etl engine readme for english
Batch stream integrated data exchange engine
Realize reading data from the source ->(target data type conversion | data distribution) ->writing to the target data source
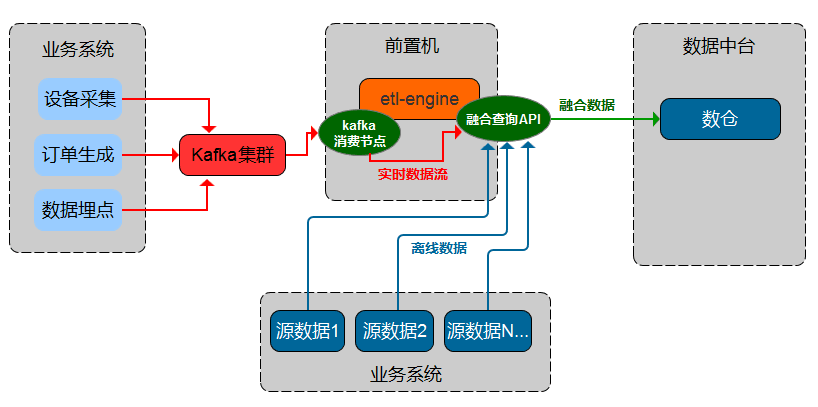
Support fusion computing queries during data stream transmission
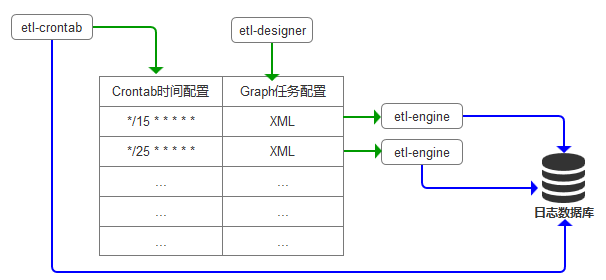
- Products are composed of etl-engine engine, etl-designer cloud designer and etl-crontab scheduling.
- Etl-engine parses etl configuration files and performs etl tasks.
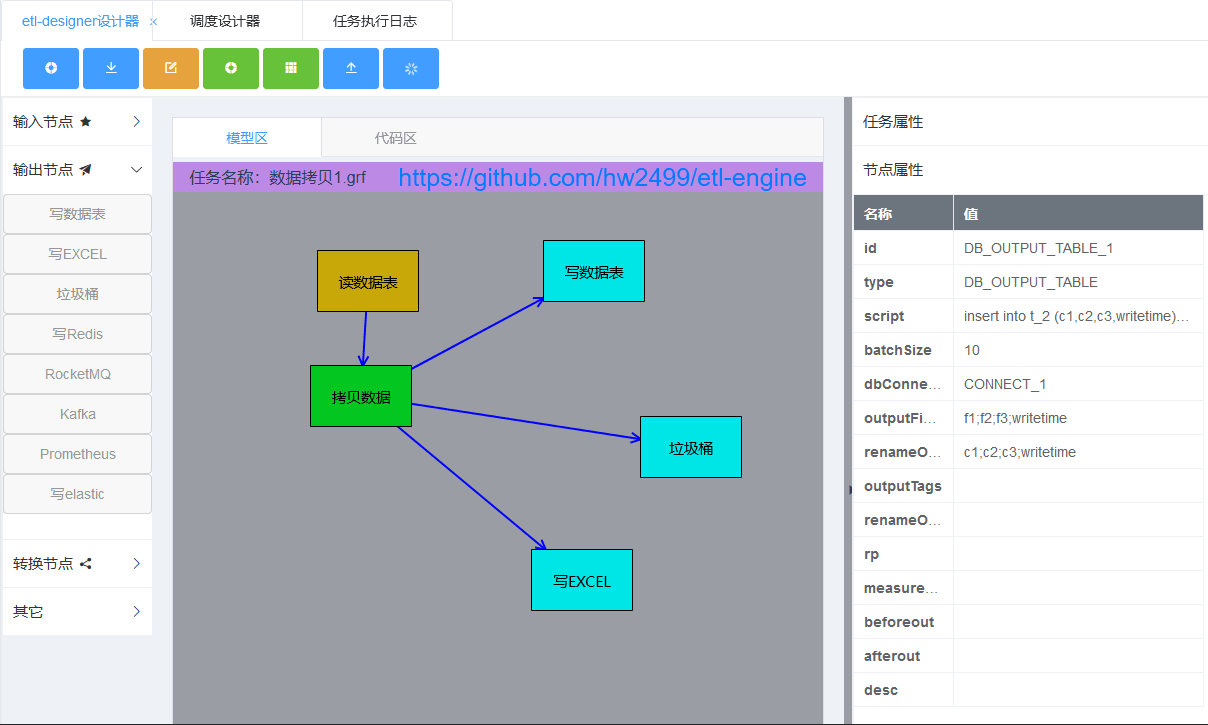
- The ETl-Designer cloud designer drag-and-drop generates etl task configuration files that are recognized by the ETl-Engine engine.
- The ETl-crontab scheduling designer is responsible for executing the specified etl task according to the time cycle. The ETL-crontab scheduling also provides the function of querying etl task execution logs.
- Three parts form an etl solution that can be integrated into any usage scenario.
High availability introduction
- etl-engine Download address
The last compile time of the current version is 20230310
- etl-designer The address of the designer video player
The etl-designer supports OEM publishing(currently integrated into etl_crontab)
- etl-crontab Scheduling designer video play address
- Sample etl-engine configuration file
- Supports cross-platform execution (windows,linux), requires only one executable and one configuration file to run, no other dependencies, lightweight engine.
- The input/output data source supports influxdb v1, clickhouse, prometheus, elasticsearch, hadoop(hive), postgresql, mysql, oracle, sqlite, rocketmq, kafka, redis, and excel
- Any input node can be combined with any output node, following the pipeline model.
