At the Chan School's Onnela Lab, the digital phenotyping project is a framework for leveraging data from digital devices to obtain moment-by-moment quantification of the individual-level human phenotype [1].
Accelerometers have been used in the study of human activity for several decades, and these sensors have become increasingly ubiquitous in modern electronic devices. Today, virtually every smartphone and tablet is equipped with a piezo-electric triaxial accelerometer. Smartphone accelerometry is currently an active area of research, with applications ranging from real-time activity classification to the detection of neuromuscular disorders [2, 3, 4].
In the context of digital phenotyping, smartphone accelerometer data can not only offer insight into individual physical activity levels, but can also inform analyses of other passively-collected data (e.g. GPS-based measures of mobility) and self-reported information (e.g. daily survey responses).
Smartphone accelerometry presents some special challenges due to the size of the data sets, and also due to specific missing data issues.
For example, a participant with an iPhone may generate more than half a million individual accelerometer observations over the course of a day, each observation consisting of a UTC timestamp and one measurement for each axis of the accelerometer. Current studies involve observation of dozens of participants for multiple weeks; in the near future, studies with thousands of participants are anticipated.
In addition, typical accelerometer data collection incorporates cyclic periods during which observation is suspended in order to conserve battery. Android phones are subject to additional missing data arising from highly variable sampling rates.
Therefore, even basic research tasks (such as assessment of data quality and data exploration) can require time-consuming calculations. And incomplete data hinders more sophisticated analyses of accelerometer data, such as estimation of parameters associated with active and sedentary time periods.
The goals of the present project are to:
-
Assemble optimized code for processing of accelerometer data.
-
Develop an efficient framework for implementing and evaluating imputation strategies.
It is assumed that the resulting code may be run in a cluster or cloud computing environment (for bulk processing of raw data), or in a desktop environment (for convenient data exploration and quality monitoring). Therefore, several optimization strategies will be pursued:
-
Convert Python code for data processing into C extensions using Cython,
-
Optimize time-consuming calculations with OpenMP,
-
Implement concurrent processing of data from multiple days and/or multiple participants using MPI functionality.
Lastly, efficient imputation routines will be implemented with hybrid parallel programming. It is anticipated that this will allow rapid evaluation of several imputation methods, with the goal of selecting an optimal method for future use.
The Onnela Lab's Beiwe software collects smartphone sensor data and delivers it in the form of zipped csv files. A participant using an iPhone will generate 40-80 MB of uncompressed accelerometer data per day, divided into hours. The raw data take the form of three time series (one for each accelerometer axis), sampled at a rate of about 9 Hz. Before extracting useful information about active and sedentary periods, the researcher must transform the data in the following way.
First, raw hourly data is collected into periods of interest identified by the researcher. The three time series are then collapsed to a single time series by calculating a signal magnitude for each observation; this is simply the length of the observed 3-dimensional acceleration vector. The signal magnitudes are then compared to the expected resting accelerometer signal magnitude of 1 g; absolute deviations from resting acceleration are averaged over epochs of five seconds. At this point, all available data from a given participant are examined in order to identify an individual cutoff point that distingushes active epochs from sedentary epochs; the location of this cutoff is based on the fact that adults spend an average of 54.9% of their awake time in sedentary activity [5]. After this classification is applied, active bursts and sedentary periods are located by tracking behavior across consecutive epochs; finally, summary statistics for the corresponding distributions are generated.
