sphinx_copybutton',
- 'sphinx.ext.autodoc.typehints',
+ 'sphinx_tabs.tabs',
+ 'myst_parser',
]
+extensions.append('notfound.extension') # enable customizing not-found page
+
+extensions.append('autoapi.extension')
+autoapi_type = 'python'
+autoapi_dirs = ['../../mmedit']
+autoapi_add_toctree_entry = False
+autoapi_template_dir = '_templates'
+# autoapi_options = ['members', 'undoc-members', 'show-module-summary']
+
+# # Core library for html generation from docstrings
+# extensions.append('sphinx.ext.autodoc')
+# extensions.append('sphinx.ext.autodoc.typehints')
+# # Enable 'expensive' imports for sphinx_autodoc_typehints
+# set_type_checking_flag = True
+# # Sphinx-native method. Not as good as sphinx_autodoc_typehints
+# autodoc_typehints = "description"
+
+# extensions.append('sphinx.ext.autosummary') # Create neat summary tables
+# autosummary_generate = True # Turn on sphinx.ext.autosummary
+# # Add __init__ doc (ie. params) to class summaries
+# autoclass_content = 'both'
+# autodoc_skip_member = []
+# # If no docstring, inherit from base class
+# autodoc_inherit_docstrings = True
+
autodoc_mock_imports = [
- 'mmedit.version', 'mmcv.ops.ModulatedDeformConv2d',
- 'mmcv.ops.modulated_deform_conv2d', 'mmcv._ext'
+ 'mmedit.version', 'mmcv._ext', 'mmcv.ops.ModulatedDeformConv2d',
+ 'mmcv.ops.modulated_deform_conv2d', 'clip', 'resize_right', 'pandas'
]
source_suffix = {
@@ -53,6 +76,11 @@
'.md': 'markdown',
}
+# # Remove 'view source code' from top of page (for html, not python)
+# html_show_sourcelink = False
+# nbsphinx_allow_errors = True # Continue through Jupyter errors
+# add_module_names = False # Remove namespaces from class/method signatures
+
# Ignore >>> when copying code
copybutton_prompt_text = r'>>> |\.\.\. '
copybutton_prompt_is_regexp = True
@@ -94,11 +122,6 @@
'url': 'https://mmediting.readthedocs.io/en/1.x/',
'description': '1.x branch',
},
- {
- 'name': 'MMEditing 1.x',
- 'url': 'https://mmediting.readthedocs.io/en/dev-1.x/',
- 'description': 'docs at 1.x branch'
- },
],
'active':
True,
@@ -106,16 +129,6 @@
],
'menu_lang':
'en',
- 'header_note': {
- 'content':
- 'You are reading the documentation for MMEditing 0.x, which '
- 'will soon be deprecated by the end of 2022. We recommend you upgrade '
- 'to MMEditing 1.0 to enjoy fruitful new features and better performance ' # noqa
- ' brought by OpenMMLab 2.0. Check out the '
- 'changelog, ' # noqa
- 'code ' # noqa
- 'and documentation of MMEditing 1.0 for more details.', # noqa
- }
}
# Add any paths that contain custom static files (such as style sheets) here,
@@ -130,13 +143,21 @@
language = 'en'
# The master toctree document.
-master_doc = 'index'
+root_doc = 'index'
+notfound_template = '404.html'
def builder_inited_handler(app):
- subprocess.run(['bash', './.dev_scripts/update_dataset_zoo.sh'])
subprocess.run(['python', './.dev_scripts/update_model_zoo.py'])
+ subprocess.run(['python', './.dev_scripts/update_dataset_zoo.py'])
+
+
+def skip_member(app, what, name, obj, skip, options):
+ if what == 'package' or what == 'module':
+ skip = True
+ return skip
def setup(app):
app.connect('builder-inited', builder_inited_handler)
+ app.connect('autoapi-skip-member', skip_member)
diff --git a/docs/en/dataset_zoo/0_overview.md b/docs/en/dataset_zoo/0_overview.md
deleted file mode 100644
index d0a2da7f40..0000000000
--- a/docs/en/dataset_zoo/0_overview.md
+++ /dev/null
@@ -1,18 +0,0 @@
-# Overview
-
-- [Prepare Super-Resolution Datasets](./1_super_resolution_datasets.md)
- - [DF2K_OST](./1_super_resolution_datasets.md#df2k_ost-dataset) \[ [Homepage](https://github.com/xinntao/Real-ESRGAN/blob/master/docs/Training.md) \]
- - [DIV2K](./1_super_resolution_datasets.md#div2k-dataset) \[ [Homepage](https://data.vision.ee.ethz.ch/cvl/DIV2K/) \]
- - [REDS](./1_super_resolution_datasets.md#reds-dataset) \[ [Homepage](https://seungjunnah.github.io/Datasets/reds.html) \]
- - [Vid4](./1_super_resolution_datasets.md#vid4-dataset) \[ [Homepage](https://drive.google.com/file/d/1ZuvNNLgR85TV_whJoHM7uVb-XW1y70DW/view) \]
- - [Vimeo90K](./1_super_resolution_datasets.md#vimeo90k-dataset) \[ [Homepage](http://toflow.csail.mit.edu) \]
-- [Prepare Inpainting Datasets](./2_inpainting_datasets.md)
- - [CelebA-HQ](./2_inpainting_datasets.md#celeba-hq-dataset) \[ [Homepage](https://github.com/tkarras/progressive_growing_of_gans#preparing-datasets-for-training) \]
- - [Paris Street View](./2_inpainting_datasets.md#paris-street-view-dataset) \[ [Homepage](https://github.com/pathak22/context-encoder/issues/24) \]
- - [Places365](./2_inpainting_datasets.md#places365-dataset) \[ [Homepage](http://places2.csail.mit.edu/) \]
-- [Prepare Matting Datasets](./3_matting_datasets.md)
- - [Composition-1k](./3_matting_datasets.md#composition-1k-dataset) \[ [Homepage](https://sites.google.com/view/deepimagematting) \]
-- [Prepare Video Frame Interpolation Datasets](./4_video_interpolation_datasets.md)
- - [Vimeo90K-triplet](./4_video_interpolation_datasets.md#vimeo90k-triplet-dataset) \[ [Homepage](http://toflow.csail.mit.edu) \]
-- [Prepare Unconditional GANs Datasets](./5_unconditional_gans_datasets.md)
-- [Prepare Image Translation Datasets](./6_image_translation_datasets.md)
diff --git a/docs/en/dataset_zoo/1_super_resolution_datasets.md b/docs/en/dataset_zoo/1_super_resolution_datasets.md
deleted file mode 100644
index e6afa8ff6d..0000000000
--- a/docs/en/dataset_zoo/1_super_resolution_datasets.md
+++ /dev/null
@@ -1,356 +0,0 @@
-# Super-Resolution Datasets
-
-It is recommended to symlink the dataset root to `$MMEDITING/data`. If your folder structure is different, you may need to change the corresponding paths in config files.
-
-MMEditing supported super-resolution datasets:
-
-- Image Super-Resolution
- - [DF2K_OST](#df2k_ost-dataset) \[ [Homepage](https://github.com/xinntao/Real-ESRGAN/blob/master/docs/Training.md) \]
- - [DIV2K](#div2k-dataset) \[ [Homepage](https://data.vision.ee.ethz.ch/cvl/DIV2K/) \]
-- Video Super-Resolution
- - [REDS](#reds-dataset) \[ [Homepage](https://seungjunnah.github.io/Datasets/reds.html) \]
- - [Vid4](#vid4-dataset) \[ [Homepage](https://drive.google.com/file/d/1ZuvNNLgR85TV_whJoHM7uVb-XW1y70DW/view) \]
- - [Vimeo90K](#vimeo90k-dataset) \[ [Homepage](http://toflow.csail.mit.edu) \]
-
-## DF2K_OST Dataset
-
-
-
-```bibtex
-@inproceedings{wang2021real,
- title={Real-ESRGAN: Training Real-World Blind Super-Resolution with Pure Synthetic Data},
- author={Wang, Xintao and Xie, Liangbin and Dong, Chao and Shan, Ying},
- booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
- pages={1905--1914},
- year={2021}
-}
-```
-
-- The DIV2K dataset can be downloaded from [here](https://data.vision.ee.ethz.ch/cvl/DIV2K/) (We use the training set only).
-- The Flickr2K dataset can be downloaded [here](https://cv.snu.ac.kr/research/EDSR/Flickr2K.tar) (We use the training set only).
-- The OST dataset can be downloaded [here](https://openmmlab.oss-cn-hangzhou.aliyuncs.com/datasets/OST_dataset.zip) (We use the training set only).
-
-Please first put all the images into the `GT` folder (naming does not need to be in order):
-
-```text
-mmediting
-├── mmedit
-├── tools
-├── configs
-├── data
-│ ├── df2k_ost
-│ │ ├── GT
-│ │ │ ├── 0001.png
-│ │ │ ├── 0002.png
-│ │ │ ├── ...
-...
-```
-
-### Crop sub-images
-
-For faster IO, we recommend to crop the images to sub-images. We provide such a script:
-
-```shell
-python tools/dataset_converters/super-resolution/df2k_ost/preprocess_df2k_ost_dataset.py --data-root ./data/df2k_ost
-```
-
-The generated data is stored under `df2k_ost` and the data structure is as follows, where `_sub` indicates the sub-images.
-
-```text
-mmediting
-├── mmedit
-├── tools
-├── configs
-├── data
-│ ├── df2k_ost
-│ │ ├── GT
-│ │ ├── GT_sub
-...
-```
-
-### Prepare LMDB dataset for DF2K_OST
-
-If you want to use LMDB datasets for faster IO speed, you can make LMDB files by:
-
-```shell
-python tools/dataset_converters/super-resolution/df2k_ost/preprocess_df2k_ost_dataset.py --data-root ./data/df2k_ost --make-lmdb
-```
-
-## DIV2K Dataset
-
-
-
-```bibtex
-@InProceedings{Agustsson_2017_CVPR_Workshops,
- author = {Agustsson, Eirikur and Timofte, Radu},
- title = {NTIRE 2017 Challenge on Single Image Super-Resolution: Dataset and Study},
- booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops},
- month = {July},
- year = {2017}
-}
-```
-
-- Training dataset: [DIV2K dataset](https://data.vision.ee.ethz.ch/cvl/DIV2K/).
-- Validation dataset: Set5 and Set14.
-
-```text
-mmediting
-├── mmedit
-├── tools
-├── configs
-├── data
-│ ├── DIV2K
-│ │ ├── DIV2K_train_HR
-│ │ ├── DIV2K_train_LR_bicubic
-│ │ │ ├── X2
-│ │ │ ├── X3
-│ │ │ ├── X4
-│ │ ├── DIV2K_valid_HR
-│ │ ├── DIV2K_valid_LR_bicubic
-│ │ │ ├── X2
-│ │ │ ├── X3
-│ │ │ ├── X4
-│ ├── Set5
-│ │ ├── GTmod12
-│ │ ├── LRbicx2
-│ │ ├── LRbicx3
-│ │ ├── LRbicx4
-│ ├── Set14
-│ │ ├── GTmod12
-│ │ ├── LRbicx2
-│ │ ├── LRbicx3
-│ │ ├── LRbicx4
-```
-
-### Crop sub-images
-
-For faster IO, we recommend to crop the DIV2K images to sub-images. We provide such a script:
-
-```shell
-python tools/dataset_converters/super-resolution/div2k/preprocess_div2k_dataset.py --data-root ./data/DIV2K
-```
-
-The generated data is stored under `DIV2K` and the data structure is as follows, where `_sub` indicates the sub-images.
-
-```text
-mmediting
-├── mmedit
-├── tools
-├── configs
-├── data
-│ ├── DIV2K
-│ │ ├── DIV2K_train_HR
-│ │ ├── DIV2K_train_HR_sub
-│ │ ├── DIV2K_train_LR_bicubic
-│ │ │ ├── X2
-│ │ │ ├── X3
-│ │ │ ├── X4
-│ │ │ ├── X2_sub
-│ │ │ ├── X3_sub
-│ │ │ ├── X4_sub
-│ │ ├── DIV2K_valid_HR
-│ │ ├── ...
-...
-```
-
-### Prepare annotation list
-
-If you use the annotation mode for the dataset, you first need to prepare a specific `txt` file.
-
-Each line in the annotation file contains the image names and image shape (usually for the ground-truth images), separated by a white space.
-
-Example of an annotation file:
-
-```text
-0001_s001.png (480,480,3)
-0001_s002.png (480,480,3)
-```
-
-### Prepare LMDB dataset for DIV2K
-
-If you want to use LMDB datasets for faster IO speed, you can make LMDB files by:
-
-```shell
-python tools/dataset_converters/super-resolution/div2k/preprocess_div2k_dataset.py --data-root ./data/DIV2K --make-lmdb
-```
-
-## REDS Dataset
-
-
-
-```bibtex
-@InProceedings{Nah_2019_CVPR_Workshops_REDS,
- author = {Nah, Seungjun and Baik, Sungyong and Hong, Seokil and Moon, Gyeongsik and Son, Sanghyun and Timofte, Radu and Lee, Kyoung Mu},
- title = {NTIRE 2019 Challenge on Video Deblurring and Super-Resolution: Dataset and Study},
- booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops},
- month = {June},
- year = {2019}
-}
-```
-
-- Training dataset: [REDS dataset](https://seungjunnah.github.io/Datasets/reds.html).
-- Validation dataset: [REDS dataset](https://seungjunnah.github.io/Datasets/reds.html) and Vid4.
-
-Note that we merge train and val datasets in REDS for easy switching between REDS4 partition (used in EDVR) and the official validation partition.
-The original val dataset (clip names from 000 to 029) are modified to avoid conflicts with training dataset (total 240 clips). Specifically, the clip names are changed to 240, 241, ... 269.
-
-You can prepare the REDS dataset by running:
-
-```shell
-python tools/dataset_converters/super-resolution/reds/preprocess_reds_dataset.py --root-path ./data/REDS
-```
-
-```text
-mmediting
-├── mmedit
-├── tools
-├── configs
-├── data
-│ ├── REDS
-│ │ ├── train_sharp
-│ │ │ ├── 000
-│ │ │ ├── 001
-│ │ │ ├── ...
-│ │ ├── train_sharp_bicubic
-│ │ │ ├── 000
-│ │ │ ├── 001
-│ │ │ ├── ...
-│ ├── REDS4
-│ │ ├── GT
-│ │ ├── sharp_bicubic
-```
-
-### Prepare LMDB dataset for REDS
-
-If you want to use LMDB datasets for faster IO speed, you can make LMDB files by:
-
-```shell
-python tools/dataset_converters/super-resolution/reds/preprocess_reds_dataset.py --root-path ./data/REDS --make-lmdb
-```
-
-### Crop to sub-images
-
-MMEditing also support cropping REDS images to sub-images for faster IO. We provide such a script:
-
-```shell
-python tools/dataset_converters/super-resolution/reds/crop_sub_images.py --data-root ./data/REDS -scales 4
-```
-
-The generated data is stored under `REDS` and the data structure is as follows, where `_sub` indicates the sub-images.
-
-```text
-mmediting
-├── mmedit
-├── tools
-├── configs
-├── data
-│ ├── REDS
-│ │ ├── train_sharp
-│ │ │ ├── 000
-│ │ │ ├── 001
-│ │ │ ├── ...
-│ │ ├── train_sharp_sub
-│ │ │ ├── 000_s001
-│ │ │ ├── 000_s002
-│ │ │ ├── ...
-│ │ │ ├── 001_s001
-│ │ │ ├── ...
-│ │ ├── train_sharp_bicubic
-│ │ │ ├── X4
-│ │ │ │ ├── 000
-│ │ │ │ ├── 001
-│ │ │ │ ├── ...
-│ │ │ ├── X4_sub
-│ │ │ ├── 000_s001
-│ │ │ ├── 000_s002
-│ │ │ ├── ...
-│ │ │ ├── 001_s001
-│ │ │ ├── ...
-```
-
-Note that by default `preprocess_reds_dataset.py` does not make lmdb and annotation file for the cropped dataset. You may need to modify the scripts a little bit for such operations.
-
-## Vid4 Dataset
-
-
-
-```bibtex
-@article{xue2019video,
- title={On Bayesian adaptive video super resolution},
- author={Liu, Ce and Sun, Deqing},
- journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
- volume={36},
- number={2},
- pages={346--360},
- year={2013},
- publisher={IEEE}
-}
-```
-
-The Vid4 dataset can be downloaded from [here](https://drive.google.com/file/d/1ZuvNNLgR85TV_whJoHM7uVb-XW1y70DW/view?usp=sharing). There are two degradations in the dataset.
-
-1. BIx4 contains images downsampled by bicubic interpolation
-2. BDx4 contains images blurred by Gaussian kernel with σ=1.6, followed by a subsampling every four pixels.
-
-## Vimeo90K Dataset
-
-
-
-```bibtex
-@article{xue2019video,
- title={Video Enhancement with Task-Oriented Flow},
- author={Xue, Tianfan and Chen, Baian and Wu, Jiajun and Wei, Donglai and Freeman, William T},
- journal={International Journal of Computer Vision (IJCV)},
- volume={127},
- number={8},
- pages={1106--1125},
- year={2019},
- publisher={Springer}
-}
-```
-
-The training and test datasets can be download from [here](http://toflow.csail.mit.edu/).
-
-The Vimeo90K dataset has a `clip/sequence/img` folder structure:
-
-```text
-mmediting
-├── mmedit
-├── tools
-├── configs
-├── data
-│ ├── vimeo_triplet
-│ │ ├── BDx4
-│ │ │ ├── 00001
-│ │ │ │ ├── 0001
-│ │ │ │ │ ├── im1.png
-│ │ │ │ │ ├── im2.png
-│ │ │ │ │ ├── ...
-│ │ │ │ ├── 0002
-│ │ │ │ ├── 0003
-│ │ │ │ ├── ...
-│ │ │ ├── 00002
-│ │ │ ├── ...
-│ │ ├── BIx4
-│ │ ├── GT
-│ │ ├── meta_info_Vimeo90K_test_GT.txt
-│ │ ├── meta_info_Vimeo90K_train_GT.txt
-```
-
-### Prepare the annotation files for Vimeo90K dataset
-
-To prepare the annotation file for training, you need to download the official training list path for Vimeo90K from the official website, and run the following command:
-
-```shell
-python tools/dataset_converters/super-resolution/vimeo90k/preprocess_vimeo90k_dataset.py ./data/Vimeo90K/official_train_list.txt
-```
-
-The annotation file for test is generated similarly.
-
-### Prepare LMDB dataset for Vimeo90K
-
-If you want to use LMDB datasets for faster IO speed, you can make LMDB files by:
-
-```shell
-python tools/dataset_converters/super-resolution/vimeo90k/preprocess_vimeo90k_dataset.py ./data/Vimeo90K/official_train_list.txt --gt-path ./data/Vimeo90K/GT --lq-path ./data/Vimeo90K/LQ --make-lmdb
-```
diff --git a/docs/en/dataset_zoo/2_inpainting_datasets.md b/docs/en/dataset_zoo/2_inpainting_datasets.md
deleted file mode 100644
index f5dac5abac..0000000000
--- a/docs/en/dataset_zoo/2_inpainting_datasets.md
+++ /dev/null
@@ -1,114 +0,0 @@
-# Inpainting Datasets
-
-It is recommended to symlink the dataset root to `$MMEDITING/data`. If your folder structure is different, you may need to change the corresponding paths in config files.
-
-MMEditing supported inpainting datasets:
-
-- [CelebA-HQ](#celeba-hq-dataset) \[ [Homepage](https://github.com/tkarras/progressive_growing_of_gans#preparing-datasets-for-training) \]
-- [Paris Street View](#paris-street-view-dataset) \[ [Homepage](https://github.com/pathak22/context-encoder/issues/24) \]
-- [Places365](#places365-dataset) \[ [Homepage](http://places2.csail.mit.edu/) \]
-
-As we only need images for inpainting task, further preparation is not necessary and the folder structure can be different from the example. You can utilize the information provided by the original dataset like `Place365` (e.g. `meta`). Also, you can easily scan the data set and list all of the images to a specific `txt` file. Here is an example for the `Places365_val.txt` from Places365 and we will only use the image name information in inpainting.
