Releases: microsoft/autogen
autogenstudio-v0.4.1
Whats New
AutoGen Studio Declarative Configuration
- in #5172, you can now build your agents in python and export to a json format that works in autogen studio
AutoGen studio now used the same declarative configuration interface as the rest of the AutoGen library. This means you can create your agent teams in python and then dump_component() it into a JSON spec that can be directly used in AutoGen Studio! This eliminates compatibility (or feature inconsistency) errors between AGS/AgentChat Python as the exact same specs can be used across.
See a video tutorial on AutoGen Studio v0.4 (02/25) - https://youtu.be/oum6EI7wohM
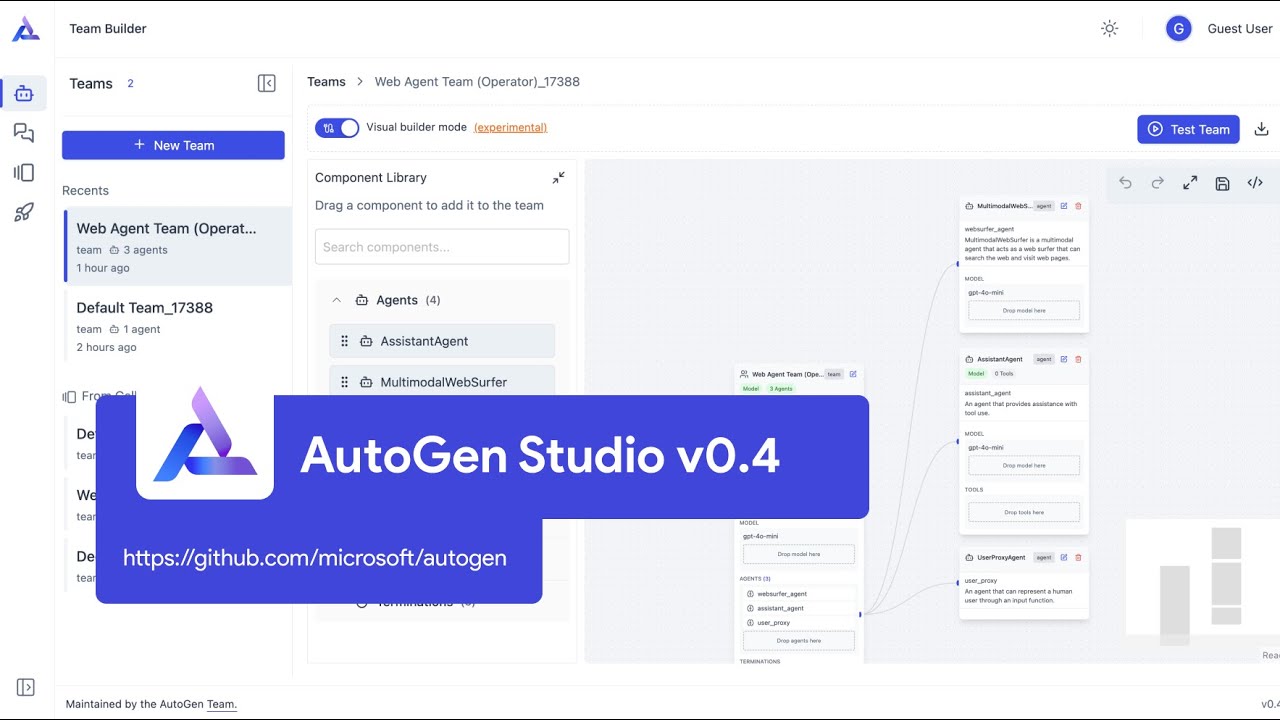
Here's an example of an agent team and how it is converted to a JSON file:
from autogen_agentchat.agents import AssistantAgent
from autogen_agentchat.teams import RoundRobinGroupChat
from autogen_ext.models.openai import OpenAIChatCompletionClient
from autogen_agentchat.conditions import TextMentionTermination
agent = AssistantAgent(
name="weather_agent",
model_client=OpenAIChatCompletionClient(
model="gpt-4o-mini",
),
)
agent_team = RoundRobinGroupChat([agent], termination_condition=TextMentionTermination("TERMINATE"))
config = agent_team.dump_component()
print(config.model_dump_json()){
"provider": "autogen_agentchat.teams.RoundRobinGroupChat",
"component_type": "team",
"version": 1,
"component_version": 1,
"description": "A team that runs a group chat with participants taking turns in a round-robin fashion\n to publish a message to all.",
"label": "RoundRobinGroupChat",
"config": {
"participants": [
{
"provider": "autogen_agentchat.agents.AssistantAgent",
"component_type": "agent",
"version": 1,
"component_version": 1,
"description": "An agent that provides assistance with tool use.",
"label": "AssistantAgent",
"config": {
"name": "weather_agent",
"model_client": {
"provider": "autogen_ext.models.openai.OpenAIChatCompletionClient",
"component_type": "model",
"version": 1,
"component_version": 1,
"description": "Chat completion client for OpenAI hosted models.",
"label": "OpenAIChatCompletionClient",
"config": { "model": "gpt-4o-mini" }
},
"tools": [],
"handoffs": [],
"model_context": {
"provider": "autogen_core.model_context.UnboundedChatCompletionContext",
"component_type": "chat_completion_context",
"version": 1,
"component_version": 1,
"description": "An unbounded chat completion context that keeps a view of the all the messages.",
"label": "UnboundedChatCompletionContext",
"config": {}
},
"description": "An agent that provides assistance with ability to use tools.",
"system_message": "You are a helpful AI assistant. Solve tasks using your tools. Reply with TERMINATE when the task has been completed.",
"model_client_stream": false,
"reflect_on_tool_use": false,
"tool_call_summary_format": "{result}"
}
}
],
"termination_condition": {
"provider": "autogen_agentchat.conditions.TextMentionTermination",
"component_type": "termination",
"version": 1,
"component_version": 1,
"description": "Terminate the conversation if a specific text is mentioned.",
"label": "TextMentionTermination",
"config": { "text": "TERMINATE" }
}
}
}Note: If you are building custom agents and want to use them in AGS, you will need to inherit from the AgentChat BaseChat agent and Component class.
