🏢 Background:
Customer churn in the telecom industry poses one of the most significant risks to loss of revenue. The average churn rate in the telecom industry is approximately 1.9% per month across the four major carriers, but could rise as high as 67% annually for prepaid services. Since the cost of acquiring new customers is up to 25 times higher than the cost of retaining them, fostering customer loyalty is key.
With low switching costs and an abundance of alternative providers, customer satisfaction is the most effective means of reducing customer churn in telecom. And the most effective means of improving the customer experience is fully taking advantage of the vast streams of rich telecom customer data. Because based on this data we can make him a special offer, trying to change his decision to leave the operator.
Through this project, and with the dataset provided from a telecommunications company. The data contains information about almost six thousand users, their demographic characteristics, the services they use, the duration of using the operator's services, the method of payment, and the amount of payment.
💭 Task:
In this project we predicted which customers are likely to churn based on certain attributes.
📃 Feature Descriptions:
-
customerID - customer id
-
gender - client gender (male / female)
-
SeniorCitizen - is the client retired (1, 0)
-
Partner - is the client married (Yes, No)
-
tenure - how many months a person has been a client of the company
-
PhoneService - is the telephone service connected (Yes, No)
-
MultipleLines - are multiple phone lines connected (Yes, No, No phone service)
-
InternetService - client’s Internet service provider (DSL, Fiber optic, No)
-
OnlineSecurity - is the online security service connected (Yes, No, No internet service)
-
OnlineBackup - is the online backup service activated (Yes, No, No internet service)
-
DeviceProtection - does the client have equipment insurance (Yes, No, No internet service)
-
TechSupport - is the technical support service connected (Yes, No, No internet service)
-
StreamingTV - is the streaming TV service connected (Yes, No, No internet service)
-
StreamingMovies - is the streaming cinema service activated (Yes, No, No internet service)
-
Contract - type of customer contract (Month-to-month, One year, Two year)
-
PaperlessBilling - whether the client uses paperless billing (Yes, No)
-
PaymentMethod - payment method (Electronic check, Mailed check, Bank transfer (automatic), Credit card (automatic))
-
MonthlyCharges - current monthly payment
-
TotalCharges - the total amount that the client paid for the services for the entire time
-
Churn - whether there was a churn (Yes or No)
🧮 Methodology:
-
Data Understanding:
- 5986 rows and 22 columns
- Remove two columns "Unnamed: 0" and "customerID"
- Feature distribution: Histogramm of all numerical features
- Correlation among the numerical features: Strong correlation (0.83) between "TotalCharges" and "tenure"
- Check for imbalance between the two classes in "Curn": 4300 times "0" and 1587 times "1"
-
Data Cleaning:
- Data leakage: no data leakage (see feature description)
- Outliers: no outliers (see Boxplots)
- Duplicates: no duplicates (based on the column "customerID")
- Missing values:10 missing values in "TotalCharges" (replaced " " by "nan")
- Changing Data Types: "TotalCharges" to numeric; "SenioCitizen" to categorical (No/ Yes instead of 0/1); "Churn" to numeric (0/1 instead of No/ Yes)
-
Data preparation and preprocessing (sklearn):
- Split numerical and categorical features
- Missing Values: Imputation of numerical data (KNNImputer)
- Data Imbalance: Upsamling of categorical data (SMOTENC)
- Define X and Y ("Churn")
- Split the data into train and test data: train_test_split (sklearn.model_selection)
- Pipeline: we created pipelines for both the categorical (incl. OneHotEncoder) and the numeric data (incl. PowerTransformer and StandardScaler) as well as a preprocessor (ColumnTransformer) to combine these two pipelines
- Why PowerTransformer: to make numeric data more Gaussian-line
-
Superviced Machine Learning Algorithm - some theory:
- Supervised Machine Learning: The training data/ labels feeding to the algorithm includes the desired solutions (Churn)
- Classification Algorithm: uses input training data to predict the likelihood that subsequent data will fall into one of the predetermined categories.