-
-```
-Places365_val_00000001.jpg 165
-Places365_val_00000002.jpg 358
-Places365_val_00000003.jpg 93
-Places365_val_00000004.jpg 164
-Places365_val_00000005.jpg 289
-Places365_val_00000006.jpg 106
-Places365_val_00000007.jpg 81
-Places365_val_00000008.jpg 121
-Places365_val_00000009.jpg 150
-Places365_val_00000010.jpg 302
-Places365_val_00000011.jpg 42
-```
-
-## CelebA-HQ Dataset
-
-
-
-```bibtex
-@article{karras2017progressive,
- title={Progressive growing of gans for improved quality, stability, and variation},
- author={Karras, Tero and Aila, Timo and Laine, Samuli and Lehtinen, Jaakko},
- journal={arXiv preprint arXiv:1710.10196},
- year={2017}
-}
-```
-
-Follow the instructions [here](https://github.com/tkarras/progressive_growing_of_gans##preparing-datasets-for-training) to prepare the dataset.
-
-```text
-mmediting
-├── mmedit
-├── tools
-├── configs
-├── data
-│ ├── CelebA-HQ
-│ │ ├── train_256
-| | ├── test_256
-| | ├── train_celeba_img_list.txt
-| | ├── val_celeba_img_list.txt
-
-```
-
-## Paris Street View Dataset
-
-
-
-```bibtex
-@inproceedings{pathak2016context,
- title={Context encoders: Feature learning by inpainting},
- author={Pathak, Deepak and Krahenbuhl, Philipp and Donahue, Jeff and Darrell, Trevor and Efros, Alexei A},
- booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition},
- pages={2536--2544},
- year={2016}
-}
-```
-
-Obtain the dataset [here](https://github.com/pathak22/context-encoder/issues/24).
-
-```text
-mmediting
-├── mmedit
-├── tools
-├── configs
-├── data
-│ ├── paris_street_view
-│ │ ├── train
-| | ├── val
-
-```
-
-## Places365 Dataset
-
-
-
-```bibtex
- @article{zhou2017places,
- title={Places: A 10 million Image Database for Scene Recognition},
- author={Zhou, Bolei and Lapedriza, Agata and Khosla, Aditya and Oliva, Aude and Torralba, Antonio},
- journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
- year={2017},
- publisher={IEEE}
- }
-
-```
-
-Prepare the data from [Places365](http://places2.csail.mit.edu/download.html).
-
-```text
-mmediting
-├── mmedit
-├── tools
-├── configs
-├── data
-│ ├── Places
-│ │ ├── data_large
-│ │ ├── val_large
-| | ├── meta
-| | | ├── places365_train_challenge.txt
-| | | ├── places365_val.txt
-
-```
diff --git a/docs/en/dataset_zoo/3_matting_datasets.md b/docs/en/dataset_zoo/3_matting_datasets.md
deleted file mode 100644
index cc9c95f924..0000000000
--- a/docs/en/dataset_zoo/3_matting_datasets.md
+++ /dev/null
@@ -1,147 +0,0 @@
-# Matting Datasets
-
-It is recommended to symlink the dataset root to `$MMEDITING/data`. If your folder structure is different, you may need to change the corresponding paths in config files.
-
-MMEditing supported matting datasets:
-
-- [Composition-1k](#composition-1k-dataset) \[ [Homepage](https://sites.google.com/view/deepimagematting) \]
-
-## Composition-1k Dataset
-
-### Introduction
-
-
-
-```bibtex
-@inproceedings{xu2017deep,
- title={Deep image matting},
- author={Xu, Ning and Price, Brian and Cohen, Scott and Huang, Thomas},
- booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition},
- pages={2970--2979},
- year={2017}
-}
-```
-
-The Adobe Composition-1k dataset consists of foreground images and their corresponding alpha images.
-To get the full dataset, one need to composite the foregrounds with selected backgrounds from the COCO dataset and the Pascal VOC dataset.
-
-### Obtain and Extract
-
-Please follow the instructions of [paper authors](https://sites.google.com/view/deepimagematting) to obtain the Composition-1k (comp1k) dataset.
-
-### Composite the full dataset
-
-The Adobe composition-1k dataset contains only `alpha` and `fg` (and `trimap` in test set).
-It is needed to merge `fg` with COCO data (training) or VOC data (test) before training or evaluation.
-Use the following script to perform image composition and generate annotation files for training or testing:
-
-```shell
-## The script is run under the root folder of MMEditing
-python tools/dataset_converters/matting/comp1k/preprocess_comp1k_dataset.py data/adobe_composition-1k data/coco data/VOCdevkit --composite
-```
-
-The generated data is stored under `adobe_composition-1k/Training_set` and `adobe_composition-1k/Test_set` respectively.
-If you only want to composite test data (since compositing training data is time-consuming), you can skip compositing the training set by removing the `--composite` option:
-
-```shell
-## skip compositing training set
-python tools/dataset_converters/matting/comp1k/preprocess_comp1k_dataset.py data/adobe_composition-1k data/coco data/VOCdevkit
-```
-
-If you only want to preprocess test data, i.e. for FBA, you can skip the train set by adding the `--skip-train` option:
-
-```shell
-## skip preprocessing training set
-python tools/data/matting/comp1k/preprocess_comp1k_dataset.py data/adobe_composition-1k data/coco data/VOCdevkit --skip-train
-```
-
-> Currently, `GCA` and `FBA` support online composition of training data. But you can modify the data pipeline of other models to perform online composition instead of loading composited images (we called it `merged` in our data pipeline).
-
-### Check Directory Structure for DIM
-
-The result folder structure should look like:
-
-```text
-mmediting
-├── mmedit
-├── tools
-├── configs
-├── data
-│ ├── adobe_composition-1k
-│ │ ├── Test_set
-│ │ │ ├── Adobe-licensed images
-│ │ │ │ ├── alpha
-│ │ │ │ ├── fg
-│ │ │ │ ├── trimaps
-│ │ │ ├── merged (generated by tools/dataset_converters/matting/comp1k/preprocess_comp1k_dataset.py)
-│ │ │ ├── bg (generated by tools/dataset_converters/matting/comp1k/preprocess_comp1k_dataset.py)
-│ │ ├── Training_set
-│ │ │ ├── Adobe-licensed images
-│ │ │ │ ├── alpha
-│ │ │ │ ├── fg
-│ │ │ ├── Other
-│ │ │ │ ├── alpha
-│ │ │ │ ├── fg
-│ │ │ ├── merged (generated by tools/dataset_converters/matting/comp1k/preprocess_comp1k_dataset.py)
-│ │ │ ├── bg (generated by tools/dataset_converters/matting/comp1k/preprocess_comp1k_dataset.py)
-│ │ ├── test_list.json (generated by tools/dataset_converters/matting/comp1k/preprocess_comp1k_dataset.py)
-│ │ ├── training_list.json (generated by tools/dataset_converters/matting/comp1k/preprocess_comp1k_dataset.py)
-│ ├── coco
-│ │ ├── train2014 (or train2017)
-│ ├── VOCdevkit
-│ │ ├── VOC2012
-```
-
-### Prepare the dataset for FBA
-
-FBA adopts dynamic dataset augmentation proposed in [Learning-base Sampling for Natural Image Matting](https://openaccess.thecvf.com/content_CVPR_2019/papers/Tang_Learning-Based_Sampling_for_Natural_Image_Matting_CVPR_2019_paper.pdf).
-In addition, to reduce artifacts during augmentation, it uses the extended version of foreground as foreground.
-We provide scripts to estimate foregrounds.
-
-Prepare the test set as follows:
-
-```shell
-## skip preprocessing training set, as it composites online during training
-python tools/dataset_converters/matting/comp1k/preprocess_comp1k_dataset.py data/adobe_composition-1k data/coco data/VOCdevkit --skip-train
-```
-
-Extend the foreground of training set as follows:
-
-```shell
-python tools/dataset_converters/matting/comp1k/extend_fg.py data/adobe_composition-1k
-```
-
-### Check Directory Structure for DIM
-
-The final folder structure should look like:
-
-```text
-mmediting
-├── mmedit
-├── tools
-├── configs
-├── data
-│ ├── adobe_composition-1k
-│ │ ├── Test_set
-│ │ │ ├── Adobe-licensed images
-│ │ │ │ ├── alpha
-│ │ │ │ ├── fg
-│ │ │ │ ├── trimaps
-│ │ │ ├── merged (generated by tools/data/matting/comp1k/preprocess_comp1k_dataset.py)
-│ │ │ ├── bg (generated by tools/data/matting/comp1k/preprocess_comp1k_dataset.py)
-│ │ ├── Training_set
-│ │ │ ├── Adobe-licensed images
-│ │ │ │ ├── alpha
-│ │ │ │ ├── fg
-│ │ │ │ ├── fg_extended (generated by tools/data/matting/comp1k/extend_fg.py)
-│ │ │ ├── Other
-│ │ │ │ ├── alpha
-│ │ │ │ ├── fg
-│ │ │ │ ├── fg_extended (generated by tools/data/matting/comp1k/extend_fg.py)
-│ │ ├── test_list.json (generated by tools/data/matting/comp1k/preprocess_comp1k_dataset.py)
-│ │ ├── training_list_fba.json (generated by tools/data/matting/comp1k/extend_fg.py)
-│ ├── coco
-│ │ ├── train2014 (or train2017)
-│ ├── VOCdevkit
-│ │ ├── VOC2012
-```
diff --git a/docs/en/dataset_zoo/4_video_interpolation_datasets.md b/docs/en/dataset_zoo/4_video_interpolation_datasets.md
deleted file mode 100644
index 9889939c91..0000000000
--- a/docs/en/dataset_zoo/4_video_interpolation_datasets.md
+++ /dev/null
@@ -1,50 +0,0 @@
-# Video Frame Interpolation Datasets
-
-It is recommended to symlink the dataset root to `$MMEDITING/data`. If your folder structure is different, you may need to change the corresponding paths in config files.
-
-MMEditing supported video frame interpolation datasets:
-
-- [Vimeo90K-triplet](#vimeo90k-triplet-dataset) \[ [Homepage](http://toflow.csail.mit.edu) \]
-
-## Vimeo90K-triplet Dataset
-
-
-
-```bibtex
-@article{xue2019video,
- title={Video Enhancement with Task-Oriented Flow},
- author={Xue, Tianfan and Chen, Baian and Wu, Jiajun and Wei, Donglai and Freeman, William T},
- journal={International Journal of Computer Vision (IJCV)},
- volume={127},
- number={8},
- pages={1106--1125},
- year={2019},
- publisher={Springer}
-}
-```
-
-The training and test datasets can be download from [here](http://toflow.csail.mit.edu/).
-
-The Vimeo90K-triplet dataset has a `clip/sequence/img` folder structure:
-
-```text
-mmediting
-├── mmedit
-├── tools
-├── configs
-├── data
-│ ├── vimeo_triplet
-│ │ ├── tri_testlist.txt
-│ │ ├── tri_trainlist.txt
-│ │ ├── sequences
-│ │ │ ├── 00001
-│ │ │ │ ├── 0001
-│ │ │ │ │ ├── im1.png
-│ │ │ │ │ ├── im2.png
-│ │ │ │ │ └── im3.png
-│ │ │ │ ├── 0002
-│ │ │ │ ├── 0003
-│ │ │ │ ├── ...
-│ │ │ ├── 00002
-│ │ │ ├── ...
-```
diff --git a/docs/en/dataset_zoo/5_unconditional_gans_datasets.md b/docs/en/dataset_zoo/5_unconditional_gans_datasets.md
deleted file mode 100644
index a0f4d67164..0000000000
--- a/docs/en/dataset_zoo/5_unconditional_gans_datasets.md
+++ /dev/null
@@ -1,91 +0,0 @@
-# Unconditional GANs Datasets
-
-**Data preparation for unconditional model** is simple. What you need to do is downloading the images and put them into a directory. Next, you should set a symlink in the `data` directory. For standard unconditional gans with static architectures, like DCGAN and StyleGAN2, `UnconditionalImageDataset` is designed to train such unconditional models. Here is an example config for FFHQ dataset:
-
-```python
-dataset_type = 'BasicImageDataset'
-
-train_pipeline = [
- dict(type='LoadImageFromFile', key='img'),
- dict(type='Flip', keys=['img'], direction='horizontal'),
- dict(type='PackGenInputs', keys=['img'], meta_keys=['img_path'])
-]
-
-# `batch_size` and `data_root` need to be set.
-train_dataloader = dict(
- batch_size=4,
- num_workers=8,
- persistent_workers=True,
- sampler=dict(type='InfiniteSampler', shuffle=True),
- dataset=dict(
- type=dataset_type,
- data_root=None, # set by user
- pipeline=train_pipeline))
-```
-
-Here, we adopt `InfinitySampler` to avoid frequent dataloader reloading, which will accelerate the training procedure. As shown in the example, `pipeline` provides important data pipeline to process images, including loading from file system, resizing, cropping, transferring to `torch.Tensor` and packing to `GenDataSample`. All of supported data pipelines can be found in `mmedit/datasets/transforms`.
-
-For unconditional GANs with dynamic architectures like PGGAN and StyleGANv1, `GrowScaleImgDataset` is recommended to use for training. Since such dynamic architectures need real images in different scales, directly adopting `UnconditionalImageDataset` will bring heavy I/O cost for loading multiple high-resolution images. Here is an example we use for training PGGAN in CelebA-HQ dataset:
-
-```python
-dataset_type = 'GrowScaleImgDataset'
-
-pipeline = [
- dict(type='LoadImageFromFile', key='img'),
- dict(type='Flip', keys=['img'], direction='horizontal'),
- dict(type='PackGenInputs')
-]
-
-# `samples_per_gpu` and `imgs_root` need to be set.
-train_dataloader = dict(
- num_workers=4,
- batch_size=64,
- dataset=dict(
- type='GrowScaleImgDataset',
- data_roots={
- '1024': './data/ffhq/images',
- '256': './data/ffhq/ffhq_imgs/ffhq_256',
- '64': './data/ffhq/ffhq_imgs/ffhq_64'
- },
- gpu_samples_base=4,
- # note that this should be changed with total gpu number
- gpu_samples_per_scale={
- '4': 64,
- '8': 32,
- '16': 16,
- '32': 8,
- '64': 4,
- '128': 4,
- '256': 4,
- '512': 4,
- '1024': 4
- },
- len_per_stage=300000,
- pipeline=pipeline),
- sampler=dict(type='InfiniteSampler', shuffle=True))
-```
-
-In this dataset, you should provide a dictionary of image paths to the `data_roots`. Thus, you should resize the images in the dataset in advance.
-For the resizing methods in the data pre-processing, we adopt bilinear interpolation methods in all of the experiments studied in MMEditing.
-
-Note that this dataset should be used with `PGGANFetchDataHook`. In this config file, this hook should be added in the customized hooks, as shown below.
-
-```python
-custom_hooks = [
- dict(
- type='GenVisualizationHook',
- interval=5000,
- fixed_input=True,
- # vis ema and orig at the same time
- vis_kwargs_list=dict(
- type='Noise',
- name='fake_img',
- sample_model='ema/orig',
- target_keys=['ema', 'orig'])),
- dict(type='PGGANFetchDataHook')
-]
-```
-
-This fetching data hook helps the dataloader update the status of dataset to change the data source and batch size during training.
-
-Here, we provide several download links of datasets frequently used in unconditional models: [LSUN](http://dl.yf.io/lsun/), [CelebA](http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html), [CelebA-HQ](https://drive.google.com/drive/folders/11Vz0fqHS2rXDb5pprgTjpD7S2BAJhi1P), [FFHQ](https://drive.google.com/drive/folders/1u2xu7bSrWxrbUxk-dT-UvEJq8IjdmNTP).
diff --git a/docs/en/dataset_zoo/6_image_translation_datasets.md b/docs/en/dataset_zoo/6_image_translation_datasets.md
deleted file mode 100644
index 85cec47c16..0000000000
--- a/docs/en/dataset_zoo/6_image_translation_datasets.md
+++ /dev/null
@@ -1,149 +0,0 @@
-# Image Translation Datasets
-
-**Data preparation for translation model** needs a little attention. You should organize the files in the way we told you in `quick_run.md`. Fortunately, for most official datasets like facades and summer2winter_yosemite, they already have the right format. Also, you should set a symlink in the `data` directory. For paired-data trained translation model like Pix2Pix , `PairedImageDataset` is designed to train such translation models. Here is an example config for facades dataset:
-
-```python
-train_dataset_type = 'PairedImageDataset'
-val_dataset_type = 'PairedImageDataset'
-img_norm_cfg = dict(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
-train_pipeline = [
- dict(
- type='LoadPairedImageFromFile',
- io_backend='disk',
- key='pair',
- domain_a=domain_a,
- domain_b=domain_b,
- flag='color'),
- dict(
- type='Resize',
- keys=[f'img_{domain_a}', f'img_{domain_b}'],
- scale=(286, 286),
- interpolation='bicubic')
-]
-test_pipeline = [
- dict(
- type='LoadPairedImageFromFile',
- io_backend='disk',
- key='image',
- domain_a=domain_a,
- domain_b=domain_b,
- flag='color'),
- dict(
- type='Resize',
- keys=[f'img_{domain_a}', f'img_{domain_b}'],
- scale=(256, 256),
- interpolation='bicubic')
-]
-dataroot = 'data/paired/facades'
-train_dataloader = dict(
- batch_size=1,
- num_workers=4,
- persistent_workers=True,
- sampler=dict(type='InfiniteSampler', shuffle=True),
- dataset=dict(
- type=dataset_type,
- data_root=dataroot, # set by user
- pipeline=train_pipeline))
-
-val_dataloader = dict(
- batch_size=1,
- num_workers=4,
- dataset=dict(
- type=dataset_type,
- data_root=dataroot, # set by user
- pipeline=test_pipeline),
- sampler=dict(type='DefaultSampler', shuffle=False),
- persistent_workers=True)
-
-test_dataloader = dict(
- batch_size=1,
- num_workers=4,
- dataset=dict(
- type=dataset_type,
- data_root=dataroot, # set by user
- pipeline=test_pipeline),
- sampler=dict(type='DefaultSampler', shuffle=False),
- persistent_workers=True)
-```
-
-Here, we adopt `LoadPairedImageFromFile` to load a paired image as the common loader does and crops
-it into two images with the same shape in different domains. As shown in the example, `pipeline` provides important data pipeline to process images, including loading from file system, resizing, cropping, flipping, transferring to `torch.Tensor` and packing to `GenDataSample`. All of supported data pipelines can be found in `mmedit/datasets/transforms`.
-
-For unpaired-data trained translation model like CycleGAN , `UnpairedImageDataset` is designed to train such translation models. Here is an example config for horse2zebra dataset:
-
-```python
-train_dataset_type = 'UnpairedImageDataset'
-val_dataset_type = 'UnpairedImageDataset'
-img_norm_cfg = dict(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
-domain_a, domain_b = 'horse', 'zebra'
-train_pipeline = [
- dict(
- type='LoadImageFromFile',
- io_backend='disk',
- key=f'img_{domain_a}',
- flag='color'),
- dict(
- type='LoadImageFromFile',
- io_backend='disk',
- key=f'img_{domain_b}',
- flag='color'),
- dict(
- type='TransformBroadcaster',
- mapping={'img': [f'img_{domain_a}', f'img_{domain_b}']},
- auto_remap=True,
- share_random_params=True,
- transforms=[
- dict(type='Resize', scale=(286, 286), interpolation='bicubic'),
- dict(type='Crop', crop_size=(256, 256), random_crop=True),
- ]),
- dict(type='Flip', keys=[f'img_{domain_a}'], direction='horizontal'),
- dict(type='Flip', keys=[f'img_{domain_b}'], direction='horizontal'),
- dict(
- type='PackGenInputs',
- keys=[f'img_{domain_a}', f'img_{domain_b}'],
- meta_keys=[f'img_{domain_a}_path', f'img_{domain_b}_path'])
-]
-test_pipeline = [
- dict(type='LoadImageFromFile', io_backend='disk', key='img', flag='color'),
- dict(type='Resize', scale=(256, 256), interpolation='bicubic'),
- dict(
- type='PackGenInputs',
- keys=[f'img_{domain_a}', f'img_{domain_b}'],
- meta_keys=[f'img_{domain_a}_path', f'img_{domain_b}_path'])
-]
-data_root = './data/horse2zebra/'
-# `batch_size` and `data_root` need to be set.
