I built auto-cpufreq genAI chatbot to handle support, answer questions, and assist with its installation and configuration, since open-source project grew too popular to manage manually. So in the process I essentially automated myself as part of:
- Blog post: How I replaced myself with a GenAI chatbot using Gemini
- Youtube video: How I replaced myself with a GenAI chatbot using Gemini
The idea is that you follow along in what's described in From Zero to AI Hero: How to Build a GenAI Chatbot with Gemini & Vertex AI Agent Builder blog post and/or (17 video) Youtube video playlist. Which expands on what I said before as part of my initial blog post/Youtube video, build the same chatbot I did, and then customize it with your own data to fit your unique GenAI chatbot use case.
This repository contains Python scripts to fetch its data from GitHub, YouTube, and Reddit APIs, which is then fed into the chatbot’s data store and used as part of a Retrieval-Augmented Generation (RAG) workflow.
auto-cpufreq genAI chatbot is built on Google Cloud, and leverages Vertex AI Agent Builder and Conversational Agents, powered by the Gemini LLM.
From Zero to AI Hero: How to Build a GenAI Chatbot with Gemini & Vertex AI Agent Builder Youtube playlist:
Ensure you have the necessary API keys for GitHub, YouTube, and Reddit by following instructions below.
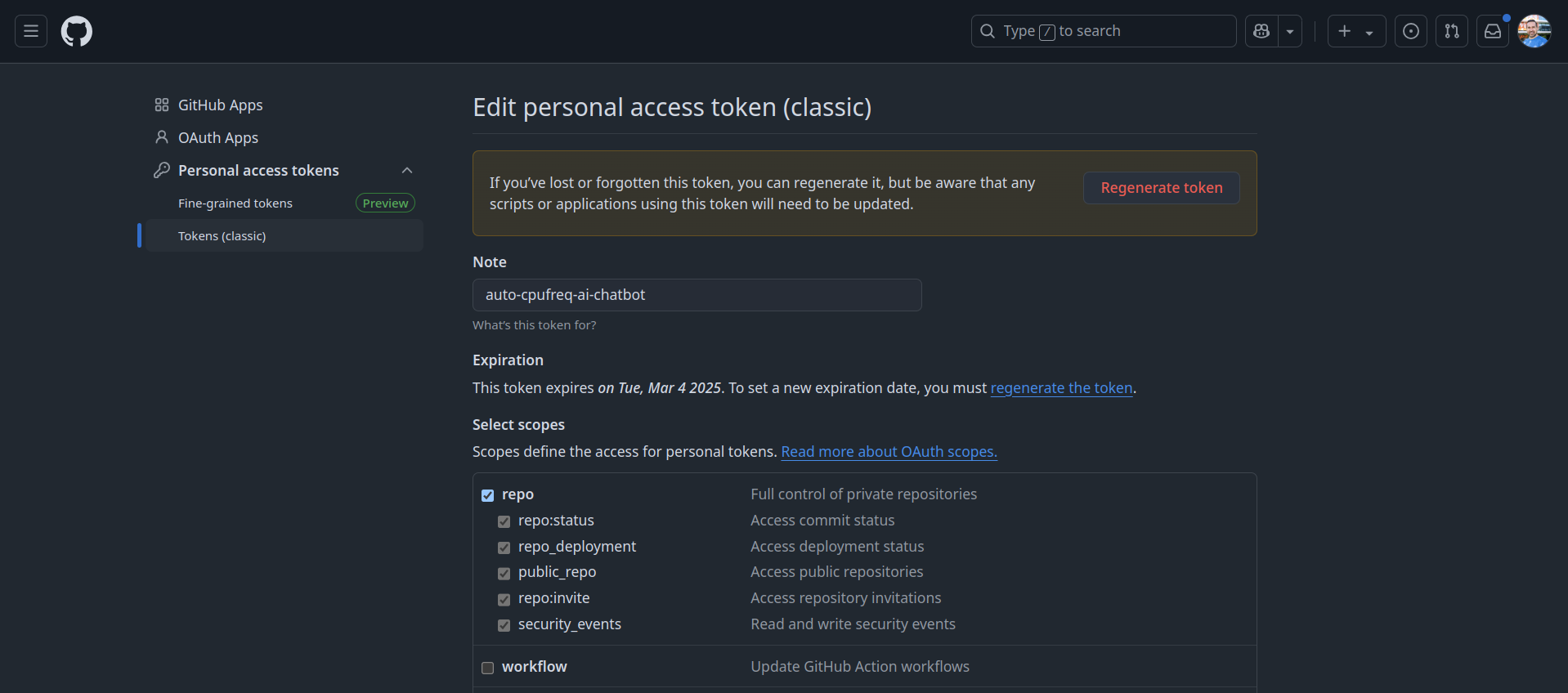
Create Github Personal access tokens under Developer Settings
I went with Token (classic) and gave it full access to repo section and select: "Full control of private repositories"
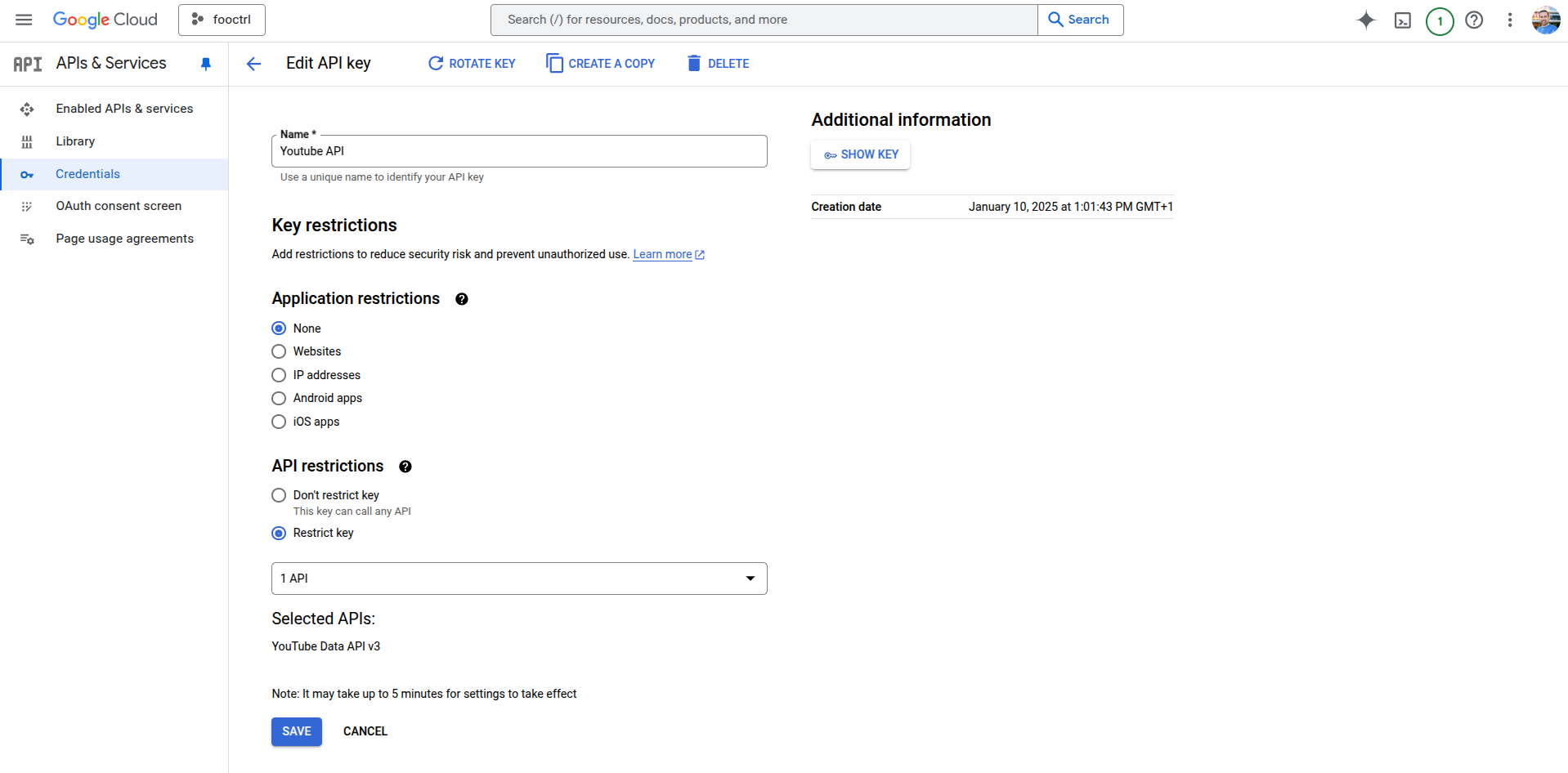
- Enable "YouTube Data API v3" in Google Cloud Console
- Under "Create credentials", create "Youtube API" key
