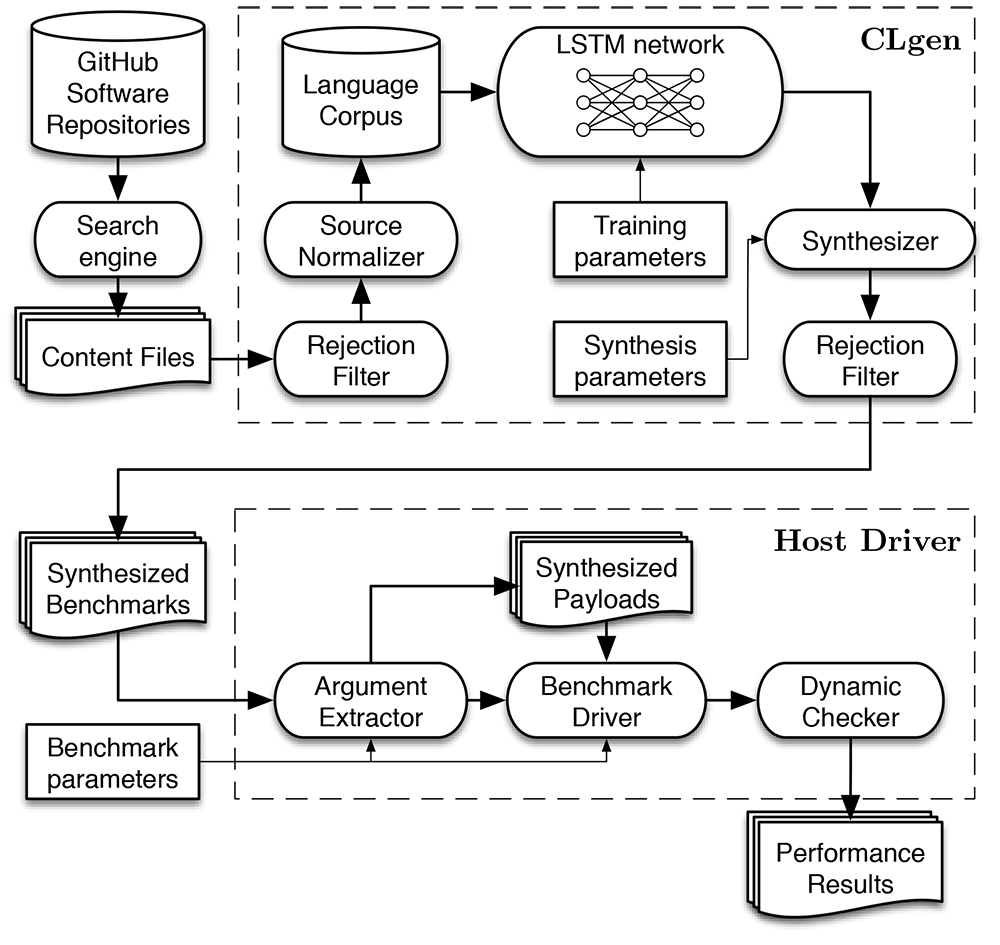
CLgen is an open source application for generating runnable programs using deep learning. CLgen learns to program using neural networks which model the semantics and usage from large volumes of program fragments, generating many-core OpenCL programs that are representative of, but distinct from, the programs it learns from.
Configure the build and answer the yes/no questions. The default answers should be fine:
$ ./configureNote that CUDA support requires CUDA to have been installed separately, see the TensorFlow build docs for instructions. CUDA support has only been tested for Linux builds, not macOS or Docker containers.
$ bazel build //deeplearning/clgenThe configure process generates a bootstrap.sh script which will install the
required dependent packages. Since installing these packages will affect the
global state of your system, and may requires root access, inspect this script
carefully. Once you're happy to proceed, run it using:
$ bash ./bootstrap.shFinally, we must set up the shell environment for running bazel. The file .env
is created by the configure process and must be sourced for every shell we want
to use bazel with:
$ source $PWD/.envUse our tiny example dataset to train and sample your first CLgen model:
$ bazel run //deeplearning/clgen -- \
--config $PWD/deeplearning/clgen/tests/data/tiny/config.pbtxt
CLgen is a tool for generating source code. How you use it will depend entirely on what you want to do with the generated code. As a first port of call I'd recommend checking out how CLgen is configured. CLgen is configured through a handful of protocol buffers defined in //deeplearning/clgen/proto. The clgen.Instance message type combines a clgen.Model and clgen.Sampler which define the way in which models are trained, and how new programs are generated, respectively. You will probably want to assemble a large corpus of source code to train a new model on - I have tools which may help with that. You may also want a means to execute arbitrary generated code - as it happens I have tools for that too. :-) Thought of a new use case? I'd love to hear about it!
Presentation slides:

Publication "Synthesizing Benchmarks for Predictive Modeling" (CGO'17).
Jupyter notebook containing experimental evaluation of an early version of CLgen.
My documentation sucks. Don't be afraid to get stuck in and start reading the code!
Copyright 2016, 2017, 2018, 2019 Chris Cummins [email protected].
Released under the terms of the GPLv3 license. See LICENSE for details.