-train_dataloader = dict(
- batch_size=1,
- num_workers=4,
- persistent_workers=True,
- sampler=dict(type='InfiniteSampler', shuffle=True),
- dataset=dict(
- type=dataset_type,
- data_root=data_root, # set by user
- pipeline=train_pipeline))
-
-val_dataloader = dict(
- batch_size=None,
- num_workers=4,
- dataset=dict(
- type=dataset_type,
- data_root=data_root, # set by user
- pipeline=test_pipeline),
- sampler=dict(type='DefaultSampler', shuffle=False),
- persistent_workers=True)
-
-test_dataloader = dict(
- batch_size=None,
- num_workers=4,
- dataset=dict(
- type=dataset_type,
- data_root=data_root, # set by user
- pipeline=test_pipeline),
- sampler=dict(type='DefaultSampler', shuffle=False),
- persistent_workers=True)
-```
-
-`UnpairedImageDataset` will load both images (domain A and B) from different paths and transform them at the same time.
-
-Here, we provide download links of datasets used in [Pix2Pix](http://efrosgans.eecs.berkeley.edu/pix2pix/datasets/) and [CycleGAN](https://people.eecs.berkeley.edu/~taesung_park/CycleGAN/datasets/).
diff --git a/docs/en/notes/4_faq.md b/docs/en/faq.md
similarity index 91%
rename from docs/en/notes/4_faq.md
rename to docs/en/faq.md
index 4edec727c2..7205a47449 100644
--- a/docs/en/notes/4_faq.md
+++ b/docs/en/faq.md
@@ -1,4 +1,4 @@
-# Frequently Asked Questions
+# Frequently asked questions
We list some common troubles faced by many users and their corresponding
solutions here. Feel free to enrich the list if you find any frequent issues
@@ -15,11 +15,11 @@ and make sure you fill in all required information in the template.
**Q2**: What's the folder structure of xxx dataset?
-**A2**: You can make sure the folder structure is correct following tutorials of [dataset preparation](../user_guides/2_dataset_prepare.md).
+**A2**: You can make sure the folder structure is correct following tutorials of [dataset preparation](user_guides/dataset_prepare.md).
**Q3**: How to use LMDB data to train the model?
-**A3**: You can use scripts in `tools/data` to make LMDB files. More details are shown in tutorials of [dataset preparation](../user_guides/2_dataset_prepare.md).
+**A3**: You can use scripts in `tools/data` to make LMDB files. More details are shown in tutorials of [dataset preparation](user_guides/dataset_prepare.md).
**Q4**: Why `MMCV==xxx is used but incompatible` is raised when import I try to import `mmgen`?
diff --git a/docs/en/2_get_started.md b/docs/en/get_started/install.md
similarity index 75%
rename from docs/en/2_get_started.md
rename to docs/en/get_started/install.md
index 3c7edcc92e..78fc8d1be3 100644
--- a/docs/en/2_get_started.md
+++ b/docs/en/get_started/install.md
@@ -1,4 +1,4 @@
-# Get Started: Install and Run MMEditing
+# Installation
In this section, you will know about:
@@ -7,7 +7,6 @@ In this section, you will know about:
- [Best practices](#best-practices)
- [Customize installation](#customize-installation)
- [Developing with multiple MMEditing versions](#developing-with-multiple-mmediting-versions)
-- [Quick run](#quick-run)
## Installation
@@ -156,7 +155,7 @@ docker run --gpus all --shm-size=8g -it -v {DATA_DIR}:/mmediting/data mmediting
#### Trouble shooting
-If you have some issues during the installation, please first view the [FAQ](notes/4_faq.md) page.
+If you have some issues during the installation, please first view the [FAQ](../faq.md) page.
You may [open an issue](https://github.com/open-mmlab/mmediting/issues/new/choose) on GitHub if no solution is found.
### Developing with multiple MMEditing versions
@@ -168,52 +167,3 @@ To use the default MMEditing installed in the environment rather than that you a
```shell
PYTHONPATH="$(dirname $0)/..":$PYTHONPATH
```
-
-## Quick run
-
-After installing MMEditing successfully, now you are able to play with MMEditing!
-
-To synthesize an image of a church, you only need several lines of codes by MMEditing!
-
-```python
-from mmedit.apis import init_model, sample_unconditional_model
-
-config_file = 'configs/styleganv2/stylegan2_c2_8xb4-800kiters_lsun-church-256x256.py'
-# you can download this checkpoint in advance and use a local file path.
-checkpoint_file = 'https://download.openmmlab.com/mmgen/stylegan2/official_weights/stylegan2-church-config-f-official_20210327_172657-1d42b7d1.pth'
-device = 'cuda:0'
-# init a generative model
-model = init_model(config_file, checkpoint_file, device=device)
-# sample images
-fake_imgs = sample_unconditional_model(model, 4)
-```
-
-Or you can just run the following command.
-
-```bash
-python demo/unconditional_demo.py \
-configs/styleganv2/stylegan2_c2_lsun-church_256_b4x8_800k.py \
-https://download.openmmlab.com/mmgen/stylegan2/official_weights/stylegan2-church-config-f-official_20210327_172657-1d42b7d1.pth
-
-```
-
-You will see a new image `unconditional_samples.png` in folder `work_dirs/demos/`, which contained generated samples.
-
-What's more, if you want to make these photos much more clear,
-you only need several lines of codes for image super-resolution by MMEditing!
-
-```python
-import mmcv
-from mmedit.apis import init_model, restoration_inference
-from mmedit.engine.misc import tensor2img
-
-config = 'configs/esrgan/esrgan_x4c64b23g32_1xb16-400k_div2k.py'
-checkpoint = 'https://download.openmmlab.com/mmediting/restorers/esrgan/esrgan_x4c64b23g32_1x16_400k_div2k_20200508-f8ccaf3b.pth'
-img_path = 'tests/data/image/lq/baboon_x4.png'
-model = init_model(config, checkpoint)
-output = restoration_inference(model, img_path)
-output = tensor2img(output)
-mmcv.imwrite(output, 'output.png')
-```
-
-Now, you can check your fancy photos in `output.png`.
diff --git a/docs/en/1_overview.md b/docs/en/get_started/overview.md
similarity index 92%
rename from docs/en/1_overview.md
rename to docs/en/get_started/overview.md
index b1c7f51472..62af697b74 100644
--- a/docs/en/1_overview.md
+++ b/docs/en/get_started/overview.md
@@ -78,7 +78,7 @@ MMEditing supports various applications, including:
- **New Modular Design for Flexible Combination:**
- We decompose the editing framework into different modules and one can easily construct a customized editor framework by combining different modules. Specifically, a new design for complex loss modules is proposed for customizing the links between modules, which can achieve flexible combinations among different modules.(Tutorial for [losses](advanced_guides/4_losses.md))
+ We decompose the editing framework into different modules and one can easily construct a customized editor framework by combining different modules. Specifically, a new design for complex loss modules is proposed for customizing the links between modules, which can achieve flexible combinations among different modules.(Tutorial for [losses](../howto/losses.md))
- **Efficient Distributed Training:**
@@ -86,12 +86,16 @@ MMEditing supports various applications, including:
## Get started
-For installation instructions, please see [get_started](2_get_started.md).
+For installation instructions, please see [Installation](install.md).
## User guides
-For beginners, we suggest learning the basic usage of MMEditing from [user_guides](user_guides/1_config.md).
+For beginners, we suggest learning the basic usage of MMEditing from [user_guides](../user_guides/config.md).
### Advanced guides
-For users who are familiar with MMEditing, you may want to learn the design of MMEditing, as well as how to extend the repo, how to use multiple repos and other advanced usages, please refer to [advanced_guides](advanced_guides/1_models.md).
+For users who are familiar with MMEditing, you may want to learn the design of MMEditing, as well as how to extend the repo, how to use multiple repos and other advanced usages, please refer to [advanced_guides](../advanced_guides/evaluator.md).
+
+### How to
+
+For users who want to use MMEditing to do something, please refer to [How to](../howto/models.md).
diff --git a/docs/en/get_started/quick_run.md b/docs/en/get_started/quick_run.md
new file mode 100644
index 0000000000..b243e5263a
--- /dev/null
+++ b/docs/en/get_started/quick_run.md
@@ -0,0 +1,48 @@
+# Quick run
+
+After installing MMEditing successfully, now you are able to play with MMEditing!
+
+To synthesize an image of a church, you only need several lines of codes by MMEditing!
+
+```python
+from mmedit.apis import init_model, sample_unconditional_model
+
+config_file = 'configs/styleganv2/stylegan2_c2_8xb4-800kiters_lsun-church-256x256.py'
+# you can download this checkpoint in advance and use a local file path.
+checkpoint_file = 'https://download.openmmlab.com/mmediting/stylegan2/official_weights/stylegan2-church-config-f-official_20210327_172657-1d42b7d1.pth'
+device = 'cuda:0'
+# init a generative model
+model = init_model(config_file, checkpoint_file, device=device)
+# sample images
+fake_imgs = sample_unconditional_model(model, 4)
+```
+
+Or you can just run the following command.
+
+```bash
+python demo/unconditional_demo.py \
+configs/styleganv2/stylegan2_c2_lsun-church_256_b4x8_800k.py \
+https://download.openmmlab.com/mmediting/stylegan2/official_weights/stylegan2-church-config-f-official_20210327_172657-1d42b7d1.pth
+
+```
+
+You will see a new image `unconditional_samples.png` in folder `work_dirs/demos/`, which contained generated samples.
+
+What's more, if you want to make these photos much more clear,
+you only need several lines of codes for image super-resolution by MMEditing!
+
+```python
+import mmcv
+from mmedit.apis import init_model, restoration_inference
+from mmedit.engine.misc import tensor2img
+
+config = 'configs/esrgan/esrgan_x4c64b23g32_1xb16-400k_div2k.py'
+checkpoint = 'https://download.openmmlab.com/mmediting/restorers/esrgan/esrgan_x4c64b23g32_1x16_400k_div2k_20200508-f8ccaf3b.pth'
+img_path = 'tests/data/image/lq/baboon_x4.png'
+model = init_model(config, checkpoint)
+output = restoration_inference(model, img_path)
+output = tensor2img(output)
+mmcv.imwrite(output, 'output.png')
+```
+
+Now, you can check your fancy photos in `output.png`.
diff --git a/docs/en/advanced_guides/2_dataset.md b/docs/en/howto/dataset.md
similarity index 79%
rename from docs/en/advanced_guides/2_dataset.md
rename to docs/en/howto/dataset.md
index ab0c380ee5..11086661fe 100644
--- a/docs/en/advanced_guides/2_dataset.md
+++ b/docs/en/howto/dataset.md
@@ -1,4 +1,4 @@
-# Prepare Your Own Datasets
+# How to prepare your own datasets
In this document, we will introduce the design of each datasets in MMEditing and how users can design their own dataset.
@@ -198,6 +198,144 @@ dataset = BasicFramesDataset(
img=['img1.png', 'img3.png'], gt=['img2.png']))
```
+### BasicConditonalDataset
+
+**BasicConditonalDataset** `mmedit.datasets.BasicConditonalDataset` is designed for conditional GANs (e.g., SAGAN, BigGAN). This dataset support load label for the annotation file. `BasicConditonalDataset` support three kinds of annotation as follow:
+
+#### 1. Annotation file read by line (e.g., txt)
+
+Sample files structure:
+
+```
+ data_prefix/
+ ├── folder_1
+ │ ├── xxx.png
+ │ ├── xxy.png
+ │ └── ...
+ └── folder_2
+ ├── 123.png
+ ├── nsdf3.png
+ └── ...
+```
+
+Sample annotation file (the first column is the image path and the second column is the index of category):
+
+```
+ folder_1/xxx.png 0
+ folder_1/xxy.png 1
+ folder_2/123.png 5
+ folder_2/nsdf3.png 3
+ ...
+```
+
+Config example for ImageNet dataset:
+
+```python
+dataset=dict(
+ type='BasicConditionalDataset,
+ data_root='./data/imagenet/',
+ ann_file='meta/train.txt',
+ data_prefix='train',
+ pipeline=train_pipeline),
+```
+
+#### 2. Dict-based annotation file (e.g., json):
+
+Sample files structure:
+
+```
+ data_prefix/
+ ├── folder_1
+ │ ├── xxx.png
+ │ ├── xxy.png
+ │ └── ...
+ └── folder_2
+ ├── 123.png
+ ├── nsdf3.png
+ └── ...
+```
+
+Sample annotation file (the key is the image path and the value column
+is the label):
+
+```
+ {
+ "folder_1/xxx.png": [1, 2, 3, 4],
+ "folder_1/xxy.png": [2, 4, 1, 0],
+ "folder_2/123.png": [0, 9, 8, 1],
+ "folder_2/nsdf3.png", [1, 0, 0, 2],
+ ...
+ }
+```
+
+Config example for EG3D (shapenet-car) dataset:
+
+```python
+dataset = dict(
+ type='BasicConditionalDataset',
+ data_root='./data/eg3d/shapenet-car',
+ ann_file='annotation.json',
+ pipeline=train_pipeline)
+```
+
+In this kind of annotation, labels can be any type and not restricted to an index.
+
+#### 3. Folder-based annotation (no annotation file need):
+
+Sample files structure:
+
+```
+ data_prefix/
+ ├── class_x
+ │ ├── xxx.png
+ │ ├── xxy.png
+ │ └── ...
+ │ └── xxz.png
+ └── class_y
+ ├── 123.png
+ ├── nsdf3.png
+ ├── ...
+ └── asd932_.png
+```
+
+If the annotation file is specified, the dataset will be generated by the first two ways, otherwise, try the third way.
+
+### ImageNet Dataset and CIFAR10 Dataset
+
+**ImageNet Dataset**`mmedit.datasets.ImageNet` and **CIFAR10 Dataset**`mmedit.datasets.CIFAR10` are datasets specific designed for ImageNet and CIFAR10 datasets. Both two datasets are encapsulation of `BasicConditionalDataset`. You can used them to load data from ImageNet dataset and CIFAR10 dataset easily.
+
+Config example for ImageNet:
+
+```python
+pipeline = [
+ dict(type='LoadImageFromFile', key='img'),
+ dict(type='RandomCropLongEdge', keys=['img']),
+ dict(type='Resize', scale=(128, 128), keys=['img'], backend='pillow'),
+ dict(type='Flip', keys=['img'], flip_ratio=0.5, direction='horizontal'),
+ dict(type='PackEditInputs')
+]
+
+dataset=dict(
+ type='ImageNet',
+ data_root='./data/imagenet/',
+ ann_file='meta/train.txt',
+ data_prefix='train',
+ pipeline=pipeline),
+```
+
+Config example for CIFAR10:
+
+```python
+pipeline = [dict(type='PackEditInputs')]
+
+dataset = dict(
+ type='CIFAR10',
+ data_root='./data',
+ data_prefix='cifar10',
+ test_mode=False,
+ pipeline=pipeline)
+```
+
### AdobeComp1kDataset
**AdobeComp1kDataset** `mmedit.datasets.AdobeComp1kDataset`
diff --git a/docs/en/advanced_guides/4_losses.md b/docs/en/howto/losses.md
similarity index 99%
rename from docs/en/advanced_guides/4_losses.md
rename to docs/en/howto/losses.md
index 22ea7a2590..3485a02ed9 100644
--- a/docs/en/advanced_guides/4_losses.md
+++ b/docs/en/howto/losses.md
@@ -1,4 +1,4 @@
-# Design Your Own Loss Functions
+# How to design your own loss functions
`losses` are registered as `LOSSES` in `MMEditing`.
Customizing losses is similar to customizing any other model.
diff --git a/docs/en/advanced_guides/1_models.md b/docs/en/howto/models.md
similarity index 99%
rename from docs/en/advanced_guides/1_models.md
rename to docs/en/howto/models.md
index 0d5e9cefdb..d7e93eb4e5 100644
--- a/docs/en/advanced_guides/1_models.md
+++ b/docs/en/howto/models.md
@@ -1,4 +1,4 @@
-# Design Your Own Models
+# How to design your own models
MMEditing is built upon MMEngine and MMCV, which enables users to design new models quickly, train and evaluate them easily.
In this section, you will learn how to design your own models.
@@ -406,7 +406,7 @@ After implementing the network architecture and the forward loop of SRCNN,
now we can create a new file `configs/srcnn/srcnn_x4k915_g1_1000k_div2k.py`
to set the configurations needed by training SRCNN.
-In the configuration file, we need to specify the parameters of our model, `class BaseEditModel`, including the generator network architecture, loss function, additional training and testing configuration, and data preprocessor of input tensors. Please refer to the [Introduction to the loss in MMEditing](./4_losses.md) for more details of losses in MMEditing.
+In the configuration file, we need to specify the parameters of our model, `class BaseEditModel`, including the generator network architecture, loss function, additional training and testing configuration, and data preprocessor of input tensors. Please refer to the [Introduction to the loss in MMEditing](./losses.md) for more details of losses in MMEditing.
```python
# model settings
@@ -425,7 +425,7 @@ model = dict(
))
```
-We also need to specify the training dataloader and testing dataloader according to [create your own dataloader](../dataset_zoo/0_overview.md).
+We also need to specify the training dataloader and testing dataloader according to create your own dataloader.
Finally we can start training our own model by:
```python
@@ -733,7 +733,7 @@ model = dict(
out_channels=1))
```
-We also need to specify the training dataloader and testing dataloader according to [create your own dataloader](2_dataset.md).
+We also need to specify the training dataloader and testing dataloader according to [create your own dataloader](dataset.md).
Finally we can start training our own model by:
```python
diff --git a/docs/en/advanced_guides/3_transforms.md b/docs/en/howto/transforms.md
similarity index 99%
rename from docs/en/advanced_guides/3_transforms.md
rename to docs/en/howto/transforms.md
index 565a3499ab..46719f58c9 100644
--- a/docs/en/advanced_guides/3_transforms.md
+++ b/docs/en/howto/transforms.md
@@ -1,4 +1,4 @@
-# Design Your Own Data Pipelines
+# How to design your own data transforms
In this tutorial, we introduce the design of transforms pipeline in MMEditing.
diff --git a/docs/en/index.rst b/docs/en/index.rst
index e60fbaefc0..73cc96cb0b 100644
--- a/docs/en/index.rst
+++ b/docs/en/index.rst
@@ -34,108 +34,128 @@ Codes are available on `GitHub
+
+#### 7. Resolve conflicts
+
+If your local branch conflicts with the latest master branch of "upstream", you'll need to resolove them. There are two ways to do this:
+
+```shell
+git fetch --all --prune
+git rebase upstream/master
+```
+
+or
+
+```shell
+git fetch --all --prune
+git merge upstream/master
+```
+
+If you are very good at handling conflicts, then you can use rebase to resolve conflicts, as this will keep your commit logs tidy. If you are not familiar with `rebase`, then you can use `merge` to resolve conflicts.
+
+### Guidance
+
+#### Unit test
+
+We should make sure the committed code will not decrease the coverage of unit test, we could run the following command to check the coverage of unit test:
+
+```shell
+python -m coverage run -m pytest /path/to/test_file
+python -m coverage html
+# check file in htmlcov/index.html
+```
+
+#### Document rendering
+
+If the documents are modified/added, we should check the rendering result. We could install the dependencies and run the following command to render the documents and check the results:
+
+```shell
+pip install -r requirements/docs.txt
+cd docs/zh_cn/
+# or docs/en
+make html
+# check file in ./docs/zh_cn/_build/html/index.html
+```
+
+### Code style
+
+#### Python
+
+We adopt [PEP8](https://www.python.org/dev/peps/pep-0008/) as the preferred code style.
+
+We use the following tools for linting and formatting:
+
+- [flake8](https://github.com/PyCQA/flake8): A wrapper around some linter tools.
+- [isort](https://github.com/timothycrosley/isort): A Python utility to sort imports.
+- [yapf](https://github.com/google/yapf): A formatter for Python files.
+- [codespell](https://github.com/codespell-project/codespell): A Python utility to fix common misspellings in text files.