Note: This is a breaking change in AutoGen Studio. You will need to update your AGS specs for any teams created with version autogenstudio <0.4.1
Ability to Test Teams in Team Builder
- in #5392, you can now test your teams as you build them. No need to switch between team builder and playground sessions to test.
You can now test teams directly as you build them in the team builder UI. As you edit your team (either via drag and drop or by editing the JSON spec)


New Default Agents in Gallery (Web Agent Team, Deep Research Team)
- in #5416, adds an implementation of a Web Agent Team and Deep Research Team in the default gallery.
The default gallery now has two additional default agents that you can build on and test:
- Web Agent Team - A team with 3 agents - a Web Surfer agent that can browse the web, a Verification Assistant that verifies and summarizes information, and a User Proxy that provides human feedback when needed.
- Deep Research Team - A team with 3 agents - a Research Assistant that performs web searches and analyzes information, a Verifier that ensures research quality and completeness, and a Summary Agent that provides a detailed markdown summary of the research as a report to the user.
Other Improvements
Older features that are currently possible in v0.4.1
- Real-time agent updates streaming to the frontend
- Run control: You can now stop agents mid-execution if they're heading in the wrong direction, adjust the team, and continue
- Interactive feedback: Add a UserProxyAgent to get human input through the UI during team runs
- Message flow visualization: See how agents communicate with each other
- Ability to import specifications from external galleries
- Ability to wrap agent teams into an API using the AutoGen Studio CLI
To update to the latest version:
pip install -U autogenstudioOverall roadmap for AutoGen Studion is here #4006 .
Contributions welcome!
python-v0.4.5
What's New
Streaming for AgentChat agents and teams
- Introduce ModelClientStreamingChunkEvent for streaming model output and update handling in agents and console by @ekzhu in #5208
To enable streaming from an AssistantAgent, set model_client_stream=True when creating it. The token stream will be available when you run the agent directly, or as part of a team when you call run_stream.
If you want to see tokens streaming in your console application, you can use Console directly.
import asyncio
from autogen_agentchat.agents import AssistantAgent
from autogen_agentchat.ui import Console
from autogen_ext.models.openai import OpenAIChatCompletionClient
async def main() -> None:
agent = AssistantAgent("assistant", OpenAIChatCompletionClient(model="gpt-4o"), model_client_stream=True)
await Console(agent.run_stream(task="Write a short story with a surprising ending."))
asyncio.run(main())If you are handling the messages yourself and streaming to the frontend, you can handle
autogen_agentchat.messages.ModelClientStreamingChunkEvent message.
