diff --git a/docs/README.md b/docs/README.md
index 76529f4..c0fbd58 100644
--- a/docs/README.md
+++ b/docs/README.md
@@ -1,15 +1,65 @@
-# GitHub Starter
+# Ratchada_Utils
+
+[](https://opensource.org/licenses/MIT)
+[](https://badge.fury.io/py/ratchada-utils)
+[](https://pypi.org/project/ratchada-utils/)
## Project Brief
-``` @TODO: Replace this readme with the one for your project. ```
+Ratchada_Utils is a Python library designed to provide text processing utilities, particularly for tasks related to the Ratchada Whisper model. It offers tools for tokenization and evaluation of speech-to-text outputs.
+
+## Features
+
+- Text tokenization
+- Simple evaluation of speech-to-text outputs
+- Parallel processing for improved performance
+
+## Installation
+
+You can install `ratchada_utils` using pip:
+
+```bash
+pip install ratchada_utils
+```
+
+For the latest development version, you can install directly from the GitHub repository:
+```bash
+pip install git+https://github.com/yourusername/ratchada_utils.git
+```
+
+## Usage
+### Tokenizing Text
+
+```bash
+from ratchada_utils.processor import tokenize_text
+
+text = "Your input text here."
+tokenized_text = tokenize_text(text, pred=True)
+print("Tokenized Text:", tokenized_text)
+# Output: Tokenized Text: ['your', 'input', 'text', 'here']
+```
+
+### Evaluate
+
+```bash
+import pandas as pd
+from ratchada_utils.evaluator import simple_evaluation
-`github-starter` is managed by Foundations Engineering.
-It's meant to uphold documentation standards and enforce security standards by serving as a template for everyone's GitHub repos.
+result = pd.read_csv("./output/result-whisper-ratchada.csv")
+summary = simple_evaluation(result["pred_text"], result["true_text"])
+print(summary)
+```
-Status: **In Progress** / Production / Deprecated
+## Requirements
-## How To Use
+1. Python 3.10 or higher
+2. Dependencies are listed in requirements.txt
-To understand the process, read the [RFC](https://docs.google.com/document/d/1PT97wDuj31BZo87SKSw0YSPvRVzunh1lAJ4I4nPctBI/edit#).
-Search for `@TODO` from within your instantiated repo and fill in the gaps.
+## Documentation
+For full documentation, please visit our documentation page.
+## Contributing
+Contributions are welcome! Please feel free to submit a Pull Request.
+## License
+This project is licensed under the MIT License - see the LICENSE file for details.
+## Contact
+For any questions or issues, please open an issue on the GitHub repository.
diff --git a/docs/architecture.md b/docs/architecture.md
index 1b96321..291992d 100644
--- a/docs/architecture.md
+++ b/docs/architecture.md
@@ -1,101 +1,72 @@
-# Project Architecture and Access to Production
+# Project Architecture
-``` @TODO: Summary of Architecture and steps to access each component ```
+## Overview
-The `github-starter` project is meant as a base repository template; it should be a basis for other projects.
-
-`github-starter` is hosted on Github, and is available as a [Template in Backstage]([url](https://catalog.tm8.dev/create?filters%5Bkind%5D=template&filters%5Buser%5D=all)****)
+Ratchada_Utils is a Python library designed to provide text processing utilities, particularly for tasks related to the Ratchada Whisper model. It's primarily used for tokenization and evaluation of speech-to-text outputs.