+- [mdformat](https://github.com/executablebooks/mdformat): Mdformat is an opinionated Markdown formatter that can be used to enforce a consistent style in Markdown files.
+- [docformatter](https://github.com/myint/docformatter): A formatter to format docstring.
+
+Style configurations of yapf and isort can be found in [setup.cfg](../../../setup.cfg).
+
+We use [pre-commit hook](https://pre-commit.com/) that checks and formats for `flake8`, `yapf`, `isort`, `trailing whitespaces`, `markdown files`,
+fixes `end-of-files`, `double-quoted-strings`, `python-encoding-pragma`, `mixed-line-ending`, sorts `requirments.txt` automatically on every commit.
+The config for a pre-commit hook is stored in [.pre-commit-config](../../../.pre-commit-config.yaml).
+
+#### C++ and CUDA
+
+We follow the [Google C++ Style Guide](https://google.github.io/styleguide/cppguide.html).
+
+### PR Specs
+
+1. Use [pre-commit](https://pre-commit.com) hook to avoid issues of code style
+
+2. One short-time branch should be matched with only one PR
+
+3. Accomplish a detailed change in one PR. Avoid large PR
+
+ - Bad: Support Faster R-CNN
+ - Acceptable: Add a box head to Faster R-CNN
+ - Good: Add a parameter to box head to support custom conv-layer number
+
+4. Provide clear and significant commit message
+
+5. Provide clear and meaningful PR description
+
+ - Task name should be clarified in title. The general format is: \[Prefix\] Short description of the PR (Suffix)
+ - Prefix: add new feature \[Feature\], fix bug \[Fix\], related to documents \[Docs\], in developing \[WIP\] (which will not be reviewed temporarily)
+ - Introduce main changes, results and influences on other modules in short description
+ - Associate related issues and pull requests with a milestone
diff --git a/docs/en/community/projects.md b/docs/en/community/projects.md
new file mode 100644
index 0000000000..50e25c903f
--- /dev/null
+++ b/docs/en/community/projects.md
@@ -0,0 +1,67 @@
+# MMEditing projects
+
+Welcome to the MMEditing community!
+The MMEditing ecosystem consists of tutorials, libraries, and projects from a broad set of researchers in academia and industry, ML and application engineers.
+The goal of this ecosystem is to support, accelerate, and aid in your exploration with MMEditing for image, video, 3D content generation, editing and processing.
+
+Here are a few projects that are built upon MMEditing. They are examples of how to use MMEditing as a library, to make your projects more maintainable.
+Please find more projects in [MMEditing Ecosystem](https://openmmlab.com/ecosystem).
+
+## Show your projects on OpenMMLab Ecosystem
+
+You can submit your project so that it can be shown on the homepage of [OpenMMLab](https://openmmlab.com/ecosystem).
+
+## Add example projects to MMEditing
+
+Here is an [example project](../../../projects/example_project) about how to add your projects to MMEditing.
+You can copy and create your own project from the [example project](../../../projects/example_project).
+
+We also provide some documentation listed below for your reference:
+
+- [Contribution Guide](https://mmediting.readthedocs.io/en/dev-1.x/community/contributing.html)
+
+ The guides for new contributors about how to add your projects to MMEditing.
+
+- [New Model Guide](https://mmediting.readthedocs.io/en/dev-1.x/howto/models.html)
+
+ The documentation of adding new models.
+
+- [Discussions](https://github.com/open-mmlab/mmediting/discussions)
+
+ Welcome to start a discussion!
+
+## Projects of libraries and toolboxes
+
+- [PowerVQE](https://github.com/ryanxingql/powervqe): Open framework for quality enhancement of compressed videos based on PyTorch and MMEditing.
+
+- [VR-Baseline](https://github.com/linjing7/VR-Baseline): Video Restoration Toolbox.
+
+- [Derain-Toolbox](https://github.com/biubiubiiu/derain-toolbox): Single Image Deraining Toolbox and Benchmark
+
+## Projects of research papers
+
+- [Towards Interpretable Video Super-Resolution via Alternating Optimization, ECCV 2022](https://arxiv.org/abs/2207.10765)[\[github\]](https://github.com/caojiezhang/DAVSR)
+
+- [SepLUT:Separable Image-adaptive Lookup Tables for Real-time Image Enhancement, ECCV 2022](https://arxiv.org/abs/2207.08351)[\[github\]](https://github.com/ImCharlesY/SepLUT)
+
+- [TTVSR: Learning Trajectory-Aware Transformer for Video Super-Resolution, CVPR 2022](https://arxiv.org/abs/2204.04216)[\[github\]](https://github.com/researchmm/TTVSR)
+
+- [Arbitrary-Scale Image Synthesis, CVPR 2022](https://arxiv.org/pdf/2204.02273.pdf)[\[github\]](https://github.com/vglsd/ScaleParty)
+
+- [Investigating Tradeoffs in Real-World Video Super-Resolution(RealBasicVSR), CVPR 2022](https://arxiv.org/abs/2111.12704)[\[github\]](https://github.com/ckkelvinchan/RealBasicVSR)
+
+- [BasicVSR++: Improving Video Super-Resolution with Enhanced Propagation and Alignment, CVPR 2022](https://arxiv.org/abs/2104.13371)[\[github\]](https://github.com/ckkelvinchan/BasicVSR_PlusPlus)
+
+- [Multi-Scale Memory-Based Video Deblurring, CVPR 2022](https://arxiv.org/abs/2204.02977)[\[github\]](https://github.com/jibo27/MemDeblur)
+
+- [AdaInt:Learning Adaptive Intervals for 3D Lookup Tables on Real-time Image Enhancement, CVPR 2022](https://arxiv.org/abs/2204.13983)[\[github\]](https://github.com/ImCharlesY/AdaInt)
+
+- [A New Dataset and Transformer for Stereoscopic Video Super-Resolution, CVPRW 2022](https://openaccess.thecvf.com/content/CVPR2022W/NTIRE/papers/Imani_A_New_Dataset_and_Transformer_for_Stereoscopic_Video_Super-Resolution_CVPRW_2022_paper.pdf)[\[github\]](https://github.com/H-deep/Trans-SVSR)
+
+- [Liquid warping GAN with attention: A unified framework for human image synthesis, TPAMI 2021](https://arxiv.org/pdf/2011.09055.pdf)[\[github\]](https://github.com/iPERDance/iPERCore)
+
+- [BasicVSR:The Search for Essential Components in Video Super-Resolution and Beyond, CVPR 2021](https://arxiv.org/abs/2012.02181)[\[github\]](https://github.com/ckkelvinchan/BasicVSR-IconVSR)
+
+- [GLEAN:Generative Latent Bank for Large-Factor Image Super-Resolution, CVPR 2021](https://arxiv.org/abs/2012.00739)[\[github\]](https://github.com/ckkelvinchan/GLEAN)
+
+- [DAN:Unfolding the Alternating Optimization for Blind Super Resolution, NeurIPS 2020](https://arxiv.org/abs/2010.02631v4)[\[github\]](https://github.com/AlexZou14/DAN-Basd-on-Openmmlab)
diff --git a/docs/en/conf.py b/docs/en/conf.py
index 81909842d5..d6aed67aad 100644
--- a/docs/en/conf.py
+++ b/docs/en/conf.py
@@ -31,21 +31,44 @@
# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
# ones.
extensions = [
- 'sphinx.ext.autodoc',
- 'sphinx.ext.autosummary',
'sphinx.ext.intersphinx',
'sphinx.ext.napoleon',
'sphinx.ext.viewcode',
'sphinx.ext.autosectionlabel',
'sphinx_markdown_tables',
- 'myst_parser',
'sphinx_copybutton',
- 'sphinx.ext.autodoc.typehints',
+ 'sphinx_tabs.tabs',
+ 'myst_parser',
]
+extensions.append('notfound.extension') # enable customizing not-found page
+
+extensions.append('autoapi.extension')
+autoapi_type = 'python'
+autoapi_dirs = ['../../mmedit']
+autoapi_add_toctree_entry = False
+autoapi_template_dir = '_templates'
+# autoapi_options = ['members', 'undoc-members', 'show-module-summary']
+
+# # Core library for html generation from docstrings
+# extensions.append('sphinx.ext.autodoc')
+# extensions.append('sphinx.ext.autodoc.typehints')
+# # Enable 'expensive' imports for sphinx_autodoc_typehints
+# set_type_checking_flag = True
+# # Sphinx-native method. Not as good as sphinx_autodoc_typehints
+# autodoc_typehints = "description"
+
+# extensions.append('sphinx.ext.autosummary') # Create neat summary tables
+# autosummary_generate = True # Turn on sphinx.ext.autosummary
+# # Add __init__ doc (ie. params) to class summaries
+# autoclass_content = 'both'
+# autodoc_skip_member = []
+# # If no docstring, inherit from base class
+# autodoc_inherit_docstrings = True
+
autodoc_mock_imports = [
- 'mmedit.version', 'mmcv.ops.ModulatedDeformConv2d',
- 'mmcv.ops.modulated_deform_conv2d', 'mmcv._ext'
+ 'mmedit.version', 'mmcv._ext', 'mmcv.ops.ModulatedDeformConv2d',
+ 'mmcv.ops.modulated_deform_conv2d', 'clip', 'resize_right', 'pandas'
]
source_suffix = {
@@ -53,6 +76,11 @@
'.md': 'markdown',
}
+# # Remove 'view source code' from top of page (for html, not python)
+# html_show_sourcelink = False
+# nbsphinx_allow_errors = True # Continue through Jupyter errors
+# add_module_names = False # Remove namespaces from class/method signatures
+
# Ignore >>> when copying code
copybutton_prompt_text = r'>>> |\.\.\. '
copybutton_prompt_is_regexp = True
@@ -94,11 +122,6 @@
'url': 'https://mmediting.readthedocs.io/en/1.x/',
'description': '1.x branch',
},
- {
- 'name': 'MMEditing 1.x',
- 'url': 'https://mmediting.readthedocs.io/en/dev-1.x/',
- 'description': 'docs at 1.x branch'
- },
],
'active':
True,
@@ -106,16 +129,6 @@
],
'menu_lang':
'en',
- 'header_note': {
- 'content':
- 'You are reading the documentation for MMEditing 0.x, which '
- 'will soon be deprecated by the end of 2022. We recommend you upgrade '
- 'to MMEditing 1.0 to enjoy fruitful new features and better performance ' # noqa
- ' brought by OpenMMLab 2.0. Check out the '
- 'changelog, ' # noqa
- 'code ' # noqa
- 'and documentation of MMEditing 1.0 for more details.', # noqa
- }
}
# Add any paths that contain custom static files (such as style sheets) here,
@@ -130,13 +143,21 @@
language = 'en'
# The master toctree document.
-master_doc = 'index'
+root_doc = 'index'
+notfound_template = '404.html'
def builder_inited_handler(app):
- subprocess.run(['bash', './.dev_scripts/update_dataset_zoo.sh'])
subprocess.run(['python', './.dev_scripts/update_model_zoo.py'])
+ subprocess.run(['python', './.dev_scripts/update_dataset_zoo.py'])
+
+
+def skip_member(app, what, name, obj, skip, options):
+ if what == 'package' or what == 'module':
+ skip = True
+ return skip
def setup(app):
app.connect('builder-inited', builder_inited_handler)
+ app.connect('autoapi-skip-member', skip_member)
diff --git a/docs/en/dataset_zoo/0_overview.md b/docs/en/dataset_zoo/0_overview.md
deleted file mode 100644
index d0a2da7f40..0000000000
--- a/docs/en/dataset_zoo/0_overview.md
+++ /dev/null
@@ -1,18 +0,0 @@
-# Overview
-
-- [Prepare Super-Resolution Datasets](./1_super_resolution_datasets.md)
- - [DF2K_OST](./1_super_resolution_datasets.md#df2k_ost-dataset) \[ [Homepage](https://github.com/xinntao/Real-ESRGAN/blob/master/docs/Training.md) \]
- - [DIV2K](./1_super_resolution_datasets.md#div2k-dataset) \[ [Homepage](https://data.vision.ee.ethz.ch/cvl/DIV2K/) \]
- - [REDS](./1_super_resolution_datasets.md#reds-dataset) \[ [Homepage](https://seungjunnah.github.io/Datasets/reds.html) \]
- - [Vid4](./1_super_resolution_datasets.md#vid4-dataset) \[ [Homepage](https://drive.google.com/file/d/1ZuvNNLgR85TV_whJoHM7uVb-XW1y70DW/view) \]
- - [Vimeo90K](./1_super_resolution_datasets.md#vimeo90k-dataset) \[ [Homepage](http://toflow.csail.mit.edu) \]
-- [Prepare Inpainting Datasets](./2_inpainting_datasets.md)
- - [CelebA-HQ](./2_inpainting_datasets.md#celeba-hq-dataset) \[ [Homepage](https://github.com/tkarras/progressive_growing_of_gans#preparing-datasets-for-training) \]
- - [Paris Street View](./2_inpainting_datasets.md#paris-street-view-dataset) \[ [Homepage](https://github.com/pathak22/context-encoder/issues/24) \]
- - [Places365](./2_inpainting_datasets.md#places365-dataset) \[ [Homepage](http://places2.csail.mit.edu/) \]
-- [Prepare Matting Datasets](./3_matting_datasets.md)
- - [Composition-1k](./3_matting_datasets.md#composition-1k-dataset) \[ [Homepage](https://sites.google.com/view/deepimagematting) \]
-- [Prepare Video Frame Interpolation Datasets](./4_video_interpolation_datasets.md)
- - [Vimeo90K-triplet](./4_video_interpolation_datasets.md#vimeo90k-triplet-dataset) \[ [Homepage](http://toflow.csail.mit.edu) \]
-- [Prepare Unconditional GANs Datasets](./5_unconditional_gans_datasets.md)
-- [Prepare Image Translation Datasets](./6_image_translation_datasets.md)
diff --git a/docs/en/dataset_zoo/1_super_resolution_datasets.md b/docs/en/dataset_zoo/1_super_resolution_datasets.md
deleted file mode 100644
index e6afa8ff6d..0000000000
--- a/docs/en/dataset_zoo/1_super_resolution_datasets.md
+++ /dev/null
@@ -1,356 +0,0 @@
-# Super-Resolution Datasets
-
-It is recommended to symlink the dataset root to `$MMEDITING/data`. If your folder structure is different, you may need to change the corresponding paths in config files.
-
-MMEditing supported super-resolution datasets:
-
-- Image Super-Resolution
- - [DF2K_OST](#df2k_ost-dataset) \[ [Homepage](https://github.com/xinntao/Real-ESRGAN/blob/master/docs/Training.md) \]
- - [DIV2K](#div2k-dataset) \[ [Homepage](https://data.vision.ee.ethz.ch/cvl/DIV2K/) \]
-- Video Super-Resolution
- - [REDS](#reds-dataset) \[ [Homepage](https://seungjunnah.github.io/Datasets/reds.html) \]
- - [Vid4](#vid4-dataset) \[ [Homepage](https://drive.google.com/file/d/1ZuvNNLgR85TV_whJoHM7uVb-XW1y70DW/view) \]
- - [Vimeo90K](#vimeo90k-dataset) \[ [Homepage](http://toflow.csail.mit.edu) \]
-
-## DF2K_OST Dataset
-
-
-
-```bibtex
-@inproceedings{wang2021real,
- title={Real-ESRGAN: Training Real-World Blind Super-Resolution with Pure Synthetic Data},
- author={Wang, Xintao and Xie, Liangbin and Dong, Chao and Shan, Ying},
- booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
- pages={1905--1914},
- year={2021}
-}
-```
-
-- The DIV2K dataset can be downloaded from [here](https://data.vision.ee.ethz.ch/cvl/DIV2K/) (We use the training set only).
-- The Flickr2K dataset can be downloaded [here](https://cv.snu.ac.kr/research/EDSR/Flickr2K.tar) (We use the training set only).
-- The OST dataset can be downloaded [here](https://openmmlab.oss-cn-hangzhou.aliyuncs.com/datasets/OST_dataset.zip) (We use the training set only).
-
-Please first put all the images into the `GT` folder (naming does not need to be in order):
-
-```text
-mmediting
-├── mmedit
-├── tools
-├── configs
-├── data
-│ ├── df2k_ost
-│ │ ├── GT
-│ │ │ ├── 0001.png
-│ │ │ ├── 0002.png
-│ │ │ ├── ...
-...
-```
-
-### Crop sub-images
-
-For faster IO, we recommend to crop the images to sub-images. We provide such a script:
-
-```shell
-python tools/dataset_converters/super-resolution/df2k_ost/preprocess_df2k_ost_dataset.py --data-root ./data/df2k_ost
-```
-
-The generated data is stored under `df2k_ost` and the data structure is as follows, where `_sub` indicates the sub-images.
-
-```text
-mmediting
-├── mmedit
-├── tools
-├── configs
-├── data
-│ ├── df2k_ost
-│ │ ├── GT
-│ │ ├── GT_sub
-...
-```
-
-### Prepare LMDB dataset for DF2K_OST
-
-If you want to use LMDB datasets for faster IO speed, you can make LMDB files by:
-
-```shell
-python tools/dataset_converters/super-resolution/df2k_ost/preprocess_df2k_ost_dataset.py --data-root ./data/df2k_ost --make-lmdb
-```
-
-## DIV2K Dataset
-
-
-
-```bibtex
-@InProceedings{Agustsson_2017_CVPR_Workshops,
- author = {Agustsson, Eirikur and Timofte, Radu},
- title = {NTIRE 2017 Challenge on Single Image Super-Resolution: Dataset and Study},
- booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops},
- month = {July},
- year = {2017}
-}
-```
-
-- Training dataset: [DIV2K dataset](https://data.vision.ee.ethz.ch/cvl/DIV2K/).
-- Validation dataset: Set5 and Set14.
-
-```text
-mmediting
-├── mmedit
-├── tools
-├── configs
-├── data
-│ ├── DIV2K
-│ │ ├── DIV2K_train_HR
-│ │ ├── DIV2K_train_LR_bicubic
-│ │ │ ├── X2
-│ │ │ ├── X3
-│ │ │ ├── X4
-│ │ ├── DIV2K_valid_HR
-│ │ ├── DIV2K_valid_LR_bicubic
-│ │ │ ├── X2
-│ │ │ ├── X3
-│ │ │ ├── X4
-│ ├── Set5
-│ │ ├── GTmod12
-│ │ ├── LRbicx2
-│ │ ├── LRbicx3
-│ │ ├── LRbicx4
-│ ├── Set14
-│ │ ├── GTmod12
-│ │ ├── LRbicx2
-│ │ ├── LRbicx3
-│ │ ├── LRbicx4
-```
-
-### Crop sub-images
-
-For faster IO, we recommend to crop the DIV2K images to sub-images. We provide such a script:
-
-```shell
-python tools/dataset_converters/super-resolution/div2k/preprocess_div2k_dataset.py --data-root ./data/DIV2K
-```
-
-The generated data is stored under `DIV2K` and the data structure is as follows, where `_sub` indicates the sub-images.
-
-```text
-mmediting
-├── mmedit
-├── tools
-├── configs
-├── data
-│ ├── DIV2K
-│ │ ├── DIV2K_train_HR
-│ │ ├── DIV2K_train_HR_sub
-│ │ ├── DIV2K_train_LR_bicubic
-│ │ │ ├── X2
-│ │ │ ├── X3
-│ │ │ ├── X4
-│ │ │ ├── X2_sub
-│ │ │ ├── X3_sub
-│ │ │ ├── X4_sub
-│ │ ├── DIV2K_valid_HR
-│ │ ├── ...
-...
-```
-
-### Prepare annotation list
-
-If you use the annotation mode for the dataset, you first need to prepare a specific `txt` file.
-
-Each line in the annotation file contains the image names and image shape (usually for the ground-truth images), separated by a white space.
