本程序是一个在 Windows 下使用 C++ 开发的软件光栅渲染器,实现了普通 ZBuffer、扫描线 ZBuffer、简单层次 ZBuffer、带场景八叉树的层次 ZBuffer、带场景 kd 树的层次 ZBuffer 这几种算法。并用这些算法来渲染三维模型。
| 组件 | 规格 |
|---|---|
| CPU | Intel(R) Core(TM) i7-8700K |
| RAM | 16.0 GB |
| 操作系统 | Windows 10 专业版 |
| 库 | 版本 |
|---|---|
| glad | core |
| glfw | 3.4 |
| glm | 4.7 |
| tiny_obj_loader | 2.0.0 |
本程序的 camera.hpp 参考的是 openGL摄像机章节中所使用的 Camera类。
在 main.cpp 文件中选择相应的模型,以及选择相应的渲染类型。如果需要改变初始相机位置,请在 application.cpp 中的 init() 函数中修改
- 鼠标左键加拖动可以改变模型位置,鼠标滚轮可以缩放模型
- 可以窗口边界改变窗口大小
W,S键可以缩放模型A,D键可以旋转模型(要配合鼠标来旋转,鼠标往反方向拖动)
ZBufRender
├─ 3rdparty
├─ asserts
├─ CMakeLists.txt
├─ README.md
└─ source
├─ CMakeLists.txt
├─ main.cpp
├─ include
│ ├─ application.hpp
│ ├─ bbox.hpp
│ ├─ camera.hpp
│ ├─ frag_mesh.hpp
│ ├─ kd_tree.hpp
│ ├─ model.hpp
│ ├─ octree.hpp
│ ├─ quad_tree.hpp
│ ├─ render.hpp
│ ├─ scanline_struct.hpp
│ ├─ shader.hpp
│ ├─ uniforms.hpp
│ ├─ window.hpp
│ └─ zbuffer.hpp
└─ src
├─ application.cpp
├─ bbox.cpp
├─ kd_tree.cpp
├─ model.cpp
├─ octree.cpp
├─ quad_tree.cpp
├─ render.cpp
├─ shader.cpp
├─ window.cpp
└─ zbuffer.cpp
普通 ZBuffer 算法,也称为传统的 ZBuffer 算法或深度缓冲算法,是三维图形渲染中最常用的算法之一。以下是该算法的基本步骤:
