Generative AI refers to artificial intelligence systems capable of creating new content—such as text, images, audio, or code—by learning patterns from existing data. These systems utilize sophisticated machine learning models, particularly deep learning algorithms, to understand and replicate the structures found in their training datasets. For example, models like OpenAI's DALL-E can generate images from textual descriptions, while ChatGPT produces human-like text responses based on input prompts.
Large Language Models (LLMs) are a subset of generative AI focused on processing and generating human language. Trained on vast amounts of text data, LLMs can perform a variety of natural language processing tasks, including text generation, translation, summarization, and question-answering. They achieve this by leveraging deep learning architectures, such as transformers, to capture the nuances of language and context. Notable examples include OpenAI's GPT series and Google's BERT.
In summary, generative AI encompasses a broad range of AI technologies capable of creating new content across various modalities, while LLMs specifically deal with understanding and generating human language, forming a crucial component of the generative AI landscape.
Watch: Prompt Engineering Fundamentals
Watch: Creating Advanced Prompts
Prompt engineering is the process of designing and refining inputs—known as prompts—to guide generative AI models in producing desired outputs. This practice involves crafting specific instructions or questions that effectively communicate the user's intent to the AI system, thereby enhancing the relevance and accuracy of the generated responses.
In the context of generative AI, which includes models capable of creating text, images, or other content, prompt engineering is crucial for several reasons:
-
Improving Output Quality: Well-crafted prompts help AI models better understand the nuances and intent behind a query, leading to more accurate and contextually appropriate responses.
-
Enhancing Model Comprehension: By providing clear and detailed prompts, users can assist AI models in comprehending complex or technical queries, thereby improving the model's ability to generate relevant outputs.
-
Mitigating Biases and Errors: Effective prompt engineering involves iterative refinement of prompts to minimize biases and confusion, which helps in producing more accurate and unbiased responses from AI models.
-
Expanding AI Capabilities: Through strategic prompt design, users can leverage AI models to perform a wide range of tasks, from answering simple questions to generating complex technical content, thereby maximizing the utility of generative AI systems.
In summary, prompt engineering serves as a vital interface between human intent and AI-generated content, playing a key role in harnessing the full potential of generative AI technologies.
RAG is a framework that enhances the generation of responses from a language model by augmenting it with external, up-to-date, and relevant information retrieved from specific data sources (like the web, documents, or databases).
In the context of RAG, think of the LLM Knowledge as the central piece, but it is being fed with various retrieval sources:
- Web: External data fetched from the internet.
- PDF: Information extracted from documents.
- Code: Programmatic knowledge or examples retrieved from code bases.
- Video Transcript: Information extracted from video transcripts to include context from audiovisual content.
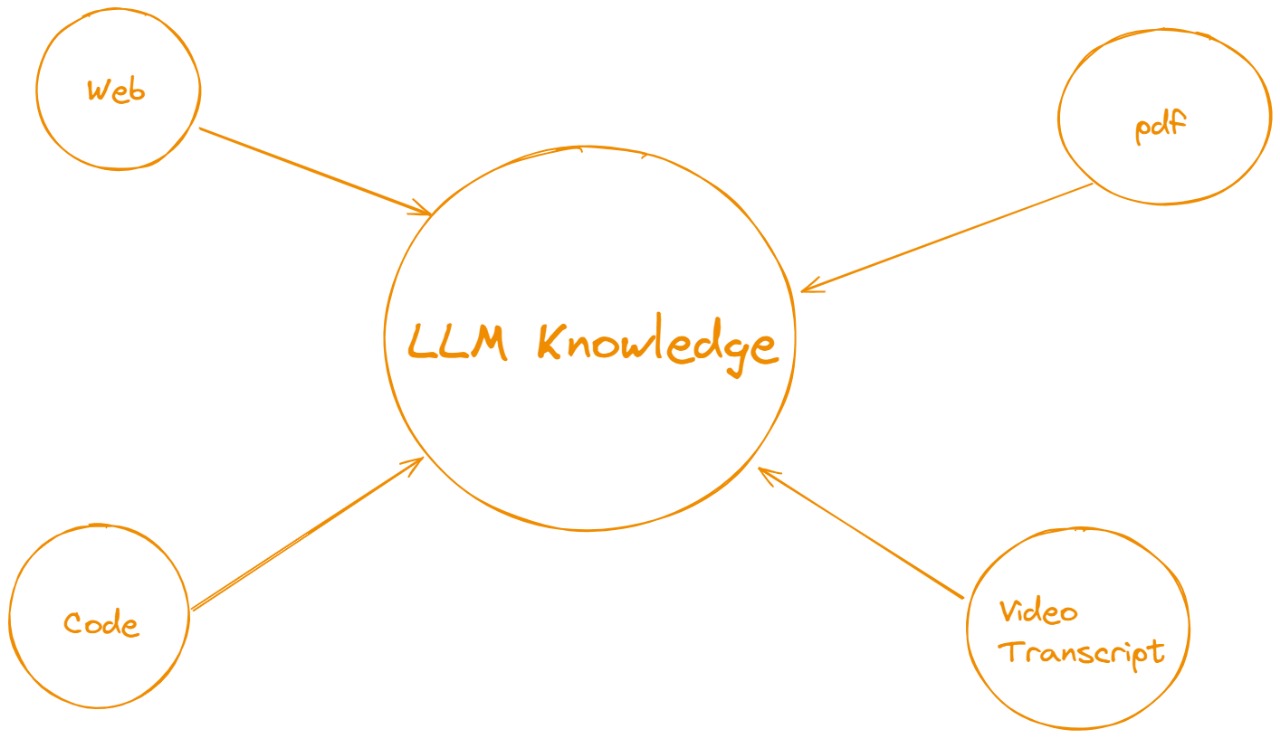
The RAG process involves retrieving relevant data from these sources, and the LLM then uses this data to generate a response. The retrieved information supplements the LLM's knowledge, resulting in more accurate and context-aware outputs.