-
-Example of an annotation file:
-
-```text
-0001_s001.png (480,480,3)
-0001_s002.png (480,480,3)
-```
-
-### Prepare LMDB dataset for DIV2K
-
-If you want to use LMDB datasets for faster IO speed, you can make LMDB files by:
-
-```shell
-python tools/dataset_converters/super-resolution/div2k/preprocess_div2k_dataset.py --data-root ./data/DIV2K --make-lmdb
-```
-
-## REDS Dataset
-
-
-
-```bibtex
-@InProceedings{Nah_2019_CVPR_Workshops_REDS,
- author = {Nah, Seungjun and Baik, Sungyong and Hong, Seokil and Moon, Gyeongsik and Son, Sanghyun and Timofte, Radu and Lee, Kyoung Mu},
- title = {NTIRE 2019 Challenge on Video Deblurring and Super-Resolution: Dataset and Study},
- booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops},
- month = {June},
- year = {2019}
-}
-```
-
-- Training dataset: [REDS dataset](https://seungjunnah.github.io/Datasets/reds.html).
-- Validation dataset: [REDS dataset](https://seungjunnah.github.io/Datasets/reds.html) and Vid4.
-
-Note that we merge train and val datasets in REDS for easy switching between REDS4 partition (used in EDVR) and the official validation partition.
-The original val dataset (clip names from 000 to 029) are modified to avoid conflicts with training dataset (total 240 clips). Specifically, the clip names are changed to 240, 241, ... 269.
-
-You can prepare the REDS dataset by running:
-
-```shell
-python tools/dataset_converters/super-resolution/reds/preprocess_reds_dataset.py --root-path ./data/REDS
-```
-
-```text
-mmediting
-├── mmedit
-├── tools
-├── configs
-├── data
-│ ├── REDS
-│ │ ├── train_sharp
-│ │ │ ├── 000
-│ │ │ ├── 001
-│ │ │ ├── ...
-│ │ ├── train_sharp_bicubic
-│ │ │ ├── 000
-│ │ │ ├── 001
-│ │ │ ├── ...
-│ ├── REDS4
-│ │ ├── GT
-│ │ ├── sharp_bicubic
-```
-
-### Prepare LMDB dataset for REDS
-
-If you want to use LMDB datasets for faster IO speed, you can make LMDB files by:
-
-```shell
-python tools/dataset_converters/super-resolution/reds/preprocess_reds_dataset.py --root-path ./data/REDS --make-lmdb
-```
-
-### Crop to sub-images
-
-MMEditing also support cropping REDS images to sub-images for faster IO. We provide such a script:
-
-```shell
-python tools/dataset_converters/super-resolution/reds/crop_sub_images.py --data-root ./data/REDS -scales 4
-```
-
-The generated data is stored under `REDS` and the data structure is as follows, where `_sub` indicates the sub-images.
-
-```text
-mmediting
-├── mmedit
-├── tools
-├── configs
-├── data
-│ ├── REDS
-│ │ ├── train_sharp
-│ │ │ ├── 000
-│ │ │ ├── 001
-│ │ │ ├── ...
-│ │ ├── train_sharp_sub
-│ │ │ ├── 000_s001
-│ │ │ ├── 000_s002
-│ │ │ ├── ...
-│ │ │ ├── 001_s001
-│ │ │ ├── ...
-│ │ ├── train_sharp_bicubic
-│ │ │ ├── X4
-│ │ │ │ ├── 000
-│ │ │ │ ├── 001
-│ │ │ │ ├── ...
-│ │ │ ├── X4_sub
-│ │ │ ├── 000_s001
-│ │ │ ├── 000_s002
-│ │ │ ├── ...
-│ │ │ ├── 001_s001
-│ │ │ ├── ...
-```
-
-Note that by default `preprocess_reds_dataset.py` does not make lmdb and annotation file for the cropped dataset. You may need to modify the scripts a little bit for such operations.
-
-## Vid4 Dataset
-
-
-
-```bibtex
-@article{xue2019video,
- title={On Bayesian adaptive video super resolution},
- author={Liu, Ce and Sun, Deqing},
- journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
- volume={36},
- number={2},
- pages={346--360},
- year={2013},
- publisher={IEEE}
-}
-```
-
-The Vid4 dataset can be downloaded from [here](https://drive.google.com/file/d/1ZuvNNLgR85TV_whJoHM7uVb-XW1y70DW/view?usp=sharing). There are two degradations in the dataset.
-
-1. BIx4 contains images downsampled by bicubic interpolation
-2. BDx4 contains images blurred by Gaussian kernel with σ=1.6, followed by a subsampling every four pixels.
-
-## Vimeo90K Dataset
-
-
-
-```bibtex
-@article{xue2019video,
- title={Video Enhancement with Task-Oriented Flow},
- author={Xue, Tianfan and Chen, Baian and Wu, Jiajun and Wei, Donglai and Freeman, William T},
- journal={International Journal of Computer Vision (IJCV)},
- volume={127},
- number={8},
- pages={1106--1125},
- year={2019},
- publisher={Springer}
-}
-```
-
-The training and test datasets can be download from [here](http://toflow.csail.mit.edu/).
-
-The Vimeo90K dataset has a `clip/sequence/img` folder structure:
-
-```text
-mmediting
-├── mmedit
-├── tools
-├── configs
-├── data
-│ ├── vimeo_triplet
-│ │ ├── BDx4
-│ │ │ ├── 00001
-│ │ │ │ ├── 0001
-│ │ │ │ │ ├── im1.png
-│ │ │ │ │ ├── im2.png
-│ │ │ │ │ ├── ...
-│ │ │ │ ├── 0002
-│ │ │ │ ├── 0003
-│ │ │ │ ├── ...
-│ │ │ ├── 00002
-│ │ │ ├── ...
-│ │ ├── BIx4
-│ │ ├── GT
-│ │ ├── meta_info_Vimeo90K_test_GT.txt
-│ │ ├── meta_info_Vimeo90K_train_GT.txt
-```
-
-### Prepare the annotation files for Vimeo90K dataset
-
-To prepare the annotation file for training, you need to download the official training list path for Vimeo90K from the official website, and run the following command:
-
-```shell
-python tools/dataset_converters/super-resolution/vimeo90k/preprocess_vimeo90k_dataset.py ./data/Vimeo90K/official_train_list.txt
-```
-
-The annotation file for test is generated similarly.
-
-### Prepare LMDB dataset for Vimeo90K
-
-If you want to use LMDB datasets for faster IO speed, you can make LMDB files by:
-
-```shell
-python tools/dataset_converters/super-resolution/vimeo90k/preprocess_vimeo90k_dataset.py ./data/Vimeo90K/official_train_list.txt --gt-path ./data/Vimeo90K/GT --lq-path ./data/Vimeo90K/LQ --make-lmdb
-```
diff --git a/docs/en/dataset_zoo/2_inpainting_datasets.md b/docs/en/dataset_zoo/2_inpainting_datasets.md
deleted file mode 100644
index f5dac5abac..0000000000
--- a/docs/en/dataset_zoo/2_inpainting_datasets.md
+++ /dev/null
@@ -1,114 +0,0 @@
-# Inpainting Datasets
-
-It is recommended to symlink the dataset root to `$MMEDITING/data`. If your folder structure is different, you may need to change the corresponding paths in config files.
-
-MMEditing supported inpainting datasets:
-
-- [CelebA-HQ](#celeba-hq-dataset) \[ [Homepage](https://github.com/tkarras/progressive_growing_of_gans#preparing-datasets-for-training) \]
-- [Paris Street View](#paris-street-view-dataset) \[ [Homepage](https://github.com/pathak22/context-encoder/issues/24) \]
-- [Places365](#places365-dataset) \[ [Homepage](http://places2.csail.mit.edu/) \]
-
-As we only need images for inpainting task, further preparation is not necessary and the folder structure can be different from the example. You can utilize the information provided by the original dataset like `Place365` (e.g. `meta`). Also, you can easily scan the data set and list all of the images to a specific `txt` file. Here is an example for the `Places365_val.txt` from Places365 and we will only use the image name information in inpainting.
-
-```
-Places365_val_00000001.jpg 165
-Places365_val_00000002.jpg 358
-Places365_val_00000003.jpg 93
-Places365_val_00000004.jpg 164
-Places365_val_00000005.jpg 289
-Places365_val_00000006.jpg 106
-Places365_val_00000007.jpg 81
-Places365_val_00000008.jpg 121
-Places365_val_00000009.jpg 150
-Places365_val_00000010.jpg 302
-Places365_val_00000011.jpg 42
-```
-
-## CelebA-HQ Dataset
-
-
-
-```bibtex
-@article{karras2017progressive,
- title={Progressive growing of gans for improved quality, stability, and variation},
- author={Karras, Tero and Aila, Timo and Laine, Samuli and Lehtinen, Jaakko},
- journal={arXiv preprint arXiv:1710.10196},
- year={2017}
-}
-```
-
-Follow the instructions [here](https://github.com/tkarras/progressive_growing_of_gans##preparing-datasets-for-training) to prepare the dataset.
-
-```text
-mmediting
-├── mmedit
-├── tools
-├── configs
-├── data
-│ ├── CelebA-HQ
-│ │ ├── train_256
-| | ├── test_256
-| | ├── train_celeba_img_list.txt
-| | ├── val_celeba_img_list.txt
-
-```
-
-## Paris Street View Dataset
-
-
-
-```bibtex
-@inproceedings{pathak2016context,
- title={Context encoders: Feature learning by inpainting},
- author={Pathak, Deepak and Krahenbuhl, Philipp and Donahue, Jeff and Darrell, Trevor and Efros, Alexei A},
- booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition},
- pages={2536--2544},
- year={2016}
-}
-```
-
-Obtain the dataset [here](https://github.com/pathak22/context-encoder/issues/24).
-
-```text
-mmediting
-├── mmedit
-├── tools
-├── configs
-├── data
-│ ├── paris_street_view
-│ │ ├── train
-| | ├── val
-
-```
-
-## Places365 Dataset
-
-
-
-```bibtex
- @article{zhou2017places,
- title={Places: A 10 million Image Database for Scene Recognition},
- author={Zhou, Bolei and Lapedriza, Agata and Khosla, Aditya and Oliva, Aude and Torralba, Antonio},
- journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
- year={2017},
- publisher={IEEE}
- }
-
-```
-
-Prepare the data from [Places365](http://places2.csail.mit.edu/download.html).
-
-```text
-mmediting
-├── mmedit
-├── tools
-├── configs
-├── data
-│ ├── Places
-│ │ ├── data_large
-│ │ ├── val_large
-| | ├── meta
-| | | ├── places365_train_challenge.txt
-| | | ├── places365_val.txt
-
-```
diff --git a/docs/en/dataset_zoo/3_matting_datasets.md b/docs/en/dataset_zoo/3_matting_datasets.md
deleted file mode 100644
index cc9c95f924..0000000000
--- a/docs/en/dataset_zoo/3_matting_datasets.md
+++ /dev/null
@@ -1,147 +0,0 @@
-# Matting Datasets
-
-It is recommended to symlink the dataset root to `$MMEDITING/data`. If your folder structure is different, you may need to change the corresponding paths in config files.
-
-MMEditing supported matting datasets:
-
-- [Composition-1k](#composition-1k-dataset) \[ [Homepage](https://sites.google.com/view/deepimagematting) \]
-
-## Composition-1k Dataset
-
-### Introduction
-
-
-
-```bibtex
-@inproceedings{xu2017deep,
- title={Deep image matting},
- author={Xu, Ning and Price, Brian and Cohen, Scott and Huang, Thomas},
- booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition},
- pages={2970--2979},
- year={2017}
-}
-```
-
-The Adobe Composition-1k dataset consists of foreground images and their corresponding alpha images.
-To get the full dataset, one need to composite the foregrounds with selected backgrounds from the COCO dataset and the Pascal VOC dataset.
-
-### Obtain and Extract
-
-Please follow the instructions of [paper authors](https://sites.google.com/view/deepimagematting) to obtain the Composition-1k (comp1k) dataset.
-
-### Composite the full dataset
-
-The Adobe composition-1k dataset contains only `alpha` and `fg` (and `trimap` in test set).
-It is needed to merge `fg` with COCO data (training) or VOC data (test) before training or evaluation.
-Use the following script to perform image composition and generate annotation files for training or testing:
-
-```shell
-## The script is run under the root folder of MMEditing
-python tools/dataset_converters/matting/comp1k/preprocess_comp1k_dataset.py data/adobe_composition-1k data/coco data/VOCdevkit --composite
-```
-
-The generated data is stored under `adobe_composition-1k/Training_set` and `adobe_composition-1k/Test_set` respectively.
-If you only want to composite test data (since compositing training data is time-consuming), you can skip compositing the training set by removing the `--composite` option:
-
-```shell
-## skip compositing training set
-python tools/dataset_converters/matting/comp1k/preprocess_comp1k_dataset.py data/adobe_composition-1k data/coco data/VOCdevkit
-```
-
-If you only want to preprocess test data, i.e. for FBA, you can skip the train set by adding the `--skip-train` option:
-
-```shell
-## skip preprocessing training set
-python tools/data/matting/comp1k/preprocess_comp1k_dataset.py data/adobe_composition-1k data/coco data/VOCdevkit --skip-train
-```
-
-> Currently, `GCA` and `FBA` support online composition of training data. But you can modify the data pipeline of other models to perform online composition instead of loading composited images (we called it `merged` in our data pipeline).
-
-### Check Directory Structure for DIM
-
-The result folder structure should look like:
-
-```text
-mmediting
-├── mmedit
-├── tools
-├── configs
-├── data
-│ ├── adobe_composition-1k
-│ │ ├── Test_set
-│ │ │ ├── Adobe-licensed images
-│ │ │ │ ├── alpha
-│ │ │ │ ├── fg
-│ │ │ │ ├── trimaps
-│ │ │ ├── merged (generated by tools/dataset_converters/matting/comp1k/preprocess_comp1k_dataset.py)
-│ │ │ ├── bg (generated by tools/dataset_converters/matting/comp1k/preprocess_comp1k_dataset.py)
-│ │ ├── Training_set
-│ │ │ ├── Adobe-licensed images
-│ │ │ │ ├── alpha
-│ │ │ │ ├── fg
-│ │ │ ├── Other
-│ │ │ │ ├── alpha
-│ │ │ │ ├── fg
-│ │ │ ├── merged (generated by tools/dataset_converters/matting/comp1k/preprocess_comp1k_dataset.py)
-│ │ │ ├── bg (generated by tools/dataset_converters/matting/comp1k/preprocess_comp1k_dataset.py)
-│ │ ├── test_list.json (generated by tools/dataset_converters/matting/comp1k/preprocess_comp1k_dataset.py)
-│ │ ├── training_list.json (generated by tools/dataset_converters/matting/comp1k/preprocess_comp1k_dataset.py)
-│ ├── coco
-│ │ ├── train2014 (or train2017)
-│ ├── VOCdevkit
-│ │ ├── VOC2012
-```
-
-### Prepare the dataset for FBA
-
-FBA adopts dynamic dataset augmentation proposed in [Learning-base Sampling for Natural Image Matting](https://openaccess.thecvf.com/content_CVPR_2019/papers/Tang_Learning-Based_Sampling_for_Natural_Image_Matting_CVPR_2019_paper.pdf).
-In addition, to reduce artifacts during augmentation, it uses the extended version of foreground as foreground.
-We provide scripts to estimate foregrounds.
-
-Prepare the test set as follows:
-
-```shell
-## skip preprocessing training set, as it composites online during training
-python tools/dataset_converters/matting/comp1k/preprocess_comp1k_dataset.py data/adobe_composition-1k data/coco data/VOCdevkit --skip-train
-```
-
-Extend the foreground of training set as follows:
-
-```shell
-python tools/dataset_converters/matting/comp1k/extend_fg.py data/adobe_composition-1k
-```
-
-### Check Directory Structure for DIM
-
-The final folder structure should look like:
-
-```text
-mmediting
-├── mmedit
-├── tools
-├── configs
-├── data
-│ ├── adobe_composition-1k
-│ │ ├── Test_set
-│ │ │ ├── Adobe-licensed images
-│ │ │ │ ├── alpha
-│ │ │ │ ├── fg
-│ │ │ │ ├── trimaps
-│ │ │ ├── merged (generated by tools/data/matting/comp1k/preprocess_comp1k_dataset.py)
-│ │ │ ├── bg (generated by tools/data/matting/comp1k/preprocess_comp1k_dataset.py)
-│ │ ├── Training_set
-│ │ │ ├── Adobe-licensed images
-│ │ │ │ ├── alpha
-│ │ │ │ ├── fg
-│ │ │ │ ├── fg_extended (generated by tools/data/matting/comp1k/extend_fg.py)
-│ │ │ ├── Other
-│ │ │ │ ├── alpha
-│ │ │ │ ├── fg
-│ │ │ │ ├── fg_extended (generated by tools/data/matting/comp1k/extend_fg.py)
-│ │ ├── test_list.json (generated by tools/data/matting/comp1k/preprocess_comp1k_dataset.py)
-│ │ ├── training_list_fba.json (generated by tools/data/matting/comp1k/extend_fg.py)
-│ ├── coco
-│ │ ├── train2014 (or train2017)
-│ ├── VOCdevkit
-│ │ ├── VOC2012
-```
diff --git a/docs/en/dataset_zoo/4_video_interpolation_datasets.md b/docs/en/dataset_zoo/4_video_interpolation_datasets.md
deleted file mode 100644
index 9889939c91..0000000000
--- a/docs/en/dataset_zoo/4_video_interpolation_datasets.md
+++ /dev/null
@@ -1,50 +0,0 @@
-# Video Frame Interpolation Datasets
-
-It is recommended to symlink the dataset root to `$MMEDITING/data`. If your folder structure is different, you may need to change the corresponding paths in config files.
-
-MMEditing supported video frame interpolation datasets:
-
-- [Vimeo90K-triplet](#vimeo90k-triplet-dataset) \[ [Homepage](http://toflow.csail.mit.edu) \]
-
-## Vimeo90K-triplet Dataset
-
-
-
-```bibtex
-@article{xue2019video,
- title={Video Enhancement with Task-Oriented Flow},
- author={Xue, Tianfan and Chen, Baian and Wu, Jiajun and Wei, Donglai and Freeman, William T},
- journal={International Journal of Computer Vision (IJCV)},
- volume={127},
- number={8},
- pages={1106--1125},
- year={2019},
- publisher={Springer}
-}
-```
-
-The training and test datasets can be download from [here](http://toflow.csail.mit.edu/).
-
-The Vimeo90K-triplet dataset has a `clip/sequence/img` folder structure:
-
-```text
-mmediting
-├── mmedit
-├── tools
-├── configs
-├── data
-│ ├── vimeo_triplet
-│ │ ├── tri_testlist.txt
-│ │ ├── tri_trainlist.txt
-│ │ ├── sequences
-│ │ │ ├── 00001
-│ │ │ │ ├── 0001
-│ │ │ │ │ ├── im1.png
-│ │ │ │ │ ├── im2.png
-│ │ │ │ │ └── im3.png
-│ │ │ │ ├── 0002
-│ │ │ │ ├── 0003
-│ │ │ │ ├── ...
-│ │ │ ├── 00002
-│ │ │ ├── ...
-```
diff --git a/docs/en/dataset_zoo/5_unconditional_gans_datasets.md b/docs/en/dataset_zoo/5_unconditional_gans_datasets.md
deleted file mode 100644
index a0f4d67164..0000000000
--- a/docs/en/dataset_zoo/5_unconditional_gans_datasets.md
+++ /dev/null
@@ -1,91 +0,0 @@
-# Unconditional GANs Datasets
-
-**Data preparation for unconditional model** is simple. What you need to do is downloading the images and put them into a directory. Next, you should set a symlink in the `data` directory. For standard unconditional gans with static architectures, like DCGAN and StyleGAN2, `UnconditionalImageDataset` is designed to train such unconditional models. Here is an example config for FFHQ dataset:
-
-```python
-dataset_type = 'BasicImageDataset'
-
-train_pipeline = [
- dict(type='LoadImageFromFile', key='img'),
- dict(type='Flip', keys=['img'], direction='horizontal'),
- dict(type='PackGenInputs', keys=['img'], meta_keys=['img_path'])
-]
-
-# `batch_size` and `data_root` need to be set.