- 初始化ZBuffer:在渲染开始之前,创建一个与屏幕像素一一对应的 ZBuffer 数组,用于存储每个像素的深度值。这个数组会被初始化为
1.0,表示没有任何物体渲染到这些像素上。 - 光栅化三角形:对于场景中的每个三角形,执行以下步骤:
- 计算 Bounding Box:首先计算三角形在屏幕上的 Bounding Box,即三角形在屏幕上占据的最小矩形区域。这个矩形框定了需要处理的像素范围。
- 逐像素处理:对于 Bounding Box 中的每个像素,执行以下操作:
- 判断像素是否在三角形内:使用
Barycentric坐标来判断当前像素是否位于三角形内部。如果像素在三角形内,则继续下一步;否则,跳过当前像素。 - 深度测试:比较当前像素的深度值与 ZBuffer 中相应位置的深度值。如果新的深度值小于 ZBuffer 中的值(即物体更靠近观察者),则通过深度测试。
- 更新 ZBuffer 和绘制像素:如果像素通过了深度测试,则更新 ZBuffer 中的深度值,并将该像素的颜色值设置为三角形的颜色。
- 判断像素是否在三角形内:使用
扫描线 ZBuffer 算法是一种用于三维图形渲染的算法,它通过处理扫描线(即屏幕上的每一行像素)来计算每个像素的深度值,并决定哪些像素应该被渲染。以下是该算法的具体步骤:
- 建立分类多边形表和分类边表:
- 分类多边形表:这个表按扫描线顺序记录了每个多边形的相关信息,包括多边形的起始扫描线和结束扫描线。
- 分类边表:这个表记录了多边形的边,以及它们与扫描线的交点。每条边都会有一个起始扫描线和结束扫描线。
- 从上到下对每行像素进行绘制:
- 重置深度 Buffer:对于当前扫描线,将深度 Buffer 重置。
- 检查分类多边形表:检查当前扫描线在分类多边形表中的条目,将所有与当前扫描线相交的多边形的边加入到活化边表中。
- 绘制和更新活化边表中的边:
- 绘制:对于活化边表中的每条边,计算它在当前扫描线上的像素范围,并根据边的深度值(
z值)来更新深度 Buffer。只有当新的z值小于当前depthBuffer中的值时,像素才会被绘制。 - 更新:在绘制过程中,使用边的斜率等信息来增量式地更新 z 值,这样可以避免在每个像素上都进行复杂的深度计算。
- 绘制:对于活化边表中的每条边,计算它在当前扫描线上的像素范围,并根据边的深度值(
- 更新活化边表:当一条边在当前扫描线上绘制完成后,需要从活化边表中移除。如果该边所属的多边形还有其他边未被处理,需要将新的边加入到活化边表中,以便在后续的扫描线上继续绘制。