- Binary Classifier: Distinguishes between the two classes "Yes" and "No"
- About CatBoostClassifier (Multiclass and Binary Classification):CatBoost (Category Boosting) is an algorithm for gradient boosting on decision trees. It is a readymade classifier in scikit-learn’s conventions terms that would deal with categorical features automatically. (source: https://www.kaggle.com/prashant111/catboost-classifier-in-python). Catboost offers a new technique called Minimal Variance Sampling (MVS), which is a weighted sampling version of Stochastic Gradient Boosting. In this technique, the weighted sampling happens in the tree-level and not in the split-level. The observations for each boosting tree are sampled in a way that maximizes the accuracy of split scoring (Source: https://medium.com/riskified-technology/xgboost-lightgbm-or-catboost-which-boosting-algorithm-should-i-use-e7fda7bb36bc).
- About LightGradientBoostMachine (LightGBM):is an algorithm for gradient boosting on decision trees. lightGBM offers gradient-based one-side sampling (GOSS) that selects the split using all the instances with large gradients (i.e., large error) and a random sample of instances with small gradients. In order to keep the same data distribution when computing the information gain, GOSS introduces a constant multiplier for the data instances with small gradients. Thus, GOSS achieves a good balance between increasing speed by reducing the number of data instances and keeping the accuracy for learned decision trees. This method is not the default method for LightGBM, so it should be selected explicitly (source: https://medium.com/riskified-technology/xgboost-lightgbm-or-catboost-which-boosting-algorithm-should-i-use-e7fda7bb36bc)
- About RandomForestClassifier (Multiclass and Binary Classification): a classification algorithm consisting of many decisions trees. It uses bagging and feature randomness when building each individual tree to try to create an uncorrelated forest of trees whose prediction by committee is more accurate than that of any individual tree.
-
Superviced Machine Learning - Model & Hyperparameter Tuning and Evaluation(pycaret and sklearn):
- Metric: F1 (combination of recall and precision), because we cared for both Recall (reducing FN, to catch as many as possible of those customers who are likely to churn) and Precision (reducing FP, as we had a list of 6000 customers and any action to retain existing customers will also cost money)
- Recall: ratio of positive instances that are correctly detected by the classifier (TP/(TP+FN))
- Precision: Accuracy of positive predicitons (TP/(TP+FP))
- Model Selection (pycaret): CatBoost, RandomForest, LightGradientBoostMachine
- CatBoost: F1-score 0.8372
- LightGradientBoostingMachine: F1-score 0.8324
- RandomForest: F1-score 0.8309
- Tuned CatBoost: 0.8380 --> Best Model
- Tuned LightGradientBoostingMachine: 0.8318
- Tuned RandomForest: 0.8257
- Best parameters of tuned CatBoost: depth 9, l2_leaf_reg 7, random_strength 0.8, n_estimators 210, eta 0.15
- Confusion matrix: TP 1131, FN 189, FP 276, TN 200
-
Feature Interpretation (SHAP):
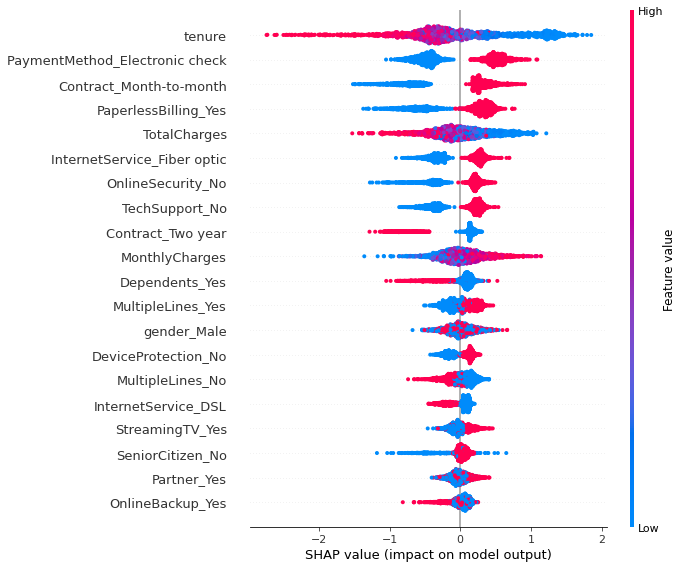
📈 Results:
- The clients that have been subscribed for the longest, are less likely to unsubscribe.
- The clients with longer contract durations, are less likely to unsubscribe.
- The clients that do not subscribe to additional services, such as Online Security and Tech Support, are more likely to unsubscribe.
- The clients that pay their bills electronically, they are more likely to unsubscribe compared to clients with other payment type.
- The clients with the highest monthly payment is, are more likely to unsubscribe.