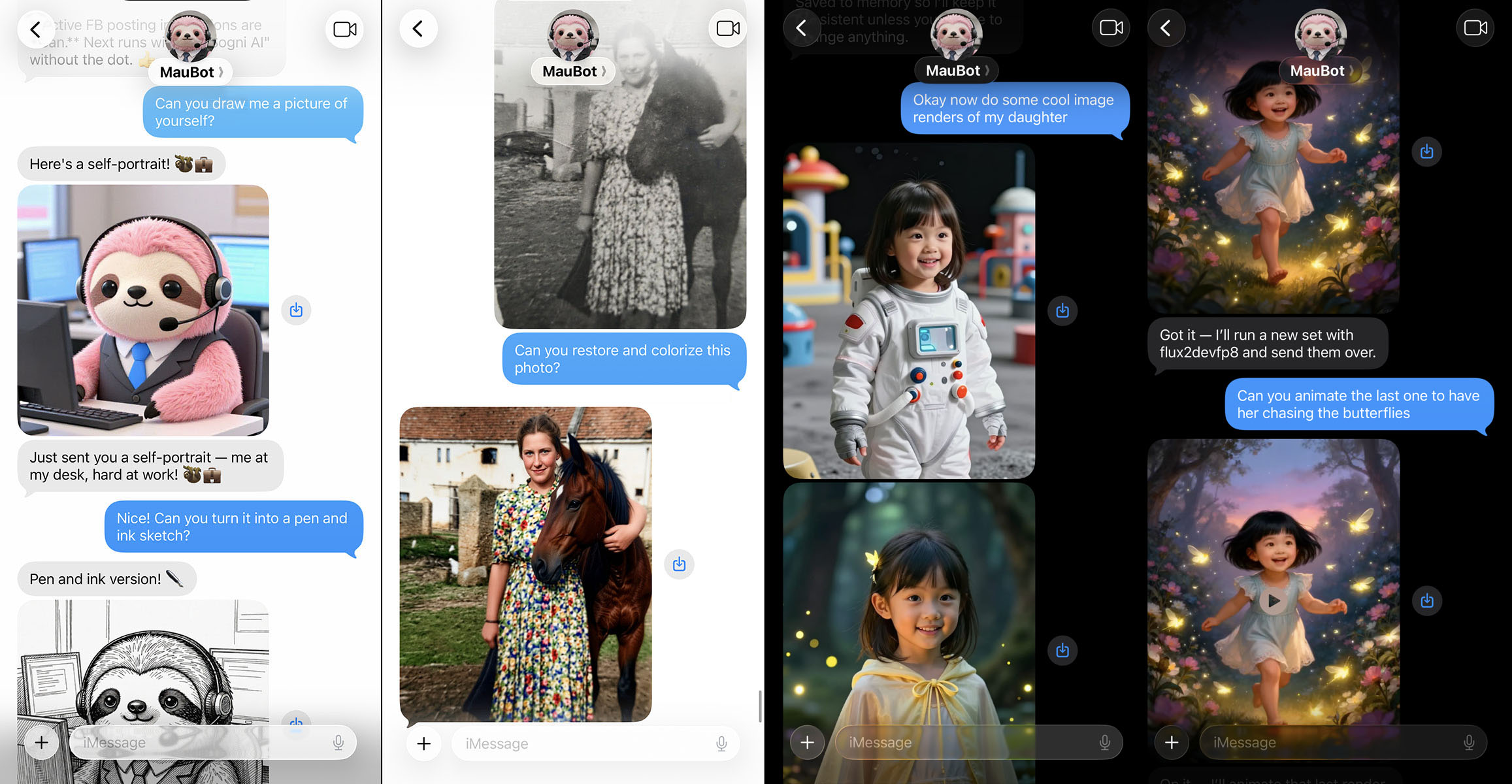
🎨 Generate images and videos using Sogni AI's decentralized GPU network.
