This is for studying both neural network and CUDA.
I focused on simplicity and conciseness while coding. That means there is no error handling but assertations. It is a self-study result for better understanding of back-propagation algorithm. It'd be good if this C++ code fragment helps someone who has an interest in deep learning. CS231n from Stanford provides a good starting point to learn deep learning.
- 2D Convolutional
- Fully connected
- Batch normalization
- Relu
- Max pooling
- Dropout
- Mean squared error
- Cross entropy loss
- Adam
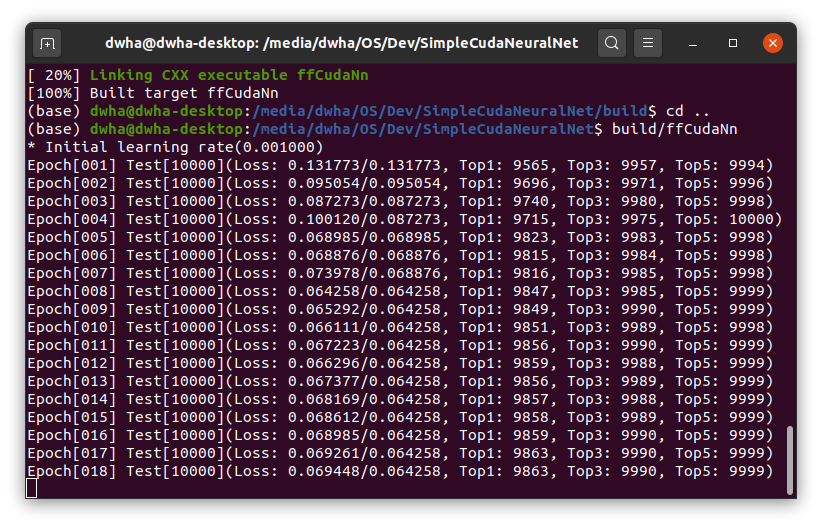
After basic components for deep learning implemented, I built a handwritten digit recognizer using MNIST database. A simple 2-layer FCNN(1000 hidden unit) could achieve 1.56% Top-1 error rate after 14 epochs which take less than 20 seconds of training time on RTX 2070 graphics card. (See mnist.cpp)
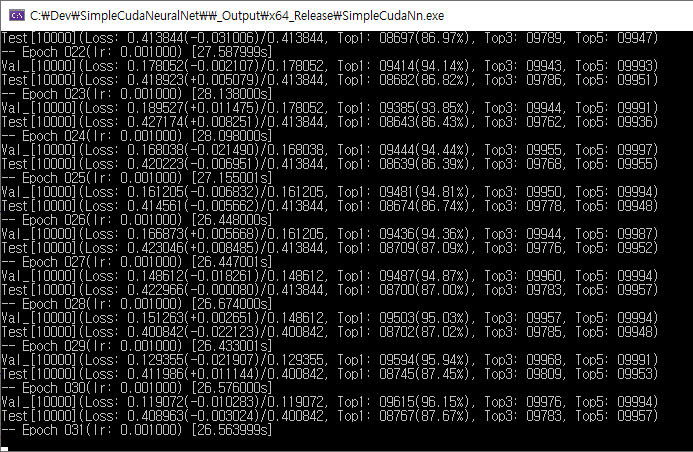
In cifar10.cpp, you can find a VGG-like convolutional network which has 8 weight layers. CIFAR-10 dataset is used to train the model. It achieves 12.3% top-1 error rate after 31 epoches. It took 26.5 seconds of training time per epoch on my RTX 2070. If you try a larger model and have enough time to train you can improve it.
- Even naive CUDA implementation easily speeds up by 700x more than single-core/no-SIMD CPU version.
- Double precision floating point on the CUDA kernels was 3~4x slower than single precision operations.
- Training performance is not comparable to PyTorch. PyTorch is much faster (x7~) to train the same model.
- Coding this kind of numerical algorithms is tricky and even hard to figure out if there is a bug or not. Thorough unit testing of every functions strongly recommended if you try.