import asyncio
from autogen_agentchat.agents import AssistantAgent
from autogen_ext.models.openai import OpenAIChatCompletionClient
async def main() -> None:
agent = AssistantAgent("assistant", OpenAIChatCompletionClient(model="gpt-4o"), model_client_stream=True)
async for message in agent.run_stream(task="Write 3 line poem."):
print(message)
asyncio.run(main())source='user' models_usage=None content='Write 3 line poem.' type='TextMessage'
source='assistant' models_usage=None content='Silent' type='ModelClientStreamingChunkEvent'
source='assistant' models_usage=None content=' whispers' type='ModelClientStreamingChunkEvent'
source='assistant' models_usage=None content=' glide' type='ModelClientStreamingChunkEvent'
source='assistant' models_usage=None content=',' type='ModelClientStreamingChunkEvent'
source='assistant' models_usage=None content=' \n' type='ModelClientStreamingChunkEvent'
source='assistant' models_usage=None content='Moon' type='ModelClientStreamingChunkEvent'
source='assistant' models_usage=None content='lit' type='ModelClientStreamingChunkEvent'
source='assistant' models_usage=None content=' dreams' type='ModelClientStreamingChunkEvent'
source='assistant' models_usage=None content=' dance' type='ModelClientStreamingChunkEvent'
source='assistant' models_usage=None content=' through' type='ModelClientStreamingChunkEvent'
source='assistant' models_usage=None content=' the' type='ModelClientStreamingChunkEvent'
source='assistant' models_usage=None content=' night' type='ModelClientStreamingChunkEvent'
source='assistant' models_usage=None content=',' type='ModelClientStreamingChunkEvent'
source='assistant' models_usage=None content=' \n' type='ModelClientStreamingChunkEvent'
source='assistant' models_usage=None content='Stars' type='ModelClientStreamingChunkEvent'
source='assistant' models_usage=None content=' watch' type='ModelClientStreamingChunkEvent'
source='assistant' models_usage=None content=' from' type='ModelClientStreamingChunkEvent'
source='assistant' models_usage=None content=' above' type='ModelClientStreamingChunkEvent'
source='assistant' models_usage=None content='.' type='ModelClientStreamingChunkEvent'
source='assistant' models_usage=RequestUsage(prompt_tokens=0, completion_tokens=0) content='Silent whispers glide, \nMoonlit dreams dance through the night, \nStars watch from above.' type='TextMessage'
TaskResult(messages=[TextMessage(source='user', models_usage=None, content='Write 3 line poem.', type='TextMessage'), TextMessage(source='assistant', models_usage=RequestUsage(prompt_tokens=0, completion_tokens=0), content='Silent whispers glide, \nMoonlit dreams dance through the night, \nStars watch from above.', type='TextMessage')], stop_reason=None)
Read more here: https://microsoft.github.io/autogen/stable/user-guide/agentchat-user-guide/tutorial/agents.html#streaming-tokens
Also, see the sample showing how to stream a team's messages to ChainLit frontend: https://github.com/microsoft/autogen/tree/python-v0.4.5/python/samples/agentchat_chainlit
R1-style reasoning output
import asyncio
from autogen_core.models import UserMessage, ModelFamily
from autogen_ext.models.openai import OpenAIChatCompletionClient
async def main() -> None:
model_client = OpenAIChatCompletionClient(
model="deepseek-r1:1.5b",
api_key="placeholder",
base_url="http://localhost:11434/v1",
model_info={
"function_calling": False,
"json_output": False,
"vision": False,
"family": ModelFamily.R1,
}
)
# Test basic completion with the Ollama deepseek-r1:1.5b model.
create_result = await model_client.create(
messages=[
UserMessage(
content="Taking two balls from a bag of 10 green balls and 20 red balls, "
"what is the probability of getting a green and a red balls?",
source="user",
),
]
)
# CreateResult.thought field contains the thinking content.
print(create_result.thought)
print(create_result.content)
asyncio.run(main())Streaming is also supported with R1-style reasoning output.
See the sample showing R1 playing chess: https://github.com/microsoft/autogen/tree/python-v0.4.5/python/samples/agentchat_chess_game
FunctionTool for partial functions
- FunctionTool partial support by @nour-bouzid in #5183
Now you can define function tools from partial functions, where some parameters have been set before hand.
import json
from functools import partial
from autogen_core.tools import FunctionTool
def get_weather(country: str, city: str) -> str:
return f"The temperature in {city}, {country} is 75°"
partial_function = partial(get_weather, "Germany")
tool = FunctionTool(partial_function, description="Partial function tool.")
print(json.dumps(tool.schema, indent=2)){
"name": "get_weather",
"description": "Partial function tool.",
"parameters": {
"type": "object",
"properties": {
"city": {
"description": "city",
"title": "City",
"type": "string"
}
},
"required": [
"city"
]
}
}CodeExecutorAgent update
New Samples
- Streamlit + AgentChat sample by @husseinkorly in #5306
- ChainLit + AgentChat sample with streaming by @ekzhu in #5304
- Chess sample showing R1-Style reasoning for planning and strategizing by @ekzhu in #5285
Documentation update:
- Add Semantic Kernel Adapter documentation and usage examples in user guides by @ekzhu in #5256
- Update human-in-the-loop tutorial with better system message to signal termination condition by @ekzhu in #5253
Moves
Bug Fixes
- fix: handle non-string function arguments in tool calls and add corresponding warnings by @ekzhu in #5260
- Add default_header support by @nour-bouzid in #5249
- feat: update OpenAIAssistantAgent to support AsyncAzureOpenAI client by @ekzhu in #5312
All Other Python Related Changes
- Update website for v0.4.4 by @ekzhu in #5246
- update dependencies to work with protobuf 5 by @MohMaz in #5195
- Adjusted M1 agent system prompt to remove TERMINATE by @afourney in #5263
#5270 - chore: update package versions to 0.4.5 and remove deprecated requirements by @ekzhu in #5280
- Update Distributed Agent Runtime Cross-platform Sample by @linznin in #5164
- fix: windows check ci failure by @bassmang in #5287
- fix: type issues in streamlit sample and add streamlit to dev dependencies by @ekzhu in #5309
- chore: add asyncio_atexit dependency to docker requirements by @ekzhu in #5307
- feat: add o3 to model info; update chess example by @ekzhu in #5311
New Contributors
- @nour-bouzid made their first contribution in #5183
- @linznin made their first contribution in #5164
- @husseinkorly made their first contribution in #5306
Full Changelog: v0.4.4...python-v0.4.5
Contributors
Assets 2
python-v0.4.4
What's New
Serializable Configuration for AgentChat
- Make FunctionTools Serializable (Declarative) by @victordibia in #5052
- Make AgentChat Team Config Serializable by @victordibia in #5071
- improve component config, add description support in dump_component by @victordibia in #5203
This new feature allows you to serialize an agent or a team to a JSON string, and deserialize them back into objects. Make sure to also read about save_state and load_state: https://microsoft.github.io/autogen/stable/user-guide/agentchat-user-guide/tutorial/state.html.