Works as:
- an MCP server for Claude Code, Claude Desktop, and any MCP-compatible agent
- an OpenClaw plugin
- a skill source for Hermes Agent, Manus AI, and other agent frameworks
- a standalone Node.js CLI
- Create Sogni credentials (one-time): see Setup.
- Install for your platform:
# MCP (Claude Code — one command)
claude mcp add sogni -- npx -y -p sogni-gen sogni-gen-mcp
# OpenClaw
openclaw plugins install sogni-gen
# Hermes Agent / Manus / other frameworks — point to this repo:
# https://github.com/Sogni-AI/openclaw-sogni-gen
# Standalone CLI
npm install -g sogni-genThen ask your agent:
- "Generate an image of a sunset over mountains"
- "Generate a pro quality image of a mountain landscape"
- "Make a video of a cat playing piano"
- "Edit this image to add a rainbow"
- "Check my Sogni balance"
- "Turn my selfie into James bond using photobooth"
- "Animate the last 3 images you generated together"
- "Generate 3 variations of a sports car in red, blue, and green"
- "Refine the last image at higher quality"
openclaw plugins install sogni-genThe installed plugin loads its behavior from SKILL.md via openclaw.plugin.json.
Point the agent to this repository's SKILL.md for behavior guidance and llm.txt for install/setup help. The agent can then invoke sogni-gen via the CLI or MCP server.
git clone git@github.com:Sogni-AI/openclaw-sogni-gen.git
cd openclaw-sogni-gen
npm installIf OpenClaw loads this plugin, sogni-gen reads defaults from your OpenClaw config:
{
"plugins": {
"entries": {
"sogni-gen": {
"enabled": true,
"config": {
"defaultImageModel": "z_image_turbo_bf16",
"defaultEditModel": "qwen_image_edit_2511_fp8_lightning",
"defaultPhotoboothModel": "coreml-sogniXLturbo_alpha1_ad",
"videoModels": {
"t2v": "wan_v2.2-14b-fp8_t2v_lightx2v",
"i2v": "wan_v2.2-14b-fp8_i2v_lightx2v",
"s2v": "wan_v2.2-14b-fp8_s2v_lightx2v",
"ia2v": "ltx2-19b-fp8_ia2v_distilled",
"a2v": "ltx2-19b-fp8_a2v_distilled",
"v2v": "ltx2-19b-fp8_v2v_distilled",
"animate-move": "wan_v2.2-14b-fp8_animate-move_lightx2v",
"animate-replace": "wan_v2.2-14b-fp8_animate-replace_lightx2v"
},
"defaultVideoWorkflow": "t2v",
"defaultNetwork": "fast",
"defaultTokenType": "spark",
"seedStrategy": "prompt-hash",
"modelDefaults": {
"flux1-schnell-fp8": { "steps": 4, "guidance": 3.5 },
"flux2_dev_fp8": { "steps": 20, "guidance": 7.5 }
},
"defaultWidth": 768,
"defaultHeight": 768,
"defaultCount": 1,
"defaultFps": 16,
"defaultDurationSec": 5,
"defaultImageTimeoutSec": 30,
"defaultVideoTimeoutSec": 300,
"credentialsPath": "~/.config/sogni/credentials",
"lastRenderPath": "~/.config/sogni/last-render.json",
"mediaInboundDir": "~/.clawdbot/media/inbound"
}
}
}
}
}CLI flags always override these defaults. If your OpenClaw config lives elsewhere, set OPENCLAW_CONFIG_PATH. Seed strategies: prompt-hash (deterministic) or random.
- Create a Sogni account at https://app.sogni.ai/
- Create credentials file:
mkdir -p ~/.config/sogni
cat > ~/.config/sogni/credentials << 'EOF'
SOGNI_API_KEY=your_api_key
# or:
# SOGNI_USERNAME=your_username
# SOGNI_PASSWORD=your_password
EOF
chmod 600 ~/.config/sogni/credentialsYou can also skip the file and set SOGNI_API_KEY, or SOGNI_USERNAME + SOGNI_PASSWORD, in your environment.