- Support data fusion queries across multiple types of databases.
- Support data fusion calculation queries with multiple types of databases during message flow data transmission.
- The data fusion query syntax follows the ANSI SQL standard.
- To meet service requirements, you can use global variables in configuration files to dynamically update configuration files.
- Any output node can be embedded in the go language script and parsed to achieve the format conversion function of the output data stream.
- Supports secondary development at the node level. By configuring custom nodes and configuring go language scripts on custom nodes, various functions can be extended and implemented.
- Any input node can be copied by combining data flows to achieve a scenario where one input is branched to multiple outputs simultaneously.
- The execution logs of each node can be output to the database.
- Combined with crontab scheduling, etl-engine tasks are executed periodically.
- Any combination of input and output
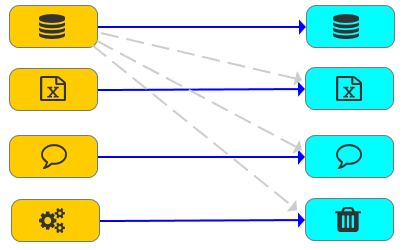
- Parsing embedded scripting language facilitates format conversion

- Data stream replication facilitates multiplexing

- Custom nodes facilitate various operations

- Transition nodes facilitate various transformations
- Streaming batch integrated query
Supports multi-source input, memory computing, and fused output
- Flexible combination of etl_crontab and etl_engine
- etl-designer
- Scheduling designer

- Scheduling log
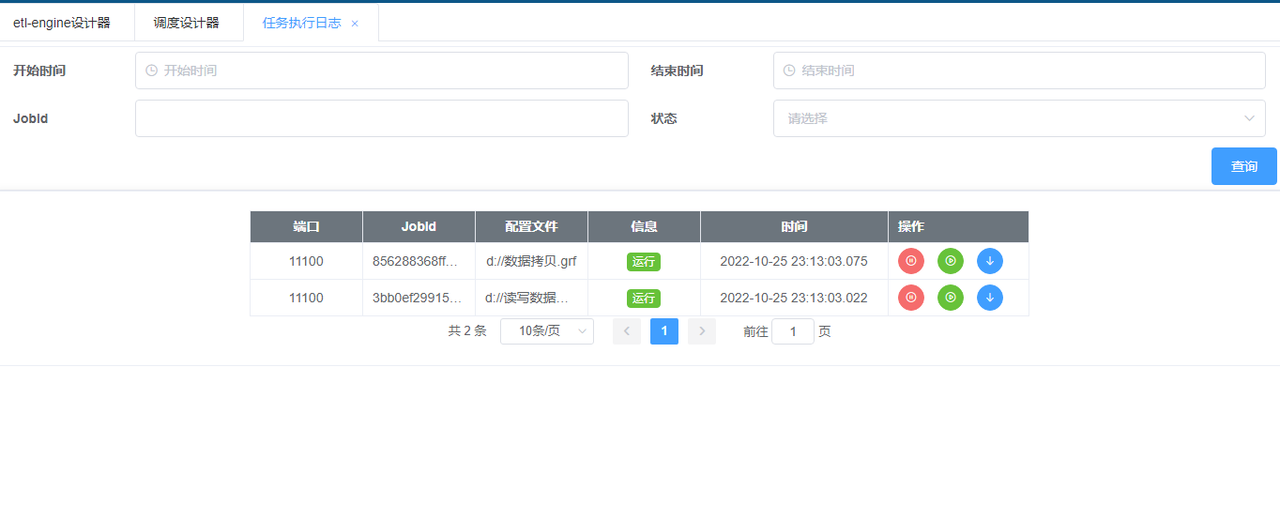
- Etl log details

etl_engine.exe -fileUrl .\graph.xml -logLevel info
etl_engine -fileUrl .\graph.xml -logLevel info
<?xml version="1.0" encoding="UTF-8"?>
<Graph>
<Node id="DB_INPUT_01" dbConnection="CONNECT_01" type="DB_INPUT_TABLE" desc="节点1" fetchSize="5">
<Script name="sqlScript"><![CDATA[
select * from (select * from t3 limit 10)
]]></Script>
</Node>
<Node id="DB_OUTPUT_01" type="DB_OUTPUT_TABLE" desc="node 2" dbConnection="CONNECT_02" outputFields="f1;f2" renameOutputFields="c1;c2" outputTags="tag1;tag4" renameOutputTags="tag_1;tag_4" measurement="t1" rp="autogen">
</Node>
<!--
<Node id="DB_OUTPUT_02" type="DB_OUTPUT_TABLE" desc="node 3" dbConnection="CONNECT_03" outputFields="f1;f2;f3" renameOutputFields="c1;c2;c3" batchSize="1000" >
<Script name="sqlScript"><![CDATA[
insert into db1.t1 (c1,c2,c3) values (?,?,?)