You now can serialize and deserialize both the configurations and the state of agents and teams.
For example, create a RoundRobinGroupChat, and serialize its configuration and state.
import asyncio
from autogen_agentchat.agents import AssistantAgent
from autogen_agentchat.teams import RoundRobinGroupChat
from autogen_agentchat.base import Team
from autogen_agentchat.ui import Console
from autogen_agentchat.conditions import TextMentionTermination
from autogen_ext.models.openai import OpenAIChatCompletionClient
async def dump_team_config() -> None:
model_client = OpenAIChatCompletionClient(model="gpt-4o")
assistant = AssistantAgent(
"assistant",
model_client=model_client,
system_message="You are a helpful assistant.",
)
critic = AssistantAgent(
"critic",
model_client=model_client,
system_message="Provide feedback. Reply with 'APPROVE' if the feedback has been addressed.",
)
termination = TextMentionTermination("APPROVE", sources=["critic"])
group_chat = RoundRobinGroupChat(
[assistant, critic], termination_condition=termination
)
# Run the group chat.
await Console(group_chat.run_stream(task="Write a short poem about winter."))
# Dump the team configuration to a JSON file.
config = group_chat.dump_component()
with open("team_config.json", "w") as f:
f.write(config.model_dump_json(indent=4))
# Dump the team state to a JSON file.
state = await group_chat.save_state()
with open("team_state.json", "w") as f:
f.write(json.dumps(state, indent=4))
asyncio.run(dump_team_config())Produces serialized team configuration and state. Truncated for illustration purpose.
{
"provider": "autogen_agentchat.teams.RoundRobinGroupChat",
"component_type": "team",
"version": 1,
"component_version": 1,
"description": "A team that runs a group chat with participants taking turns in a round-robin fashion\n to publish a message to all.",
"label": "RoundRobinGroupChat",
"config": {
"participants": [
{
"provider": "autogen_agentchat.agents.AssistantAgent",
"component_type": "agent",
"version": 1,
"component_version": 1,
"description": "An agent that provides assistance with tool use.",
"label": "AssistantAgent",
"config": {
"name": "assistant",
"model_client": {
"provider": "autogen_ext.models.openai.OpenAIChatCompletionClient",
"component_type": "model",
"version": 1,
"component_version": 1,
"description": "Chat completion client for OpenAI hosted models.",
"label": "OpenAIChatCompletionClient",
"config": {
"model": "gpt-4o"
}{
"type": "TeamState",
"version": "1.0.0",
"agent_states": {
"group_chat_manager/25763eb1-78b2-4509-8607-7224ae383575": {
"type": "RoundRobinManagerState",
"version": "1.0.0",
"message_thread": [
{
"source": "user",
"models_usage": null,
"content": "Write a short poem about winter.",
"type": "TextMessage"
},
{
"source": "assistant",
"models_usage": {
"prompt_tokens": 25,
"completion_tokens": 150
},
"content": "Amidst the still and silent air, \nWhere frost adorns the branches bare, \nThe world transforms in shades of white, \nA wondrous, shimmering, quiet sight.\n\nThe whisper of the wind is low, \nAs snowflakes drift and dance and glow. \nEach crystal, delicate and bright, \nFalls gently through the silver night.\n\nThe earth is hushed in pure embrace, \nA tranquil, glistening, untouched space. \nYet warmth resides in hearts that roam, \nFinding solace in the hearth of home.\n\nIn winter\u2019s breath, a promise lies, \nBeneath the veil of cold, clear skies: \nThat spring will wake the sleeping land, \nAnd life will bloom where now we stand.",
"type": "TextMessage"Load the configuration and state back into objects.
import asyncio
import json
from autogen_agentchat.teams import RoundRobinGroupChat
from autogen_agentchat.base import Team
async def load_team_config() -> None:
# Load the team configuration from a JSON file.
with open("team_config.json", "r") as f:
config = json.load(f)
group_chat = Team.load_component(config)
# Load the team state from a JSON file.
with open("team_state.json", "r") as f:
state = json.load(f)
await group_chat.load_state(state)
assert isinstance(group_chat, RoundRobinGroupChat)
asyncio.run(load_team_config())This new feature allows you to manage persistent sessions across server-client based user interaction.