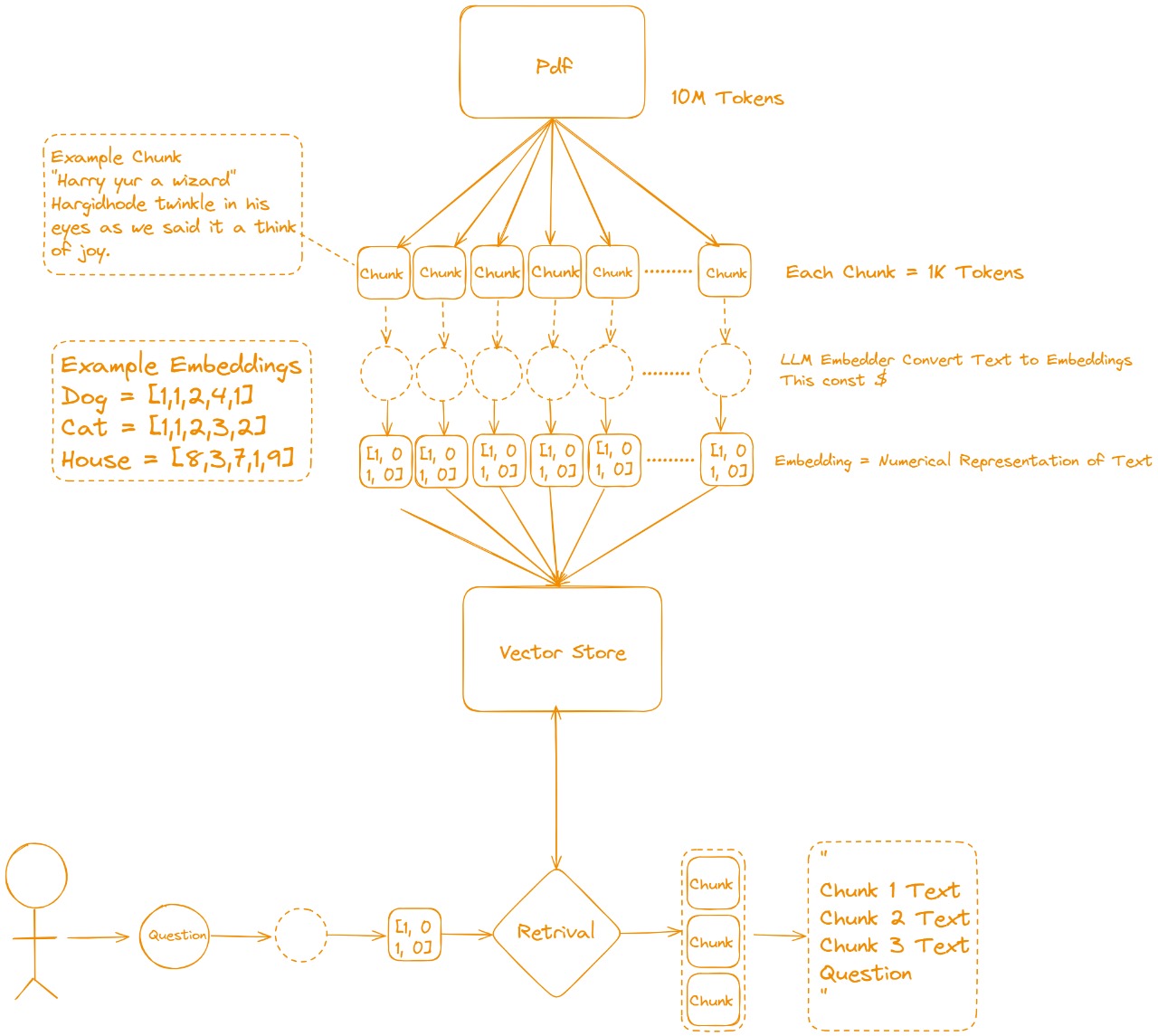
Web pages, PDFs, policy docs, code bases, video transcripts, anything you can turn into text is fair game. These sources live outside the model and can be updated independently.
