{kind=link}
For ease of interaction in a spreadsheet, people will often "join" together a parent dataset and a child dataset together in the same tab or sheet in a way that doesn't repeat parent data over and over. For example, let's say you have a parent dataset (e.g., companies) and a child dataset (e.g., contacts at those companies).
| A | B |
|---|---|
| valueA1 | valueB1 |
| valueA2 | valueB2 |
| A | C | D |
|---|---|---|
| valueA1 | valueC1 | valueD1 |
| valueA2 | valueC2 | valueD2 |
| valueA1 | valueC3 | valueD3 |
| valueA1 | valueC4 | valueD4 |
| valueA2 | valueC5 | valueD5 |
| valueA2 | valueC6 | valueD6 |
- Join together with A as the common column
| A | B | C | D |
|---|---|---|---|
| valueA1 | valueB1 | valueC1 | valueD1 |
| valueA1 | valueB1 | valueC3 | valueD3 |
| valueA1 | valueB1 | valueC4 | valueD4 |
| valueA2 | valueB2 | valueC2 | valueD2 |
| valueA2 | valueB2 | valueC5 | valueD5 |
| valueA2 | valueB2 | valueC6 | valueD6 |
- Drop redundant "parent" data
| A | B | C | D |
|---|---|---|---|
| valueA1 | valueB1 | valueC1 | valueD1 |
| valueC3 | valueD3 | ||
| valueC4 | valueD4 | ||
| valueA2 | valueB2 | valueC2 | valueD2 |
| valueC5 | valueD5 | ||
| valueC6 | valueD6 |
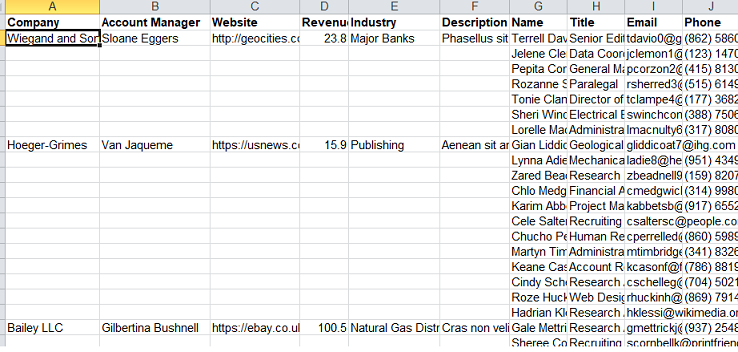
I needed to import into Salesforce the data from a panhandled spreadsheet with company and contact information mixed together. For this, I needed a properly formed database (tidy) structure to import into the Account object and a separate one to import into the Contact object. I looked through the tidyr package, but didn't see anything that would do what I needed done.
This is what the script does.
data/original.xlsx
data/parent.csvdata/child.csv
- The different "pans" (parent with children) can be separated by blank lines or not.
- All information except the "pans" has been deleted.
- The first column contains the keys for the parent and child datasets
- Read in the spreadsheet as our original table to work with
- In the original table, clear any blank rows used to separate parent/child groupings
- In the original table, collect together the rows with first columns that aren't blank and store in the parent table
- From the original table, fill the blanks cells in column 1 with the last non-blank value in that column (working down)
- Save just column 1 into a one-column (key) table we will use later
- From the original table, create a temporary table consisting of only the rows that are blank in the first column
- Using this temporary table, get the name of the first column in this table to figure out which number column is the beginning of the child columns in the original (where the panhandle meets the pan)
- Use this information to drop the columns that aren' t child columns and bind the remaining columns with the single key column created above to make a child table
- Return to the parent table to drop the columns that aren't parent columns
- Save out the the two new tables