Azure AI Client for Azure-Hosted Models
- Feature/azure ai inference client by @lspinheiro and @rohanthacker in #5153
This allows you to use Azure and GitHub-hosted models, including Phi-4, Mistral models, and Cohere models.
import asyncio
import os
from autogen_core.models import UserMessage
from autogen_ext.models.azure import AzureAIChatCompletionClient
from azure.core.credentials import AzureKeyCredential
async def main() -> None:
client = AzureAIChatCompletionClient(
model="Phi-4",
endpoint="https://models.inference.ai.azure.com",
# To authenticate with the model you will need to generate a personal access token (PAT) in your GitHub settings.
# Create your PAT token by following instructions here: https://docs.github.com/en/authentication/keeping-your-account-and-data-secure/managing-your-personal-access-tokens
credential=AzureKeyCredential(os.environ["GITHUB_TOKEN"]),
model_info={
"json_output": False,
"function_calling": False,
"vision": False,
"family": "unknown",
},
)
result = await client.create(
[UserMessage(content="What is the capital of France?", source="user")]
)
print(result)
asyncio.run(main())Rich Console UI for Magentic One CLI
You can now enable pretty printed output for m1 command line tool by adding --rich argument.
m1 --rich "Find information about AutoGen"
Default In-Memory Cache for ChatCompletionCache
- Implement default in-memory store for ChatCompletionCache by @srjoglekar246 in #5188
This allows you to cache model client calls without specifying an external cache service.
import asyncio
from autogen_core.models import UserMessage
from autogen_ext.models.openai import OpenAIChatCompletionClient
from autogen_ext.models.cache import ChatCompletionCache
async def main() -> None:
# Create a model client.
client = OpenAIChatCompletionClient(model="gpt-4o")
# Create a cached wrapper around the model client.
cached_client = ChatCompletionCache(client)
# Call the cached client.
result = await cached_client.create(
[UserMessage(content="What is the capital of France?", source="user")]
)
print(result.content, result.cached)
# Call the cached client again.
result = await cached_client.create(
[UserMessage(content="What is the capital of France?", source="user")]
)
print(result.content, result.cached)
asyncio.run(main())The capital of France is Paris. False
The capital of France is Paris. True
Docs Update
- Update model client documentation add Ollama, Gemini, Azure AI models by @ekzhu in #5196
- Add Model Client Cache section to migration guide by @ekzhu in #5197
- docs: Enhance documentation for SingleThreadedAgentRuntime with usage examples and clarifications; undeprecate process_next by @ekzhu in #5230
- docs: Update user guide notebooks to enhance clarity and add structured output by @ekzhu in #5224
- docs: Core API doc update: split out model context from model clients; separate framework and components by @ekzhu in #5171
- docs: Add a helpful comment to swarm.ipynb by @withsmilo in https://github.com/microsoft/autogen...
Contributors
Assets 2
python-v0.4.3
What's new
This is the first release since 0.4.0 with significant new features! We look forward to hearing feedback and suggestions from the community.
Chat completion model cache
One of the big missing features from 0.2 was the ability to seamlessly cache model client completions. This release adds ChatCompletionCache which can wrap any other ChatCompletionClient and cache completions.
There is a CacheStore interface to allow for easy implementation of new caching backends. The currently available implementations are:
import asyncio
import tempfile
from autogen_core.models import UserMessage
from autogen_ext.models.openai import OpenAIChatCompletionClient
from autogen_ext.models.cache import ChatCompletionCache, CHAT_CACHE_VALUE_TYPE
from autogen_ext.cache_store.diskcache import DiskCacheStore
from diskcache import Cache
async def main():
with tempfile.TemporaryDirectory() as tmpdirname:
openai_model_client = OpenAIChatCompletionClient(model="gpt-4o")
cache_store = DiskCacheStore[CHAT_CACHE_VALUE_TYPE](Cache(tmpdirname))
cache_client = ChatCompletionCache(openai_model_client, cache_store)
response = await cache_client.create([UserMessage(content="Hello, how are you?", source="user")])
print(response) # Should print response from OpenAI
response = await cache_client.create([UserMessage(content="Hello, how are you?", source="user")])
print(response) # Should print cached response
asyncio.run(main())ChatCompletionCache is not yet supported by the declarative component config, see the issue to track progress.
GraphRAG
This releases adds support for GraphRAG as a tool agents can call. You can find a sample for how to use this integration here, and docs for LocalSearchTool and GlobalSearchTool.
import asyncio
from autogen_ext.models.openai import OpenAIChatCompletionClient
from autogen_agentchat.ui import Console
from autogen_ext.tools.graphrag import GlobalSearchTool
from autogen_agentchat.agents import AssistantAgent
async def main():
# Initialize the OpenAI client
openai_client = OpenAIChatCompletionClient(
model="gpt-4o-mini",
)
# Set up global search tool
global_tool = GlobalSearchTool.from_settings(settings_path="./settings.yaml")
# Create assistant agent with the global search tool
assistant_agent = AssistantAgent(
name="search_assistant",
tools=[global_tool],
model_client=openai_client,
system_message=(
"You are a tool selector AI assistant using the GraphRAG framework. "
"Your primary task is to determine the appropriate search tool to call based on the user's query. "
"For broader, abstract questions requiring a comprehensive understanding of the dataset, call the 'global_search' function."
),
)
# Run a sample query
query = "What is the overall sentiment of the community reports?"
await Console(assistant_agent.run_stream(task=query))
if __name__ == "__main__":
asyncio.run(main())#4612 by @lspinheiro
Semantic Kernel model adapter
Semantic Kernel has an extensive collection of AI connectors. In this release we added support to adapt a Semantic Kernel AI Connector to an AutoGen ChatCompletionClient using the SKChatCompletionAdapter.