## Architecture Details
-```Note: Structure of this document assumes Dev and Prod are in different Cloud Platform projects. You can reduce the sections for architecture if redundant. Just note the datasets, vms, buckets, etc. being used in Dev vs Prod ```
-- Provider: ``` @TODO: GCP / AWS / Azure / etc ```
-- Dev Environment: ``` @TODO: Link to dev env ```
-- Prod Environment: ``` @TODO: Link to prod env ```
-- Technology: ``` @TODO: Python / Airflow / Dagster / Postgres / Snowflake / etc ```
-
-### Implementation Notes
-``` @TODO: Note down known limitations, possible issues, or known quirks with the project. The following questions might help: ```
-``` 1. Which component needs most attention? ie. Usually the first thing that needs tweaks ```
-``` 2. Are the parts of the project that might break in the future? (eg. Filling up of disk space, memory issues if input data size increases, a web scraper, etc.)```
-``` 3. What are some known limitations for the project? (eg. Input data schema has to remain the same, etc.)```
-
-## Dev Architecture
-``` @TODO: Dev architecture diagram and description. Please include any OAuth or similar Applications.```
-``` @TODO: List out main components being used and their descriptions.```
-
-### Virtual Machines
-``` @TODO: List VMs used and what they host```
-### Datasets
-``` @TODO: List datasets given following format```
-#### Dataset A
-- Description: PSGC Data
-- File Location: GCS Uri / GDrive link / etc
-- Retention Policy: 3 months
-
-### Tokens and Accounts
-``` @TODO: Please fill out all Tokens and Accounts being used in the project given the format below. Include tokens from client used in the project.```
-
-**Dev Github Service Account Token**
-
-- Location: Bitwarden Github Collection
-- Person in charge: Client Name (client@email.com)
-- Validity: 30 Days
-- Description: This token is used to call the Github API using the account ``sample-account@thinkingmachin.es`
-- How to Refresh:
- 1. Go to github.com
- 2. Click refresh
-
-## Production Architecture
-``` @TODO: Prod architecture diagram and description. Please include any OAuth or similar Applications.```
-``` @TODO: List out main components being used and their descriptions.```
-
-### Virtual Machines
-``` @TODO: List VMs used and what they host```
-### Datasets
-``` @TODO: List datasets given following format```
-#### Dataset A
-- Description: PSGC Data
-- File Location: GCS Uri / GDrive link / etc
-- Retention Policy: 3 months
-
-### Tokens and Accounts
-``` @TODO: Please fill out all Tokens and Accounts being used in the project given the format below. Include tokens from client used in the project.```
-
-**Prod Github Service Account Token**
-
-- Location: Bitwarden Github Collection
-- Person in charge: Client Name (client@email.com)
-- Validity: 30 Days
-- Description: This token is used to call the Github API using the account ``sample-account@thinkingmachin.es`
-- How to Refresh:
- 1. Go to github.com
- 2. Click refresh
-
-## Accessing Cloud Platform Environments
-```@TODO: Describe the steps to access the prod VMs/platform```
-
-**Get access to Client AWS Platform**
-- Person in charge: Client Name/Dev Name
-- Bitwarden Credentials:
-1. Install AWS CLI
-2. Run `aws configure` - ID and Secret from Bitwarden
-
-**Accessing Prod VM**
-1. Update your ssh config to have the following:
-```
-Host project-vpn
- Hostname xx.xxx.xxx.xxx
- User ubuntu
-
-# Use the Private IP for the rest
-Host dev-project-app
- Hostname xxx.xx.xx.xx
- User ubuntu
- ProxyJump project-vpn
-```
-2. Run `ssh dev-project-app`
-
-**Access Prod App in UI**
-1. Install `sshuttle`
-2. Run `sshuttle -r dev-project-app xxx.xx.0.0/16`
-3. Open web browser using the Private IP found in you SSH config (http:xxx.xx.xx.xx:3000)
+
+- Language: Python (3.10+)
+- Package Manager: pip
+- Documentation: MkDocs
+- Testing: pytest
+- Code Style: Black, Flake8
+- Continuous Integration: GitHub Actions
+
+## Main Components
+
+1. Text Processor
+ - Location: `ratchada_utils/processor/`
+ - Key Function: `tokenize_text()`
+ - Description: Handles text tokenization for both prediction and reference texts.
+
+2. Evaluator
+ - Location: `ratchada_utils/evaluator/`
+ - Key Function: `simple_evaluation()`
+ - Description: Provides metrics for comparing predicted text against reference text.
+
+## Data Flow
+
+1. Input: Raw text (string)
+2. Processing: Tokenization
+3. Evaluation: Comparison of tokenized prediction and reference texts
+4. Output: Evaluation metrics (pandas DataFrame)
+
+## Dependencies
+
+Major dependencies include:
+- pandas: For data manipulation and analysis
+- numpy: For numerical operations
+- concurrent.futures: For parallel processing
+
+Full list of dependencies can be found in `requirements.txt`.
+
+## Development Environment
+
+The project is developed using a virtual environment to isolate dependencies. See the [Development Guide](development.md) for setup instructions.
+
+## Deployment
+
+The package is deployed to PyPI for easy installation by users. Deployment is handled through GitHub Actions. See the [Deployment Procedure](deployment.md) for details.
+
+## Security Considerations
+
+- The library doesn't handle sensitive data directly, but users should be cautious about the content they process.
+- No external API calls are made by the library.