By default, the runtime reads/writes:
- Credentials file:
~/.config/sogni/credentials(read) - Last render metadata:
~/.config/sogni/last-render.json(read/write) - OpenClaw config:
~/.openclaw/openclaw.json(read) - Inbound media listing (
--list-media):~/.clawdbot/media/inbound(read) - MCP local result copies:
~/Downloads/sogni(write)
Override with environment variables:
SOGNI_CREDENTIALS_PATHSOGNI_LAST_RENDER_PATHSOGNI_MEDIA_INBOUND_DIROPENCLAW_CONFIG_PATHSOGNI_DOWNLOADS_DIR(MCP)SOGNI_MCP_SAVE_DOWNLOADS=0(disable MCP local file writes)SOGNI_ALLOWED_DOWNLOAD_HOSTS(comma-separated HTTPS host suffixes the MCP server may auto-download locally)
claude mcp add sogni -- npx -y -p sogni-gen sogni-gen-mcpAdd to ~/Library/Application Support/Claude/claude_desktop_config.json:
{
"mcpServers": {
"sogni": {
"command": "npx",
"args": ["-y", "-p", "sogni-gen", "sogni-gen-mcp"]
}
}
}Restart Claude Desktop after saving.
npm install -g sogni-gen
sogni-gen --versionIf sogni-gen-mcp is on your PATH, you can register it directly:
# Claude Code using globally installed binary
claude mcp add sogni -- sogni-gen-mcpClaude Desktop config using global binary:
{
"mcpServers": {
"sogni": {
"command": "sogni-gen-mcp",
"args": []
}
}
}The MCP server exposes these tools to Claude Code and Claude Desktop:
| Tool | Description |
|---|---|
generate_image |
Generate images with quality presets, prompt variations, and full model control |
generate_video |
Multi-workflow video generation (t2v, i2v, s2v, ia2v, a2v, v2v, animate) |
edit_image |
Edit images using 1-3 context images and a prompt |
photobooth |
Face transfer portraits with InstantID |
refine_result |
Re-run the last generation with tweaked parameters (quality, model, seed, etc.) |
estimate_cost |
Estimate generation cost before running (precise for video, heuristic for images) |
check_balance |
Show current SPARK/SOGNI token balances |
list_models |
List all available models with speed estimates |
manage_memory |
Save/read/delete persistent user preferences across sessions |
manage_personality |
Get/set/clear custom agent personality instructions |
manage_personas |
CRUD for named people with reference photos and voice clips |
apply_style |
Apply artistic styles to images (Warhol, Ghibli, Banksy, etc.) |
change_angle |
Generate a photo from a different camera angle |
extract_last_frame |
Extract the last frame from a video as an image |
concat_videos |
Concatenate multiple video clips into one |
list_media |
List recent inbound media files |
get_version |
Show running sogni-gen version |
# Generate image, get URL
node sogni-gen.mjs "a dragon eating tacos"
# Quality presets (recommended — no need to remember model IDs)
node sogni-gen.mjs -Q fast "a dragon eating tacos" # z_image_turbo, 8 steps, 512x512
node sogni-gen.mjs -Q hq "a dragon eating tacos" # z_image_turbo, default steps, 768x768
node sogni-gen.mjs -Q pro "a dragon eating tacos" # flux2_dev, 40 steps, 1024x1024
# Save to file
node sogni-gen.mjs -o dragon.png "a dragon eating tacos"
# JSON output
node sogni-gen.mjs --json "a dragon eating tacos"
# Dynamic prompt variations — generate diverse images in one call
node sogni-gen.mjs -n 3 "a {red|blue|green} sports car on a highway"
node sogni-gen.mjs -n 4 "a cat {sleeping|playing|eating|running} in a {garden|kitchen|bedroom|park}"