Currently this requires passing the kernel during create, and so cannot be used with AssistantAgent directly yet. This will be fixed in a future release (#5144).
#4851 by @lspinheiro
AutoGen to Semantic Kernel tool adapter
We also added a tool adapter, but this time to allow AutoGen tools to be added to a Kernel, called KernelFunctionFromTool.
#4851 by @lspinheiro
Jupyter Code Executor
This release also brings forward Jupyter code executor functionality that we had in 0.2, as the JupyterCodeExecutor.
Please note that this currently on supports local execution and should be used with caution.
Memory
It's still early on but we merged the interface for agent memory in this release. This allows agents to enrich their context from a memory store and save information to it. The interface is defined in core and AssistantAgent in agentchat accepts memory as a parameter now. There is an initial example memory implementation which simply injects all memories as system messages for the agent. The intention is for the memory interface to be able to be used for both RAG and agent memory systems going forward.
- Tutorial
- Core
Memoryinterface - Existing
AssistantAgentwith new memory parameter
#4438 by @victordibia, #5053 by @ekzhu
Declarative config
We're continuing to expand support for declarative configs throughout the framework. In this release, we've added support for termination conditions and base chat agents. Once we're done with this, you'll be able to configure and entire team of agents with a single config file and have it work seamlessly with AutoGen studio. Stay tuned!
#4984, #5055 by @victordibia
Other
- Add sources field to TextMentionTermination by @Leon0402 in #5106
- Update gpt-4o model version to 2024-08-06 by @ekzhu in #5117
Bug fixes
- Retry multiple times when M1 selects an invalid agent. Make agent sel… by @afourney in #5079
- fix: normalize finish reason in CreateResult response by @ekzhu in #5085
- Pass context between AssistantAgent for handoffs by @ekzhu in #5084
- fix: ensure proper handling of structured output in OpenAI client and improve test coverage for structured output by @ekzhu in #5116
- fix: use tool_calls field to detect tool calls in OpenAI client; add integration tests for OpenAI and Gemini by @ekzhu in #5122
Other changes
- Update website for 0.4.1 by @jackgerrits in #5031
- PoC AGS dev container by @JohanForngren in #5026
- Update studio dep by @ekzhu in #5062
- Update studio dep to use version bound by @ekzhu in #5063
- Update gpt-4o model version and add new model details by @keenranger in #5056
- Improve AGS Documentation by @victordibia in #5065
- Pin uv to 0.5.18 by @jackgerrits in #5067
- Update version to 0.4.3 pre-emptively by @jackgerrits in #5066
- fix: dotnet azure pipeline (uv sync installation) by @bassmang in #5042
- docs: .NET Documentation by @lokitoth in #5039
- [Documentation] Update tools.ipynb: use system messages in the tool_agent_caller_loop session by @zysoong in #5068
- docs: enhance agents.ipynb with parallel tool calls section by @ekzhu in #5088
- Use caching to run tests and report coverage by @lspinheiro in #5086
- fix: ESPR dotnet code signing by @bassmang in #5081
- Update AGS pyproject.toml by @victordibia in #5101
- docs: update AssistantAgent documentation with a new figure, attention and warning notes by @ekzhu in #5099
- Rysweet fix integration tests and xlang by...
Contributors
Assets 2
python-v0.4.2
- Change async input strategy in order to remove unintentional and accidentally added GPL dependency (#5060)
Full Changelog: v0.4.1...v0.4.2
python-v0.4.1
What's Important
- Fixed console user input bug that affects
m1and other apps that use console user input. #4995 - Improved component config by allowing subclassing the
BaseComponentclass. #5017 To read more about how to create your own component config to support serializable components: https://microsoft.github.io/autogen/stable/user-guide/core-user-guide/framework/component-config.html - Fixed
stop_reasonrelated bug by making the stop reason setting more robust #5027 - Disable
Consoleoutput statistics by default. - Minor doc fixes.