+
+## Scalability
+
+The `simple_evaluation` function uses `concurrent.futures.ProcessPoolExecutor` for parallel processing, allowing it to scale with available CPU cores.
+
+## Limitations
+
+- The library is designed for text processing and may not handle other data types effectively.
+- Performance may degrade with extremely large input sizes due to memory constraints.
+
+## Future Improvements
+
+1. Implement more advanced tokenization methods
+2. Add support for additional evaluation metrics
+3. Optimize memory usage for large inputs
+
+For any questions or issues regarding the architecture, please open an issue on the GitHub repository.
diff --git a/docs/deployment.md b/docs/deployment.md
index 8cd0508..565b461 100644
--- a/docs/deployment.md
+++ b/docs/deployment.md
@@ -1,18 +1,72 @@
# Deployment Procedure
-## Dev Deployment
+## PyPI Deployment
### Pre-requisites
-``` @TODO: Fill with pre-reqs such as access, CI/CD setup, variables used for deployment etc ```
+- PyPI account
+- `setuptools` and `wheel` installed
+- `.pypirc` file configured with your PyPI credentials
### How-to-Guide
-``` @TODO: Fill with steps to deploy. Feel free to subdivide to sections or multiple MD files through mkdocs.yml ```
+1. Update the version number in `setup.py`.
+2. Create source distribution and wheel:
+```zsh
+python setup.py sdist bdist_wheel
+```
-## Production Deployment
+3. Upload to PyPI:
+```zsh
+twine upload dist/*
+```
+
+## Documentation Deployment
### Pre-requisites
-``` @TODO: Fill with pre-reqs such as access, CI/CD setup, variables used for deployment etc ```
+- MkDocs installed
+- GitHub Pages configured for your repository
### How-to-Guide
-``` @TODO: Fill with steps to deploy. Feel free to subdivide to sections or multiple MD files through mkdocs.yml ```
+1. Build the documentation:
+```zsh
+mkdocs build
+```
+2. Deploy to GitHub Pages:
+```zsh
+mkdocs gh-deploy
+```
+3. docs/features/example.md:
+This file should be replaced with actual features of your project. Here's an example:
+```markdown
+# Feature: Text Tokenization
+
+## Description
+The text tokenization feature allows users to split input text into individual tokens or words.
+
+## How does it work
+1. The input text is passed to the `tokenize_text` function.
+2. The function removes punctuation and splits the text on whitespace.
+3. If `pred=True`, additional preprocessing steps are applied for prediction tasks.
+4. The function returns a list of tokens.
+
+## Gotchas / Specific Behaviors
+- The tokenizer treats hyphenated words as a single token.
+- Numbers are treated as separate tokens.
+- The tokenizer is case-sensitive by default.
+```
+
+4. docs/README.md:
+This file should be updated to reflect your project. Here's a suggested update:
+```markdown
+# Ratchada Utils Documentation
+
+## Project Brief
+
+`ratchada_utils` is a Python library for text processing and utilities related to the Ratchada Whisper model. It provides tools for tokenization and evaluation of speech-to-text models.
+
+Status: **In Development**
+
+## How To Use
+
+Refer to the [Installation](../README.md#installation) and [Usage](../README.md#usage) sections in the main README for basic usage instructions. For more detailed information on each feature, check the individual documentation pages.
+```
diff --git a/docs/development.md b/docs/development.md
index aedf10f..3dffe83 100644
--- a/docs/development.md
+++ b/docs/development.md
@@ -1,49 +1,50 @@
-# Development Lifecycle
-
-``` @TODO: Replace Example with your Team's Dev Workflow ```
-
-## Trunk Based Development
-
-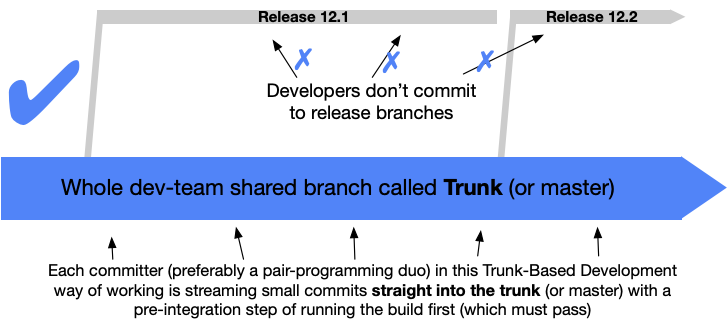
-
-The github-starter project follows the concept of Trunk-based Development, wherein User Stories are worked on PRs. PRs then get merged to `master` once approved by the team.