# Token auto-fallback (tries SPARK first, falls back to SOGNI)
node sogni-gen.mjs --token-type auto "a dragon eating tacos"
# Check token balances (no prompt required)
node sogni-gen.mjs --balance
# Check token balances with JSON output
node sogni-gen.mjs --json --balance
# Different model (overrides --quality if both set)
node sogni-gen.mjs -m flux1-schnell-fp8 "a dragon eating tacos"
# JPG output
node sogni-gen.mjs --output-format jpg -o dragon.jpg "a dragon eating tacos"
# Photobooth (face transfer)
node sogni-gen.mjs --photobooth --ref face.jpg "80s fashion portrait"
node sogni-gen.mjs --photobooth --ref face.jpg -n 4 "LinkedIn professional headshot"
# Image edit with LoRA
node sogni-gen.mjs -c subject.jpg --lora sogni_lora_v1 --lora-strength 0.7 \
"add a neon cyberpunk glow"
# Multiple angles (Qwen + Multiple Angles LoRA)
node sogni-gen.mjs --multi-angle -c subject.jpg \
--azimuth front-right --elevation eye-level --distance medium \
--angle-strength 0.9 \
"studio portrait, same person"
# 360 turntable (8 azimuths)
node sogni-gen.mjs --angles-360 -c subject.jpg --distance medium --elevation eye-level \
"studio portrait, same person"
# 360 turntable video (looping mp4, uses i2v between angles; requires ffmpeg)
node sogni-gen.mjs --angles-360 --angles-360-video /tmp/turntable.mp4 \
-c subject.jpg --distance medium --elevation eye-level \
"studio portrait, same person"
# Text-to-video (t2v)
node sogni-gen.mjs --video "ocean waves at sunset"
# Image-to-video (i2v)
node sogni-gen.mjs --video --ref cat.jpg "gentle camera pan"
# Sound-to-video (s2v)
node sogni-gen.mjs --video --ref face.jpg --ref-audio speech.m4a \
-m wan_v2.2-14b-fp8_s2v_lightx2v "lip sync talking head"
# Image+audio-to-video (ia2v, LTX)
node sogni-gen.mjs --video --workflow ia2v --ref cover.jpg --ref-audio song.mp3 \
"music video with synchronized motion"
# Audio-to-video (a2v, LTX)
node sogni-gen.mjs --video --workflow a2v --ref-audio song.mp3 \
"abstract audio-reactive visualizer"
# LTX-2.3 text-to-video
node sogni-gen.mjs --video -m ltx23-22b-fp8_t2v_distilled --duration 20 \
"A wide cinematic aerial shot opens over steep tropical cliffs at golden hour, warm sunlight grazing the rock faces while sea mist drifts above the water below. Palm trees bend gently along the ridge as waves roll against the shoreline, leaving bright bands of foam across the dark stone. The camera glides forward in one continuous pass, revealing more of the coastline as sunlight flickers across wet surfaces and distant birds wheel through the haze. The scene holds a calm, upscale travel-film mood with smooth stabilized motion and crisp environmental detail."
# Animate (motion transfer)
node sogni-gen.mjs --video --ref subject.jpg --ref-video motion.mp4 \
--workflow animate-move "transfer motion"
# Estimate video cost (requires --steps)
node sogni-gen.mjs --video --estimate-video-cost --steps 20 \
-m wan_v2.2-14b-fp8_t2v_lightx2v "ocean waves at sunset"When you use ltx23-22b-fp8_t2v_distilled, do not feed it short tag prompts like "cinematic drone shot over tropical cliffs". LTX-2.3 renders more reliably from a dense natural-language scene description.
- Write one unbroken paragraph with no line breaks, bullets, headers, or tag blocks.
- Use 4-8 flowing present-tense sentences describing one continuous shot, not a montage.