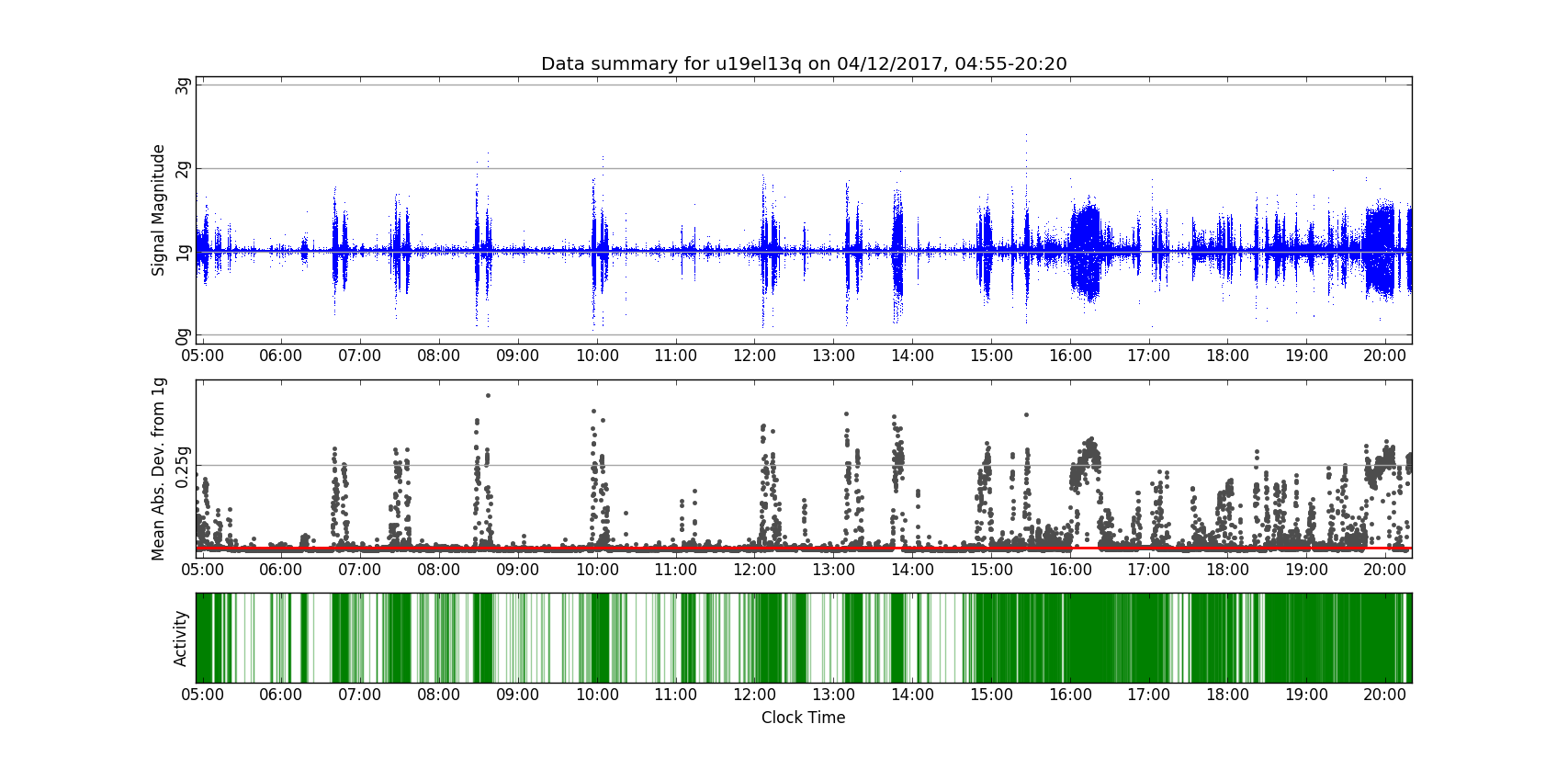
The above plots illustrate several steps in this pipeline, beginning with the signal magnitude time series at top. The center plot shows mean absolute deviations from resting acceleration, with the individual cutoff represented by a red line (just above the x-axis). At bottom, green vertical lines represent epochs that have been classified as active.
The processing pipeline was initially coded in Python. The optimization strategy adopted the hybrid SPMD model, and took place in two stages. First, several key segments of code were rewritten as C extensions with Cython, and then implemented as multithreaded algorithms. This was especially important for calculating five-second averages, a time-consuming computation due to nonuniform accelerometer sampling rates. Using OpenMP functionality from the cython.parallel module, this parallel algorithm speeded computation by concurrently performing multiple unbounded searches. Speedups and throughput for the shared-memory algorithm are shown below, at left and center. For a typical dataset of 16 hours processed on 32 cores, throughput approached 8 MFLOP/s and runtime was reduced by a factor of 8.