]]></Script>
</Node>
-->
<Line id="LINE_01" type="STANDARD" from="DB_INPUT_01" to="DB_OUTPUT_01" order="0" metadata="METADATA_01"></Line>
<Metadata id="METADATA_01">
<Field name="c1" type="string" default="-1" nullable="false"/>
<Field name="c2" type="int" default="-1" nullable="false"/>
<Field name="tag_1" type="string" default="-1" nullable="false"/>
<Field name="tag_4" type="string" default="-1" nullable="false"/>
</Metadata>
<Connection id="CONNECT_01" dbURL="http://127.0.0.1:58080" database="db1" username="user1" password="******" token=" " org="hw" type="INFLUXDB_V1"/>
<Connection id="CONNECT_02" dbURL="http://127.0.0.1:58086" database="db1" username="user1" password="******" token=" " org="hw" type="INFLUXDB_V1"/>
<!-- <Connection id="CONNECT_04" dbURL="127.0.0.1:19000" database="db1" username="user1" password="******" type="CLICKHOUSE"/>-->
<!-- <Connection id="CONNECT_03" dbURL="127.0.0.1:3306" database="db1" username="user1" password="******" type="MYSQL"/>-->
<!-- <Connection id="CONNECT_03" database="d:/sqlite_db1.db" batchSize="10000" type="SQLITE"/>-->
</Graph>Any read node can output to any write node
Input node - Read the data table
Output node - Write data table
Input node - Read excel file
Output Node - Write excel files
Input node - Execute database script
Output node - Trash can, no output
Input node -MQ consumer
Output node -MQ producer
The data stream copy node, located between the input node and the output node, is both output and input
Input node - Read redis
Output node - Write redis
Custom nodes, by embedding the go script to achieve various operations
Input Node - Execute system script node
Input node - Read CSV file node
Input Node - Read PROMETHEUS node
Input node -PROMETHEUS EXPORTER node
Output Node - Write PROMETHEUS node
Input node -Http node
Input node - Read elastic node
Output node - Write elastic node
Input Node - Read hive node
Any input node can be connected to any output nodeAny input node can connect to a copy nodeA copy node can connect to multiple output nodesAny input node can be connected to a transition nodeThe copy node cannot connect to the transition node
Input node
| attribute | description |
|---|---|
| id | Unique mark |
| type | The type is , DB_INPUT_TABLE |
| script | sqlScript SQL statement |
| fetchSize | Number of records read per session |
| dbConnection | Data source ID |
| desc | description |
MYSQL、Influxdb 1x、CK、PostgreSQL、Oracle、sqlite
<Node id="DB_INPUT_01" dbConnection="CONNECT_01" type="DB_INPUT_TABLE" desc="节点1" fetchSize="1000">
<Script name="sqlScript"><![CDATA[
select * from (select * from t4 limit 100000)
]]></Script>
</Node>Input node
| attribute | description |
|---|---|
| id | Unique mark |
| type | The type is , XLS_READER |
| fileURL | File path + file name |
| startRow | Read from row 1 with index 0 (usually column header) |
| sheetName | Table name |
| maxRow | The maximum number of lines read is *, which means all lines read, and 10, which means 10 lines read |
| fieldMap | Field mapping in the format of field1=A; field2=B; field3=C Field name = Number of columns Multiple fields are separated by semicolons |
<Node id="XLS_READER_01" type="XLS_READER" desc="Input node 1" fileURL="d:/demo/test1.xlsx" startRow="2" sheetName="Personnel information" fieldMap="field1=A;field2=B;field3=C">
</Node>Output node
| attribute | description | Suitable for |
|---|---|---|
| id | Unique mark | |
| type | The type is, DB_OUTPUT_TABLE | |
| script | insert、delete、update SQL statements | ck,mysql,sqlite,postgre,oracle |
| batchSize | The number of records committed per batch | ck,mysql,sqlite,postgre,oracle Note that influx entered with the fetchSize as the batch submitted size |
| outputFields | Enter the field name passed by the node when reading data | influx,ck,mysql,sqlite,postgre,oracle |
| renameOutputFields | The field name of the output node to the target data source | influx,ck,mysql,sqlite,postgre,oracle |
| dbConnection | Data source ID | |
| desc | description | |
| outputTags | Enter the label name passed by the node when reading data | influx |
| renameOutputTags | The label name of the output node to the target data source | influx |
| rp | Reserve policy name | influx |
| measurement | Table name | influx |
| timeOffset | The time jitter offset used to generate a non-repeatable timestamp when writing in bulk (This feature is implemented through time.Sleep, which suggests adding a nanosecond time column by embedding the script, or adjusting your time+tags.) |
influx |
MYSQL、Influxdb 1x、CK、PostgreSQL、Oracle、sqlite
<Node id="DB_OUTPUT_01" type="DB_OUTPUT_TABLE" desc="write influx node1" dbConnection="CONNECT_02" outputFields="f1;f2;f3;f4" renameOutputFields="c1;c2;c3;c4" outputTags="tag1;tag2;tag3;tag4" renameOutputTags="tag_1;tag_2;tag_3;tag_4" measurement="t5" rp="autogen">
</Node>
<Node id="DB_OUTPUT_02" type="DB_OUTPUT_TABLE" desc="write mysql node2" dbConnection="CONNECT_03" outputFields="time;f1;f2;f3;f4;tag1;tag2;tag3;tag4" renameOutputFields="time;c1;c2;c3;c4;tag_1;tag_2;tag_3;tag_4" batchSize="1000" >
<Script name="sqlScript"><![CDATA[
insert into db1.t1 (time,c1,c2,c3,c4,tag_1,tag_2,tag_3,tag_4) values (?,?,?,?,?,?,?,?,?)