四叉树是一种树形数据结构,它将二维空间划分为四个象限,每个象限又可以是一个四叉树。简单层次 ZBuffer 算法可以利用四叉树来优化深度缓冲的处理,特别是当场景中存在大量空旷区域时。以下是一个简化的层次 ZBuffer 算法,它结合了四叉树的概念:
- 初始化四叉树:
- 根据屏幕分辨率创建一个四叉树结构,树的每个节点代表屏幕上的一个矩形区域。
- 将屏幕划分为四个相等的部分,每个部分成为一个子节点。
- 递归地将每个子节点继续划分为四个更小的部分,直到达到预设的最大深度或者节点的尺寸小于一个特定的阈值。
- 构建四叉树:
- 遍历 Mesh:对于场景中的每个三角形,执行以下步骤:
- 计算三角形在屏幕上的包围盒(Bounding Box)。
- 从四叉树的根节点开始,遍历四叉树以找到包含该包围盒的最深节点。
- 深度测试:如果三角形的最小深度大于节点当前记录的最大深度,则说明三角形被遮挡,不需要进一步处理,返回。
- 遍历像素:对于三角形覆盖的每个像素,执行以下步骤:
- 确定像素所属的最深四叉树节点。
- 计算像素的深度值。
- 深度测试:如果像素的深度值大于四叉树节点记录的深度值,则说明像素被遮挡,不需要绘制,返回;如果像素的深度值小于或等于四叉树节点记录的深度值,则绘制该像素,并更新四叉树节点的深度值。
- 遍历 Mesh:对于场景中的每个三角形,执行以下步骤:
结合八叉树和四叉树来优化层次 ZBuffer 算法是一个更为复杂但也更为高效的方法。在这种情况下,八叉树用于三维空间中的物体划分,而四叉树用于二维屏幕空间中的像素划分。以下是结合八叉树和四叉树的层次 ZBuffer 算法的步骤:
- 初始化四叉树和八叉树:
- 四叉树的初始化:
- 根据屏幕分辨率,创建一个四叉树结构,其中树的每个节点代表屏幕上的一个矩形区域。
- 将屏幕划分为四个相等的部分,每个部分成为一个子节点。
- 递归地将每个子节点继续划分为四个更小的部分,直到达到预设的最大深度或者节点的尺寸小于一个特定的阈值。
- 八叉树的初始化:对于场景中的每个
Mesh,执行以下步骤:- 计算该 Mesh 在三维空间中的包围盒(Bounding Box)。
- 从八叉树的根节点开始,递归地将
Mesh分配到其所属的最深的八叉树节点中。 - 如果一个八叉树节点包含多个
Mesh,并且节点的大小允许进一步分割,则将该节点分割成更小的八叉树节点,直到每个节点只包含一个Mesh或者达到八叉树的最大深度。
- 四叉树的初始化:
- 遍历八叉树:从四叉树的根节点开始,同时查看对应的八叉树根节点,递归地进行以下操作:
- 处理八叉树节点中的 Mesh:对于八叉树中的每个节点,执行以下步骤:
- 检查该节点中的
Mesh是否需要渲染。如果Mesh的包围盒的最小 z 值大于四叉树节点的深度阈值,则不需要渲染该Mesh,跳过后续步骤。 - 对于需要渲染的