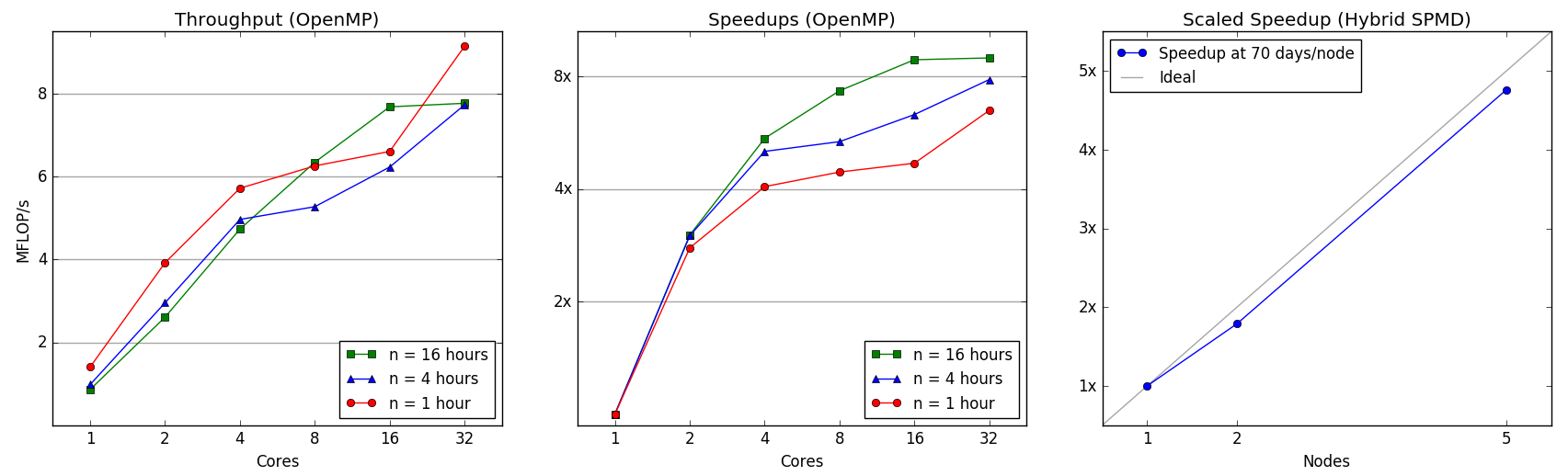
In order to address concurrent processing of data from multiple participants, and to accommodate synchronization points involving data from multiple files, an explicit parallel programming approach was adopted for a second level of optimization. Of particular interest was coordinating multiple processes prior to identifying individual cutoff points for activity classification, a task that required scanning several processed files from each participant. The message passing framework was implemented with MPI functionality from the mpi4py package. The final hybrid SPMD version of the processing code leverages resources from not only multiple nodes in a cluster, but also multiple cores; this allows relatively large accelerometer data sets (e.g. 100-400 days of data) to be processed in under one hour. The scaled speedup is above right; performance was evaluated on 1, 2, and 5 nodes with problem sizes corresponding to 70, 140, and 350 simulated days of accelerometer data.
Each version of the code was benchmarked on a small data set containing 62 hours of accelerometer observations from two participants (130 MB). Additional benchmarks were obtained with data from a simulated pilot study in which ten hypothetical participants contributed data for two weeks (2100 hours of accelerometer observations, 17 GB).
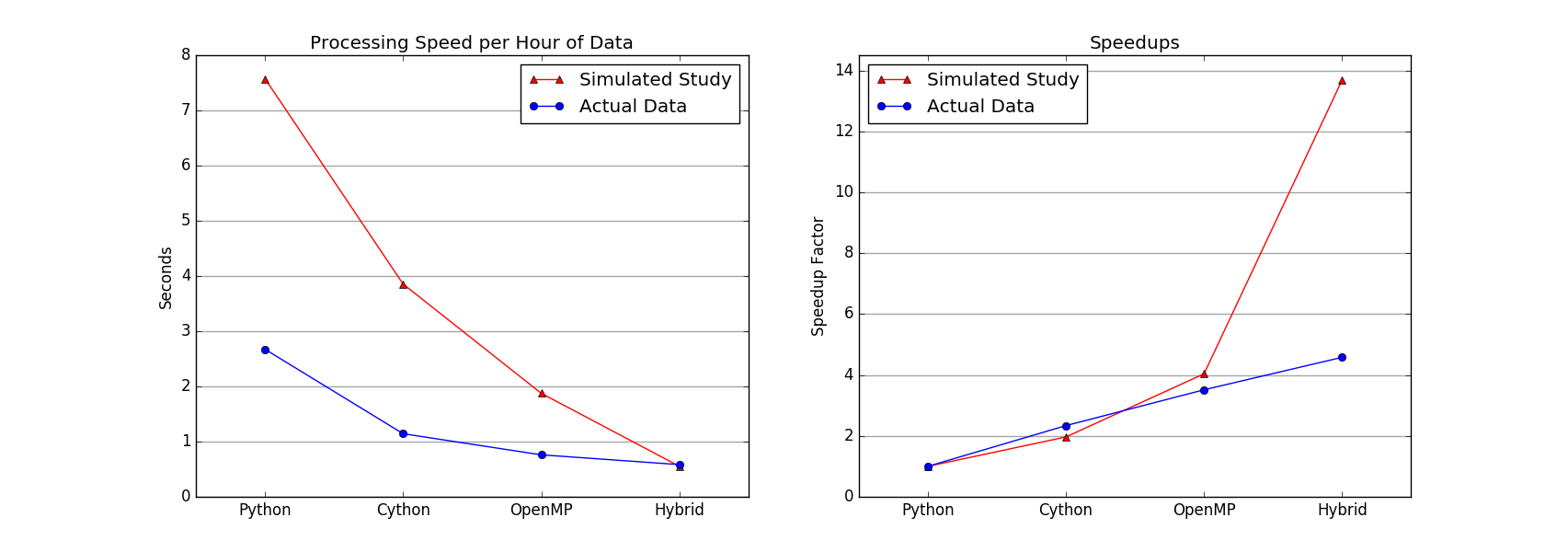
