
⚡ I'm a Machine Learning Engineer in Milan (Italy).
🔭 I’m currently working on different generative AI projects
🔷 Deep Learning for AI and Published Streamlit App for Age prediction!
In this course we've learned what Neural Networks are and how they can be used in modelling data. We used pytorch library for creating our projects. We covered different neural networks concept: starting from the linear neural network, we moved to the convolutional and RRN. We deepened some popular architectures like AlexNet, GoogleNet, LSTM, etc.
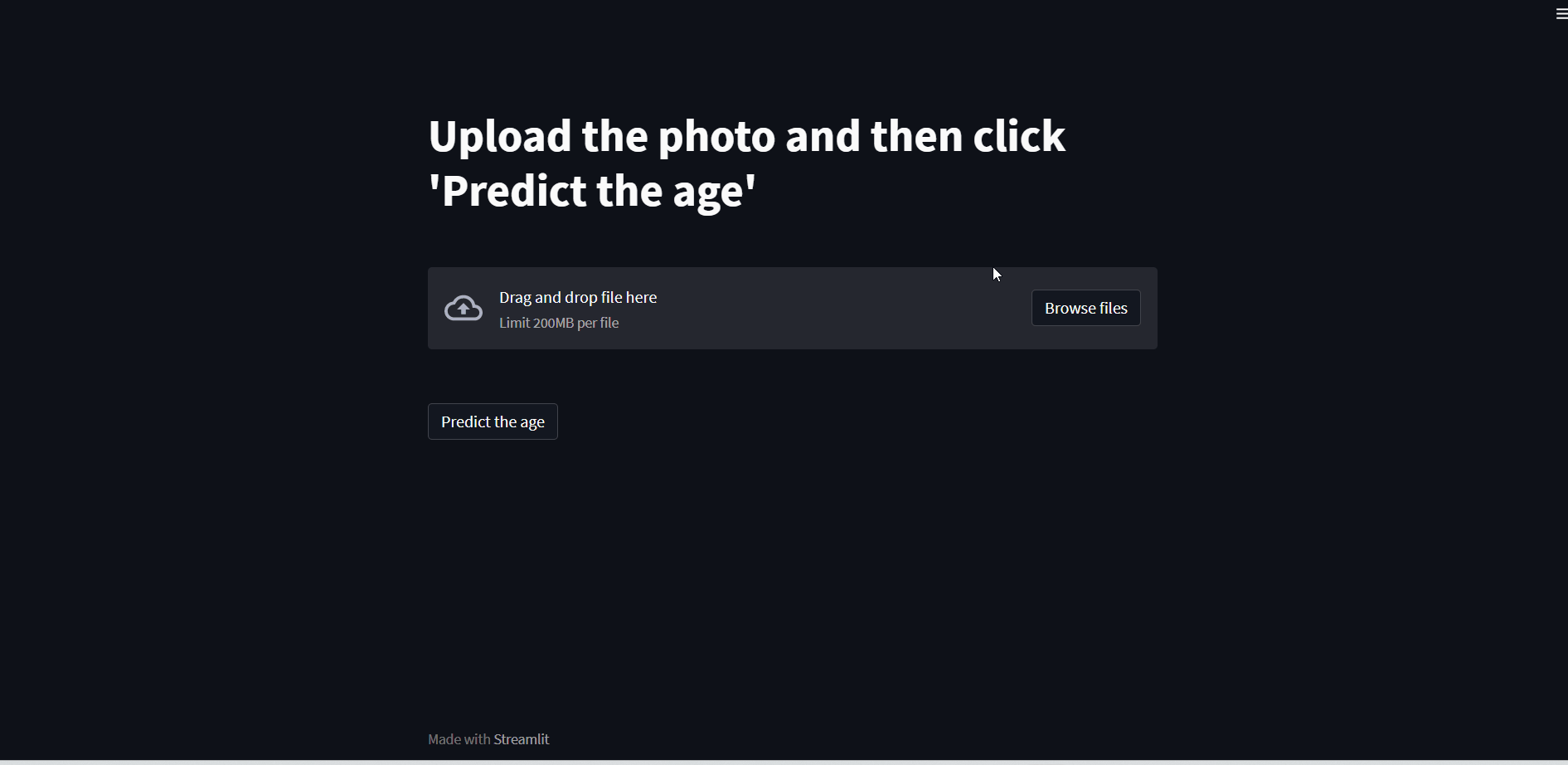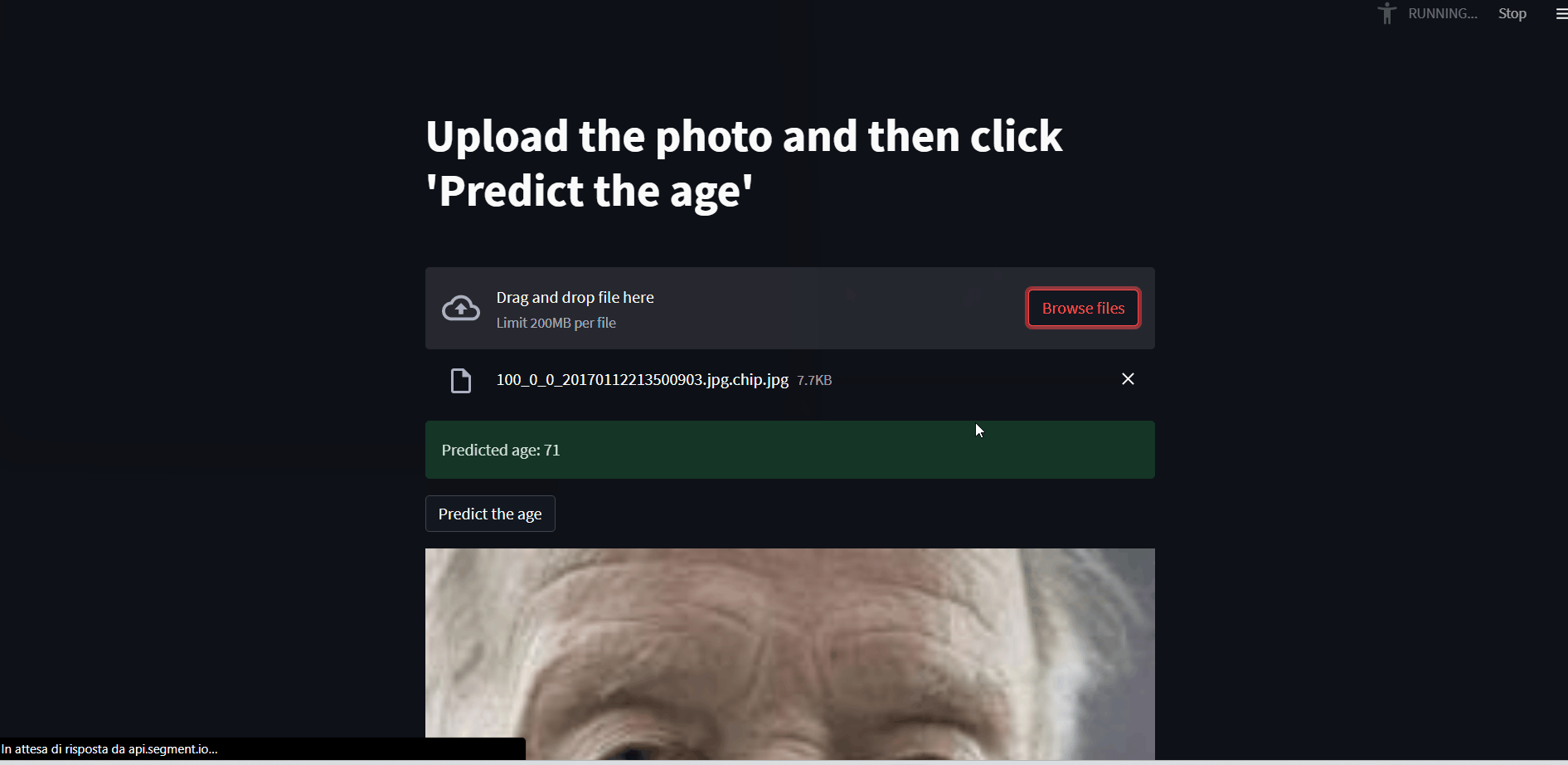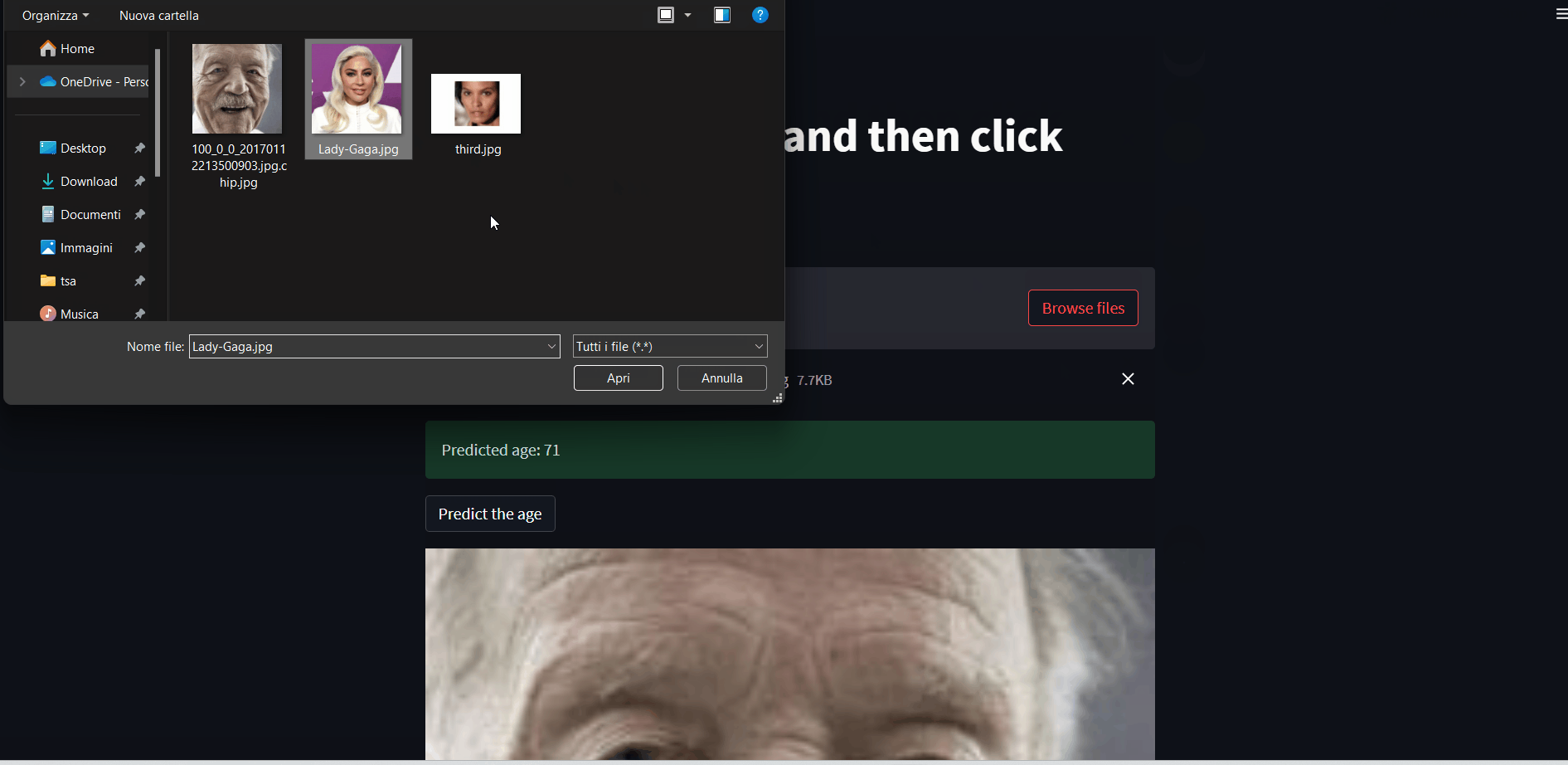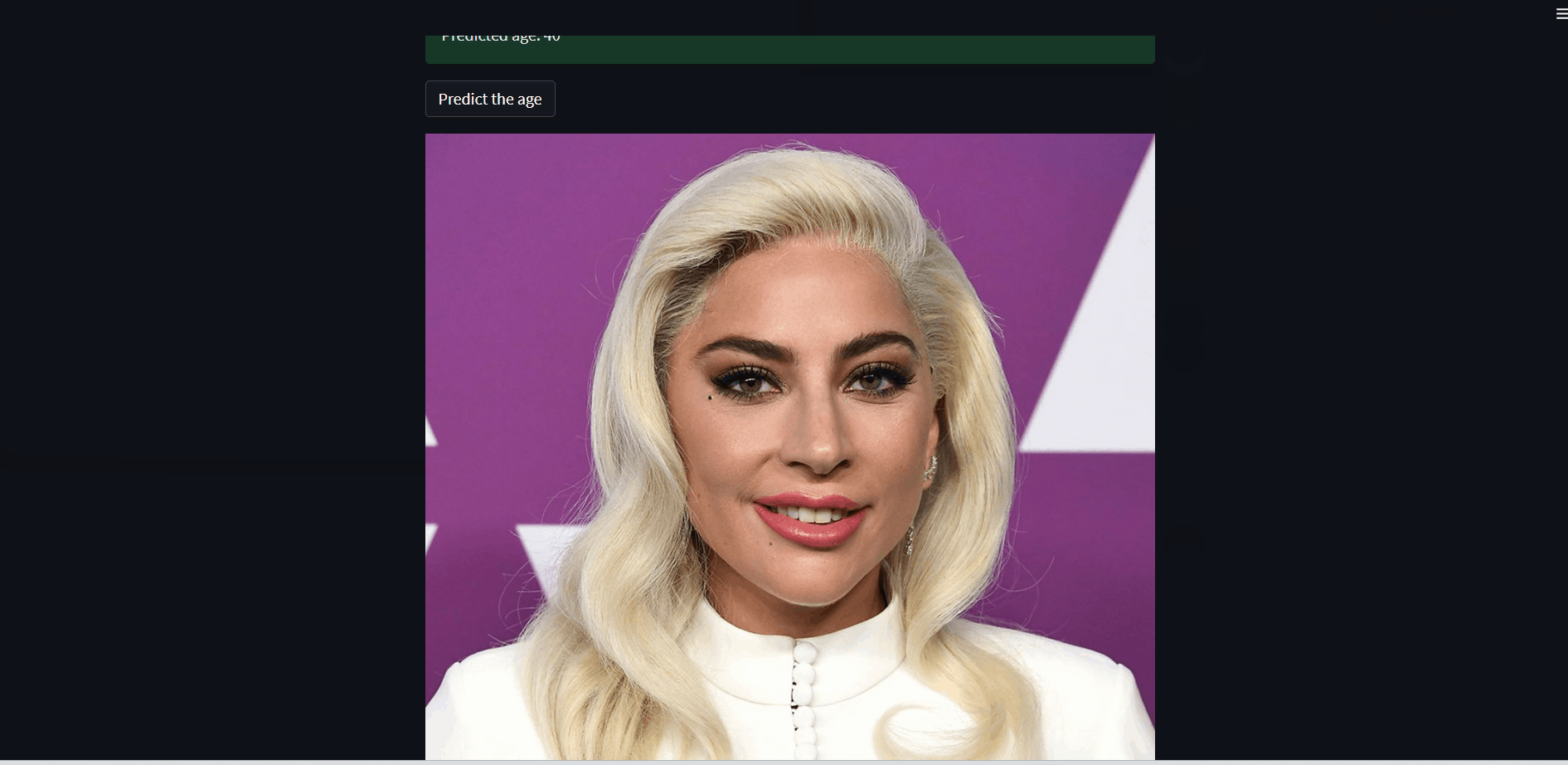
In general, we had to deal with the ethnicity classification and age prediction (as real value) starting from pictures of 20000+ people. The most difficult part of this project was the problem about the loss function and the distribution of the prediction - I explain this part better in the