]]></Script>
</Node>Output node
| attribute | description |
|---|---|
| id | Unique mark |
| type | XLS_WRITER |
| fileURL | File path + file name |
| startRow | For example, the number 2 indicates that data is written from the second line |
| sheetName | Table name |
| outputFields | Enter the name of the field passed by the node, Format: field1; field2; field3 |
| renameOutputFields | Field mapping, format: indicator =B; Year =C; Region =D Field name = Number of columns Multiple fields are separated by semicolons |
| metadataRow | The number of lines in the EXCEL file where the field name is displayed. For example, the number 1 indicates the field name that is started in line 1 |
| appendRow | true indicates the append record mode and false indicates the overwrite mode. |
<Node id="XLS_WRITER_01" type="XLS_WRITER" desc="Output node 2" appendRow="true" fileURL="d:/demo/test2.xlsx" startRow="3" metadataRow="2" sheetName="Personnel information" outputFields="c1;c3;tag_1" renameOutputFields="Index=B;Year=C;Region=D" >
</Node>Input node
| attribute | description | Suitable for |
|---|---|---|
| id | Unique mark | |
| type | DB_EXECUTE_TABLE | |
| roolback | Rollback or not | false is not rolled back. true is rolled back |
| sqlScript | delete、updatestatements are separated by semicolons | mysql,sqlite,postgre,oracle,ck(delete,update not supported) |
| fileURL | External file | fileURL has a higher priority than sqlScript, and only one of the two can be used |
<Node id="DB_EXECUTE_01" dbConnection="CONNECT_01" type="DB_EXECUTE_TABLE" desc="node 1" rollback="false" >
<Script name="sqlScript"><![CDATA[
insert into t_1 (uuid,name) values (13,'aaa');
insert into t_1 (uuid,name) values (14,'bbb');
insert into t_1 (uuid,name) values (15,'ccc');
insert into t_1 (uuid,name) values (1,'aaa')
]]></Script>Output node
Empty pipe with no output, suitable for the target node connected as a node without any output (for example, the DB_EXECUTE_TABLE node)
<Node id="OUTPUT_TRASH_01" type="OUTPUT_TRASH" desc="node 2" >
</Node>Input node, block mode
| attribute | description | Suitable for |
|---|---|---|
| id | Unique mark | |
| type | MQ_CONSUMER | |
| flag | Default value:ROCKETMQ | rocketmq is supported |
| nameServer | The address of the mq server is in the format of 127.0.0.1:8080 | |
| group | mq group name | |
| topic | Subscribed subject name | |
| tag | Label name, format: * represents all labels consumed, tag_1 means that only the tag_1 tag is consumed |
<Node id="MQ_CONSUMER_02" type="MQ_CONSUMER" flag="ROCKETMQ" nameServer="127.0.0.1:8080" group="group_1" topic="out_event_user_info" tag="*"></Node>| attribute | description | Suitable for |
|---|---|---|
| id | Unique mark | |
| type | MQ_CONSUMER | |
| flag | Default value:KAFKA | kafka is supported |
| nameServer | The address of the mq server is in the format of 127.0.0.1:8080 | |
| group | mq group name | |
| topic | Subscribed subject name | |
| listenerFlag | 1 is to listen by partition. 2 is to monitor by a single channel,topic can be multiple |
<Node id="MQ_CONSUMER_03" type="MQ_CONSUMER" flag="KAFKA" nameServer="127.0.0.1:18081" group="group_10" topic="out_event_user_info" listenerFlag="2"></Node>
Output node
| attribute | description | Suitable for |
|---|---|---|
| id | Unique mark | |
| type | MQ_PRODUCER | |
| flag | Default value:ROCKETMQ | rocketmq is supported |
| nameServer | The address of the mq server is in the format of 127.0.0.1:8080 | |
| group | mq group name | |
| topic | Subscribed subject name | |
| tag | Label name. The format is tag_1 | |
| sendFlag | Sending mode,1 is synchronization; 2 is asynchronous; Three is one way | |
| outputFields | Enter the name of the field passed by the node, Format: field1; field2; field3 Multiple fields are separated by semicolons |
|
| renameOutputFields | Field mapping format: field1; field2; field3 Multiple fields are separated by semicolons |
<Node id="MQ_PRODUCER_01" type="MQ_PRODUCER" flag="ROCKETMQ" nameServer="127.0.0.1:8080" group="group_11" topic="out_event_system_user" tag="tag_1"
sendFlag="3" outputFields="time;tag_1;c2" renameOutputFields="Time;Equipment;index" >
</Node>| attribute | description | Suitable for |
|---|---|---|
| id | Unique mark | |
| type | MQ_PRODUCER | |
| flag | Default value:KAFKA | kafka is supported |
| nameServer | The address of the mq server is in the format of 127.0.0.1:8080 | |
| topic | Subscribed subject name | |
| isPartition | true sends messages to the specified partition. false: send messages to random partitions | |
| sendFlag | Sending mode,1 is synchronization; 2 is asynchronous | |
| outputFields | Enter the name of the field passed by the node, Format: field1; field2; field3 Multiple fields are separated by semicolons |
|
| renameOutputFields | Field mapping format: field1; field2; field3 Multiple fields are separated by semicolons |
<Node id="MQ_PRODUCER_02" type="MQ_PRODUCER" flag="KAFKA" nameServer="127.0.0.1:18081" topic="out_event_system_user"
sendFlag="1" outputFields="Offset;Partition;Topic;Value" renameOutputFields="Offset;Partition;Topic;Value" >
</Node>Output a data stream from one input node to multiple branch output nodes
| attribute | description | Suitable for |
|---|---|---|
| id | Unique mark | |
| type | COPY_STREAM |
<Node id="COPY_STREAM_01" type="COPY_STREAM" desc="Data flow copy node" ></Node>
<Line id="LINE_01" type="STANDARD" from="DB_INPUT_01" to="COPY_STREAM_01" order="1" metadata="METADATA_01" ></Line>
<Line id="LINE_02" type="COPY" from="COPY_STREAM_01:0" to="DB_OUTPUT_01" order="2" metadata="METADATA_01"></Line>
<Line id="LINE_03" type="COPY" from="COPY_STREAM_01:1" to="DB_OUTPUT_02" order="2" metadata="METADATA_02"></Line>Input node