Mesh,执行简单层次 ZBuffer 算法中的构建四叉树过程。
- 检查该节点中的
- 递归遍历八叉树的子节点:对于八叉树的每个子节点,执行以下步骤:
- 检查该节点是否能通过深度测试,如不能直接返回。
- 确定该八叉树子节点对应的四叉树子节点。
- 递归地遍历八叉树的子节点,重复上述处理八叉树节点的过程。
- 处理八叉树节点中的 Mesh:对于八叉树中的每个节点,执行以下步骤:
- 初始化四叉树和八叉树:
- 四叉树的初始化:
- 将场景划分成多个区域,每个区域对应四叉树的一个节点。
- 对于每个节点,根据其包含的几何对象进一步划分为四个子节点,直到满足特定的终止条件(例如,节点中的对象数量少于一个阈值)。
- kd 树的初始化:递归执行下述划分过程,直到达到预定的最大深度或节点的体积小于给定的阈值。
- 从场景中的所有几何对象中提取顶点数据。
- 选择一个维度(通常是 x, y, 或 z 轴)进行空间划分。
- 根据所选轴上的坐标值,将网格(mesh)中的点分配到相应的 KD 树子节点中;若点不明确属于任一子节点,则将其归类到当前节点。
- 四叉树的初始化:
- 绘制场景:
- 从四叉树的根节点开始,同时查看 kd 树根节点,递归的进行以下操作:
- 深度测试:检查 kd 树节点是否能通过深度测试,如果不能通过则直接返回,不需要进一步处理。
- 包围盒相交测试:查看当前四叉树节点是否与 kd 树节点的包围盒相交,如果不相交则直接返回,因为当前四叉树节点内的几何对象不会与 kd 树节点内的对象相交。
- 叶子节点处理:如果当前 kd 树节点是叶子节点,则绘制属于当前 kd 树节点的 mesh。此时可能需要进行以下步骤:
- ZBuffer 测试:对于 mesh 中的每个三角形,进行 ZBuffer 测试,确定其是否可见。
- 光栅化:对于通过 ZBuffer 测试的三角形,进行光栅化处理,生成像素。
- 像素处理:对生成的像素进行着色、纹理映射、光照计算等处理。
- 递归处理:如果当前 kd 树节点不是叶子节点,则递归地对每个子节点执行上述步骤。
- 从四叉树的根节点开始,同时查看 kd 树根节点,递归的进行以下操作:
在 asserts 文件夹中存放了用于进行算法比较的模型,它们所含的顶点数和面元数如下表所示。渲染窗口大小默认为(800,600)。
| 模型文件 | 顶点数 | 面元数 |
|---|---|---|
| suzanne_1k.obj | 2,904 | 968 |
| spot_5k.obj | 2,930 | 5,856 |