-
-The master branch serves as the most up-to-date version of the code base. For releases, whenever we deploy, we create a `release/` branch, which is based off of `master` at a given point in time, and serves as the branch to be deployed
-
-### Naming Format
-
-``` @TODO: Update according to Team's agreement ```
-
-**Branch Names:**
-- To `` Branch:
- - `feature/-`
- - `fix/-`
-- To `` Branch:
- - `release/`
- - `release/-`
-
-**PR Title:** `[]() `
-
-**PR Template:** [pull_request_template.md](../.github/pull_request_template.md)
-
-### Development Workflow
-``` @TODO: Development workflow being used by the devs. Eg: Make changes in local, push to dev for testing, make a PR, deploy after merging```
-
-## Local Development
-``` Note: This should contain all information for new devs to set up and make changes```
-### File Structure Walkthrough
-``` @TODO: Fill with a brief walkthrough of the codebase ```
-- `docs/` - This folder contains all Markdown files for creating Backstage TechDocs.
-- `infra/` - This folder contains all infra definitions through Terraform.
-
-### Pre-requisites
-``` @TODO: Fill with pre-reqs such as access to Cloud Platform, Bitwarden Collection, Github etc ```
-
-### Cloning and Installation
-``` @TODO: Fill with set-up/installation guide. Feel free to subdivide to sections or multiple MD files through mkdocs.yml ```
-
-### Environment Setup
-``` @TODO: Fill with instructions for exporting local env variables. Distinguish variables being used in local vs dev vs prod ```
-
-### Running the Application
-``` @TODO: Fill with steps on running the app locally. Feel free to subdivide to sections or multiple MD files through mkdocs.yml ```
+# Development Guide
+
+## Setting Up Development Environment
+
+1. Clone the repository:
+
+```zsh
+git clone https://github.com/yourusername/ratchada_utils.git
+cd ratchada_utils
+```
+
+2. Create a virtual environment:
+```zsh
+python -m venv venv
+source venv/bin/activate # On Windows, use venv\Scripts\activate
+```
+3. Install development dependencies:
+```zsh
+pip install -r requirements-dev.txt
+```
+
+## Code Style
+
+We follow PEP 8 guidelines. We use Black for code formatting and Flake8 for linting.
+
+To format your code:
+```zsh
+black .
+```
+To run the linter:
+```zsh
+flake8 .
+```
+## Making a Release
+
+1. Update the version number in `setup.py`.
+2. Update `CHANGELOG.md`.
+3. Commit these changes with a message like "Bump version to x.x.x".
+4. Tag the commit: `git tag vx.x.x`
+5. Push to GitHub: `git push origin master --tags`
+6. Create a new release on GitHub using this tag.
+7. The GitHub Action will automatically publish to PyPI.
+
+## Documentation
+
+We use MkDocs for documentation. To build the docs locally:
+```zsh
+mkdocs serve
+```
+Then visit `http://localhost:8000` to view the documentation.
diff --git a/docs/features/example.md b/docs/features/example.md
deleted file mode 100644
index 156e250..0000000
--- a/docs/features/example.md
+++ /dev/null
@@ -1,10 +0,0 @@
-# Milestone: Role-based Access Control (RBAC)
-
-## Description
-``` @TODO: Fill up desc ```
-
-## How does it work
-``` @TODO: Turn the black box into a white box ```
-
-## Gotchas / Specific Behaviors
-``` @TODO: List any gotchas we should be aware of, or client specific asks ```
diff --git a/docs/features/flexible_tokenization.md b/docs/features/flexible_tokenization.md
new file mode 100644
index 0000000..a93b8bb
--- /dev/null
+++ b/docs/features/flexible_tokenization.md
@@ -0,0 +1,12 @@
+## 3. Flexible Tokenization Options
+
+### Description
+The tokenization function provides flexibility through its `pred` parameter, allowing different tokenization strategies for prediction and reference texts.
+
+### How it works
+1. When `pred=True`, the tokenization applies additional preprocessing steps suitable for prediction texts.
+2. When `pred=False` (default), it applies standard tokenization suitable for reference texts.
+
+### Gotchas / Specific Behaviors
+- Users need to ensure they're using the appropriate `pred` value based on whether they're tokenizing prediction or reference text.