- Click on "Youtube API" to set key restrictions, e.g: "Youtube Data API v3" so only this API can use it (or that it can only be used from your IP).
Click on "Create app" in Reddit "apps ("developed applications")
In case you use Zsh, e.g: vim ~/.zshrc
# auto-cpufreq genAI chatbot API keys
# reference: https://github.com/AdnanHodzic/auto-cpufreq-genAI-chatbot
# github token
export github_export_token="REDACTED
# reddit
export reddit_client_id="REDACTED"
export reddit_client_secret="REDACTED"
# Youtube API key
export youtube_api_key="REDACTED"
Followed by: source ~/.zshrc
How to fetch data from defined GenAI Chatbot Data Sources:
Since all requirements to run any of the .py files are stored in a single Pipfile file, after you have pipenv installed on your system, you'll need to run pipenv install the first time to install needed dependencies.
After which you can run each script with:
- github_export_readme.py -
pipenv run python github_export_readme.py - github_export_issues.py -
pipenv run python github_export_issues.py - github_export_discussions.py -
pipenv run python github_export_discussions.py - github_export_pull_requests.py -
pipenv run python github_export_pull_requests.py - github_export_releases.py -
pipenv run python github_export_releases.py $URL
- youtube_transcript_downloader.py -
pipenv run python youtube_transcript_downloader.py $URL - youtube_comments_downloader.py -
pipenv run python youtube_comments_downloader.py $URL
- reddit_post_comments_export.py -
pipenv run python reddit_post_comments_export.py $URL
The exported HTML files, containing all necessary data, will be stored in the Data/ directory, organized by source.
Google Cloud credits are provided for this project #VertexAISprint