All Changes since v0.4.0
- Update magentic-one-cli version to 0.2.0 by @jackgerrits in #4973
- Update switcher versions and make 0.4.0 stable by @jackgerrits in #4940
- Fix version switcher rendering by @jackgerrits in #4974
- Don't show banner on stable by @jackgerrits in #4976
- Remove accidentally added character by @jackgerrits in #4980
- Update README.md to fix spelling error by @guinaut in #4982
- Minor API doc update for openai assistant agent by @ekzhu in #4986
- Add guidance for docstrings when adding an API by @jackgerrits in #4981
- Fix typo in
Multi-Agent Design Patterns -> Introdocs by @timrogers in #4991 - Add missing py.typed in autogen_ext, fix type issue in core by @jackgerrits in #4993
- Minor Updates to AGS Docs by @victordibia in #5010
- Fix: Properly await
agent.run()in READMEHello Worldexample by @Programmer-RD-AI in #5013 - Add python version requirement to frontpage and readme by @ekzhu in #5014
- Disable output usage stat summary in Console as the stats is often inaccurate. by @ekzhu in #5021
- Add AGS to README.md by @ekzhu in #5019
- fix: fix user input in m1 by @jackgerrits in #4995
- Typo in teams.ipynb by @SudhakarPunniyakotti in #5028
- fix: Normalize openai client stop reason to make more robust by @jackgerrits in #5027
- Add tiktoken as a dependency in pyproject.toml by @JohanForngren in #5008
- fix: Fix provider string for AzureTokenProvider by @jackgerrits in #4992
- Split apart component infra to allow for abstract class integration by @jackgerrits in #5017
- Update version to 0.4.1 by @jackgerrits in #5029
- Fixup autogen-ext version by @jackgerrits in #5030
New Contributors
- @guinaut made their first contribution in #4982
- @timrogers made their first contribution in #4991
- @Programmer-RD-AI made their first contribution in #5013
- @SudhakarPunniyakotti made their first contribution in #5028
- @JohanForngren made their first contribution in #5008
Full Changelog: v0.4.0...v0.4.1
Contributors
Assets 2
python-v0.4.0
What's Important
🎉 🎈 Our first stable release of v0.4! 🎈 🎉
To upgrade from v0.2, read the migration guide. For a basic setup:
pip install -U "autogen-agentchat" "autogen-ext[openai]"You can refer to our updated README for more information about the new API.
Major Changes from v0.4.0.dev13
- [New] Added m1 cli package by @afourney in #4949
- [New] Activate deactivate agents by @peterychang in #4800
- [New] Add coverage task & integrate with poe check by @srjoglekar246 in #4847
- [New] Move core samples to /python/samples by @ekzhu in #4911
- [New] feat: Add o1-2024-12-17 model by @bassmang in #4965
- [Breaking] fix!: Move azure auth provider to separate module by @jackgerrits in #4912
- [Breaking] feat!: Add message context to signature of intervention handler, add more to docs by @jackgerrits in #4882
- [Breaking] Remove deprecated items for release by @jackgerrits in #4927
Change Log from v0.4.0.dev13: v0.4.0.dev13...v0.4.0
New Contributors to v0.4.0
❤️ Big thanks to all the contributors since the first preview version was open sourced. ❤️
- @lspinheiro made their first contribution in #3652
- @husseinmozannar made their first contribution in #3714
- @NiklasGustafsson made their first contribution in #3727
- @maxgolov made their first contribution in #3758
- @vikas434 made their first contribution in #3770
- @tarockey made their first contribution in #3813
- @zboyles made their first contribution in #3855
- @markdouthwaite made their first contribution in #3871
- @gziz made their first contribution in #3876
- @SeryioGonzalez made their first contribution in #3901
- @rohanthacker made their first contribution in #3929
- @Ucoming made their first contribution in #3979
- @auphof made their first contribution in #3972
- @ReubenBond made their first contribution in #4034
- @maheshpec made their first contribution in #4070
- @mbaneshi made their first contribution in #4168
- @hasamm90 made their first contribution in #4170
- @tsinggggg made their first contribution in #4130
- @genlin made their first contribution in #4205
- @kkasemos made their first contribution in #4218
- @JMLX42 made their first contribution in #4201
- @ksachdeva made their first contribution in #4265
- @MervinPraison made their first contribution in #4280
- @thainduy made their first contribution in #4123
- @goyalpramod made their first contribution in #4149
- @kartikx made their first contribution in #4336
- @wi-ski made their first contribution in #4102
- @timparka made their first contribution in #4432
- @vballoli made their first contribution in #4548
- @eranco74 made their first contribution in #4639
- @hsm207 made their first contribution in #4655
- @iamarunbrahma made their first contribution in #4500
- @inbal2l made their first contribution in #4717
- @r-bit-rry made their first contribution in #4759
- @jspv made their first contribution in #4755
- @akurniawan made their first contribution in #4681
- @lanbaoshen made their first contribution in #4767
- @srjoglekar246 made their first contribution in #4801
- @richard-gyiko made their first contribution in #4826
- @kimmywork made their first contribution in #4732
- @Leon0402 made their first contribution in #4848
- @w121211 made their first contribution in #4874
- @PratyushNag made their first contribution in #4903
Changes from v0.2.36
- Use trusted publisher for pypi release by @jackgerrits in #3596
- Fix typos in Cerebras doc by @henrytwo in #3590
- Add blog post announcing the new architecture preview by @jackgerrits in #3599
- Fix dotnet test and reformat dotnet code by @LittleLittleCloud in #3603
- Update PR link in blog post by @jackgerrits in #3602