| bunny_69k.obj | 34,817 | 69,630 |
| armadillo_212k.obj | 106,289 | 212,574 |
| dragon_871k.obj | 435,545 | 871,306 |
各个模型使用各种算法绘制所需的时间如下表所示。
| 用时(ms) | suzanne_1k.obj | spot_5k.obj | bunny_69k.obj | armadillo_212k.obj | dragon_871k.obj |
|---|---|---|---|---|---|
| 模型加载时间 | 2 | 6 | 88 | 275 | 858 |
| 模型转换时间 | 0 | 1 | 24 | 82 | 289 |
模型转换时间即将三维模型经过 MVP 矩阵转换为屏幕像素坐标的时间。在代码中即生成 FragMesh 的时间,还包括一些其他用于绘制的函数。
渲染的结果如下所示。
| suzanne_1k.obj | spot_5k.obj | bunny_69k.obj |
|---|---|---|
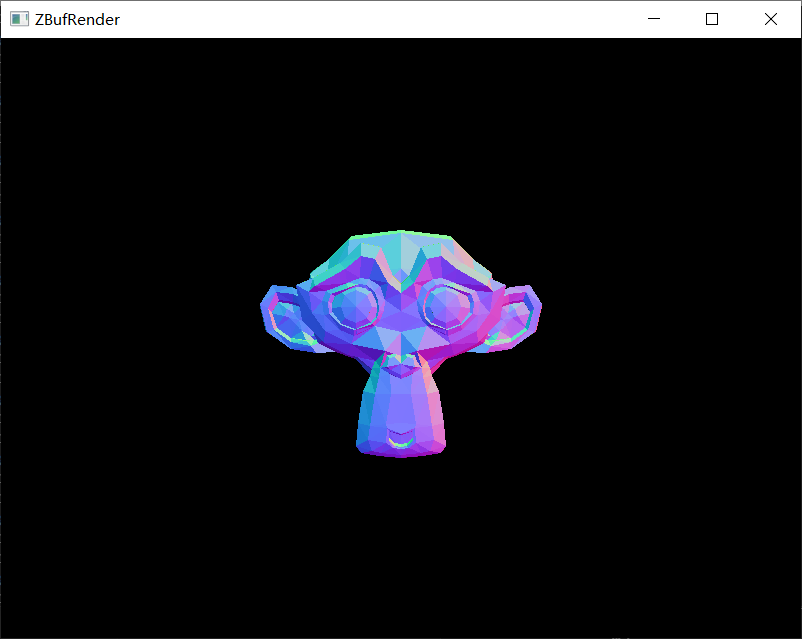 |
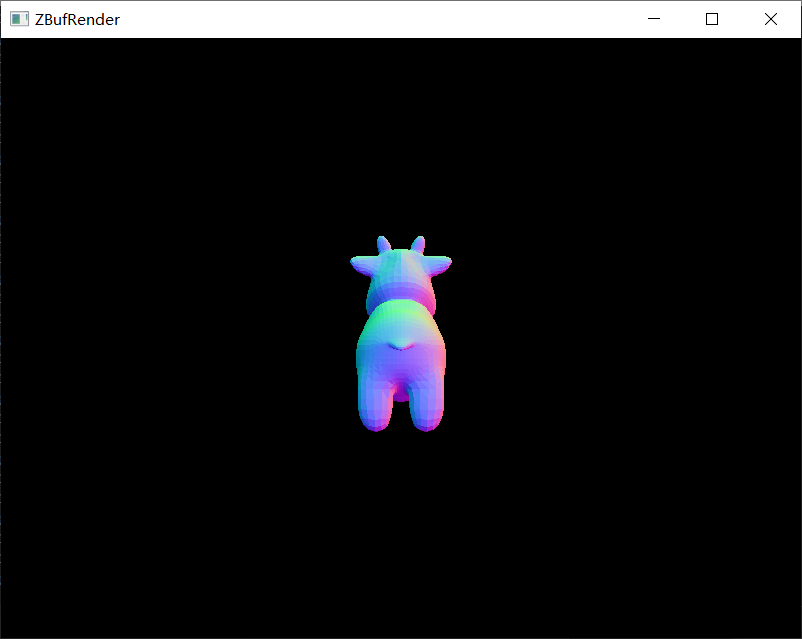 |
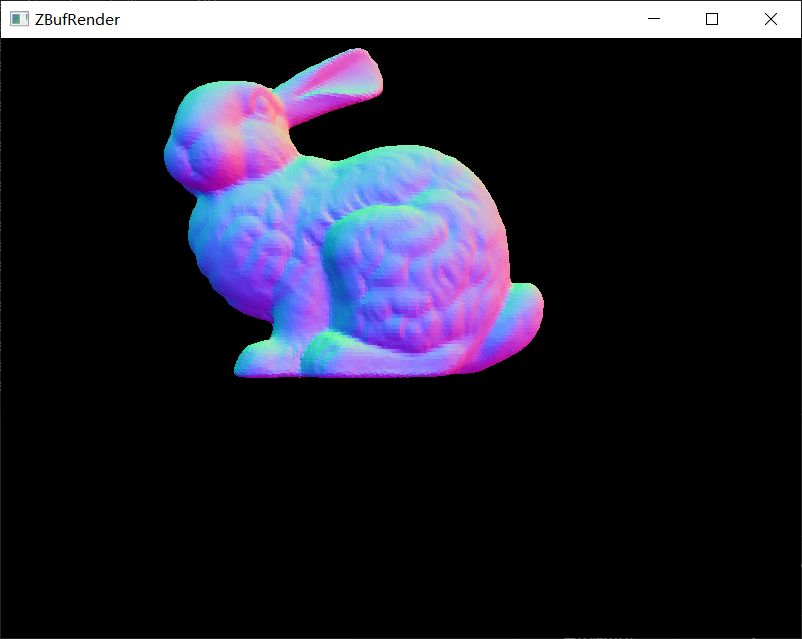 |
| armadillo_212k.obj | dragon_871k.obj |
|---|---|
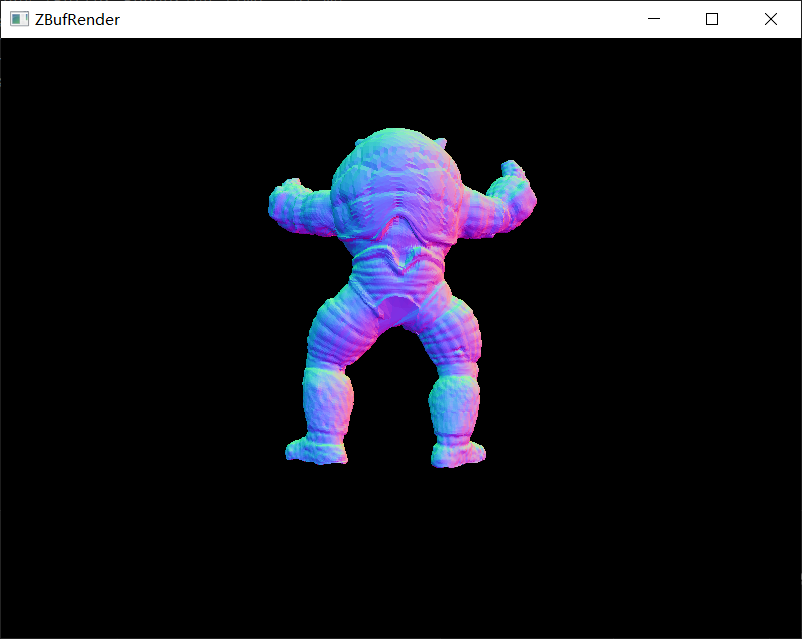 |
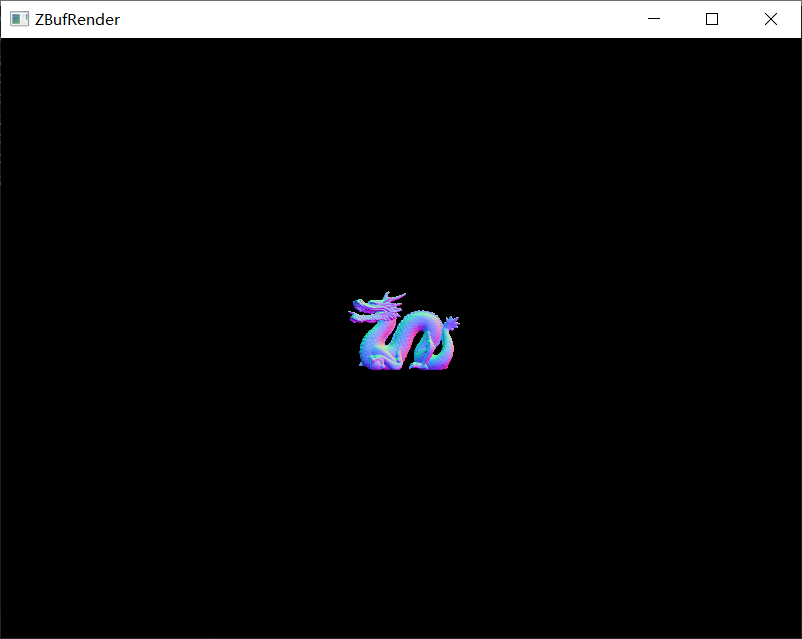 |
| 用时(ms) | suzanne_1k.obj | spot_5k.obj | bunny_69k.obj | armadillo_212k.obj | dragon_871k.obj |
|---|---|---|---|---|---|
| 渲染时间 | 2 | 6 | 88 | 275 | 858 |
| 用时(ms) | suzanne_1k.obj | spot_5k.obj | bunny_69k.obj | armadillo_212k.obj | dragon_871k.obj |
|---|---|---|---|---|---|
| CPT and CET 建立 | 0 | 1 | 23 | 42 | 145 |
| 渲染时间 | 1 | 3 | 193 | 364 | 135 |
注:CPT即 Classification Polygon Table (分类多边形表),CET 即 Classification Edge Table(分类边表)