Computation took place on the Odyssey Cluster's seas_iacs partition. Preliminary versions of the code were run on individual nodes equipped with 32 cores; hybrid code was run on four such nodes. Estimates for the actual data set were calculated by averaging runtimes for five repetitions of the data processing task. For the simulated data, the task was completed only once by each version of the code. The above plots show estimated times-to-solution, in seconds per hour of accelerometer data, as well as speedups relative to the baseline of unaccelerated Python code.
On a single node with 32 processors, the use of C extensions reduces runtime by a factor of about 2, and OpenMP functionality yields a speedup factor of over 3.5. On four contiguous nodes, the hybrid code is over 4.5 times as fast as unaccelerated Python code for the actual data task, and almost 14 times as fast for the larger hypothetical data task. The difference may be due, in part, to startup costs associated with unzipping compressed files. Only the hybrid code implements concurrent decompression, a considerable advantage for data sets that contain numerous zipped directories. Prior to optimization, each hour of accelerometer data took multiple seconds to process; the hybrid code brings this processing time to under 0.6 seconds.
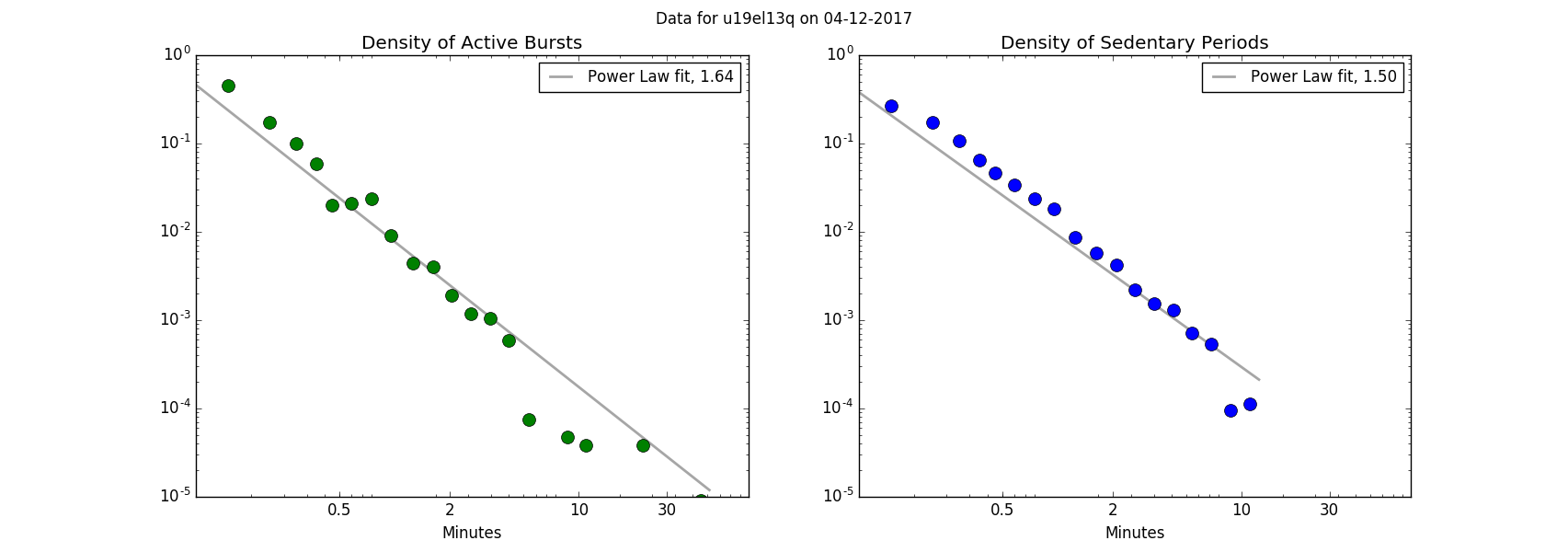
Physical activity, like many other human behaviors, is bursty and correlated. One approach to characterizing such activity is to model the distribution of bursty periods and the distribution of inter-event times [6]. In the present context, a binary time series of active and sedentary epochs (identified with 1 and 0, respectively) can be aggregated into active bursts and sedentary periods, as shown below.