-train_dataloader = dict(
- batch_size=4,
- num_workers=8,
- persistent_workers=True,
- sampler=dict(type='InfiniteSampler', shuffle=True),
- dataset=dict(
- type=dataset_type,
- data_root=None, # set by user
- pipeline=train_pipeline))
-```
-
-Here, we adopt `InfinitySampler` to avoid frequent dataloader reloading, which will accelerate the training procedure. As shown in the example, `pipeline` provides important data pipeline to process images, including loading from file system, resizing, cropping, transferring to `torch.Tensor` and packing to `GenDataSample`. All of supported data pipelines can be found in `mmedit/datasets/transforms`.
-
-For unconditional GANs with dynamic architectures like PGGAN and StyleGANv1, `GrowScaleImgDataset` is recommended to use for training. Since such dynamic architectures need real images in different scales, directly adopting `UnconditionalImageDataset` will bring heavy I/O cost for loading multiple high-resolution images. Here is an example we use for training PGGAN in CelebA-HQ dataset:
-
-```python
-dataset_type = 'GrowScaleImgDataset'
-
-pipeline = [
- dict(type='LoadImageFromFile', key='img'),
- dict(type='Flip', keys=['img'], direction='horizontal'),
- dict(type='PackGenInputs')
-]
-
-# `samples_per_gpu` and `imgs_root` need to be set.
-train_dataloader = dict(
- num_workers=4,
- batch_size=64,
- dataset=dict(
- type='GrowScaleImgDataset',
- data_roots={
- '1024': './data/ffhq/images',
- '256': './data/ffhq/ffhq_imgs/ffhq_256',
- '64': './data/ffhq/ffhq_imgs/ffhq_64'
- },
- gpu_samples_base=4,
- # note that this should be changed with total gpu number
- gpu_samples_per_scale={
- '4': 64,
- '8': 32,
- '16': 16,
- '32': 8,
- '64': 4,
- '128': 4,
- '256': 4,
- '512': 4,
- '1024': 4
- },
- len_per_stage=300000,
- pipeline=pipeline),
- sampler=dict(type='InfiniteSampler', shuffle=True))
-```
-
-In this dataset, you should provide a dictionary of image paths to the `data_roots`. Thus, you should resize the images in the dataset in advance.
-For the resizing methods in the data pre-processing, we adopt bilinear interpolation methods in all of the experiments studied in MMEditing.
-
-Note that this dataset should be used with `PGGANFetchDataHook`. In this config file, this hook should be added in the customized hooks, as shown below.
-
-```python
-custom_hooks = [
- dict(
- type='GenVisualizationHook',
- interval=5000,
- fixed_input=True,
- # vis ema and orig at the same time
- vis_kwargs_list=dict(
- type='Noise',
- name='fake_img',
- sample_model='ema/orig',
- target_keys=['ema', 'orig'])),
- dict(type='PGGANFetchDataHook')
-]
-```
-
-This fetching data hook helps the dataloader update the status of dataset to change the data source and batch size during training.
-
-Here, we provide several download links of datasets frequently used in unconditional models: [LSUN](http://dl.yf.io/lsun/), [CelebA](http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html), [CelebA-HQ](https://drive.google.com/drive/folders/11Vz0fqHS2rXDb5pprgTjpD7S2BAJhi1P), [FFHQ](https://drive.google.com/drive/folders/1u2xu7bSrWxrbUxk-dT-UvEJq8IjdmNTP).
diff --git a/docs/en/dataset_zoo/6_image_translation_datasets.md b/docs/en/dataset_zoo/6_image_translation_datasets.md
deleted file mode 100644
index 85cec47c16..0000000000
--- a/docs/en/dataset_zoo/6_image_translation_datasets.md
+++ /dev/null
@@ -1,149 +0,0 @@
-# Image Translation Datasets
-
-**Data preparation for translation model** needs a little attention. You should organize the files in the way we told you in `quick_run.md`. Fortunately, for most official datasets like facades and summer2winter_yosemite, they already have the right format. Also, you should set a symlink in the `data` directory. For paired-data trained translation model like Pix2Pix , `PairedImageDataset` is designed to train such translation models. Here is an example config for facades dataset:
-
-```python
-train_dataset_type = 'PairedImageDataset'
-val_dataset_type = 'PairedImageDataset'
-img_norm_cfg = dict(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
-train_pipeline = [
- dict(
- type='LoadPairedImageFromFile',
- io_backend='disk',
- key='pair',
- domain_a=domain_a,
- domain_b=domain_b,
- flag='color'),
- dict(
- type='Resize',
- keys=[f'img_{domain_a}', f'img_{domain_b}'],
- scale=(286, 286),
- interpolation='bicubic')
-]
-test_pipeline = [
- dict(
- type='LoadPairedImageFromFile',
- io_backend='disk',
- key='image',
- domain_a=domain_a,
- domain_b=domain_b,
- flag='color'),
- dict(
- type='Resize',
- keys=[f'img_{domain_a}', f'img_{domain_b}'],
- scale=(256, 256),
- interpolation='bicubic')
-]
-dataroot = 'data/paired/facades'
-train_dataloader = dict(
- batch_size=1,
- num_workers=4,
- persistent_workers=True,
- sampler=dict(type='InfiniteSampler', shuffle=True),
- dataset=dict(
- type=dataset_type,
- data_root=dataroot, # set by user
- pipeline=train_pipeline))
-
-val_dataloader = dict(
- batch_size=1,
- num_workers=4,
- dataset=dict(
- type=dataset_type,
- data_root=dataroot, # set by user
- pipeline=test_pipeline),
- sampler=dict(type='DefaultSampler', shuffle=False),
- persistent_workers=True)
-
-test_dataloader = dict(
- batch_size=1,
- num_workers=4,
- dataset=dict(
- type=dataset_type,
- data_root=dataroot, # set by user
- pipeline=test_pipeline),
- sampler=dict(type='DefaultSampler', shuffle=False),
- persistent_workers=True)
-```
-
-Here, we adopt `LoadPairedImageFromFile` to load a paired image as the common loader does and crops
-it into two images with the same shape in different domains. As shown in the example, `pipeline` provides important data pipeline to process images, including loading from file system, resizing, cropping, flipping, transferring to `torch.Tensor` and packing to `GenDataSample`. All of supported data pipelines can be found in `mmedit/datasets/transforms`.
-
-For unpaired-data trained translation model like CycleGAN , `UnpairedImageDataset` is designed to train such translation models. Here is an example config for horse2zebra dataset:
-
-```python
-train_dataset_type = 'UnpairedImageDataset'
-val_dataset_type = 'UnpairedImageDataset'
-img_norm_cfg = dict(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
-domain_a, domain_b = 'horse', 'zebra'
-train_pipeline = [
- dict(
- type='LoadImageFromFile',
- io_backend='disk',
- key=f'img_{domain_a}',
- flag='color'),
- dict(
- type='LoadImageFromFile',
- io_backend='disk',
- key=f'img_{domain_b}',
- flag='color'),
- dict(
- type='TransformBroadcaster',
- mapping={'img': [f'img_{domain_a}', f'img_{domain_b}']},
- auto_remap=True,
- share_random_params=True,
- transforms=[
- dict(type='Resize', scale=(286, 286), interpolation='bicubic'),
- dict(type='Crop', crop_size=(256, 256), random_crop=True),
- ]),
- dict(type='Flip', keys=[f'img_{domain_a}'], direction='horizontal'),
- dict(type='Flip', keys=[f'img_{domain_b}'], direction='horizontal'),
- dict(
- type='PackGenInputs',
- keys=[f'img_{domain_a}', f'img_{domain_b}'],
- meta_keys=[f'img_{domain_a}_path', f'img_{domain_b}_path'])
-]
-test_pipeline = [
- dict(type='LoadImageFromFile', io_backend='disk', key='img', flag='color'),
- dict(type='Resize', scale=(256, 256), interpolation='bicubic'),
- dict(
- type='PackGenInputs',
- keys=[f'img_{domain_a}', f'img_{domain_b}'],
- meta_keys=[f'img_{domain_a}_path', f'img_{domain_b}_path'])
-]
-data_root = './data/horse2zebra/'
-# `batch_size` and `data_root` need to be set.
-train_dataloader = dict(
- batch_size=1,
- num_workers=4,
- persistent_workers=True,
- sampler=dict(type='InfiniteSampler', shuffle=True),
- dataset=dict(
- type=dataset_type,
- data_root=data_root, # set by user
- pipeline=train_pipeline))
-
-val_dataloader = dict(
- batch_size=None,
- num_workers=4,
- dataset=dict(
- type=dataset_type,
- data_root=data_root, # set by user
- pipeline=test_pipeline),
- sampler=dict(type='DefaultSampler', shuffle=False),
- persistent_workers=True)
-
-test_dataloader = dict(
- batch_size=None,
- num_workers=4,
- dataset=dict(
- type=dataset_type,
- data_root=data_root, # set by user
- pipeline=test_pipeline),
- sampler=dict(type='DefaultSampler', shuffle=False),
- persistent_workers=True)
-```
-
-`UnpairedImageDataset` will load both images (domain A and B) from different paths and transform them at the same time.
-
-Here, we provide download links of datasets used in [Pix2Pix](http://efrosgans.eecs.berkeley.edu/pix2pix/datasets/) and [CycleGAN](https://people.eecs.berkeley.edu/~taesung_park/CycleGAN/datasets/).
diff --git a/docs/en/notes/4_faq.md b/docs/en/faq.md
similarity index 91%
rename from docs/en/notes/4_faq.md
rename to docs/en/faq.md
index 4edec727c2..7205a47449 100644
--- a/docs/en/notes/4_faq.md
+++ b/docs/en/faq.md
@@ -1,4 +1,4 @@
-# Frequently Asked Questions
+# Frequently asked questions
We list some common troubles faced by many users and their corresponding
solutions here. Feel free to enrich the list if you find any frequent issues
@@ -15,11 +15,11 @@ and make sure you fill in all required information in the template.
**Q2**: What's the folder structure of xxx dataset?
-**A2**: You can make sure the folder structure is correct following tutorials of [dataset preparation](../user_guides/2_dataset_prepare.md).
+**A2**: You can make sure the folder structure is correct following tutorials of [dataset preparation](user_guides/dataset_prepare.md).
**Q3**: How to use LMDB data to train the model?
-**A3**: You can use scripts in `tools/data` to make LMDB files. More details are shown in tutorials of [dataset preparation](../user_guides/2_dataset_prepare.md).
+**A3**: You can use scripts in `tools/data` to make LMDB files. More details are shown in tutorials of [dataset preparation](user_guides/dataset_prepare.md).
**Q4**: Why `MMCV==xxx is used but incompatible` is raised when import I try to import `mmgen`?
diff --git a/docs/en/2_get_started.md b/docs/en/get_started/install.md
similarity index 75%
rename from docs/en/2_get_started.md
rename to docs/en/get_started/install.md
index 3c7edcc92e..78fc8d1be3 100644
--- a/docs/en/2_get_started.md
+++ b/docs/en/get_started/install.md
@@ -1,4 +1,4 @@
-# Get Started: Install and Run MMEditing
+# Installation
In this section, you will know about:
@@ -7,7 +7,6 @@ In this section, you will know about:
- [Best practices](#best-practices)
- [Customize installation](#customize-installation)
- [Developing with multiple MMEditing versions](#developing-with-multiple-mmediting-versions)
-- [Quick run](#quick-run)
## Installation
@@ -156,7 +155,7 @@ docker run --gpus all --shm-size=8g -it -v {DATA_DIR}:/mmediting/data mmediting
#### Trouble shooting
-If you have some issues during the installation, please first view the [FAQ](notes/4_faq.md) page.
+If you have some issues during the installation, please first view the [FAQ](../faq.md) page.
You may [open an issue](https://github.com/open-mmlab/mmediting/issues/new/choose) on GitHub if no solution is found.
### Developing with multiple MMEditing versions
@@ -168,52 +167,3 @@ To use the default MMEditing installed in the environment rather than that you a
```shell
PYTHONPATH="$(dirname $0)/..":$PYTHONPATH
```
-
-## Quick run
-
-After installing MMEditing successfully, now you are able to play with MMEditing!
-
-To synthesize an image of a church, you only need several lines of codes by MMEditing!
-
-```python
-from mmedit.apis import init_model, sample_unconditional_model
-
-config_file = 'configs/styleganv2/stylegan2_c2_8xb4-800kiters_lsun-church-256x256.py'
-# you can download this checkpoint in advance and use a local file path.
-checkpoint_file = 'https://download.openmmlab.com/mmgen/stylegan2/official_weights/stylegan2-church-config-f-official_20210327_172657-1d42b7d1.pth'
-device = 'cuda:0'
-# init a generative model
-model = init_model(config_file, checkpoint_file, device=device)
-# sample images
-fake_imgs = sample_unconditional_model(model, 4)
-```
-
-Or you can just run the following command.
-
-```bash
-python demo/unconditional_demo.py \
-configs/styleganv2/stylegan2_c2_lsun-church_256_b4x8_800k.py \
-https://download.openmmlab.com/mmgen/stylegan2/official_weights/stylegan2-church-config-f-official_20210327_172657-1d42b7d1.pth
-
-```
-
-You will see a new image `unconditional_samples.png` in folder `work_dirs/demos/`, which contained generated samples.
-
-What's more, if you want to make these photos much more clear,
-you only need several lines of codes for image super-resolution by MMEditing!
-
-```python
-import mmcv
-from mmedit.apis import init_model, restoration_inference
-from mmedit.engine.misc import tensor2img
-
-config = 'configs/esrgan/esrgan_x4c64b23g32_1xb16-400k_div2k.py'
-checkpoint = 'https://download.openmmlab.com/mmediting/restorers/esrgan/esrgan_x4c64b23g32_1x16_400k_div2k_20200508-f8ccaf3b.pth'
-img_path = 'tests/data/image/lq/baboon_x4.png'
-model = init_model(config, checkpoint)
-output = restoration_inference(model, img_path)
-output = tensor2img(output)
-mmcv.imwrite(output, 'output.png')
-```
-
-Now, you can check your fancy photos in `output.png`.
diff --git a/docs/en/1_overview.md b/docs/en/get_started/overview.md
similarity index 92%
rename from docs/en/1_overview.md
rename to docs/en/get_started/overview.md
index b1c7f51472..62af697b74 100644
--- a/docs/en/1_overview.md
+++ b/docs/en/get_started/overview.md
@@ -78,7 +78,7 @@ MMEditing supports various applications, including:
- **New Modular Design for Flexible Combination:**
- We decompose the editing framework into different modules and one can easily construct a customized editor framework by combining different modules. Specifically, a new design for complex loss modules is proposed for customizing the links between modules, which can achieve flexible combinations among different modules.(Tutorial for [losses](advanced_guides/4_losses.md))
+ We decompose the editing framework into different modules and one can easily construct a customized editor framework by combining different modules. Specifically, a new design for complex loss modules is proposed for customizing the links between modules, which can achieve flexible combinations among different modules.(Tutorial for [losses](../howto/losses.md))
- **Efficient Distributed Training:**
@@ -86,12 +86,16 @@ MMEditing supports various applications, including:
## Get started
-For installation instructions, please see [get_started](2_get_started.md).
+For installation instructions, please see [Installation](install.md).
## User guides
-For beginners, we suggest learning the basic usage of MMEditing from [user_guides](user_guides/1_config.md).
+For beginners, we suggest learning the basic usage of MMEditing from [user_guides](../user_guides/config.md).
### Advanced guides
-For users who are familiar with MMEditing, you may want to learn the design of MMEditing, as well as how to extend the repo, how to use multiple repos and other advanced usages, please refer to [advanced_guides](advanced_guides/1_models.md).
+For users who are familiar with MMEditing, you may want to learn the design of MMEditing, as well as how to extend the repo, how to use multiple repos and other advanced usages, please refer to [advanced_guides](../advanced_guides/evaluator.md).
+
+### How to
+
+For users who want to use MMEditing to do something, please refer to [How to](../howto/models.md).
diff --git a/docs/en/get_started/quick_run.md b/docs/en/get_started/quick_run.md
new file mode 100644
index 0000000000..b243e5263a
--- /dev/null
+++ b/docs/en/get_started/quick_run.md
@@ -0,0 +1,48 @@
+# Quick run
+
+After installing MMEditing successfully, now you are able to play with MMEditing!
+
+To synthesize an image of a church, you only need several lines of codes by MMEditing!
+
+```python
+from mmedit.apis import init_model, sample_unconditional_model
+
+config_file = 'configs/styleganv2/stylegan2_c2_8xb4-800kiters_lsun-church-256x256.py'
+# you can download this checkpoint in advance and use a local file path.
+checkpoint_file = 'https://download.openmmlab.com/mmediting/stylegan2/official_weights/stylegan2-church-config-f-official_20210327_172657-1d42b7d1.pth'
+device = 'cuda:0'
+# init a generative model
+model = init_model(config_file, checkpoint_file, device=device)
+# sample images
+fake_imgs = sample_unconditional_model(model, 4)
+```
+
+Or you can just run the following command.
+
+```bash
+python demo/unconditional_demo.py \
+configs/styleganv2/stylegan2_c2_lsun-church_256_b4x8_800k.py \
+https://download.openmmlab.com/mmediting/stylegan2/official_weights/stylegan2-church-config-f-official_20210327_172657-1d42b7d1.pth
+
+```
+
+You will see a new image `unconditional_samples.png` in folder `work_dirs/demos/`, which contained generated samples.
+
+What's more, if you want to make these photos much more clear,
+you only need several lines of codes for image super-resolution by MMEditing!
+
+```python
+import mmcv
+from mmedit.apis import init_model, restoration_inference
+from mmedit.engine.misc import tensor2img
+
+config = 'configs/esrgan/esrgan_x4c64b23g32_1xb16-400k_div2k.py'
+checkpoint = 'https://download.openmmlab.com/mmediting/restorers/esrgan/esrgan_x4c64b23g32_1x16_400k_div2k_20200508-f8ccaf3b.pth'
+img_path = 'tests/data/image/lq/baboon_x4.png'
+model = init_model(config, checkpoint)
+output = restoration_inference(model, img_path)
+output = tensor2img(output)
+mmcv.imwrite(output, 'output.png')
+```
+
+Now, you can check your fancy photos in `output.png`.
diff --git a/docs/en/advanced_guides/2_dataset.md b/docs/en/howto/dataset.md
similarity index 79%
rename from docs/en/advanced_guides/2_dataset.md
rename to docs/en/howto/dataset.md
index ab0c380ee5..11086661fe 100644
--- a/docs/en/advanced_guides/2_dataset.md
+++ b/docs/en/howto/dataset.md
@@ -1,4 +1,4 @@
-# Prepare Your Own Datasets
+# How to prepare your own datasets
In this document, we will introduce the design of each datasets in MMEditing and how users can design their own dataset.
@@ -198,6 +198,144 @@ dataset = BasicFramesDataset(
img=['img1.png', 'img3.png'], gt=['img2.png']))
```
+### BasicConditonalDataset
+
+**BasicConditonalDataset** `mmedit.datasets.BasicConditonalDataset` is designed for conditional GANs (e.g., SAGAN, BigGAN). This dataset support load label for the annotation file. `BasicConditonalDataset` support three kinds of annotation as follow:
+
+#### 1. Annotation file read by line (e.g., txt)
+
+Sample files structure:
+
+```
+ data_prefix/
+ ├── folder_1
+ │ ├── xxx.png
+ │ ├── xxy.png
+ │ └── ...
+ └── folder_2
+ ├── 123.png
+ ├── nsdf3.png
+ └── ...
+```
+
+Sample annotation file (the first column is the image path and the second column is the index of category):
+
+```
+ folder_1/xxx.png 0
+ folder_1/xxy.png 1
+ folder_2/123.png 5
+ folder_2/nsdf3.png 3
+ ...
+```
+
+Config example for ImageNet dataset:
+
+```python
+dataset=dict(
+ type='BasicConditionalDataset,
+ data_root='./data/imagenet/',
+ ann_file='meta/train.txt',
+ data_prefix='train',
+ pipeline=train_pipeline),
+```
+
+#### 2. Dict-based annotation file (e.g., json):
+
+Sample files structure:
+
+```
+ data_prefix/
+ ├── folder_1
+ │ ├── xxx.png
+ │ ├── xxy.png
+ │ └── ...
+ └── folder_2
+ ├── 123.png
+ ├── nsdf3.png
+ └── ...