| attribute | description | Suitable for |
|---|---|---|
| id | Unique mark | |
| type | REDIS_READER | |
| nameServer | 127.0.0.1:6379 | |
| password | ****** | |
| db | 0 | Database ID |
| isGetTTL | true or false Whether to read the ttl information | |
| keys | Read keys separated by semicolons | Currently, only string,int, and float content can be read |
<Node id="REDIS_READER_01" type="REDIS_READER" desc="Input node 1"
nameServer="127.0.0.1:6379" password="******" db="0" isGetTTL="true" keys="a1;a_1" ></Node>Output node: Because the key name cannot be repeated, only the last line of the read node is suitable for writing
| attribute | description | Suitable for |
|---|---|---|
| id | Unique mark | |
| type | REDIS_WRITER | |
| nameServer | 127.0.0.1:6379 | |
| password | ****** | |
| db | 0 | Database ID |
| isGetTTL | true or false Whether to read the ttl information | |
| outputFields | Currently, only string,int, and float contents are supported | |
| renameOutputFields | Currently, only string,int, and float contents are supported |
<Node id="REDIS_WRITER_01" type="REDIS_WRITER" desc="Output node 1" nameServer="127.0.0.1:6379" password="******" db="1"
isGetTTL="true" outputFields="a1;a_1" renameOutputFields="f1;f2" ></Node>Custom nodes, which can be implemented by embedding GO scripts
| attribute | description | Suitable for |
|---|---|---|
| id | Unique mark | |
| type | CUSTOM_READER_WRITER |
Input Node - Execute system script node
| attribute | description | Suitable for |
|---|---|---|
| id | Unique mark | |
| type | EXECUTE_SHELL | |
| fileURL | External script file location | Only one fileURL and Script can appear. When fileURL appears at the same time, fileurl takes precedence over Script |
| Script | Script content | |
| outLogFileURL | The console outputs content to the specified log file |
<Node id="EXECUTE_SHELL_01" type="EXECUTE_SHELL" desc="node 1" _fileURL="d:/test1.bat" outLogFileURL="d:/test1_log.txt">
<Script><![CDATA[
c:
dir/w
]]></Script>
</Node>Input node - Read CSV file node
| attribute | description | Suitable for |
|---|---|---|
| id | Unique mark | |
| type | CSV_READER | |
| fileURL | CSV file location | |
| fetchSize | Number of batches read from memory at a time | For example, influxdb can match the number of records submitted in each batch. 123 fields of 1W pieces of data have been tested and 100 is configured. The storage time is 15 seconds |
| startRow | The row from which the data is read, with 0 representing row 1 by default | Usually 0 is the first column name |
| fields | Defines the output field name, separated by a semicolon | field1;field2;field3 |
| fieldsIndex | Define the columns of the output. By default, 0 represents column 1. Multiple fields are separated by semicolons. If the value is set to -1, all fields are read in sequence | "2;3;4" |
<Node id="CSV_READER_01" type="CSV_READER" desc="Input node 1" fetchSize="5" fileURL="d:/demo2.csv" startRow="1" fields="field1;field2;field3" fieldsIndex="0;3;4">
</Node>
Input Node - Read PROMETHEUS node
| attribute | description | Suitable for |
|---|---|---|
| id | Unique mark | |
| type | PROMETHEUS_API_READER | |
| url | prometheus server address | For example:http://127.0.0.1:9090 |
| Script | To query API content, only /api/v1/query is supported And /api/v1/query_range |
For example: /api/v1/query?query=my_device_info{deviceCode="DeviceNumber000"}[1d] |
** Note: in the result set returned by the query, name is the measure name; TIME is the timestamp when prometheus was stored; VALUE is the value of prometheus **
<Node id="PROMETHEUS_API_READER_1" type="PROMETHEUS_API_READER" url="http://127.0.0.1:9090" >
<Script name="sqlScript">
<![CDATA[
/api/v1/query?query=my_device_info{deviceCode="DeviceNumber000"}[1d]
]]>
</Script>
</Node>
<Node id="DB_OUTPUT_TABLE_1" type="DB_OUTPUT_TABLE" batchSize="10" dbConnection="CONNECT_1" desc="" outputFields="__name__;address;deviceCode;__TIME__;__VALUE__" renameOutputFields="f1;f2;f3;f4;f5" >
<Script name="sqlScript">
<![CDATA[insert into
t_prome_info_bk
(f1,f2,f3,f4,f5)
values (?,?,?,?,?)]]>
</Script>Input node-PROMETHEUS EXPORTER
| attribute | description | Suitable for |
|---|---|---|
| id | Unique mark | |
| type | PROMETHEUS_EXPORTER | |
| exporterAddr | The address of the exporter, IP:PORT | For example: :10000 |
| exporterMetricsPath | exporter's path, | For example: /EtlEngineExport |
| metricName | Metric name | For example:Etl_Engine_Exporter |
| metricHelp | Metric description | sample |
| labels | Label name | For example:deviceCode;address;desc |
<Node id="PROMETHEUS_EXPORTER_1" type="PROMETHEUS_EXPORTER"
exporterAddr=":10000" exporterMetricsPath="/EtlEngineExport"
metricName="Etl_Engine_Exporter" metricHelp="Etl_Engine_Exporter samples"
labels="deviceCode;address;desc">
</Node>Add the following contents to the prometheus configuration file:
- job_name: "etlengine_exporter"
metrics_path: "/EtlEngineExport"
static_configs:
- targets: ["127.0.0.1:10000"]A service address /pushDataService is also exposed for generating data. postman debugging details are as follows:
POST Method
URL http://127.0.0.1:10000/pushDataService ,
Body x-www-form-urlencoded
Parameters:
"jsondata":{
"labels":{"deviceCode":"DeviceCode001","address":"District_1","desc":"Maximum value"},
"value":100
}Two fields are automatically added to the output data stream; name is the name of the measure, VALUE is the value of prometheus,
Output Node - Write PROMETHEUS node
| attribute | description | Suitable for |
|---|---|---|
| id | Unique mark | |
| type | PROMETHEUS_API_WRITER | |
| url | prometheus server address | For example:http://127.0.0.1:9090 |
| metric | Metric name | |