+- The exact differences in tokenization between `pred=True` and `pred=False` should be clearly documented in the function's docstring.
diff --git a/docs/features/simple_evaluation.md b/docs/features/simple_evaluation.md
new file mode 100644
index 0000000..9a1b2b9
--- /dev/null
+++ b/docs/features/simple_evaluation.md
@@ -0,0 +1,16 @@
+## 2. Simple Evaluation
+
+### Description
+The simple evaluation feature provides a way to compare predicted text against reference text, which is particularly useful for assessing the performance of speech-to-text models.
+
+### How it works
+1. The `simple_evaluation` function takes two lists: predicted texts and actual (reference) texts.
+2. It tokenizes both lists using the `tokenize_text` function.
+3. The function uses parallel processing to flatten and filter the tokenized lists.
+4. It then calls an `evaluate` function (not shown in the provided code) to compute evaluation metrics.
+5. The result is returned as a pandas DataFrame.
+
+### Gotchas / Specific Behaviors
+- The evaluation is performed on a token level, not character level.
+- The function uses multiprocessing, which may not work in all environments (e.g., some Jupyter notebook setups).
+- The exact metrics computed depend on the implementation of the `evaluate` function.
diff --git a/docs/features/text_tokenize.md b/docs/features/text_tokenize.md
new file mode 100644
index 0000000..e20b4f4
--- /dev/null
+++ b/docs/features/text_tokenize.md
@@ -0,0 +1,15 @@
+## 1. Text Tokenization
+
+### Description
+The text tokenization feature allows users to split input text into individual tokens or words, which is a crucial preprocessing step for many natural language processing tasks.
+
+### How it works
+1. The input text is passed to the `tokenize_text` function.
+2. The function removes punctuation and splits the text on whitespace.
+3. If `pred=True`, additional preprocessing steps are applied for prediction tasks.
+4. The function returns a list of tokens.
+
+### Gotchas / Specific Behaviors
+- The tokenizer treats hyphenated words as a single token.
+- Numbers are treated as separate tokens.
+- The tokenizer is case-sensitive by default.
diff --git a/docs/troubleshooting.md b/docs/troubleshooting.md
index 510ee1c..6fdc472 100644
--- a/docs/troubleshooting.md
+++ b/docs/troubleshooting.md
@@ -1,35 +1,44 @@
# Troubleshooting
-## Unit Testing
+## Common Issues
-### How-to-Guide
-``` @TODO: Fill with steps to run unit tests ```
+### ImportError: No module named 'ratchada_utils'
-```sh
-{command}
-{command}
+Make sure you have installed the package correctly. Try reinstalling:
+
+```zsh
+pip uninstall ratchada_utils
+pip install ratchada_utils
```
-### Code Coverage
-``` @TODO: Update command and data ```
+### TypeError when using tokenize_text
-To check code coverage, run: `pytest --cov=src --cov-report term-missing test/`
+Make sure you're passing the correct type of arguments to the function. The `text` parameter should be a string, and `pred` should be a boolean.
-```
-Name Stmts Miss Cover Missing
-----------------------------------------------------------
-src/config.py 46 0 100%
-src/script.py 84 33 61% 25-46, 60-62, 80-81, 145, 173-186, 207-213
-----------------------------------------------------------
-TOTAL 130 33 75%
+## Debugging
+
+If you encounter any issues, you can enable debug logging:
+```python
+import logging
+logging.basicConfig(level=logging.DEBUG)
```
+Then run your code, and you'll see more detailed logging output.
-## Debugging
+## Reporting Issues
+
+If you encounter a bug or have a feature request, please open an issue on our GitHub repository.
+When reporting an issue, please include:
+
+- A clear description of the problem
+- Steps to reproduce the issue
+- Your operating system and Python version
+- The version of ratchada_utils you're using
-### Logs Location
-``` @TODO: Fill with links, paths, etc to logs ```
+## Getting Help
+If you need help using ratchada_utils, you can:
-### Common Issues
-``` @TODO: Add if there are any ```
+- Check the documentation
+- Open an issue on GitHub
+- Reach out to the maintainers directly (contact information in README)
diff --git a/setup.py b/setup.py
index 9d02a7d..83819f6 100644
--- a/setup.py
+++ b/setup.py
@@ -23,7 +23,7 @@ def parse_requirements(filename):
setup(
name="ratchada_utils",
- version="2.1.20",
+ version="2.1.21",
packages=find_packages(include=["ratchada_utils", "ratchada_utils.*"]),
package_data={
"ratchada_utils.processor": ["*.json", "*.py"],