+```
+
+Sample annotation file (the key is the image path and the value column
+is the label):
+
+```
+ {
+ "folder_1/xxx.png": [1, 2, 3, 4],
+ "folder_1/xxy.png": [2, 4, 1, 0],
+ "folder_2/123.png": [0, 9, 8, 1],
+ "folder_2/nsdf3.png", [1, 0, 0, 2],
+ ...
+ }
+```
+
+Config example for EG3D (shapenet-car) dataset:
+
+```python
+dataset = dict(
+ type='BasicConditionalDataset',
+ data_root='./data/eg3d/shapenet-car',
+ ann_file='annotation.json',
+ pipeline=train_pipeline)
+```
+
+In this kind of annotation, labels can be any type and not restricted to an index.
+
+#### 3. Folder-based annotation (no annotation file need):
+
+Sample files structure:
+
+```
+ data_prefix/
+ ├── class_x
+ │ ├── xxx.png
+ │ ├── xxy.png
+ │ └── ...
+ │ └── xxz.png
+ └── class_y
+ ├── 123.png
+ ├── nsdf3.png
+ ├── ...
+ └── asd932_.png
+```
+
+If the annotation file is specified, the dataset will be generated by the first two ways, otherwise, try the third way.
+
+### ImageNet Dataset and CIFAR10 Dataset
+
+**ImageNet Dataset**`mmedit.datasets.ImageNet` and **CIFAR10 Dataset**`mmedit.datasets.CIFAR10` are datasets specific designed for ImageNet and CIFAR10 datasets. Both two datasets are encapsulation of `BasicConditionalDataset`. You can used them to load data from ImageNet dataset and CIFAR10 dataset easily.
+
+Config example for ImageNet:
+
+```python
+pipeline = [
+ dict(type='LoadImageFromFile', key='img'),
+ dict(type='RandomCropLongEdge', keys=['img']),
+ dict(type='Resize', scale=(128, 128), keys=['img'], backend='pillow'),
+ dict(type='Flip', keys=['img'], flip_ratio=0.5, direction='horizontal'),
+ dict(type='PackEditInputs')
+]
+
+dataset=dict(
+ type='ImageNet',
+ data_root='./data/imagenet/',
+ ann_file='meta/train.txt',
+ data_prefix='train',
+ pipeline=pipeline),
+```
+
+Config example for CIFAR10:
+
+```python
+pipeline = [dict(type='PackEditInputs')]
+
+dataset = dict(
+ type='CIFAR10',
+ data_root='./data',
+ data_prefix='cifar10',
+ test_mode=False,
+ pipeline=pipeline)
+```
+
### AdobeComp1kDataset
**AdobeComp1kDataset** `mmedit.datasets.AdobeComp1kDataset`
diff --git a/docs/en/advanced_guides/4_losses.md b/docs/en/howto/losses.md
similarity index 99%
rename from docs/en/advanced_guides/4_losses.md
rename to docs/en/howto/losses.md
index 22ea7a2590..3485a02ed9 100644
--- a/docs/en/advanced_guides/4_losses.md
+++ b/docs/en/howto/losses.md
@@ -1,4 +1,4 @@
-# Design Your Own Loss Functions
+# How to design your own loss functions
`losses` are registered as `LOSSES` in `MMEditing`.
Customizing losses is similar to customizing any other model.
diff --git a/docs/en/advanced_guides/1_models.md b/docs/en/howto/models.md
similarity index 99%
rename from docs/en/advanced_guides/1_models.md
rename to docs/en/howto/models.md
index 0d5e9cefdb..d7e93eb4e5 100644
--- a/docs/en/advanced_guides/1_models.md
+++ b/docs/en/howto/models.md
@@ -1,4 +1,4 @@
-# Design Your Own Models
+# How to design your own models
MMEditing is built upon MMEngine and MMCV, which enables users to design new models quickly, train and evaluate them easily.
In this section, you will learn how to design your own models.
@@ -406,7 +406,7 @@ After implementing the network architecture and the forward loop of SRCNN,
now we can create a new file `configs/srcnn/srcnn_x4k915_g1_1000k_div2k.py`
to set the configurations needed by training SRCNN.
-In the configuration file, we need to specify the parameters of our model, `class BaseEditModel`, including the generator network architecture, loss function, additional training and testing configuration, and data preprocessor of input tensors. Please refer to the [Introduction to the loss in MMEditing](./4_losses.md) for more details of losses in MMEditing.
+In the configuration file, we need to specify the parameters of our model, `class BaseEditModel`, including the generator network architecture, loss function, additional training and testing configuration, and data preprocessor of input tensors. Please refer to the [Introduction to the loss in MMEditing](./losses.md) for more details of losses in MMEditing.
```python
# model settings
@@ -425,7 +425,7 @@ model = dict(
))
```
-We also need to specify the training dataloader and testing dataloader according to [create your own dataloader](../dataset_zoo/0_overview.md).
+We also need to specify the training dataloader and testing dataloader according to create your own dataloader.
Finally we can start training our own model by:
```python
@@ -733,7 +733,7 @@ model = dict(
out_channels=1))
```
-We also need to specify the training dataloader and testing dataloader according to [create your own dataloader](2_dataset.md).
+We also need to specify the training dataloader and testing dataloader according to [create your own dataloader](dataset.md).
Finally we can start training our own model by:
```python
diff --git a/docs/en/advanced_guides/3_transforms.md b/docs/en/howto/transforms.md
similarity index 99%
rename from docs/en/advanced_guides/3_transforms.md
rename to docs/en/howto/transforms.md
index 565a3499ab..46719f58c9 100644
--- a/docs/en/advanced_guides/3_transforms.md
+++ b/docs/en/howto/transforms.md
@@ -1,4 +1,4 @@
-# Design Your Own Data Pipelines
+# How to design your own data transforms
In this tutorial, we introduce the design of transforms pipeline in MMEditing.
diff --git a/docs/en/index.rst b/docs/en/index.rst
index e60fbaefc0..73cc96cb0b 100644
--- a/docs/en/index.rst
+++ b/docs/en/index.rst
@@ -34,108 +34,128 @@ Codes are available on `GitHub + 未找到你要打开的页面。 +
++ 如果你是从旧版本文档跳转至此,可能是对应的页面被移动了。请从左侧的目录中寻找新版本文档,或者跳转至首页。 +
++ 如果你找不到希望打开的文档,欢迎在 Issue 中告诉我们! +
+ +{% endblock %} diff --git a/docs/zh_cn/advanced_guides/data_flow.md b/docs/zh_cn/advanced_guides/data_flow.md new file mode 100644 index 0000000000..ccc734f77f --- /dev/null +++ b/docs/zh_cn/advanced_guides/data_flow.md @@ -0,0 +1 @@ +# 数据流(待更新) diff --git a/docs/zh_cn/advanced_guides/data_preprocessor.md b/docs/zh_cn/advanced_guides/data_preprocessor.md new file mode 100644 index 0000000000..b944a828f3 --- /dev/null +++ b/docs/zh_cn/advanced_guides/data_preprocessor.md @@ -0,0 +1 @@ +# 数据预处理器(待更新) diff --git a/docs/zh_cn/advanced_guides/evaluator.md b/docs/zh_cn/advanced_guides/evaluator.md new file mode 100644 index 0000000000..87a5701991 --- /dev/null +++ b/docs/zh_cn/advanced_guides/evaluator.md @@ -0,0 +1 @@ +# 评估器(待更新) diff --git a/docs/zh_cn/advanced_guides/index.rst b/docs/zh_cn/advanced_guides/index.rst deleted file mode 100644 index dab3050979..0000000000 --- a/docs/zh_cn/advanced_guides/index.rst +++ /dev/null @@ -1,7 +0,0 @@ -.. toctree:: - :maxdepth: 2 - - models/customize_models.md - dataset.md - transforms.md - losses.md diff --git a/docs/zh_cn/advanced_guides/losses.md b/docs/zh_cn/advanced_guides/losses.md deleted file mode 100644 index 260855c734..0000000000 --- a/docs/zh_cn/advanced_guides/losses.md +++ /dev/null @@ -1 +0,0 @@ -# 自定义损失函数(待更新) diff --git a/docs/zh_cn/advanced_guides/structures.md b/docs/zh_cn/advanced_guides/structures.md new file mode 100644 index 0000000000..c2118c34a3 --- /dev/null +++ b/docs/zh_cn/advanced_guides/structures.md @@ -0,0 +1 @@ +# 数据结构(待更新) diff --git a/docs/zh_cn/api.rst b/docs/zh_cn/api.rst deleted file mode 100644 index 8fe6a7c0c6..0000000000 --- a/docs/zh_cn/api.rst +++ /dev/null @@ -1,99 +0,0 @@ -mmedit.apis ---------------- -.. automodule:: mmedit.apis - :members: - - -mmedit.datasets -------------------------- - -datasets -^^^^^^^^^^ -.. automodule:: mmedit.datasets - :members: - -transforms -^^^^^^^^^^ -.. automodule:: mmedit.datasets.transforms - :members: - - -mmedit.engine --------------- - -hooks -^^^^^^^^^^ -.. automodule:: mmedit.engine.hooks - :members: - -optimizers -^^^^^^^^^^ -.. automodule:: mmedit.engine.optimizers - :members: - -schedulers -^^^^^^^^^^ -.. automodule:: mmedit.engine.schedulers - :members: - - -mmedit.evaluation ------------------- - -metrics -^^^^^^^^^^ -.. automodule:: mmedit.evaluation.metrics - :members: - - -functional -^^^^^^^^^^ -.. automodule:: mmedit.evaluation.functional - :members: - - -mmedit.models --------------- - -base_models -^^^^^^^ -.. automodule:: mmedit.models.base_models - :members: - -data_preprocessors -^^^^^^^ -.. automodule:: mmedit.models.data_preprocessors - :members: - -layers -^^^^^^^^^^^^ -.. automodule:: mmedit.models.layers - :members: - -losses -^^^^^^^^^^^^ -.. automodule:: mmedit.models.losses - :members: - -utils -^^^^^^^^^^^^ -.. automodule:: mmedit.models.utils - :members: - -editors -^^^^^^^^^^^^ -.. automodule:: mmedit.models.editors - :members: - - -mmedit.visualization --------------------- - -.. automodule:: mmedit.visualization - :members: - -mmedit.utils --------------------- - -.. automodule:: mmedit.utils - :members: diff --git a/docs/zh_cn/notes/changelog.md b/docs/zh_cn/changelog.md similarity index 100% rename from docs/zh_cn/notes/changelog.md rename to docs/zh_cn/changelog.md diff --git a/docs/zh_cn/community/contributing.md b/docs/zh_cn/community/contributing.md new file mode 100644 index 0000000000..028e00a4a9 --- /dev/null +++ b/docs/zh_cn/community/contributing.md @@ -0,0 +1,875 @@ +# 贡献代码 + +欢迎加入 MMEditing 社区,我们致力于打造最前沿的计算机视觉基础库,我们欢迎任何类型的贡献,包括但不限于 + +**修复错误** + +修复代码实现错误的步骤如下: + +1. 如果提交的代码改动较大,建议先提交 issue,并正确描述 issue 的现象、原因和复现方式,讨论后确认修复方案。 +2. 修复错误并补充相应的单元测试,提交拉取请求。 + +**新增功能或组件** + +1. 如果新功能或模块涉及较大的代码改动,建议先提交 issue,确认功能的必要性。 +2. 实现新增功能并添单元测试,提交拉取请求。 + +**文档补充** + +修复文档可以直接提交拉取请求 + +添加文档或将文档翻译成其他语言步骤如下 + +1. 提交 issue,确认添加文档的必要性。 +2. 添加文档,提交拉取请求。 + +### 拉取请求工作流 + +如果你对拉取请求不了解,没关系,接下来的内容将会从零开始,一步一步地指引你如何创建一个拉取请求。如果你想深入了解拉取请求的开发模式,可以参考 github [官方文档](https://docs.github.com/en/github/collaborating-with-issues-and-pull-requests/about-pull-requests) + +#### 1. 复刻仓库 + +当你第一次提交拉取请求时,先复刻 OpenMMLab 原代码库,点击 GitHub 页面右上角的 **Fork** 按钮,复刻后的代码库将会出现在你的 GitHub 个人主页下。 + +
+
+将代码克隆到本地
+
+```shell
+git clone git@github.com:{username}/mmediting.git
+```
+
+添加原代码库为上游代码库
+
+```bash
+git remote add upstream git@github.com:open-mmlab/mmediting
+```
+
+检查 remote 是否添加成功,在终端输入 `git remote -v`
+
+```bash
+origin git@github.com:{username}/mmediting.git (fetch)
+origin git@github.com:{username}/mmediting.git (push)
+upstream git@github.com:open-mmlab/mmediting (fetch)
+upstream git@github.com:open-mmlab/mmediting (push)
+```
+
+```{note}
+这里对 origin 和 upstream 进行一个简单的介绍,当我们使用 git clone 来克隆代码时,会默认创建一个 origin 的 remote,它指向我们克隆的代码库地址,而 upstream 则是我们自己添加的,用来指向原始代码库地址。当然如果你不喜欢他叫 upstream,也可以自己修改,比如叫 open-mmlab。我们通常向 origin 提交代码(即 fork 下来的远程仓库),然后向 upstream 提交一个 pull request。如果提交的代码和最新的代码发生冲突,再从 upstream 拉取最新的代码,和本地分支解决冲突,再提交到 origin。
+```
+
+#### 2. 配置 pre-commit
+
+在本地开发环境中,我们使用 [pre-commit](https://pre-commit.com/#intro) 来检查代码风格,以确保代码风格的统一。在提交代码,需要先安装 pre-commit(需要在 mmediting 目录下执行):
+
+```shell
+pip install -U pre-commit
+pre-commit install
+```
+
+检查 pre-commit 是否配置成功,并安装 `.pre-commit-config.yaml` 中的钩子:
+
+```shell
+pre-commit run --all-files
+```
+
+
+
+
+
+```{note}
+如果你是中国用户,由于网络原因,可能会出现安装失败的情况,这时可以使用国内源
+
+pre-commit install -c .pre-commit-config-zh-cn.yaml
+
+pre-commit run --all-files -c .pre-commit-config-zh-cn.yaml
+```
+
+如果安装过程被中断,可以重复执行 `pre-commit run ...` 继续安装。
+
+如果提交的代码不符合代码风格规范,pre-commit 会发出警告,并自动修复部分错误。
+
+
+
+如果我们想临时绕开 pre-commit 的检查提交一次代码,可以在 `git commit` 时加上 `--no-verify`(需要保证最后推送至远程仓库的代码能够通过 pre-commit 检查)。
+
+```shell
+git commit -m "xxx" --no-verify
+```
+
+#### 3. 创建开发分支
+
+安装完 pre-commit 之后,我们需要基于 master 创建开发分支,建议的分支命名规则为 `username/pr_name`。
+
+```shell
+git checkout -b yhc/refactor_contributing_doc
+```
+
+在后续的开发中,如果本地仓库的 master 分支落后于 upstream 的 master 分支,我们需要先拉取 upstream 的代码进行同步,再执行上面的命令
+
+```shell
+git pull upstream master
+```
+
+#### 4. 提交代码并在本地通过单元测试
+
+- mmediting 引入了 mypy 来做静态类型检查,以增加代码的鲁棒性。因此我们在提交代码时,需要补充 Type Hints。具体规则可以参考[教程](https://zhuanlan.zhihu.com/p/519335398)。
+
+- 提交的代码同样需要通过单元测试
+
+ ```shell
+ # 通过全量单元测试
+ pytest tests
+
+ # 我们需要保证提交的代码能够通过修改模块的单元测试,以 runner 为例
+ pytest tests/test_runner/test_runner.py
+ ```
+
+ 如果你由于缺少依赖无法运行修改模块的单元测试,可以参考[指引-单元测试](#单元测试)
+
+- 如果修改/添加了文档,参考[指引](#文档渲染)确认文档渲染正常。
+
+#### 5. 推送代码到远程
+
+代码通过单元测试和 pre-commit 检查后,将代码推送到远程仓库,如果是第一次推送,可以在 `git push` 后加上 `-u` 参数以关联远程分支
+
+```shell
+git push -u origin {branch_name}
+```
+
+这样下次就可以直接使用 `git push` 命令推送代码了,而无需指定分支和远程仓库。
+
+#### 6. 提交拉取请求(PR)
+
+(1) 在 GitHub 的 Pull request 界面创建拉取请求
+
+
+(2) 根据指引修改 PR 描述,以便于其他开发者更好地理解你的修改
+
+
+
+描述规范详见[拉取请求规范](#拉取请求规范)
+
+
+
+**注意事项**
+
+(a) PR 描述应该包含修改理由、修改内容以及修改后带来的影响,并关联相关 Issue(具体方式见[文档](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue))
+
+(b) 如果是第一次为 OpenMMLab 做贡献,需要签署 CLA
+
+
+
+(c) 检查提交的 PR 是否通过 CI(集成测试)
+
+
+
+mmediting 会在不同的平台(Linux、Window、Mac),基于不同版本的 Python、PyTorch、CUDA 对提交的代码进行单元测试,以保证代码的正确性,如果有任何一个没有通过,我们可点击上图中的 `Details` 来查看具体的测试信息,以便于我们修改代码。
+
+(3) 如果 PR 通过了 CI,那么就可以等待其他开发者的 review,并根据 reviewer 的意见,修改代码,并重复 [4](#4-提交代码并本地通过单元测试)-[5](#5-推送代码到远程) 步骤,直到 reviewer 同意合入 PR。
+
+
+
+所有 reviewer 同意合入 PR 后,我们会尽快将 PR 合并到主分支。
+
+#### 7. 解决冲突
+
+随着时间的推移,我们的代码库会不断更新,这时候,如果你的 PR 与主分支存在冲突,你需要解决冲突,解决冲突的方式有两种:
+
+```shell
+git fetch --all --prune
+git rebase upstream/master
+```
+
+或者
+
+```shell
+git fetch --all --prune
+git merge upstream/master
+```
+
+如果你非常善于处理冲突,那么可以使用 rebase 的方式来解决冲突,因为这能够保证你的 commit log 的整洁。如果你不太熟悉 `rebase` 的使用,那么可以使用 `merge` 的方式来解决冲突。
+
+### 指引
+
+#### 单元测试
+
+在提交修复代码错误或新增特性的拉取请求时,我们应该尽可能的让单元测试覆盖所有提交的代码,计算单元测试覆盖率的方法如下
+
+```shell
+python -m coverage run -m pytest /path/to/test_file
+python -m coverage html
+# check file in htmlcov/index.html
+```
+
+#### 文档渲染
+
+在提交修复代码错误或新增特性的拉取请求时,可能会需要修改/新增模块的 docstring。我们需要确认渲染后的文档样式是正确的。
+本地生成渲染后的文档的方法如下
+
+```shell
+pip install -r requirements/docs.txt
+cd docs/zh_cn/
+# or docs/en
+make html
+# check file in ./docs/zh_cn/_build/html/index.html
+```
+
+### 代码风格
+
+#### Python
+
+[PEP8](https://www.python.org/dev/peps/pep-0008/) 作为 OpenMMLab 算法库首选的代码规范,我们使用以下工具检查和格式化代码
+
+- [flake8](https://github.com/PyCQA/flake8): Python 官方发布的代码规范检查工具,是多个检查工具的封装
+- [isort](https://github.com/timothycrosley/isort): 自动调整模块导入顺序的工具
+- [yapf](https://github.com/google/yapf): Google 发布的代码规范检查工具
+- [codespell](https://github.com/codespell-project/codespell): 检查单词拼写是否有误
+- [mdformat](https://github.com/executablebooks/mdformat): 检查 markdown 文件的工具
+- [docformatter](https://github.com/myint/docformatter): 格式化 docstring 的工具
+
+yapf 和 isort 的配置可以在 [setup.cfg](../../../setup.cfg) 找到
+
+通过配置 [pre-commit hook](https://pre-commit.com/) ,我们可以在提交代码时自动检查和格式化 `flake8`、`yapf`、`isort`、`trailing whitespaces`、`markdown files`,修复 `end-of-files`、`double-quoted-strings`、`python-encoding-pragma`、`mixed-line-ending`,调整 `requirments.txt` 的包顺序。
+pre-commit 钩子的配置可以在 [.pre-commit-config](../../../.pre-commit-config.yaml) 找到。
+
+pre-commit 具体的安装使用方式见[拉取请求](#2-配置-pre-commit)。
+
+更具体的规范请参考 [OpenMMLab 代码规范](contributing.md#代码风格)。
+
+#### C++ and CUDA
+
+C++ 和 CUDA 的代码规范遵从 [Google C++ Style Guide](https://google.github.io/styleguide/cppguide.html)
+
+### 拉取请求规范
+
+1. 使用 [pre-commit hook](https://pre-commit.com),尽量减少代码风格相关问题
+
+2. 一个`拉取请求`对应一个短期分支
+
+3. 粒度要细,一个`拉取请求`只做一件事情,避免超大的`拉取请求`
+
+ - Bad:实现 Faster R-CNN
+ - Acceptable:给 Faster R-CNN 添加一个 box head
+ - Good:给 box head 增加一个参数来支持自定义的 conv 层数
+
+4. 每次 Commit 时需要提供清晰且有意义 commit 信息
+
+5. 提供清晰且有意义的`拉取请求`描述
+
+ - 标题写明白任务名称,一般格式:\[Prefix\] Short description of the pull request (Suffix)
+ - prefix: 新增功能 \[Feature\], 修 bug \[Fix\], 文档相关 \[Docs\], 开发中 \[WIP\] (暂时不会被review)
+ - 描述里介绍`拉取请求`的主要修改内容,结果,以及对其他部分的影响, 参考`拉取请求`模板
+ - 关联相关的`议题` (issue) 和其他`拉取请求`
+
+6. 如果引入了其他三方库,或借鉴了三方库的代码,请确认他们的许可证和 mmediting 兼容,并在借鉴的代码上补充 `This code is inspired from http://`
+
+## 代码规范
+
+### 代码规范标准
+
+#### PEP 8 —— Python 官方代码规范
+
+[Python 官方的代码风格指南](https://www.python.org/dev/peps/pep-0008/),包含了以下几个方面的内容:
+
+- 代码布局,介绍了 Python 中空行、断行以及导入相关的代码风格规范。比如一个常见的问题:当我的代码较长,无法在一行写下时,何处可以断行?