- Create CI to tag issues with needs triage by @jackgerrits in #3605
- Update Magentic-One Results by @afourney in #3611
- Update issue templates by @jackgerrits in #3610
- add logging to agentchat by @victordibia in #3606
- Add staging to workflow target; fix circular imports in autogen_agentchat by @ekzhu in #3651
- Add redirects from current website to /0.2/ by @jackgerrits in #3659
- Remove accidentally added files from 0.2 by @jackgerrits in #3661
- Try fix docs CI by @jackgerrits in #3660
- fix: remove subscription on client disconnect in worker runtime by @MohMaz in #3653
- Move tools to agent in
agentchat; refactored logging to support tool events by @ekzhu in #3665 - [.Net] Remove merging primitive from .editorconfig and gitignore by @LittleLittleCloud in #3676
- Add poethepoet to dev deps by @jackgerrits in #3675
- Rysweet hello fix by @rysweet in #3683
- add a way to provide extra grpc options by @MohMaz in #3667
- Selector group chat that uses LLM to select the next speaker by @ekzhu in #3680
- Add Documentation for AgentChat by @victordibia in #3635
- Set logging of internal messages to debug by @ekzhu in #3694
- Lspinheiro/chore/migrate azure executor autogen ext by @lspinheiro in #3652
- remove broken sample and update readme quickstart for the good sample by @rysweet in #3687
- Website design tweaks by @jackgerrits in #3699
- Termination condition for agentchat teams by @ekzhu in #3696
- Rysweet dotnet folder moves by @rysweet in #3693
- add documentation for dotnet AutoGen 0.4 HellowWorld sample by @rysweet in #3698
- Add clarity to new site by @jackgerrits in #3704
- Documentation tweaks by @jackgerrits in #3705
- Add more FAQs to readme by @jackgerrits in #3707
- Include license file in package by @jackgerrits in #3703
- Update references by @jackgerrits in #3708
- Refactor logging in agentchat by @ekzhu in #3709
- New AutoGen Architecture Preview by @jackgerrits in #3600
- Fix output directory for website by @jackgerrits in #3712
- Update logo link by @jackgerrits in #3713
- Fix redirects taking into account base path by @jackgerrits in #3716
- Fix packages link by @jackgerrits in #3718
- Move from tomllib to tomli by @husseinmozannar in #3714
- Add workflow for package releases by @jackgerrits i...
Contributors
Assets 2
v0.4.0.dev13
What's new
- An initial version of the migration guide is ready. Find it here! (#4765)
- Model family is now available in the model client (#4856)
Breaking changes
- Previously deprecated module paths have been removed (#4853)
SingleThreadedAgentRuntime.process_nextis now blocking and has moved to be an internal API (#4855)
Fixes
- Fix SingleThreadedAgentRuntime busy loop by @jackgerrits in #4855
- Fix BaseOpenAIChatCompletionClient token usage by @gziz in #4770
Doc changes
- Migration guide for 0.4 by @ekzhu in #4765
- Clarify tool use in agent tutorial by @ekzhu in #4860
- AgentChat tutorial update to include model context usage and langchain tool by @ekzhu in #4843
- Add missing model context attribute by @Leon0402 in #4848
Other
- Replace Tuple[type[ChatMessage], ...] with Sequence[type[ChatMessage]] by @ekzhu in #4857
- Make
register_factorya user facing API by @jackgerrits in #4854 - Move intervention objects to root module by @jackgerrits in #4859
New Contributors
Full Changelog: v0.4.0.dev12...v0.4.0.dev13
Contributors
Assets 2
v0.4.0.dev12
Important Changes
runandrun_streamnow support a list of messages astaskinput.- Introduces
AgentEventunion type in AgentChat, for all messages that are not meant to be consumed by other agents. ReplaceAgentMessagewithAgentEvent | ChatMessageunion type in your code, e.g., in your custom selector function forSelectorGroupChatand processing code forTaskResult.messages. - Introduce
ToolCallSummaryMessagetoChatMessagefor tool call results from agents. Read AssistantAgent Doc - Introduce
ModelContextparameter forAssistantAgent, allow usage ofBufferedChatCompletionContextto limit context window size sent to model. - Introduce
ComponentConfigand add configuration loader forChatCompletionClient. See Component Config - Moved
autogen_core.tools.PythonCodeExecutorTooltoautogen_ext.tools.code_execution.PythonCodeExecutionTool. - Documentation updates.
Upcoming Changes
- Deprecating
@message_handler. Use@eventor@rpcto annotate handlers instead.@message_handlerwill be kept with a deprecation warning until further notice. #4828 - Token counting mechanism bug fixes #4719
New Contributors
- @hsm207 made their first contribution in #4655
- @iamarunbrahma made their first contribution in #4500
- @inbal2l made their first contribution in #4717
- @r-bit-rry made their first contribution in #4759
- @jspv made their first contribution in #4755
- @akurniawan made their first contribution in #4681
- @lanbaoshen made their first contribution in #4767
- @srjoglekar246 made their first contribution in #4801
- @richard-gyiko made their first contribution in #4826
- @kimmywork made their first contribution in #4732
Full Changelog: v0.4.0.dev11...v0.4.0.dev12
Contributors
Assets 2
v0.2.40
What's Changed
- Add warning message when NoEligibleSpeaker by @thinkall in #4535
- [Bug]: Bedrock client uses incorrect environment variables for authentication by @vaisakh-prod in #4657
- fix "keep_first_message" to make sure messages are in correct order, by @milkmeat in #4653
- fix: No context vars for async agents replies by @violonistahiles in #4640
- update version by @ekzhu in #4713
New Contributors
- @vaisakh-prod made their first contribution in #4657
- @milkmeat made their first contribution in #4653
- @violonistahiles made their first contribution in #4640
Full Changelog: v0.2.39...v0.2.40