- Start with shot scale and scene identity, then cover environment, time of day, textures, and named light sources.
- Keep characters and objects concrete and stable. Describe one main action thread from start to finish.
- If the user wants dialogue, weave it into the prose with the speaker and delivery identified inline.
- Express mood through visible behavior, motion, and sound cues instead of vague adjectives.
- Use positive phrasing. Avoid script formatting, negative prompts, on-screen text/logo requests, and generic filler words like "beautiful" or "nice".
- Match scene density to clip length. For the default short clips, describe one main beat rather than several unrelated actions.
Example rewrite:
User ask: "make a 4k video of a woman in a neon alley"
LTX-2.3 prompt: "A medium cinematic shot frames a woman in her 30s standing in a rain-soaked neon alley at night, violet and amber signs reflecting across the wet pavement while warm steam drifts from street vents. She wears a dark trench coat with damp strands of black hair clinging near her cheek as light glances across the fabric texture and the brick walls behind her. She turns toward the camera and steps forward with measured focus, one hand tightening around the strap of her bag while rain taps softly on the metal fire escape and a distant train hum rolls through the block. The camera performs a slow push-in as her jaw sets and her breathing steadies, maintaining smooth stabilized motion and a tense urban-thriller mood."
Generate stylized portraits from a face photo using InstantID ControlNet:
# Basic photobooth
node sogni-gen.mjs --photobooth --ref face.jpg "80s fashion portrait"
# Multiple outputs
node sogni-gen.mjs --photobooth --ref face.jpg -n 4 "LinkedIn professional headshot"
# Custom ControlNet tuning
node sogni-gen.mjs --photobooth --ref face.jpg --cn-strength 0.6 --cn-guidance-end 0.5 "oil painting"
# Custom model
node sogni-gen.mjs --photobooth --ref face.jpg -m coreml-dreamshaperXL_v21TurboDPMSDE "anime style"Uses SDXL Turbo (coreml-sogniXLturbo_alpha1_ad) at 1024x1024 by default. The face image is passed via --ref and styled according to the prompt. Cannot be combined with --video or -c/--context.
Multi-angle mode auto-builds the <sks> prompt and applies the multiple_angles LoRA.
--angles-360-video generates i2v clips between consecutive angles (including last→first) and concatenates them with ffmpeg for a seamless loop.
--balance / --balances does not require a prompt and exits after printing current SPARK and SOGNI balances.
- WAN models use dimensions divisible by 16, min 480px, max 1536px.
- LTX family models (
ltx2-*,ltx23-*) use dimensions divisible by 64. A practical default range is 768px to 1920px. - The script auto-normalizes video sizes to satisfy those constraints.
- For i2v (and any workflow using
--ref/--ref-end), the client wrapper resizes the reference image with a strict aspect-fit (fit: inside) and then uses the resized reference dimensions as the final video size. Because that resize uses rounding, a “valid” requested size can still produce an invalid final size (example:1024x1536requested, but ref becomes1024x1535). sogni-gendetects this for local refs and will auto-adjust the requested size to a nearby safe size so the resized reference is divisible by 16.- If you want the script to fail instead of auto-adjusting, pass
--strict-sizeand it will print a suggested size.
- Exit code is non-zero on failure.
- Default output is human-readable errors on stderr.
- With
--json, the script prints a single JSON object to stdout for both success and failure.- For
--balance, success output looks like:{"success": true, "type": "balance", "spark": <number|null>, "sogni": <number|null>, ...} - On failure:
{"success": false, "error": "...", "errorCode": "...?", "errorDetails": {...}?, "hint": "...?", "context": {...}?}
- For
- When invoked by OpenClaw, errors are always returned as JSON (and also logged to stderr for humans).