+
+- 表达式,介绍了 Python 中表达式空格相关的一些风格规范。
+
+- 尾随逗号相关的规范。当列表较长,无法一行写下而写成如下逐行列表时,推荐在末项后加逗号,从而便于追加选项、版本控制等。
+
+ ```python
+ # Correct:
+ FILES = ['setup.cfg', 'tox.ini']
+ # Correct:
+ FILES = [
+ 'setup.cfg',
+ 'tox.ini',
+ ]
+ # Wrong:
+ FILES = ['setup.cfg', 'tox.ini',]
+ # Wrong:
+ FILES = [
+ 'setup.cfg',
+ 'tox.ini'
+ ]
+ ```
+
+- 命名相关规范、注释相关规范、类型注解相关规范,我们将在后续章节中做详细介绍。
+
+ "A style guide is about consistency. Consistency with this style guide is important. Consistency within a project is more important. Consistency within one module or function is the most important." PEP 8 -- Style Guide for Python Code
+
+:::{note}
+PEP 8 的代码规范并不是绝对的,项目内的一致性要优先于 PEP 8 的规范。OpenMMLab 各个项目都在 setup.cfg 设定了一些代码规范的设置,请遵照这些设置。一个例子是在 PEP 8 中有如下一个例子:
+
+```python
+# Correct:
+hypot2 = x*x + y*y
+# Wrong:
+hypot2 = x * x + y * y
+```
+
+这一规范是为了指示不同优先级,但 OpenMMLab 的设置中通常没有启用 yapf 的 `ARITHMETIC_PRECEDENCE_INDICATION` 选项,因而格式规范工具不会按照推荐样式格式化,以设置为准。
+:::
+
+#### Google 开源项目风格指南
+
+[Google 使用的编程风格指南](https://google.github.io/styleguide/pyguide.html),包括了 Python 相关的章节。相较于 PEP 8,该指南提供了更为详尽的代码指南。该指南包括了语言规范和风格规范两个部分。
+
+其中,语言规范对 Python 中很多语言特性进行了优缺点的分析,并给出了使用指导意见,如异常、Lambda 表达式、列表推导式、metaclass 等。
+
+风格规范的内容与 PEP 8 较为接近,大部分约定建立在 PEP 8 的基础上,也有一些更为详细的约定,如函数长度、TODO 注释、文件与 socket 对象的访问等。
+
+推荐将该指南作为参考进行开发,但不必严格遵照,一来该指南存在一些 Python 2 兼容需求,例如指南中要求所有无基类的类应当显式地继承 Object, 而在仅使用 Python 3 的环境中,这一要求是不必要的,依本项目中的惯例即可。二来 OpenMMLab 的项目作为框架级的开源软件,不必对一些高级技巧过于避讳,尤其是 MMCV。但尝试使用这些技巧前应当认真考虑是否真的有必要,并寻求其他开发人员的广泛评估。
+
+另外需要注意的一处规范是关于包的导入,在该指南中,要求导入本地包时必须使用路径全称,且导入的每一个模块都应当单独成行,通常这是不必要的,而且也不符合目前项目的开发惯例,此处进行如下约定:
+
+```python
+# Correct
+from mmedit.cnn.bricks import (Conv2d, build_norm_layer, DropPath, MaxPool2d,
+ Linear)
+from ..utils import ext_loader
+
+# Wrong
+from mmedit.cnn.bricks import Conv2d, build_norm_layer, DropPath, MaxPool2d, \
+ Linear # 使用括号进行连接,而不是反斜杠
+from ...utils import is_str # 最多向上回溯一层,过多的回溯容易导致结构混乱
+```
+
+OpenMMLab 项目使用 pre-commit 工具自动格式化代码,详情见[贡献代码](contributing.md#代码风格)。
+
+### 命名规范
+
+#### 命名规范的重要性
+
+优秀的命名是良好代码可读的基础。基础的命名规范对各类变量的命名做了要求,使读者可以方便地根据代码名了解变量是一个类 / 局部变量 / 全局变量等。而优秀的命名则需要代码作者对于变量的功能有清晰的认识,以及良好的表达能力,从而使读者根据名称就能了解其含义,甚至帮助了解该段代码的功能。
+
+#### 基础命名规范
+
+| 类型 | 公有 | 私有 |
+| --------------- | ---------------- | ------------------ |
+| 模块 | lower_with_under | \_lower_with_under |
+| 包 | lower_with_under | |
+| 类 | CapWords | \_CapWords |
+| 异常 | CapWordsError | |
+| 函数(方法) | lower_with_under | \_lower_with_under |
+| 函数 / 方法参数 | lower_with_under | |
+| 全局 / 类内常量 | CAPS_WITH_UNDER | \_CAPS_WITH_UNDER |
+| 全局 / 类内变量 | lower_with_under | \_lower_with_under |
+| 变量 | lower_with_under | \_lower_with_under |
+| 局部变量 | lower_with_under | |
+
+注意:
+
+- 尽量避免变量名与保留字冲突,特殊情况下如不可避免,可使用一个后置下划线,如 class\_
+- 尽量不要使用过于简单的命名,除了约定俗成的循环变量 i,文件变量 f,错误变量 e 等。
+- 不会被用到的变量可以命名为 \_,逻辑检查器会将其忽略。
+
+#### 命名技巧
+
+良好的变量命名需要保证三点:
+
+1. 含义准确,没有歧义
+2. 长短适中
+3. 前后统一
+
+```python
+# Wrong
+class Masks(metaclass=ABCMeta): # 命名无法表现基类;Instance or Semantic?
+ pass
+
+# Correct
+class BaseInstanceMasks(metaclass=ABCMeta):
+ pass
+
+# Wrong,不同地方含义相同的变量尽量用统一的命名
+def __init__(self, inplanes, planes):
+ pass
+
+def __init__(self, in_channels, out_channels):
+ pass
+```
+
+常见的函数命名方法:
+
+- 动宾命名法:crop_img, init_weights
+- 动宾倒置命名法:imread, bbox_flip
+
+注意函数命名与参数的顺序,保证主语在前,符合语言习惯:
+
+- check_keys_exist(key, container)
+- check_keys_contain(container, key)
+
+注意避免非常规或统一约定的缩写,如 nb -> num_blocks,in_nc -> in_channels
+
+### docstring 规范
+
+#### 为什么要写 docstring
+
+docstring 是对一个类、一个函数功能与 API 接口的详细描述,有两个功能,一是帮助其他开发者了解代码功能,方便 debug 和复用代码;二是在 Readthedocs 文档中自动生成相关的 API reference 文档,帮助不了解源代码的社区用户使用相关功能。
+
+#### 如何写 docstring
+
+与注释不同,一份规范的 docstring 有着严格的格式要求,以便于 Python 解释器以及 sphinx 进行文档解析,详细的 docstring 约定参见 [PEP 257](https://www.python.org/dev/peps/pep-0257/)。此处以例子的形式介绍各种文档的标准格式,参考格式为 [Google 风格](https://zh-google-styleguide.readthedocs.io/en/latest/google-python-styleguide/python_style_rules/#comments)。
+
+1. 模块文档
+
+ 代码风格规范推荐为每一个模块(即 Python 文件)编写一个 docstring,但目前 OpenMMLab 项目大部分没有此类 docstring,因此不做硬性要求。
+
+ ```python
+ """A one line summary of the module or program, terminated by a period.
+
+ Leave one blank line. The rest of this docstring should contain an
+ overall description of the module or program. Optionally, it may also
+ contain a brief description of exported classes and functions and/or usage
+ examples.
+
+ Typical usage example:
+
+ foo = ClassFoo()
+ bar = foo.FunctionBar()
+ """
+ ```
+
+2. 类文档
+
+ 类文档是我们最常需要编写的,此处,按照 OpenMMLab 的惯例,我们使用了与 Google 风格不同的写法。如下例所示,文档中没有使用 Attributes 描述类属性,而是使用 Args 描述 __init__ 函数的参数。
+
+ 在 Args 中,遵照 `parameter (type): Description.` 的格式,描述每一个参数类型和功能。其中,多种类型可使用 `(float or str)` 的写法,可以为 None 的参数可以写为 `(int, optional)`。
+
+ ```python
+ class BaseRunner(metaclass=ABCMeta):
+ """The base class of Runner, a training helper for PyTorch.
+
+ All subclasses should implement the following APIs:
+
+ - ``run()``
+ - ``train()``
+ - ``val()``
+ - ``save_checkpoint()``
+
+ Args:
+ model (:obj:`torch.nn.Module`): The model to be run.
+ batch_processor (callable, optional): A callable method that process
+ a data batch. The interface of this method should be
+ ``batch_processor(model, data, train_mode) -> dict``.
+ Defaults to None.
+ optimizer (dict or :obj:`torch.optim.Optimizer`, optional): It can be
+ either an optimizer (in most cases) or a dict of optimizers
+ (in models that requires more than one optimizer, e.g., GAN).
+ Defaults to None.
+ work_dir (str, optional): The working directory to save checkpoints
+ and logs. Defaults to None.
+ logger (:obj:`logging.Logger`): Logger used during training.
+ Defaults to None. (The default value is just for backward
+ compatibility)
+ meta (dict, optional): A dict records some import information such as
+ environment info and seed, which will be logged in logger hook.
+ Defaults to None.
+ max_epochs (int, optional): Total training epochs. Defaults to None.
+ max_iters (int, optional): Total training iterations. Defaults to None.
+ """
+
+ def __init__(self,
+ model,
+ batch_processor=None,
+ optimizer=None,
+ work_dir=None,
+ logger=None,
+ meta=None,
+ max_iters=None,
+ max_epochs=None):
+ ...
+ ```
+
+ 另外,在一些算法实现的主体类中,建议加入原论文的链接;如果参考了其他开源代码的实现,则应加入 modified from,而如果是直接复制了其他代码库的实现,则应加入 copied from ,并注意源码的 License。如有必要,也可以通过 .. math:: 来加入数学公式
+
+ ```python
+ # 参考实现
+ # This func is modified from `detectron2
+ #  +
+ +
+ +
+| Method | +class | +Example | +
|---|---|---|
| vanilla gan loss | +mmedit.models.GANLoss | ++ +```python +# dic gan +loss_gan=dict( + type='GANLoss', + gan_type='vanilla', + loss_weight=0.001, +) + +``` + + | + +
| lsgan loss | +mmedit.models.GANLoss | ++ | + +
| wgan loss | +mmedit.models.GANLoss | ++ +```python +# deepfillv1 +loss_gan=dict( + type='GANLoss', + gan_type='wgan', + loss_weight=0.0001, +) +``` + + | + +
| hinge loss | +mmedit.models.GANLoss | ++ +```python +# deepfillv2 +loss_gan=dict( + type='GANLoss', + gan_type='hinge', + loss_weight=0.1, +) +``` + + | + +
| smgan loss | +mmedit.models.GANLoss | ++ +```python +# aot-gan +loss_gan=dict( + type='GANLoss', + gan_type='smgan', + loss_weight=0.01, +) +``` + + | + +
| gradient penalty | +mmedit.models.GradientPenaltyLoss | ++ +```python +# deepfillv1 +loss_gp=dict(type='GradientPenaltyLoss', loss_weight=10.) +``` + + | + +
| discriminator shift loss | +mmedit.models.DiscShiftLoss | ++ +```python +# deepfillv1 +loss_disc_shift=dict(type='DiscShiftLoss', loss_weight=0.001) + +``` + + | + +
| clip loss | +mmedit.models.CLIPLoss | ++ + |
| L1 composition loss | +mmedit.models.L1CompositionLoss | ++ + |
| MSE composition loss | +mmedit.models.MSECompositionLoss | ++ + |
| charbonnier composition loss | +mmedit.models.CharbonnierCompLoss | ++ +```python +# dim +loss_comp=dict(type='CharbonnierCompLoss', loss_weight=0.5) +``` + + | + +
| face id Loss | +mmedit.models.FaceIdLoss | ++ + |
| light cnn feature loss | +mmedit.models.LightCNNFeatureLoss | ++ +```python +# dic gan +feature_loss=dict( + type='LightCNNFeatureLoss', + pretrained=pretrained_light_cnn, + loss_weight=0.1, + criterion='l1') +``` + + | + +
| gradient loss | +mmedit.models.GradientLoss | ++ + |
| l1 Loss | +mmedit.models.L1Loss | ++ +```python +# dic gan +pixel_loss=dict(type='L1Loss', loss_weight=1.0, reduction='mean') +``` + + | + +
| mse loss | +mmedit.models.MSELoss | ++ +```python +# dic gan +align_loss=dict(type='MSELoss', loss_weight=0.1, reduction='mean') +``` + + | + +
| charbonnier loss | +mmedit.models.CharbonnierLoss | ++ +```python +# dim +loss_alpha=dict(type='CharbonnierLoss', loss_weight=0.5) +``` + + | + +
| masked total variation loss | +mmedit.models.MaskedTVLoss | ++ +```python +# partial conv +loss_tv=dict( + type='MaskedTVLoss', + loss_weight=0.1 +) + +``` + + | + +
| perceptual loss | +mmedit.models.PerceptualLoss | ++ +```python +# real_basicvsr +perceptual_loss=dict( + type='PerceptualLoss', + layer_weights={ + '2': 0.1, + '7': 0.1, + '16': 1.0, + '25': 1.0, + '34': 1.0, + }, + vgg_type='vgg19', + perceptual_weight=1.0, + style_weight=0, + norm_img=False) + +``` + + | + +
| transferal perceptual loss | +mmedit.models.TransferalPerceptualLoss | ++ +```python +# ttsr +transferal_perceptual_loss=dict( + type='TransferalPerceptualLoss', + loss_weight=1e-2, + use_attention=False, + criterion='mse') + +``` + + | +
| Model | -Config | -Dataset | -Metric | -PyTorch | -ONNX Runtime | -TensorRT FP32 | -TensorRT FP16 | -
|---|---|---|---|---|---|---|---|
| ESRGAN | -
- esrgan_x4c64b23g32_g1_400k_div2k.py
- |
- Set5 | -PSNR | -28.2700 | -28.2619 | -28.2619 | -28.2616 | -
| SSIM | -0.7778 | -0.7784 | -0.7784 | -0.7783 | -|||
| Set14 | -PSNR | -24.6328 | -24.6290 | -24.6290 | -24.6274 | -||
| SSIM | -0.6491 | -0.6494 | -0.6494 | -0.6494 | -|||
| DIV2K | -PSNR | -26.6531 | -26.6532 | -26.6532 | -26.6532 | -||
| SSIM | -0.7340 | -0.7340 | -0.7340 | -0.7340 | -|||
| ESRGAN | -
- esrgan_psnr_x4c64b23g32_g1_1000k_div2k.py
- |
- Set5 | -PSNR | -30.6428 | -30.6307 | -30.6307 | -30.6305 | -
| SSIM | -0.8559 | -0.8565 | -0.8565 | -0.8566 | -|||
| Set14 | -PSNR | -27.0543 | -27.0422 | -27.0422 | -27.0411 | -||
| SSIM | -0.7447 | -0.7450 | -0.7450 | -0.7449 | -|||
| DIV2K | -PSNR | -29.3354 | -29.3354 | -29.3354 | -29.3339 | -||
| SSIM | -0.8263 | -0.8263 | -0.8263 | -0.8263 | -|||
| SRCNN | -
- srcnn_x4k915_g1_1000k_div2k.py
- |
- Set5 | -PSNR | -28.4316 | -28.4120 | -27.2144 | -27.2127 | -
| SSIM | -0.8099 | -0.8106 | -0.7782 | -0.7781 | -|||
| Set14 | -PSNR | -25.6486 | -25.6367 | -24.8613 | -24.8599 | -||
| SSIM | -0.7014 | -0.7015 | -0.6674 | -0.6673 | -|||
| DIV2K | -PSNR | -27.7460 | -27.7460 | -26.9891 | -26.9862 | -||
| SSIM | -0.7854 | -0.78543 | -0.7605 | -0.7604 | -
| Model | +Config | +Dataset | +Metric | +PyTorch | +ONNX Runtime | +TensorRT FP32 | +TensorRT FP16 | +
|---|---|---|---|---|---|---|---|
| ESRGAN | +
+ esrgan_x4c64b23g32_g1_400k_div2k.py
+ |
+ Set5 | +PSNR | +28.2700 | +28.2619 | +28.2619 | +28.2616 | +
| SSIM | +0.7778 | +0.7784 | +0.7784 | +0.7783 | +|||
| Set14 | +PSNR | +24.6328 | +24.6290 | +24.6290 | +24.6274 | +||
| SSIM | +0.6491 | +0.6494 | +0.6494 | +0.6494 | +|||
| DIV2K | +PSNR | +26.6531 | +26.6532 | +26.6532 | +26.6532 | +||
| SSIM | +0.7340 | +0.7340 | +0.7340 | +0.7340 | +|||
| ESRGAN | +
+ esrgan_psnr_x4c64b23g32_g1_1000k_div2k.py
+ |
+ Set5 | +PSNR | +30.6428 | +30.6307 | +30.6307 | +30.6305 | +
| SSIM | +0.8559 | +0.8565 | +0.8565 | +0.8566 | +|||
| Set14 | +PSNR | +27.0543 | +27.0422 | +27.0422 | +27.0411 | +||
| SSIM | +0.7447 | +0.7450 | +0.7450 | +0.7449 | +|||
| DIV2K | +PSNR | +29.3354 | +29.3354 | +29.3354 | +29.3339 | +||
| SSIM | +0.8263 | +0.8263 | +0.8263 | +0.8263 | +|||
| SRCNN | +
+ srcnn_x4k915_g1_1000k_div2k.py
+ |
+ Set5 | +PSNR | +28.4316 | +28.4120 | +27.2144 | +27.2127 | +
| SSIM | +0.8099 | +0.8106 | +0.7782 | +0.7781 | +|||
| Set14 | +PSNR | +25.6486 | +25.6367 | +24.8613 | +24.8599 | +||
| SSIM | +0.7014 | +0.7015 | +0.6674 | +0.6673 | +|||
| DIV2K | +PSNR | +27.7460 | +27.7460 | +26.9891 | +26.9862 | +||
| SSIM | +0.7854 | +0.78543 | +0.7605 | +0.7604 | +
 +
+ +
+ +
+