| outputFields | Input the name of the field passed by the node | |
| renameOutputFields | Name of the label corresponding to when prometheus was imported; data items correspond to the outputFields | |
| valueField | value of prometheus when it was imported into the library; the data entry corresponds to an existing field name in the input node |
<Node id="DB_INPUT_TABLE_1" type="DB_INPUT_TABLE" fetchSize="1000" dbConnection="CONNECT_1" >
<Script name="sqlScript">
<![CDATA[select f2,f3,f4 from t_prome_info ]]>
</Script>
</Node>
<Node id="PROMETHEUS_API_WRITER_1" type="PROMETHEUS_API_WRITER" url="http://127.0.0.1:9090" metric="my_device_info" outputFields="f2;f3" renameOutputFields="deviceCode;address" valueField="f4" >
</Node>Input node -Http node, blocking mode
| attribute | description | Suitable for |
|---|---|---|
| id | Unique mark | |
| type | HTTP_INPUT_SERVICE | |
| serviceIp | Bind the IP address of the HTTP/HTTPS service | |
| servicePort | Port bound to the HTTP/HTTPS service | |
| serviceName | Name of the exposed service | Default:etlEngineService |
| serviceCertFile | Location of HTTPS service certificate file | |
| serviceKeyFile | Location of the HTTPS service key file |
<Node id=""
type="HTTP_INPUT_SERVICE"
serviceIp=""
servicePort="8081"
serviceName="etlEngineService"
serviceCertFile=""
serviceKeyFile="" >
</Node>
postman debugging :
http://127.0.0.1:8081/etlEngineService
POST Method,URL: /etlEngineService , Body:x-www-form-urlencoded
Parameters:
"jsondata":{
"rows":[
{"deviceCode":"DeviceCode001","address":"Chaoyang District","desc":"Maximum value","value":20},
{"deviceCode":"DeviceCode002","address":"Chaoyang District","desc":"Maximum value","value":18}
]
}
Note: You must pass an array structure with rows as the KEYInput node - Read elastic node
| attribute | description | Suitable for |
|---|---|---|
| id | Unique mark | |
| type | ELASTIC_READER | |
| index | Index name | |
| sourceFields | The name of the field output in the result set | |
| fetchSize | Number of records read per session | |
| Script标签 | DSL query syntax |
<Node id="ELASTIC_READER_01" dbConnection="CONNECT_02"
type="ELASTIC_READER" desc="node 2" sourceFields="custom_type;username;desc;address" fetchSize="2" >
<Script name="sqlScript"><![CDATA[
{
"query" : {
"bool":{
"must":[
//{
// "term": { "username.keyword": "Mr.Wang" }
// "match": { "username": "" }
// },
{
"term": { "custom_type":"t_user_info" }
}
]
}
}
}
]]></Script>
</Node>
<Connection id="CONNECT_02" type="ELASTIC" dbURL="http://127.0.0.1:9200" database="es_db3" username="elastic" password="******" />
Output node - Write elastic node
| attribute | description | Suitable for |
|---|---|---|
| id | Unique mark | |
| type | ELASTIC_WRITER | |
| index | Index name | |
| idType | Primary key output mode: 1 indicates that the id is not specified. The es system generates a 20-bit GUID by itself. 2 indicates the field name specified in idExpress, and the value matching the same field name is obtained from the renameOutputFields of the previous node. 3 indicates that the value is configured using the expression specified in idExpress. The _HW_UUID32 expression indicates that a primary key is automatically generated by a 32-bit UUID |
|
| idExpress | For example, idType is set to 3. This parameter is set to _HW_UUID32 | |
| outputFields | Input node the field name passed by the node when reading data | Output field contents in sequence, not by field name |
| renameOutputFields | The field name of the output node to the target data source | Output field contents in sequence, not by field name |
<Node id="DB_INPUT_01" dbConnection="CONNECT_01" type="DB_INPUT_TABLE" desc="node 1" fetchSize="2">
<Script name="sqlScript"><![CDATA[
SELECT "t_user_info" AS custom_type,uname, udesc,uaddress,uid FROM t_u_info
]]></Script>
</Node>
<Node id="ELASTIC_WRITER_01" dbConnection="CONNECT_02" type="ELASTIC_WRITER" desc="node 2"
outputFields="custom_type;uname;udesc;uaddress;uid"
renameOutputFields="custom_type;username;desc;address;uid"
idType="3"
idExpress="_HW_UUID32">
</Node>
<Line id="LINE_01" type="STANDARD" from="DB_INPUT_01" to="ELASTIC_WRITER_01" order="0" metadata="METADATA_01"></Line>
<Metadata id="METADATA_01">
<Field name="custom_type" type="string" default="-1" nullable="false"/>
<Field name="username" type="string" default="-1" nullable="false"/>
<Field name="desc" type="string" default="-1" nullable="false"/>
<Field name="address" type="string" default="-1" nullable="false"/>
<Field name="uid" type="string" default="-1" nullable="false"/>
</Metadata>
<Connection id="CONNECT_02" type="ELASTIC" dbURL="http://127.0.0.1:9200" database="es_db3" username="elastic" password="******" />
Input node -Read hive node
hive.server2.authentication = NONE
hive.server2.authentication = KERBEROS
| attribute | description |
|---|---|
| id | Unique mark |
| type | HIVE_READER |
| script | sqlScript SQL statements |
| fetchSize | Number of records read per session |
| dbConnection | Data source ID |
| authFlag | Authentication type: NONE or KERBEROS, default is NONE |
| krb5Principal | Kerberos user name, such as: hive. server2. authentication. kerberos. principal=hive/ [email protected] Hive in |
| desc | description |
<Node id="HIVE_READER_01" dbConnection="CONNECT_01"
type="HIVE_READER" desc="node 1" fetchSize="100" >
<Script name="sqlScript"><![CDATA[
select * from db1.t_u_info
]]></Script>
</Node>
<Connection id="CONNECT_01"
dbURL="127.0.0.1:10000" database="db1"
username="root" password="******"
batchSize="1000" type="HIVE"/>
The metadata file defines the target data format (such as the name and type of the field corresponding to renameOutputFields or renameOutputTags defined in the output node).