dragon_871k.obj 的渲染时间很低的原因是根据同一摄像机位置,它在屏幕上的大小更小(如之前渲染的结果所示),因而需要光栅化的像素更少。
当定义不同的摄像机位置时,可以看到如下对比。
| 摄像机位置 | (0,0,6.5) | (0,0,3) |
|---|---|---|
| 渲染时间(ms) | 135 | 850 |
其渲染结果分别如下所示。
|
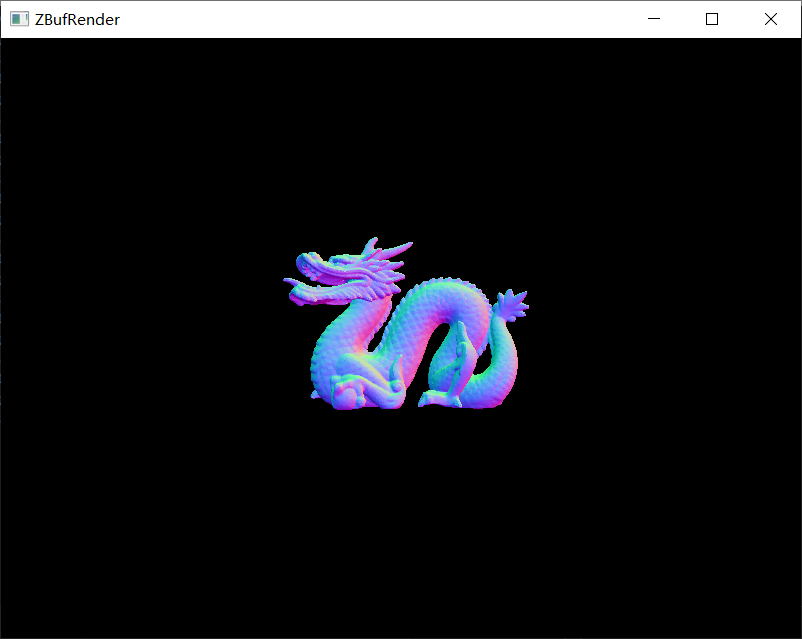 |
| 用时(ms) | suzanne_1k.obj | spot_5k.obj | bunny_69k.obj | armadillo_212k.obj | dragon_871k.obj |
|---|---|---|---|---|---|
| QuadTree 建立 | 87 | 83 | 81 | 79 | 89 |
| 渲染时间 | 14 | 5 | 55 | 85 | 169 |
可以看出四叉树的建立主要与屏幕大小相关。
为什么虽然 spot_5k.obj 的面片数比 suzanne_1k.obj 大,渲染时间反而更低是因为模型本身的原因。即使在摄像机在同一个位置,由于模型经过 MVP 矩阵变换之后占据屏幕空间的不同,对四叉树的建立与搜索会有较大影响。
| 用时(ms) | suzanne_1k.obj | spot_5k.obj | bunny_69k.obj | armadillo_212k.obj | dragon_871k.obj |
|---|---|---|---|---|---|
| QuadTree 建立 | 87 | 83 | 81 | 79 | 89 |
| Octree 建立 | 0 | 1 | 28 | 96 | 342 |
| 渲染时间 | 13 | 4 | 33 | 57 | 107 |
可以看出八叉树的场景建树会随着模型的增大逐渐变大;渲染时间相比于其他算法增大的速率较慢。
| 用时(ms) | suzanne_1k.obj | spot_5k.obj | bunny_69k.obj | armadillo_212k.obj | dragon_871k.obj |
|---|---|---|---|---|---|
| QuadTree 树 建立 | 83 | 83 | 81 | 79 | 89 |
| kd 树建立 | 0 | 1 | 27 | 92 | 312 |
| 渲染时间 | 13 | 5 | 37 | 71 | 190 |
相比于八叉树,kd 树的绘制时间稍慢了些。