The observed active burst lengths (green) and the observed sedentary period lengths (blue) are taken as samples from the corresponding distributions.
The densities of these two distributions appear linear on a log-log plot, as shown below. The power law is one possible candidate for a parametric model for these distributions. Fitting a power law corresponds to estimation of the exponent in the density P(x) ~ x-a. There are a number of subtleties associated with fitting heavy-tailed distributions to data [7]; many of the relevant methods have been implemented in the Python package powerlaw [8].
Of special concern is the systematic missingness associated with battery-conservation strategies. Accelerometer data collection over the course of a day may deplete a smartphone's battery by more than 50%. Therefore, by design, data collection is continuously interrupted. For example, each minute of accelerometer data may be sandwiched between minutes when the sensor is turned off. The exact on-off pattern of the sensor is determined by the researcher during the study planning phase.

While this missingness is "uninformative" at the level of the binary time series, longer bursts will be disproportionately interrupted, leading to biased estimates of distribution parameters. (In the case of the power law exponent, estimates will be biased upwards.) A possible solution may be a multiple imputation strategy based on stochastic models of the binary time series. While imputation for accelerometer data has been studied in the past [9], estimation of parameters for bursty periods and inter-event times has yet to be examined in this context.
Complete, uninterrupted days of accelerometer data were used as the basis for a simulation study designed to examine the viability of multiple imputation for missing data, and to assess the impact of missingness on parameter estimation. A memoryless process was adopted as a stochastic data-generating model for the binary time series. This model can be though of as a Markov chain of order m, or equivalently, a saturated logistic regression model with m predictors, where m is half the length of an accelerometer on-period.
To implement this simulation, four days of complete accelerometer data were systematically downsampled with on/off cycles ranging from 30 seconds to two minutes. For each set of downsampled data, the memoryless model was first fitted to the available data, and then used to generate 1000 imputed data sets. The power law exponent was estimated from each imputed data set, and the average of these estimates was compared to the "true" estimate from the original complete data.
While the data processing pipeline needed to accommodate hundreds of hours of data, this simulation required only that four days of data be processed in a reasonable time frame. As before, C extensions with Open MP parallelization were implemented in combination with explicit parallel processing with MPI. The resulting hybrid SPMD implementation of the simulation ran in about four hours on four 32-core nodes.