outputFields is the name of the field in the data result set in the input node. Converts a field defined by outputFields to a field defined by renameOutputFields. The renameOutputFields conversion format is defined in the metadata file.
| attribute | description | Suitable for |
|---|---|---|
| id | Unique mark | |
| field | ||
| name | The field name of the output data source | renameOutputFields, renameOutputTags |
| type | The field type of the output data source | string,int,int32,float, str_timestamp,decimal, datetime,timestamp |
| default | Default value | When nullable is false, if the output value is an empty string, you can specify the default value of the output by default |
| nullable | Whether to allow null | false cannot be empty. It must be used with default. true is allowed to be null. |
| attribute | description | Suitable for |
|---|---|---|
| id | Unique mark | |
| type | Data source type | INFLUXDB_V1、MYSQL、CLICKHOUSE、SQLITE、POSTGRES、ORACLE、ELASTIC |
| dbURL | Connection address | ck,mysql,influx,postgre,oracle,elastic |
| database | Database name | ck,mysql,influx,sqlite,postgre,oracle,elastic |
| username | User name | ck,mysql,influx,postgre,oracle,elastic |
| password | password | ck,mysql,influx,postgre,oracle,elastic |
| token | token name | influx 2x |
| org | Organization name | influx 2x |
| rp | Name of the data retention policy | influx 1x |
| attribute | description | Suitable for |
|---|---|---|
| runMode | 1. Serial mode; 2 Parallel mode | Parallel mode is recommended by default, If you want the processes to execute in order, you can use the serial mode |
| attribute | description | Suitable for |
|---|---|---|
| id | Unique mark | |
| from | Input node Unique mark | |
| to | Output node Unique mark | |
| type | STANDARD one in, one out,COPY copies data streams and copies data in the intermediate link | |
| order | Serial sort numbers, in ascending order of positive integers. When the graph attribute runMode is 1, Configure 0,1, and 2 to implement serial execution |
|
| metadata | ID of the target metadata |
etl_engine -fileUrl ./global6.xml -logLevel debug arg1="d:/test3.xlsx" arg2=上海arg1 and arg2 are global variables passed in from the command line
<Node id="DB_INPUT_01" dbConnection="CONNECT_01" type="DB_INPUT_TABLE" desc="node 1" fetchSize="500">
<Script name="sqlScript"><![CDATA[
select * from (select * from t5 where tag_1='${arg2}' limit 1000)
]]></Script>
<Node id="XLS_WRITER_01" type="XLS_WRITER" desc="output node 2" appendRow="true" fileURL="${arg1}" startRow="3" metadataRow="2" sheetName="Personnel information" outputFields="c1;c3;tag_1" renameOutputFields="Index=B;Year=C;Region=D" >
${arg1} in the configuration file will be replaced with the value of arg1 d:/test3.xlsx at service runtime.
${arg2} in the configuration file will be replaced with the value of arg2 ShangHai service runtime
To facilitate the generation of fixed formatted content, the system has built-in common variables, which can be used to dynamically replace variable values when configuring global variables.
Built-in variable prefix _HW_
- Time variable
Format:_HW_YYYY-MM-DD hh:mm:ss.SSS
The current system time is displayed, for example, 2022-01-02 19:33:06.108
Note that Spaces are escaped by 0x32, so the correct way to pass them is_HW_YYYY-MM-DD0x32hh:mm:ss.SSSYYYY Output four-bit Year 2022 MM output two-bit month 01 DD output two-bit day 02 hh output two-bit hour 19 mm output two-bit minute 33 ss output two-bit second 06 .SSS output a prefix. And three milliseconds .108
The above parts can be combined at will, for example, _HW_YYYYMM, output202201
-
Time displacement variable
On the basis of the original time variable, the capital Z character represents the addition or subtraction of time, minutes and seconds.
For example, the format is:_HW_YYYY-MM-DD hh:mm:ss.SSSZ2h45m
Indicates the time after 2 hours and 45 minutes.
For example, the format is:_HW_YYYY-MM-DD hh:mm:ssZ-24h10m
大A negative number follows the uppercase character Z to reduce the displacement.
Output the time after the current time is reduced by 24 hours and 10 minutes.
Support the time and frequency of the unit is as follows:
"ns", "us" (or "µs"), "ms", "s", "m", "h"
On the basis of the original time variable, the lowercase z character represents the addition or subtraction of the year, month, and day.
For example, the format is :_HW_YYYY-MM-DD hh:mm:ssz1,2,3
The current time is accumulated 1 year,2 months, and 3 days.