-Q, --quality <tier> Quality preset: fast|hq|pro (auto-selects model/steps/size)
-o, --output <path> Save image to file
-m, --model <id> Model (default: z_image_turbo_bf16, overrides --quality)
-w, --width <px> Width (default: 512)
-h, --height <px> Height (default: 512)
-n, --count <num> Number of images (default: 1)
-t, --timeout <sec> Timeout (default: 30)
-s, --seed <num> Specific seed
--last-seed Reuse last seed
--seed-strategy <s> random|prompt-hash
--multi-angle Multiple angles LoRA mode (Qwen Image Edit)
--angles-360 Generate 8 azimuths (front -> front-left)
--angles-360-video Assemble a looping 360 mp4 using i2v between angles (requires ffmpeg)
--azimuth <key> front|front-right|right|back-right|back|back-left|left|front-left
--elevation <key> low-angle|eye-level|elevated|high-angle
--distance <key> close-up|medium|wide
--angle-strength <n> LoRA strength for multiple_angles (default: 0.9)
--angle-description <text> Optional subject description
--output-format <f> Image output format: png|jpg
--steps <num> Override steps (model-dependent)
--guidance <num> Override guidance (model-dependent)
--sampler <name> Sampler (model-dependent)
--scheduler <name> Scheduler (model-dependent)
--lora <id> LoRA id (repeatable, edit only)
--loras <ids> Comma-separated LoRA ids
--lora-strength <n> LoRA strength (repeatable)
--lora-strengths <n> Comma-separated LoRA strengths
--token-type <type> spark|sogni|auto (auto retries with alternate token on insufficient balance)
--balance, --balances Show SPARK/SOGNI balances and exit
--version, -V Show sogni-gen version and exit
--video, -v Generate video instead of image
--workflow <type> t2v|i2v|s2v|ia2v|a2v|v2v|animate-move|animate-replace
--fps <num> Frames per second (video)
--duration <sec> Video duration in seconds
--frames <num> Override total frames (video)
--auto-resize-assets Auto-resize video reference assets
--no-auto-resize-assets Disable auto-resize for video assets
--estimate-video-cost Estimate video cost and exit (requires --steps)
--photobooth Face transfer mode (InstantID + SDXL Turbo)
--cn-strength <n> ControlNet strength (default: 0.8)
--cn-guidance-end <n> ControlNet guidance end point (default: 0.3)
--ref <path|url> Reference image for i2v/s2v/animate/photobooth
--ref-end <path|url> End frame for i2v interpolation
--ref-audio <path> Reference audio for s2v
--ref-video <path> Reference video for animate workflows
-c, --context <path> Context image(s) for editing (repeatable)
--last-image Use last image as context/ref
--json JSON output
--strict-size Do not auto-adjust i2v video size for reference resizing constraints
-q, --quiet Suppress progress
--no-filter Disable NSFW content filter
--memory-set <k> <v> Save a user preference
--memory-get <key> Get a specific memory
--memory-list List all saved memories
--memory-remove <key> Delete a memory
--personality-set <t> Set custom personality instructions
--personality-get Show current personality
--personality-clear Reset personality to default
--persona-add <name> Add persona (with --ref, --relationship, --description, --voice-clip)
--persona-list List all personas
--persona-remove <n> Remove a persona
--persona-resolve <n> Look up a persona
--persona <name> Generate using persona's reference photo
--relationship <type> self|partner|child|friend|pet
--voice-clip <path> Voice clip for LTX-2.3 voice cloning
Instead of remembering model IDs, use --quality / -Q to auto-select the right model, steps, and dimensions:
| Preset | Model | Steps | Size | Speed |
|---|---|---|---|---|
fast |
z_image_turbo_bf16 | 8 | 512x512 | ~5-10s |
hq |
z_image_turbo_bf16 | default | 768x768 | ~10-15s |
pro |
flux2_dev_fp8 | 40 | 1024x1024 | ~2min |
Explicit --model overrides the quality preset's model. Explicit -w/-h overrides dimensions.