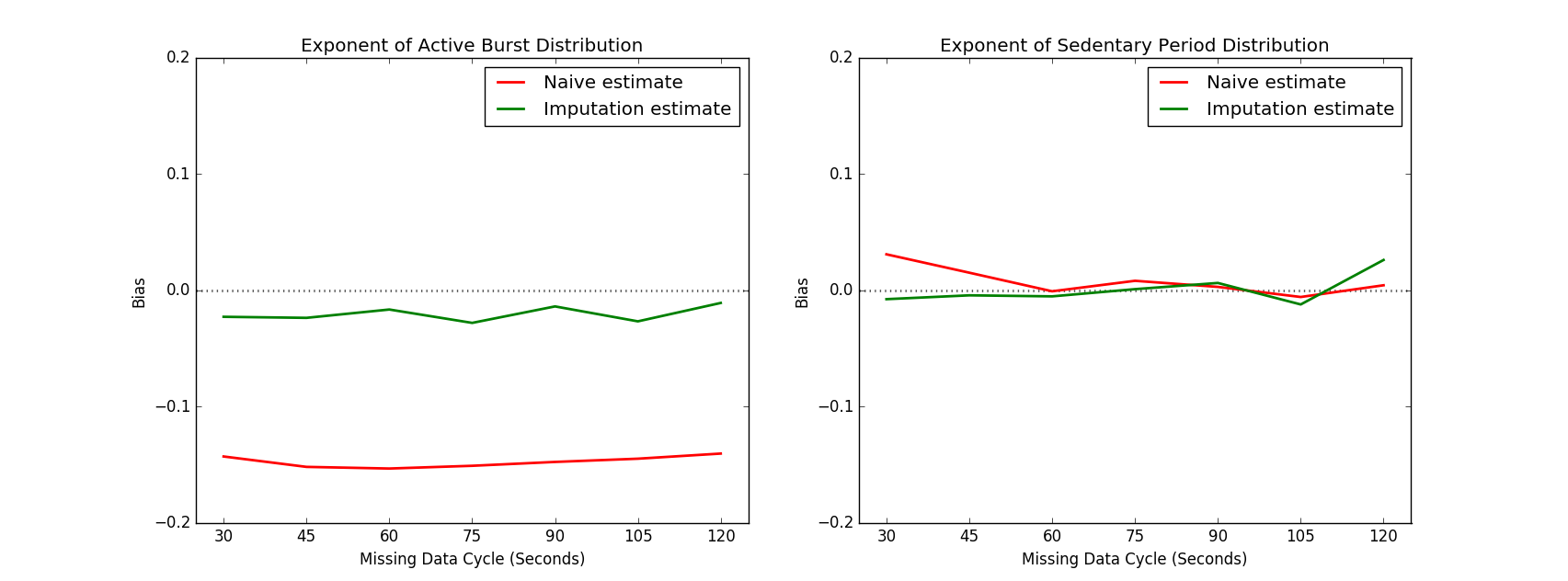
The above plots show the bias of the naive estimates (red) and imputation-based estimates (green) for the exponents of the activity distributions. While the imputation strategy appears to be a substantial improvement over the naive approach, especially in the case of the active burst distribution, the imputation-based estimate is nevertheless consistently biased downward by several percent.
Smartphone accelerometry offers the possibility of important insights into human physical activity. However, large data sets and a variety of missing data features create special challenges. In this project, parallel programming was used to address both of these issues. A hybrid SPMD programming model facilitated efficient data processing, reducing runtimes by a factor of 14. And the same programming approach also allowed rapid evaluation of a multiple imputation strategy for parameter estimation.
[1] https://www.hsph.harvard.edu/onnela-lab/
[2] del Rosario, M. B., Redmond, S. J. & Lovell, N. H. Tracking the Evolution of Smartphone Sensing for Monitoring Human Movement. Sensors (Basel) 15, 18901–18933 (2015).
[3] Mitchell, E., Monaghan, D. & O’Connor, N. E. Classification of Sporting Activities Using Smartphone Accelerometers. Sensors (Basel) 13, 5317–5337 (2013).
[4] Lau, S. L. & David, K. Movement recognition using the accelerometer in smartphones. in 2010 Future Network Mobile Summit 1–9 (2010).
[5] Matthews, C. E. et al. Amount of Time Spent in Sedentary Behaviors in the United States, 2003–2004. Am J Epidemiol 167, 875–881 (2008).
[6] Karsai, M., Kaski, K., Barabási, A.-L. & Kertész, J. Universal features of correlated bursty behaviour. Scientific Reports 2, 397 (2012).
[7] Clauset, A., Shalizi, C. & Newman, M. Power-Law Distributions in Empirical Data. SIAM Rev. 51, 661–703 (2009).
[8] Alstott, J., Bullmore, E. & Plenz, D. Powerlaw: a Python package for analysis of heavy-tailed distributions. PLoS ONE 9, e85777 (2014).
[9] Catellier, D. J. et al. Imputation of Missing Data When Measuring Physical Activity by Accelerometry. Medicine & Science in Sports & Exercise 37, (2005).