Large documents are sliced into small, overlapping passages (typically 300-1 000 tokens). This keeps each piece topically focused and cheap to search.
Every chunk is converted into a numerical vector that captures semantic meaning. Similar ideas land near one another in this high-dimensional space.
A purpose-built database (Pinecone, Chroma, Weaviate, etc.) stores those vectors and supports lightning-fast similarity search, plus metadata filters and access controls.
When a user asks a question, their query is embedded too. The system pulls the k most similar chunks—often refined with hybrid keyword + semantic search to boost precision.
Retrieved chunks are “stapled” onto the user’s question, along with system instructions like “Cite all sources and answer only from provided context.”
The language model now drafts its reply, grounding every claim in the supplied passages. Many implementations surface inline citations so users can audit each fact.
- Efficiency: Instead of passing an entire document to the model, RAG retrieves only the most relevant chunks, reducing the computational load.
- Accuracy: By using real-time data retrieval, the model can generate more accurate and context-aware answers.
- Scalability:: RAG can scale to handle large volumes of text, as it uses chunking and efficient retrieval techniques to access specific parts of the document.
Fine-tuning moves beyond clever prompts or run-time retrieval by re-training an LLM’s weights on your own examples. A short, extra training phase nudges the model’s millions of parameters so it naturally speaks in your brand voice, uses domain jargon, follows fixed output formats, or executes niche tasks—even when you give it a tiny prompt.
How it’s done
-
Collect high-quality prompt-response pairs (a few thousand good ones usually beat tens of thousands of noisy ones).
-
Pick a strategy
- Full fine-tune – update all weights on a small/medium model for maximum control.
- LoRA / PEFT adapters – insert small trainable matrices into a frozen large model: cheaper, popular for chatbots.
- Instruction-tune – adjust only upper layers to enforce politeness, JSON output, etc.
-
Train & monitor until validation loss plateaus, then evaluate with safety and hallucination tests.
-
Deploy the resulting checkpoint, optionally quantised for edge devices, and version it like any other binary.
Why people do it
- Consistency – personality and formatting are baked in; no giant system prompts required.
- Offline / air-gapped use – all knowledge sits inside the model weights, no external DB calls.
- Latency & throughput – deterministic answers for high-volume classification or extraction tasks.
Trade-offs
- Up-front cost – GPUs, data labelling, and ML-Ops infrastructure.
- Maintenance – new facts mean another training round (or you add a RAG layer on top).
- Risk of over-fit – too little or biased data can narrow the model’s general reasoning.
When it’s the right tool
Choose fine-tuning when you must lock in brand tone at scale, run on secure hardware with no internet, or deliver ultra-fast, structured outputs (e.g., invoice coding). Stick with prompt engineering for quick prototypes, and add RAG when you simply need fresher facts.
LangChain is an open‑source Python framework that streamlines the creation of applications powered by large language models. It offers a high‑level interface for prompt management, chaining multiple model calls, connecting to external data sources, and orchestrating tool usage such as web search or code execution. By abstracting away repetitive boilerplate API calls, token counting, retry logic, and rate‑limiting, LangChain lets developers focus on product logic while still retaining low‑level control when needed.
- Models – Wrappers for proprietary (OpenAI, Anthropic) and open-source (Llama, Mistral) LLMs.
- Prompts & Prompt Templates – Reusable, parameterised instructions that keep your prompt engineering organized.
- Chains – Composable workflows that pass the output of one step into the next, enabling multi-step reasoning or data pipelines.
- Retrievers & Vector Stores – Plug-ins for Retrieval-Augmented Generation (RAG) that ground model output in private or real-time knowledge.
- Agents & Tools – Higher-order abstractions allowing an LLM to decide which actions to take (e.g., run a search query, call an API) in order to meet a user goal.
Together, these components transform a raw LLM into a fully-fledged, context-aware application with minimal code.