Generate diverse images in a single call using {option1|option2|option3} syntax:
# Generates 3 images: "a red car", "a blue car", "a green car"
node sogni-gen.mjs -n 3 "a {red|blue|green} car"
# Multiple variation groups cycle independently
node sogni-gen.mjs -n 4 "a {cat|dog} in a {garden|kitchen}"
# → "a cat in a garden", "a dog in a kitchen", "a cat in a garden", "a dog in a kitchen"Options cycle sequentially per image. Without {...} syntax, -n generates multiple images with the same prompt as before.
Use --token-type auto to automatically retry with SOGNI tokens if SPARK balance is insufficient:
node sogni-gen.mjs --token-type auto "a dragon eating tacos"This tries SPARK first (free daily tokens), then falls back to SOGNI if the balance is too low.
Named people with saved reference photos and optional voice clips for identity-preserving generation:
# Add a persona
node sogni-gen.mjs --persona-add "Mark" --ref face.jpg --relationship self --description "30s male, brown hair"
# Add with voice clip for video voice cloning
node sogni-gen.mjs --persona-add "Sarah" --ref sarah.jpg --relationship partner --voice-clip voice.webm
# Generate using a persona (auto-injects photo as context)
node sogni-gen.mjs --persona "Mark" -o hero.png "superhero in dramatic lighting"
# List / remove
node sogni-gen.mjs --persona-list
node sogni-gen.mjs --persona-remove "Mark"Personas are stored at ~/.config/sogni/personas/. Pronouns like "me"/"myself" auto-resolve to the self persona. "my wife" resolves to partner, etc.
Save preferences that agents respect across sessions:
node sogni-gen.mjs --memory-set preferred_style "watercolor and soft lighting"
node sogni-gen.mjs --memory-set aspect_ratio "16:9"
node sogni-gen.mjs --memory-list
node sogni-gen.mjs --memory-remove preferred_styleStored at ~/.config/sogni/memories.json.
Set how the agent should behave:
node sogni-gen.mjs --personality-set "Be concise, always use cinematic lighting"
node sogni-gen.mjs --personality-get
node sogni-gen.mjs --personality-clearStored at ~/.config/sogni/personality.txt.
| Model | Speed | Notes |
|---|---|---|
z_image_turbo_bf16 |
~5-10s | Default, general purpose |
flux1-schnell-fp8 |
~3-5s | Fast iterations |
flux2_dev_fp8 |
~2min | High quality |
chroma-v.46-flash_fp8 |
~30s | Balanced |
qwen_image_edit_2511_fp8 |
~30s | Image editing with context |
qwen_image_edit_2511_fp8_lightning |
~8s | Fast image editing |
coreml-sogniXLturbo_alpha1_ad |
Fast | Photobooth face transfer (SDXL Turbo) |
wan_v2.2-14b-fp8_t2v_lightx2v |
~5min | Text-to-video |
wan_v2.2-14b-fp8_i2v_lightx2v |
~3-5min | Image-to-video |
wan_v2.2-14b-fp8_s2v_lightx2v |
~5min | Sound-to-video |
wan_v2.2-14b-fp8_animate-move_lightx2v |
~5min | Animate-move |
wan_v2.2-14b-fp8_animate-replace_lightx2v |
~5min | Animate-replace |
ltx2-19b-fp8_t2v_distilled |
~2-3min | LTX-2 text-to-video |
ltx2-19b-fp8_i2v_distilled |
~2-3min | LTX-2 image-to-video |
ltx2-19b-fp8_ia2v_distilled |
~2-3min | LTX-2 image+audio-to-video |
ltx2-19b-fp8_a2v_distilled |
~2-3min | LTX-2 audio-to-video |
ltx2-19b-fp8_v2v_distilled |
~3min | LTX-2 video-to-video with ControlNet |
ltx23-22b-fp8_t2v_distilled |
~2-3min | LTX-2.3 text-to-video |
MIT