For example, the format is:_HW_YYYY-MM-DD hhz-1,-2,-3
The current output time is reduced by 1 year, 2 months and 3 days -
Timestamp variable
format:_HW_timestamp10
Displays the current 10-bit system timestamp, For example,1669450716
Format:_HW_timestamp13
Displays the current 13-bit system timestamp, for example,1669450716142
Format:_HW_timestamp16
Displays the 16-bit timestamp of the current system, for example, 1669450716142516
Format:_HW_timestamp19
Displays the 19-bit timestamp of the current system, for example, 1669450716142516700 -
UUID variables
format:_HW_UUID32
output 32-bit UUID,for example,D54C3C7163844E4DB4F073E8EEC83328
format:_HW_uuid32
output 32-bit UUID,for example,d54c3c7163844e4dB4f073e8eec83328
etl_engine -fileUrl ./global6.xml -logLevel debug arg1=_HW_YYYY-MM-DD0x32hh:mm:ss.SSS arg2=_HW_YYYY-MM-DD <Node id="DB_INPUT_01" dbConnection="CONNECT_01" type="DB_INPUT_TABLE" desc="node 1" fetchSize="500">
<Script name="sqlScript"><![CDATA[
select * from (select * from t5 where tag_1='${arg1}' limit 1000)
]]></Script>
<Node id="XLS_WRITER_01" type="XLS_WRITER" desc="output node 2" appendRow="true" fileURL="${arg2}.xlsx" _fileURL="d:/demo/test2.xlsx" startRow="3" metadataRow="2" sheetName="Personnel information" outputFields="c1;c3;tag_1" renameOutputFields="Index=B;Year=C;Region=D" >
You can embed your own business logic in the tag <BeforeOut></BeforeOut> of any output node,More introduction
Multiple fields can be added and given default values
package ext
import (
"errors"
"fmt"
"strconv"
)
func RunScript(dataValue string) (result string, topErr error) {
newRows := ""
rows := gjson.Get(dataValue, "rows")
for index, row := range rows.Array() {
//tmpStr, _ := sjson.Set(row.String(), "addCol1", time.Now().Format("2006-01-02 15:04:05.000"))
tmpStr, _ := sjson.Set(row.String(), "addCol1", "1")
tmpStr, _ = sjson.Set(tmpStr, "addCol2", "${arg2}")
newRows, _ = sjson.SetRaw(newRows, "rows.-1", tmpStr)
}
return newRows, nil
}
Multiple fields can be combined into a single field
package ext
import (
"errors"
"fmt"
"strconv"
)
func RunScript(dataValue string) (result string, topErr error) {
newRows := ""
rows := gjson.Get(dataValue, "rows")
for index, row := range rows.Array() {
area := gjson.Get(row.String(),"tag_1").String()
year := gjson.Get(row.String(),"c3").String()
tmpStr, _ := sjson.Set(row.String(), "tag_1", area + "_" + year)
newRows, _ = sjson.SetRaw(newRows, "rows.-1", tmpStr)
}
return newRows, nil
}
<?xml version="1.0" encoding="UTF-8"?>
<Graph>
<Node id="CSV_READER_01" type="CSV_READER" desc="node 1" fetchSize="500" fileURL="d:/demo.csv" startRow="1" fields="field1;field2;field3;field4" fieldsIndex="0;1;2;3" >
</Node>
<Node id="OUTPUT_TRASH_01" type="OUTPUT_TRASH" desc="node 2" >
<BeforeOut>
<![CDATA[
package ext
import (
"errors"
"fmt"
"strconv"
"strings"
"time"
"github.com/tidwall/gjson"
"github.com/tidwall/sjson"
"etl-engine/etl/tool/extlibs/common"
"io/ioutil"
"os"
)
func RunScript(dataValue string) (result string, topErr error) {
defer func() {
if topLevelErr := recover(); topLevelErr != nil {
topErr = errors.New("RunScript Capture fatal error" + topLevelErr.(error).Error())
} else {
topErr = nil
}
}()
newRows := ""
GenLine(dataValue,"db1","autogen","t13","field2","field3;field4")
return newRows, nil
}
//Received is JSON
func GenLine(dataValue string, db string, rp string, measurement string, fields string, tags string) error {
head := "# DML\n# CONTEXT-DATABASE: " + db + "\n# CONTEXT-RETENTION-POLICY: " + rp + "\n\n"
line := ""
fieldLine := ""
tagLine := ""
_t_ := strings.Split(tags, ";")
_f_ := strings.Split(fields, ";")
rows := gjson.Get(dataValue, "rows")
for _, row := range rows.Array() {
fieldLine = ""
tagLine = ""
for i1 := 0; i1 < len(_t_); i1++ {
tagValue := gjson.Get(row.String(), _t_[i1])
tagLine = tagLine + _t_[i1] + "=\"" + tagValue.String() + "\","
}
tagLine = tagLine[0 : len(tagLine)-1]
for i1 := 0; i1 < len(_f_); i1++ {
fieldValue := gjson.Get(row.String(), _f_[i1])
fieldLine = fieldLine + _f_[i1] + "=" + fieldValue.String() + ","
}
fieldLine = fieldLine[0 : len(fieldLine)-1]
if len(tagLine) > 0 && len(fieldLine) > 0 {
line = line + measurement + "," + tagLine + " " + fieldLine + " " + strconv.FormatInt(time.Now().Add(500*time.Millisecond).UnixNano(), 10) + "\n"
} else {
if len(fieldLine) > 0 {
line = line + measurement + "," + fieldLine + " " + strconv.FormatInt(time.Now().Add(500*time.Millisecond).UnixNano(), 10) + "\n"
}
}
}
if len(line) > 0 {
txt := head + line
fileName := "d:/"+strconv.FormatInt(time.Now().UnixNano(), 10)
WriteFileToDB(fileName, txt)
err1 := os.Remove(fileName)
if err1 != nil {
fmt.Println("delete temp file fail:", fileName)
return err1
}
}
return nil
}
func WriteFileToDB(fileName string, txt string) {
buf := []byte(txt)
err := ioutil.WriteFile(fileName, buf, 0666)
if err != nil {
fmt.Println("write file fail:", err)
return
} else {
cmdLine := "D:/software/influxdb-1.8.10-1/influx.exe -import -path=" + fileName + " -host 127.0.0.1 -port 58086 -username u1 -password 123456 -precision=ns"
//fmt.Println("cmdLine:",cmdLine)
common.Command3("GB18030", "cmd", "/c", cmdLine)
}
}
]]>
</BeforeOut>
</Node>
<Line id="LINE_01" type="STANDARD" from="CSV_READER_01" to="OUTPUT_TRASH_01" order="0" metadata="METADATA_03">线标注</Line>
<Metadata id="METADATA_03">
<Field name="field1" type="string" default="-1" nullable="false"/>
<Field name="field2" type="string" default="-1" nullable="false"/>
<Field name="field3" type="string" default="-1" nullable="false"/>
<Field name="field4" type="string" default="-1" nullable="false"/>
</Metadata>
</Graph>
Welcome docking and cooperation
```
@auth Mr Huang
mail:[email protected]
vx:weigeonlyyou
```