README file and, of course, in the notebook. In March I implemented a Streamlit app that returns the predicted age starting from a user-uploaded picture.
The course was made for understanding concept concerning time series analysis (stationarity, autocorrelation, etc.) and model this type of data.
Me and 3 colleagues of mine decided to model the wind energy production in Germany, using AR e ARX approach. Originally the project was made in R but I decided by myself to convert it in Python and moreover build a Flask web-app that can be used for specific forecast periods.

This course focuses on NLP, covering the concepts of: text classification and generation, Sentiment Analysis, Topic Modelling, Embeddings. Moreover, one of the most relevant part is focused on deep neural network applied to text, using NLTK, SpaCy, TensorFlow - Keras and Pytorch. In the last part we learnt the Attention Concept and how it's used for encoder-decoder algorithm and transformers.
The dataset, which is very popular in NLP tasks, contains about 20.000 documents divided into 20 categories. Our task was to classify the documents based on their content with three approaches: Machine Learning, Neural networks, Transformers.
The course focuses on linear models and generalized linear models employed to explain how a response variable relates to one or more explanatory variables. The arguments was related to linear regression in general, predictions, model validation and selection, and ended with generalized and mixed linear models
The project: Red Wine Quality
This is a brief description, a full analysis is available here. The dataset is probably one of the most known in data science field, our interest was to see how physiochemical properties affect the quality of the red wine using a Binomial model and a Multinomial model to divide the categories of the quality. The latter, which is the response variable, is given from feedback of different consumers of each wine.
Bayesian statistics is a powerful methodology that over the years has gained wide recognition because it is sound, flexible, produces clear answers, and makes use of a variety of information. It has become an indispensable resource for scientific and social science researchers. The course deal with foundations, models and computation.
Unlike the project about the red wine, this dataset is not known (when we used it, there was only 3 project about it on Kaggle). Given some features, the data comes from an original model which gives as response the Chance of being admitted to a certain Master Programme. Starting from this information, we tried to model those chance in two different way: a logistic regression and a beta regression. You can think about them as a very easy task, but what makes it different is the Bayesian Approach that led the development of this project. Enjoy it!
The complete analysis is in its repository here.
📫 You can find me on Linkedin and Kaggle:
![]()